Activation-Space Personality Steering: Hybrid Layer Selection for Stable Trait Control in LLMs
名词解释
1、激活空间(Activation Space):在神经网络的特定层中,所有神经元的激活值(outputs)所构成的多维向量空间。
2、激活值(Activation Value):在LLM的神经网络中,每一层(如全连接层、自注意力层)的神经元会对输入数据进行计算,并输出一个数值结果,这个结果被称为激活值。它是模型对输入数据的中间表示,反映了神经元对输入特征的响应程度。
3、激活引导(Activation Steering)通过直接修改模型内部的激活值来控制其行为,能够在推理阶段动态调整模型行为,无需重新训练模型。改变模型中间值,改变输出。
4、微调(Fine-tuning):使用新数据更新模型的权重参数来改变输出。改变模型的权重参数,永久性的改变模型。
5、因果语言模型(Causal LM):一种自回归模型,生成文本时只能基于前面的词预测下一个词,无法利用未来信息,如GPT系列;
6、Logits:模型预测过程中最后一层输出的原始值。它们通常是一个未归一化的实数向量,每个值对应一个类别。取值范围:任意实数,无概率意义,仅表示模型对某类别的“倾向性”。
7、Softmax:是一个将原始分数(logits)向量转换为概率分布的函数,其中每个元素代表输入样本属于对应类别的概率。通过指数化和归一化两个步骤实现。取值范围:[0, 1],满足概率分布的性质,所有值之和为 1,每个值表示模型预测该类别的概率。
8、标准化(Standardization):通过将数据转换为均值为0、标准差为1的分布,它不改变数据的分布形状,只改变其中心位置和缩放程度。标准化可以确保所有特征在同一尺度上进行计算,较好的保留了数据之间的分布,即保留了样本之间的距离,避免某些特征的值过大或过小对算法性能的影响。
9、归一化(Normalization):将数据按比例缩放到一个特定的区间,通常是[0, 1]或[-1, 1]。它改变了数据的原始范围。常见的归一化方法是最小-最大缩放(Min-Max Scaling),通过调整数据的最小值和最大值,将数据的范围缩放到统一的区间,不会改变数据的分布形态,但可以减少某些特征的绝对数值差异,使得它们在一个固定范围内有相同的尺度。
10、KL散度( Kullback-Leibler):也被称为相对熵、信息散度。它的核心思想是:衡量一个概率分布 P 与另一个参考概率分布 Q 之间的差异程度。KL散度是非负的,当且仅P(x)=Q(x)时,KL散度为0。
13、前向钩子(forward hook)是PyTorch提供的一种功能,允许用户在神经网络模块的前向传播过程中注册自定义操作。当输入数据通过该模块时,注册的钩子函数会被调用,从而可以对输入和输出进行监控或修改。
一、动机
大语言模型(Large Language Models,LLMs)正在越来越多地塑造人机交互,其在生成文本时,并没有被明确指定人格特质,但输出内容会不自觉地体现出一些默认的、模糊的人格倾向—— 比如基础模型可能默认更 “外向”(爱用互动性语言)、更 “宜人”(偏向包容的表述),这些倾向是模型训练数据和预训练逻辑带来的 “隐性特征”。
现有的一些控制人格特性的方法,比如提示词工程(prompt),描述一段人格,如“你是一个很外向的朋友”,输出变化明显,但是这个方法只是“外部人格写入”,缺乏对模型内部机制的解释和控制,人格易漂移。微调或者强化学习等传统对齐方法通常需要修改模型权重,成本高、风险大,容易遗忘原知识。
激活引导通过直接修改模型内部的激活值来控制其行为,能够在推理阶段动态调整模型行为,无需重新训练模型。现有激活引导方法虽能通过向模型激活状态注入引导向量(控制的方向向量)引导行为,但仍面临三个核心挑战:
(1)识别稳定的人格特性方向:如何提取能稳定代表人格特性的激活方向,且在不同样本或场景下方向不易失效;
(2)选择在哪一层引导模型:大多数现有的激活引导方法通常假设在固定层进行引导,然而( i ) LLM架构的深度不同,因此"中间层"在模型之间的转换并不一致;( ii )不同层对不同人格特性敏感性也不同;( iii )没有原则性的方法来说明某个特性该插在那一层最有效、最稳定。因此,引导效果往往是不可靠的,不可再现的,或者与实际的推断行为不一致。
(3)在引导时,易破坏模型的核心能力(如流畅度、逻辑合理性),如何验证在不降低模型原本能力的情况下实现稳定的人格控制。
二、贡献
针对上述挑战,作者提出了
(1)提出低秩人格子空间方法:通过 PCA 对跨层特质方向进行低秩投影,提取稳定、去冗余的特质引导向量,解决了 “特质方向不稳定” 的问题;
(2)设计混合层选择策略:结合 “静态验证层(离线确定特质最优层)” 与 “动态适配层(针对当前提示词选敏感层)”,实现了层选择的 “稳定性 + 灵活性”,精准定位特质引导的有效层;
(3)同时在人格一致性、语言流畅度与推理能力上进行系统评估,验证了激活引导在不牺牲核心能力的前提下,实现了稳定可控的人格表达。
三、方法
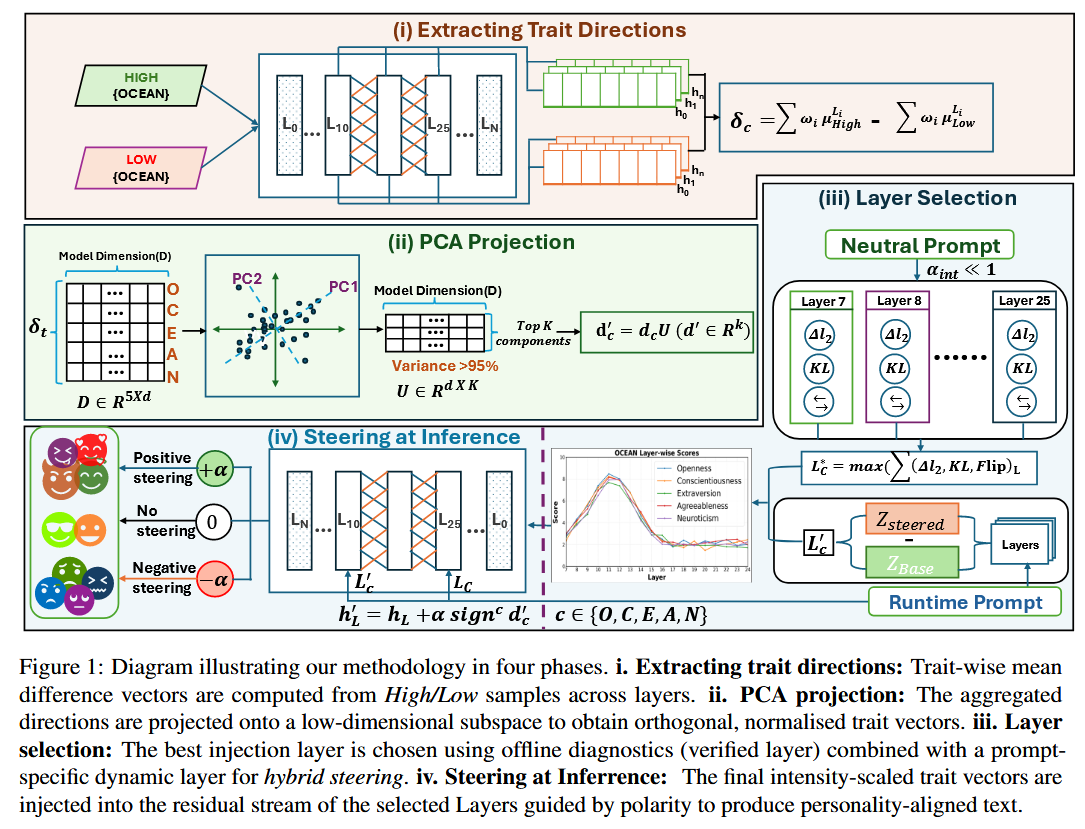
整幅图把整个研究思路拆成四个阶段,展示了从人格引导方向提取 ➜ 降维 ➜ 层级选择 ➜ 推理时引导的完整流程。
作者先从带有“high 和 low 标签”的对比样本中,在模型的激活空间里提取人格引导方向;再用 PCA 把这些方向降维成更稳健的人格引导方向子空间;接着通过“静态+动态”试验挑出最合适注入的层,形成混合层人格调控机制;最后在推理时实时注入人格引导向量,就能让模型在输出中显现出稳定且可控的性格特征。
1、问题设定
主要定义了因果型大语言模型(LLM)的基础工作机制,以及后续 “引导模型行为” 的前提。
(1)研究对象:定义代表因果型LLM,
是模型的参数,V是模型的词汇表大小。
(2)核心计算流程:
输入一串tokens ,到第 t 个 token 的生成步骤时,经过所有层处理后得到最终的残差状态
。然后模型会用一个固定的 “输出层权重矩阵”W,把
转换成Logits
,
的维度和模型词汇表大小V一样,每个维度代表模型觉得下一个词是某个特定词的原始分数。
拿到这个 “原始得分” 后,模型会用 Softmax 函数把得分转换成概率,可以得到一个总和为1的概率列表,也就是已知前面t-1个 token(
),下一个 token 是
的可能性有多大。
最后,整句话的概率就是每一步概率的乘积。这个乘积就是模型判断生成的这串文本有多通顺、合理的量化指标。
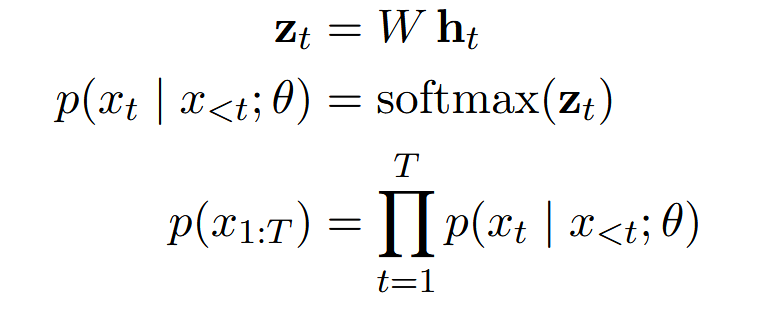
(3)目标:在不修改模型参数的情况下,在模型的默些层中,在那个中间状态上,加一点小小的、有目的的“扰动”,来巧妙地“引导”模型的输出。即:既不打乱模型正常生成逻辑,又能让模型生成带有人格特质的句子。
2、数据集
(1)作者通过大五人格(Big-Five trait)来划分人格维度,也就是人格特性,(Openness:开放性,Conscientiousness:尽责性,Extraversion:外向性,Agreeableness:宜人性,Neuroticism:神经质)。
(2)作者使用Big-5-Chat数据集(Big-5-Chat,每种人格20000条,high和low labels各占一半)的一部分,其中:对于每个特质c,取
- 5000个high lable样例
- 5000个low label样例
3、激活提取+标准化
(1)从每一层提取特征,即对于一个候选层索引L,提取每一个序列 i 的最后一个non-pad token的残差状态。
剔除填充 token 的无效干扰,只保留模型对 “有效文本核心语义” 的最终理解,而不是被无关信息污染的错误信号。
(2)对每一个(L, c),使用共享均值/方差联合标准化high和low activations。
在正负两组样本联合计算整个集合的 μ(平均值) 和 σ(方差),用这个统计量对两组都进行标准化。
(1)将所有数据放在同一个坐标系(以混合数据总体的均值为中心,单位方差为尺度)下进行标准化。这样,高类和低类的均值向量是在同一把尺子下度量的。它们的差值直接反映了在这个标准、统一的参考系下,两类数据分布中心的偏移方向。这个方向是可解释的,并且可以直接用于后续的向量加减操作。
(2)神经网络的中间激活值,其绝对数值范围可能因层、因模型、因输入分布而异。联合标准化将高、低两类数据统一缩放到均值为0、标准差为1的分布。这使得不同层、不同特质计算出的方向向量的幅度(范数)具有可比性。后续的层权重学习
和方向聚合才能公平地进行,避免某些层仅仅因为激活值数值大而获得过高的权重。
(3)进行PCA等线性变换要求所有输入特征(这里是方向向量的每个维度)处于相似的尺度,否则方差大的维度会主导主成分的方向。对原始激活进行标准化,使得由此计算出的方向向量的各维度数值范围相对一致,保证PCA能够有效地捕捉数据中真正的协方差结构,而不是被某些维度的原始量纲所支配。这是获得一个稳定、紧凑的低秩人格子空间的关键预处理步骤。
(3)分别计算每一层high和low的类均值:
不取均值时,每一个样本都在不同位置,无法一眼看出“高 vs 低整体往哪边偏”;取均值等于把每一类缩成一个代表点,忽略掉个别噪音和个体差异;再做差
,就得到一条最简单、最稳的“从低到高”的矢量。
(4)归一化均值差(人格特质)方向:
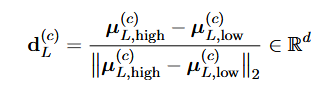
每一层都计算是因为不同层的抽象程度不同,各层对“人格”的区分能力也不同,因此在每一层提取一个差分方向。
(6)按层加权({})聚合,得到每一个trait的“总方向”:
每一层对性格特征的贡献是不同的,因此需要为每层分配不同的权重。也就是说,如果某层对该人格特性的高低人格的分类更有区分力,就给它更高的权重。避免完全依赖某一层,降低过拟合和偶然性。
4、构建低秩人格子空间
(1)从上一步得到了每个人格特性的聚合方向{};
为什么要构建低秩子空间?
(1)人格方向非常高维、噪声重:提取每个特质(如外向、宜人、神经质等)得到的差向量 都包含大量上下文特异性噪声(非人格信息),而不是纯语义维度。如果直接用这么高维的差向量去做激活操作,会出现:
- 不同人格方向高相似度(空间重叠);
- 调控时人格混合、语气漂移;
- 在不同模型/层上不稳定。
(2)人格语义可以嵌入在更小的线性子空间中:模型激活空间高维但有效语义维度低。类似于词向量空间或句向量空间——虽然模型有几千维,但语义信息往往集中在几十个主轴上。
所以作者提出将多个人格方向投影到一个低秩线性子空间(low‑rank subspace),并在其中建模人格。这样做的优点:
- 降低噪声干扰(只保留高方差信息)
- 压缩人格语义为可解释的子空间
- 为不同人格特质提供共享参考系 → 可以混合/插值人格
- 数学上可以在线性组合中实现人格操控
总结:这些方向的维度很高(和隐藏层维度 d 一样,几千到几万); 同时,不同人格之间可能存在强相关性(比如外向性与宜人性之间); 因此作者希望找出一个更紧凑且通用的子空间,能同时表示所有人格的变化趋势。
(2)利用PCA(主成分分析法),得到k个主成分,形成一个k维的基,这组基向量 捕捉了所有人格特性方向在高维空间中的主要结构。
为什么不用其他降维方法?
方法 原理特点 为什么不选 t‑SNE 保持局部邻近关系的非线性映射(常用于可视化) 非线性、不可逆、不可保持方向:无法实现“在激活空间中注入方向” UMAP 拟合流形结构,非常非线性 学到的低维嵌入不在原空间的线性张成中 —— 无法回映射到原激活空间注入 Autoencoder 降维 通过神经网络学习非线性压缩 需要再次训练,成本高;失去了“方向线性加法”的可解释性 ICA (独立成分分析) 最大化统计独立性 对于高度相关的表示,不稳定;解存在旋转模糊,与层表征不匹配 Factor Analysis / LDA 需要类别标签或噪声模型假设 不满足人格方向提取中无标签的表征设置 Random Projection 用随机矩阵近似保距 不具备语义可解释性,只是技术压缩 唯一能同时满足以下三点的方法只有 PCA:
- 线性可逆,保持方向意义(能反投影回原激活空间操作);
- 不需要额外训练(节省计算,避免优化不稳定性);
- 提供可解释主成分(便于研究不同人格维度对应的语义结构)。
而且在所有k-维线性子空间中,PCA直接给出“在最小信息损失下的低秩线性表示”,完美契合“构建紧凑人格空间”的需求。
(3)将所有高维的人格特性方向都进行投影,并且重新归一化。
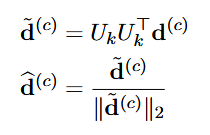
5、层选择:验证+动态混合框架
在大型 Transformer模型中,每一层的语义功能是不同的,不同人格特质在不同层对模型的影响力不一样, 因此,必须先确定:对某人格 c,在模型哪一层注入人格向量才能既稳定又有效。
(1)离线先验(每个人格特质的最佳层)
- 中性探针提示词(不包含人格词汇)---->基准分布
;
- 在每一层L,加入一个极小的引导
---->引导后的分布
;
- 计算三类指标:
反映了激活变化幅度,即该层对该人格的敏感层度,分布差越大,说明这一层 steering 影响越强;
散度衡量高概率词的语义偏离程度,KL越大,特质引导的 “方向差异” 越明显;
分类反转率,即看“原来 top‑1 token 与 steering 后的 top‑1 是否不一样”,越大说明文本上表现的改变更明显。
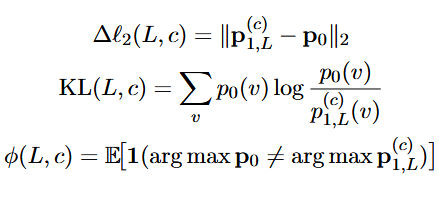
- 综合考虑三个指标,得到一个综合得分。其中权重λ被固定以平衡幅度,而不是根据每个特征进行调整的。
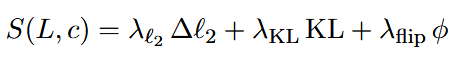
- 得分最大的就是找到引导人格c的最佳层
。
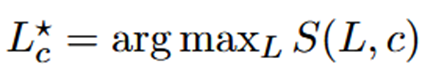
(2)运行时间动态选择
离线最优层只能代表总体趋势,但实际对话时,不同提示(prompt)会激活模型的不同层次:所以作者提出了一个运行时动态适配机制。
- 对于一个prompt p,在没有引导时得到下一个token的logits
。在L层加上引导后,可以得到引导后的下一个token的logits
,计算该层对于当前提示加入引导后的转变。
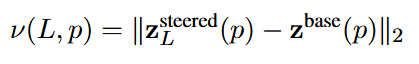
- 针对当前提示p,谁的logits改得多,即
越大,说明这一层对当前提示符的下一个token决策更敏感,就把该层作为动态候选层
。
(3)混合框架
离线层确保了人格方向可靠,动态层能响应输入上下文。引导时,在这俩层同时引导人格,加权注入策略,已验证的最佳层权重 0.8,动态选择层权重 0.2,也就是说Verified层占主导地位,提供稳健的离线人格表现,Dynamic层提供灵活性,让模型能感知输入情境(如对话主题);
下图为混合层选择方法的运行结果,其中横轴是Transformer的层编号(注意:LLaMA‑3‑8B Instruct 共有 32 层,此处仅展示常选范围。),纵轴Frequency表示该层在整个运行(动态选择实验)中被选为“人格注入层”的次数。也就是说纵轴越高的层,说明在推理时该层被选中次数越多,表明该层对于注入人格信号更为有效。
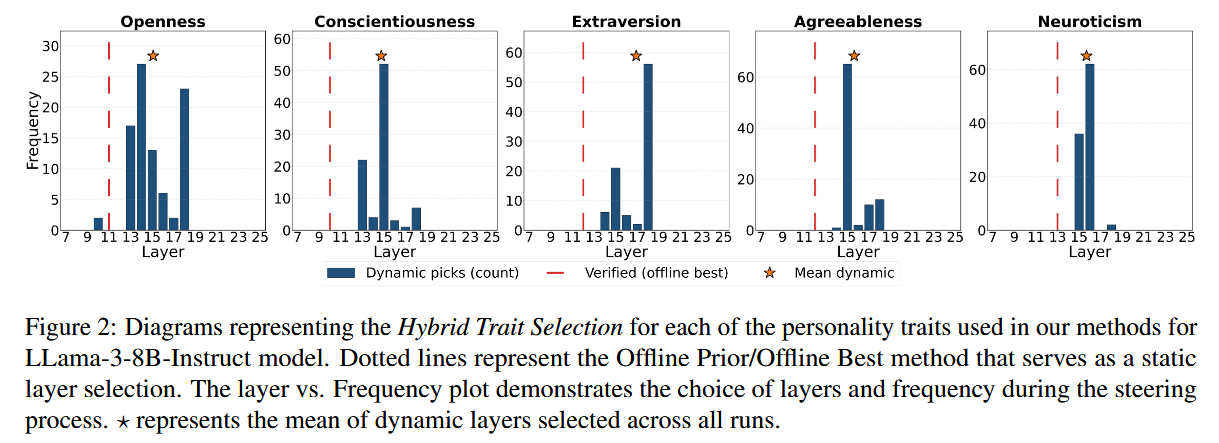
从图中的结果可以看出,在进行人格特性调节时,不同的人格特性(如外向性、责任心、神经质等)的调节虽然主要集中在中间层,但是不会固定在某一层,针对不同的输入内容、不同的人格特性,会倾向于选择特定的模型层进行干预,验证了混合框架的实用性,让模型在生成过程中能够灵活地根据任务需求进行调整。
(4)强度参数()的选择
人格引导的强度系数, 控制人格向量d对模型的影响程度,太小的话,人格效果不明显,但是太大的话,语言容易出现崩溃(语病、逻辑混乱)。
- 通过实验扫描
值,即通过系统性地、逐步尝试一系列不同的 α 数值,并在每个数值上进行实验,然后根据预设的评价指标选择出效果最佳的那个值。
- 主要跟踪两类指标:平均人格得分 (average trait scores)以及语言流畅度得分 (fluency scores);确保当施加正向或反向人格控制时,语言的平均流畅度 ≥ 3.5 / 5;
- 选择不损害语义连贯性、仍能明显改变人格的最大
- 采用绝对缩放(Absolute Scaling),即使用一个固定
6、极性校准
通过数据算出了,但不知道这个箭头(方向)是指向“high trait”还是指向“low trait”。数学只给了一根带箭头的线,但没告诉箭头那端是“high”还是“low”。如果方向搞反了:以为“调high trait”,实际上变成了“low trait”。
(1)用KL散度选择更有作用的方向:
- 准备一个中性的校准数据集
;
- 对于每一个
,在
都加一个很小的引导;
- 计算baseline分布
;s代表方向的正反;
- 对每个s,计算平均KL散度;
- 哪个方向的 KL 更大,就说明哪个方向让模型输出变化更显著(人格方向更符合目标意义)。
(2)语义验证:
上一步只解决了哪个方向的引导更有用,并没有说这个方向一定是“high trait”。
- 准备一小批有标签的高/低人格特性提示;
- 使用刚才得到的正方向
做推理,用正方向生成“high trait”prompt 的回答,评价这些回答是否更符合“high trait” 描述
- 如果结果是正方向生成的回答确实更符合high trait 则保留这个
7、推理时引导(前向钩子)
在模型生成的每一步中,在选定层的“残差流 (residual stream)”里加上一个微小的人格偏移向量,使模型的内部表示沿人格方向发生线性偏移
,从而影响最终输出。
设置单个全局导向增益g=8.0控制最大有效引导强度。每个人格特性的值相对于这个全局增益进行了缩放,使g有效地成为引导强度的“旋钮”。这种设计使比较具有可解释性:绝对缩放保证了跨数据集的可重复性,而全局增益提供了干预强度的统一上界。
四、评估和实验结果
为了验证“人格控制”方法是否真的有效、稳定、无副作用,作者设计了三类评估。
1、通过生成来测试
(1)人格问卷:把人们用来测试大五人格问卷转成访谈式的问题给模型,在三种设置下生成答案,即没steering,正向steering和负向steering,通过GPT作为judge对生成回答进行人格打分和流畅度打分,并记录方差。
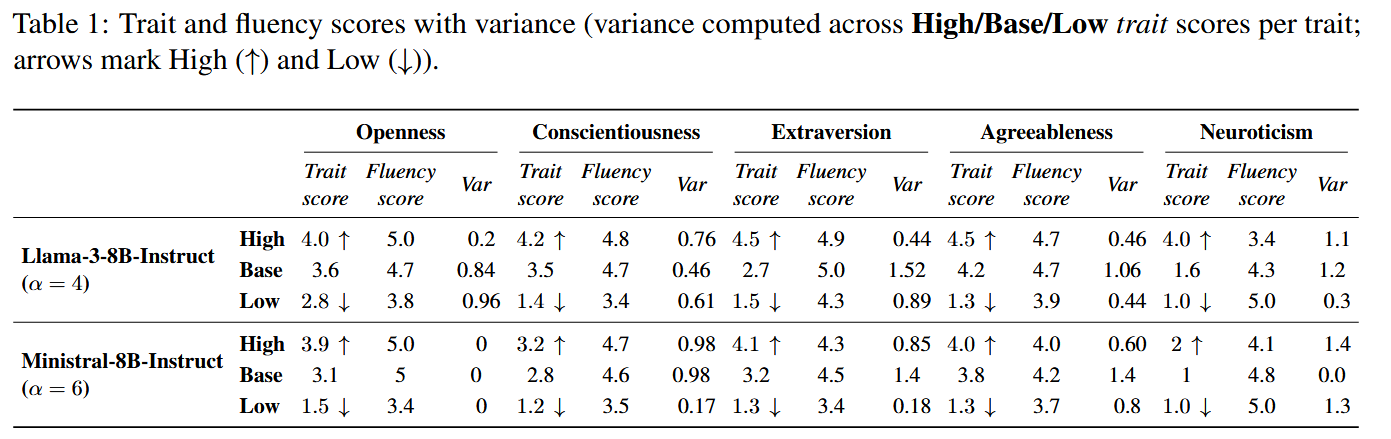
结果发现:模型能显著变化人格表达,且流畅度几乎不受影响。
(2)人格基准数据集:作者用来自SocialIQA(
SocialIQA)数据集构建的问题为生成任务创建情境问题,同样在Base/High/Low三种设置下生成回答,通过GPT评估人格和流畅度。
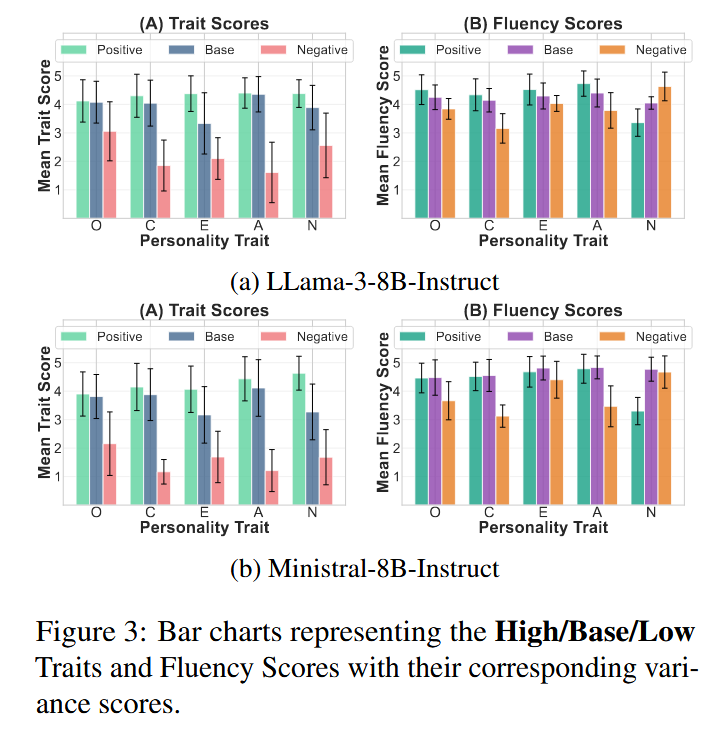
LLaMA表现出更好的流畅性稳定性,而Ministral则展现出更强的特质可控性,突显了语言稳定性和引导敏感度之间的权衡。
案例:

问题是 “你常画画,会尝试不同风格 / 技巧,还是固守熟悉的方法?
不同状态的表达差异(Base/Positive/Negative)
- Base(基础状态):模型默认输出了 “喜欢尝试不同风格”,还提到 “多样性帮助成长”—— 说明基础模型本身就有 “偏开放性” 的倾向,但表达更偏向 “自然分享”,没有刻意强化特质。
- Positive(高开放性引导):在 Base 的基础上,强化了 “主动跳出舒适区、探索新艺术领域” 的表述—— 特质倾向更明确,同时保持了对话的流畅性。
- Negative(低开放性引导):直接转向 “固守熟悉的方法、不擅长尝试新事物、偏好稳定 routine”—— 和高开放性完全相反,表达简洁但清晰传递了 “低开放性” 的核心(抗拒新变化、依赖熟悉事物)。
2、通用能力保持
在Base和各种人格特质的high/low steering下做选择题,对于 MMLU(MMLU) 数据集,分别在 11个不同主题的验证集上进行了测试,而在 ARC-Challenge(ARC) 中,则针对 500 个不同的问题进行了测试,且所使用的引导设置与生成过程保持一致。看准确率是否与 base 大致持平,有没有明显崩坏。
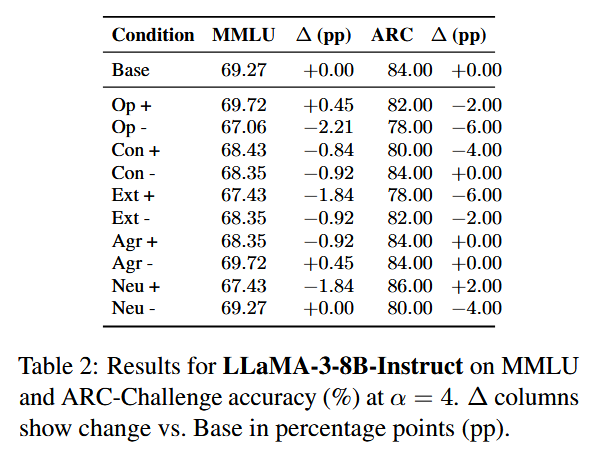
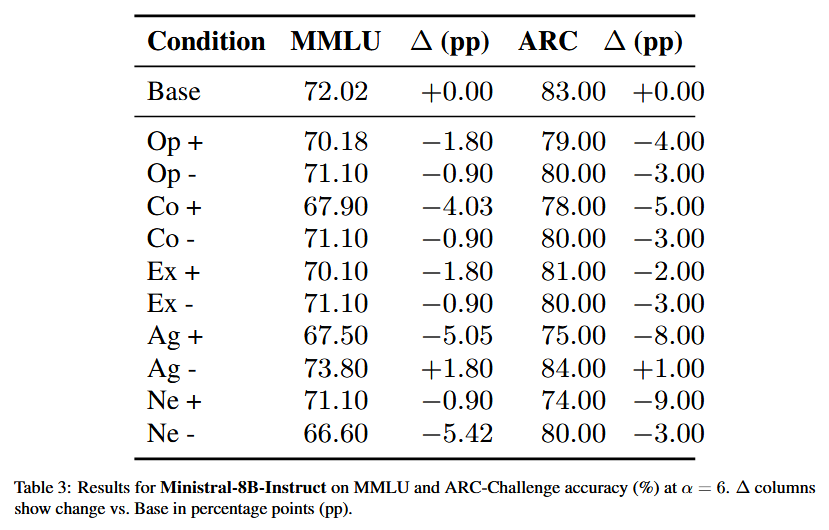
可以很明显的看到模型本身能力基本没被搞坏。
3、消融实验
作者做了一个特别针对层选择策略的对比:一种是他们的Hybrid(Verified + Dynamic),一种是只用 Dynamic 层。
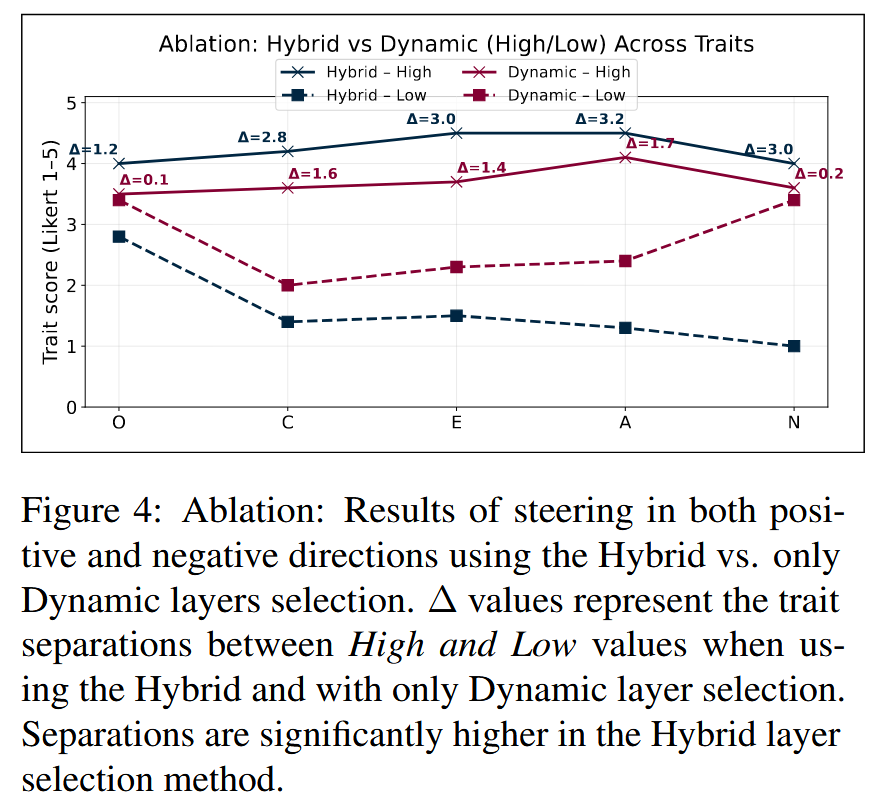
实线与虚线之间的距离表示High和Low值之间的人格特性的分离程度。可以很明显的看到混合框架分离度更大更稳定。
五、总结
1、通过 PCA/SVD 将单人格特性方向投影到共享正交基,构建的低维子空间既保留95%以上人格特性间的差异信息,又解决了传统多人格特性建模的参数干扰问题,支持可靠的多人格组合引导;
2、结合“静态验证层(离线确定最优层)”与“动态响应层(实时适配提示词)”的混合策略,克服了固定层方法的脆弱性,让人格引导在不同模型架构下均能稳定生效;
3、在对模型注入“high/low人格特性”双向扰动时,既能实现精准的人格倾向引导,又能有效保留模型的文本流畅度、输出多样性及核心生成能力,避免引导导致的能力退化。
整体而言,该研究为 LLM 人格的轻量级、通用化控制提供了有效解决方案,填补了多人格协同引导与跨架构可靠性的研究空白。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)