企业实训:AI运维工程师实训——某外资商业银行
课程总结:回顾LLM架构、模型部署和运维数据管理课后作业:提交一份部署小模型并整理自有日志数据的报告。
11月下旬到12月上旬,TsingtaoAI技术团队为汇丰银行量身定制交付AI运维工程师实训课程,深度融合LLM技术与真实运维场景。课程分三阶段系统授课:首阶段详解Transformer架构与ChatGLM-6B、LLaMA3-8B等轻量模型特性,通过Docker容器化实现GPU/CPU资源优化部署;第二阶段聚焦日志智能分析、故障预测与安全事件识别,基于历史数据分析生成预测模型并构建实时预警机制;第三阶段实现自动化升级,包括性能瓶颈诊断、资源调度优化及自动生成运维脚本与标准化文档。全程结合真实运维数据实操,学员将掌握从模型部署到智能运维的闭环能力,显著提升系统稳定性与运维效率,精准匹配金融行业对AI驱动运维的高阶需求,助力企业实现运维智能化升级。
第1课:LLM基础与模型部署
课程目标
理解LLM的架构与工作原理
掌握小模型的选择、部署与运维数据管理
能够搭建基础LLM环境并准备训练分析数据
实训方案
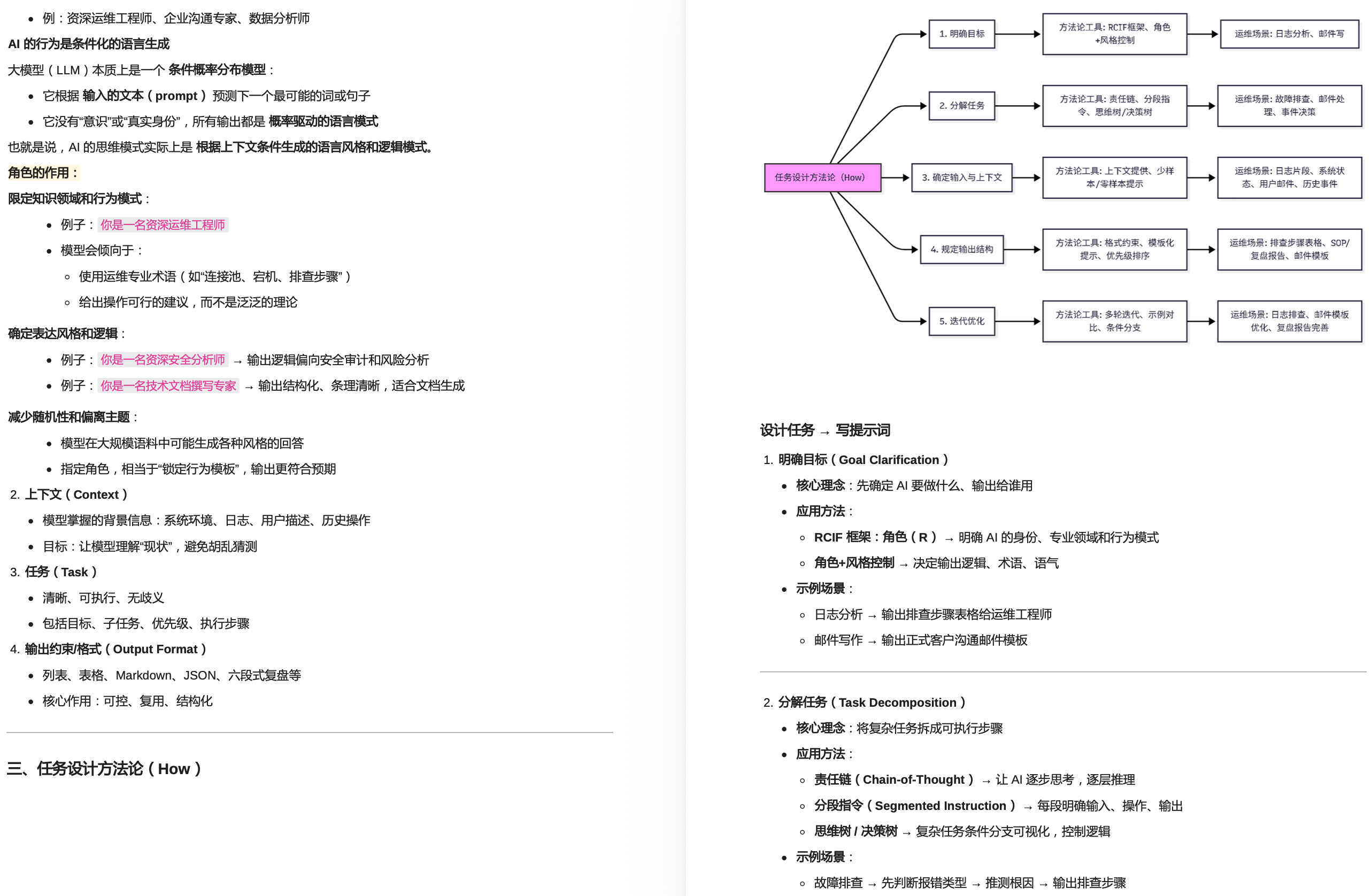
LLM基础与模型部署
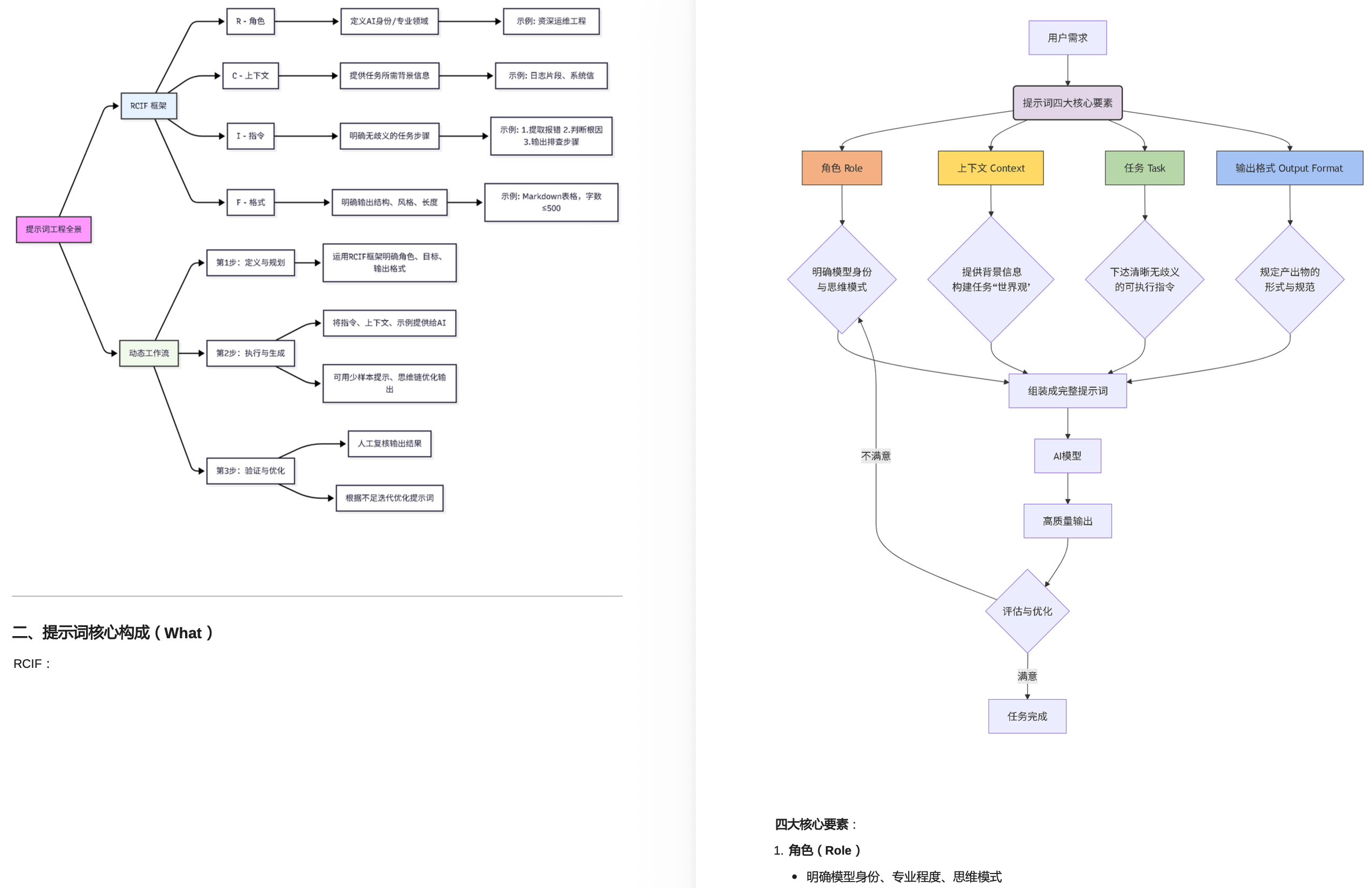
1.1 LLM Transformer架构与工作原理 Transformer架构、注意力机制、训练与推理流程
1.2 主流LLM及其特点 GPT、BERT、LLaMA、ChatGLM等模型的优势与适用场景
小模型的部署
2.1 小模型的选择与使用场景:轻量级模型在资源受限环境中的优势
2.2 Docker/GPU-CPU模型部署技术栈:Docker、资源分配、模型加载
运维数据整理
3.1 数据收集与管理的最佳实践
3.2 运维数据的分类与标注
3.3 构建高质量的训练数据集
实操练习
ChatGLM2-6B/LLaMA3-8B环境搭建与模型部署:容器化部署轻量级开源模型
运维数据处理:收集示例日志、分类与标注,为后续分析准备高质量数据集
输出成果:小组生成基础模型部署与数据整理报告
总结与课后作业
课程总结:回顾LLM架构、模型部署和运维数据管理
课后作业:提交一份部署小模型并整理自有日志数据的报告
第2课:LLM在运维中的应用
课程目标
掌握LLM在日志分析、故障诊断与预防性维护中的应用
能够使用LLM生成诊断报告和维护建议
实训方案
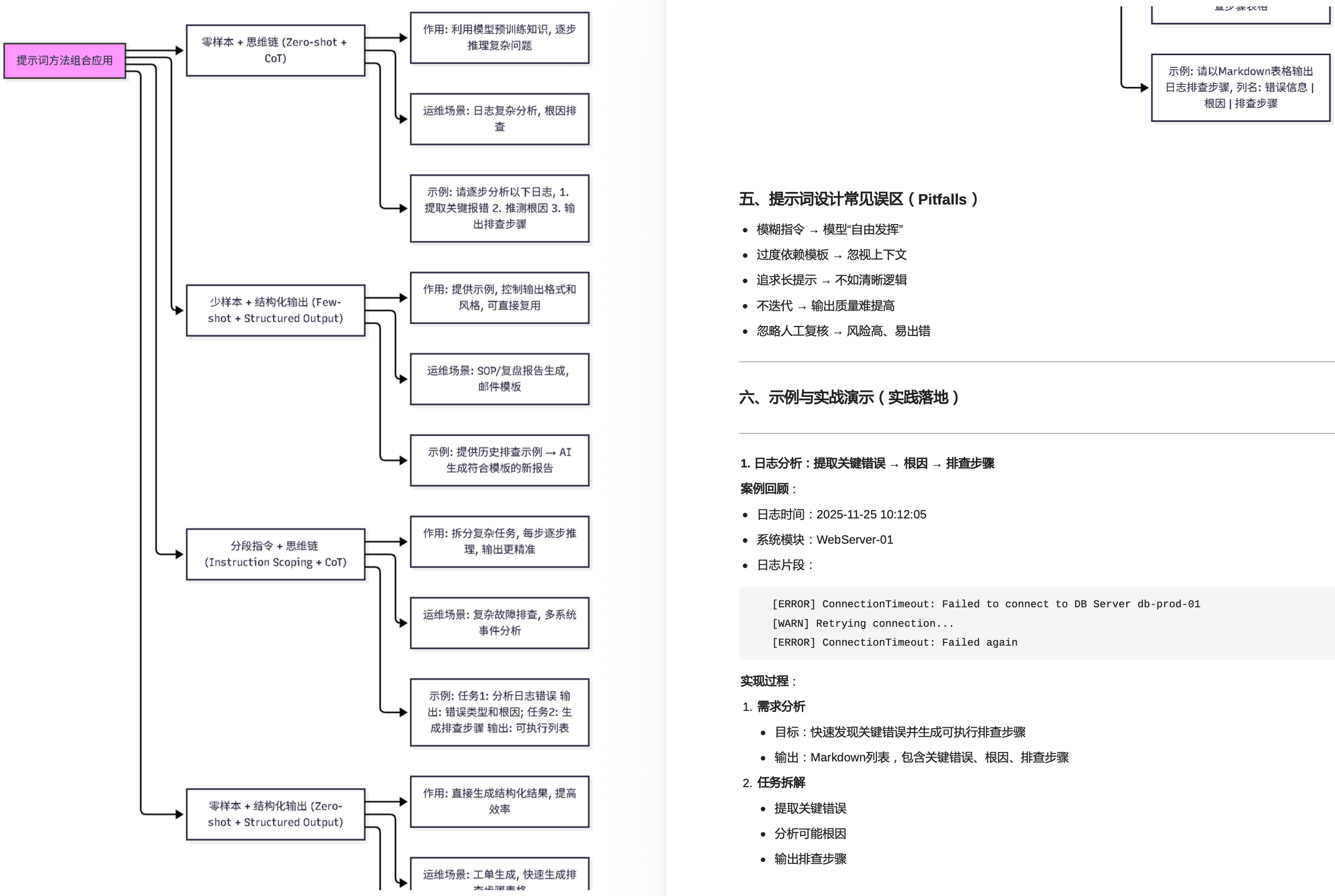
LLM在运维中的应用
日志分析与故障诊断
4.1 日志分析的必要性与挑战
4.2 LLM在日志分析中的应用
故障模式识别与分析
自动生成故障诊断报告
故障诊断与预防性维护
5.1 LLM在故障预测中的应用:历史数据分析生成预测模型、实时监控与告警系统集成
5.2 预防性维护建议生成:根据故障模式生成维护计划、经验知识库的构建与利用
LLM网络安全中的应用
6.1 恶意流量检测:LLM自动识别恶意流量特征、实时监控与响应机制设计
6.2 安全日志分析:LLM在安全事件识别中的应用
实操练习
LLM日志异常检测与分析:使用LLM识别异常日志模式并分类
故障诊断报告生成:输出故障定位报告与预防性维护计划
安全事件模拟:分析日志并生成安全事件响应报告
总结与课后作业
课程总结:强调LLM在运维诊断与安全中的价值
课后作业:提交基于时序监控数据或安全日志的故障预测与安全事件分析报告
第3课:性能优化与自动化运维
课程目标
掌握LLM在性能优化和自动化运维中的应用
能够生成运维脚本、自动化文档,并设计资源调度方案
实训方案
性能优化与自动化运维
性能优化
7.1 性能瓶颈分析:LLM在性能分析中的角色、生成性能瓶颈识别报告
7.2 资源调度优化:LLM基于数据生成最优资源调度方案
自动化运维
8.1 自动化脚本生成:LLM生成常见运维脚本、自动生成安全事件报告与响应措施、自适应脚本设计与实施
8.2 自动化文档生成:运维文档标准化流程、自动更新与管理文档内容
实操练习
自动化脚本生成:根据自然语言任务生成可执行脚本
运维文档自动生成:生成标准化文档,并支持实时更新
输出成果:小组完成性能优化方案与自动化运维文档
课件节选


实训技术专家
陈老师 AI智算技术专家
CS硕士,高性能计算方向
研究方向:分布式计算、深度学习模型优化、GPU加速计算。
曾就职中国电⼦科技集团高性能计算研发工程师,一线智算厂商高性能AI Infra工程师,现就职TsingtaoAI公司AI框架及AI应用研发工程师。
专业领域
华为昇腾技术栈: 深入掌握华为昇腾AI计算平台,包括昇腾算子开发、HCCL集合通信优化、智算集群建设与性能调优。
智算集群建设与优化: 专注于大规模智算集群的设计、部署、设备选型、网络配置及系统集成,提升集群性能和稳定性。
深度学习与高性能计算: 研究和应用分布式训练框架、优化技术,进行大规模计算任务的高效处理。
网络与系统集成: 在复杂网络环境下进行系统集成,确保数据传输的高效性与系统的稳定性。
AI开发框架: 熟悉多种AI开发框架,包括NCE fabric、NCE insight fabric、MindX和ModelArts平台的高阶使用。
代表性项目经验
GFDX智算集群项目
负责内容: 主导智算集群的整体设计与交付,包括设备选型、系统集成和网络设备配置。负责优化集群性能以满足高负载计算需求。
实际项目交付经验: 成功实施了62.5P的智算集群交付,确保系统的高效能和稳定性。
首都在线智算集群项目
负责内容: 主导智算集群的设计与部署,负责设备选型、集群网络架构设计和HCCL集合通信的优化配置。
实际项目交付经验: 成功交付了80P的智算集群项目,实现了高效的数据处理和计算能力。
北京昇腾人工智能计算中心
负责内容: 智算集群项目的建设与交付,包括设备选型、系统集成、网络设备配置与调优,以及昇腾平台的算子开发与优化。
实际项目交付经验: 主导了100P的智算集群交付,显著提升了计算能力和系统性能,满足了大规模AI应用需求。
教学与培训经验
昇腾技术培训: 为多家企业和研究机构提供昇腾技术栈的定制化培训,涵盖昇腾算子开发、HCCL通信优化、智算集群建设等内容。
教学方法: 善于将复杂的理论知识与实际应用相结合,通过案例分析与实践操作,帮助学员在短时间内掌握核心技术,并能在实际项目中独立应用。
实训案例
某智算中心运维厂商:
1. IB网络
-IB网络的概述与原理
-IB网络的传输协议与数据传输原理
-深入讲解InfiniBand的传输协议,包括RC、UC和UD,并解释数据传输机制。
-描述IB网络的硬件架构,包括交换机、路由器、HCA和TCA等。
-IB网络的故障诊断与排除
-实操环节,教授如何诊断和解决IB网络中可能出现的问题。
· GPU架构与CUDA编程
-NVIDIA GPU架构与特性
-介绍GPU的基本概念和CUDA编程模型。
-提供CUDA编程的基础知识和入门指导。
-GPU内部结构与性能优化关键点
-分析GPU加速计算的实际案例,包括性能提升和应用场景。
-讲解如何优化CUDA程序的性能,以及CUDA生态系统中的各种工具和库。
-GPU加速计算与案例分析
-高级CUDA库与工具链详解
-性能优化与CUDA生态系统
· 算力集群规划与设计
-算力集群架构与设计
-软件栈设计与集群性能评估
-集群性能调优的高级技巧与实践
-集群性能调优
智算集群的开发调优-某运营商研发中心
昇腾算子开发相关
2. 常见错误码与问题排查
3. 自定义算子的调用与调试
4. 高阶融合算子实现方法
HCCL集合通信相关
5. HCCL常见错误码与处理方法
6. HCCL通信算法与算子开发
7. HCCL新特性与调优
昇腾智算集群网络设备管理
8. NSLB1.0和2.0方案实现细节
9. 端网协同机制
10. 集合通信建链与mpirun测试
华为AI开发框架与工具链
11. 华为CCAE与NCE系统使用
12. MindX与ModelArts框架使用
13. 昇腾环境适配的AI开发框架
基于华为昇腾的分布式训练技术咨询-某科研学术机构
利用 PyTorch DDP 在多 GPU 上并行训练 ResNet-18,加速 CIFAR-10 训练并保持高准确率。通过环境配置、数据分发与采样、模型分布式包装和自动梯度同步,实现高效训练。结合混合精度、梯度压缩和自适应批大小等策略,大幅减少通信开销、提升计算效率。针对分布式任务调度与容错机制进行深入探索,保障大规模训练的稳定性与可扩展性,提供了高效、易扩展的分布式深度学习解决方案。
张老师 AI运维资深技术专家
泰健科技CTO,《SRE原理与实践:构建高可靠性互联网应用》作者。
曾任虎牙资深运维专家和架构师,拥有20年软件开发、架构、运维、SRE经验。历任项目研发负责人、SRE负责人、架构师,事故管理委员会委员、基础保障部架构师委员会委员。
为虎牙基于微服务架构的直播业务、音视频业务、海外直播业务建立了稳定性保障体系,在混合多云架构、可观测性、预案、变更管控、AIOps等SRE领域有深入研究和丰富经验。多次担任虎牙“英雄联盟全球总决赛直播”稳定性保障负责人。
同时,他也是中国信通院分布式系统稳定性实验室高级技术专家,参与编写了信通院《信息系统稳定性保障能力建设指南》。《运维前线》一书的联合作者。多次参与GOPS、MSUP/EE、GDevops、Takintalks技术大会分享。
关于TsingtaoAI
TsingtaoAI企业实训业务线专注于提供LLM、具身智能、AIGC、智算和数据科学领域的企业实训服务,通过深入业务场景的案例实战和项目式实训,帮助企业应对AI转型中的技术挑战。其实训内容涵盖AI大模型开发、Prompt工程、数据分析与模型优化等最新前沿技术,并结合实际应用场景,如智能制造、医药健康、金融科技和智能驾驶等。通过案例式学习和PBL项目训练,TsingtaoAI能够精准满足企业技术团队的学习需求,提升员工的业务能力和实战水平,实现AI技术的高效落地,为企业创新和生产力提升提供强有力的支持。
同时,TsingtaoAI公司并不是一家单纯的实训机构,我们同样是一家AI产品开发公司,公司核心团队主要也都是由技术和产品人才构成,公司团队大部分成员在大模型时代之前就在从事AI产品相关的工作。公司在过去一年里,为10余家客户开发了AI相关的产品,涵盖医疗、教育、智能制造、人力资源等领域。相信我们在AI产品开发和客户服务的过程所形成的认知和方法论,能对贵司的需求有更深更细的洞察和理解,也能提供更深入业务肌理的“AI能力获得”。
举报/反馈
评论

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)