DevOps系列之生产Java问题常见排查
Java生产环境故障排查与性能分析指南摘要 核心工具: HPROF文件分析OOM问题 堆内存快照,记录对象实例、引用关系 使用MAT工具分析泄漏报告/支配树/直方图 重点排查Retained Heap大的对象 JFR文件分析性能问题 低开销持续记录JVM运行数据 使用JMC分析CPU热点/线程阻塞/内存分配 支持按症状选择分析路径(CPU高/响应慢/GC频繁) 关键技巧: OOM问题查支配树找内存
Java 生产环境故障排查与性能分析指南
OOM 崩溃 -> 查 HPROF
慢/卡/CPU高 -> 查 JFR
0. 核心概念与分析目标
1 Java HPROF 文件分析指南
1.1 什么是 HPROF 文件?(文件介绍)
HPROF 是 Java 堆内存转储(Heap Dump)文件的标准后缀名。
- 本质:它是一张“快照” (Snapshot)。它记录了在 JVM 崩溃或手动导出那一瞬间,Java 堆内存中所有存活对象的状态。
- 包含内容:
- 对象实例:内存里有哪些对象(String, HashMap, User对象等)。
- 引用关系:谁在引用谁(A 引用了 B,导致 B 无法被回收)。
- 对象大小:每个对象占用了多少字节。
- 类信息:类加载器、静态变量等。
- 不包含内容:通常不包含对象被分配时的堆栈信息(除非使用特殊的 Agent),也不包含 CPU 使用情况。
1.2 文件来源:如何获取 HPROF?
参考 OOM 生产持久化,K8S + OSS等方案,这里说手动的方式
当发现内存缓慢上涨但还未崩溃时,手动导出,命令 (需进入 Pod):
# 查找 Java 进程 PID
jcmd
# 导出 Dump
jcmd <PID> GC.heap_dump /tmp/manual-dump.hprof
1.3 MAT 查看方式与核心视图
假设你使用 Eclipse MAT 打开了文件,以下是必须关注的三个核心视图:
第一步:概览与泄漏报告
打开文件后,MAT 会弹出一个向导,直接选择 “Leak Suspects Report” (泄漏疑点报告)。
- 作用:MAT 会自动通过算法计算,告诉你:“有个地方占了 80% 的内存,嫌疑最大的是这个
ArrayList”。 - 价值:80% 的 OOM 问题看这个报告就能解决。
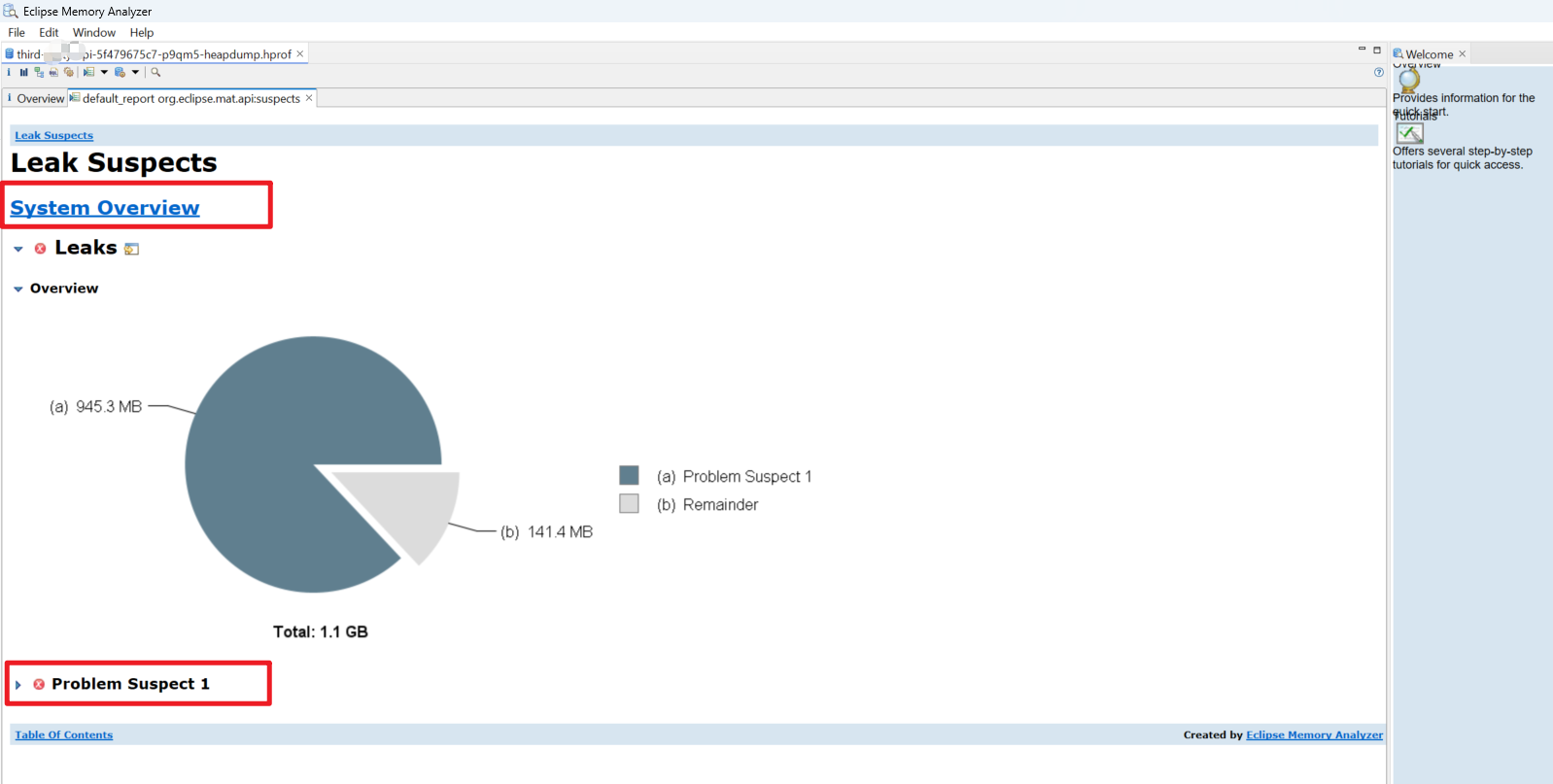
第二步:Dominator Tree (支配树) —— 最重要
点击工具栏上的按钮进入。
- 展示内容:列出内存中最大的对象。
- 排序:默认按
Retained Heap(深堆/保留大小) 倒序排列。 - 怎么看:排在第一行的通常就是导致 OOM 的元凶(比如一个巨大的 Cache,或者一个无限增长的 Queue)。
第三步:Histogram (直方图)
- 展示内容:按“类”分组,统计每个类有多少个实例。
- 怎么看:如果你发现
java.lang.String或char[]有几百万个,虽然单个很小,但加起来很大。这通常意味着日志过多、缓存设计不当或循环拼接字符串。
1.4 分析技巧:如何定位问题?
核心概念:Shallow vs Retained Heap
- Shallow Heap (浅堆):对象本身占用的内存(比如一个 ArrayList 对象本身只有几十字节)。
- Retained Heap (深堆):对象被回收后,能释放的总内存(这个 ArrayList 里面存了 100万个 User,那它的深堆就是几百 MB)。
- 分析口诀:找 Retained Heap 最大的对象,它就是内存黑洞。
技巧 A:Path to GC Roots (顺藤摸瓜)
当你发现了一个不该存在的大对象(比如一个应该被销毁的 UserContext),你想知道“是谁抓着它不放?”
- 在 Dominator Tree 中选中该对象。
- 右键 ->
Path to GC Roots->exclude all phantom/weak/soft etc. references(排除软弱虚引用,只看强引用)。 - 结果:MAT 会展示一条引用链,比如:
ThreadLocal->Map->UserContext。你就知道是 ThreadLocal 没清理导致的。
2 JFR 文件 (Java Flight Recorder)
2.1 什么是 JFR 文件?(文件介绍)
JFR (Java Flight Recorder) 是 JVM 内置的性能监控和故障诊断工具。
- 本质:它像飞机的黑匣子一样,连续记录 JVM 运行一段时间内的所有事件。它不是“一瞬间”的快照,而是一段“录像”。
- 文件后缀:
.jfr - 核心特性:极低开销 (Overhead < 1%)。基于事件采样机制,专为生产环境 7x24 小时运行设计。
- 主要分析内容:
- Method Profiling (CPU):哪些方法在消耗 CPU(采样)。
- Wall Clock (Latency):线程在“等待”什么(锁、IO、Sleep)。
- Memory Allocation (TLAB):对象分配速率(谁在制造垃圾),而不是存活对象。
- JVM Internals:GC 暂停时间、JIT 编译、类加载。
- Thread Dumps:定时的线程快照。
2.2 文件来源:如何获取 JFR?
在 EKS + DataKit 环境中,获取方式非常灵活:
A. 通过 观测云平台下载
如果您开启了 Continuous Profiler:
- 登录观测云 APM 界面。
- 找到感兴趣的时间段(比如 CPU 飙高那分钟)。
- 点击右上角的 Download Recording (下载 JFR)。
B. 命令行按需开启 (排查特定问题)
手动抓取某 60 秒的数据:
# 1. 找到 Java 进程 PID
jcmd
# 2. 开启录制 (持续 60秒,存到 /tmp)
jcmd <PID> JFR.start duration=60s filename=/tmp/my-recording.jfr
2.3 分析技巧与排查流程 (Workflow)
拿到 .jfr 文件后,不要盲目看,请根据“症状”选择分析路径:
场景一:CPU 飙高 (High CPU)
- 工具选择:IDEA 或 JMC。
- JMC 路径:
Method Profiling(方法分析) ->Count(排序)。 - 分析技巧:
- 找 “Hot Methods”:看哪个方法占用的 Samples 最多。
- 辨别类型:
- 如果是业务方法(如
OrderService.calc):检查死循环、复杂算法。 - 如果是
G1Refine/GC相关:说明内存压力大,CPU 被 GC 吃掉了(转去查内存分配)。 - 如果是
C2 Compiler:刚启动时的正常热身。
- 如果是业务方法(如
场景二:应用响应慢,但 CPU 不高 (Latency / Slowness)
- 工具选择:JMC 是首选。
- JMC 路径:
- 看左侧 Automated Analysis Results:有没有红色的
Synchronized Locks或Socket I/O。 - 看 Threads 视图:勾选
Socket Read或Java Blocking。
- 看左侧 Automated Analysis Results:有没有红色的
- 分析技巧:
- Socket Read:如果耗时很长,查该线程连接的 IP 是哪里(数据库?Redis?第三方?)。
- Monitor Blocked:如果看到红色的阻塞条,说明发生了锁竞争。查看
Lock Instances找是谁持有了锁。
场景三:排查频繁 GC / 内存分配过快 (Allocation Pressure)
- 注意:JFR 不擅长看“内存泄漏”(那是 HPROF 的事),但它擅长看“谁在制造垃圾”。
- JMC 路径:
Memory->TLAB Allocations。 - 分析技巧:
- 查看 Allocation by Class:通常是
char[](String) 或byte[]。 - 查看 Stack Trace:看是哪行代码在疯狂
new对象。 - 优化:减少这些临时对象的创建,就能降低 GC 频率,从而降低 CPU。
- 查看 Allocation by Class:通常是
2.4 关键指标解读备忘 (Cheatsheet)
在 JMC 的“自动分析结果”页面,关注以下警告:
- 🔴 Synchronized Locks:死锁或严重的锁竞争。
- 🔴 Socket I/O:网络调用极慢。
- 🟠 G1 GC Pause:GC 停顿时间超过了预期。
- 🟠 Code Cache Full:JIT 编译器没内存用了,性能会退化。
- 🟠 Stackdepth Truncated:调用栈太深被截断了(提示你需要把
stackdepth调大到 256)。
3. 常用分析工具 (Toolbox)
| 工具名称 | 适用文件类型 | 推荐场景 | 特点 | 下载地址 |
|---|---|---|---|---|
| Eclipse Memory Analyzer (MAT) | .hprof |
OOM 必选 | 业界标准,擅长分析大内存,拥有强大的“支配树”和“泄漏报告”。 | 官方下载地址 |
| JDK Mission Control (JMC) | .jfr |
性能调优必选 | Oracle/OpenJDK 官方工具,由“自动分析”功能,能给出评分和建议。 | Eclipse JMC 官方版 |
| IntelliJ IDEA (Ultimate) | .hprof / .jfr |
日常快速查看 | 界面友好,直接关联源码,适合开发人员快速定位热点。 | |
| VisualVM | Both | 轻量级查看 | 简单直观,适合查看基础指标,深度分析能力弱于 MAT/JMC。 |
3. 排查与分析流程 (Workflow)
场景 A:应用发生 OOM (OutOfMemoryError)
- 获取文件:
- 通过
-XX:+HeapDumpOnOutOfMemoryError自动生成。 - 文件路径通常为启动参数配置的
-XX:HeapDumpPath(如/tmp或挂载卷)。
- 通过
- 使用 MAT 分析:
- 第一步:打开文件,选择 “Leak Suspects Report”(泄漏疑点报告)。
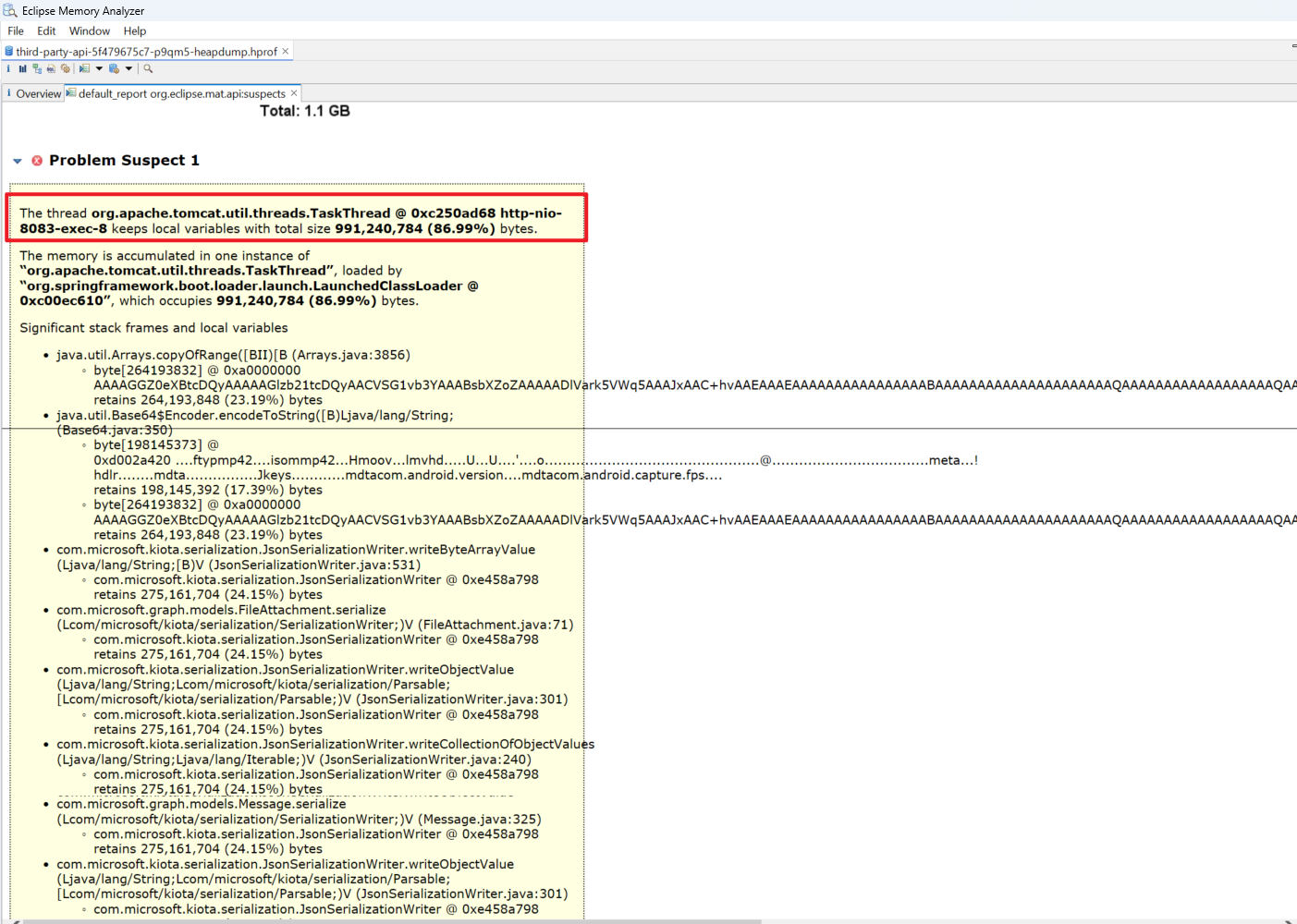
- 第二步:查看 Dominator Tree。按
Retained Heap(深堆)倒序排列。 - 第三步:找到占比最大的对象,右键 ->
Path to GC Roots->exclude all phantom/weak/soft etc. references。 - 结论:如果发现某个
List、Map或ThreadLocal占用了 80% 内存,且无法回收,即为内存泄漏源头。
- 第一步:打开文件,选择 “Leak Suspects Report”(泄漏疑点报告)。
场景 B:应用 CPU 飙高或响应慢 (Performance Issue)
- 获取文件:
- Datadog 用户:直接在 APM Profiler 界面下载
.jfr文件。 - 手动获取:使用
jcmd <pid> JFR.start duration=60s filename=myrecording.jfr。
- Datadog 用户:直接在 APM Profiler 界面下载
- 使用 JMC 分析:
- 第一步 (看宏观):点击左侧 Automated Analysis Results。关注红色/橙色警告(如“Synchronized Locks”、“Socket I/O”)。
- 第二步 (看 CPU):点击 Method Profiling。按
Count排序,找到最热的方法(Hotspot)。 - 第三步 (看延迟):点击 Threads 视图,勾选
Java Blocking或Socket Read,查看线程是否被数据库或网络阻塞。
- 使用 IDEA 分析:
- 直接拖入
.jfr文件,查看 Flame Graph (火焰图)。 - 宽顶原则:寻找最顶层且最宽的色块,直接点击跳转到代码。
- 直接拖入
4. 关键指标解读备忘 (Cheatsheet)
HPROF 常见嫌疑人
char[]/String:通常是日志打印过多、XML/JSON 解析生成的大量临时字符串。Object[]:通常是ArrayList或HashMap等集合类持有大量对象。ClassLoader:如果出现大量 ClassLoader,可能是元空间(Metaspace)泄漏(常见于动态代理、热部署)。
JFR 常见嫌疑人
SocketRead/SocketWrite:网络 IO 慢(数据库、Redis、第三方 API)。Monitor Blocked:synchronized锁竞争严重。G1NewAllocator:年轻代分配过快,通常意味着代码在循环中创建了大量临时对象。Throwable/Exception:业务代码在用异常控制流程,或底层连接不断失败重试。
5. 工具下载地址 (Resources)
- Eclipse Memory Analyzer (MAT)
- 官方下载地址
- 注意:MAT 运行需要 JDK 17+,分析大堆文件时需修改
MemoryAnalyzer.ini中的-Xmx参数。
- JDK Mission Control (JMC)
- Eclipse 官方版 (推荐,兼容性好)
- Azul Mission Control (对 Mac 支持较好)
- 注意:需下载 JMC 8.0 或 9.0+ 以支持 JDK 17/21。
- VisualVM

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)