100 万亿 Token 的启示:当 AI 开始“慢思考”,我们该如何选择模型?
OpenRouter 作为全球最大的 LLM 聚合平台之一,发布了名为《State of AI: An Empirical 100 Trillion Token Study》的重磅报告。通过分析其平台上发生的超过 100 万亿 token 的真实交互,这份报告揭示了开发者行为、模型偏好以及 AI 应用形态的剧烈变化
发布时间: 2025年12月
数据来源: OpenRouter (基于 100 万亿 tokens 的实证研究)
引言:当 AI 开始“慢思考”
过去的一年(2024-2025)是 AI 领域的分水岭。如果说 2023 年是“聊天机器人”的元年,那么 2025 年则是**代理(Agents)与推理(Reasoning)**的时代。
OpenRouter 作为全球最大的 LLM 聚合平台之一,发布了名为《State of AI: An Empirical 100 Trillion Token Study》的重磅报告。通过分析其平台上发生的超过 100 万亿 token 的真实交互,这份报告揭示了开发者行为、模型偏好以及 AI 应用形态的剧烈变化。
以下是报告的核心洞察整理。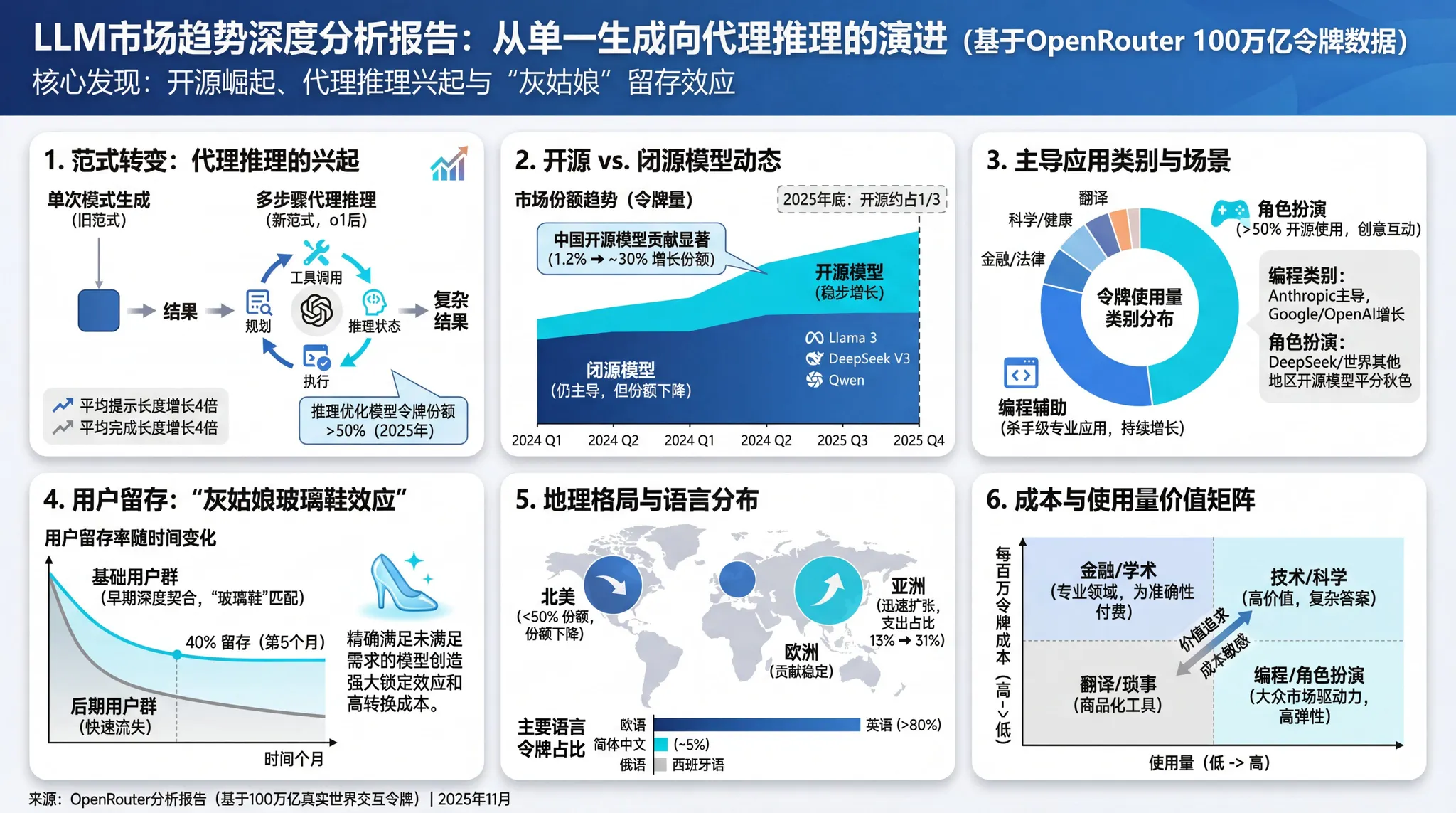
1. 核心趋势:从“模式匹配”到“深度推理”
报告指出的最大变化是模型能力的质变。
- 转折点: 2024 年 12 月 OpenAI 发布 o1 (Strawberry) 模型是一个关键节点。在此之前,模型主要擅长单次传递的模式预测(流畅但缺乏深度);在此之后,模型开始具备**多步推理(Multi-step deliberation)**能力。
- 表现形式: 现在的模型不仅仅是回答问题,而是会先“拆解问题”、“搜索信息”、“评估路径”。
- 数据佐证:
- 输出变长: 平均 Completion(补全/输出)的 Token 长度增加了近 3倍。这并非用户变得啰嗦,而是模型在输出最终答案前,生成了大量的“思维链(Chain of Thought)”Token。
- 输入变长: 平均 Prompt(提示词)长度增长了近 4倍,反映出用户不再只问简单问题,而是投喂大量的上下文(Context)让 AI 处理复杂任务。
2. 市场格局:开源模型在“走量”上通过碾压
一个令人惊讶的数据是 OpenRouter 平台上的 Token 消耗量排名。在“按需付费”的开发者市场中,**开源/开放权重模型(Open Weights)**正在通过极致的性价比占据主导地位。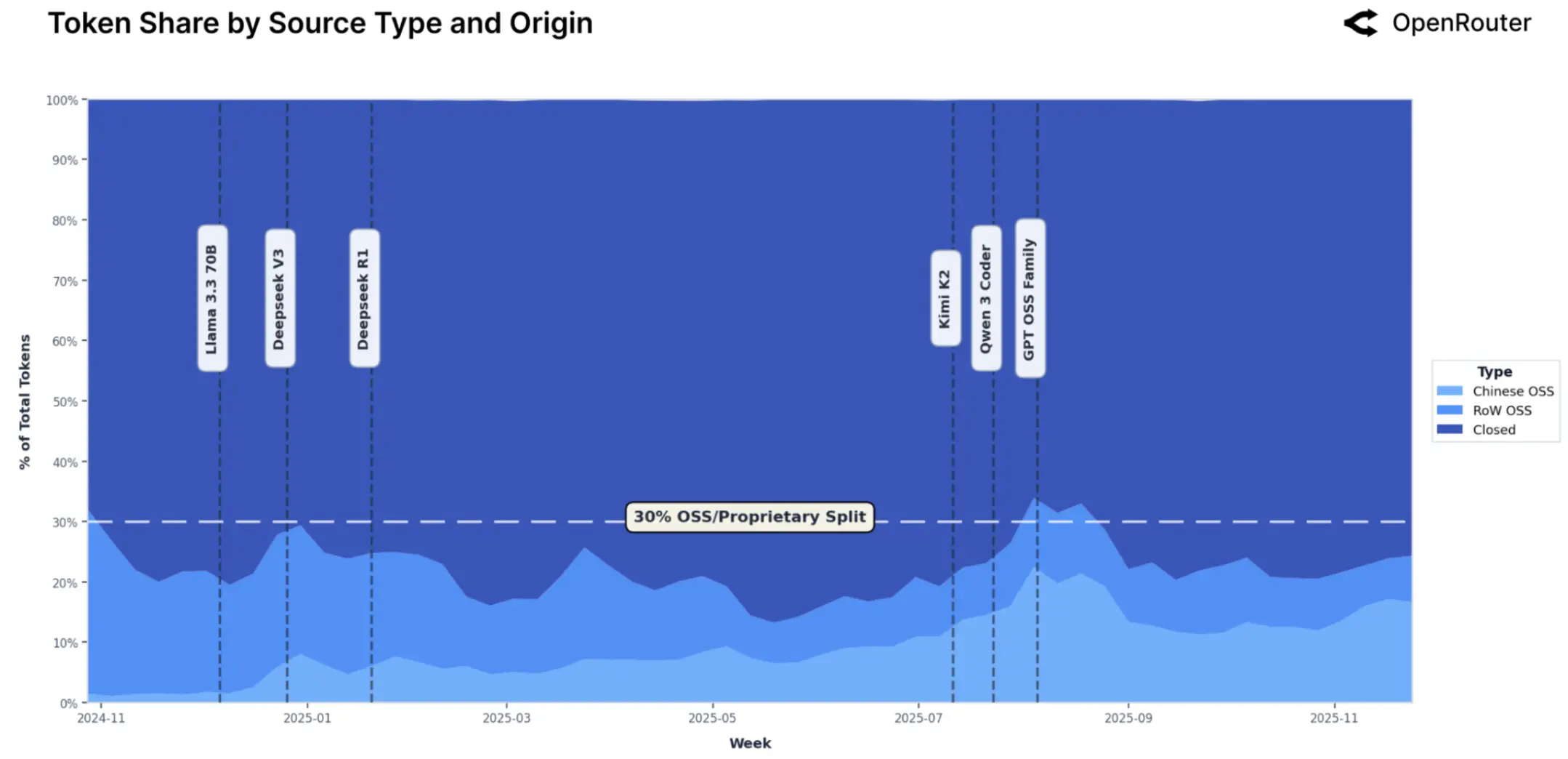
Token 总消耗量排名(按模型厂商):
- 🥇 DeepSeek (深度求索): 14.37 Trillion Tokens —— 凭借 DeepSeek V3/R1 系列的高智商与低价格,成为开发者首选。
- 🥈 Qwen (通义千问): 5.59 Trillion Tokens —— Qwen 2.5/Coder 系列在编程领域表现极其强势。
- 🥉 Meta (LLaMA): 3.96 Trillion Tokens —— LLaMA 3.1/3.2 依然是微调和私有部署的基石。
- Mistral AI: 2.92 Trillion Tokens
- OpenAI: 1.65 Trillion Tokens
注:此数据反映的是 OpenRouter 这一聚合平台的开发者偏好,他们更倾向于灵活、低成本的 API,而非 OpenAI 的原生 ChatGPT 用户。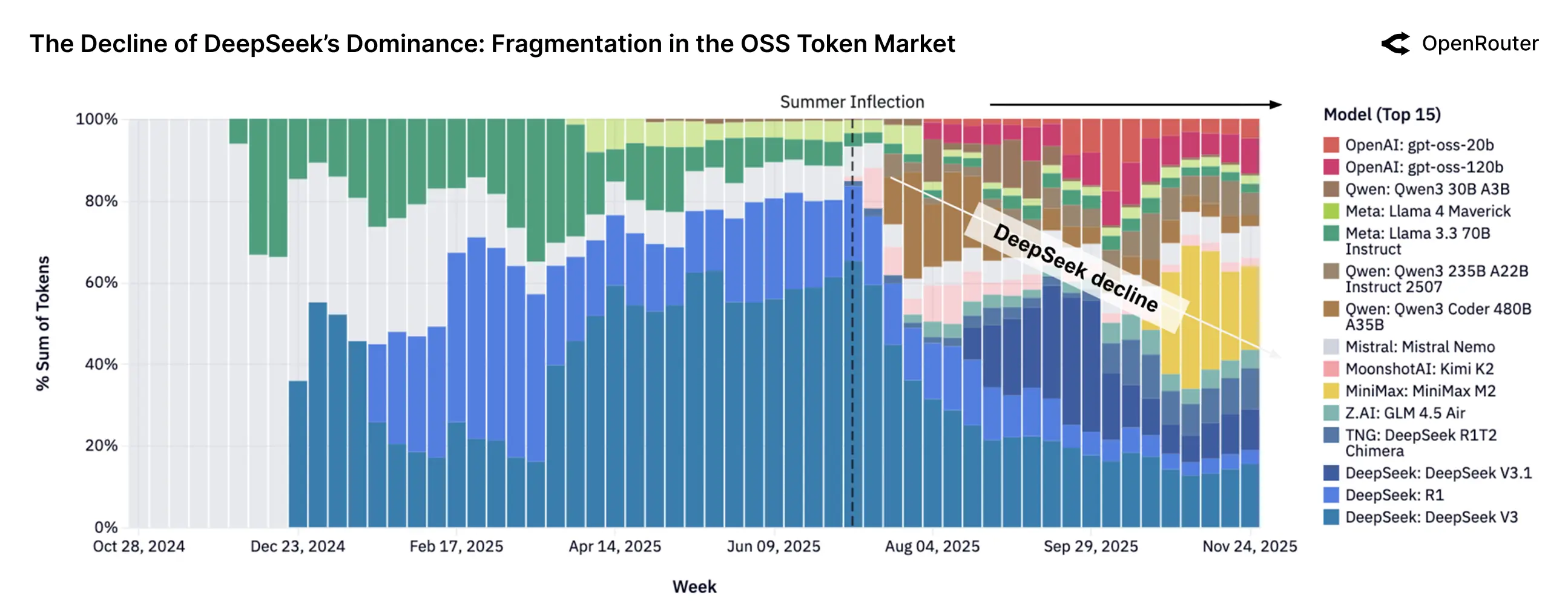
每周领先开源模型的相对代币份额(堆叠面积图)。每个彩色条带代表一个模型对开源软件代币总量的贡献。随着时间的推移,颜色范围逐渐扩大,表明近几个月来市场竞争更加激烈,没有哪个模型占据绝对主导地位。
3. 开发者行为:编程(Coding)是第一生产力
在所有应用类别中,编程辅助(Coding Assistance) 是推动 Token 增长的最大动力。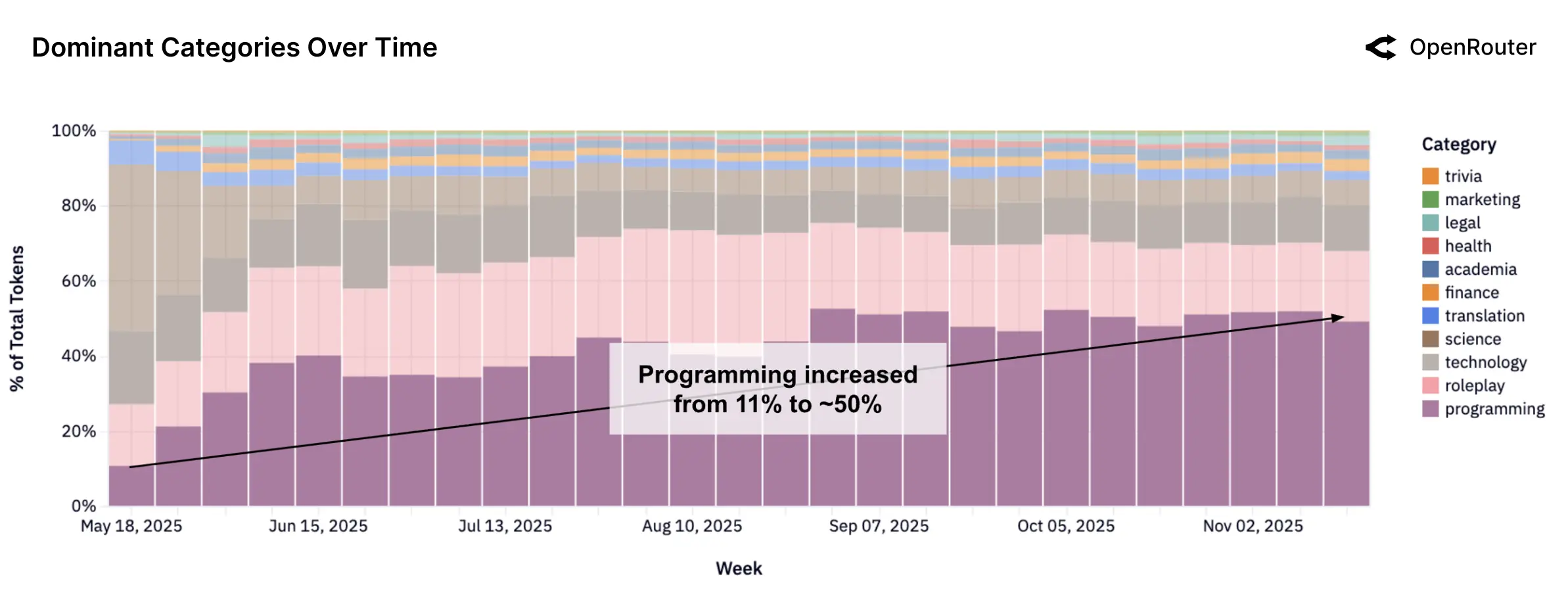
- 热门模型: x-ai 的 Grok Code Fast 和 Anthropic 的 Claude Sonnet 4.5 是该领域的双子星。Grok 凭借速度和上下文窗口在自动补全场景占优,而 Claude Sonnet 4.5 则在复杂的架构设计和 Debug 上无可替代。
- 上下文依赖: 编程任务通常需要通过 RAG(检索增强生成)或长窗口(Long Context)加载整个代码库,这直接导致了 Input Token 的激增。
4. 代理式推理(Agentic Inference)的崛起
报告定义了一种新兴的交互模式:Agentic Inference(代理式推理)。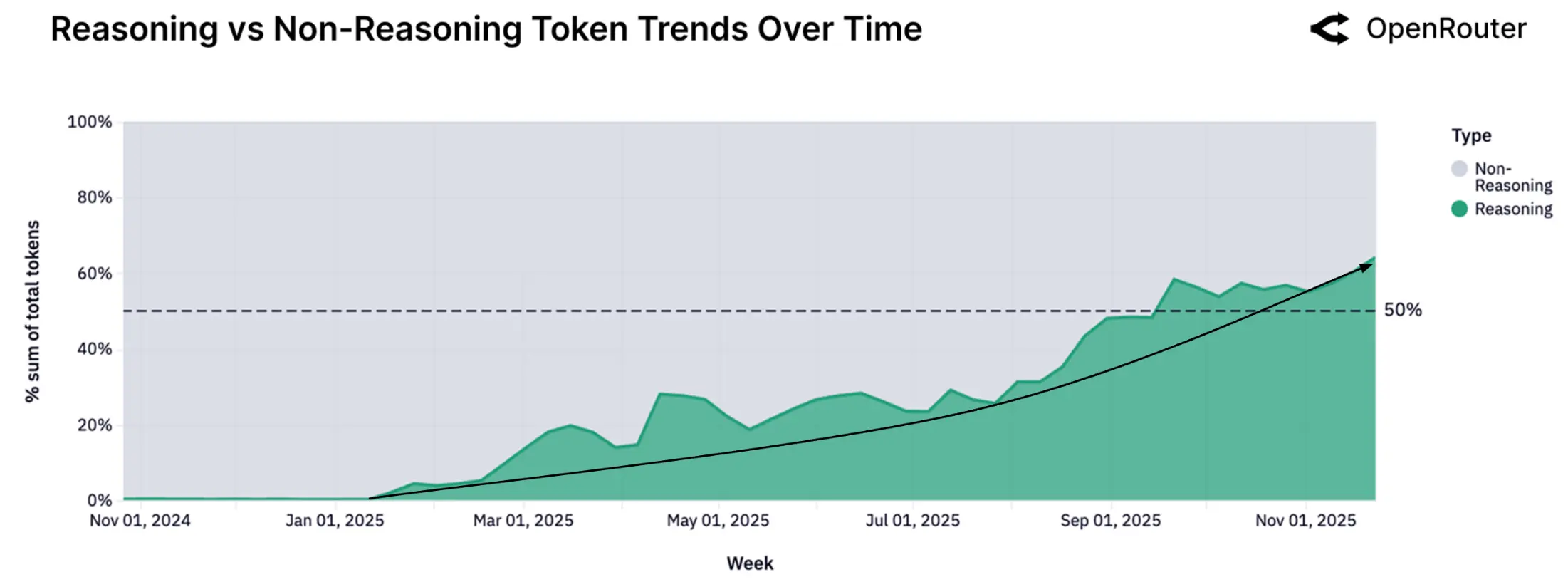
自 2025 年初以来,所有通过推理优化模型路由的代币份额稳步上升。该指标反映的是由推理模型处理的代币占所有代币的比例,而不是模型输出中“推理型代币”的比例。
- 定义: 不再是“人问-AI答”的回合制,而是“人下指令-AI自主循环”。AI 会自主调用工具、运行代码、查看报错、修正代码,直到任务完成。
- 影响: 这种模式对模型的稳定性和指令遵循能力要求极高。
- 赢家: 在这个领域,Google Gemini 2.5 Flash 和 Claude Sonnet 4.5 表现突出,因为它们在处理大量工具调用(Tool Use)时更加精准且便宜。
5. 模型排行榜一览 (Snapshot)
OpenRouter 根据真实调用量和评分整理出的当前“T0 梯队”模型:
| 类别 | 推荐模型 | 优势关键词 |
|---|---|---|
| 极致推理 (SOTA) | Claude Sonnet 4.5 / Opus 4.5 | 复杂逻辑、代码架构、长文理解 |
| 编程神器 | Grok Code Fast / Claude Sonnet 4.5 | 响应速度快、代码准确率高 |
| 性价比之王 | DeepSeek V3 / R1 | 极其便宜、推理能力接近 SOTA |
| 长窗口/多模态 | Gemini 2.5 Flash | 1M+ 上下文、原生视频理解、极快 |
总结:AI 的“实用主义”时代
OpenRouter 的这份报告揭示了一个清晰的趋势:开发者不再盲目迷信“最强模型”,而是开始通过路由(Routing) 技术,根据任务难度动态选择模型。
- 写复杂的 Python 后端架构?用 Claude Sonnet 4.5。
- 批量处理百万级文档总结?用 Gemini 2.5 Flash。
- 日常的翻译和简单对话?用 DeepSeek V3 或 Llama 3.1。
这就是 2025 年的 AI 现状:模型不仅更聪明了,而且由于激烈的竞争,它们变得前所未有的便宜和好用。
本研究从实证角度展现了大型语言模型如何融入全球计算基础设施。它们如今已成为工作流程、应用程序和智能体系统不可或缺的一部分,改变了信息的生成、传递和消费方式。
过去一年,该领域对推理的理解发生了根本性的转变。O1级模型的出现使长时间的深思熟虑和工具的使用成为常态,评估方式也从单次基准测试转向基于过程的指标、延迟成本权衡以及在协同任务下的成功率。推理已成为衡量模型规划和验证效率的指标,旨在提供更可靠的结果。
数据显示,LLM生态系统在结构上呈现多元化特征。没有单一模型或供应商占据主导地位;相反,用户会根据具体情况,从功能、延迟、价格和信任度等多个维度选择系统。这种异质性并非暂时现象,而是市场的根本属性。它促进了快速迭代,并降低了系统对任何单一模型或技术栈的依赖。
推理本身也在发生变化。多步骤交互和工具链接交互的兴起标志着从静态补全向动态编排的转变。用户将模型、API 和工具串联起来以实现复杂的目标,从而产生了所谓的智能体推理。有很多理由相信,智能体推理将会超越人类推理,即便它现在还没有超越。
从地域上看,机器学习的格局正变得更加分散。亚洲的使用份额持续增长,尤其是中国,已成为模型开发和出口的双重中心,Moonshot AI、DeepSeek 和 Qwen 等公司的崛起便是最好的例证。非西方开放权重模型的成功表明,机器学习模型(LLM)确实是一种全球性的计算资源。
实际上,o1并没有终结竞争,恰恰相反,它拓展了设计空间。该领域正从单一的孤注一掷转向系统思维,从依赖直觉转向依赖工具,从关注排行榜上的差距转向基于经验的使用分析。如果说过去一年证明了智能推理在规模化应用中的可行性,那么未来一年将着重于卓越运营:衡量实际任务完成情况,降低分布变化带来的偏差,并使模型行为与生产规模工作负载的实际需求保持一致。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)