Spring AI:DeepSeek 整合 RAG 增强检索: 实现与 PDF 对话
Spring AI:DeepSeek 整合 RAG 增强检索: 实现与 PDF 对话
历史文章
Spring AI:对接DeepSeek实战
Spring AI:对接官方 DeepSeek-R1 模型 —— 实现推理效果
Spring AI:ChatClient实现对话效果
Spring AI:使用 Advisor 组件 - 打印请求大模型出入参日志
Spring AI:ChatMemory 实现聊天记忆功能
Spring AI:本地安装 Ollama 并运行 Qwen3 模型
Spring AI:提示词工程
Spring AI:提示词工程 - Prompt 角色分类(系统角色与用户角色)
Spring AI:基于 “助手角色” 消息实现聊天记忆功能
Spring AI:结构化输出 - 大模型响应内容
Spring AI:Docker 安装 Cassandra 5.x(限制内存占用)&& CQL
Spring AI:整合 Cassandra - 实现聊天消息持久化
Spring AI:多模态 AI 大模型
Spring AI:文生图:调用通义万相 AI 大模型
Spring AI:文生音频 - cosyvoice-V2
Spring AI:文生视频 - wanx2.1-i2v-plus
Spring AI:上手体验工具调用(Tool Calling)
Spring AI:整合 MCP Client - 调用高德地图 MCP 服务
Spring AI:搭建自定义 MCP Server:获取 QQ 信息
Spring AI:对接自定义 MCP Server
Spring AI:RAG 增强检索介绍
Spring AI:Docker 安装向量数据库 - Redis Stack
Spring AI:文档向量化存储与检索
Spring AI:提取 txt、Json、Markdown、Html、Pdf 文件数据,转换为 Document 文档
Spring AI:Apache Tika 读取 Word、PPT 文档

目前,我们已经学会了读取各种格式的文件,转换为 Document 文档集合,以及通过向量模型,将文档进行向量化,最终存储到 Redis 向量数据库中。
本文中,我们尝试通过一个案例 —— 与 PDF 进行对话,看看在 Spring AI 项目中,要如何将整个 RAG 流程串起来。
将 PDF 向量化存储到 Redis 中
编辑 InitEmbeddingIndexRunner 启动任务类,将之前写死的 3 条 Document 文档,修改为从 PDF 文件中读取
@Component
public class InitEmbeddingIndexRunner implements ApplicationRunner {
@Resource
private VectorStore vectorStore;
@Override
public void run(ApplicationArguments args) {
// 新建 PagePdfDocumentReader 阅读器
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader("classpath:/document/xxx.pdf", // 类路径PDF文件
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0) // 设置页面顶边距为0
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0) // 设置删除顶部文本行数为0
.build())
.withPagesPerDocument(1) // 设置每个文档包含1页
.build());
// 读取并转换为 Document 文档集合
List<Document> documents = pdfReader.get();
// 通过向量模型,将文档向量化存储到 Redis 中
vectorStore.add(documents);
}
}
清空 Redis 中的向量数据
为了方便等会测试,执行如下命令,先将 Redis 中向量都删除掉:
FLUSHDB
删除完毕后,重启后端项目,再次查看 Redis 中的数据,该 PDF 向量数据就存储成功了
防止重复添加相同数据
之前小节中,我们发现一旦重启后端项目,就会再次执行文档向量化存储的逻辑,这会导致重复添加相同的文档。为了避免此问题,编辑 InitEmbeddingIndexRunner 启动任务,在进行向量化存储之前,对 Redis 进行查询,若发现有相同的文档,则跳过,否则才写入到 Redis 中,代码如下:
@Component
public class InitEmbeddingIndexRunner implements ApplicationRunner {
@Resource
private VectorStore vectorStore;
@Override
public void run(ApplicationArguments args) {
// 省略...
// 读取并转换为 Document 文档集合
List<Document> documents = pdfReader.get();
// 防止重复添加到 Redis 中
for (Document document : documents) {
// 从向量数据中,查询当前文档
List<Document> results = vectorStore.similaritySearch(SearchRequest.builder()
.query(document.getText())
.topK(1) // 查询一条最高得分的
.build());
// 如果结果不为空,并且得分大于 0.99,则表示文档较高几率重复,直接跳过
if (!results.isEmpty() && results.get(0).getScore() > 0.99)
continue;
// 通过向量模型,将文档向量化存储到 Redis 中
vectorStore.add(List.of(document));
}
}
}
添加上述逻辑后,小伙伴们可以再次重启项目,测试看看是否还会添加重复文档!
整合 DeepSeek
接着,再来为项目整合一下 DeepSeek 大模型。编辑 pom.xml, 添加如下依赖:
<!-- DeepSeek 模型 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
记得刷新一下 Maven,然后编辑 applicaiton.yml, 添加 AI 大模型相关配置项,如下:
spring:
// 省略...
ai:
// 省略...
deepseek:
base-url: https://api.deepseek.com # DeepSeek 的请求 URL, 可不填,默认值为 api.deepseek.com
api-key: xxx # 填写 DeepSeek Api Key,改成你自己的
chat:
options:
model: deepseek-reasoner # 使用哪个模型
temperature: 0.0 # 温度值
解释一下核心部分:
- deepseek-reasoner 表示使用的是 R1 推理大模型;
- temperature 温度值设置为了 0.0。大多数聊天模型的默认温度通常过高,在 RAG 场景下,较低的温度值可降低生成内容的随机性,减少幻觉率(AI 大模型胡编乱造),确保输出更贴近检索到的参考信息,适合需要高准确性的任务。
接着,创建一个 /config 包,并新建 ChatClientConfig 客户端配置类:
@Configuration
public class ChatClientConfig {
/**
* 初始化 ChatClient 客户端
* @param chatModel
* @return
*/
@Bean
public ChatClient chatClient(DeepSeekChatModel chatModel) {
return ChatClient.builder(chatModel)
.build();
}
}
RAG 增强检索
最后,就剩 RAG 增强检索部分了。编辑 pom.xml , 添加向量 Advisor 依赖,它可以在调用 AI 大模型之前,查询向量数据库,并将结果组合成增强型提示词:
<!-- 向量 Advisor -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
记得刷新一下 Maven, 将包下载到本地仓库中。
然后,在 /controller 包下,新建一个 RAGController 控制器:’
声明一个 /rag/generateStream 流式对话接口,代码如下,只需在调用 AI 大模型时,配置上 Spring AI 提供的 QuestionAnswerAdvisor 即可完成 RAG 功能,是不是很简单:
@RestController
@RequestMapping("/rag")
public class RAGController {
@Resource
private VectorStore vectorStore;
@Resource
private ChatClient chatClient;
/**
* 流式对话
* @param message
* @return
*/
@GetMapping(value = "/generateStream", produces = "text/html;charset=utf-8")
public Flux<String> generateStream(@RequestParam(value = "message") String message) {
// 流式输出
return chatClient.prompt()
.system("请你扮演一名企业客服。从企业内部知识库中查阅相关资料,并回答用户,若内部资料没有相关内容,则回答 “未找到相关资料”")
.user(message) // 提示词
.advisors(new QuestionAnswerAdvisor(vectorStore)) // 检索向量库,组合增强提示词,调用 AI 大模型
.stream()
.content();
}
}
重启项目,调用接口测试下自己的pdf内容
关于 QuestionAnswerAdvisor
有兴趣的小伙伴,也可以进入到 QuestionAnswerAdvisor 类的源码中,里面有个 before() 方法,就是在调用 AI 大模型之前织入代码,如下图所示:
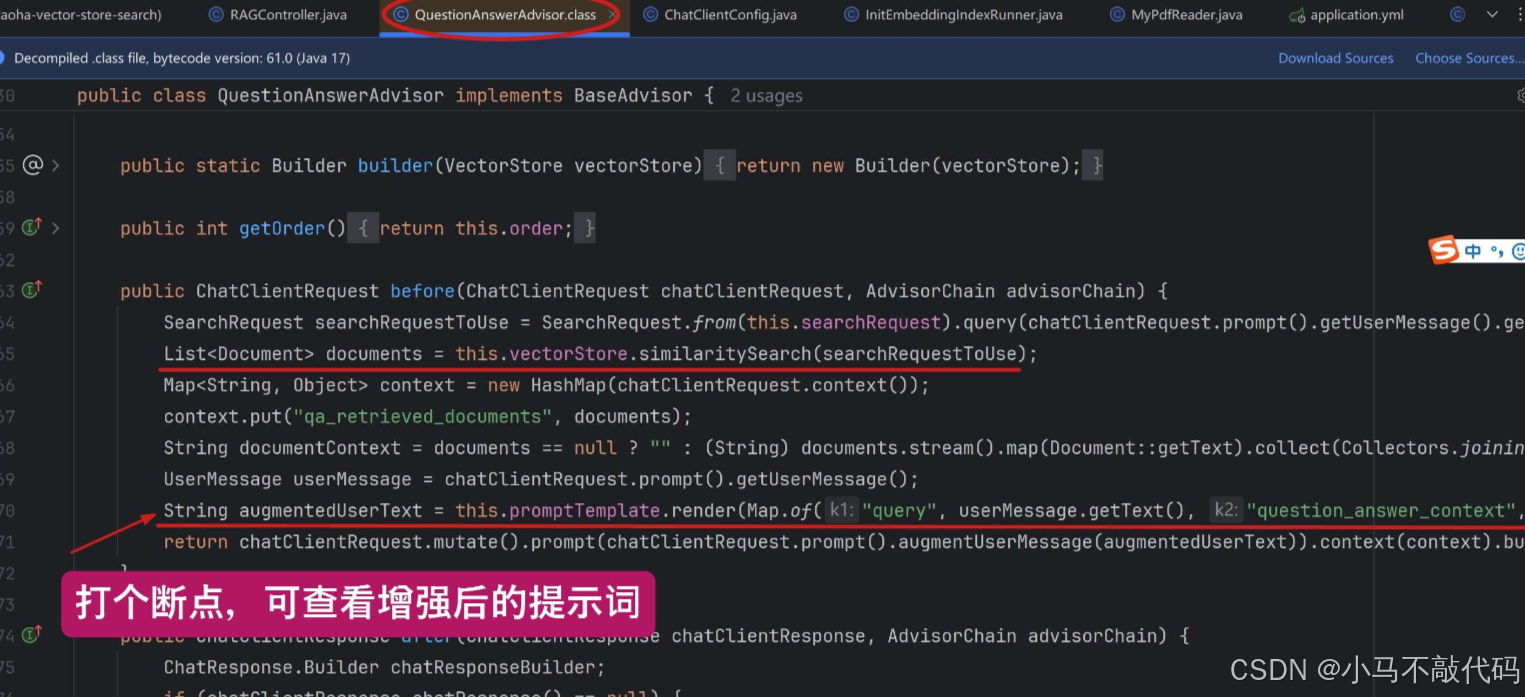
无非是拿着我们提问的问题,去检索向量数据库,获取匹配度较高的文档;
再把查询结果,组合成 “增强型” 的提示词模板。你可以在 promptTemplate.render() 这行打个断点,看看实际组合出来的提示词模板是什么样的

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)