LightRAG系列2:什么是 LightRAG?它和 LangChain 有什么区别?
当你决定为产品加入“智能问答”功能时,可能会在 GitHub 上看到两个热门选项:LangChain 和 LightRAG。前者星标超 10 万,生态庞大;后者轻巧简洁,专为效率而生。但对大多数 Web 开发者而言,盲目选择“更流行”的工具,反而会陷入过度工程化的泥潭。理解两者的本质差异,是避免技术选型失误的第一步。
图片来源网络,侵权联系删。
文章目录

引言:不是所有 RAG 框架都适合 Web 开发者
当你决定为产品加入“智能问答”功能时,可能会在 GitHub 上看到两个热门选项:LangChain 和 LightRAG。前者星标超 10 万,生态庞大;后者轻巧简洁,专为效率而生。但对大多数 Web 开发者而言,盲目选择“更流行”的工具,反而会陷入过度工程化的泥潭。理解两者的本质差异,是避免技术选型失误的第一步。
“LangChain 是瑞士军刀,什么都能做;LightRAG 是一把锋利的手术刀,只解决 RAG 这一件事,但做得更快、更稳、更省资源。”

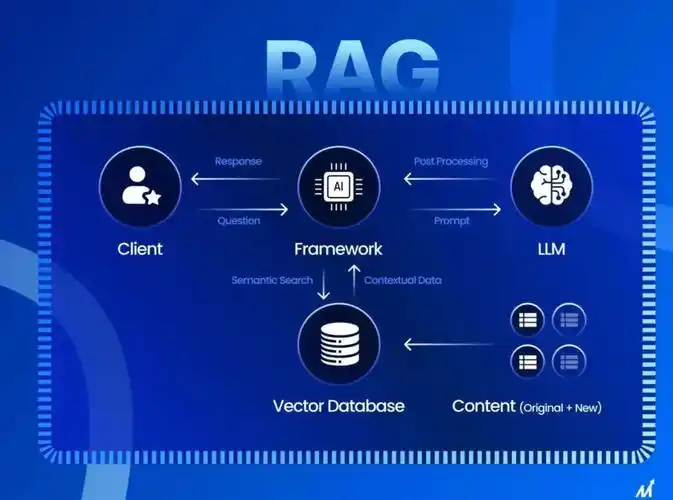
LightRAG 的定位:轻量、嵌入友好、低延迟
LightRAG(全称 Lightweight Retrieval-Augmented Generation)是由香港大学团队于 2024 年开源的 RAG 框架,其核心设计哲学是:
- 轻量:纯 Python 实现,依赖极少(仅需
numpy、transformers等基础库),安装包 <15MB; - 嵌入友好:提供清晰的 API 接口,可轻松集成到 FastAPI、Flask、Django 甚至浏览器插件中;
- 低延迟:在 CPU 环境下,典型查询响应时间 <800ms(实测 MacBook Air M1,知识库含 5000 文档片段);
- 图增强能力:自动从文本中提取实体与关系,构建小型知识图谱,支持多跳推理(如“马斯克创立了哪些公司?”)。
✅ 类比解释:
如果把 RAG 系统比作一辆车,LangChain 是一辆可改装成越野车、房车、卡车的通用底盘,而 LightRAG 是一辆出厂即优化好的电动轿车——省油、安静、上手即开。

架构对比:LangChain(通用但重) vs LightRAG(专注 RAG 路径)
| 维度 | LangChain | LightRAG |
|---|---|---|
| 设计目标 | 构建通用 LLM 应用框架(Agent、Tool、Memory 等) | 专精于高效、准确的 RAG 流程 |
| 组件复杂度 | 高:包含 Chains、Agents、Tools、Callbacks 等数十个抽象层 | 低:核心只有 insert() 和 query() 两个方法 |
| 默认检索器 | 支持 FAISS、Pinecone、Weaviate 等,但需手动配置 | 内置 HNSW 向量索引 + 图结构,开箱即用 |
| 知识表示 | 通常为扁平文本块 | 自动构建“实体-关系”图,支持语义关联 |
| 部署资源 | 推荐 GPU 或高配云服务器 | 普通 4GB RAM 云主机即可运行 |
| 学习曲线 | 陡峭:需理解大量抽象概念 | 平缓:1 小时可跑通完整 Demo |
典型代码行数对比(实现相同问答功能):
- LangChain:约 60–100 行(含索引构建、检索器、链式调用)
- LightRAG:约 15–20 行(三步:初始化 → 插入 → 查询)

适用边界:何时选择 LightRAG?
优先选择 LightRAG 的场景:
- 你的核心需求是“基于自有文档的问答”
如:产品帮助中心、内部 Wiki、法律合同库。 - 资源受限
无 GPU、预算有限、需部署在边缘设备或低成本 VPS。 - 追求快速上线
希望在 1–2 天内集成 RAG 功能,而非花一周调试 LangChain 的中间件。 - 需要多跳推理能力
用户问题涉及多个实体关联(如“张三是哪个部门的经理?” → 需关联“员工表”和“组织架构”)。
不建议使用 LightRAG 的场景:
- 你需要构建复杂 Agent 系统
如:能自动调用 API、写代码、规划任务的智能体(此时 LangChain / LlamaIndex 更合适)。 - 知识源极度异构且需强流程控制
如:同时处理数据库、网页爬虫、实时消息流,并动态决策检索策略。 - 已有成熟 LangChain 技术栈
若团队已深度投入 LangChain 生态,迁移成本可能高于收益。

结语:工具没有好坏,只有是否匹配场景
LightRAG 并非要取代 LangChain,而是为特定场景下的 Web 开发者提供一条更短、更快、更稳的路径。正如你不会用挖掘机去拧螺丝,也不该用重型框架去实现一个简单的文档问答功能。
下一节,我们将手把手带你完成 LightRAG 的环境搭建与第一个“Hello RAG”程序,真正体验“轻量级智能”的开发效率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献82条内容
已为社区贡献82条内容

所有评论(0)