用 Qoder 开发大型项目的 8 个核心技巧
本文分享了作者团队使用Qoder开发大型云原生开源项目的实践经验。从最初采用VibeCoding模式导致代码质量不佳,到转向Spec-DrivenCoding(规范驱动编程)的成功实践,作者总结了八大心得:1)Prompt工程成为开发主力;2)精确描述需求;3)分阶段构建中间产物;4)预置上下文与约束;5)警惕上下文压缩失真;6)及时提交代码;7)从可测试代码开始;8)构建FVT测试集。作者强调,
大家好,我是莫源。今天我想从一个终端用户的角度,和大家分享我们在使用Qoder开发一个约2万行代码的大型云原生开源项目过程中踩过的“坑”,以及我们解决问题的一些方法。
从Vibe Coding到Spec-Driven Coding:一次认知的升级
首先谈谈最近比较火的Vibe Coding。我们团队很早就开始使用AI编程工具。从GitHub Copilot刚推出,到阿里内部“通义灵码”上线初期,我们就在用AI做代码补全、单元测试补充等工作。
最初,我们使用AI 编程主要用于存量项目的维护性任务,比如修复小问题、提升测试覆盖率。那时我们基本采用 Vibe Coding 模式:输入一段自然语言,在极小的上下文中让 AI 生成局部代码,完成简单的补齐或修改。这种方式在小任务场景下基本能解决问题。但今年当我们启动一个从零开始、规模较大的新项目时,继续沿用 Vibe Coding 就暴露出严重问题。
核心在于使用Vibe Coding 方式给到 Qoder 的输入信息太少,导致 Qoder 对问题的拆解与我们真实期望存在巨大偏差。如果前期依赖 Vibe Coding 生成整个项目,并让它持续写代码,最终产出的代码将无法维护。
我们开发这个开源项目的第一版正是用了 Vibe Coding。但写了一周左右就发现:代码结构混乱、逻辑高度耦合,既无法维护,也不敢上线生产。于是在尝试一周后,我们果断转向了 Spec-Driven Coding(规范驱动编程)。
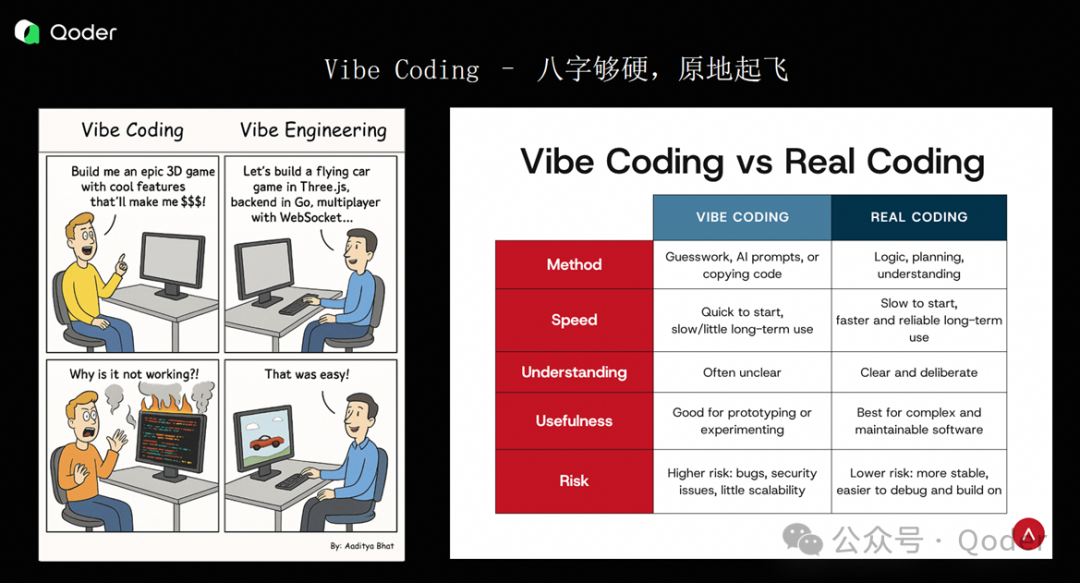
一句话总结我对 Vibe Coding 的观点:对于小型项目、工程脚本或对 SLA 要求不高的场景,Vibe Coding 是足够的;但对于规模超过三千行、需对代码质量负责、可能引发生产故障的系统,我不建议使用 Vibe Coding,应尽可能采用 Spec-Driven Coding。
刚接触 Vibe Coding 时,很多程序员会感到兴奋,仿佛自己从“乙方”变成了“甲方”——只需把需求抛给 AI,它就能自动交付代码。但随着使用深入,我发现 AI 与我们的关系更像是你带的一个实习生或初级工程师,双方是在协同编程。你并没有变成甲方,而是多了一个“乙方”,你们共同作为乙方完成任务。
因为在与 AI 协同的过程中,很多事情仍需我们主动去做。回想传统的软件开发生命周期(SDLC),我们需要明确需求分析、问题定义、接口设计、实体划分、参数规范、风险边界等内容。这些必须经过团队讨论、评审,形成明确结论后,才能进入开发阶段。
Vibe Coding 相当于跳过了整个流程;而 Spec-Driven Coding 只是加速了流程中的每个环节。
当前很多人讨论 AI 编程工具时,常说“这个工具适合这个场景,那个工具适合另一个场景”。但我觉得,核心问题不在于工具本身,而在于我们是否掌握了使用 AI 的策略和方法。
举个例子:同样是做一个网站,不同提示词(Prompt)产生的结果完全不同。如果某个 AI 工具针对特定场景做了提示词优化,效果自然更好。因此,我建议大家在 AI 编程中,把精力更多放在提示词工程和上下文工程上,而不是依赖工具本身的领域优化。
当我们把 Spec-Driven Coding 看作“带一个实习生一起写生产级代码”时,就必须思考一个问题:我们对 AI 的信任度到底有多高?
我的真实体感是:“总有刁民想害朕。”——写着写着,总担心 AI 在代码里埋了坑。如果不仔细审查,很多问题会非常难调试。接下来我会通过一个具体案例来说明这一点。
开发大型云原生开源项目沉淀的Qoder交互的八大心得
项目介绍:
我们开发的项目是为 Kubernetes 社区的 Karpenter 工具提供阿里云 Provider。
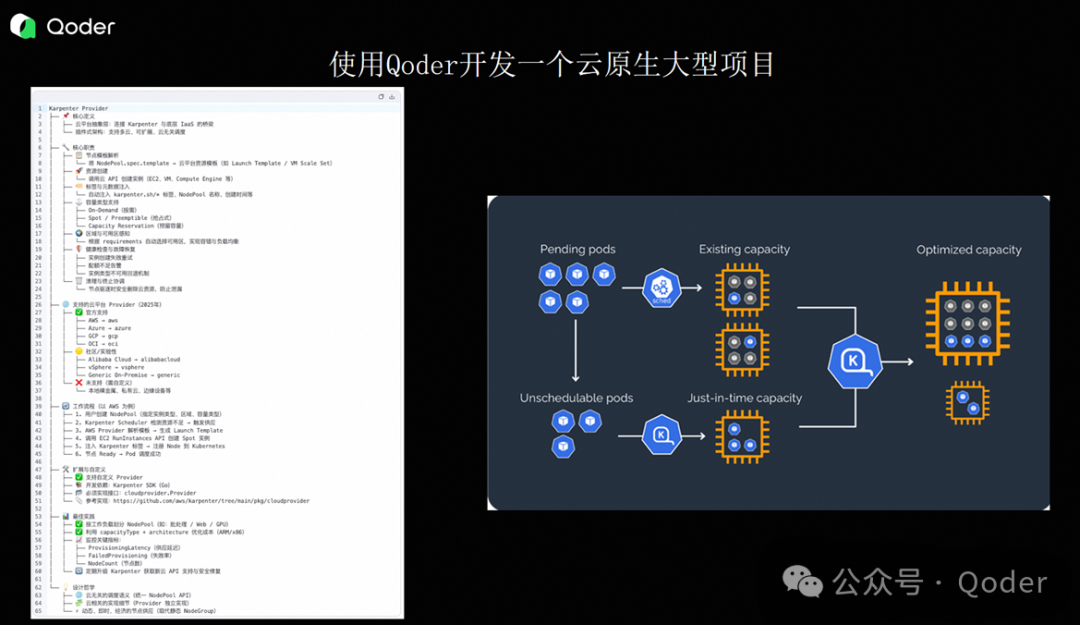
Karpenter 是一个弹性伸缩组件:当集群中某个 Pod 处于 Pending 状态时,它会通过模拟调度,调用云厂商的 API(如计算、存储、网络资源)动态创建所需资源,从而完成调度闭环。
该项目由 AWS 发起,后被 CNCF 社区接纳为孵化项目。阿里云与 Kubernetes 社区协商后,负责实现对应的云 Provider。
这个项目有几个显著挑战:
-
涉及大量云 API 调用;
-
需严格遵循社区定义的接口规范;
-
项目较新,主流 AI 模型对其几乎“一无所知”。
如果你直接告诉 AI:“帮我开发一个 Karpenter 的阿里云 Provider”,它很可能开始“瞎编”。正因如此,我们在开发初期遇到了大量不稳定现象。所以通过这个项目,我沉淀出与Qoder交互的八个具体的实践心得:
技巧一、写代码的时间大幅压缩,但 Prompt 工程成为主力
因为我们最开始是用 Vibe Coding 的方式来做这个项目,所以一开始遇到了非常多效果不稳定的现象。
在传统工程项目中,我们写代码的时间大概占 60% 左右,剩下的 30% 左右会花在测试和文档编写上。但如果我们使用 Spec-Driven Coding 的方式,实际手写代码的时间大概只有 5% 左右。那超过 30% 的时间花在哪儿了呢?是改 Prompt、改 Spec、构建上下文——目的就是让 AI 能在更符合我们预期的情况下输出代码。
在 Qoder 里面,我们会用到 Quest Mode 和 Ask Mode。这两种模式面向不同的使用场景。比如,Quest Mode 我可能会用来解决一些框架层面的问题:项目的整体工程结构、实体的定义、接口的设计,或者一个大模块的整体实现。而对于一些小的修正,比如参数变更、上下游文件的联动修改、某个小功能方法的抽象,我可能会用 Ask Mode。
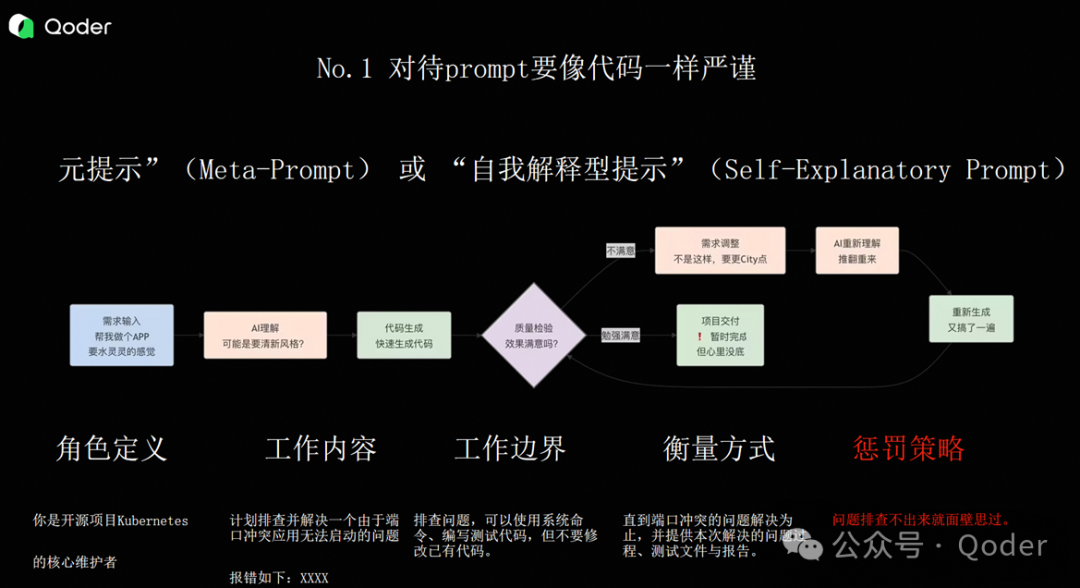
但不管用哪一种方式,和大模型沟通时,我们都严格遵守一种叫“自解释式提示”的原则,如下:
-
角色的定义。这里我想分享一个小技巧:很多人会把角色定义得很抽象,比如“你是一个程序员”。但我们在开发这个项目时,会把它定义得非常具体,比如“你是一个 Kubernetes 开源项目的维护者”。这样就把 AI 的参考范围局限在一个很小的领域里,它生成的代码和参考依据就会更精准。
-
明确工作内容。这个工作内容必须包含足够的上下文。比如你要解决一个问题,可能需要把相关的代码片段、错误日志贴出来,说明上下文关联在哪里。如果你用的是 Ask Mode,一定要记得在那个“+”号的地方勾选出它所涉及的上下文文件。
-
工作边界。为什么要强调工作边界?因为如果你用过早期的“通义灵码”或者 GitHub Copilot,会有非常强烈的体感:AI 总是在动你不希望它动的代码。它可能会跨很多个文件去修改一个东西,而那个修改范围和你认为该改的地方完全不同。所以很多时候我们在做 AI Coding 时,一定要把工作边界讲清楚:什么东西能改,什么东西不能改。
-
衡量标准。之前有同学提到,AI 写出来的代码有时候效果不太好,是不是得“PUA”它一下?那怎么 PUA 呢?我的经验是:你其实不用那么礼貌地跟 AI 沟通。你可以直接说:“你做不好就去罚站。”
-
通过量化的方法达到效果。比如用 Flyway 做数据库迁移,他明确了工具、明确了生产流程中的使用方法、明确了单元测试框架。这样你就可以定义具体的指标:比如“用 GoLand 实现整个项目的 lint 检查,使用 GUnit 做单元测试,覆盖率要达到 80%”。
有时候 Qoder 可能很简单就能达到效果。但我们采用这种方式,是为了保证在不同的 AI 模型、不同的 AI 工具之下,AI 的行为能尽可能保持一致。
技巧二、如何向 Qoder 描述需求——不能靠 AI 自己发散

第二个经验是:我们到底该怎么向 Qoder 描述自己的需求?
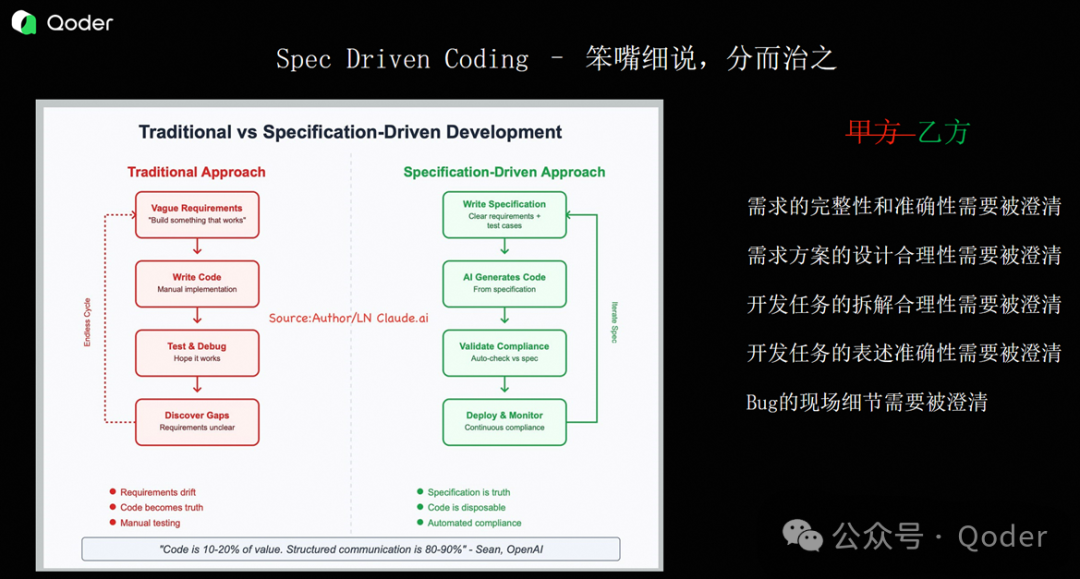
以前大家讲 AI Coding 的时候,经常是让 AI 自己去发散。比如我要做一个博客系统,我知道里面有网页、控制器、数据库,需求是明确的。但在我们这个场景下,面对的是一个完全未知的领域,你就必须把需求描述得非常清楚。
比如用 Markdown 文件来声明整个系统的设计。这种做法其实有点类似于 Quest Mode 里生成的中间内容。但我们这个项目不能直接用 Quest Mode 快速生成,核心原因在于 AI 根本不知道这个项目的“中台”到底长什么样。
那我们是怎么做的呢?幸运的是,AWS 在把项目提交进 CNCF 社区的时候,提供了一个 Sample Provider。这个 Sample 项目把所有该实现的东西都写好了,目的就是给其他云厂商的 Provider 提供参考:你可以照着这个模式,逐步生成你自己的 Provider。
所以我们做的第一件事,就是做了大量的预 Prompt 工程。简单理解就是:我们通过大模型,在前置阶段花了非常多的时间,去生成 Quest Mode 所需要的高质量 Prompt。
具体怎么做?
1、第一步,我们先把 Sample 代码用 Qoder 生成了一个 Repo Wiki,把整个项目拆解了一遍:到底有多少个实体、实体之间的调用关系是什么、定义了多少个接口、接口的参数是什么、约束条件有哪些等;
2、第二步,我们用 Quest Mode 对刚才生成的 Repo Wiki 做进一步分析,让它抽象出一份开发过程中所需要的设计文档和实现文档。这就相当于“分而治之”——我们先不让它写代码,而是让它根据已有项目,把核心的东西抽出来。抽完之后,我们得到了不同的文件,分别描述了:整体架构是什么样子、有哪些实体、有哪些接口、参数是什么、实体之间的调用关系、对应的测试要点、边界条件等等,非常清晰;
3、第三步,我们要注入上下文工程。为什么要这么做?我举个例子:比如我们要在云上驱动一台 ECS(或 EC2)的创建,就需要调用 OpenAPI。而 OpenAPI 是有版本的,不同版本的调用差异非常大。所以在 Qoder 里,我们利用它自带的上下文机制(Memory 机制),做了几件事:
-
把阿里云在这个项目中可能用到的 API 文档灌进去,告诉它:“我有这样一个 API,它的 spec 是这样的”;
-
把刚才生成的 Repo Wiki 也灌进去;
-
把最佳实践文档也灌进去。
这样,Qoder 就有了一个更清晰的上下文,再去生成 Prompt 时就会更准确。
最后一步,才是把刚才整体抽象出来的内容,生成一个完整的 Prompt,交给 Quest Mode 去生成代码。这就是我们在写 Prompt 之前做的“预 Prompt 工程”。
技巧三、分阶段使用 Quest Mode 构建中间产物
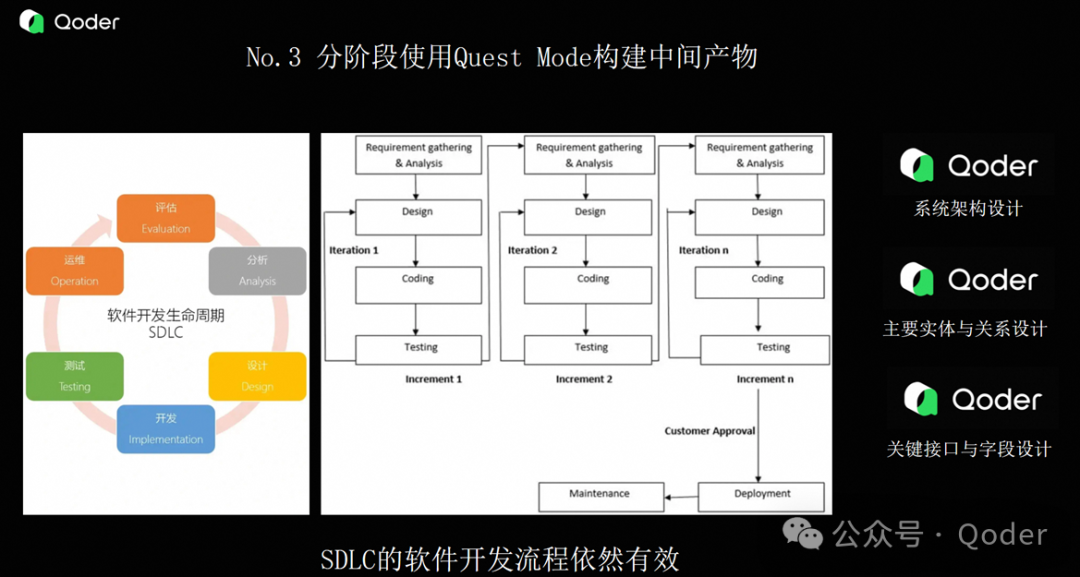
第三个经验是:我们要分阶段使用 Qoder 来构建中间产物。我们主要分成了三个阶段:
-
第一个阶段,是用 Qoder 的快速模式,第一次生成系统的整体架构设计。这一步主要是看 Qoder 在识别问题时,有没有和我们在大方向上出现出入。比如它对依赖框架的判断、对实体的分割、对目录结构的划分、对核心依赖库的选择,这些都是框架层的设计;
-
第二个阶段,是做实体和关系的设计;
-
第三个阶段,是做对应的接口和字段设计。
我们实际上是分三次使用 Quest Mode,逐步生成了一个中间的框架程序。最后才是基于这个框架,去进行代码的实际实现。
技巧四、编码时的上下文预置与约束
第四个经验,是关于编码时的上下文预制和约束。
在 Qoder 里,你可以通过它的位置去灌入一些上下文——可以是文档、代码仓库、URL 地址等。因为 Qoder 支持 MCP(Model Context Protocol),比如你可以把一个 GitHub 地址记下来,MCP 能调得到,那也是可以的。
有时候我们用 AI 编程时,它生成的代码风格是不连贯的。所以我们会在这个约束里设置一些规则,比如代码风格的约束、编译方式的约束、生成语言的倾向性约束(比如优先用 context 包,而不是全局变量)。
这些约束是全局的,相当于让它在整个代码生成过程中都必须遵守。用一句话总结就是:用规则去约束边界,用记忆去扩展边界。
技巧五、警惕上下文压缩带来的失真
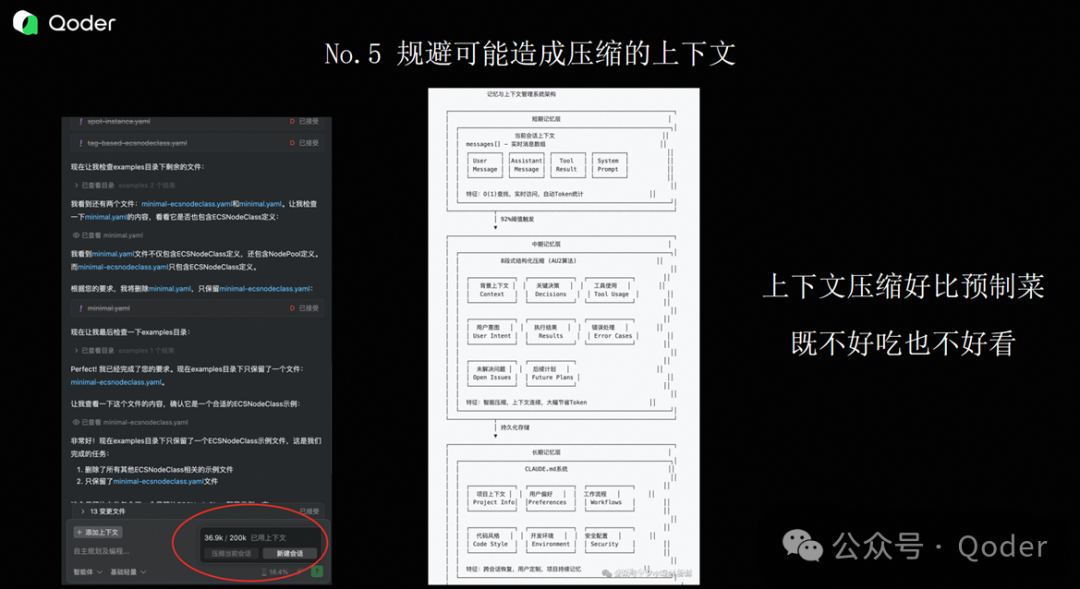
第五个经验,是关于上下文压缩的问题。
如果你用 Qoder 去调试或者开发比较大的代码,经常会遇到上下文不够用的情况。在 Qoder 界面右下角有一个百分比,表示你当前用了多少上下文。根据我的实际经验,当上下文使用率达到 70% 左右时,Qoder 就开始“胡说”了。
因为它可能会对上下文进行压缩,而这种压缩是有损的。这就好比一道菜,本来是现炒的,现在被做成预制菜装进袋子,再加热出来——味道和质感肯定变了。
所以我的个人经验是:当你解决一个问题时,不要永远在一个上下文里工作。解决这个问题用一个上下文,下一个问题就新开一个上下文,不要让上下文持续处于高压缩状态。
基本上我用到 50% 左右,就不会再继续用了,直接新开一个对话。如果一个问题解决不了,我就开一个新的上下文。否则一方面 Qoder 会反应特别慢,另一方面在压缩过程中生成的结果和效果也会变得很差。
技巧六、及时 Accept 文件并提交代码
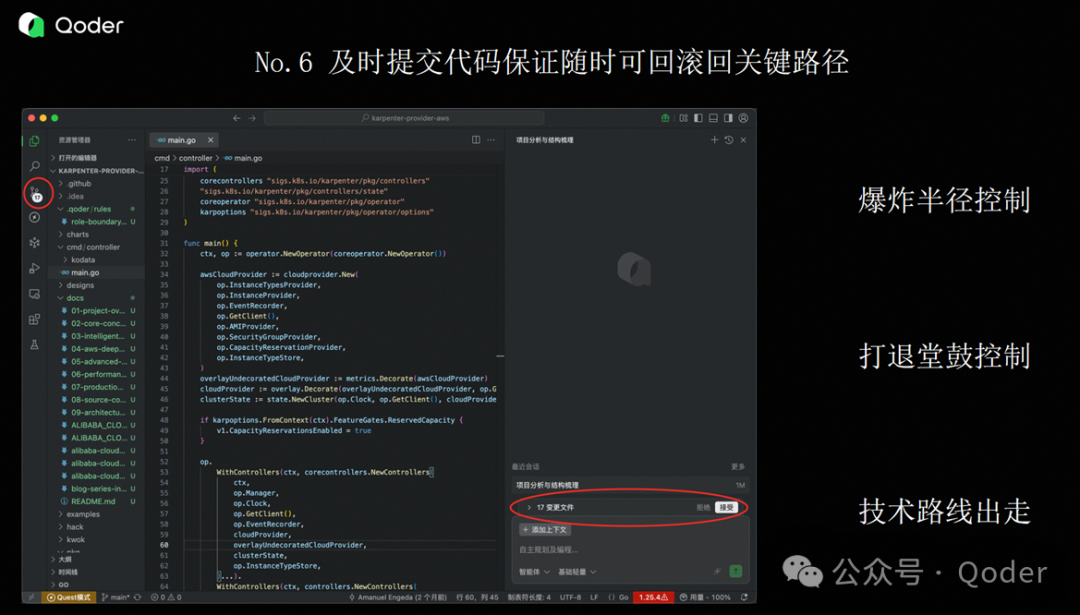
第六个经验,也是一个比较惨痛的教训:要及时 Accept 文件,并及时提交代码。
这里面主要有三个原因:
-
第一是控制爆炸半径。就算你用各种方式去限制边界,AI 有时候还是会改一些非预期的代码。如果你没有及时保存和提交,一旦出现问题,想要完整回滚就非常困难,很容易引入额外的问题。
-
第二是AI 有时候是个“国家级的打退堂鼓艺术家”。它在解决问题时,倾向于选择最简单、最容易得到结果的路径,但这个路径往往不是我们期望的解决方案。
经常会出现这样的现象:你让 AI 写一段代码,写到一半你觉得不错,结果它往下再走两步,发现有点难,就把前面所有写好的内容全删了。但我们可能希望的是:它写得不错的地方先留下来,后面难的部分我们手动介入。所以及时 Accept 非常关键。
-
第三是以前我们做开发时,换技术方案或实现方式成本很高,所以比较抵触。但用了 AI 之后,你会发现变更代码实现或调整技术路线变得非常容易。这时候,代码的“回复点”(即可回溯的提交点)就变得极其重要。只有这样,你才能基于一个良好的 codebase 去做技术路线的分叉。
技巧七、从“可测试的第一行代码”开始测试
第七个经验,我要讲一个比较惨痛的故事,这也是我们为什么在第一周就放弃 Vibe Coding 的原因。
当时我们用 Vibe Coding 直接生成了一个大概两万行的代码库。这段代码自己能编译通过,所以我们兴高采烈地去 debug 它——因为我们知道它一定有问题。
我们的项目需要连接远程的 Kubernetes 集群,去获取资源对象、调用 K8s API。结果项目刚跑起来,就报了一个错:“APIServer 的端口 Bad Descriptor”。
熟悉 K8s 的人可能会觉得,这肯定是配置问题:安全组没放通、网络不通、权限不足等,我们检查了一圈,都没问题。更奇怪的是,本地的 kubectl 能正常连通,但我们的代码却连不上。这就很迷惑了——本地能通,代码不能通,大概率说明代码实现有问题。
于是我们开始从头往下 debug。但因为代码量太大,你从头查起非常困难。你从来没有在一个“最小可行”的基础上验证过,而是直接面对一个两万行的 codebase,不确定问题到底出在哪。
我们排查了安全证书、网络连接,甚至怀疑是不是 FD(文件描述符)泄漏了——因为 “Bad Descriptor” 有时候意味着 FD 耗尽。我们还专门写了工具去监听 FD 泄露,监控资源使用情况,但也没发现问题。更诡异的是,机器重启后,代码又能跑了;过一会儿又不行了。
后来我让组里一个同学帮忙跑这段代码,结果在他的电脑上完全能跑。这个问题把我们整个团队卡了三天,抓包看到的是 connection reset,但代码怎么看都看不出问题。
最后定位的原因是:公司安全团队升级了策略,拦截了对外访问的某个 IP 段,而我们的代码恰好访问了那个 IP。
但你要知道,这三天我们的心理变化是什么:第一天觉得“AI 写得不错”,第二天就开始怀疑“AI 代码里全是坑”,到第三天已经完全不信任 AI 生成的任何代码了。
回头反思,核心问题是我们过早让 AI 生成了太多代码,却没有一个可测试的基础。如果这个问题是在第一天生成框架代码时就暴露出来,我们不会卡这么久。但当你面对一个两万行的 codebase 时,第一反应就是“肯定是 AI 写错了”。
所以我建议大家:在用 AI 写代码时,越早进入测试阶段就越友好。
技巧八、构建一套长期主义的 FVT 测试集
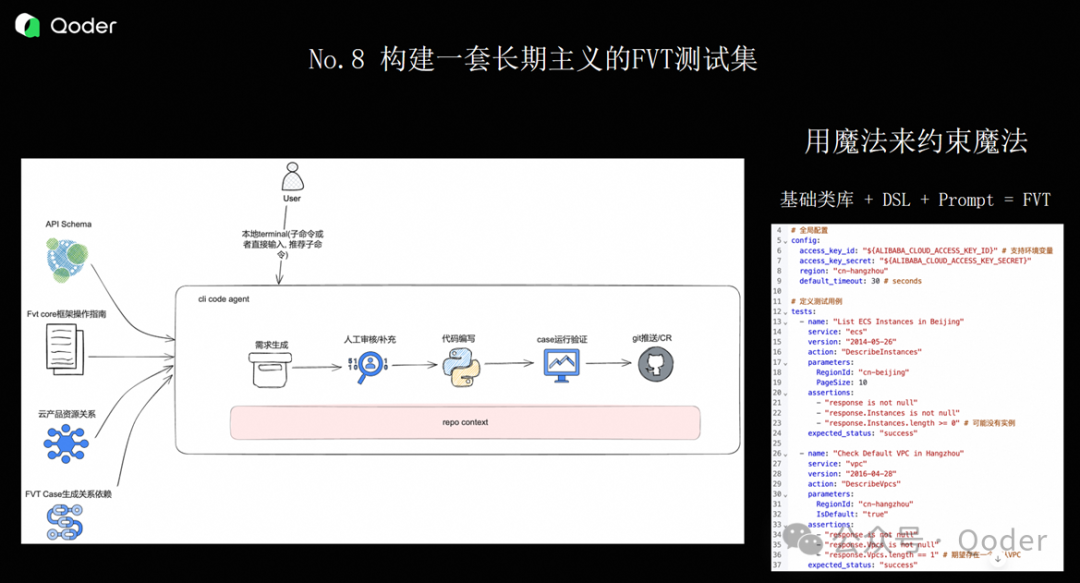
最后一个经验,是要构建一套长期主义的 FVT(Functional Verification Test)测试集。
为什么这么说?因为我们用 AI Coding 时,最终代码里可能有 80%、90% 都是 AI 写的。那单元测试能不能解决问题?单元测试解决不了。因为 AI 在写单元测试时,很少会帮你把大部分边界条件在“代码之外”考虑清楚。什么叫“代码之外”?比如你测试一个函数,它有入参、有出参,但它的边界条件是什么、哪些输入会导致异常等,这些很少有 AI 能补充完整。
第二,单一方法的正确性不代表功能的正确性。在这个场景下,我们更需要通过黑盒的、外置的功能性测试来保证整体功能可用。就像那句老话:“不管你是不是鸭子,只要你长得像鸭子、叫得像鸭子,我就认为你是鸭子。”FVT 的价值就体现在这里。
但写 FVT 的难点在于:单元测试有 codebase 可以参考,而 FVT 往往需要用人的语言去描述场景。
举个例子:我们的 FVT 场景是——Pod Pending 触发云上一台 ECS 的创建,然后把这个 Pod 调度上去,最后服务能正常拉起。这是一个标准的 FVT 流程。
但 AI 理解这个流程时,每次都有偏差。为什么?因为里面的很多词和底层功能是对不上的。
比如“生成一台 ECS”隐含了什么?地域 是什么、交换机是什么、网络插件是什么、磁盘大小是多少等,这些参数完全不同。如果你完全让 AI 自由发挥,它几乎不可能写对。
那我们是怎么解决的?我们定义了一套基础类库 + DSL + 通用 Prompt 的组合方案。
具体来说:
-
我们先预定义了 FVT 中需要用到的公共方法,比如“获取地域从哪里拿”“磁盘类型从哪里取”“测试用的 Pod 有哪些种类”;
-
然后在 DSL(领域特定语言)里,定义自然语言和底层代码的映射关系。比如“地域”对应 region,“存储大小”对应 diskSize;
-
最后基于这套标准化的 DSL,配合通用 Prompt,去生成 FVT 用例。
通过这种方式,我们生成的 FVT 效果比较可控,人在介入时对 AI 的依赖也大大减少。最终建立了一套覆盖度高、完成度好的功能性测试集。
结语:Qoder 已融入我的整个研发生命周期
我使用 Qoder 最大的感受是:我把 Qoder 当成了几个不同的角色。
-
IDE 插件:大家都会用;
-
Browser:我用它去查资料,并让它帮我整理成文档。比如我看一个开源项目时,会先让它生成 Repo Wiki,再找材料,最后生成一系列文章,这些文章是我每天会看的;
-
RSS:我把很多材料的收集和整理都交给它;
-
RPA:通过 MCP Server 去操作一些自动化流程。
可以说,Qoder 已经贯穿在我的整个日常研发生命周期里。
关注我,掌握Qoder最新动态


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)