关于llamasharp 使用多卡GPU运行模型以及GPU回退机制遇到的问题。
本文记录了在4张NVIDIA RTX 4090显卡上部署AI模型推理服务器的实践过程。作者最初使用ollama+dify框架效果不佳,后改用.NET Core自主开发模型容器,解决了IIS线程回收和模型驻留问题。在启用CUDA加速时遇到路径和依赖问题,通过日志分析发现llamaSharp库的路径处理缺陷,最终通过手动调整DLL依赖关系成功实现GPU加速,使4张4090显卡的算力得到充分利用,CPU
最近上了4张nvidia rtx 4090 48G 显卡做了PCIE人工智能模型推理服务器,本来想着4张4090就很牛逼了,跑个70B的模型毫无压力,首先通过 ollama + dify 跑了一下,效果一般,没有达到预期效果,因为业务开发需要,打算用微软的ML km 和 sm agent 框架实现本地加载模型,全技术栈开发,那么就需要把ollama 和 dify 平替了,因为要做RAG增强技术,ollama 不支持 rerank API接口,必须用 dify 配合 Inferences , 三个平台web api 交互损失了很多CPU时间,所以第一步先把模型容器ollama给平替了,考虑到做成服务,还得实现API接口,那么直接通过netcore 实现ollama容器功能,管理模型启动和调用及应答,API接口直接实现就好了,简单来说就是netcore web 实现人工智能模型NLP和RAG技术全生命周期,再不依赖ollama/dify/Inferences, 只需要注意两个关键点:
1. IIS 线程池回收问题,很好解决,设置让IIS不要回收,或者在凌晨回收,问答时候驱动模型启动。
2. 模型驻留内存,方便即问即答,消除模型驱动启动时间,提高用户体验度,也很好解决,使用Quartz 任务计划,设置标识,如果模型句柄为空或者触发异常,重新启动模型即可。
经过几周开发,底层库以及模型管理和问答全部实现了,模型正常启动了,32B

使用CPU模型推理没有任何问题。
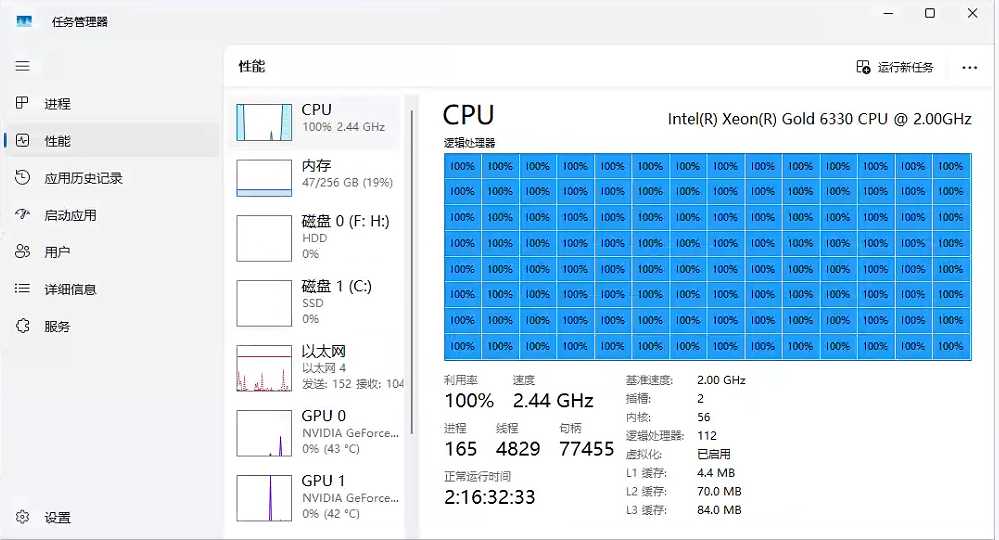
回答也没问题,本地调用模型使用websocket 回答。
这么这个时候问题来了,我4张4090总不能当摆设嘛,总得利用GPU Cuda 强大得推理性能吧。
于是我加载了cuda 驱动,这是第一步,动态监测硬件运行状况,4张4090昂。

然后在底层启用Gpu运算以及Cuda推理。核心代码:启用Cuda,启用Vulkan, 禁止回退到CPU。
NativeLibraryConfig.All.WithCuda(true);
NativeLibraryConfig.All.WithVulkan(true);
NativeLibraryConfig.All.WithAutoFallback(false);那么这个时候就要注意了,llamasharp 底层有一个BUG,如果你的模型加载GpuLayerCount设置不合理,或者CPU核心数特别多的时候,它对算力的分配总是偏爱CPU,导致运行32B 70B以上大参数模型的时候,CPU满载干活,GPU潇潇洒洒坐着小板凳看戏,这是我们不能容忍的。
ModelDataInfo? modelInfo = GetModelById(ModelId);
if (modelInfo == null) {return false;}
await Task.Run(async ()=>
{
modelInfo.ModelParam = new ModelParams(modelInfo.ModelPath!);
modelInfo.ModelParam.ContextSize = modelInfo.ModelContext;
modelInfo.ModelParam.GpuLayerCount = modelInfo.ModelGpuLayerCount;
modelInfo.ModelParam.PoolingType = modelInfo.ModelPoolingType;
modelInfo.ModelParam.Threads = Environment.ProcessorCount;
modelInfo.ModelWeight = await LLamaWeights.LoadFromFileAsync(modelInfo?.ModelParam!);
});
return true;一顿梭哈,代码写完了启动模型,等了几分钟模型没启动起来,检查了nvidia cuda 驱动没问题,12.9 检查了 llamasharp.backend.cuda12.0.25.0 , 没问题,然后 nvcc 和 nvidia-smi 都问题,证明问题不在cuda 驱动本身,然后在代码里面写入日志回调看看到底咋回事。
NativeLibraryConfig.All.WithLogCallback((level, message) =>
{
string logFilePath = @"F:\logfile.txt";
using (StreamWriter writer = File.AppendText(logFilePath))
{
writer.WriteLine($"{DateTime.Now}: {message}");
}
});结果发现有如下错误提示:很明显llamasharp 加载 cuda 驱动失败了,导致llama.dll 和 ggml 以及llama_cuda 核心驱动加载失败,一思考这是web应用多半是路径问题,果然llamasharp 当初开发的时候应该没想到会有web容器的应用所以对相对目录没有实现转换。
2025/12/5 0:31:16: Loading library: 'llama'
2025/12/5 0:31:16: Detected OS Platform: 'WINDOWS'
2025/12/5 0:31:16: Detected OS string: 'win-x64'
2025/12/5 0:31:16: Detected extension string: '.dll'
2025/12/5 0:31:16: Detected prefix string: ''
2025/12/5 0:31:16: NativeLibraryConfig Description:
- LibraryName: LLama
- Path: 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\llama.dll'
- PreferCuda: True
- PreferVulkan: True
- PreferredAvxLevel: AVX2
- AllowFallback: False
- SkipCheck: False
- SearchDirectories and Priorities: { ./ }
2025/12/5 0:31:16: NativeLibraryConfig Description:
- LibraryName: LLama
- Path: 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\llama.dll'
- PreferCuda: True
- PreferVulkan: True
- PreferredAvxLevel: AVX2
- AllowFallback: False
- SkipCheck: False
- SearchDirectories and Priorities: { ./ }
2025/12/5 0:31:16: Got relative library path 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\llama.dll' from local with , trying to load it...
2025/12/5 0:31:16: Found full path file 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\ggml-base.dll' for relative path 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\ggml-base.dll'
2025/12/5 0:31:16: Failed Loading 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\ggml-base.dll'
2025/12/5 0:31:16: Failed loading dependency 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\ggml-base.dll'
2025/12/5 0:31:16: Found full path file 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\ggml.dll' for relative path 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\ggml.dll'
2025/12/5 0:31:16: Failed Loading 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\ggml.dll'
2025/12/5 0:31:16: Failed loading dependency 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\ggml.dll'
2025/12/5 0:31:16: Found full path file 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\llama.dll' for relative path 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\llama.dll'
2025/12/5 0:31:16: Failed Loading 'D:\MyProject_2025\瓜州县人工智能应用系统开发\GzAIManager\runtimes\win-x64\native\cuda12\llama.dll'
直接指定llama.dll 的路径,会自动加载其他cuda驱动,这其实是netcore 多平台发布runtime的时候出现的一个问题,一局代码解决问题,然后重新启动模型。
NativeLibraryConfig.LLama.WithLibrary($"{env.ContentRootPath}\\runtimes\\win-x64\\native\\cuda12\\llama.dll");然后一看日志,又提示 llama.dll 加载成功,但是 ggml_base.dll 和 ggml.dll ggml-cuda.dll 三个dll 依旧加载失败,这就不是路径问题了,根据以往经验,要么权限问题,IIS池设置的localsystem 肯定不是权限问题,那么就是dll 依赖了,打开vs2025的 命令行 dumpbin /dependents
dumpbin /dependents C:\Users\Administrator\Desktop\人工智能发布-22222\runtimes\win-x64\native\cuda12\ggml-base.dll
提示依赖如下:
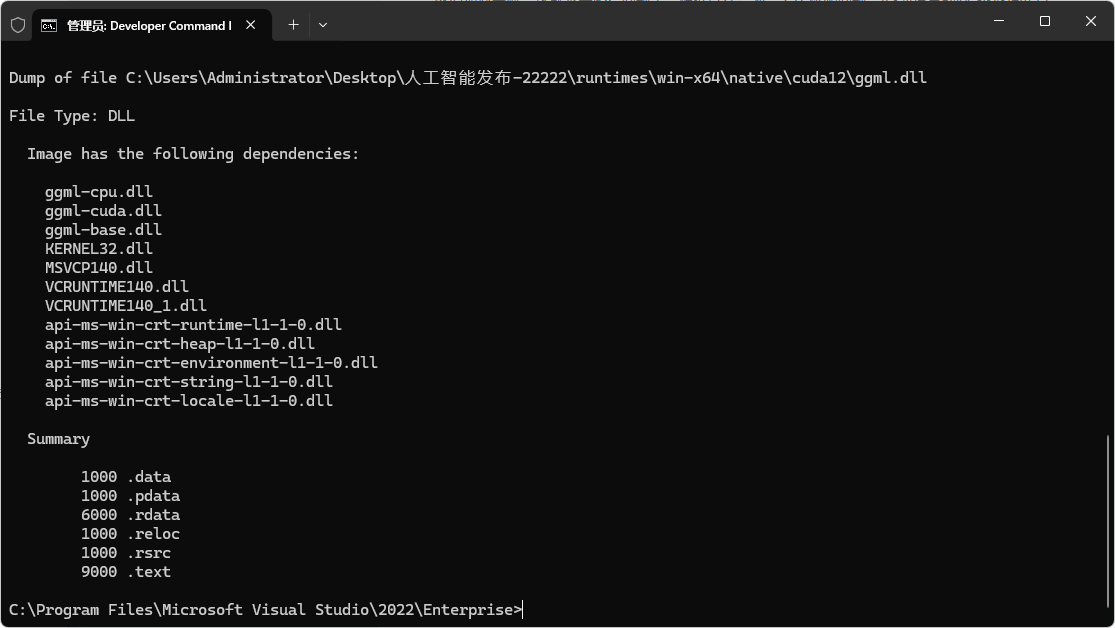
主要又VC14 64的运行库,这个库我已经安装了,仔细一看,他需要加载一个ggml-cpu.dll , 那么我就理解了,当前目录netcore 发布的时候,因为是 cuda12 版本,所以就没有将cpu版本发布到这个目录。然后我一看avx512 目录里面恰好有这个文件,先手动打补丁,把ggml-cpu.dll从avx512复制到cuda 目录,注意架构兼容,现在主流AI服务器CPU都支持avx512指令。
然后现在又到了测试的时候,继续重启模型,果然所有cuda dll 都加载成功,模型成功启动。
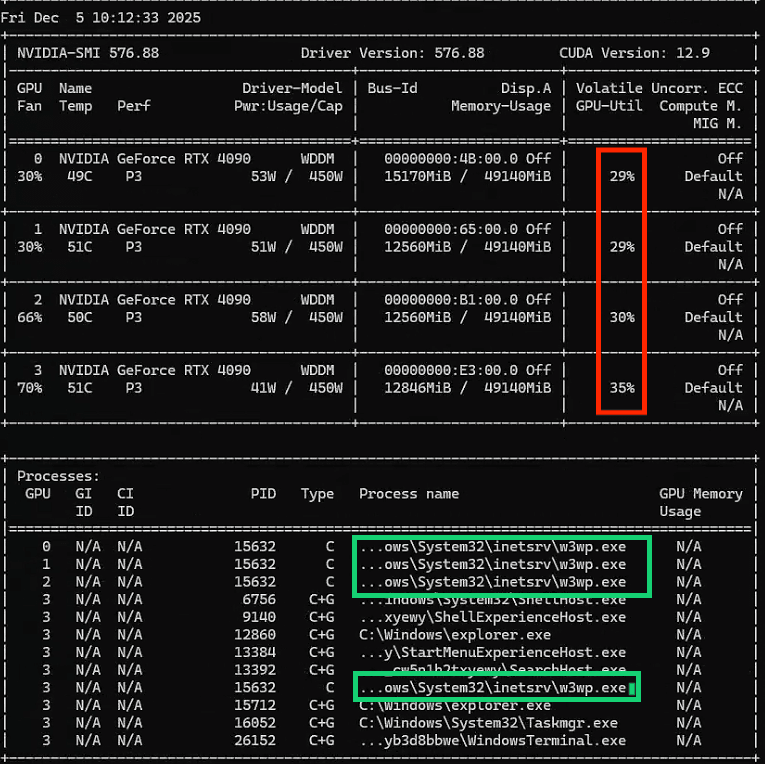
GPU算力基本平均分配,CPU利用率12%,基本符合预期,花了大10几万你不干活怎么行?
w3wp.exe 一个进程4个线程调度GPU,也是符合预期,好了解决了继续干活。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)