【第一阶段—数学基础】第六章:AI数学入门:线性代数基础—变形金刚的骨架
本文系统介绍了线性代数在人工智能中的核心应用,重点讲解了向量的基本概念与运算方法。主要内容包括:1)向量作为AI的基本语言,通过实例展示了如何用多维向量表示学生成绩、图像像素和词语特征;2)详细解析了向量加法、数乘、点积和模长等基本运算及其现实类比;3)重点阐述了余弦相似度的计算原理与几何意义,通过苹果、香蕉和iPhone的向量对比,演示了如何量化语义相似性。文章通过Python代码示例和直观图示

📋 本篇内容
向量概念 → 矩阵运算 → 特征值 → 矩阵分解 → AI应用
🎯 1. 向量:AI的基本语言
1.1 什么是向量?
生活类比:向量就像是"带方向的箭头"
# 向量的本质:一组有序的数字
import numpy as np
# 例子1:一个学生的成绩
student_scores = np.array([85, 90, 78]) # [数学, 英语, 物理]
# 这就是一个3维向量!
# 为什么是3维?因为用3个数字来描述这个学生的成绩
# 第1维:数学成绩 = 85
# 第2维:英语成绩 = 90
# 第3维:物理成绩 = 78
# 💡 向量的维度 = 用来描述对象的特征数量
# 例子2:一张图片的像素
# 一个32x32的灰度图片 = 1024维向量
# 为什么是1024维?因为 32 × 32 = 1024 个像素点
# 每个像素点的灰度值(0-255)就是向量的一个维度
image = np.array([0, 15, 230, ...]) # 1024个数字,每个数字代表一个像素的灰度值
# 0 = 黑色,255 = 白色,中间值 = 不同程度的灰色
# 💡 更直观的理解:
# 想象把一张32×32的图片"拉平"成一条线
# 原本是:
# 第1行:[0, 15, 230, ...] (32个像素)
# 第2行:[45, 100, 200, ...] (32个像素)
# ...
# 第32行:[...] (32个像素)
# 拉平后:[0, 15, 230, ..., 45, 100, 200, ..., ...] (1024个数字)
# 这就是一个1024维向量!
# 例子3:一个词的特征
# "苹果"这个词可以表示为:
word_apple = np.array([0.2, 0.8, 0.1, 0.9]) # [水果性, 科技性, 颜色, 甜度]
# 为什么是4维?因为我们选择用4个特征来描述"苹果"这个词
# 第1维:水果性 = 0.2(不太像水果?其实应该是0.9,这里假设是品牌"苹果")
# 第2维:科技性 = 0.8(很有科技感,想到iPhone)
# 第3维:颜色 = 0.1(红色程度,这里假设指的是公司logo)
# 第4维:甜度 = 0.9(如果是水果苹果,很甜)
# 💡 在AI中,词向量通常有几百维,用来捕捉词的各种语义特征
# 📌 总结:向量维度的本质
# 向量的维度 = 描述对象所需的数字个数
# - 3个成绩 → 3维向量
# - 1024个像素 → 1024维向量
# - 4个特征 → 4维向量
# 维度越高,描述越详细,但计算也越复杂
# 🎮 游戏玩家的类比:六边形战士!
# 想象游戏中描述一个英雄的能力:
hero_stats = np.array([90, 85, 70, 95, 80, 88])
# [攻击, 防御, 速度, 技能, 生命, 魔法] → 6维向量
#
# 在雷达图上:
# 攻击(90)
# /\
# 魔法 / \ 防御
# (88) /____\ (85)
# / \
# 生命/ \速度
# (80)/ \(70)
# \ /
# \________/
# 技能(95)
#
# 这就是"六边形战士"!用6个维度描述英雄的全面能力
# AI也是这样:用多个维度来描述和理解事物!
为什么AI需要向量?
- 计算机只认识数字
- 向量可以表示任何东西:图片、文字、声音
- 向量之间可以计算相似度
1.2 向量的基本运算
import numpy as np
# 创建向量
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 1️⃣ 向量加法(对应位置相加)
# 生活类比:两个人的工资分别是 [基本工资, 奖金, 补贴]
salary_A = np.array([5000, 2000, 1000])
salary_B = np.array([6000, 1500, 800])
total = salary_A + salary_B # [11000, 3500, 1800]
print(f"总工资: {total}")
# 2️⃣ 向量数乘(每个元素乘以同一个数)
# 生活类比:工资涨20%
salary = np.array([5000, 2000, 1000])
after_raise = salary * 1.2 # [6000, 2400, 1200]
print(f"涨薪后: {after_raise}")
# 3️⃣ 点积(Dot Product)- 最重要!
# 生活类比:计算总分
scores = np.array([85, 90, 78]) # 各科成绩
weights = np.array([0.4, 0.3, 0.3]) # 各科权重
total_score = np.dot(scores, weights) # 85*0.4 + 90*0.3 + 78*0.3
print(f"加权总分: {total_score}")
# 4️⃣ 向量长度(模)
# 生活类比:从家到公司的直线距离
displacement = np.array([3, 4]) # 向东3km,向北4km
distance = np.linalg.norm(displacement) # √(3² + 4²) = 5km
print(f"直线距离: {distance}km")
1.3 向量的相似度
import numpy as np
def cosine_similarity(a, b):
"""计算余弦相似度(-1到1,越接近1越相似)"""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 例子:判断两个词是否相似
# 假设我们用4个特征表示词:[水果性, 科技性, 红色, 甜度]
apple = np.array([0.9, 0.1, 0.8, 0.9]) # 苹果
banana = np.array([0.9, 0.1, 0.2, 0.8]) # 香蕉
iphone = np.array([0.1, 0.9, 0.3, 0.0]) # iPhone
print(f"苹果 vs 香蕉: {cosine_similarity(apple, banana):.2f}") # 0.92 很相似
print(f"苹果 vs iPhone: {cosine_similarity(apple, iphone):.2f}") # 0.29 不太相似
1.4 余弦相似度详解
公式:
cos(θ) = (a · b) / (||a|| × ||b||)
其中:
- a · b = 点积(内积)= Σ(aᵢ × bᵢ)
- ||a|| = 向量a的模长 = √(Σaᵢ²)
- ||b|| = 向量b的模长 = √(Σbᵢ²)
计算步骤:
1️⃣ 计算点积(分子):对应元素相乘再求和
苹果·香蕉 = 0.9×0.9 + 0.1×0.1 + 0.8×0.2 + 0.9×0.8 = 1.70
2️⃣ 计算模长(分母):各元素平方和再开方
||苹果|| = √(0.9² + 0.1² + 0.8² + 0.9²) = 1.51
||香蕉|| = √(0.9² + 0.1² + 0.2² + 0.8²) = 1.22
3️⃣ 相除得到相似度:
相似度 = 1.70 / (1.51 × 1.22) = 0.92 ✓ 很相似!
同理计算"苹果 vs iPhone":
点积 = 0.9×0.1 + 0.1×0.9 + 0.8×0.3 + 0.9×0.0 = 0.33
相似度 = 0.33 / (1.51 × 0.95) = 0.23 ✗ 不相似
几何意义:向量夹角的余弦值
1.0 → 完全相同(夹角0°)
0.5 → 比较相似(夹角60°)
0.0 → 完全无关(夹角90°,垂直)
-0.5 → 相反趋势(夹角120°)
-1.0 → 完全相反(夹角180°)
为什么"苹果"和"香蕉"相似?
- 都是水果(0.9 vs 0.9)✓
- 都不是科技产品(0.1 vs 0.1)✓
- 都比较甜(0.9 vs 0.8)✓
- 只有颜色不同(0.8 vs 0.2)
为什么"苹果"和"iPhone"不相似?
- 水果性相反(0.9 vs 0.1)✗
- 科技性相反(0.1 vs 0.9)✗
- 甜度不同(0.9 vs 0.0)✗
为什么叫"余弦"相似度?
余弦相似度的名字来源于它计算的是两个向量夹角的余弦值。在二维空间中可以直观看到:
情况1:相似的向量(苹果 vs 香蕉)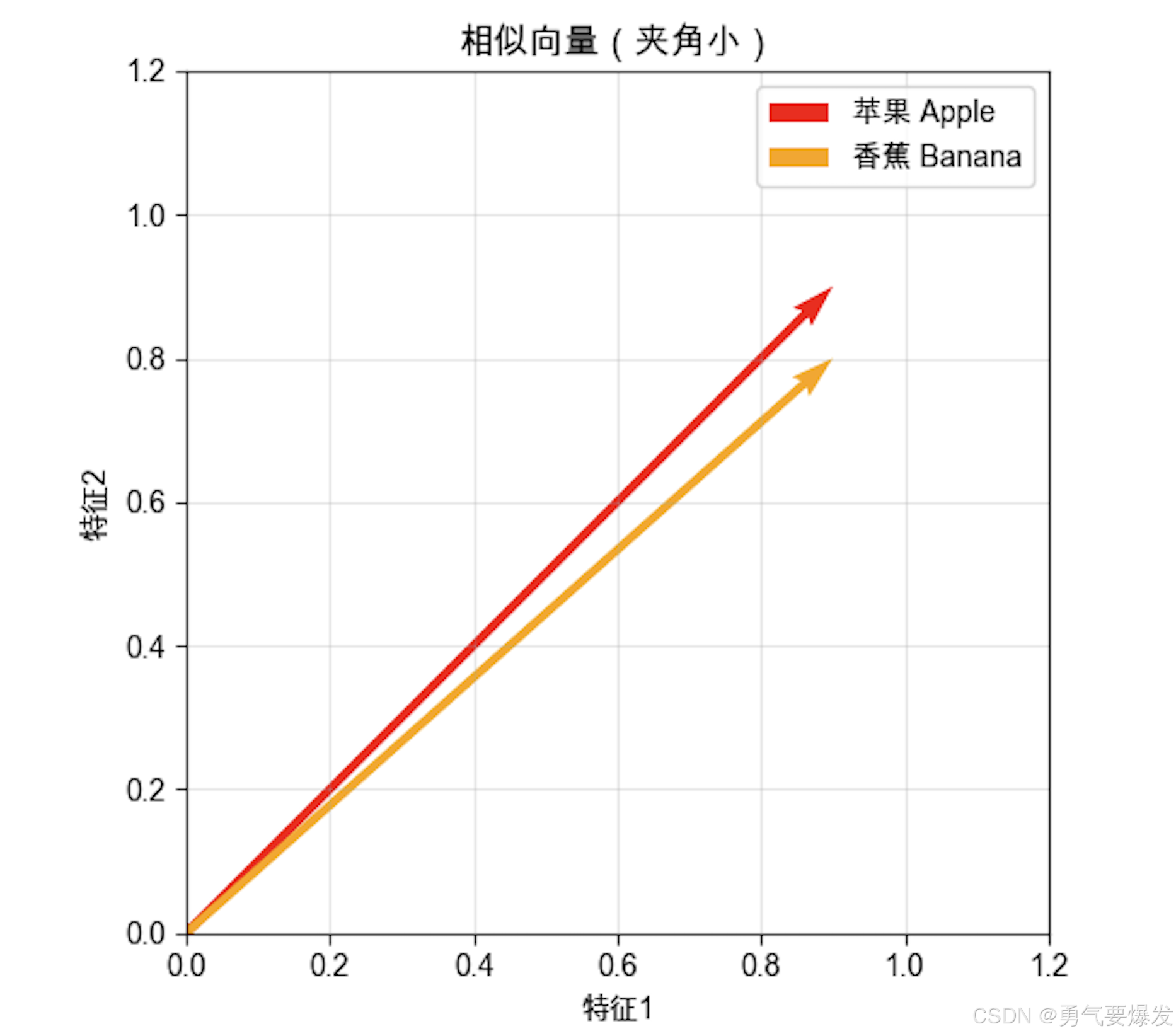
情况2:不相似的向量(苹果 vs iPhone)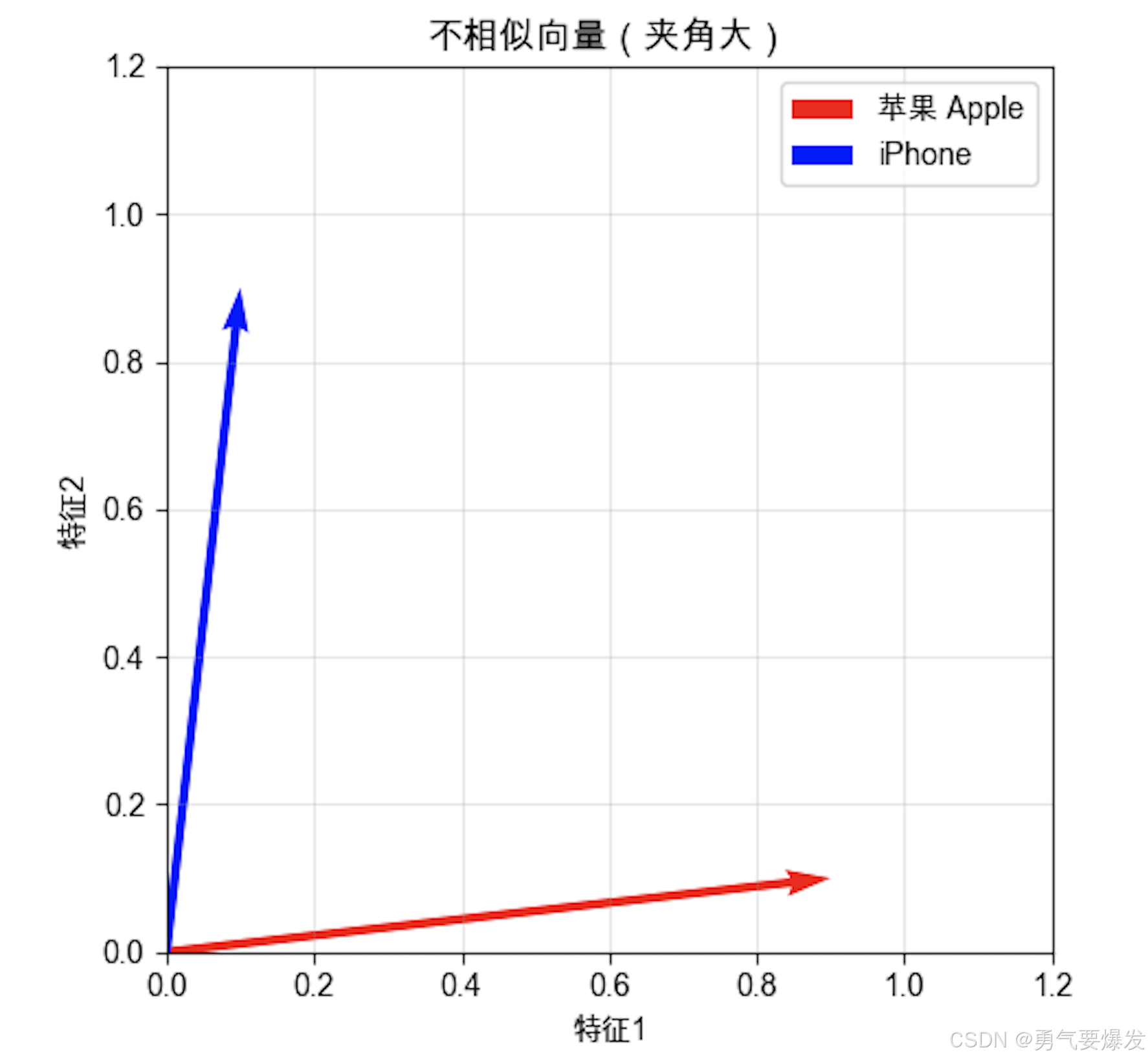
关键理解:
- 两个向量方向越接近 → 夹角越小 → 余弦值越大 → 越相似
- 两个向量方向越不同 → 夹角越大 → 余弦值越小 → 越不相似
- 当夹角为0°时,cos(0°) = 1,完全相同
- 当夹角为90°时,cos(90°) = 0,完全无关
- 当夹角为180°时,cos(180°) = -1,完全相反
AI应用场景:
- 推荐系统:计算用户和商品的相似度
- 搜索引擎:计算查询和文档的相似度
- 人脸识别:计算两张脸的相似度
- 文本分析:判断文章主题是否相似
可视化代码(可选):
如果你想自己绘制余弦相似度的可视化图,可以运行以下代码:
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'Microsoft YaHei', 'STHeiti']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 创建图形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 左图:相似的向量
apple = np.array([0.9, 0.9])
banana = np.array([0.9, 0.8])
ax1.quiver(0, 0, apple[0], apple[1], angles='xy', scale_units='xy', scale=1,
color='red', width=0.01, label='苹果 Apple')
ax1.quiver(0, 0, banana[0], banana[1], angles='xy', scale_units='xy', scale=1,
color='orange', width=0.01, label='香蕉 Banana')
ax1.set_xlim(0, 1.2)
ax1.set_ylim(0, 1.2)
ax1.set_aspect('equal')
ax1.grid(True, alpha=0.3)
ax1.legend()
ax1.set_title('相似向量(夹角小)')
ax1.set_xlabel('特征1')
ax1.set_ylabel('特征2')
# 右图:不相似的向量
apple2 = np.array([0.9, 0.1])
iphone = np.array([0.1, 0.9])
ax2.quiver(0, 0, apple2[0], apple2[1], angles='xy', scale_units='xy', scale=1,
color='red', width=0.01, label='苹果 Apple')
ax2.quiver(0, 0, iphone[0], iphone[1], angles='xy', scale_units='xy', scale=1,
color='blue', width=0.01, label='iPhone')
ax2.set_xlim(0, 1.2)
ax2.set_ylim(0, 1.2)
ax2.set_aspect('equal')
ax2.grid(True, alpha=0.3)
ax2.legend()
ax2.set_title('不相似向量(夹角大)')
ax2.set_xlabel('特征1')
ax2.set_ylabel('特征2')
plt.tight_layout()
plt.show()
📊 2. 矩阵:向量的集合
2.1 什么是矩阵?
生活类比:矩阵就像是"Excel表格"
import numpy as np
# 例子1:学生成绩表
# 数学 英语 物理
scores = np.array([
[85, 90, 78], # 学生A
[92, 88, 95], # 学生B
[78, 85, 82], # 学生C
])
print("成绩表:\n", scores)
# 例子2:图片就是矩阵!
# 一张灰度图片 = 像素值矩阵
image = np.array([
[0, 50, 100],
[150, 200, 255],
])
# 0=黑色, 255=白色
# 例子3:社交网络
# 朋友关系矩阵(1=是朋友,0=不是)
# A B C
friends = np.array([
[0, 1, 1], # A和B、C是朋友
[1, 0, 0], # B和A是朋友
[1, 0, 0], # C和A是朋友
])
2.2 矩阵的基本运算
import numpy as np
# 创建矩阵
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# 1️⃣ 矩阵加法
C = A + B
print("A + B:\n", C)
# 输出:
# A + B:
# [[ 6 8]
# [10 12]]
# 2️⃣ 矩阵转置(行列互换)
# 生活类比:把表格横着看变成竖着看
scores = np.array([
[85, 90, 78], # 学生A
[92, 88, 95], # 学生B
])
print("原始(按学生):\n", scores)
# 输出:
# 原始(按学生):
# [[85 90 78]
# [92 88 95]]
print("转置(按科目):\n", scores.T)
# 输出:
# 转置(按科目):
# [[85 92] ← 数学成绩
# [90 88] ← 英语成绩
# [78 95]] ← 物理成绩
# 3️⃣ 矩阵乘法 - 最重要!
# 生活类比:神经网络的核心运算
# 输入 × 权重 = 输出
inputs = np.array([[1, 2, 3]]) # 1个样本,3个特征
weights = np.array([
[0.1, 0.2], # 特征1的权重
[0.3, 0.4], # 特征2的权重
[0.5, 0.6], # 特征3的权重
])
output = np.dot(inputs, weights)
print("神经网络输出:\n", output)
# 输出:
# 神经网络输出:
# [[2.2 2.8]]
#
# 计算过程:
# 第1个输出 = 1×0.1 + 2×0.3 + 3×0.5 = 0.1 + 0.6 + 1.5 = 2.2
# 第2个输出 = 1×0.2 + 2×0.4 + 3×0.6 = 0.2 + 0.8 + 1.8 = 2.8
2.3 矩阵乘法的直观理解
import numpy as np
# 例子:计算多个学生的加权总分
# 成绩矩阵(3个学生 × 3门课)
scores = np.array([
[85, 90, 78], # 学生A
[92, 88, 95], # 学生B
[78, 85, 82], # 学生C
])
# 权重向量(3门课的权重)
weights = np.array([
[0.4], # 数学40%
[0.3], # 英语30%
[0.3], # 物理30%
])
# 矩阵乘法:一次性计算所有学生的总分
total_scores = np.dot(scores, weights)
print("所有学生的加权总分:\n", total_scores)
# 等价于:
# 学生A: 85*0.4 + 90*0.3 + 78*0.3 = 84.4
# 学生B: 92*0.4 + 88*0.3 + 95*0.3 = 91.7
# 学生C: 78*0.4 + 85*0.3 + 82*0.3 = 81.3
🔍 3. 特征值和特征向量
3.1 什么是特征值?
生活类比1:拍照的最佳角度
想象你在一个广场上拍照:
- 特征向量:最佳拍摄角度(方向)
- 特征值:这个角度能拍到多少内容(重要程度)
比如:
- 从正面拍(特征值=10):能拍到整个广场,信息量最大 ⭐⭐⭐
- 从侧面拍(特征值=3):只能拍到一部分,信息量较小 ⭐
- 从背面拍(特征值=0.1):几乎拍不到什么,信息量很小
特征值越大 = 这个方向越重要 = 包含的信息越多
特征值告诉我们:哪些因素对整体影响最大
import numpy as np
# 例子:社交网络中的影响力
# 朋友关系矩阵(谁和谁是朋友)
network = np.array([#A B C D
[0, 1, 1, 0], # A有2个朋友:B和C
[1, 0, 1, 1], # B有3个朋友:A、C、D
[1, 1, 0, 1], # C有3个朋友:A、B、D
[0, 1, 1, 0], # D有2个朋友:B和C
])
# 计算特征值和特征向量
# 原理:求解方程 A·v = λ·v
# 其中:A是矩阵,v是特征向量,λ是特征值
# 意思是:矩阵A作用在向量v上,只改变v的长度(λ倍),不改变方向
eigenvalues, eigenvectors = np.linalg.eig(network)
print("特征值(影响力大小):", eigenvalues)
# 实际输出:[ 2.56155281e+00 -8.96100801e-17 -1.56155281e+00 -1.00000000e+00]
# 解读:
# - 最大特征值:2.56(最重要的方向)
# - 第二个值:-8.96e-17 ≈ 0(几乎为0,可以忽略)
# - 其他值:负数(次要方向)
print("最大特征值:", eigenvalues[0])
# 实际输出:2.5615528128088294
print("对应的特征向量(每个人的影响力):", eigenvectors[:, 0])
# 实际输出:[-0.43516215 -0.55734541 -0.55734541 -0.43516215]
# 解读:
# - A的影响力:|-0.435| = 0.435
# - B的影响力:|-0.557| = 0.557 ⭐ 最大
# - C的影响力:|-0.557| = 0.557 ⭐ 最大
# - D的影响力:|-0.435| = 0.435
#
# 结论:B和C是网络中心,影响力最大(朋友最多)
# A和D在网络边缘,影响力较小(朋友较少)
# 📖 计算原理简单说明:
# 1. 特征方程:det(A - λI) = 0
# 找到所有让这个方程成立的λ值(特征值)
#
# 2. 对每个特征值λ,求解:(A - λI)·v = 0
# 找到对应的向量v(特征向量)
#
# 3. 物理意义:
# - 特征向量:矩阵变换的"不变方向"
# - 特征值:这个方向上的"缩放倍数"
# 💡 直观理解:
# 想象这是一个微信群:
# - 特征向量 = 每个人在群里的"话语权"
# - 特征值 = 整个群的"活跃度"
#
# 结果分析:
# B和C的影响力最大(|0.557| > |0.435|)
# 为什么?因为他们朋友最多(3个),处于网络的中心位置
# A和D的影响力较小,因为他们只有2个朋友,在网络边缘
# 就像群里的"意见领袖",中心位置的人说的话传播最广
# 🎯 特征值方程的直观理解:
# A·v = λ·v
#
# 用社交网络解释:
# - A(矩阵)= 朋友关系网络
# - v(特征向量)= 每个人的初始影响力
# - λ(特征值)= 影响力的放大倍数
# - A·v = 通过朋友关系传播后的影响力
#
# 方程的意思:
# "通过网络传播后的影响力" = "放大倍数" × "初始影响力"
#
# 例如:如果λ=3,意思是通过朋友圈传播,影响力会扩大3倍!
3.2 特征值的直观理解
import numpy as np
import matplotlib.pyplot as plt
# 例子:数据的主要方向
# 假设我们有学生的身高和体重数据
np.random.seed(42)
height = np.random.normal(170, 10, 100) # 身高
weight = height * 0.8 + np.random.normal(0, 5, 100) # 体重(与身高相关)
# 构建数据矩阵
data = np.vstack([height, weight])
print("数据矩阵:\n", data.T)
# 计算协方差矩阵
cov_matrix = np.cov(data)
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
print("特征值:", eigenvalues)
print("第一主方向(最重要):", eigenvectors[:, 0])
print("第二主方向(次要):", eigenvectors[:, 1])
# 输出结果
# 特征值: [134.90493238 13.64210718]
# 第一主方向(最重要): [0.75342573 0.65753302]
# 第二主方向(次要): [-0.65753302 0.75342573]
# 解释:
# 最大特征值对应的方向 = 数据变化最大的方向
# 在这个例子中,就是"身高-体重"的主要关系方向
AI应用:
- PCA降维:保留最重要的特征
- 推荐系统:找到用户的主要兴趣方向
- 图像压缩:保留图像的主要信息
🧩 4. 矩阵分解
4.1 什么是矩阵分解?
生活类比:把复杂的东西拆解成简单的部分
import numpy as np
# 例子:电影评分矩阵分解(推荐系统的核心)
# 用户对电影的评分(5个用户 × 4部电影)
ratings = np.array([
[5, 3, 0, 1], # 用户1
[4, 0, 0, 1], # 用户2
[1, 1, 0, 5], # 用户3
[1, 0, 0, 4], # 用户4
[0, 1, 5, 4], # 用户5
])
# SVD分解:ratings ≈ U × Σ × V^T
#
# 💡 SVD是什么?
# SVD = Singular Value Decomposition(奇异值分解)
# 把一个复杂的矩阵分解成三个简单矩阵的乘积
#
# 生活类比:
# 想象你要描述一张照片(矩阵)
# SVD把它分解成:
# - U:照片中有哪些"主题"(用户偏好)
# - Σ:每个主题有多重要(重要程度)
# - V^T:每个主题包含哪些"元素"(电影特征)
#
# 在推荐系统中:
# - U:每个用户对不同类型电影的喜好程度
# - Σ:每种类型的重要性(动作片、爱情片等)
# - V^T:每部电影属于哪种类型
U, sigma, VT = np.linalg.svd(ratings, full_matrices=False)
print("U矩阵(用户特征)形状:", U.shape)
# 输出:(5, 4) → 5个用户,4个隐藏特征
print("Σ矩阵(重要程度):", sigma)
# 输出:[7.35 3.52 2.11 0.89] → 第一个特征最重要
print("V^T矩阵(电影特征)形状:", VT.shape)
# 输出:(4, 4) → 4个隐藏特征,4部电影
# 重构矩阵(预测缺失的评分)
reconstructed = U @ np.diag(sigma) @ VT
print("\n预测的评分矩阵:\n", reconstructed.round(1))
SVD分解的直观理解:
原始评分矩阵(5×4):
电影1 电影2 电影3 电影4
用户1 5 3 0 1
用户2 4 0 0 1
用户3 1 1 0 5
用户4 1 0 0 4
用户5 0 1 5 4
SVD分解后:ratings = U × Σ × V^T
U矩阵(5×4):用户对"隐藏类型"的喜好
类型1 类型2 类型3 类型4
用户1 [喜欢 一般 不喜欢 一般 ]
用户2 [喜欢 不喜欢 一般 喜欢 ]
用户3 [不喜欢 一般 喜欢 喜欢 ]
...
Σ矩阵(对角矩阵):每种类型的重要性
[7.35, 3.52, 2.11, 0.89]
↑ ↑ ↑ ↑
类型1 类型2 类型3 类型4
最重要 重要 一般 不重要
V^T矩阵(4×4):电影属于哪种类型
电影1 电影2 电影3 电影4
类型1 [强 弱 中 强 ]
类型2 [弱 强 弱 中 ]
类型3 [中 中 强 弱 ]
类型4 [弱 强 中 中 ]
关键发现:
通过SVD分解,我们发现了"隐藏的类型"(潜在特征):
- 类型1可能代表"动作片"
- 类型2可能代表"爱情片"
- 类型3可能代表"科幻片"
- 类型4可能代表"喜剧片"
预测原理:
如果用户1喜欢"动作片"(类型1),而电影1是"动作片",那么用户1很可能会给电影1高分!
这样就能预测用户对没看过的电影的评分,实现个性化推荐!
4.2 SVD的实际应用
import numpy as np
# 例子:图像压缩
# 假设我们有一张灰度图片(矩阵)
image = np.random.rand(100, 100) * 255 # 100×100的图片
# SVD分解
U, sigma, VT = np.linalg.svd(image, full_matrices=False)
# 只保留前k个最重要的成分
k = 20 # 只保留20个(原来有100个)
compressed = U[:, :k] @ np.diag(sigma[:k]) @ VT[:k, :]
print(f"原始大小: {image.size} 个数字")
print(f"压缩后: {U[:, :k].size + k + VT[:k, :].size} 个数字")
print(f"压缩率: {(1 - (U[:, :k].size + k + VT[:k, :].size) / image.size) * 100:.1f}%")
# 这就是JPEG压缩的原理!
4.3 常见的矩阵分解类型
📌 初学者提示:这部分是进阶内容,可以先跳过,等学到机器学习时再回来看。
现在只需要知道"有这些工具"就够了,不需要深入理解算法原理。
AI中最常用的矩阵分解:
| 分解类型 | 用途 | 何时需要了解 |
|---|---|---|
| SVD | 推荐系统、降维 | ⭐⭐⭐ 必须掌握 |
| 特征值分解 | PCA、图算法 | ⭐⭐ 重要 |
| LU分解 | 求解方程组 | ⭐ 了解即可 |
| QR分解 | 最小二乘法 | ⭐ 了解即可 |
初学者建议:
- ✅ 重点掌握:SVD分解(上面已经讲过)
- ✅ 理解概念:特征值和特征向量(上面已经讲过)
- ⏭️ 暂时跳过:LU、QR等其他分解(用到时再学)
快速参考代码(可选):
import numpy as np
# SVD分解(最重要!)
A = np.array([[1, 2], [3, 4], [5, 6]])
U, sigma, VT = np.linalg.svd(A, full_matrices=False)
print("SVD分解 - 推荐系统、降维必备")
# 特征值分解(重要!)
A = np.array([[4, 2], [2, 3]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("\n特征值分解 - PCA降维必备")
# 其他分解(了解即可,用到时查文档)
# LU分解 - 求解线性方程组
# QR分解 - 最小二乘法
# Cholesky分解 - 优化算法
学习路径建议:
现在(基础阶段):
✅ 理解SVD的概念和应用
✅ 理解特征值的含义
学机器学习时:
📚 深入学习PCA(用到特征值分解)
📚 深入学习推荐系统(用到SVD)
学深度学习时:
📚 了解其他分解方法(按需学习)
🤖 5. 线性代数在AI中的应用
5.1 神经网络的前向传播
import numpy as np
# 简单的神经网络:输入层 → 隐藏层 → 输出层
def neural_network(X, W1, W2):
"""
X: 输入矩阵 (样本数 × 特征数)
W1: 第一层权重 (特征数 × 隐藏层神经元数)
W2: 第二层权重 (隐藏层神经元数 × 输出数)
"""
# 第一层:输入 × 权重
hidden = np.dot(X, W1)
hidden = np.maximum(0, hidden) # ReLU激活函数
# 第二层:隐藏层 × 权重
output = np.dot(hidden, W2)
return output
# 示例:预测房价
# 输入:[面积, 房间数, 楼层]
X = np.array([
[100, 3, 5], # 房子1
[80, 2, 3], # 房子2
[120, 4, 10], # 房子3
])
# 权重(随机初始化)
W1 = np.random.randn(3, 5) # 3个特征 → 5个隐藏神经元
W2 = np.random.randn(5, 1) # 5个隐藏神经元 → 1个输出(价格)
# 预测
predictions = neural_network(X, W1, W2)
print("预测的房价:\n", predictions)
5.2 图像处理
import numpy as np
# 例子:图像卷积(边缘检测)
image = np.array([
[0, 0, 0, 0, 0],
[0, 255, 255, 255, 0],
[0, 255, 255, 255, 0],
[0, 255, 255, 255, 0],
[0, 0, 0, 0, 0],
])
# 边缘检测卷积核
kernel = np.array([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1],
])
# 卷积运算(矩阵乘法的变体)
def convolve(image, kernel):
result = np.zeros((3, 3))
for i in range(3):
for j in range(3):
patch = image[i:i+3, j:j+3]
result[i, j] = np.sum(patch * kernel)
return result
edges = convolve(image, kernel)
print("边缘检测结果:\n", edges)
5.3 推荐系统
import numpy as np
# 例子:协同过滤推荐
# 用户-物品评分矩阵
ratings = np.array([
[5, 3, 0, 1], # 用户1对4个商品的评分
[4, 0, 0, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4],
])
# 计算用户之间的相似度
def user_similarity(ratings):
# 使用余弦相似度
norm = np.linalg.norm(ratings, axis=1, keepdims=True)
normalized = ratings / (norm + 1e-8)
similarity = np.dot(normalized, normalized.T)
return similarity
sim_matrix = user_similarity(ratings)
print("用户相似度矩阵:\n", sim_matrix.round(2))
# 为用户1推荐:找到相似用户喜欢但用户1没评分的商品
user_id = 0
similar_users = np.argsort(sim_matrix[user_id])[::-1][1:3] # 最相似的2个用户
print(f"\n与用户{user_id}最相似的用户: {similar_users}")
🎯 总结
核心概念
- ✅ 向量是AI的基本数据结构
- ✅ 矩阵乘法是神经网络的核心运算
- ✅ 特征值揭示数据的主要方向
- ✅ 矩阵分解用于降维和推荐
线性代数是AI的语言,掌握它就像学会了编程的基本语法! 🚀✨

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)