【珍藏】大语言模型应用指南:RAG、微调与提示工程三种技术深度解析
文章摘要:本文探讨了大语言模型的三种知识增强方法:RAG(检索增强生成)、微调和提示工程。重点介绍了RAG技术原理及实现流程,包括使用FAISS构建向量库、文本切分和相似度检索等关键步骤,并通过动漫知识库查询实例演示了RAG的实际应用。文章比较了三种技术的优缺点,指出RAG能有效扩展模型知识边界,适合知识更新频繁的场景。
文章介绍了大语言模型的三种知识增强技术:RAG通过检索外部知识增强回答,微调使模型适配特定任务,提示工程优化问题描述方式。重点详细讲解了RAG技术的原理、实现流程和代码示例,演示了如何使用FAISS构建向量库,并通过Streamlit开发了一个动漫知识库查询应用,展示了RAG在实际场景中的应用价值。
生成式AI是一种能够生成各类内容的技术,包括文本、图像、音频和合成数据。大语言模型(Large Language Model, LLM)经过海量文本数据的训练后,能将这些文本数据以一种黑盒形式压缩在模型参数中。预训练完成后,模型便掌握了大量的人类世界知识。研究者发现,当模型的规模足够大且经过指令微调对齐后,便可通过提示模板,运用零样本(zero-shot)或少样本(few-shot)的提示词来完成许多自然语言理解和自然语言生成任务。但是大模型并不具备在环境不断变化的场景中回答特定问题所需的全面知识。
针对这种问题,一般有三种解决方式:
1.RAG(Retrieval Augmented Generation)
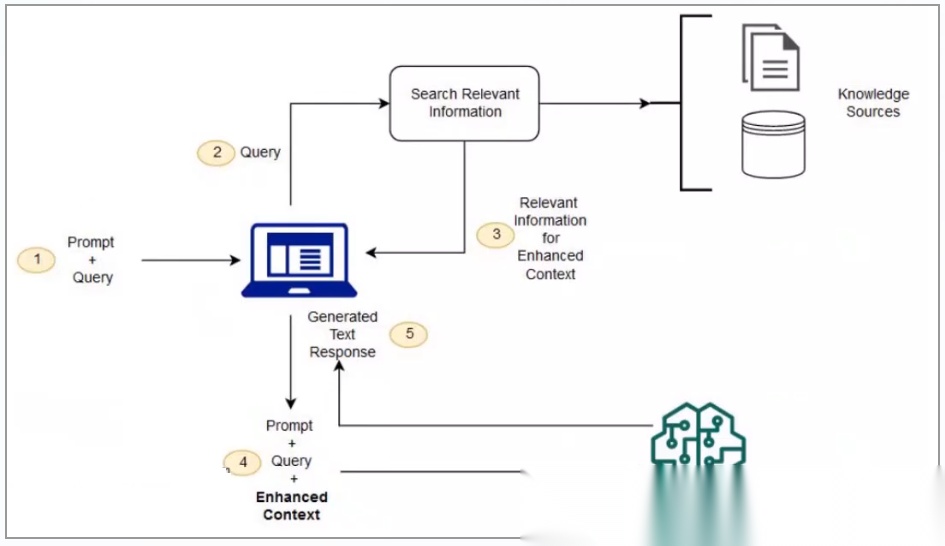
2020年,Facebook在“Retrieval-AugmentedGeneration for Knowledge-Intensive NLP Tasks”一文中首先提出了一种称为检索增强生成(RAG)的框架。该框架可以使模型访问超出其训练数据范围之外的信息,使得模型在每次生成时可以利用检索提供的外部更专业、更准确的知识,从而更好地回答用户问题。
RAG在推理过程中分为两个阶段:检索和内容生成。在检索阶段,通过算法检索与用户问题相关的知识片段。在开放领域中,这些知识片段可以来自互联网上搜索引擎检索到的文档,例如微软Bing AI的模式;在私有领域的企业场景中,通常使用大量的内部文档通过更小的信息源约束来提高模型生成的安全性和可靠性。完成检索之后,可以获取到一些与用户输入相关的可靠外部知识。在内容生成阶段,通过一个结构化的prompt模板约束,将这些外部知识添加到用户的问题中,并传递给语言模型。模型基于知识增强的prompt,通过自己的大量参数计算,就可以生成一个针对该用户问题的更准确的答案。
RAG具体执行时包括三个环节,首先对用户问题进行处理,这个过程通常称为嵌入(embedding),然后从向量库中根据相似度取出跟问题最相关的内容,最后把检索出的内容作为问题的上下文一起发给大模型,通过大模型来生成符合我们习惯的回答。通过向量库的检索,大模型可以掌握原本训练过程中不了解的知识。
2.微调(Fine Tunning)
所谓微调就是对大模型在自己的数据上进行微调。大模型微调的核心是 “保留预训练知识,适配下游任务”,能以较低成本让通用大模型具备场景化能力,是落地大模型应用的关键手段。通过对大模型进行微调,同样可以使大模型具有业务知识,也可以进行知识更新,但是大模型微调需要较高的GPU计算资源,并且较为复杂,训练数据准备也要耗费不少时间。因此,如果对于知识不断变化的场景,会频繁进行微调,成本较高。
3.提示工程(Prompt Engineering)
不同的问题描述方式会导致LLM回答质量的差异。因此,学会如何更好地向LLM描述问题变得非常重要。ChatGPT的爆火推动了prompt工程的兴起,它旨在优化和开发提示词,以便更高效地利用LLM解决各种实际问题。目前,在某些场景下,LLM很难准确理解用户意图,因此我们需要更详细地描述问题才能获得更好的答案。相比RAG和微调,提示工程最简单,因为不需要做额外的工作,但是由于没有加入新的知识,因此大模型所回答的内容依然仅依赖于它原本训练过程中获取到的知识,除非在提示词中把新的知识在上下文中输入到大模型。
这三种技术各有优劣,在不同的场景下可以具体应用。RAG的相关教程现在很多,我这里主要举几个例子,起到抛砖引玉的作用。
要使用RAG,我可以先把需要文档存入到向量库中,这里我们使用FAISS。然后根据相似度查询匹配度最高的内容:
#--------------测试向量库FAISS--------------
from langchain_ollama import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.docstore.document import Document
raw_documents = [Document(page_content="葡萄", metadata={"source": "local"}),
Document(page_content="白菜", metadata={"source": "local"}),
Document(page_content="狗", metadata={"source": "local"})]
embeddings = OllamaEmbeddings(model="bge-m3:567m")
db = FAISS.from_documents(raw_documents, embeddings)
query = "动物"
docs = db.similarity_search(query)
print(docs[0].page_content)
# 输出:狗
这里可以看到,我们先把“葡萄”、“白菜”、“狗”作为原始文本,通过embedding模型,对文本进行嵌入操作,然后把embedding后的文本向量存储到向量库中,最后根据查询的问题去寻找相似度最高的文本。
可以看到,构建RAG向量库的基本流程都是如此的方式。
下面我们看一个简单的查询例子,假设我想构建一个动漫知识库,存储一些热门动漫。我这里有个《龙珠》的简单介绍,我想要存储到向量库中,并进行提问。原始文本如下:
孙悟空是《龙珠》系列的核心主人公,来自贝吉塔行星的赛亚人,以乐观、勇敢和对战斗的热爱贯穿全篇。
### 核心身份与背景
原名卡卡罗特,婴儿时期被送往地球,因头部撞击失去赛亚人侵略本性,被地球人孙悟饭收养长大。
赛亚人天生热爱战斗,拥有越战越强的体质,还有变身超级赛亚人等强大形态的能力。
### 关键性格特质
纯真善良,对世界充满好奇,不谙世事却坚守正义底线。
战斗狂热,遇强则强,始终追求更强的对手和更高的实力境界。
重视亲情与友情,愿意为保护家人、伙伴和地球付出一切,甚至牺牲自己。
### 成长与成就
从懵懂的山野少年起步,历经无数战斗,结识布尔玛、克林、贝吉塔等挚友。
多次拯救地球于毁灭危机,击败弗利萨、沙鲁、布欧等强敌,成为宇宙级的强者。
始终保持谦逊,即便实力顶尖,仍不断修炼突破,从未停止变强的脚步。
### 核心攻击型绝招
龟派气功:最具代表性的招式,双手合十积蓄能量后推出冲击波,可根据实力提升威力,是常用的远程攻击手段。
元气弹:集合周围生物的元气凝聚成巨大能量球,威力极强且只对邪恶目标生效,多次在决战中扭转战局。
龙拳爆发:将能量集中于拳头,打出形似巨龙的冲击,爆发力惊人,常用于近距离重创强敌。
近身与辅助型招式
舞空术:通过控制能量实现飞行,是后期战斗和移动的基础技能。
瞬间移动:从 Yardrat 星习得,能感知对方气息并瞬间转移到指定地点,兼具逃生、支援和突袭功能。
赛亚人变身:不算直接招式但核心能力,从超级赛亚人到超蓝、超本能等形态,变身後全方面提升战斗力,配合招式发挥更强威力。
衍生与组合招式
界王拳:通过倍数提升自身战斗力,初期常用,后期多与变身形态结合使用,但会对身体造成负荷。
分身术:分裂出多个自身分身,用于迷惑对手或同时攻击,实力随本体强度同步。
我们这里先用文档加载器把txt文本加载进来,然后通过RecursiveCharacterTextSplitter类对文档进行分段,分段也是一个影响RAG效果的非常关键步骤,不同的分段策略可能导致RAG的效果有很大的差别。我这里选择每500个字分段,并设定以换行符作为分段标志。分段后的文档再进行embedding操作,存入到向量库。查询的时候,系统会先去向量库中寻找问题相关的内容,再和问题一起提交给大模型,从而得到结果。
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langchain_ollama import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.docstore.document import Document
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 数据加载与文本切块
loader = TextLoader('2.txt', encoding='utf-8') # 定义加载器
documents = loader.load() # 加载文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0, separators=["\n"]) # 定义一个文档切分器
chunks = text_splitter.split_documents(documents) # 切分文档
template = """
你是一位问答助手,你的任务是根据###中间的文本信息回答问题,请准确回答问题,不要健谈,如果提供的文本信息无法回答问题,请直接回复“提供的文本无法回答问题”,
我相信你能做得很好。###\n{context}###\n 问题:{question}
"""
question = "卡卡罗特的绝招有哪些?"
# 写入向量数据库,获取检索器
embeddings = OllamaEmbeddings(model="bge-m3:567m")
db = FAISS.from_documents(chunks, embeddings)
retriever = db.as_retriever(search_kwargs={"k": 2})
# 召回和问题相关的文本
context = retriever.get_relevant_documents(question)
print(context)
context_str = "; ".join([doc.page_content for doc in context])
input_str = template.format_map({"context":context_str, "question":question})
chat = ChatOpenAI(
streaming=True,
model='deepseek-chat',
openai_api_key='<你的API KEY>',
openai_api_base='https://api.deepseek.com',
max_tokens=1024
)
messages = [
SystemMessage(content="你是一位问答助手"),
HumanMessage(content=input_str)
]
response = chat(messages)
print(response.content)

根据控制台的输出,我们可以看到系统找到的分段,并且给出了正确的结果,而且我们这里问的是卡卡罗特,而文档里面一开始说的是孙悟空,说明大模型自动识别了卡卡罗特就是孙悟空。
下面我用streamlit作为前端界面框架,做了一个简单的例子,我们可以针对向量库中的内容进行查询,并可以添加新的文档到向量库中,增加文档的知识。首先构建一个可以操作向量库的工具文件:
# 例子,动漫RAG
# 存储和获取向量库
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_ollama import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import Docx2txtLoader
def load_word_file(file_path):
loader = Docx2txtLoader(file_path)
data = loader.load()
return data
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n","\n\n"],
chunk_size=500,
chunk_overlap=0,
length_function=len,
is_separator_regex=False
)
def add_word(filename, index_name):
# Word
docs = load_word_file(filename)
documents = text_splitter.split_documents(docs)
embeddings = OllamaEmbeddings(model="bge-m3:567m")
vector = FAISS.load_local("faiss_index_word", embeddings, allow_dangerous_deserialization=True)
vector.add_documents(documents)
vector.save_local("faiss_index_word")
def get(index_name):
embeddings = OllamaEmbeddings(model="bge-m3:567m")
vector = FAISS.load_local(index_name, embeddings, allow_dangerous_deserialization=True)
return vector
def init_db(index_name):
file_path = "D:\\zj\\AI\\corpus\\孙悟空.docx"
docs = load_word_file(file_path)
documents = text_splitter.split_documents(docs)
# -------------------- 2. 向量库构建 --------------------
# 使用 OpenAI 文本嵌入(可替换为其他嵌入模型)
embeddings = OllamaEmbeddings(model="bge-m3:567m")
# 创建 FAISS 向量库
vector_db = FAISS.from_documents(
documents=documents,
embedding=embeddings
)
vector_db.save_local(index_name)
然后用Streamlit作为外部界面,构建一个可以查询和增加文档的小应用,也可以对向量库进行初始化,初始化的时候,系统会自动构建动漫龙珠的向量库,后续可以上传文档并添加新的知识。
import streamlit as st
from langchain_core.output_parsers import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from vector2 import init_db,get,add_word
import asyncio
chat = ChatOpenAI(
streaming=True,
model='deepseek-chat',
openai_api_key='<你的AIP KEY>',
openai_api_base='https://api.deepseek.com',
max_tokens=1024
)
def main():
index_name = "anime_index_word"
st.title("动漫知识库")
question = st.text_input("请输入查询内容:")
uploaded_file = st.sidebar.file_uploader("上传文件", type=["txt", "docx"])
if st.sidebar.button("初始化向量库"):
init_db(index_name)
if uploaded_file is not None:
if st.sidebar.button("添加文件到向量库"):
with open("D:\\temp\\"+uploaded_file.name, "wb") as f:
f.write(uploaded_file.getbuffer())
f.close()
add_word("D:\\temp\\"+uploaded_file.name, index_name)
st.sidebar.success("添加成功")
if st.button("执行查询"):
if question:
template = """
你是一位问答助手,你的任务是根据###中间的文本信息回答问题,请准确回答问题,不要健谈,如果提供的文本信息无法回答问题,请直接回复“提供的文本无法回答问题”,
我相信你能做得很好。###\n{context}###\n 问题:{question}
"""
PROMPT = PromptTemplate(
template=template,
input_variables=["context","question"]
)
db = get(index_name)
retriever = db.as_retriever(search_kwargs={"k": 2})
# 召回和问题相关的文本
context = retriever.get_relevant_documents(question)
print(context)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| PROMPT
| chat
| StrOutputParser()
)
# 流式返回
stream = chain.stream(question)
st.write_stream(stream)
else:
st.write("查询出错,请检查输入或数据库连接。")
if __name__ == "__main__":
main()
运行后,界面如下:
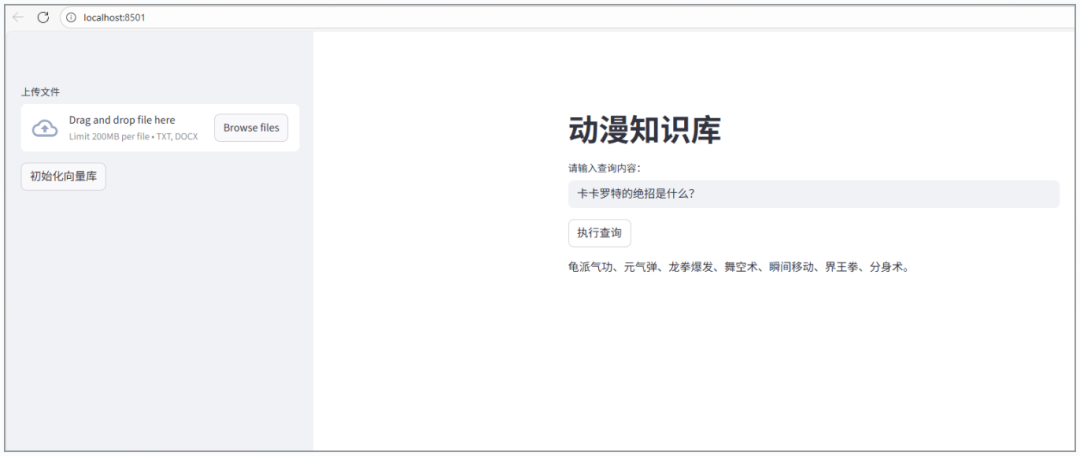
可以看到,回答的结果是正确的,下面再看一下,我问文档中不存在的《诛仙》的问题:
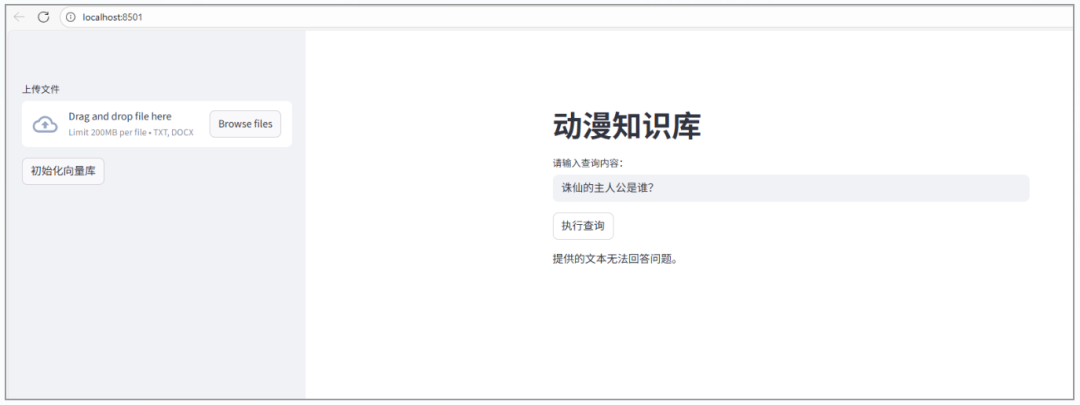
系统就无法正确回答了,所以我增加一下《诛仙》的知识进去:
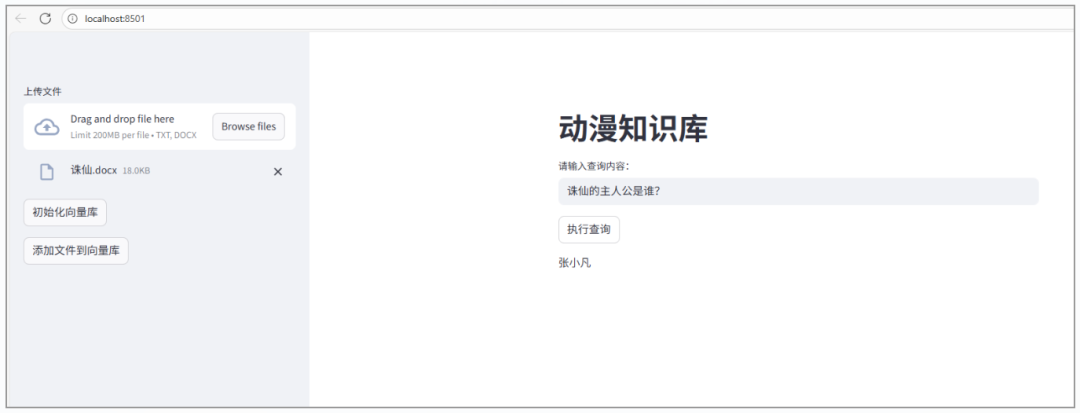
可以看到,当我上传了《诛仙》的相关文档后,系统就可以查询到《诛仙》的相关信息了。
AI时代,未来的就业机会在哪里?
答案就藏在大模型的浪潮里。从ChatGPT、DeepSeek等日常工具,到自然语言处理、计算机视觉、多模态等核心领域,技术普惠化、应用垂直化与生态开源化正催生Prompt工程师、自然语言处理、计算机视觉工程师、大模型算法工程师、AI应用产品经理等AI岗位。
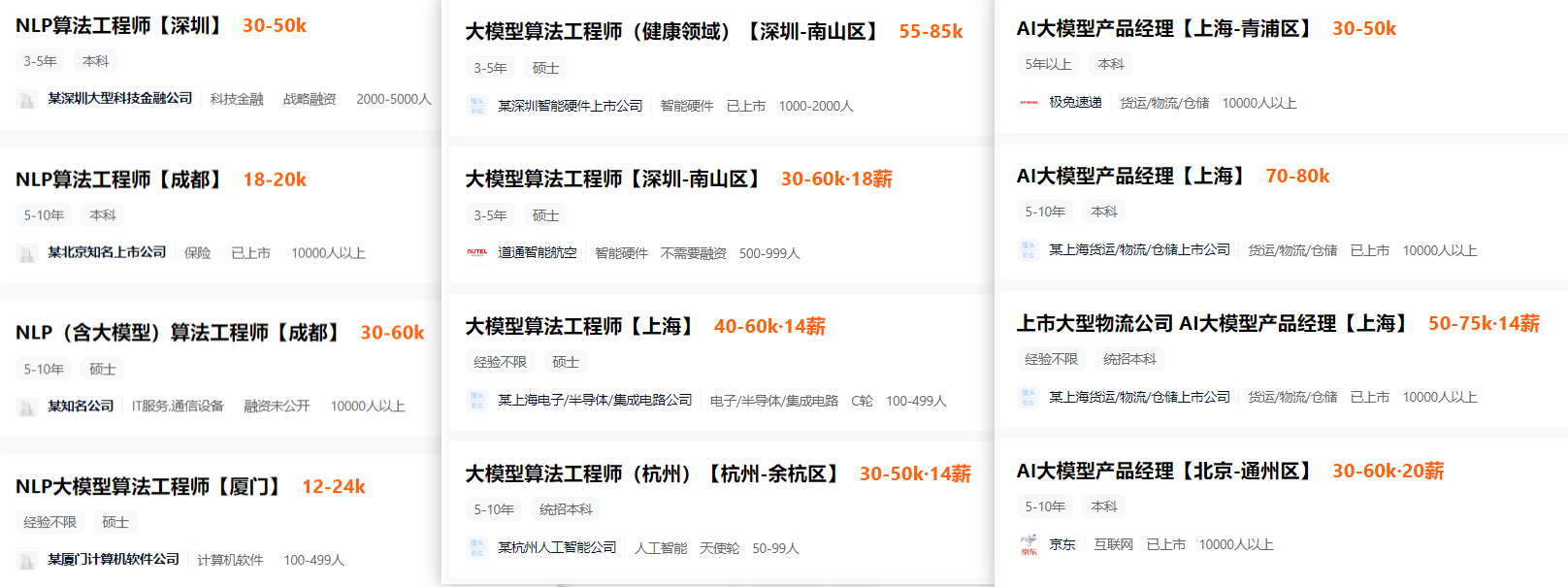
掌握大模型技能,就是把握高薪未来。
那么,普通人如何抓住大模型风口?
AI技术的普及对个人能力提出了新的要求,在AI时代,持续学习和适应新技术变得尤为重要。无论是企业还是个人,都需要不断更新知识体系,提升与AI协作的能力,以适应不断变化的工作环境。
因此,这里给大家整理了一份《2025最新大模型全套学习资源》,包括2025最新大模型学习路线、大模型书籍、视频教程、项目实战、最新行业报告、面试题等,带你从零基础入门到精通,快速掌握大模型技术!
由于篇幅有限,有需要的小伙伴可以扫码获取!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。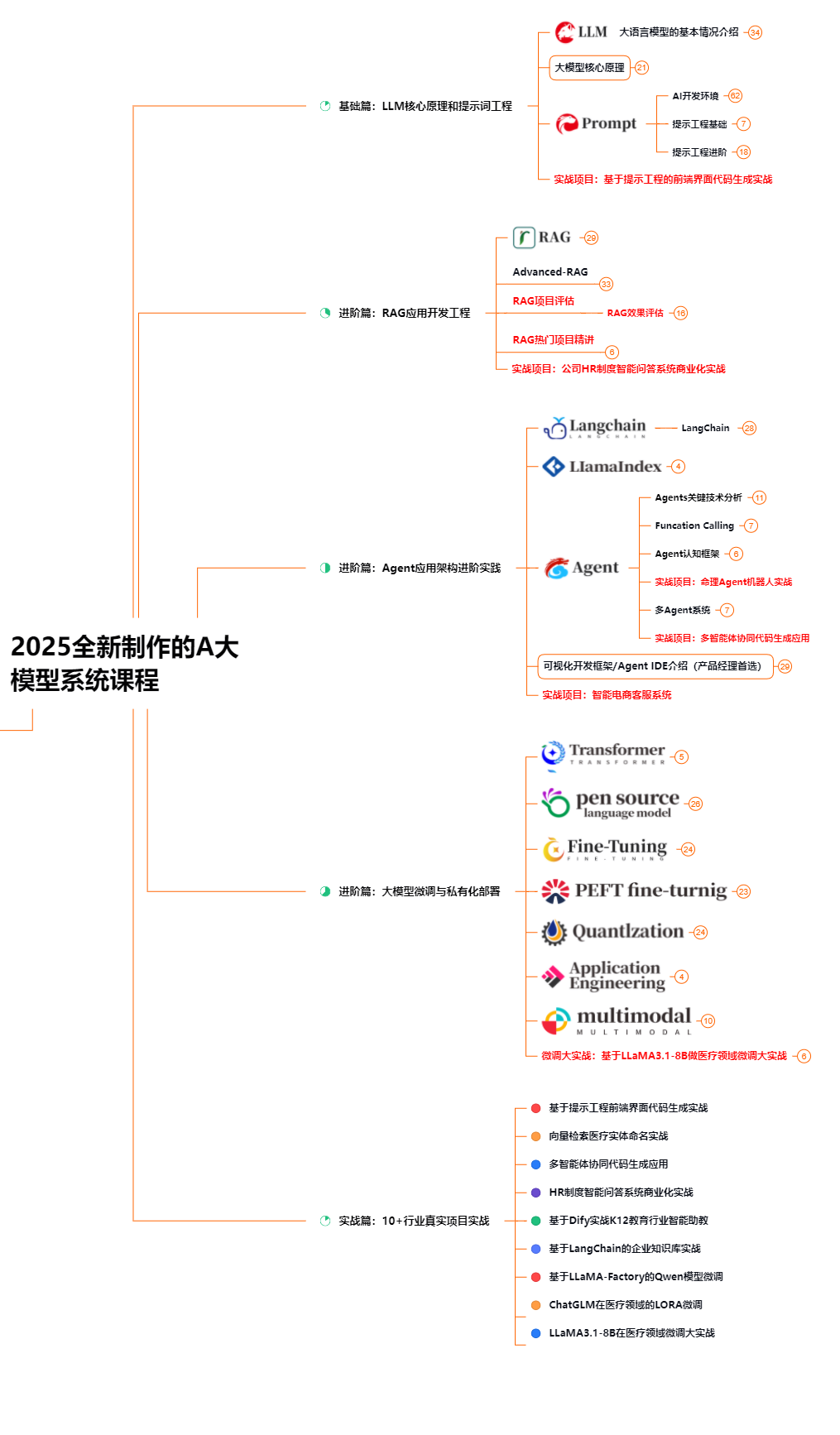
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
5. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

为什么大家都在学AI大模型?
随着AI技术的发展,企业对人才的需求从“单一技术”转向 “AI+行业”双背景。企业对人才的需求从“单一技术”转向 “AI+行业”双背景。金融+AI、制造+AI、医疗+AI等跨界岗位薪资涨幅达30%-50%。
同时很多人面临优化裁员,近期科技巨头英特尔裁员2万人,传统岗位不断缩减,因此转行AI势在必行!

这些资料有用吗?
这份资料由我们和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


大模型全套学习资料已整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献400条内容
已为社区贡献400条内容

所有评论(0)