在大模型班学算法的笔记记录-逻辑回归
逻辑回归二元分类的损失函数是二元交叉熵,单个样本为,整体为所有样本的平均值;二元交叉熵不适用于多分类,会导致概率和不为1,多分类应使用Softmax+多分类交叉熵;MSE不推荐做分类,核心问题是损失非凸、易梯度消失、对异常值敏感;三种梯度下降的核心差异是迭代样本量:BGD用全量(稳定但慢)、SGD用单个(快但波动大)、MBGD用小批量(平衡最优)。
逻辑回归针对二元分类(标签![]() )设计,其损失函数(对数损失)的核心是二元交叉熵,分为单个样本和整体样本两种形式:
)设计,其损失函数(对数损失)的核心是二元交叉熵,分为单个样本和整体样本两种形式:
单个样本损失函数
对于单个样本,模型通过sigmoid函数输出正类概率 ![]() (
( ![]() 是线性输出),损失函数为:
是线性输出),损失函数为:![]()
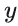 :真实标签(0表示负类,1表示正类);
:真实标签(0表示负类,1表示正类);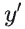 :模型预测为正类的概率(范围0~1);
:模型预测为正类的概率(范围0~1);- 物理意义:当
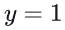 时,损失仅关注
时,损失仅关注 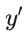 与1的差距(
与1的差距(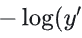 );当
);当 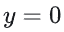 时,损失仅关注
时,损失仅关注 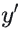 与0的差距(
与0的差距(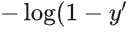 ),保证预测越准,损失越小。
),保证预测越准,损失越小。
整体样本代价函数
对于 ![]() 个训练样本,整体损失是单个样本损失的平均值(优化目标是最小化该值):
个训练样本,整体损失是单个样本损失的平均值(优化目标是最小化该值):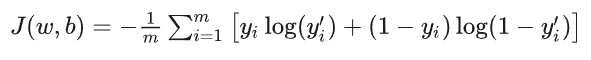
其中 ![]() 是权重参数,
是权重参数, ![]() 是偏置参数。
是偏置参数。
3. 二元交叉熵做多分类的结果
二元交叉熵(BCE)仅适用于二元分类,若直接用于多分类(标签 ![]() )
)
1. 类别互斥性失效
多分类任务中,样本只能属于一个类别(如手写数字识别,样本只能是0~9中的一个),但二元交叉熵会将每个类别视为“独立的二元判断”(比如同时判断“是否是0”“是否是1”),导致模型输出的各类别概率之和不等于1,违背概率分布的基本要求。
2. 损失计算不合理,优化目标偏离
例如:样本真实标签是2![]() ,用二元交叉熵时,会同时计算“不是0”“不是1”“是2”的损失,迫使模型压低所有非目标类的概率,但无类间约束,易出现
,用二元交叉熵时,会同时计算“不是0”“不是1”“是2”的损失,迫使模型压低所有非目标类的概率,但无类间约束,易出现 ![]() (和为1.2)的混乱输出。
(和为1.2)的混乱输出。
3. 正确方案
多分类应搭配 Softmax函数(将线性输出转换为和为1的概率分布)+ 多分类交叉熵损失: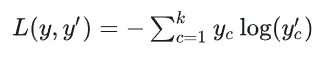
其中![]() 是独热编码(真实类别为1,其余为0),
是独热编码(真实类别为1,其余为0), ![]() 是Softmax输出的类别概率。
是Softmax输出的类别概率。
4. MSE损失函数能否用于分类?
结论:不推荐,仅理论可行但效果极差,核心原因如下:
1. 损失函数非凸,优化困难
逻辑回归的输出是sigmoid/softmax概率,若用MSE(均方误差):![]()
sigmoid+MSE的组合会让损失函数变为非凸函数(存在多个局部最小值),梯度下降易陷入局部最优,无法找到全局最优解;而交叉熵+ sigmoid/softmax的损失是凸函数,优化更稳定。
2. 梯度易消失,收敛极慢
对MSE损失求导,梯度项包含 :![]()
- 当
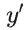 接近0或1(预测置信度高)时
接近0或1(预测置信度高)时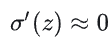 梯度消失,参数几乎不更新;
梯度消失,参数几乎不更新; - 交叉熵损失的梯度无
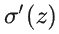 项,更新速度稳定,无梯度消失问题。
项,更新速度稳定,无梯度消失问题。
3. 对异常值敏感
MSE是“平方误差”,异常样本(如标签错误)的误差会被平方放大,严重影响模型拟合;而交叉熵关注概率的对数误差,更贴合分类任务的核心目标。
总结
- 逻辑回归二元分类的损失函数是二元交叉熵,单个样本为
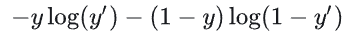 ,整体为所有样本的平均值;
,整体为所有样本的平均值; - 二元交叉熵不适用于多分类,会导致概率和不为1,多分类应使用Softmax+多分类交叉熵;
- MSE不推荐做分类,核心问题是损失非凸、易梯度消失、对异常值敏感;
- 三种梯度下降的核心差异是迭代样本量:BGD用全量(稳定但慢)、SGD用单个(快但波动大)、MBGD用小批量(平衡最优)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)