手把手教你从0到1搭建一个AI Agent(智能体)
手把手教你从0到1搭建一个AI Agent(智能体)
虽然大语言模型的能力很强大,但是Llm仅限于用于训练的知识,这些知识很快会过时,所以llm有以下缺点
- 幻觉
- 结果并不总是真实的
- 对时事的了解有限或一无所知
- 难以应对复杂推理和计算
例如:买高铁票
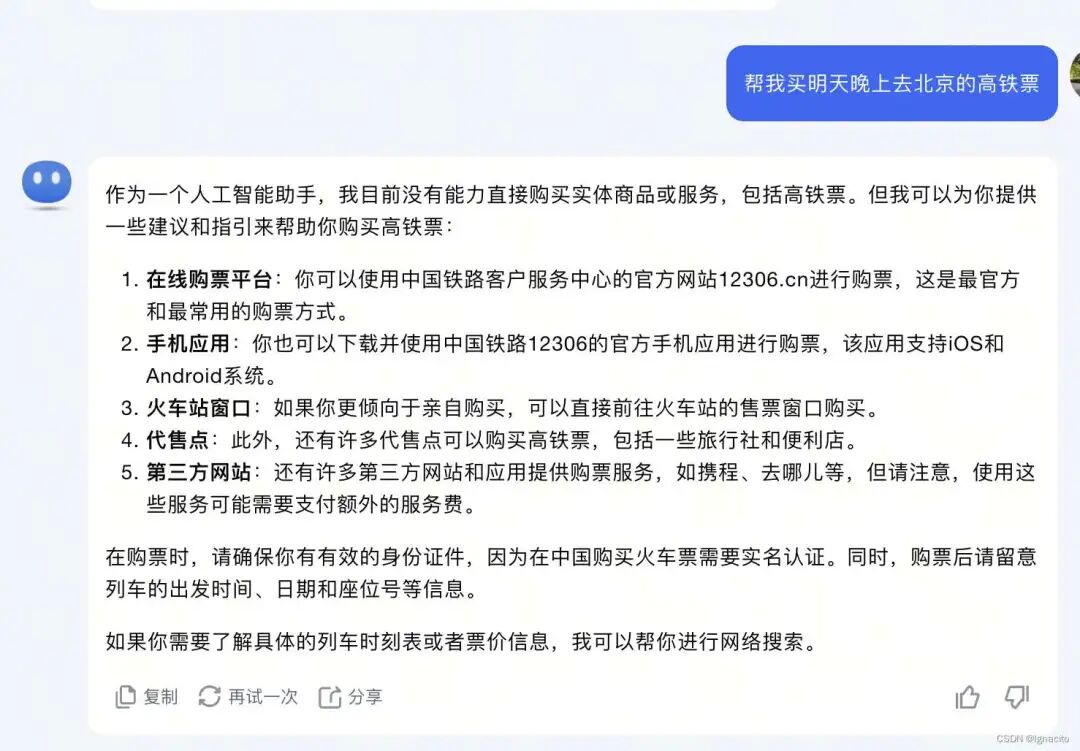 (虽然LLM完全理解了买票的行为,但是它本身并不知道“我”所处的城市,列车的时刻表,价格等等信息) 而基于大模型的Agent (LLM based Agent) 可以利用外部工具来克服以上缺点。
(虽然LLM完全理解了买票的行为,但是它本身并不知道“我”所处的城市,列车的时刻表,价格等等信息) 而基于大模型的Agent (LLM based Agent) 可以利用外部工具来克服以上缺点。
LLM Agent 的升级之路:
Standard IO(直接回答) -> COT(chain-of-thought)(思维链) -> Action-Only (Function calling) -> Reason + Action ReAct = Reasoning(推理) + Action(行动)
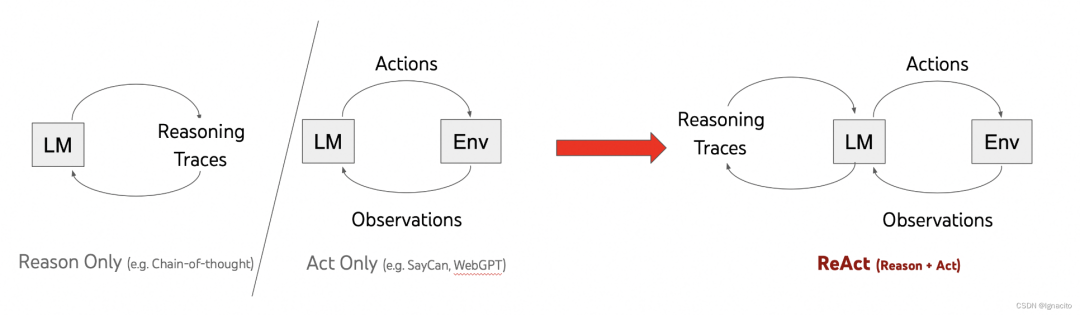
ReAct Agent 的组成部分 (通过LangChain实现)
M- odels:LLM
- Prompts:对Agent的指令、约束
- Memory : 记录Action执行状态 & 缓存已知信息
- Indexes : 用于结构化文档,以便和模型交互
- Chains :Langchain的核心(链)
- Agent
ReAct Agent 的prompt 模板
from langchain_core.prompts import PromptTemplatetemplate = '''Answer the following questions as best you can. You have access to the following tools:{tools}Use the following format:Question: the input question you must answerThought: you should always think about what to doAction: the action to take, should be one of [{tool_names}]Action Input: the input to the actionObservation: the result of the action... (this Thought/Action/Action Input/Observation can repeat N times)Thought: I now know the final answerFinal Answer: the final answer to the original input questionBegin!Question: {input}Thought:{agent_scratchpad}'''prompt = PromptTemplate.from_template(template)
代码
手写一个能帮忙买火车票的智能Agent
注:火车票相关API均为mock
安装 & import依赖
pip install langchainpip install uuidpip install pydanticimport jsonimport sysfrom typing import List, Optional, Dict, Any, Tuple, Unionfrom uuid import UUIDfrom langchain.memory import ConversationTokenBufferMemoryfrom langchain.tools.render import render_text_descriptionfrom langchain_core.callbacks import BaseCallbackHandlerfrom langchain_core.language_models import BaseChatModelfrom langchain_core.output_parsers import PydanticOutputParser, StrOutputParserfrom langchain_core.outputs import GenerationChunk, ChatGenerationChunk, LLMResultfrom langchain_core.prompts import PromptTemplatefrom langchain_core.tools import StructuredToolfrom langchain_openai import ChatOpenAIfrom pydantic import BaseModel, Field, ValidationError
定义工具(Tools)
细节可参考LangChain定义Tool
from typing import Listfrom langchain_core.tools import StructuredTooldef search_train_ticket( origin: str, destination: str, date: str, departure_time_start: str, departure_time_end: str) -> List[dict[str, str]]: """按指定条件查询火车票""" # mock train list return [ { "train_number": "G1234", "origin": "北京", "destination": "上海", "departure_time": "2024-06-01 8:00", "arrival_time": "2024-06-01 12:00", "price": "100.00", "seat_type": "商务座", }, { "train_number": "G5678", "origin": "北京", "destination": "上海", "departure_time": "2024-06-01 18:30", "arrival_time": "2024-06-01 22:30", "price": "100.00", "seat_type": "商务座", }, { "train_number": "G9012", "origin": "北京", "destination": "上海", "departure_time": "2024-06-01 19:00", "arrival_time": "2024-06-01 23:00", "price": "100.00", "seat_type": "商务座", } ]def purchase_train_ticket( train_number: str,) -> dict: """购买火车票""" return { "result": "success", "message": "购买成功", "data": { "train_number": "G1234", "seat_type": "商务座", "seat_number": "7-17A" } }search_train_ticket_tool = StructuredTool.from_function( func=search_train_ticket, name="查询火车票", description="查询指定日期可用的火车票。",)purchase_train_ticket_tool = StructuredTool.from_function( func=purchase_train_ticket, name="购买火车票", description="购买火车票。会返回购买结果(result), 和座位号(seat_number)",)finish_placeholder = StructuredTool.from_function( func=lambda: None, name="FINISH", description="用于表示任务完成的占位符工具")tools = [search_train_ticket_tool, purchase_train_ticket_tool, finish_placeholder]
Prompt
主要任务Prompt
prompt_text = """你是强大的AI火车票助手,可以使用工具与指令查询并购买火车票你的任务是:{task_description}你可以使用以下工具或指令,它们又称为动作或actions:{tools}当前的任务执行记录:{memory}按照以下格式输出:任务:你收到的需要执行的任务思考: 观察你的任务和执行记录,并思考你下一步应该采取的行动然后,根据以下格式说明,输出你选择执行的动作/工具:{format_instructions}"""
最终回复Prompt
final_prompt = """你的任务是:{task_description}以下是你的思考过程和使用工具与外部资源交互的结果。{memory}你已经完成任务。现在请根据上述结果简要总结出你的最终答案。直接给出答案。不用再解释或分析你的思考过程。"""
一些方便编程的工具类
class Action(BaseModel): """结构化定义工具的属性""" name: str = Field(description="工具或指令名称") args: Optional[Dict[str, Any]] = Field(description="工具或指令参数,由参数名称和参数值组成")class MyPrintHandler(BaseCallbackHandler): """自定义LLM CallbackHandler,用于打印大模型返回的思考过程""" def __init__(self): BaseCallbackHandler.__init__(self) def on_llm_new_token( self, token: str, *, chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any, ) -> Any: end = "" content = token + end sys.stdout.write(content) sys.stdout.flush() return token def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any: end = "" content = "\n" + end sys.stdout.write(content) sys.stdout.flush() return response
定义Agent
class MyAgent: def __init__( self, llm: BaseChatModel = ChatOpenAI( model="gpt-4-turbo", # agent用GPT4效果好一些,推理能力较强 temperature=0, model_kwargs={ "seed": 42 }, ), tools=None, prompt: str = "", final_prompt: str = "", max_thought_steps: Optional[int] = 10, ): if tools is None: tools = [] self.llm = llm self.tools = tools self.final_prompt = PromptTemplate.from_template(final_prompt) self.max_thought_steps = max_thought_steps # 最多思考步数,避免死循环 self.output_parser = PydanticOutputParser(pydantic_object=Action) self.prompt = self.__init_prompt(prompt) self.llm_chain = self.prompt | self.llm | StrOutputParser() # 主流程的LCEL self.verbose_printer = MyPrintHandler() def __init_prompt(self, prompt): return PromptTemplate.from_template(prompt).partial( tools=render_text_description(self.tools), format_instructions=self.__chinese_friendly( self.output_parser.get_format_instructions(), ) ) def run(self, task_description):"""Agent主流程""" # 思考步数 thought_step_count = 0 # 初始化记忆 agent_memory = ConversationTokenBufferMemory( llm=self.llm, max_token_limit=4000, ) agent_memory.save_context( {"input": "\ninit"}, {"output": "\n开始"} ) # 开始逐步思考 while thought_step_count < self.max_thought_steps: print(f">>>>Round: {thought_step_count}<<<<") action, response = self.__step( task_description=task_description, memory=agent_memory ) # 如果是结束指令,执行最后一步 if action.name == "FINISH": break # 执行动作 observation = self.__exec_action(action) print(f"----\nObservation:\n{observation}") # 更新记忆 self.__update_memory(agent_memory, response, observation) thought_step_count += 1 if thought_step_count >= self.max_thought_steps: # 如果思考步数达到上限,返回错误信息 reply = "抱歉,我没能完成您的任务。" else: # 否则,执行最后一步 final_chain = self.final_prompt | self.llm | StrOutputParser() reply = final_chain.invoke({ "task_description": task_description, "memory": agent_memory }) return reply def __step(self, task_description, memory) -> Tuple[Action, str]: """执行一步思考""" response = "" for s in self.llm_chain.stream({ "task_description": task_description, "memory": memory }, config={ "callbacks": [ self.verbose_printer ] }): response += s action = self.output_parser.parse(response) return action, response def __exec_action(self, action: Action) -> str: observation = "没有找到工具" for tool in self.tools: if tool.name == action.name: try: # 执行工具 observation = tool.run(action.args) except ValidationError as e: # 工具的入参异常 observation = ( f"Validation Error in args: {str(e)}, args: {action.args}" ) except Exception as e: # 工具执行异常 observation = f"Error: {str(e)}, {type(e).__name__}, args: {action.args}" return observation @staticmethod def __update_memory(agent_memory, response, observation): agent_memory.save_context( {"input": response}, {"output": "\n返回结果:\n" + str(observation)} ) @staticmethod def __chinese_friendly(string) -> str: lines = string.split('\n') for i, line in enumerate(lines): if line.startswith('{') and line.endswith('}'): try: lines[i] = json.dumps(json.loads(line), ensure_ascii=False) except: pass return'\n'.join(lines)
测试
if __name__ == "__main__": my_agent = MyAgent( tools=tools, prompt=prompt_text, final_prompt=final_prompt, ) task = "帮我买24年6月1日早上去上海的火车票" reply = my_agent.run(task) print(reply)
结果
第一轮思考
Agent根据要求,选择了需要使用的Tool,组装了请求参数并完成了调用。 (还可以多定义一些Tools,比如获取当前位置的,获取今天日期的工具等等,这样这里的查询火车票的参数可以更智能)
>>>>Round: 0<<<<任务:帮我买24年6月1日早上去上海的火车票思考: 根据任务需求,首先需要查询2024年6月1日早上从当前位置到上海的火车票。这需要使用“查询火车票”工具,指定出发地、目的地、日期以及早上的时间范围。动作/工具:{"name": "查询火车票","args": { "origin": "当前位置", "destination": "上海", "date": "2024-06-01", "departure_time_start": "00:00", "departure_time_end": "12:00" }}----Observation:[{'train_number': 'G1234', 'origin': '北京', 'destination': '上海', 'departure_time': '2024-06-01 8:00', 'arrival_time': '2024-06-01 12:00', 'price': '100.00', 'seat_type': '商务座'}, {'train_number': 'G5678', 'origin': '北京', 'destination': '上海', 'departure_time': '2024-06-01 18:30', 'arrival_time': '2024-06-01 22:30', 'price': '100.00', 'seat_type': '商务座'}, {'train_number': 'G9012', 'origin': '北京', 'destination': '上海', 'departure_time': '2024-06-01 19:00', 'arrival_time': '2024-06-01 23:00', 'price': '100.00', 'seat_type': '商务座'}]
第二轮思考
根据查询出的车票信息去调用购票的Tool
>>>>Round: 1<<<<任务:帮我买24年6月1日早上去上海的火车票思考: 根据查询结果,有三个车次可供选择,但只有车次G1234符合早上出发的要求,因此应选择购买这个车次的票。动作/工具:{"name": "购买火车票","args": { "train_number": "G1234" }}----Observation:{'result': 'success', 'message': '购买成功', 'data': {'train_number': 'G1234', 'seat_type': '商务座', 'seat_number': '7-17A'}}
第三轮思考
LLM识别到任务已完成,输出了结果
>>>>Round: 2<<<<任务:帮我买24年6月1日早上去上海的火车票思考: 根据执行记录,已经成功购买了2024年6月1日早上从北京到上海的火车票(车次G1234)。因此,接下来的任务是完成这个购票任务。动作/工具:{ "name": "FINISH"}购买成功。您已成功购买2024年6月1日早上从北京出发前往上海的火车票,车次为G1234,座位类型为商务座,座位号为7-17A。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献512条内容
已为社区贡献512条内容

所有评论(0)