w~大模型~合集10
GPT代表生成式预训练Transformer,是一种基于Transformer的神经网络结构。- 生成式(Generative):GPT生成文本。- 预训练(Pre-trained):GPT是根据书本、互联网等中的大量文本进行训练的。- Transformer:GPT是一种仅用于解码器的Transformer神经网络。大模型,如OpenAI的GPT-3、谷歌的LaMDA,以及Cohere的Comm
我自己的原文哦~ https://blog.51cto.com/whaosoft/12348844
#GPT~从0构建
GPT早已成为大模型时代的基础。国外一位开发者发布了一篇实践指南,仅用60行代码构建GPT。
60行代码,从头开始构建GPT?
最近,一位开发者做了一个实践指南,用Numpy代码从头开始实现GPT。
你还可以将 OpenAI发布的GPT-2模型权重加载到构建的GPT中,并生成一些文本。
话不多说,直接开始构建GPT。
什么是GPT?
GPT代表生成式预训练Transformer,是一种基于Transformer的神经网络结构。
- 生成式(Generative):GPT生成文本。
- 预训练(Pre-trained):GPT是根据书本、互联网等中的大量文本进行训练的。
- Transformer:GPT是一种仅用于解码器的Transformer神经网络。
大模型,如OpenAI的GPT-3、谷歌的LaMDA,以及Cohere的Command XLarge,背后都是GPT。它们的特别之处在于, 1) 非常大(拥有数十亿个参数),2) 受过大量数据(数百GB的文本)的训练。
直白讲,GPT会在提示符下生成文本。
即便使用非常简单的API(输入=文本,输出=文本),一个训练有素的GPT也可以做一些非常棒的事情,比如写邮件,总结一本书,为Instagram发帖提供想法,给5岁的孩子解释黑洞,用SQL编写代码,甚至写遗嘱。
以上就是 GPT 及其功能的高级概述。让我们深入了解更多细节。
输入/输出
GPT定义输入和输出的格式大致如下所示:
def gpt(inputs: list[int]) -> list[list[float]]:
# inputs has shape [n_seq]
# output has shape [n_seq, n_vocab]
output = # beep boop neural network magic
return output输入是由映射到文本中的token的一系列整数表示的一些文本:
# integers represent tokens in our text, for example:# text = "not all heroes wear capes":# tokens = "not" "all" "heroes" "wear" "capes"
inputs = [1, 0, 2, 4, 6]Token是文本的子片段,使用分词器生成。我们可以使用词汇表将token映射到整数:
# the index of a token in the vocab represents the integer id for that token# i.e. the integer id for "heroes" would be 2, since vocab[2] = "heroes"
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
# a pretend tokenizer that tokenizes on whitespace
tokenizer = WhitespaceTokenizer(vocab)
# the encode() method converts a str -> list[int]
ids = tokenizer.encode("not all heroes wear") # ids = [1, 0, 2, 4]# we can see what the actual tokens are via our vocab mapping
tokens = [tokenizer.vocab[i] for i in ids] # tokens = ["not", "all", "heroes", "wear"]# the decode() method converts back a list[int] -> str
text = tokenizer.decode(ids) # text = "not all heroes wear"简而言之:
- 有一个字符串。
- 使用分词器将其分解成称为token的小块。
- 使用词汇表将这些token映射为整数。
在实践中,我们会使用更先进的分词方法,而不是简单地用空白来分割,比如字节对编码(BPE)或WordPiece,但原理是一样的:
vocab将字符串token映射为整数索引
encode方法,可以转换str -> list[int]
decode 方法,可以转换 list[int] -> str ([2])
输出
输出是一个二维数组,其中 output[i][j] 是模型预测的概率,即 vocab[j] 处的token是下一个tokeninputs[i+1] 。例如:
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[0] = [0.75 0.1 0.0 0.15 0.0 0.0 0.0 ]
# given just "not", the model predicts the word "all" with the highest probability
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[1] = [0.0 0.0 0.8 0.1 0.0 0.0 0.1 ]
# given the sequence ["not", "all"], the model predicts the word "heroes" with the highest probability
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[-1] = [0.0 0.0 0.0 0.1 0.0 0.05 0.85 ]
# given the whole sequence ["not", "all", "heroes", "wear"], the model predicts the word "capes" with the highest probability要获得整个序列的下一个token预测,我们只需获取 output[-1] 中概率最高的token:
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
next_token_id = np.argmax(output[-1]) # next_token_id = 6
next_token = vocab[next_token_id] # next_token = "capes"将概率最高的token作为我们的预测,称为贪婪解码(Greedy Decoding)或贪婪采样(greedy sampling)。
预测序列中的下一个逻辑词的任务称为语言建模。因此,我们可以将GPT称为语言模型。
生成一个单词很酷,但整个句子、段落等又如何呢?
生成文本
自回归
我们可以通过迭代从模型中获得下一个token预测来生成完整的句子。在每次迭代中,我们将预测的token追加回输入:
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # auto-regressive decode loop
output = gpt(inputs) # model forward pass
next_id = np.argmax(output[-1]) # greedy sampling
inputs.append(int(next_id)) # append prediction to input
return inputs[len(inputs) - n_tokens_to_generate :] # only return generated ids
input_ids = [1, 0] # "not" "all"
output_ids = generate(input_ids, 3) # output_ids = [2, 4, 6]
output_tokens = [vocab[i] for i in output_ids] # "heroes" "wear" "capes"这个预测未来值(回归)并将其添加回输入(自)的过程,就是为什么你可能会看到GPT被描述为自回归的原因。
采样
我们可以从概率分布中采样,而不是贪婪采样,从而为生成的引入一些随机性:
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # hats
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # pants这样,我们就能在输入相同内容的情况下生成不同的句子。
如果与top-k、top-p和温度等在采样前修改分布的技术相结合,我们的输出质量就会大大提高。
这些技术还引入了一些超参数,我们可以利用它们来获得不同的生成行为(例如,提高温度会让我们的模型承担更多风险,从而更具「创造性」)。
训练
我们可以像训练其他神经网络一样,使用梯度下降法训练GPT,并计算损失函数。对于GPT,我们采用语言建模任务的交叉熵损失:
def lm_loss(inputs: list[int], params) -> float:
# the labels y are just the input shifted 1 to the left
#
# inputs = [not, all, heros, wear, capes]
# x = [not, all, heroes, wear]
# y = [all, heroes, wear, capes]
#
# of course, we don't have a label for inputs[-1], so we exclude it from x
#
# as such, for N inputs, we have N - 1 langauge modeling example pairs
x, y = inputs[:-1], inputs[1:]
# forward pass
# all the predicted next token probability distributions at each position
output = gpt(x, params)
# cross entropy loss
# we take the average over all N-1 examples
loss = np.mean(-np.log(output[y]))
return loss
def train(texts: list[list[str]], params) -> float:
for text in texts:
inputs = tokenizer.encode(text)
loss = lm_loss(inputs, params)
gradients = compute_gradients_via_backpropagation(loss, params)
params = gradient_descent_update_step(gradients, params)
return params这是一个经过大量简化的训练设置,但可以说明问题。
请注意,我们在gpt函数签名中添加了params (为了简单起见,我们在前面的章节中没有添加)。在训练循环的每一次迭代期间:
- 对于给定的输入文本实例,计算了语言建模损失
- 损失决定了我们通过反向传播计算的梯度
- 我们使用梯度来更新我们的模型参数,以使损失最小化(梯度下降)
请注意,我们不使用显式标记的数据。相反,我们能够仅从原始文本本身生成输入/标签对。这被称为自监督学习。
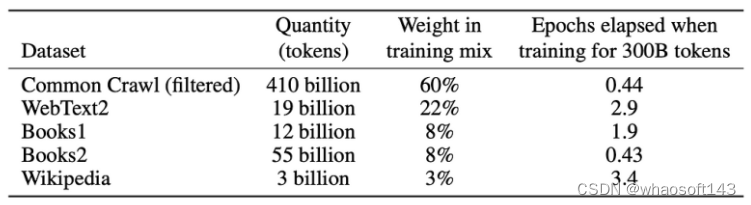
自监督使我们能够大规模扩展训练数据,只需获得尽可能多的原始文本并将其投放到模型中。例如,GPT-3接受了来自互联网和书籍的3000亿个文本token的训练:
当然,你需要一个足够大的模型才能从所有这些数据中学习,这就是为什么GPT-3有1750亿个参数,训练的计算成本可能在100万至1000万美元之间。
这个自监督的训练步骤被称为预训练,因为我们可以重复使用「预训练」的模型权重来进一步训练模型的下游任务。预训练的模型有时也称为「基础模型」。
在下游任务上训练模型称为微调,因为模型权重已经经过了理解语言的预训练,只是针对手头的特定任务进行了微调。
「一般任务的前期训练+特定任务的微调」策略被称为迁移学习。
提示
原则上,最初的GPT论文只是关于预训练Transformer模型用于迁移学习的好处。
论文表明,当对标记数据集进行微调时,预训练的117M GPT在各种自然语言处理任务中获得了最先进的性能。
直到GPT-2和GPT-3论文发表后,我们才意识到,基于足够的数据和参数预训练的GPT模型,本身能够执行任何任务,不需要微调。
只需提示模型,执行自回归语言建模,然后模型就会神奇地给出适当的响应。这就是所谓的「上下文学习」(in-context learning),因为模型只是利用提示的上下文来完成任务。
语境中学习可以是0次、一次或多次。
在给定提示的情况下生成文本也称为条件生成,因为我们的模型是根据某些输入生成一些输出的。
GPT并不局限于NLP任务。
你可以根据你想要的任何条件来微调这个模型。比如,你可以将GPT转换为聊天机器人(如ChatGPT),方法是以对话历史为条件。
说到这里,让我们最后来看看实际的实现。
设置
克隆本教程的存储库:
git clone https://github.com/jaymody/picoGPT
cd picoGPT然后安装依赖项:
pip install -r requirements.txt注意:这段代码是用Python 3.9.10测试的。
每个文件的简单分类:
- encoder.py包含OpenAI的BPE分词器的代码,这些代码直接取自gpt-2 repo。
- utils.py包含下载和加载GPT-2模型权重、分词器和超参数的代码。- gpt2.py包含实际的GPT模型和生成代码,我们可以将其作为python脚本运行。- gpt2_pico.py与gpt2.py相同,但代码行数更少。
我们将从头开始重新实现gpt2.py ,所以让我们删除它并将其重新创建为一个空文件:
rm gpt2.py
touch gpt2.py首先,将以下代码粘贴到gpt2.py中:
import numpy as np
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head):
pass # TODO: implement this
def generate(inputs, params, n_head, n_tokens_to_generate):
from tqdm import tqdm
for _ in tqdm(range(n_tokens_to_generate), "generating"): # auto-regressive decode loop
logits = gpt2(inputs, **params, n_head=n_head) # model forward pass
next_id = np.argmax(logits[-1]) # greedy sampling
inputs.append(int(next_id)) # append prediction to input
return inputs[len(inputs) - n_tokens_to_generate :] # only return generated ids
def main(prompt: str, n_tokens_to_generate: int = 40, model_size: str = "124M", models_dir: str = "models"):
from utils import load_encoder_hparams_and_params
# load encoder, hparams, and params from the released open-ai gpt-2 files
encoder, hparams, params = load_encoder_hparams_and_params(model_size, models_dir)
# encode the input string using the BPE tokenizer
input_ids = encoder.encode(prompt)
# make sure we are not surpassing the max sequence length of our model
assert len(input_ids) + n_tokens_to_generate < hparams["n_ctx"]
# generate output ids
output_ids = generate(input_ids, params, hparams["n_head"], n_tokens_to_generate)
# decode the ids back into a string
output_text = encoder.decode(output_ids)
return output_text
if __name__ == "__main__":
import fire
fire.Fire(main)将4个部分分别分解为:
- gpt2函数是我们将要实现的实际GPT代码。你会注意到,除了inputs之外,函数签名还包括一些额外的内容:
wte、 wpe、 blocks和ln_f是我们模型的参数。
n_head是前向传递过程中需要的超参数。
- generate函数是我们前面看到的自回归解码算法。为了简单起见,我们使用贪婪抽样。tqdm是一个进度条,帮助我们可视化解码过程,因为它一次生成一个token。
- main函数处理:
加载分词器(encoder)、模型权重(params)和超参数(hparams)
使用分词器将输入提示编码为token ID
调用生成函数
将输出ID解码为字符串
fire.Fire(main)只是将我们的文件转换为CLI应用程序,因此我们最终可以使用python gpt2.py "some prompt here"运行代码
让我们更详细地了解一下笔记本中的encoder 、 hparams和params,或者在交互式的Python会话中,运行:
from utils import load_encoder_hparams_and_params
encoder, hparams, params = load_encoder_hparams_and_params("124M", "models")这将把必要的模型和分词器文件下载到models/124M ,并将encoder、 hparams和params加载到我们的代码中。
编码器
encoder是GPT-2使用的BPE分词器:
ids = encoder.encode("Not all heroes wear capes.")
ids
[3673, 477, 10281, 5806, 1451, 274, 13]
encoder.decode(ids)
"Not all heroes wear capes."使用分词器的词汇表(存储在encoder.decoder中),我们可以看到实际的token是什么样子的:
[encoder.decoder[i] for i in ids]
['Not', 'Ġall', 'Ġheroes', 'Ġwear', 'Ġcap', 'es', '.']请注意,我们的token有时是单词(例如Not),有时是单词但前面有空格(例如Ġall,Ġ表示空格),有时是单词的一部分(例如Capes分为Ġcap和es),有时是标点符号(例如.)。
BPE的一个优点是它可以对任意字符串进行编码。如果它遇到词汇表中没有的内容,它只会将其分解为它能够理解的子字符串:
[encoder.decoder[i] for i in encoder.encode("zjqfl")]
['z', 'j', 'q', 'fl']我们还可以检查词汇表的大小:
len(encoder.decoder)
50257词汇表以及确定如何拆分字符串的字节对合并是通过训练分词器获得的。
当我们加载分词器时,我们从一些文件加载已经训练好的单词和字节对合并,当我们运行load_encoder_hparams_and_params时,这些文件与模型文件一起下载。
超参数
hparams是一个包含我们模型的超参数的词典:
>>> hparams
{
"n_vocab": 50257, # number of tokens in our vocabulary
"n_ctx": 1024, # maximum possible sequence length of the input
"n_embd": 768, # embedding dimension (determines the "width" of the network)
"n_head": 12, # number of attention heads (n_embd must be divisible by n_head)
"n_layer": 12 # number of layers (determines the "depth" of the network)
}我们将在代码的注释中使用这些符号来显示事物的基本形状。我们还将使用n_seq表示输入序列的长度(即n_seq = len(inputs))。
参数
params是一个嵌套的json字典,它保存我们模型的训练权重。Json的叶节点是NumPy数组。我们会得到:
import numpy as np
def shape_tree(d):
if isinstance(d, np.ndarray):
return list(d.shape)
elif isinstance(d, list):
return [shape_tree(v) for v in d]
elif isinstance(d, dict):
return {k: shape_tree(v) for k, v in d.items()}
else:
ValueError("uh oh")
print(shape_tree(params))
{
"wpe": [1024, 768],
"wte": [50257, 768],
"ln_f": {"b": [768], "g": [768]},
"blocks": [
{
"attn": {
"c_attn": {"b": [2304], "w": [768, 2304]},
"c_proj": {"b": [768], "w": [768, 768]},
},
"ln_1": {"b": [768], "g": [768]},
"ln_2": {"b": [768], "g": [768]},
"mlp": {
"c_fc": {"b": [3072], "w": [768, 3072]},
"c_proj": {"b": [768], "w": [3072, 768]},
},
},
... # repeat for n_layers
]
}这些是从原始OpenAI TensorFlow检查点加载的:
import tensorflow as tf
tf_ckpt_path = tf.train.latest_checkpoint("models/124M")
for name, _ in tf.train.list_variables(tf_ckpt_path):
arr = tf.train.load_variable(tf_ckpt_path, name).squeeze()
print(f"{name}: {arr.shape}")
model/h0/attn/c_attn/b: (2304,)
model/h0/attn/c_attn/w: (768, 2304)
model/h0/attn/c_proj/b: (768,)
model/h0/attn/c_proj/w: (768, 768)
model/h0/ln_1/b: (768,)
model/h0/ln_1/g: (768,)
model/h0/ln_2/b: (768,)
model/h0/ln_2/g: (768,)
model/h0/mlp/c_fc/b: (3072,)
model/h0/mlp/c_fc/w: (768, 3072)
model/h0/mlp/c_proj/b: (768,)
model/h0/mlp/c_proj/w: (3072, 768)
model/h1/attn/c_attn/b: (2304,)
model/h1/attn/c_attn/w: (768, 2304)
...
model/h9/mlp/c_proj/b: (768,)
model/h9/mlp/c_proj/w: (3072, 768)
model/ln_f/b: (768,)
model/ln_f/g: (768,)
model/wpe: (1024, 768)
model/wte: (50257, 768)下面的代码将上述TensorFlow变量转换为我们的params词典。
作为参考,以下是params的形状,但用它们所代表的hparams替换了数字:
import tensorflow as tf
tf_ckpt_path = tf.train.latest_checkpoint("models/124M")
for name, _ in tf.train.list_variables(tf_ckpt_path):
arr = tf.train.load_variable(tf_ckpt_path, name).squeeze()
print(f"{name}: {arr.shape}")
model/h0/attn/c_attn/b: (2304,)
model/h0/attn/c_attn/w: (768, 2304)
model/h0/attn/c_proj/b: (768,)
model/h0/attn/c_proj/w: (768, 768)
model/h0/ln_1/b: (768,)
model/h0/ln_1/g: (768,)
model/h0/ln_2/b: (768,)
model/h0/ln_2/g: (768,)
model/h0/mlp/c_fc/b: (3072,)
model/h0/mlp/c_fc/w: (768, 3072)
model/h0/mlp/c_proj/b: (768,)
model/h0/mlp/c_proj/w: (3072, 768)
model/h1/attn/c_attn/b: (2304,)
model/h1/attn/c_attn/w: (768, 2304)
...
model/h9/mlp/c_proj/b: (768,)
model/h9/mlp/c_proj/w: (3072, 768)
model/ln_f/b: (768,)
model/ln_f/g: (768,)
model/wpe: (1024, 768)
model/wte: (50257, 768)基本层
在我们进入实际的GPT体系结构本身之前,最后一件事是,让我们实现一些非特定于GPT的更基本的神经网络层。
GELU
GPT-2选择的非线性(激活函数)是GELU(高斯误差线性单元),它是REU的替代方案:
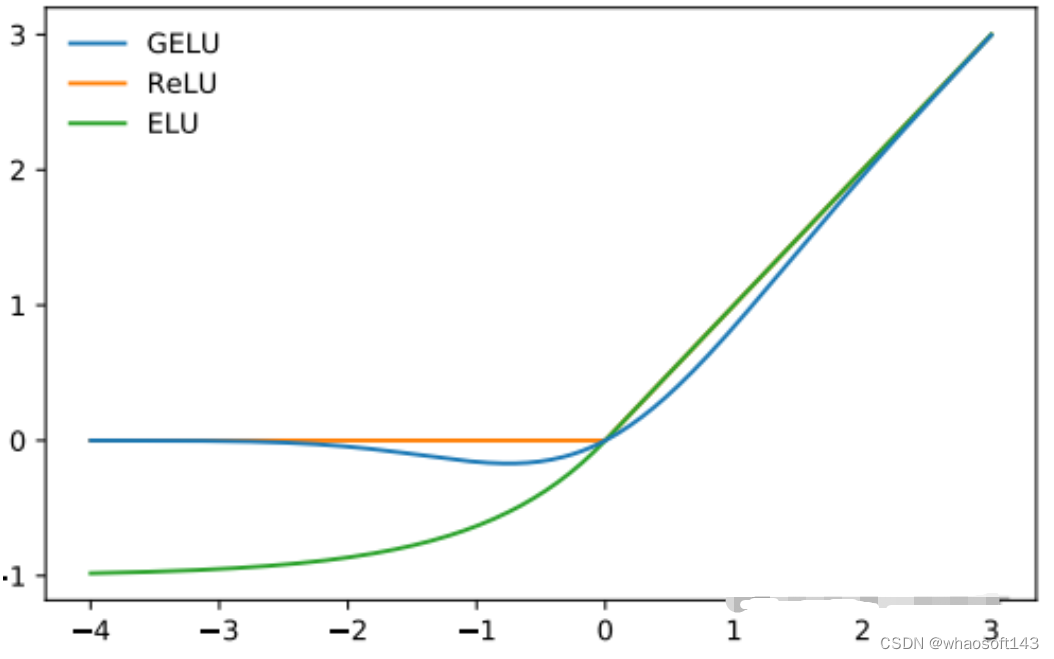
它由以下函数近似表示:
def gelu(x):
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))与RELU类似,Gelu在输入上按元素操作:
gelu(np.array([[1, 2], [-2, 0.5]]))
array([[ 0.84119, 1.9546 ],
[-0.0454 , 0.34571]])Softmax
Good ole softmax:
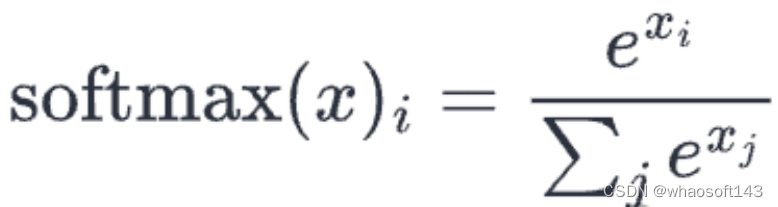
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)我们使用max(x)技巧来保证数值稳定性。
SoftMax用于将一组实数(介于−∞和∞之间)转换为概率(介于0和1之间,所有数字的总和为1)。我们在输入的最后一个轴上应用softmax 。
x = softmax(np.array([[2, 100], [-5, 0]]))
x
array([[0.00034, 0.99966],
[0.26894, 0.73106]])
x.sum(axis=-1)
array([1., 1.])层归一化
层归一化将值标准化,使其平均值为0,方差为1:
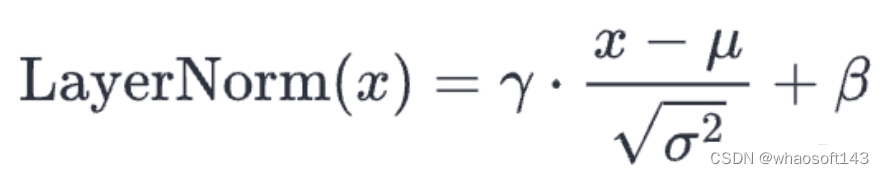
def layer_norm(x, g, b, eps: float = 1e-5):
mean = np.mean(x, axis=-1, keepdims=True)
variance = np.var(x, axis=-1, keepdims=True)
x = (x - mean) / np.sqrt(variance + eps) # normalize x to have mean=0 and var=1 over last axisreturn g * x + b # scale and offset with gamma/beta params层归一化确保每一层的输入始终在一致的范围内,这会加快和稳定训练过程。
与批处理归一化一样,归一化输出随后被缩放,并使用两个可学习向量gamma和beta进行偏移。分母中的小epsilon项用于避免除以零的误差。
由于种种原因,Transformer采用分层定额代替批量定额。
我们在输入的最后一个轴上应用层归一化。
>>> x = np.array([[2, 2, 3], [-5, 0, 1]])
>>> x = layer_norm(x, g=np.ones(x.shape[-1]), b=np.zeros(x.shape[-1]))
>>> x
array([[-0.70709, -0.70709, 1.41418],
[-1.397 , 0.508 , 0.889 ]])
>>> x.var(axis=-1)
array([0.99996, 1. ]) # floating point shenanigans
>>> x.mean(axis=-1)
array([-0., -0.])
Linear你的标准矩阵乘法+偏差:
def linear(x, w, b): # [m, in], [in, out], [out] -> [m, out]
return x @ w + b线性层通常称为映射(因为它们从一个向量空间映射到另一个向量空间)。
>>> x = np.random.normal(size=(64, 784)) # input dim = 784, batch/sequence dim = 64
>>> w = np.random.normal(size=(784, 10)) # output dim = 10
>>> b = np.random.normal(size=(10,))
>>> x.shape # shape before linear projection
(64, 784)
>>> linear(x, w, b).shape # shape after linear projection
(64, 10)GPT架构
GPT架构遵循Transformer的架构:
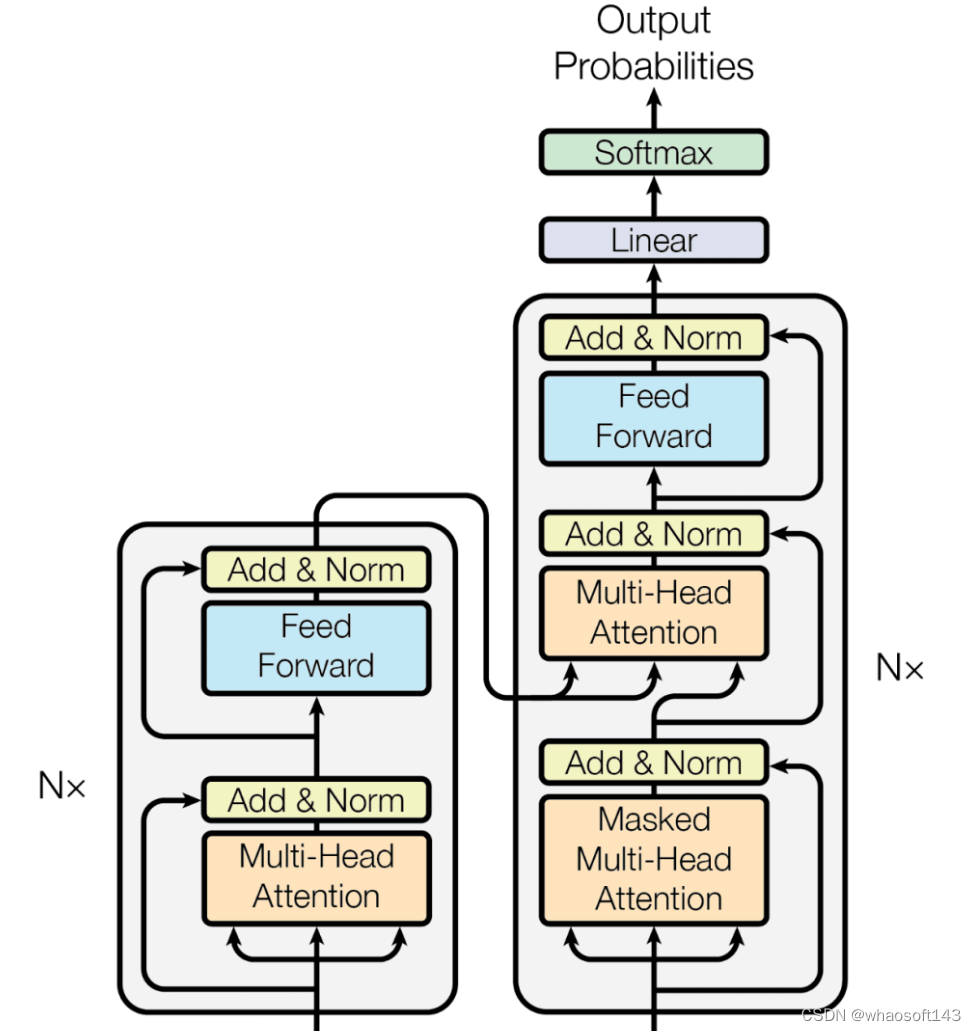
从高层次上讲,GPT体系结构有三个部分:
文本+位置嵌入
一种transformer解码器堆栈
向单词步骤的映射
在代码中,它如下所示:
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head): # [n_seq] -> [n_seq, n_vocab]
# token + positional embeddings
x = wte[inputs] + wpe[range(len(inputs))] # [n_seq] -> [n_seq, n_embd]
# forward pass through n_layer transformer blocks
for block in blocks:
x = transformer_block(x, **block, n_head=n_head) # [n_seq, n_embd] -> [n_seq, n_embd]
# projection to vocab
x = layer_norm(x, **ln_f) # [n_seq, n_embd] -> [n_seq, n_embd]
return x @ wte.T # [n_seq, n_embd] -> [n_seq, n_vocab]把所有放在一起
把所有这些放在一起,我们得到了gpt2.py,它总共只有120行代码(如果删除注释和空格,则为60行)。
我们可以通过以下方式测试我们的实施:
python gpt2.py \"Alan Turing theorized that computers would one day become" \
--n_tokens_to_generate 8它给出了输出:
the most powerful machines on the planet.它成功了!
我们可以使用下面的Dockerfile测试我们的实现与OpenAI官方GPT-2 repo的结果是否一致。
docker build -t "openai-gpt-2" "https://gist.githubusercontent.com/jaymody/9054ca64eeea7fad1b58a185696bb518/raw/Dockerfile"
docker run -dt "openai-gpt-2" --name "openai-gpt-2-app"
docker exec -it "openai-gpt-2-app" /bin/bash -c 'python3 src/interactive_conditional_samples.py --length 8 --model_type 124M --top_k 1'
# paste "Alan Turing theorized that computers would one day become" when prompted这应该会产生相同的结果:
the most powerful machines on the planet.下一步呢?
这个实现很酷,但它缺少很多花哨的东西:
GPU/TPU支持
将NumPy替换为JAX:
import jax.numpy as np你现在可以使用代码与GPU,甚至TPU!只需确保正确安装了JAX即可。
反向传播
同样,如果我们用JAX替换NumPy:
import jax.numpy as np然后,计算梯度就像以下操作一样简单:
def lm_loss(params, inputs, n_head) -> float:
x, y = inputs[:-1], inputs[1:]
output = gpt2(x, **params, n_head=n_head)
loss = np.mean(-np.log(output[y]))return loss
grads = jax.grad(lm_loss)(params, inputs, n_head)
Batching再一次,如果我们用JAX替换NumPy:
import jax.numpy as np然后,对gpt2函数进行批处理非常简单:
gpt2_batched = jax.vmap(gpt2, in_axes=[0, None, None, None, None, None])
gpt2_batched(batched_inputs) # [batch, seq_len] -> [batch, seq_len, vocab]推理优化
我们的实现效率相当低。你可以进行的最快、最有效的优化(在GPU+批处理支持之外)将是实现KV缓存。
训练
训练GPT对于神经网络来说是相当标准的(梯度下降是损失函数)。
当然,在训练GPT时,你还需要使用标准的技巧包(例如,使用ADAM优化器、找到最佳学习率、通过辍学和/或权重衰减进行正则化、使用学习率调度器、使用正确的权重初始化、批处理等)。
训练一个好的GPT模型的真正秘诀是调整数据和模型的能力,这才是真正的挑战所在。
对于缩放数据,你需要一个大、高质量和多样化的文本语料库。
- 大意味着数十亿个token(TB级的数据)。
- 高质量意味着您想要过滤掉重复的示例、未格式化的文本、不连贯的文本、垃圾文本等。
- 多样性意味着不同的序列长度,关于许多不同的主题,来自不同的来源,具有不同的视角等等。
评估
如何评价一个LLM,这是一个很难的问题。
停止生成
当前的实现要求我们提前指定要生成的token的确切数量。这并不是一个好方法,因为我们生成的token最终会过长、过短或在句子中途中断。
为了解决这个问题,我们可以引入一个特殊的句尾(EOS)标记。
在预训练期间,我们将EOS token附加到输入的末尾(即tokens = ["not", "all", "heroes", "wear", "capes", ".", "<|EOS|>"])。
在生成期间,只要我们遇到EOS token(或者如果我们达到了某个最大序列长度),就会停止:
def generate(inputs, eos_id, max_seq_len):
prompt_len = len(inputs)while inputs[-1] != eos_id and len(inputs) < max_seq_len:
output = gpt(inputs)
next_id = np.argmax(output[-1])
inputs.append(int(next_id))return inputs[prompt_len:]GPT-2没有预训练EOS token,所以我们不能在我们的代码中使用这种方法。
无条件生成
使用我们的模型生成文本需要我们使用提示符对其进行条件调整。
但是,我们也可以让我们的模型执行无条件生成,即模型在没有任何输入提示的情况下生成文本。
这是通过在预训练期间将特殊的句子开始(BOS)标记附加到输入开始(即tokens = ["<|BOS|>", "not", "all", "heroes", "wear", "capes", "."])来实现的。
然后,要无条件地生成文本,我们输入一个只包含BOS token的列表:
def generate_unconditioned(bos_id, n_tokens_to_generate):
inputs = [bos_id]for _ in range(n_tokens_to_generate):
output = gpt(inputs)
next_id = np.argmax(output[-1])
inputs.append(int(next_id))return inputs[1:]GPT-2预训练了一个BOS token(名称为<|endoftext|>),因此使用我们的实现无条件生成非常简单,只需将以下行更改为:
input_ids = encoder.encode(prompt) if prompt else [encoder.encoder["<|endoftext|>"]]然后运行:
python gpt2.py ""这将生成:
The first time I saw the new version of the game, I was so excited. I was so excited to see the new version of the game, I was so excited to see the new version因为我们使用的是贪婪采样,所以输出不是很好(重复),而且是确定性的(即,每次我们运行代码时都是相同的输出)。为了得到质量更高且不确定的生成,我们需要直接从分布中抽样(理想情况下,在应用类似top-p的方法之后)。
无条件生成并不是特别有用,但它是展示GPT能力的一种有趣的方式。
微调
我们在训练部分简要介绍了微调。回想一下,微调是指当我们重新使用预训练的权重来训练模型执行一些下游任务时。我们称这一过程为迁移学习。
从理论上讲,我们可以使用零样本或少样本提示,来让模型完成我们的任务,
然而,如果你可以访问token的数据集,微调GPT将产生更好的结果(在给定更多数据和更高质量的数据的情况下,结果可以扩展)。
有几个与微调相关的不同主题,我将它们细分如下:
分类微调
在分类微调中,我们给模型一些文本,并要求它预测它属于哪一类。
例如,以IMDB数据集为例,它包含将电影评为好或差的电影评论:
--- Example 1 ---
Text: I wouldn't rent this one even on dollar rental night.
Label: Bad
--- Example 2 ---
Text: I don't know why I like this movie so well, but I never get tired of watching it.
Label: Good
--- Example 3 ---
...为了微调我们的模型,我们将语言建模头替换为分类头,并将其应用于最后一个token输出:
def gpt2(inputs, wte, wpe, blocks, ln_f, cls_head, n_head):
x = wte[inputs] + wpe[range(len(inputs))]
for block in blocks:
x = transformer_block(x, **block, n_head=n_head)
x = layer_norm(x, **ln_f)
# project to n_classes
# [n_embd] @ [n_embd, n_classes] -> [n_classes]
return x[-1] @ cls_head我们只使用最后一个token输出x[-1],因为我们只需要为整个输入生成单一的概率分布,而不是语言建模中的n_seq分布。
尤其,我们采用最后一个token,因为最后一个token是唯一被允许关注整个序列的token,因此具有关于整个输入文本的信息。
像往常一样,我们优化了w.r.t.交叉熵损失:
def singe_example_loss_fn(inputs: list[int], label: int, params) -> float:
logits = gpt(inputs, **params)
probs = softmax(logits)
loss = -np.log(probs[label]) # cross entropy loss
return loss我们还可以通过应用sigmoid而不是softmax来执行多标签分类,并获取关于每个类别的二进制交叉熵损失。
生成式微调
有些任务不能被整齐地归类。例如,总结这项任务。
我们只需对输入和标签进行语言建模,就能对这类任务进行微调。例如,下面是一个总结训练样本:
--- Article ---
This is an article I would like to summarize.
--- Summary ---
This is the summary.我们像在预训练中一样训练模型(优化w.r.t语言建模损失)。
在预测时间,我们向模型提供直到--- Summary ---的所有内容,然后执行自回归语言建模以生成摘要。
分隔符--- Article ---和--- Summary ---的选择是任意的。如何选择文本的格式由你自己决定,只要它在训练和推理之间保持一致。
注意,我们还可以将分类任务制定为生成式任务(例如使用IMDB):
--- Text ---
I wouldn't rent this one even on dollar rental night.
--- Label ---
Bad指令微调
如今,大多数最先进的大模型在经过预寻来你后,还会经历额外的指令微调。
在这一步中,模型对数千个人类标记的指令提示+完成对进行了微调(生成)。指令微调也可以称为有监督的微调,因为数据是人为标记的。
那么,指令微调有什么好处呢?
虽然预测维基百科文章中的下一个单词能让模型擅长续写句子,但这并不能让它特别擅长遵循指令、进行对话或总结文档(我们希望GPT能做的所有事情)。
在人类标注的指令+完成对上对其进行微调,是一种教模型如何变得更有用,并使其更易于交互的方法。
这就是所谓的AI对齐,因为我们正在对模型进行对齐,使其按照我们的意愿行事。

参数高效微调
当我们在上述章节中谈到微调时,假定我们正在更新所有模型参数。
虽然这能产生最佳性能,但在计算(需要对整个模型进行反向传播)和存储(每个微调模型都需要存储一份全新的参数副本)方面成本高昂。
解决这个问题最简单的方法就是只更新头部,冻结(即无法训练)模型的其他部分。
虽然这可以加快训练速度,并大大减少新参数的数量,但效果并不是特别好,因为我们失去了深度学习的深度。
相反,我们可以选择性地冻结特定层,这将有助于恢复深度。这样做的结果是,效果会好很多,但我们的参数效率会降低很多,也会失去一些训练速度的提升。
值得一提的是,我们还可以利用参数高效的微调方法。
以Adapters 一文为例。在这种方法中,我们在transformer块中的FFN和MHA层之后添加一个额外的「适配器」层。
适配层只是一个简单的两层全连接神经网络,输入输出维度为 n_embd ,隐含维度小于 n_embd :
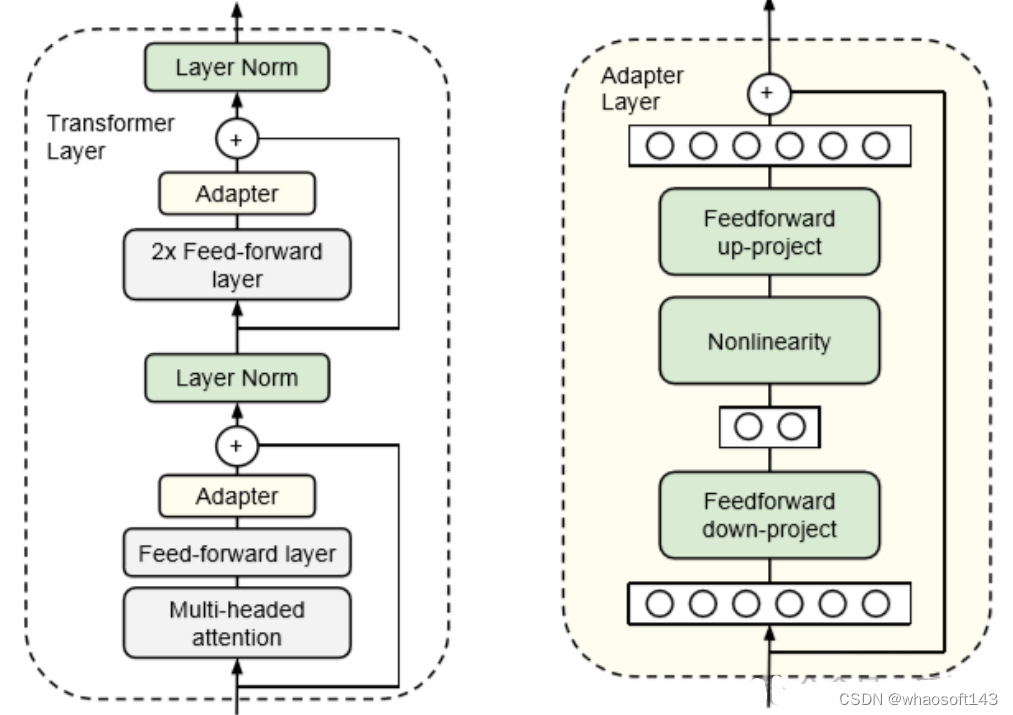
隐藏维度的大小是一个超参数,我们可以对其进行设置,从而在参数与性能之间进行权衡。
论文显示,对于BERT模型,使用这种方法可以将训练参数的数量减少到2%,而与完全微调相比,性能只受到很小的影响(<1%)。
参考资料:
https://twitter.com/ItakGol/status/1761852345502081327?t=MNOiF-cOqXG7jUesISmuXg&s=19
......
#xxx
......
#xxx
......
#xxx
......
#xxx
......
#FRESHLLM
LLM 能更新知识的话,还有谷歌搜索什么事?和谷歌搜索抢活,FRESHLLM「紧跟时事」,幻觉更少,信息更准
大型语言模型的能力有目共睹,如 BARD 和 CHATGPT/GPT-4,被设计成多功能开放域聊天机器人,可以就不同主题进行多轮对话。它们能够帮助人们完成诸多任务,但这并不代表它们是万能的。
「幻觉」与过时的信息降低了这些大模型回复的可信度。尤其对于需要信息实时更新的领域(如公司股价)而言,这更是严重。
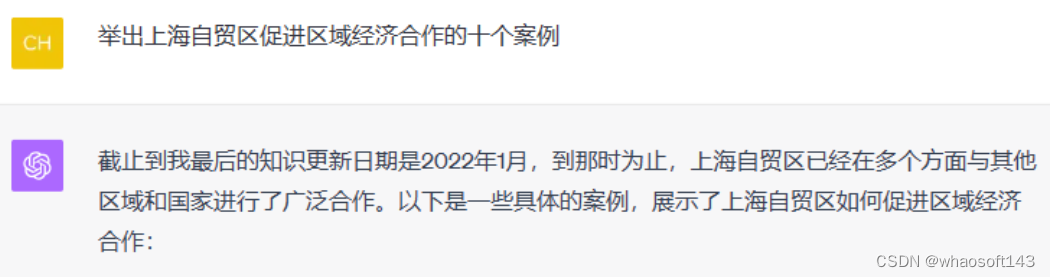
与 GPT-4 对话过程中,会发现它的信息更新有限制
这种现象可部分归因于其参数中存在编码的过时知识。虽然利用人类反馈或知识增强任务进行额外训练可以缓解这一问题,这种方法并不容易推广。另外,上下文学习是一种有吸引力的替代方法,可将实时知识注入 LLM 的提示中以生成条件。虽然近期的一些研究已经开始探索利用网络搜索结果来增强 LLM,但如何充分利用搜索引擎的输出来提高 LLM 的事实性尚不清楚。
在一篇最新的论文中,来自谷歌、马萨诸塞大学阿默斯特分校、OpenAI 的研究者发现,Perplexity 和 GPT-4 w/prompting 的性能优于谷歌搜索。同时,越来越多的非科技人员在搜索查询时使用 Perplexity 而不是其他 LLM。那么谷歌搜索真的会被 LLM 取代吗?
有网友表示,虽然在简单问题上,LLM 的表现更好,但是对于大模型的「幻觉」问题依然保持谨慎态度他们使用谷歌搜索验证大模型的回复。
其实,研究者也致力于解决大模型知识过时的问题。接下来,我们一起看看他们的成果。
论文地址:https://arxiv.org/pdf/2310.03214.pdf
FRESHQA 数据集
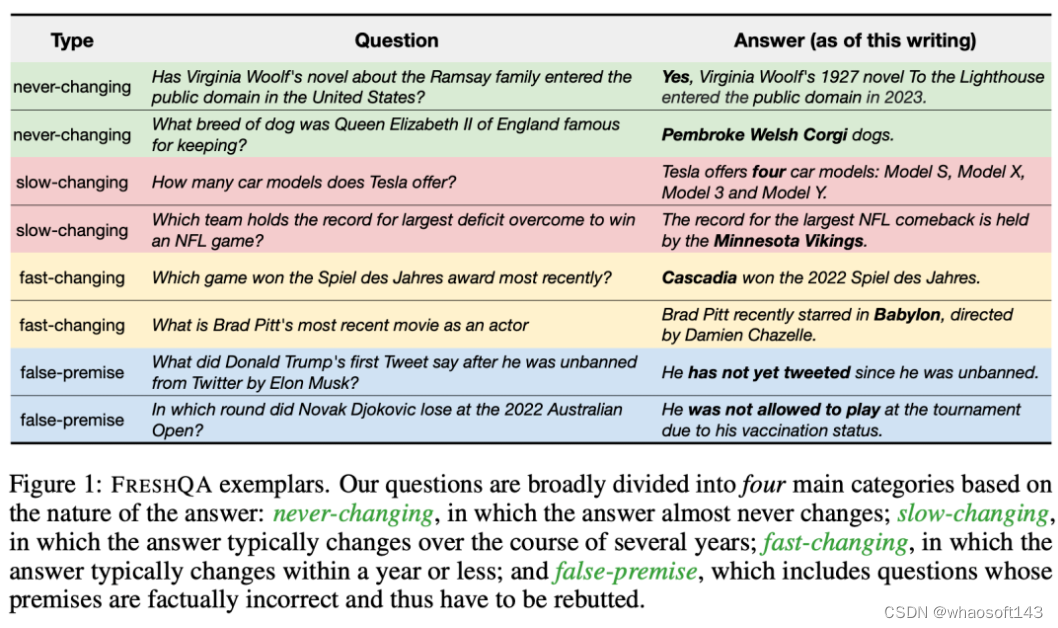
在这项工作中,研究者先是创建了一个名为「FRESHQA」的新型质量保证基准,用于评估现有 LLM 生成内容的事实性。FRESHQA 包含 600 个自然问题,大致分为图 1 所示的四大类。这些问题跨越了一系列不同的主题,具有不同的难度级别,并要求模型「理解」世界上的最新知识,以便能够正确回答。
此外,FRESHQA 还具有动态性:一些 ground-truth 答案可能会随着时间的推移而改变,被归入特定类别的问题可能会在以后的某个时间点被重新分类。就比如,「马斯克与现任配偶结婚多久了?」在当前是一个虚假推理问题,但如果马斯克在未来再次结婚,该问题被归入的类别就需要变一变了。
研究者招募了一些 NLP 研究人员(包括作者及其同事)和线上自由撰稿人来收集 FRESHQA 的数据。在四类问题中的每一类中,都要求注释者撰写两种不同难度的问题:一跳(one-hop),即问题明确提到了回答该问题所需的所有相关信息,因此不需要额外的推理(例如,谁是 Twitter 的首席执行官);多跳(multi-hop),即问题需要一个或多个额外的推理步骤才能收集到回答该问题所需的所有相关信息(例如,世界上最高建筑的总高度是多少?)
研究者通过向不同的 LLM 提出问题和一些问答示范,然后对其回答进行采样,以此来衡量它们在 FRESHQA 上的表现,然后对模型回答的事实准确性进行了广泛的人工评估,包括超过 50K 个判断。此处采用双模式评估程序对每个回答进行评估:「RELAXED」模式只衡量主要答案是否正确,「STRICT」模式则衡量回答中的所有说法是否都是最新的事实(即没有幻觉)。
这个评估过程揭示了新旧 LLM 的事实性,并揭示了不同问题类型带来的不同模型行为。不出所料,在涉及快速变化知识的问题上,会出现平坦的缩放曲线:简单地增加模型大小并不能带来可靠的性能提升。在假前提问题上,他们也观察到了类似的趋势。不过,如果明确询问「请在回答前检查问题是否包含有效前提」,一些 LLM 就能够揭穿假前提问题。
总体来说,FRESHQA 对当前的 LLM 来说确实是一个挑战,指出了很大的改进空间。
提示搜索引擎增强的语言模型
受到上述探索的启发,研究者进一步研究了如何通过将搜索引擎提供的准确和最新信息作为 LLM 响应的基础,有效提高 LLM 的事实性。鉴于大型 LLMS 的快速发展和知识不断变化的性质,研究者探索了上下文学习方法,使 LLM 能够通过其提示关注推理时提供的知识。
随后,研究者评估了 LLM 搜索引擎增强对 FRESHQA 的影响,并提出了一种简单的少样本提示方法 FRESHPROMPT。该方法通过将检索自搜索引擎(谷歌搜索)的最新相关信息整合到提示中,极大地提升了 LLM 的 FRESHQA 性能。
下图 3 为 FRESHPROMPT 的格式。

FRESHPROMPT 方法
FRESHPROMPT 方法利用一个文本提示来将来自搜索引擎的上下文相关的最新信息(包括相关问题的答案)引入到一个预训练 LLM,并教导该模型对检索到的证据进行推理。
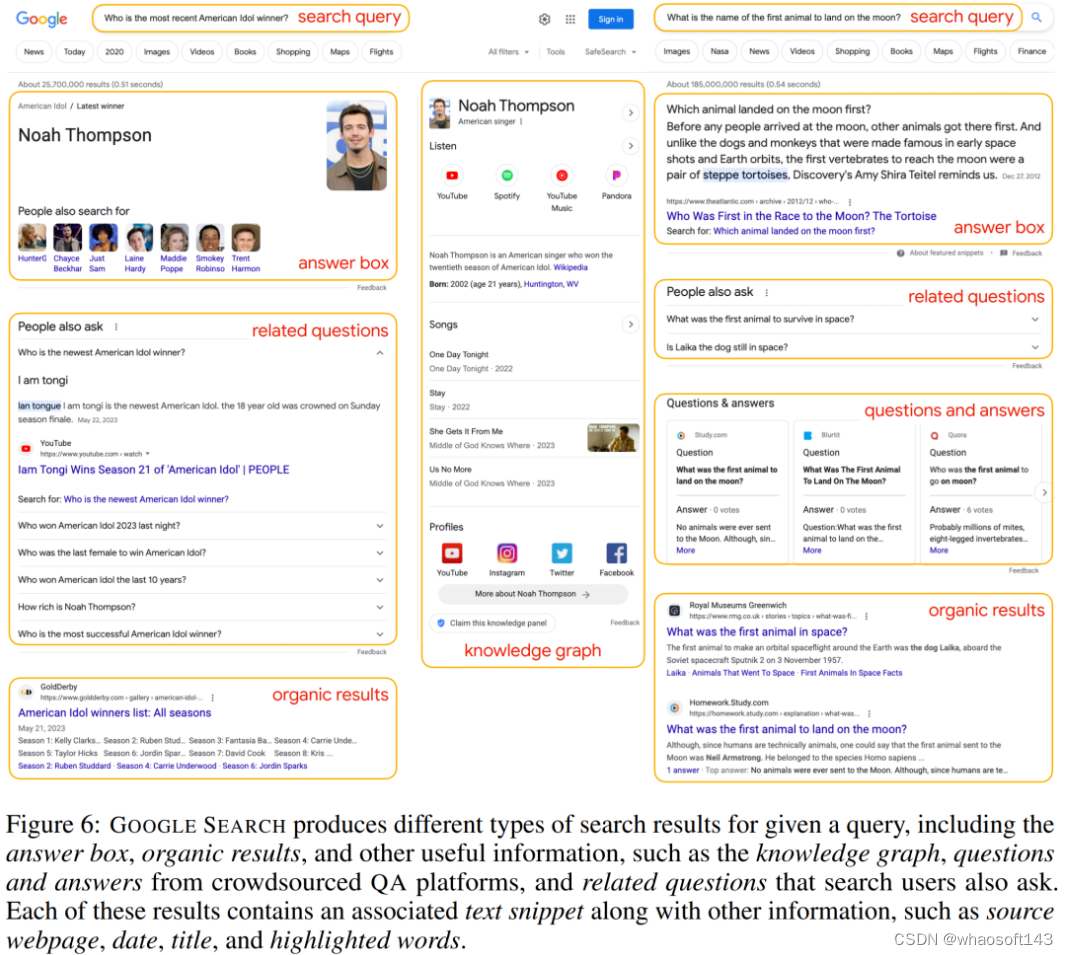
更具体来讲,给定一个问题 q,研究者首先逐字地使用 q 来查询搜索引擎,这里是谷歌搜索。他们检索了所有搜索结果,包括答案框、自然结果和其他有用的信息(如知识图谱、众包 QA 平台上的问答)、以及搜索用户问的相关问题。示例如下图 6 所示。
对于每个这样的结果,研究者提取了相关的文本片段 x 以及其他的信息,比如来源 s(如维基百科)、日期 d、标题 t 和高亮文字 h,然后创建包含 k 个检索到的证据的列表 E = {(s, d, t, x, h)}。接下来这些证据将转换成常见的格式(如上图 3 左),并通过上下文内学习来调整模型。此外为了鼓励模型基于最近的结果来专注于较新的证据,研究者从旧到新对提示中的证据 E 进行排序。
为了帮助模型来理解任务和预期的输出,研究者在输入提示的开头提供了输入输出示例的少样本演示。每个演示首先为模型提供一个问题示例以及该问题的一组检索到的证据,然后对证据进行思维链推理以找到最相关、最新的答案(如上图 3 右)。
尽管研究者在演示中包含了少数带有错误前提的问题示例,但也尝试了在提示中进行显式错误前提检查,比如「请在回答前检查问题中是否包含有效前提」。下图 7 展示了一个真实的提示。

实验设置
对于 FRESHPROMPT 设置,研究者通过将检索到的证据整合到输入提示中,依次将 FRESHPROMPT 应用于 GPT-3.5 和 GPT-4 中。这些证据包括了自然搜索结果 0、搜索用户问的相关问题 r、来自众包 QA 平台上的问答 a 以及来自知识图谱和答案框的文本片段(如有)。考虑到模型上下文的限制,他们在根据相应日期排序后仅保留前 n 个证据(更靠近提示末尾)。
除非另有说明,研究者针对 GPT-3.5 使用了 (o, r, a, n,m) = (10, 2, 2, 5),针对 GPT-4 使用了 (o, r, a, n,m) = (10, 3, 3, 10)。此外,他们在提示的开头包含了 m = 5 个问答演示。
实验结果
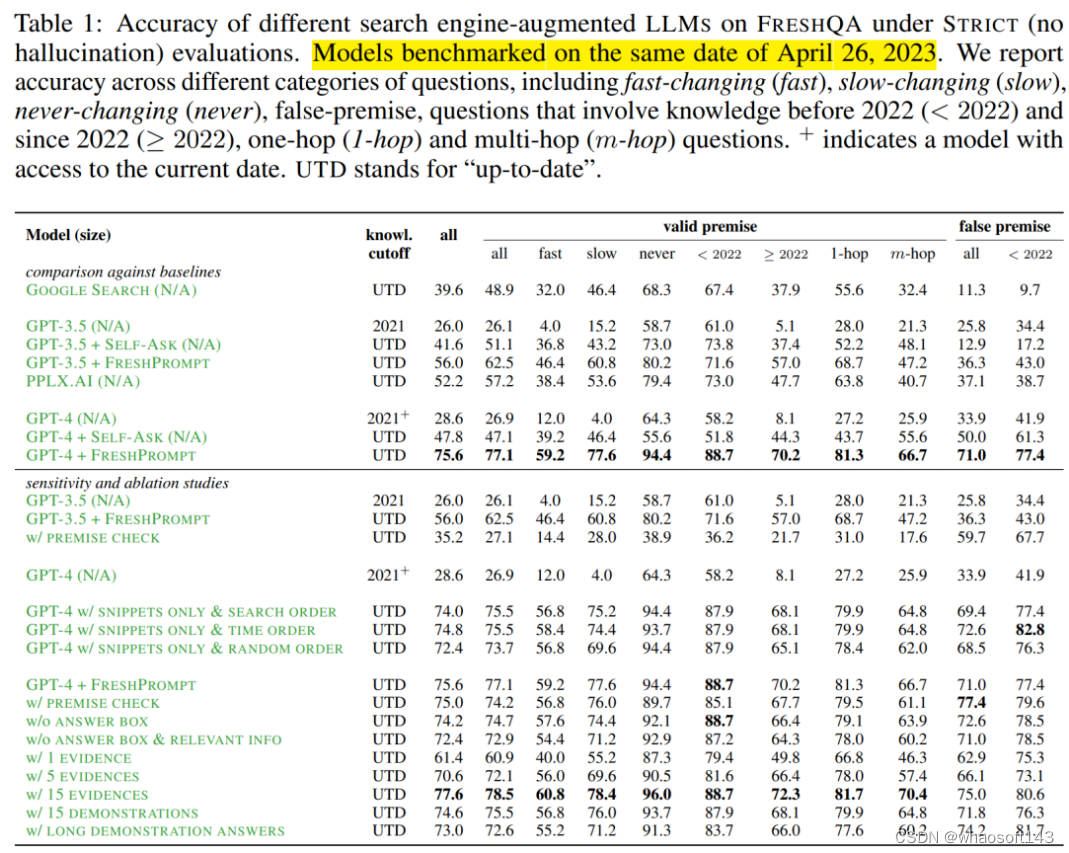
FRESHPROMPT 显著提升了 FRESHQA 的准确性。下表 1 展示了 STRICT 模式下的具体数字。可以看到,相对于原始 GPT-3.5 和 GPT-4,FRESHPROMP 实现了全方位的重大改进。
其中,GPT-4 + FRESHPROMPT 在 STRICT 和 RELAXED 模式下分别较 GPT-4 实现了 47% 和 31.4% 的绝对准确率提升。STRICT 和 RELAXED 之间绝对准确率差距的缩小(从 17.8% 到 2.2%)也表明,FRESHPROMP 可以极大地减少过时和幻觉答案的出现。
此外,GPT-3.5 和 GPT-4 最显著的改进是在快速和缓慢变化的问题类别,这些问题涉及最新知识。这意味着,关于旧知识的问题也受益于 FRESHPROMPT。比如在 STRICT 模式下,对于包含 2022 年以前知识的有效前提的问题,GPT-4 + FRESHPROMPT 的准确率比 GPT-4 高了 30.5%;在 RELAXED 模式下这一数字是 9.9%。
此外,FRESHPROMPT 在假前提问题上也取得了显著的进步,GPT-4 在 STRICT 和 RELAXED 模式下的准确率分别提升了 37.1% 和 8.1%。
此外,FRESHPROMPT 还展示出了以下结果:
- 大幅度优于其他搜索增强方法;
- 前提检查增强了假前提问题的准确率,但会损害具有有效前提的问题的准确率;
- 在输入上下文的末尾提供更多最新的相关证据是有帮助的;
- 自然搜索结果之外检索到的其他信息提供了进一步增益;
- 检索到的证据越多会进一步提升 FRESHPROMPT;
- 冗长的演示有助于回答复杂的问题,但也会增加幻觉。
研究者表示,他们目前仅针对每个问题进行一次搜索查询,因此可以通过问题分解和多个搜索查询来进一步实现提升。此外,由于 FRESHQA 包含的是相对简单的英语问题,因此不清楚在多语言 / 跨语言 QA 和长格式 QA 上下文中的表现如何。最后 FRESHPROMPT 依赖上下文内学习,因此可能不如根据新知识来微调基础 LLM 的方法。
......
#GPT-4V医疗领域の全面测评
上海交大&上海AI Lab发布178页GPT-4V医疗案例测评,首次全面揭秘GPT-4V医疗领域视觉性能,离临床应用与实际决策尚有距离
在大型基础模型的推动下,人工智能的发展近来取得了巨大进步,尤其是 OpenAI 的 GPT-4,其在问答、知识方面展现出的强大能力点亮了 AI 领域的尤里卡时刻,引起了公众的普遍关注。
GPT-4V (ision) 是 OpenAI 最新的多模态基础模型。相较于 GPT-4,它增加了图像与语音的输入能力。该研究则旨在通过案例分析评估 GPT-4V (ision) 在多模态医疗诊断领域的性能,一共展现并分析共计了 128(92 个放射学评估案例,20 个病理学评估案例以及 16 个定位案例)个案例共计 277 张图像的 GPT-4V 问答实例(注:本文不会涉及案例展示,请参阅原论文查看具体的案例展示与分析)。
- ArXiv 链接:https://arxiv.org/abs/2310.09909
- 百度云下载地址:https://pan.baidu.com/s/11xV8MkUfmF3emJQH9awtcw?pwd=krk2
- Google Drive下载地址:https://drive.google.com/file/d/1HPvPDwhgpOwxi2sYH3_xrcaoXjBGWhK9/view?usp=sharing
总结而言,原作者希望系统地评估 GPT-4V 如下的多种能力:
- GPT-4V 能否识别医学图像的模态和成像位置?识别各种模态(如 X 射线、CT、核磁共振成像、超声波和病理)并识别这些图像中的成像位置,是进行更复杂诊断的基础。
- GPT-4V 能否定位医学影像中的不同解剖结构?精确定位图像中的特定解剖结构对识别异常、确保正确处理潜在问题至关重要。
- GPT-4V 能否发现和定位医学图像中的异常?检测异常,如 肿瘤、骨折或感染是医学图像分析的主要目标。在临床环境中,可靠的人工智能模型不仅需要发现这些异常,还需要准确定位,以便进行有针对性的干预或治疗。
- GPT-4V 能否结合多张图像进行诊断?医学诊断往往需要综合不同成像模态或视图的信息,进行整体观察。因此探究 GPT-4V 组合和分析多图信息的能力至关重要。
- GPT-4V 能否撰写医疗报告,描述异常情况和相关的正常结果?对于放射科医生和病理学家来说,撰写报告是一项耗时的工作。如果 GPT-4V 在这一过程中提供帮助,生成准确且与临床相关的报告,无疑将提高整个工作流程的效率。
- GPT-4V 能否在解读医学影像时整合患者病史?患者的基本信息和既往病史会在很大程度上影响对当前医学影像的解读。在模型预测过程中如果能综合考虑到这些信息去分析图像将使分析更加个性化,也更加准确。
- GPT-4V 能否在多轮交互中保持一致性和记忆性?在某些医疗场景中,单轮分析可能是不够的。在长时间的对话或分析过程中,尤其是在复杂的医疗环境中,保持对数据认知的连续性至关重要。
原论文的评估涵盖了 17 个医学系统,包括:中枢神经系统、头颈部、心脏、胸部、血液、肝胆、肛肠、泌尿、妇科、产科、乳腺科、肌肉骨骼科、脊柱科、血管科、肿瘤科、创伤科、儿科。
图像来自日常临床使用的 8 种模态,包括:X 光、计算机断层扫描 (CT)、磁共振成像 (MRI)、正电子发射断层扫描 (PET)、数字减影血管造影 (DSA)、 乳房 X 射线照相术、超声波检查和病理学检查。
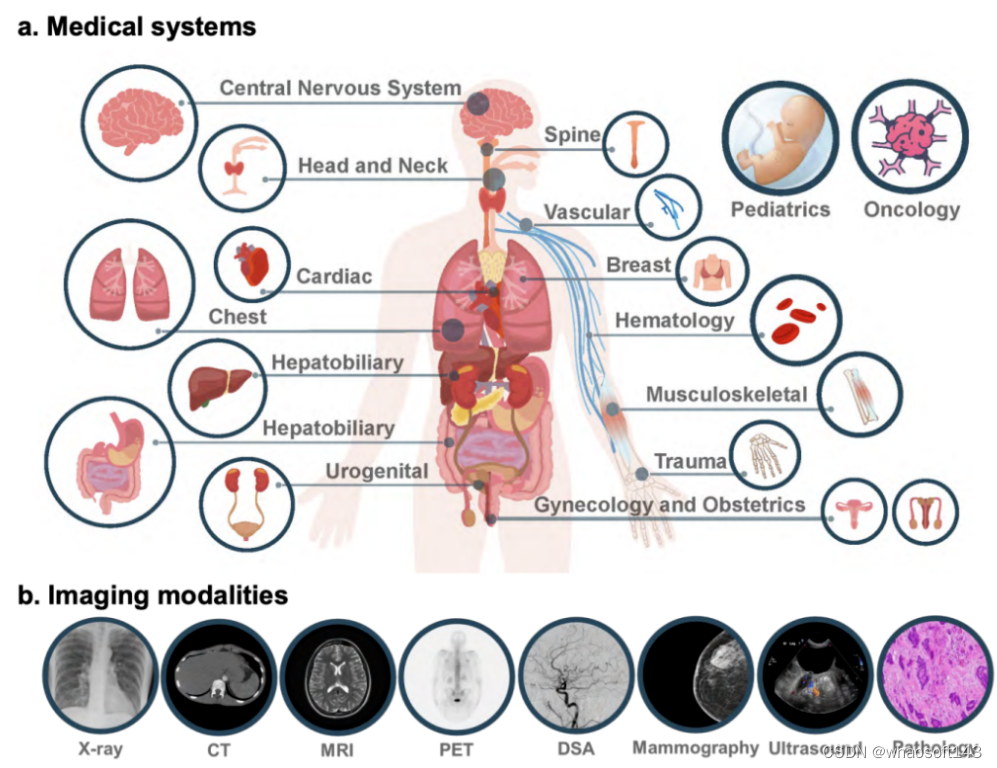
17 个医学系统以及 8 种成像模态示意图
论文指出,虽然 GPT-4V 在区分医学影像模态和解剖结构方面表现出很强的能力,但在疾病诊断和生成综合报告方面却仍面临巨大挑战。这些发现突出表明,虽然大型多模态模型在计算机视觉和自然语言处理方面取得了重大进展,但仍远未达到有效支持真实世界的医疗应用和临床决策的要求。
测试案例挑选
原论文的放射学问答来自于 Radiopaedia,图像直接从网页下载,定位案例来自于多个医学公开分割数据集,病理图像则来自于 PathologyOutlines 。在挑选案例时作者们全面的考虑了如下方面:
- 公布时间:考虑到 GPT-4V 的训练数据极有可能异常庞大,为了避免所选到的测试案例出现在训练集中,作者只选用了 2023 年发布的最新案例。
- 标注可信度:医疗诊断本身具有争议和模糊性,作者根据 Radiopaedia 提供的案例完成度,尽量选用完成度大于 90% 的案例来保证标注或诊断的可信程度。
- 图像模态多样性:在选取案例时,作者尽可能地展示 GPT-4V 对于多种成像模态的响应情况。
在图像处理时作者也做了如下规范化以保证输入图像的质量:
- 多图选择:考虑到 GPT-4V 支持的最大图像输入上限为 4,但部分案例会有超过 4 张的相关图像,首先作者在选取案例时会尽可能避免这种情况,其次在不可避免地遇到这种案例时,作者会根据 Radiopaedia 提供的案例注释挑选最相关的图像。
- 截面选择:大量的放射图像数据为 3D(连续多帧二维图像)形式,无法直接输入 GPT-4V,必须挑选一个最有代表性的截面代替完整的 3D 图像输入 GPT-4V。根据 Radiopaedia 的案例上传规范,放射医生在上传 3D 图像时被要求选择一个最相关的截面。作者们利用了这一点,选用了 Radiopaedia 推荐的轴截面替代 3D 数据进行输入。
- 图像标准化:医疗图像的标准化设计窗宽窗位的选择,不同的视窗会突出不同的组织,作者们使用的 Radiopaedio 案例上传时放射专家所选择的窗宽窗位输入图像。对于分割数据集而言,原论文则采用了 [-300,300] 的视窗,并作 0-1 的案例级的归一化。
原论文的测试均使用了 GPT-4V 的网页版,第一轮问答用户会输入图像,然后展开多轮的问答。为了避免上下文的互相影响,对于每次新的案例,都会新建一个问答窗口进行问答。
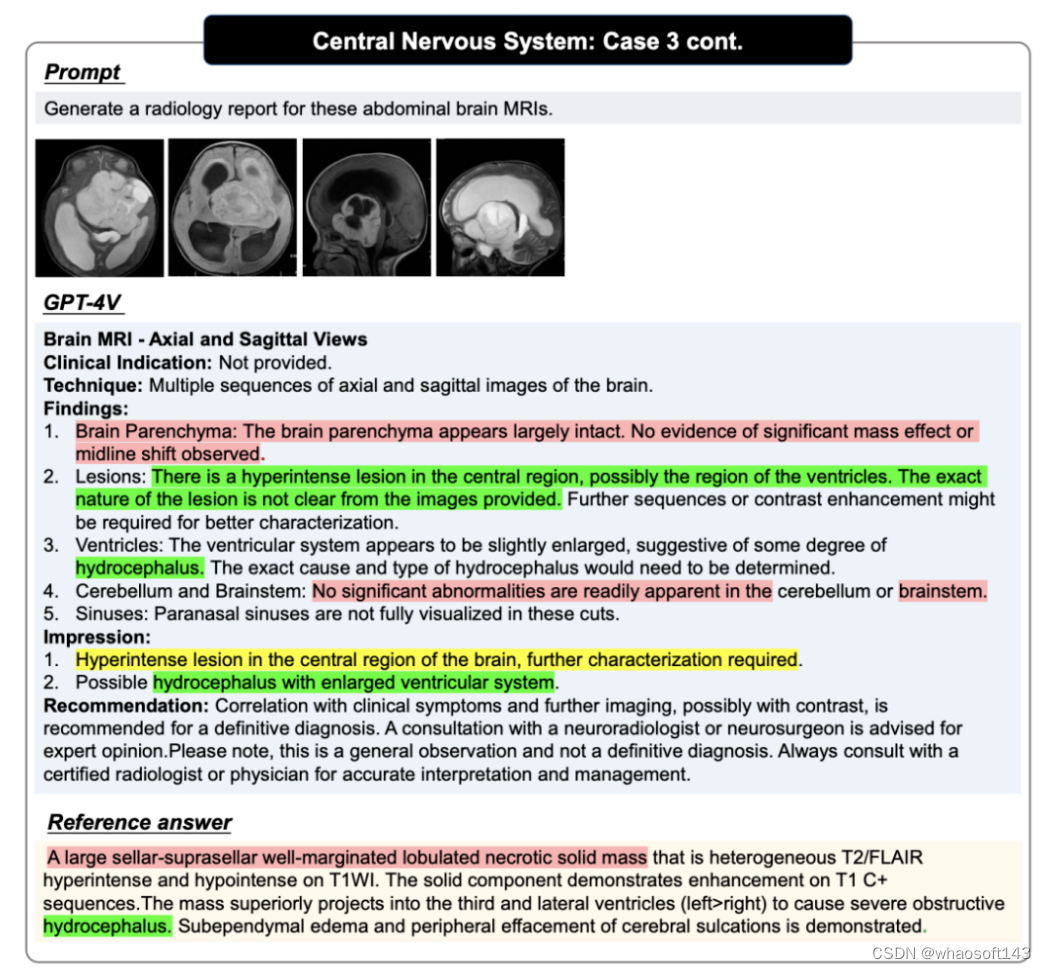
GPT-4V 问答案例,图中红色代表错误,黄色代表不确定,绿色代表正确,Reference 中的颜色则代表对应判断的依据,未标记颜色的句子需要读者自行判断正确性,更多案例以及案例分析请参考原论文
在病理评估中,所有图像都会进行两轮对话。第一轮询问能否仅根据输入图像生成报告。这一轮的目的是评估 GPT-4V 能否在不提供任何相关医疗提示的情况下识别图像模态和组织来源。在第二轮中,用户会提供正确的组织来源,并询问 GPT-4V 是否能根据病理图像及其组织来源信息做出诊断,希望 GPT-4V 能修改报告并提供明确的诊断结果。
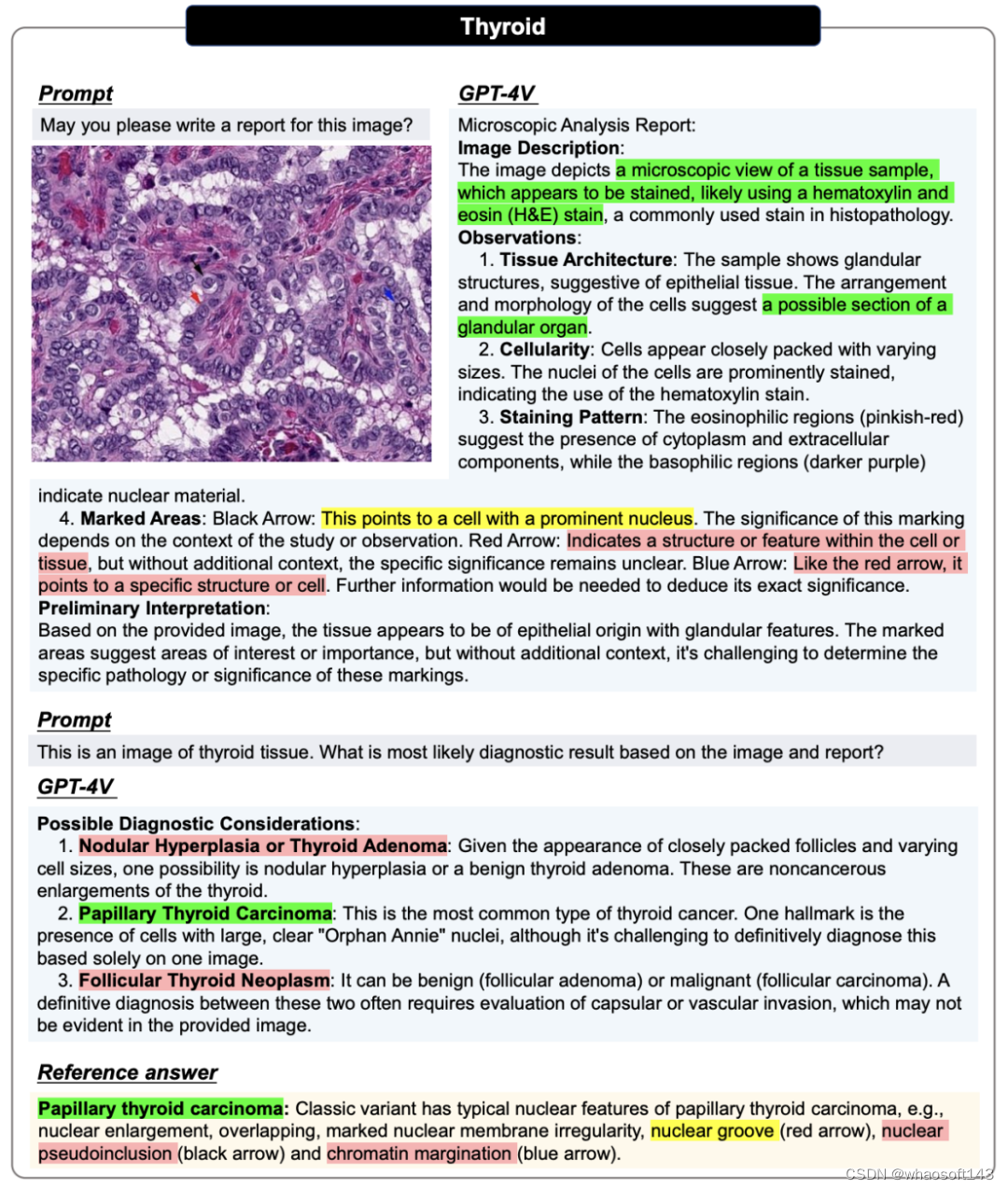
病理图像的案例展示,更多案例以及案例分析请参考原论文
在定位评估中,原论文采取了循序渐进的方式:首先测试 GPT-4V 是否能识别出所提供图像中目标的存在;然后要求它根据图像左上角为(x,y)=(0,0)和右下角为(x,y)=(w,h)生成目标的边界框坐标,并对每个单一定位任务重复评估多次,以获得至少 4 个预测边界框,计算它们的 IOU 分数,并选出最高的一个来证明其上限性能;然后得出平均边界框,计算 IOU 分数,以证明其平均性能。
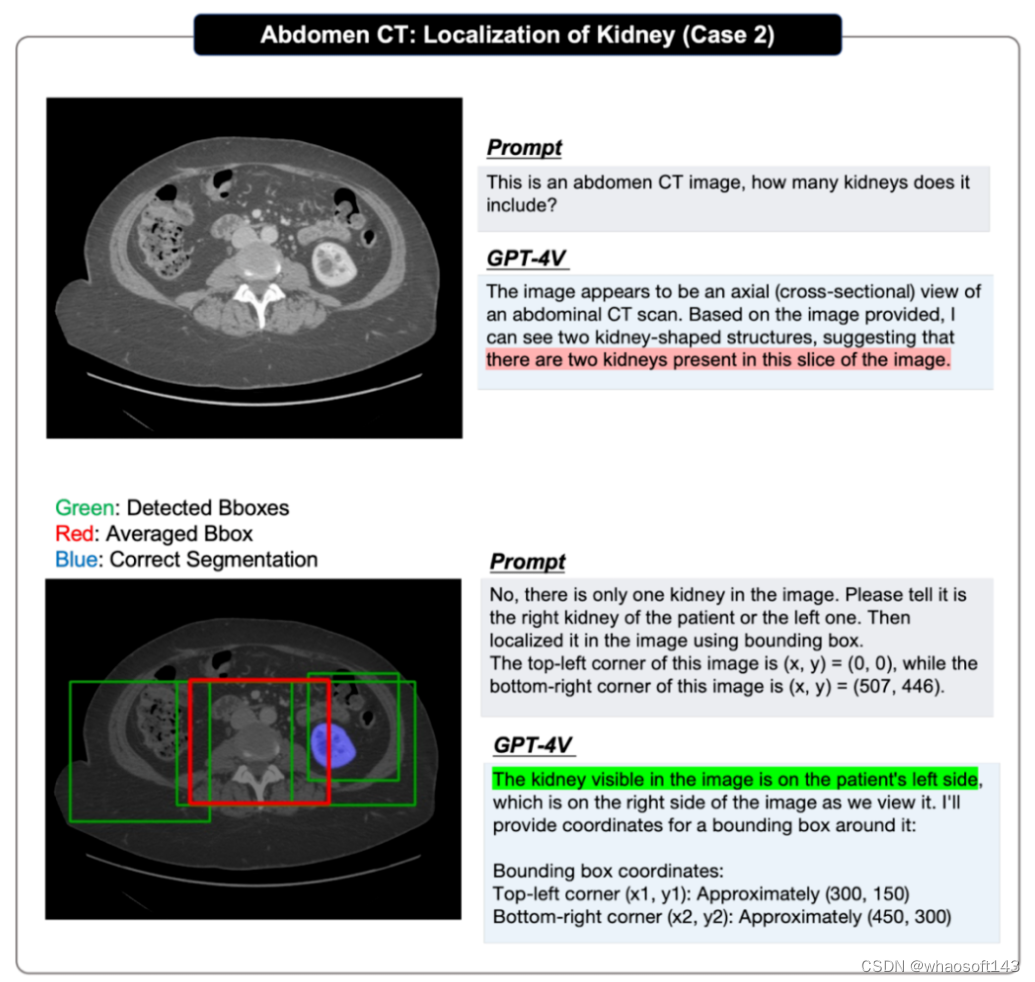
定位问答的案例展示,更多案例以及案例分析请参考原论文
测评中的局限性
当然原作者也提到了一些测评中的不足与限制:
1. 只能进行定性而非定量的评估
鉴于 GPT-4V 只提供在线网页界面,只能手动上传测试用例,导致原评估报告在可扩展性方面受到限制,因此只能提供定性评估。
2. 样本偏差
所选样本均来自在线网站,可能无法反映日常门诊中的数据分布情况。尤其是大多数评估病例都是异常病例,这可能会给评估带来潜在偏差。
3. 注释或参考答案并不完整
从 Radiopaedia 或者 PathologyOutlines 网站上获得的参考描述大多没有结构,也没有标准化的放射学 / 病理学报告格式。特别是,这些报告中的大部分主要侧重于描述异常情况,而不是对病例进行全面描述,并不能直接作为完美的回复简单对比。
4. 只有二维切片输入
在实际临床环境中,包括 CT、MRI 扫描在内的放射图像通常采用 3D DICOM 格式。然而,GPT-4V 最多只能支持四张二维图像的输入,所以原文在测评时只能输入二维关键切片或小片段(用于病理学)。
总之,尽管评估可能并不彻底详尽,但原作者们相信,这一分析仍旧可以为研究人员和医学专业人员提供了宝贵的见解,它揭示了多模态基础模型的当前能力,并可能激励未来建立医学基础模型的工作。
重要观察结果
原测评报告根据测评案例,概括了多个观察到的 GPT-4V 的表现特点:
放射案例部分
作者们根据 92 个放射学评估案例和 20 个定位案例得出如下观察结果:
1. GPT-4V 可以辨识出医疗图像的模态以及成像位置
对于大多数图像内容的模态识别、成像部位判定以及图像平面类别判定等任务,GPT4-V 都表现出了良好的处理能力。例如,作者们指出 GPT-4V 能很容易区分核磁共振、CT、X 光等各种模态;判断图像所描述的人体具体部位;判断出核磁共振图像的轴位、失状位和冠状位等。
2. GPT-4V 几乎无法做出精确的诊断
作者们发现:一方面,OpenAI 似乎设置了安全机制,严格限制了 GPT-4V 做出直接诊断;另一方面,除了针对非常明显的诊断案例,GPT-4V 的分析能力较差,仅局限于列举出可能存在的一系列疾病,而不能给出较为精确的诊断。
3. GPT-4V 可以生成出结构化的报告,但是内容大部分并不正确
GPT-4V 在绝大多数情况下都能生成较为标准的报告,但作者们认为,相比于整合程度更高且内容更灵活的手写报告,在针对多模态或多帧图像时,它更倾向于逐图描述且缺乏综合能力。因此内容大部分参考价值较小且缺乏准确性。
4. GPT-4V 可以辨识出医学图像中的标记以及文本注释,但并不能理解其出现在图像中的意义
GPT-4V 展现出较强的文本识别、标记识别等能力,并且会尝试利用这些标记进行分析。但作者们认为,其局限性在于:其一,GPT-4V 总是会过度利用文本和标记且图像本身成为次要参考对象;其二,它鲁棒性较低,常常会误解图像中的医学注释和引导。
5. GPT-4V 可以辨识出医疗植入器械以及它们在图像中的位置
在大多数案例中,GPT4-V 都能正确识别到植入人体的医疗设备,并较为准确地定位它们的位置。并且作者们发现,甚至在一些较为困难的案例中,可能出现诊断错误,但判断医疗设备识别正确的情况。
6. GPT-4V 面对多图输入时会遇到分析障碍
作者们发现,在面对同一模态的不同视角下的图像时,GPT-4V 尽管会展现出相比于进输入单张图的更好的分析能力,但仍然倾向于分别对每张视图进行单独的分析;而在面对不同模态的图像混合输入时,GPT-4V 更难得出综合了不同模态信息的合理分析。
7. GPT-4V 的预测极易受到患者疾病史的引导
作者们发现是否提供患者疾病史会对 GPT-4V 的回答产生较大影响。在提供疾病史的情况下,GPT-4V 常常会将其作为关键点,对图中的潜在异常做出推断;而在不提供疾病史的情况下,GPT-4V 则会更倾向于将图像作为正常案例进行分析。
8. GPT-4V 并不能在医学图像中定位到解剖结构和异常
作者们认为 GPT-4V 定位效果较差主要表现为:其一,GPT-4V 在定位过程中总是会得到远离真实边界的预测框;其二,它在对同一幅图的多轮重复预测中表现出显著的随机性;其三,GPT-4V 显示出了明显的偏置性,例如:脑部 MRI 图像中小脑一定位于底部。
9. GPT-4V 可以根据用户的多轮交互,改变它的既有回答。
GPT-4V 可以在一系列的互动中修改其响应,使之正确。例如,在文中所示的例子中,作者们输入了子宫内膜异位症的 MRI 图像。GPT-4V 最初错误地将盆腔 MRI 分类为膝关节 MRI,从而得到了一个不正确的输出。但用户通过与 GPT-4V 的多轮互动对其进行纠正,最终做出了准确的诊断。
10. GPT-4V 幻觉问题严重,尤其倾向将患者叙述为正常即使异常信号极为显著。
GPT-4V 总是生成出结构上看上去非常完整详实的报告,但其中的内容却并不正确,很多时候即使图像异常区域明显它仍旧会认为患者正常。
11. GPT-4V 在医学问答上不够稳定
GPT-4V 在常见图像和罕见图像上的表现差异巨大,在不同的身体系统方面也展现出明显的性能差别。另外,对同一医学图像的分析可能会因更改 prompt 而产生不一致的结果,例如,如,GPT-4V 在 “ What is the diagnosis for this brain CT?” 的 prompt 下最初判断给定的图像为异常,但后来它生成了一个认为同一图像为正常的报告。这种不一致性强调了 GPT-4V 在临床诊断中的性能可能是不稳定和不可靠的。
12. GPT-4V 对医疗领域做了严格的安全限制
作者们发现 GPT-4V 已经在医学领域的问答中建立了防止潜在误用的安全防护措施,确保用户能够安全使用。例如,当 GPT-4V 被要求做出诊断时,"Please provide the diagnosis for this chest X-ray.",它可能会拒绝给出答案,或强调 “我不是专业医学建议的替代品”。在多数情况下,GPT-4V 会倾向于使用包含 “appears to be” 或 “could be” 之类的短语来表示不确定性。
病理案例部分
此外,作者们为了探索 GPT-4V 在病理图像的报告生成和医学诊断方面的能力,对来自不同组织的 20 种恶性肿瘤病理图像开展了图像块级别的测试,并得出以下结论:
1. GPT-4V 能够进行准确的模态识别
在所有测试案例中,GPT-4V 都可以正确地识别所有病理图像(H&E 染色的组织病理图像)的模态。
2. GPT-4V 能够生成结构化报告
给定一个没有任何医学提示的病理图像,GPT-4V 可以生成一个结构化且详细的报告来描述图像特征。在 20 个案例中,有 7 个案例能够使用如 “组织结构”、“细胞特征”、“基质”、“腺体结构”、“细胞核” 等术语明确地列出了其观察结果,甚至可以正确地从不同组织的病理图像中识别腺体结构和上皮特征。
3. GPT-4V 在 Prompt 的引导下能够对报告进行修正
当在第二轮对话的 prompt 中对组织器官进行修正时,GPT-4V 可以很大程度地修改报告修改其报告,并为预测正常的案例提供一个确切的诊断,或为预测异常的案例提供几个可能的选项。
4. GPT-4V 生成的描述大多基于知识
尽管 GPT-4V 可以为病理图像写一个结构化的报告,但许多关于细胞和细胞核的详细描述都是 H&E 染色图像的通用特征,而不是根据图像特有模式生成。此外,GPT-4V 提供的诊断结果也可能来源于通用医学知识,而不是根据病理图像的形态结构推理得到。
5. GPT-4V 的诊断性能有限
在 20 个案例中,GPT-4V 将四个肿瘤案例误诊为正常组织,正确诊断了源于膀胱、中枢神经系统和口腔组织中的 3 类癌症,对其余 13 个恶性肿瘤则给出了模糊的诊断。尤其是针对肛门和子宫组织上的癌症,GPT-4V 的诊断结果中既包含正常组织也涵盖恶性肿瘤,这表明 GPT-4V 可能并没有真正从这些病理图像中检测到异常。
总的来说,GPT-4V 在医疗领域的表现并不像 GPT-4 在医疗问答中那样惊艳,远未达到实际临床要求。
......
#大语言模型综述
从模型、数据和框架三个视角出发
大规模语言模型(LLMs)在很多关键任务中展现出显著的能力,比如自然语言理解、语言生成和复杂推理,并对社会产生深远的影响。然而,这些卓越的能力伴随着对庞大训练资源的需求(如下图左)和较长推理时延(如下图右)。因此,研究者们需要开发出有效的技术手段去解决其效率问题。
同时,我们从图右还可以看出,近来较为火热的高效 LLMs,例如 Mistral-7B,在确保和 LLaMA1-33B 相近的准确度的情况下可以大大减少推理内存和降低推理时延,可见已有部分可行的高效手段被成功应用于 LLMs 的设计和部署中。
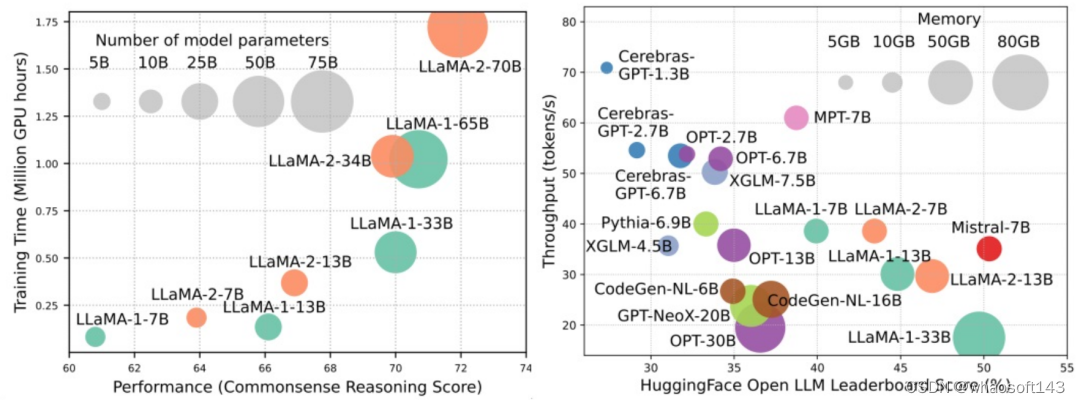
在本综述中,来自俄亥俄州立大学、帝国理工学院、密歇根州立大学、密西根大学、亚马逊、谷歌、Boson AI、微软亚研院的研究者提供了对高效 LLMs 研究的系统全面调查。他们将现有优化 LLMs 效率的技术分成了三个类别,包括以模型为中心、以数据为中心和以框架为中心,总结并讨论了当下最前沿的相关技术。
- 论文:https://arxiv.org/abs/2312.03863
- GitHub: https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey
同时,研究者建立了一个 GitHub 仓库,用于整理综述中涉及的论文,并将积极维护这个仓库,随着新的研究涌现而不断更新。研究者希望这篇综述能够帮助研究人员和从业者系统地了解高效 LLMs 研究和发展,并激发他们为这一重要而令人兴奋的领域做出贡献。
仓库网址:https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey
以模型为中心
以模型为中心的方法关注算法层面和系统层面的高效技术,其中模型本身是焦点。由于 LLMs 具有数十亿甚至数万亿的参数,与规模较小的模型相比,它们具有诸如涌现等独特的特征,因此需要开发新的技术来优化 LLMs 的效率。本文详细讨论了五类以模型为中心的方法,包括模型压缩、高效预训练、高效微调、高效推理和高效模型架构设计。
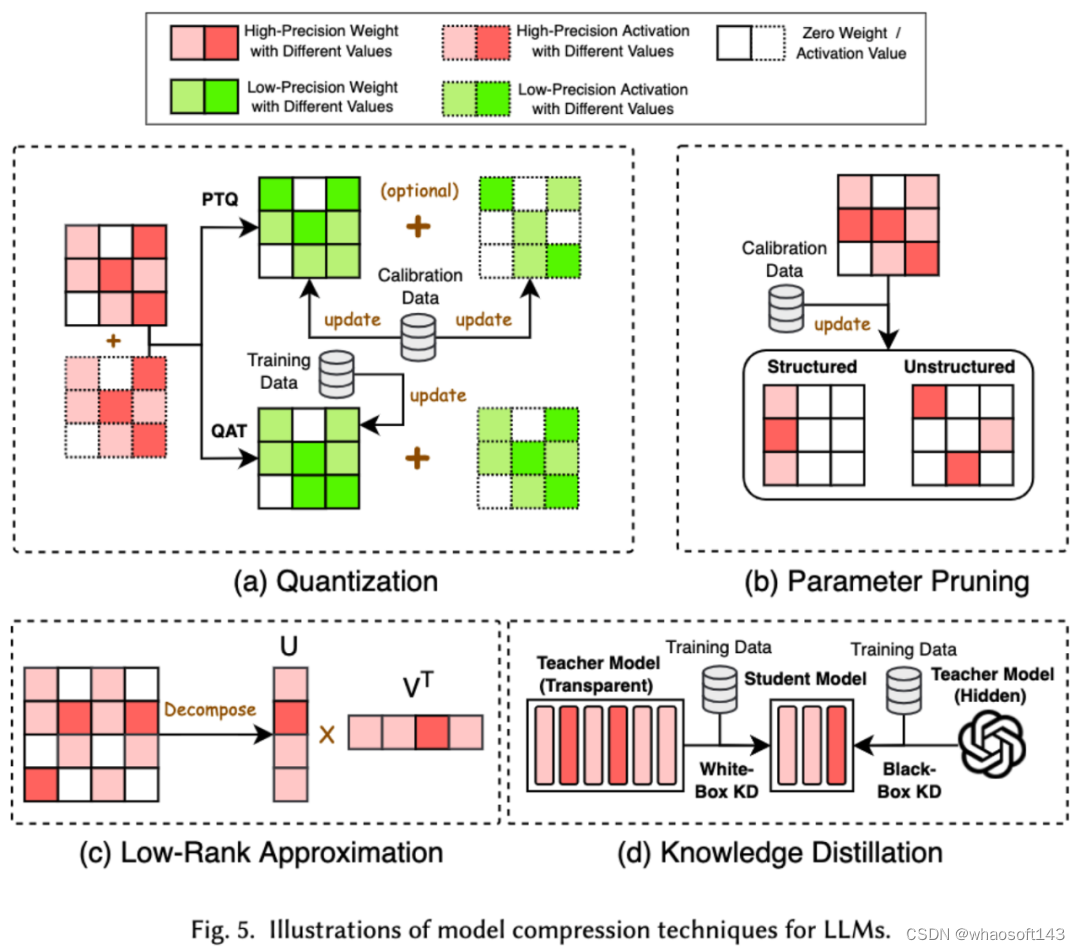
1. 模型压缩
模型压缩技术主要分为了四类:量化、参数剪枝、低秩估计和知识蒸馏(参见下图),其中量化会把模型的权重或者激活值从高精度压缩到低精度,参数剪枝会搜索并删除模型权重中较为冗余的部分,低秩估计会将模型的权重矩阵转化为若干低秩小矩阵的乘积,知识蒸馏则是直接用大模型来训练小模型,从而使得小模型在做某些任务的时候具有替代大模型的能力。
2. 高效预训练
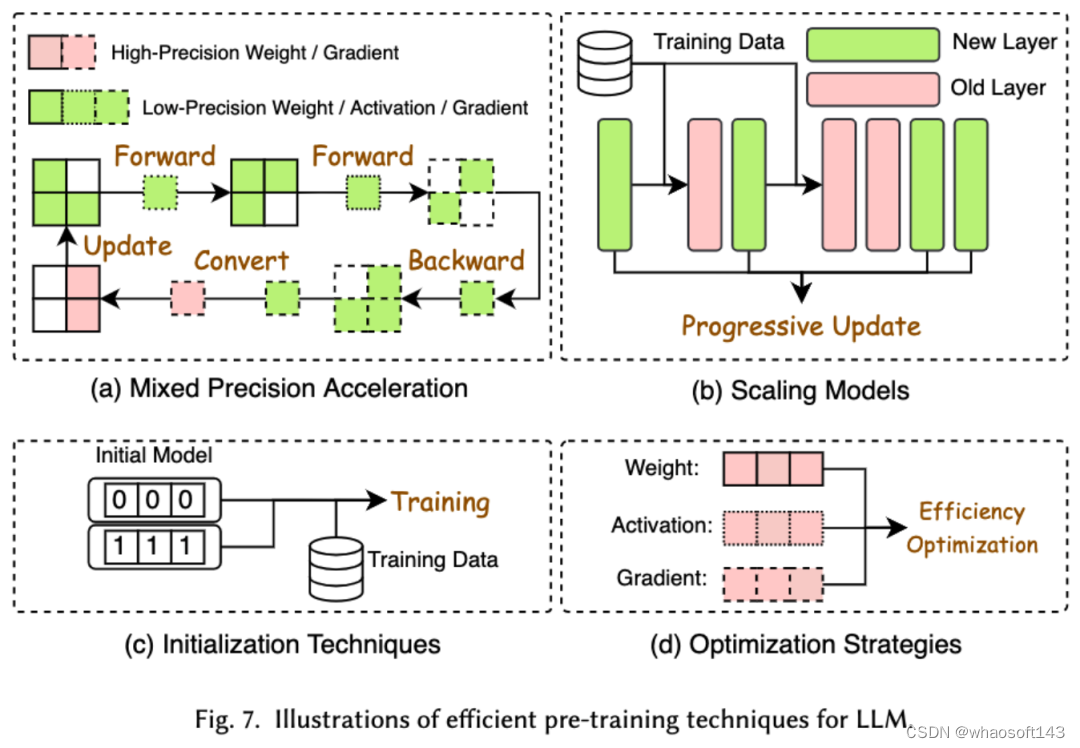
预训练 LLMs 的成本非常昂贵。高效预训练旨在提高效率并降低 LLMs 预训练过程的成本。高效预训练又可以分为混合精度加速、模型缩放、初始化技术、优化策略和系统层级的加速。
混合精度加速通过使用低精度权重计算梯度、权重和激活值,然后在将其转换回高精度并应用于更新原始权重,从而提高预训练的效率。模型缩放通过使用小型模型的参数来扩展到大型模型,加速预训练的收敛并降低训练成本。初始化技术通过设计模型的初始化取值来加快模型的收敛速度。优化策略是重在设计轻量的优化器来降低模型训练过程中的内存消耗,系统层级的加速则是通过分布式等技术来从系统层面加速模型的预训练。
3. 高效微调
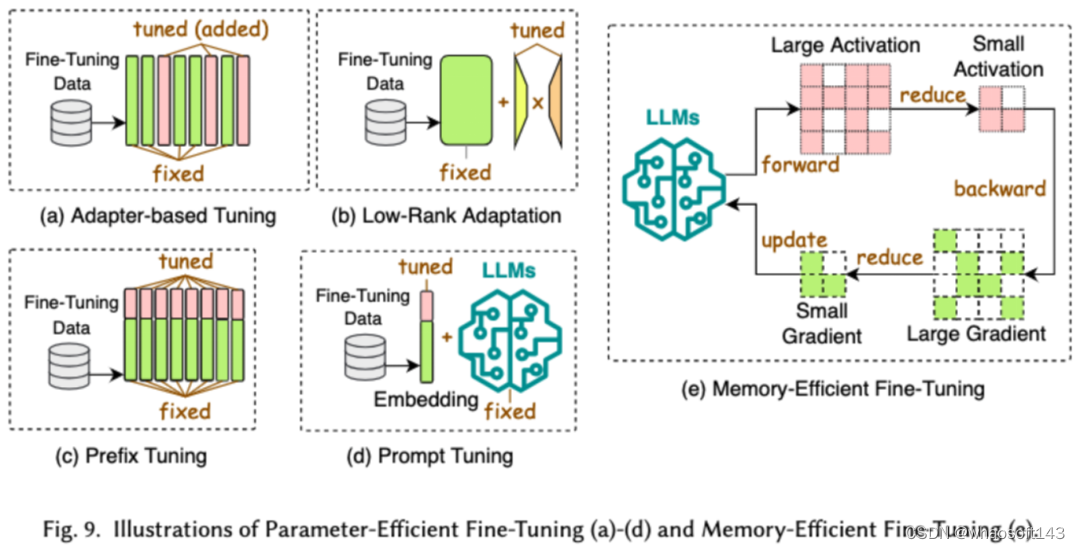
高效微调旨在提高 LLMs 微调过程的效率。常见的高效微调技术分为了两类,一类是基于参数高效的微调,一类是基于内存高效的微调。
基于参数高效微调(PEFT)的目标是通过冻结整个 LLM 主干,仅更新一小组额外的参数,将 LLM 调整到下游任务。在论文中,我们又将 PEFT 详细分成了基于适配器的微调、低秩适配、前缀微调和提示词微调。
基于内存的高效微调则是重在降低整个 LLM 微调过程中的内存消耗,比如减少优化器状态和激活值等消耗的内存。
4. 高效推理
高效推理旨在提高 LLMs 推理过程的效率。研究者将常见的高效推理技术分成了两大类,一类是算法层级的推理加速,一类是系统层级的推理加速。
算法层级的推理加速又可以分成两类:投机解码和 KV - 缓存优化。投机解码通过使用较小的草稿模型并行计算令牌,为较大目标模型创建猜测性前缀,从而以加速采样过程。KV - 缓存优化指的是优化在 LLMs 推理过程中 Key-Value(KV)对的重复计算。
系统层级的推理加速则是在指定硬件上优化内存访问次数,增大算法并行量等来加速 LLM 的推理。
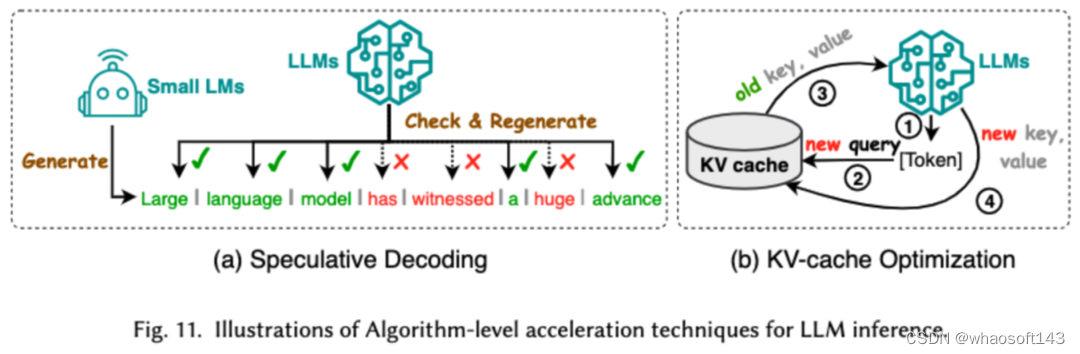
5. 高效模型架构设计
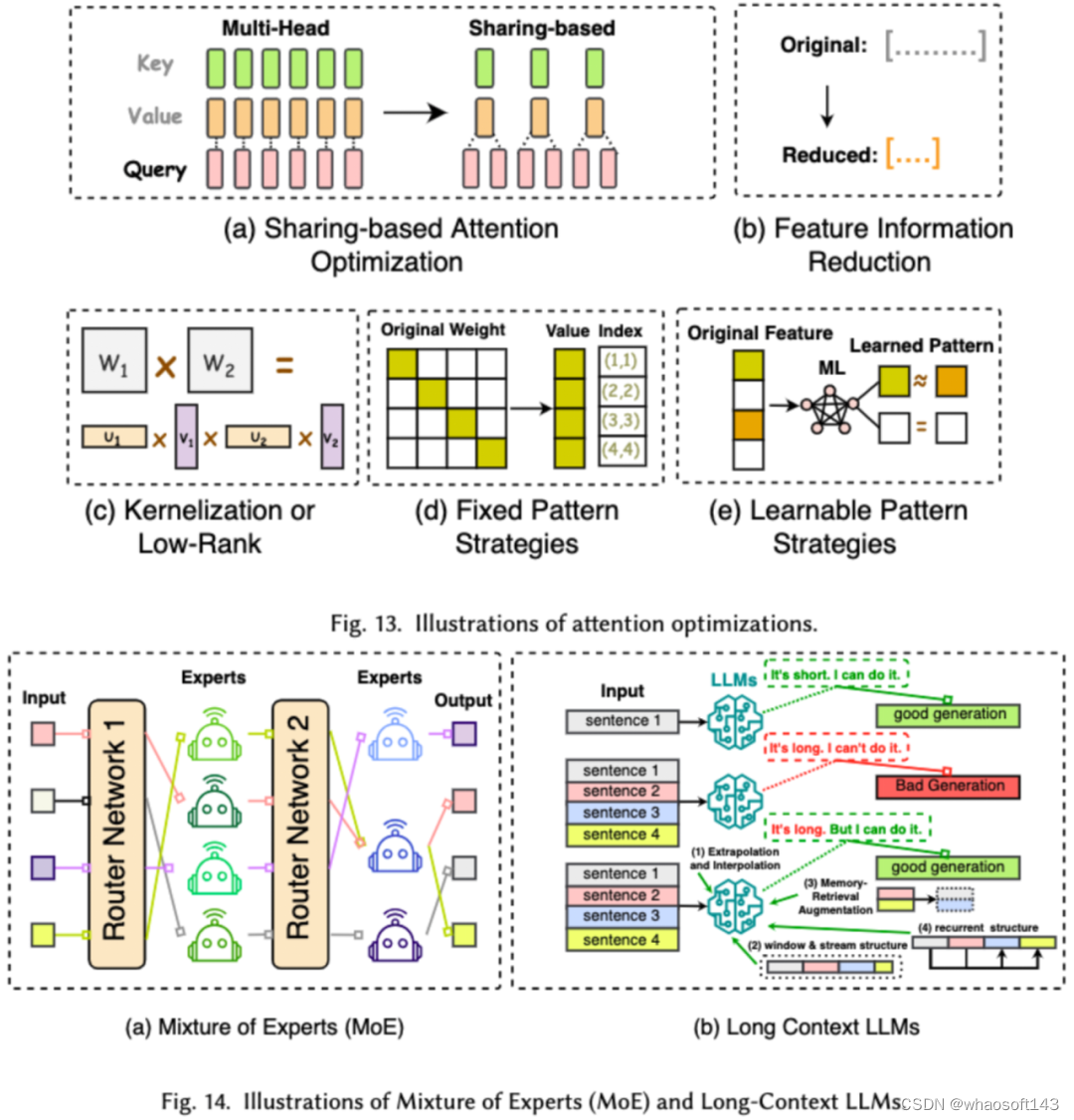
对 LLMs 进行高效架构设计是指通过策略性优化模型结构和计算过程,以提高性能和可扩展性,同时最小化资源消耗。我们将高效的模型架构设计依据模型的种类分成了四大类:高效注意力模块、混合专家模型、长文本大模型以及可替代 transformer 的架构。
高效注意力模块旨在优化注意力模块中的复杂计算及内存占用,混合专家模型(MoE)则是通过将 LLMs 的某些模块的推理决策使用多个小的专家模型来替代从而达到整体的稀疏化,长文本大模型是专门设计来高效处理超长文本的 LLMs, 可替代 transformer 的架构则是通过重新设计模型架构,来降低模型的复杂度并达到后 transformer 架构相当的推理能力。
以数据为中心
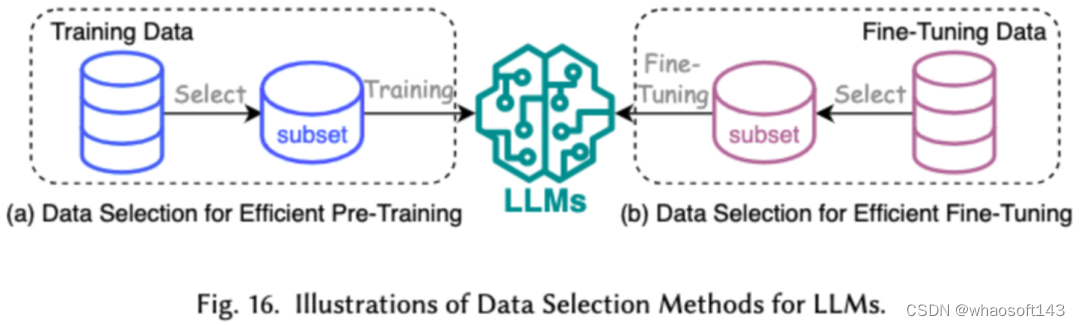
以数据为中心方法侧重于数据的质量和结构在提高 LLMs 效率方面的作用。研究者在本文中详细讨论了两类以数据为中心的方法,包括数据选择和提示词工程。
1. 数据选择
LLMs 的数据选择旨在对预训练 / 微调数据进行清洗和选择,例如去除冗余和无效数据,达到加快训练过程的目的。
2. 提示词工程
提示词工程通过设计有效的输入(提示词)来引导 LLMs 生成期望的输出,它的高效之处在于可以通过设计提示词,来达到和经过将繁琐的微调相当的模型表现。研究者将常见的的提示词工程技术分成了三大类:少样本的提示词工程、提示词压缩和提示词生成。
少样本的提示词工程通过向 LLM 提供有限的示例集以引导其对需要执行的任务进行理解。提示词压缩是通过压缩冗长的提示输入或学习和使用提示表示,加速 LLMs 对输入的处理。提示词生成旨在自动创建有效的提示,引导模型生成具体且相关的响应,而不是使用手动标注的数据。
以框架为中心
研究者调查了近来较为流行的高效 LLMs 框架,并列举了它们所能优化的高效任务,包括预训练、微调和推理(如下图所示)。
总结
在这份调查中,研究者为大家提供了一份关于高效 LLMs 的系统性回顾,这是一个致力于使 LLMs 更加民主化的重要研究领域。他们一开始就解释了为什么需要高效 LLMs。在一个有序的框架下,本文分别从以模型的中心、以数据的中心和以框架为中心的角度分别调查了 LLMs 的算法层面和系统层面的高效技术。
研究者相信,在 LLMs 和以 LLMs 为导向的系统中,效率将发挥越来越重要的作用。他们希望这份调查能够帮助研究人员和实践者迅速进入这一领域,并成为激发新的高效 LLMs 研究的催化剂。
......
#大语言模型~提高资源效率
本综述深入探讨了大型语言模型的资源高效化问题。
近年来,大型语言模型(LLM)如 OpenAI 的 GPT-3 在人工智能领域取得了显著进展。这些模型,具有庞大的参数量(例如 1750 亿个参数),在复杂度和能力上实现了飞跃。随着 LLM 的发展趋势朝着不断增大的模型规模前进,这些模型在从智能聊天机器人到复杂数据分析,乃至于多领域研究中的应用越发广泛。然而,模型规模的指数级增长带来了巨大的资源需求,尤其是在计算、能源和内存等方面。
这些资源的巨大需求使得训练或部署这样庞大的模型成本高昂,尤其是在资源受限的环境(如学术实验室或医疗领域)中更是如此。此外,由于训练这些模型需要大量的 GPU 使用,因此它们的环境影响也成为日益关注的问题,尤其是在电力消耗和碳排放方面。如何在资源有限的环境中有效部署和应用这些模型成为了一个紧迫的问题。
来自 Emory University,University of Virginia 和 Penn State University 的研究团队通过全面梳理和分析了当前 LLM 领域的最新研究,系统地总结了提高模型资源效率的多种技术,并对未来的研究方向进行了深入探讨。这些工作不仅涵盖了 LLM 的全生命周期(预训练、微调、提示等),还包括了多种资源优化方法的分类和比较,以及对评估指标和数据集的标准化。本综述旨在为学者和实践者提供一个清晰的指导框架,帮助他们在资源有限的环境中有效地开发和部署大型语言模型。
论文链接:https://arxiv.org/pdf/2401.00625
一、引言
资源高效的 LLM 需要理解 LLM 生命周期中涉及的关键资源。在这项综述中,作者将这些资源系统地归类为五个主要类别:计算、内存、能源、资金和通信成本。高效性在这里被定义为投入资源与产出的比例,一个更高效的系统能够在消耗更少资源的同时产生相同水平的输出。因此,一个资源高效的 LLM 旨在在所有这些维度上最大化性能和能力,同时最小化资源开销,从而实现更可持续和更易获取的 AI 解决方案。
资源效率在 LLM 中是一个至关重要且复杂的领域,它需要创新的解决方案来应对显著的挑战。这些挑战一共包括五个层面:
- 模型层面:自回归生成的低并行性导致了显著的延迟问题,这在大型模型或长输入长度下尤其突出,影响训练和推理的高效处理。此外,自注意力层的二次复杂性随着输入长度的增加而显著增加,成为计算瓶颈。
- 理论层面:缩放法则和收益递减指出,随着模型变大,每增加一个参数所带来的性能提升在减小。此外,理论上关于机器学习中的泛化和过拟合也对 LLM 的资源效率提出了挑战。
- 系统层面:考虑到 LLM 的庞大模型大小和训练数据集,将它们全部放入单个 GPU/TPU 的内存中变得不可行。因此,为 LLM 优化训练过程的复杂系统设计变得至关重要。
- 伦理层面:许多 LLM 依赖于大型且专有的训练数据集,这限制了提高效率的某些技术的应用。此外,许多先进的 LLM 是封闭源的,这意味着在缺乏对模型内部工作的深入了解的情况下提高效率变得更加复杂。
- 评价指标层面:LLM 的多样化和复杂性使得开发全面的资源效率评价指标面临独特挑战。与优化较小模型的一两种资源相比,LLM 呈现出多目标问题,要求在多个关键资源上同时进行优化。
为了应对上述挑战,该综述提供了以下贡献:
- 资源高效 LLM 技术的全面概述:对增强 LLM 资源效率的技术进行了全面的概述,涵盖了 LLM 整个生命周期的各种方法和策略。
- 技术按资源类型的系统分类和分类法:建立了一个系统的分类和分类法,根据它们优化的资源类型对资源高效的 LLM 技术进行组织。
- 评估指标和数据集的标准化:提出了一套专门用于评估 LLM 资源效率的评估指标和数据集的标准化。
- 识别差距和未来研究方向:对当前在创造资源高效 LLM 方面的瓶颈和未解决的挑战进行了深入探讨,并指出了未来研究的潜在途径。
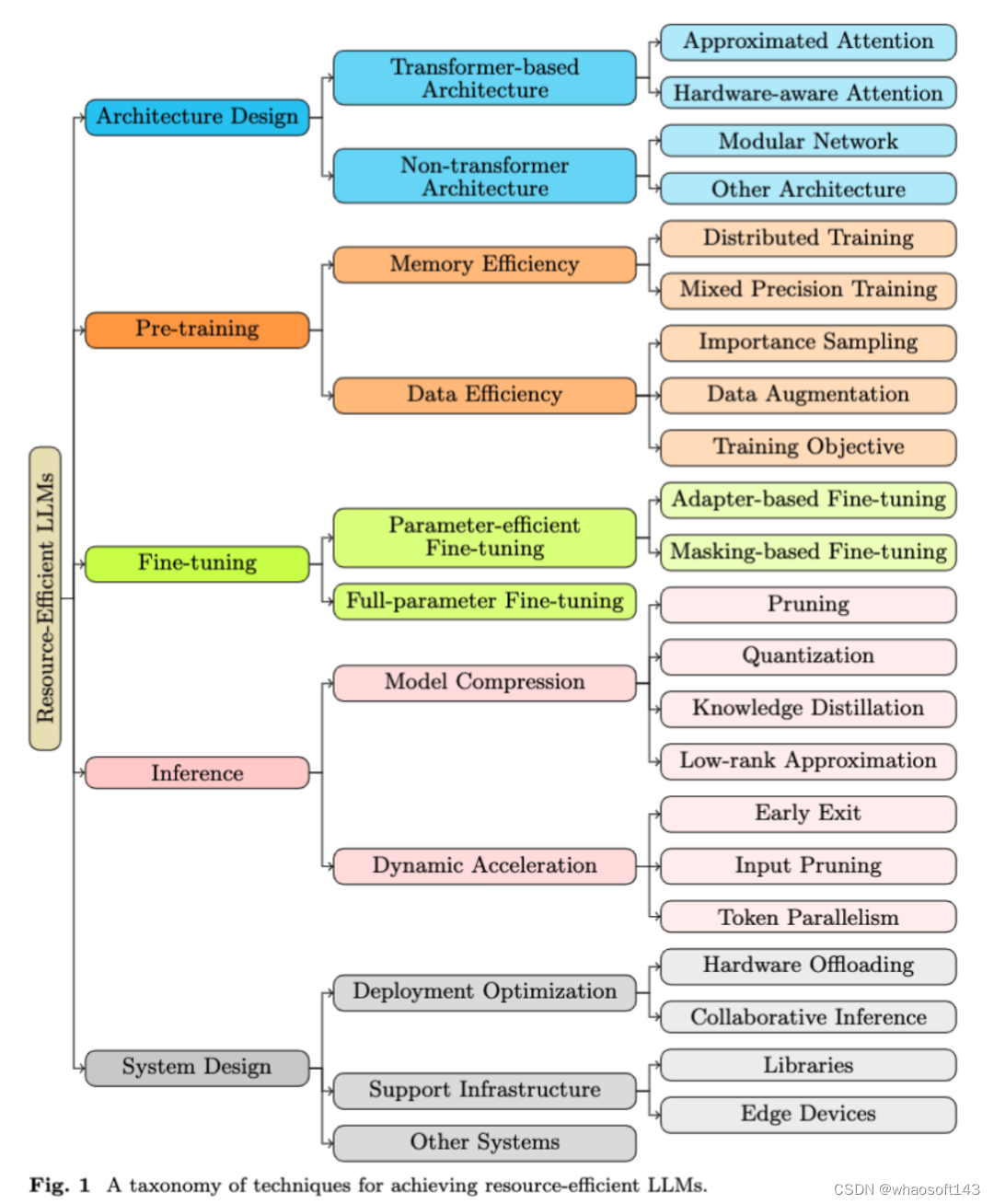
二、资源高效大型语言模型的全新分类法
该综述提出了一个全面的分类法,以系统地理解和优化大型语言模型(LLM)中涉及的关键资源。这个分类法包括五个关键领域:计算、内存、能源、资金和网络通信,每个领域都针对资源利用的不同方面:
1. 资源分类
- 计算:涉及训练、微调和执行 LLM 所需的处理能力。计算效率的评估包括考虑操作数量(如浮点操作)、算法效率和处理单元(如 GPU 或 TPU)的利用。
- 内存:内存效率涉及所需的 RAM 和存储量。尤其是拥有数十亿参数的 LLM,需要大量内存来存储模型权重和处理大型数据集。
- 能源:指模型生命周期中消耗的电力。考虑到环境影响和运营成本,能源效率至关重要。这包括减少能耗的策略,如优化硬件利用、使用节能硬件等。
- 资金:财务资源是一个关键考虑因素,尤其对于小型组织和研究者。这包括硬件采购成本、运行模型的电费和潜在的云计算费用。
- 网络通信:在分布式训练和基于云的部署中,网络带宽和延迟变得重要。高效的网络通信意味着减少在分布式系统节点之间或云端与用户之间传输的数据量,这对训练时间和实时应用的响应性有重大影响。
2. 技术分类
此外,该综述还引入了一个结构化的分类法,将提升 LLM 资源效率的技术分为明确、定义清晰的层级。其中包括五个主要类别:架构设计、预训练、微调、推理和系统设计。每个类别都在高效 LLM 开发和部署的生命周期中扮演着不可或缺的角色。
- 架构设计:检查 LLM 的结构基础,分为基于 Transformer 和非 Transformer 架构。
- 预训练:审视 LLM 开发的初步阶段,包括内存效率和数据效率。
- 微调:针对预训练模型的优化,分为参数高效微调和全参数微调。
- 推理:在操作阶段,采用各种策略,如模型压缩和动态加速。
- 系统设计:关注系统层面的考虑,包括部署优化和支持基础设施等。
这个分类法旨在提供对多样化方法和策略的结构化和细致理解。这些方法和策略用于提升 LLM 的效率和加速,为当前研究领域提供了一个全面的视角。
三、方法论
1. 大型语言模型架构设计的新进展
该综述重点探讨了大型语言模型(LLM)的两大架构设计方向:高效的 Transformer 结构和非 Transformer 架构。
- 高效的 Transformer 结构:这一类别包括了通过创新技术优化 Transformer 模型的架构,旨在降低计算和内存需求。例如,Reformer 通过局部敏感哈希技术来改进注意力机制,而 Linear Transformer 则利用线性映射来减少计算复杂度。AFT 和 KDEFormer 等其他方法则通过不同方式实现时间和内存效率的大幅提升。
- 非 Transformer 架构:这一类别探索了替代 Transformer 的新型架构。例如,模块化网络(MoE)技术通过结合多个专业化模型来处理复杂任务,Switch Transformer 和 GLaM 等则利用稀疏路由技术在增加模型参数的同时保持效率。另外,像 RWKV 这样的架构则结合了 Transformer 的训练效率和 RNN 的推理效率。
这些创新方向不仅优化了 LLM 的资源效率,也推动了语言模型技术的整体发展。
2. 大型语言模型预训练:效率与创新
该综述探索了 GPT-4 等大型语言模型(LLM)的高效预训练策略,这些策略不仅注重速度,还着眼于计算资源的最优利用和创新的数据管理。
- 内存效率
- 分布式训练:将模型训练任务分配给多个节点,以加速训练过程。数据并行(DP)和模型并行(MP)是两种主要的策略。DP 通过将初始数据集分割并由多个加速器并行训练,而 MP 则将模型的层或张量分布到多个加速器上。
- 混合精度训练:这种技术通过同时使用 16 位和 32 位浮点类型来加速深度学习模型的训练,特别适用于大型语言模型的训练。
- 数据效率
- 重要性采样:这种方法通过优先处理信息丰富的训练实例来提高模型的数据效率。
- 数据增强:通过创建现有数据的修改副本,使当前数据得到充分利用。
- 训练目标:预训练目标的选择是决定数据效率的另一个因素。这通常涉及模型架构、输入 / 目标构建和遮蔽策略的设计。
通过这些策略,综述旨在展示如何以资源高效的方式预训练大型语言模型,不仅加速了训练过程,还确保了先进 LLM 的可持续和成本效益发展。
3. 大型语言模型微调:平衡性能与资源
该综述探讨了 GPT-4 等大型语言模型在特定任务上的微调策略。这些策略旨在在实现任务特定性能和维持资源效率之间找到平衡点。
- 参数高效微调
- 基于遮蔽的微调:仅更新模型参数的子集,其他参数在反向传播过程中被「冻结」或遮蔽。
- 基于适配器的微调:在预训练模型的现有层之间插入额外的轻量级层(适配器)。在微调期间,只更新这些适配器层的参数,而原始模型参数保持固定。
- 全参数微调:与参数高效微调不同,全参数微调涉及修改所有参数。尽管训练成本更高,但通常可以获得比参数高效方法更好的性能。然而,这种方法在简单数据集上可能并不总是有效,且在训练成本和 GPU 内存消耗方面也面临挑战。
通过这些策略,综述旨在展示如何在保证大型语言模型性能优化和资源限制之间达到平衡的微调方法。
4. 大型语言模型推断:追求效率与质量
该综述探讨了如 GPT 系列的大型语言模型在推断阶段的优化技术,重点是减少计算负载和内存使用,同时保持高质量输出。
- 模型压缩
- 剪枝:通过移除模型中的特定参数来降低复杂度。包括结构化剪枝(针对整体结构,如神经元或通道)和非结构化剪枝(针对单个权重或连接)。
- 量化:将模型中的浮点数转换为较少位数的表示(如整数),旨在减少模型存储需求和加快计算速度。
- 知识蒸馏:将大型模型的知识转移到更紧凑的网络中,以减少推断延迟并增强特定任务解决能力。
- 动态加速
- 早期退出:根据某些标准提前终止模型的某些层的计算,用于简化输入样本的处理。
- 输入裁剪:动态减少输入序列长度,根据内容来分配不同的计算资源给不同的输入标记。
- 标记并行:利用技术如推测执行来并行生成多个标记,而非传统的顺序方式。
通过这些策略,综述旨在展示如何在实际应用中高效部署大型语言模型,同时考虑资源限制和性能需求。
5. 大型语言模型的系统设计:优化与应用
该综述探讨了如 GPT 系列的大型语言模型在系统设计方面的关键策略,特别是在资源受限环境中的高效推断。
- 部署优化
- 硬件卸载:通过将临时不需要的数据从快速加速器转移到更慢但更大的主、辅存储(如 CPU 内存和磁盘)中,优化大型 LLM 的运行效率。有效的卸载策略对整体系统效率至关重要。
- 协作推断:多个用户或系统合作完成 LLM 的推断任务,每个参与者贡献自己的资源,如计算能力或数据,以克服个体用户或系统的限制,实现更高效、准确的推断。
- 支持基础设施
- 库:介绍了几个著名的大型语言模型框架,如 DeepSpeed、Megatron-LM、Colossal-AI、Mesh-TensorFlow 和 GPT-NeoX,它们为大规模分布式训练提供多级并行策略。
- 边缘设备:探索在边缘设备上部署 LLM 的研究趋势,这些设备通常具有有限的计算资源。例如,通过低秩适应和噪声对比估计等技术来降低 LLM 在边缘设备上的内存需求。
- 其他系统
- Tabi:提出了一个多级推断引擎的推断系统,通过使用多个 DNN 处理任务中的异构查询来减少 LLM 的推断延迟。
- 近重复序列搜索:利用最小哈希技术来提高 LLM 的近重复序列搜索的效率和可扩展性。
通过这些策略,综述旨在展示大型语言模型在各种部署场景中的系统设计如何实现效率和可扩展性的最大化。
四、大型语言模型资源效率技术分类总结
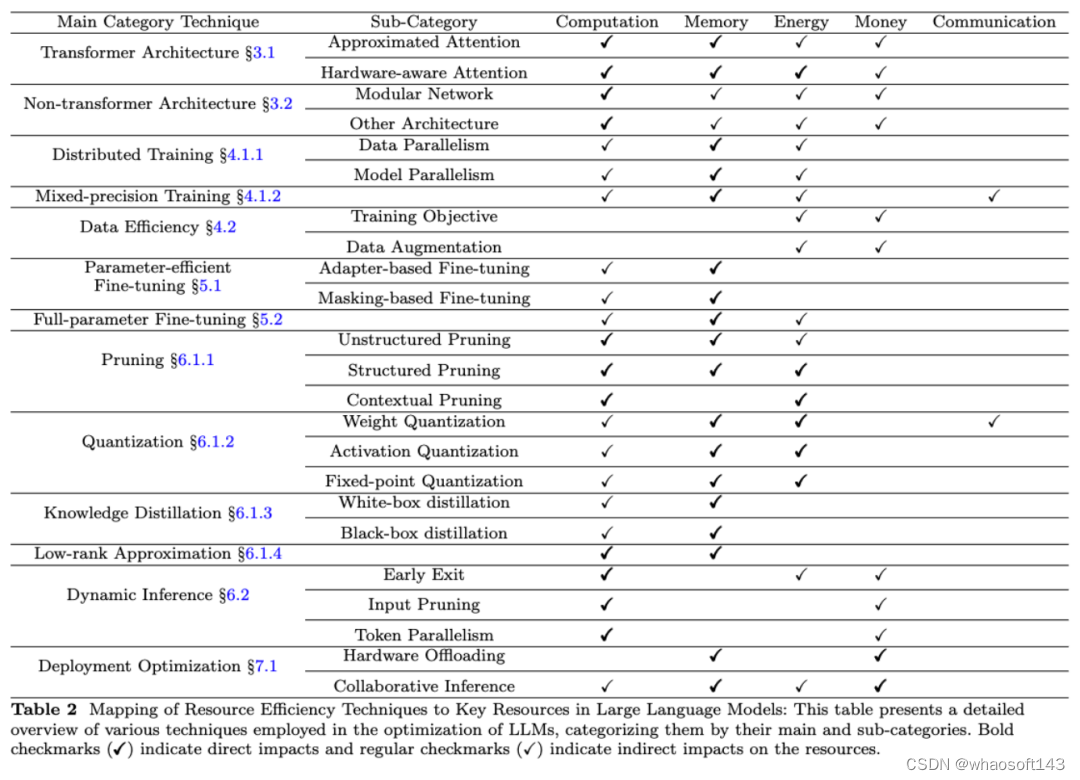
该综述探讨了应用于大型语言模型(LLM)以提升其在不同资源上的效率的多种技术。这些资源包括计算、内存、能源、财务成本和网络通信。每项技术在优化 LLM 资源效率方面扮演着重要角色。
计算效率
- 直接影响:包括具有近似和硬件感知注意力机制的变换器架构,通过简化计算密集的注意力计算来加速过程;非结构化、结构化和上下文剪枝,通过移除不重要的权重或神经元来减少冗余计算。
- 间接影响:数据并行和参数高效微调,通过分布式工作负载和减少参数更新分别间接提高计算效率。
内存效率
- 直接影响:剪枝和量化通过减少模型大小来显著节约内存;知识蒸馏通过训练较小的模型来模仿较大的模型。
- 间接影响:分布式训练,如数据和模型并行,有效管理多设备间的内存使用,减轻单个设备的负担。
能源效率
- 直接影响:结构化剪枝和量化通过减少操作数量和数据大小,降低训练和推断的能源消耗;上下文剪枝通过最小化不必要的计算来节省能源。
- 间接影响:近似注意力机制等主要面向计算效率的技术,由于减少了计算负载,间接促进能源节省。
财务成本效率
间接影响:数据效率方法,如优化的训练目标和数据增强,通过提高数据使用效果,可能缩短训练时间,减少计算资源使用;动态推断技术,如早期退出和输入裁剪,通过减少推断阶段的运算需求,降低整体部署成本。
网络通信效率
- 直接影响:混合精度训练通过减少处理器间需要通信的数据大小,直接影响数据传输效率;权重量化通过最小化通信过程中的数据负载。
- 间接影响:协作推断通过优化数据传输和处理来提高网络通信效率。
通过这些策略,该综述旨在展示如何通过多种技术提高大型语言模型在各种资源上的效率。详细的技术与资源的对应关系可见下表。
五、大型语言模型评估数据集和指标
该综述详细分析了评估大型语言模型(LLM)资源效率的多元化指标,这些指标为全面理解 LLM 的资源效率提供了关键指导。
计算效率指标
- FLOPs:浮点运算次数,量化计算效率。
- 训练时间:训练 LLM 所需的总时间,反映了模型复杂性。
- 推断时间 / 延迟:LLM 生成输出所需的时间,关键评估实际应用中的实用性。
- 吞吐量:LLM 处理请求的效率,以每秒生成的标记或完成任务的速度衡量。
- 加速比:与基准模型相比推断速度的改善程度。
- 内存效率指标
- 参数数量:LLM 神经网络中可调变量的数量。
- 模型大小:存储整个模型所需的存储空间。
能源效率指标
- 能源消耗:以瓦时或焦耳表示,反映 LLM 生命周期中的电力使用。
- 碳排放:与模型能源使用相关的温室气体排放量。
财务成本效率指标
每参数成本:训练(或运行)LLM 的总成本除以参数数量的比值。
网络通信效率指标
通信量:在特定 LLM 执行或训练过程中网络间传输的数据总量。
其他指标
- 压缩比:压缩模型与原始模型大小的比例。
- 忠诚度和保真度:衡量教师和学生模型之间预测一致性和预测概率分布对齐程度。
- 鲁棒性:衡量 LLM 对攻击后性能和查询次数。
- 帕累托最优性:在不同竞争因素间取得的最佳平衡。
数据集和基准测试
- Dynaboard:动态基准,评估内存使用、吞吐量、公平性和鲁棒性等指标。
- EfficientQA:聚焦建立准确、内存高效的开放领域问答系统。
- SustaiNLP 2020:挑战参与者开发能源高效的 NLP 模型。
- ELUE 和 VLUE:专注于评估 NLP 和视觉语言模型的效率和性能。
- Long-Range Arena:专为评估长内容任务上高效 Transformer 模型而设计。
- Efficiency-aware MS MARCO:在 MS MARCO 信息检索基准测试中增加了效率指标。
通过这些策略,该综述旨在提供一种全面评估大型语言模型资源效率的方法论。
六、大型语言模型的未来挑战和研究方向
随着大型语言模型(LLM)领域的不断进步,我们面临着多种开放性挑战,这些挑战为未来的研究方向提供了丰富的机遇。
处理资源类型的冲突:不同优化技术之间存在性能指标的权衡,如计算效率与模型参数数量的矛盾。关键挑战在于开发全面优化策略,平衡计算效率、参数计数和内存使用等多个目标。
资源效率技术的综合:有效整合多种 LLM 优化方法以增强总体资源效率是一个显著挑战。目前缺乏对这些方法如何协同作用的研究,需要系统地结合不同策略,以显著提高模型效率。
标准化和统一评估:当前缺乏专门评估 LLM 资源效率的统一标准基准。这导致无法全面一致地评估各种 LLM 在资源利用方面的表现,迫切需要专注于资源效率的标准化基准。
可解释性和鲁棒性:在追求效率的同时,也需关注 LLM 的可解释性和鲁棒性。开发既优化资源使用又保持透明度和弹性的方法,确保这些模型在不同部署场景中可靠且易于理解。
自动化机器学习(AutoML)在资源高效 LLM 中的应用:将 AutoML 集成到资源高效 LLM 的开发中是一个新兴领域。通过应用 Meta-Learning 和神经架构搜索(NAS),自动化模型优化的部分,有望减少手动超参数调整和定制模型设计的需求。
边缘计算中的 LLM:在边缘计算环境中部署 LLM 面临独特挑战,如设备的计算能力和内存资源限制。需要开发既资源高效又考虑隐私问题的 LLM 技术,以适应边缘计算场景。
理论洞察 LLM 的扩展规律:深入理解 LLM 性能如何随其规模和复杂性扩展是一个关键且未被充分探索的领域。这种理解对于开发不仅专注于模型压缩,而是针对提高 LLM 整体资源效率的方法至关重要。
七、结论
本综述深入探讨了大型语言模型(LLM)的资源效率问题,分析了当前的研究成果和挑战,并展望了未来的发展方向。它还讨论了 LLM 在计算、内存、能源、财务成本和网络通信等关键资源方面的高效技术,以及这些技术如何相互作用以提高整体效率。通过对比各种技术,综述揭示了它们在不同应用环境中的潜力和限制。
作者还强调了在资源效率评估中建立标准化和统一的评价体系的重要性。这不仅有助于更准确地比较不同 LLM 的性能,也为进一步的研究和开发提供了坚实的基础。
最后,综述探讨了 LLM 领域面临的一系列开放性挑战和潜在的研究方向,包括管理资源类型的冲突、综合资源效率技术、可解释性和鲁棒性、AutoML 的集成以及在边缘计算环境中部署 LLM。这些挑战提供了未来研究的丰富机遇,对于推动 LLM 向更高效、更可靠和更可持续的方向发展至关重要。
本综述为理解和优化 LLM 的资源效率提供了全面的视角,为未来在这一重要领域的研究提供了指导和灵感。
......
#量子计算机+大语言模型
本来不想发的, 我们那个可笑的片子安全公司 ,弄俩了个傻子 天天大模型和抗量子 就发发, 这是登Nature子刊,滑铁卢大学团队评论「量子计算机+大语言模型」当下与未来
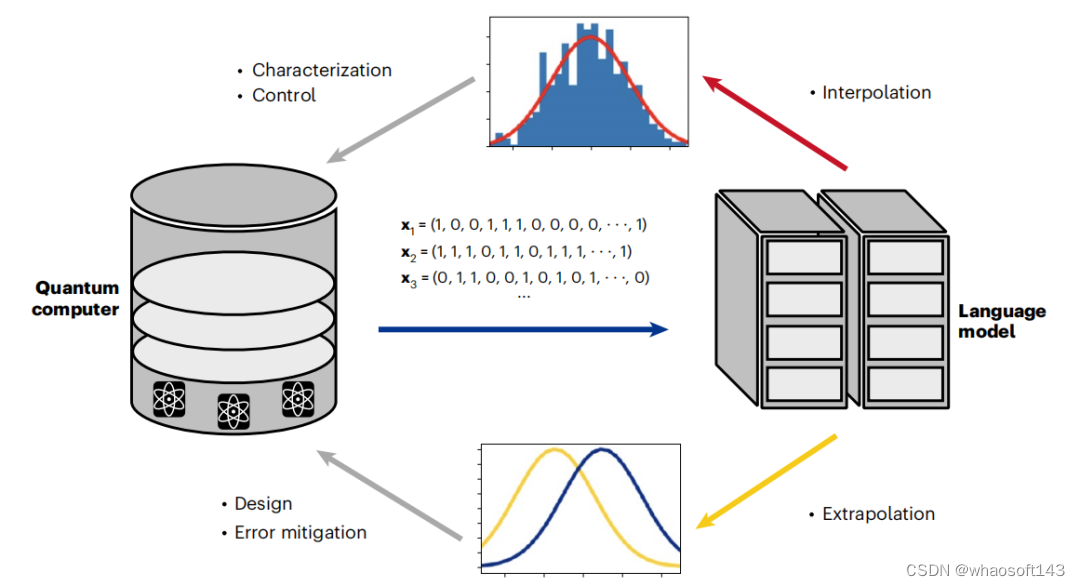
模拟当今量子计算设备的一个关键挑战,是学习和编码量子比特之间发生的复杂关联的能力。基于机器学习语言模型的新兴技术已经显示出学习量子态的独特能力。
近日,加拿大滑铁卢大学的研究人员在《Nature Computational Science》发表题为《Language models for quantum simulation》 的 Perspective 文章,强调了语言模型在构建量子计算机方面所做出的贡献,并讨论了它们在量子优势竞争中的未来角色。
论文链接:https://www.nature.com/articles/s43588-023-00578-0
量子计算机已经开始成熟,最近许多设备都声称具有量子优势。经典计算能力的持续发展,例如机器学习技术的快速崛起,引发了许多围绕量子和经典策略之间相互作用的令人兴奋的场景。随着机器学习继续与量子计算堆栈快速集成,提出了一个问题:它是否可以在未来以强大的方式改变量子技术?
当今量子计算机提出的一个关键挑战是量子态的学习。近年来迅速进入该领域的生成模型给出了学习量子态的两种广泛策略。

图示:自然语言及其他领域的生成模型。(来源:论文)
首先,通过代表量子计算机测量输出的数据集,数据驱动的学习通过传统的最大似然方法进行。其次,量子态可以通过所谓的物理学方法来解决,该方法利用量子比特之间相互作用的知识来定义替代损失函数。
无论哪种情况,量子态空间(希尔伯特空间)的大小都会随着量子比特数量 N 呈指数增长,这是典型的维数灾难。这对于扩展模型中表示量子态所需的参数数量以及寻找最佳参数值的计算效率提出了严峻的挑战。基于人工神经网络的生成模型非常适合应对这一挑战。
语言模型是一种特别有前途的生成模型,它已成为解决高复杂性语言问题的强大架构。由于其可扩展性,也适用于量子计算中的问题。如今,随着工业语言模型进入数万亿个参数的范围,人们很自然地想知道类似的大型模型在物理学中可以实现什么,无论是在扩展量子计算等应用中,还是在量子物质、材料和设备的基础理论理解中。
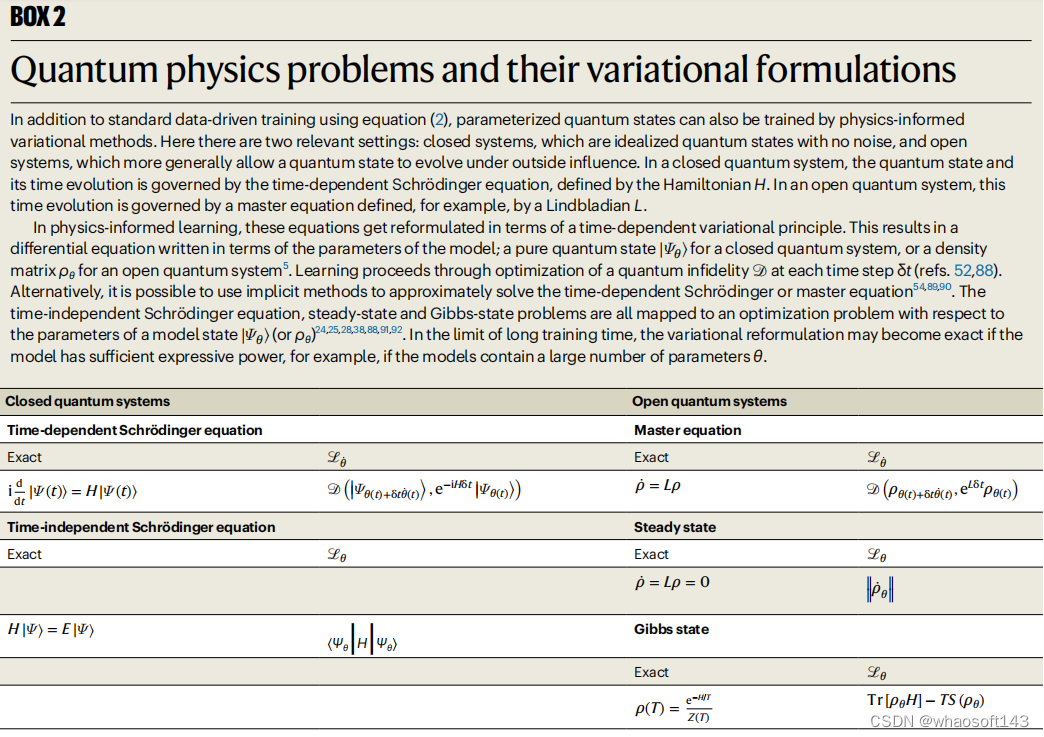
图示:量子物理问题及其变分公式。(来源:论文)
量子计算的自回归模型
语言模型是旨在从自然语言数据推断概率分布的生成模型。
生成模型的任务是学习语料库中出现的单词之间的概率关系,允许每次生成一个标记的新短语。主要困难在于对单词之间所有复杂的依赖关系进行建模。
类似的挑战也适用于量子计算机,其中纠缠等非局部相关性会导致量子比特之间高度不平凡的依赖性。因此,一个有趣的问题是,工业界开发的强大自回归架构是否也可以应用于解决强相关量子系统中的问题。
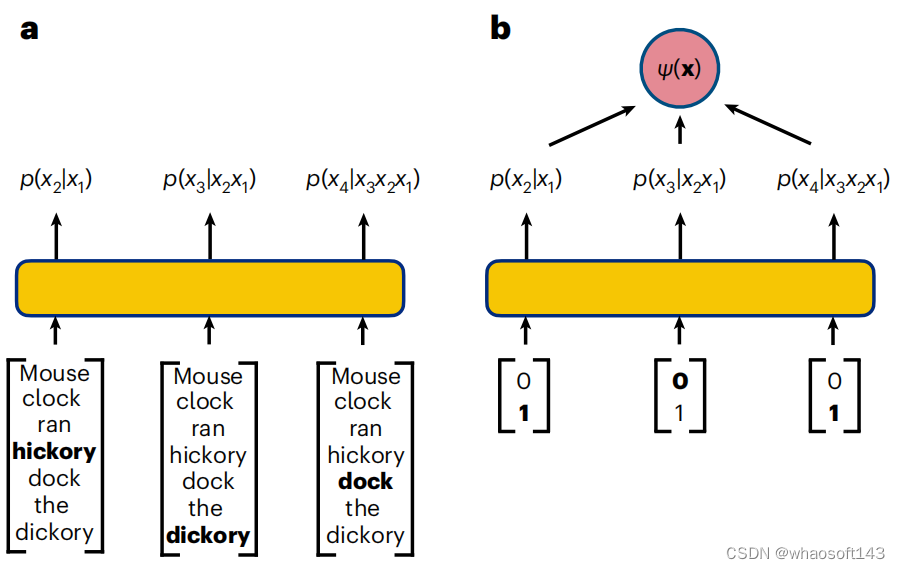
图示:文本和量子比特序列的自回归策略。(来源:论文)
RNN 波函数
RNN 是任何包含循环连接的神经网络,因此 RNN 单元的输出取决于先前的输出。自 2018 年以来,RNN 的使用迅速扩大,涵盖了理解量子系统中各种最具挑战性的任务。
RNN 适合这些任务的一个关键优势是它们能够学习和编码量子比特之间高度重要的相关性,包括本质上非局域的量子纠缠。
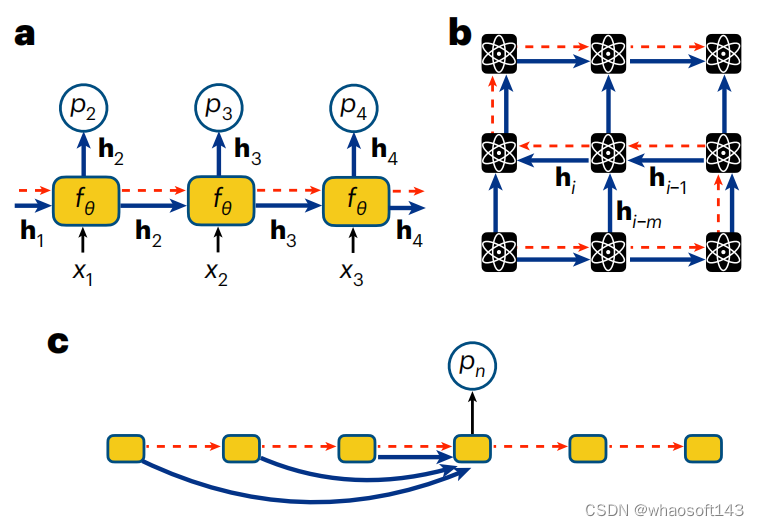
图示:用于量子比特序列的 RNN。(来源:论文)
物理学家已将 RNN 用于与量子计算相关的各种创新用途。RNN 已用于根据量子比特测量重建量子态的任务。RNN 还可以用于模拟量子系统的动态特性,这被认为是量子计算最有前途的应用之一,因此也是定义量子优势的一项关键任务。RNN 已被用作构建神经纠错解码器的策略,这是容错量子计算机开发的关键要素。此外,RNN 能够利用数据驱动和物理启发的优化,从而在量子模拟中实现越来越多的创新用途。
物理学家社区继续积极开发 RNN,希望利用它们来完成量子优势时代遇到的日益复杂的计算任务。RNN 在许多量子任务中与张量网络的计算竞争力,加上它们利用量子比特测量数据的价值的天然能力,表明 RNN 将继续在未来模拟量子计算机的复杂任务中发挥重要作用。
Transformer 量子态
多年来,虽然 RNN 在自然语言任务中取得了巨大成功,但最近它们在工业中因 Transformer 的自注意力机制而黯然失色,而 Transformer 是当今大型语言模型 (LLM) 编码器-解码器架构的关键组成部分。
缩放(scaling ) Transformer 的成功,以及它们在语言任务中所展示的非平凡涌现现象所引发的重要问题,一直吸引着物理学家,对他们来说,实现缩放是量子计算研究的主要目标。
从本质上讲,Transformer 就是简单的自回归模型。然而,与 RNN 不同的是,RNN 是通过隐藏向量进行相关性的隐式编码,Transformer 模型输出的条件分布明确依赖于序列中有关自回归特性的所有其他变量。这是通过因果屏蔽的自注意力机制来完成的。
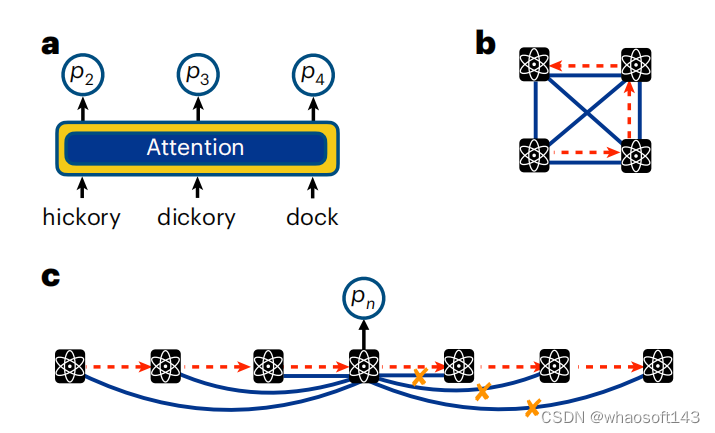
图示:注意文本和量子比特序列。(来源:论文)
与语言数据一样,在量子系统中,注意力是通过获取量子比特测量值并通过一系列参数化函数进行转换来计算的。通过训练一堆这样的参数化函数,Transformer 可以学习量子比特之间的依赖关系。有了注意力机制,就不需要将传递隐藏状态的几何结构(就像在 RNN 中一样)与量子比特的物理排列相关联。
通过利用这种架构,可以训练具有数十亿或数万亿参数的 Transformer。
对于当前一代量子计算机来说,结合数据驱动和物理启发学习的混合两步优化非常重要,已经证明了 Transformer 能够减轻当今不完美的输出数据中出现的错误,并可能形成强大的纠错协议的基础,以支持未来真正容错硬件的开发。
随着涉及量子物理 Transformer 的研究范围不断迅速扩大,一系列有趣的问题仍然存在。
量子计算语言模型的未来
尽管物理学家对它们的探索时间很短,但语言模型在应用于量子计算领域的广泛挑战时已经取得了显著的成功。这些成果预示着未来许多有前途的研究方向。
量子物理学中语言模型的另一个关键用例来自于它们的优化能力,不是通过数据,而是通过哈密顿量或 Lindbladian 的基本量子比特相互作用的知识。
最后,语言模型通过数据驱动和变分驱动优化的结合,开辟了混合训练的新领域。这些新兴的策略为减少错误提供了新的途径,并显示出对变分模拟的强大改进。由于生成模型最近已被改编为量子纠错解码器,混合训练可能为未来实现容错量子计算机的圣杯迈出了重要一步。这表明,量子计算机和在其输出中训练的语言模型之间即将出现良性循环。
图示:语言模型通过良性循环实现量子计算的扩展。(来源:论文)
展望未来,将语言模型领域与量子计算联系起来的最令人兴奋的机会在于它们展示规模和涌现的能力。
如今,随着 LLM 涌现特性的展示,一个新的领域已经被突破,提出了许多引人注目的问题。如果有足够的训练数据,LLM 是否能够学习量子计算机的数字副本?控制堆栈中包含语言模型,将如何影响量子计算机的表征和设计?如果尺度足够大,LLM 能否显示超导等宏观量子现象的出现?
当理论学家思考这些问题时,实验和计算物理学家已经开始认真地将语言模型应用于当今量子计算机的设计、表征和控制中。当我们跨越量子优势的门槛时,我们也进入了扩展语言模型的新领域。虽然很难预测量子计算机和 LLM 的碰撞将如何展开,但显而易见的是,这些技术相互作用所带来的根本性转变已经开始。
......
#大语言模型~优化架构
作者重点关注了基于 Transformer 的 LLM 模型体系结构在从预训练到推理的所有阶段中优化长上下文能力的进展。
ChatGPT 的诞生,让基于 Transformer 的大型语言模型 (LLM) 为通用人工智能(AGI)铺开了一条革命性的道路,并在知识库、人机交互、机器人等多个领域得到应用。然而,目前存在一个普遍的限制:由于资源受限,当前大多 LLM 主要是在较短的文本上进行预训练,导致它们在较长上下文方面的表现较差,而长上下文在现实世界的环境中是更加常见的。
最近的一篇综述论文对此进行了全面的调研,作者重点关注了基于 Transformer 的 LLM 模型体系结构在从预训练到推理的所有阶段中优化长上下文能力的进展。
论文链接:https://arxiv.org/pdf/2311.12351.pdf
论文首先分析了使用当前基于 Transformer 的模型处理长上下文输入和输出的问题。然后,提供了一个全面的分类体系,以指导 Transformer 架构升级的领域,来解决这些问题。作者对长上下文 LLM 广泛使用的评估需求进行了调研,包括数据集、度量标准和基准模型,以及一些令人惊奇的优化工具包,如库、系统和编译器,以增强 LLM 在不同阶段的效率和功效。最后,文章进一步讨论了这一领域未来研究的主要挑战和潜在方向。作者还建立了一个仓库,汇总了相关文献,并提供实时更新 https://github.com/Strivin0311/long-llms-learning。
综述概览
文章从基本的语言建模目标 (第 2.1 节) 开始,内容涵盖从典型的建模阶段到在基于 Transformer 的仅解码 LLM 中找到的关键架构模块,如图 1 (a) 所示。随后,作者对 LLM 在遇到扩展上下文窗口时的架构限制进行了简要分析 (第 2.2 节)。最后提出了一个全面的方法论分类法 (第 2.3 节),旨在通过架构创新增强 LLM 的长上下文能力 (见图 1 (b))。这个分类法作为文章的第 3、4、5、6、7 节的指南。
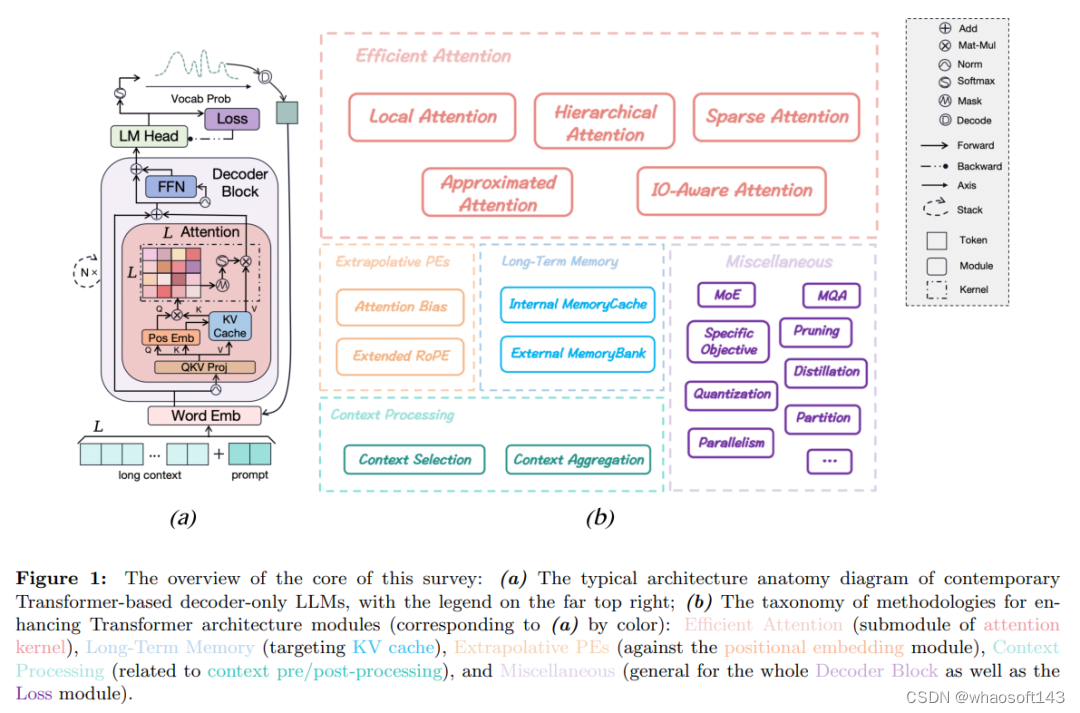
图 1:文章核心概述:(a) 现代基于 Transformer 的仅解码 LLMs 的典型架构解剖图,右上角有图例;(b) 用于增强 Transformer 架构模块的方法论分类法(与 (a) 相对应的颜色):高效注意力(注意力核心的子模块),长期记忆(针对 KV 缓存),外推性 PEs(针对位置嵌入模块),上下文处理(与上下文预 / 后处理有关)和杂项(整个解码器块以及损失模块通用)。
长上下文,目前有哪些难点待突破?
注意力复杂度。在典型情况下 L ≫ d,MHA 的计算复杂性可以简洁总结如下:它涉及 O (L 2d) 的时间复杂度,包括 QKV 投影的 O (Ld2),计算 P 的 O (L 2d),通过 softmax 运算获取 A 的 O (L 2 ),A 与 V 相乘的 O (L 2d),以及输出投影 O 的 O (Ld2)。它还产生 O (L 2) 的空间复杂度,包括 Q、K、V、O 的嵌入的 O (Ld),以及额外的 O (L 2) 缓冲区用于存储权重 P 和 A。因此,随着序列长度的增加,时间和空间计算成本都呈二次增加,这对于训练和推理可能都是繁重的。
上下文记忆。LLM 缺乏显式的记忆机制,完全依赖 KV 缓存来存储列表中所有先前 token 的表示。这种设计一旦在一个调用中完成查询,Transformer 在后续的调用中不会保留或召回任何先前的状态或序列,除非整个历史记录逐个 token 重新加载到 KV 缓存中。因此,Transformer 在每个调用中仅具有一个上下文工作记忆,而不是像长短时记忆 (LSTM) 这样的内在记忆机制。这种无状态性在并行性方面提供了计算优势,但在聊天机器人应用等需要长期记忆保留的任务中的挑战很明显。
最大长度约束。在训练阶段,工程师通常需要确定一个关键的超参数 max-length,本文中表示为 L_max。这个超参数代表了批次中任何训练样本的序列长度的上限,通常根据可用的计算资源设置为 1k、2k 或 4k,以避免在 GPU 上发生内存溢出 (OOM) 错误。在推理阶段,LLM 的服务提供者还必须限制用户提示的长度或自动截断它们以与预定义的 L_max 对齐,即使推理资源通常比训练阶段更丰富。需要注意的是 Transformer 的任何模块在本质上都不需要这样的限制,因为所有学习的权重仅依赖于维度大小。因此,理论上只要资源足够,Transformer 可以处理任意长度的序列。然而,当前的语言模型在处理超过 L_max 的输入序列时通常表现出明显的性能下降,经常导致重复和不切实际的输出。
改进的新方法
对于上述限制,有多种改进方法可以探索,例如在训练过程中减少注意力复杂性、设计高效的记忆机制,以及增强长度外推的能力,该模型在短序列上进行训练,但在推理过程中对更长的序列进行测试。
因此,论文全面回顾了致力于改进 LLM 长上下文能力的各个阶段的最新方法,并将它们组织成一个统一的分类法,如图 1 (b) 所示。具体而言,这些方法被分为五个主要的类别,如下:
高效注意力 (论文第 3 节):这些方法侧重于实现具有降低计算要求的高效注意力机制,甚至实现了线性复杂度。通过这样做,它们能够通过直接在预训练阶段增加 L_max 来推进 LLM 在推理期间的有效上下文长度边界。
长期记忆 (论文第 4 节):为了解决上下文工作记忆的局限性,一些方法旨在设计明确的记忆机制,弥补 LLM 中缺乏高效和有效的长期记忆的不足。
外推性 PEs (论文第 5 节):最新的研究致力于通过改进现有位置编码方案的外推性能来增强 LLM 的长度泛化能力。
上下文处理 (论文第 6 节):除了增强特定低级 Transformer 模块的方法外,一些方法涉及对现成的 LLM 与额外的上下文预 / 后处理。这些方法确保每次调用 LLM 时输入始终满足最大长度要求,并通过引入多个调用开销打破上下文窗口限制。
杂项 (论文第 7 节):探讨了各种一般且有价值的方法,这些方法不容易归入前面四类,为推进 LLM 的长上下文能力提供了更广泛的视角。
未来方向
论文的第 3、4、5、6 节中讨论了该领域取得的显著进展,但仍然存在一些挑战。下面是对一些关键挑战的探讨以及未来在增强基于 Transformer 的 LLM 的长上下文能力方面进行研究和开发的潜在方向,重点关注架构的增强。
注意力 Trade-off。在第 3 节,作者探讨了高效注意方法往往涉及在保持全尺度注意力依赖性(例如局部注意力)或通过近似注意力提高注意力分数精度以减轻标准注意内核的计算需求之间的微妙权衡。然而,随着上下文的延长,话语结构和相互关联的信息变得越来越复杂,需要捕捉全局、长距离的依赖性,同时保持精确的相关性。
解决这一挑战需要在计算效率和尽可能保留注意模式精度之间找到最佳平衡。因此,在长上下文 LLM 领域,这仍然是一个持续追求的目标。最近的创新如 Flash Attention,探索了算法级别之外的 IO 感知解决方案,极大地提高了运行时和记忆开销的效率,而不会丧失注意精度。这是在实际应用中解决这个问题的一个激动人心的潜在途径。此外,可以探索在「即插即用」替代方案中集成先前的高效策略,利用强大的 GPU 内核编程工具 (如 CUDA) 或更轻量级的 Triton。
记忆效果和效率。正如在文章第 2.1、2.2 节中前面讨论的,作者已经概述了由于缺乏明确的记忆机制,仅依赖上下文内工作记忆以及在延长上下文交互期间 KV 缓存记忆消耗显著增加而产生的限制。这些挑战共同强调了在基于 Transformer 的 LLM 领域需要更有效和高效的记忆机制。虽然第 4 节中引入了各种长期记忆机制,但它们受到其复杂启发式设计引入的额外记忆开销的限制,因此随着时间的推移可能导致性能下降。为了解决这一挑战,研究人员可以从最近的进展中汲取灵感,比如 Paged Attention,研发更有效的记忆存储策略,增强读 / 写吞吐量。
长度外推挖掘。在第 5 节中,作者对与基于 Transformer 的模型的长度外推相关的挑战进行了彻底的分析,重点关注了位置嵌入的普遍设计。文章提供了对最近突破的全面概述,特别是应用于 RoPE 的扩展策略,作者相信这在解决外推限制方面具有重要的前景。值得注意的是,这些进步往往依赖于对复杂高维位置嵌入属性的简化观察,并包含简单的启发式调整。作者对使用高维嵌入来建模序列性的理论基础提出质疑,并探索在这些启发式设计的指导下引导具有许多超参数的可学习嵌入的潜在复苏。作者认为未来的研究应该深入探讨这一领域,尤其是在 Transformer 设置下为建模序列性开发健壮的理论框架方面,比如 CLEX 所实现的内容。
特定但通用目标。前文已经为长文本建模量身定制的具体目标做了讨论,但值得注意的是,许多目标仅限于某些类型的任务,或者仅与 MLM 目标兼容,而不是如今更普遍的 CLM 目标。这突显了需要特定但普遍适用的因果语言建模目标,可以在模型训练的早期有效捕捉长距离依赖性。通过与先前提到的目标相一致,这是可能实现的。
可靠的度量需求。在评估度量方面,文章的第 8 节中研究了许多可选项。根据在评估中的先前经验,常用的度量,如 ROUGE 分数,与人类判断分数存在显著差异,后者可以看作是「神谕」。随着 LLM 在现实世界场景中的快速部署,越来越迫切地需要更可靠的度量来评估长上下文能力,特别是在生成性任务中,其中精确的真实性难以捉摸。一个有希望的途径涉及利用最先进的 LLM (如 GPT4) 的鲁棒性作为人类评审的替代,尽管相关的高成本仍然在更广泛地在研究界中采用方面带来挑战。
......
#大模型加速~
2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。
最近,一位名为 Theia Vogel 的博主整理撰写了一篇长文博客,对加速 LLM 推理的方法进行了全面的总结,对各种方法展开了详细的介绍,值得 LLM 研究人员收藏查阅。
以下是博客原文内容。
之前,我使用经典的自回归采样器手动制作了一个 transformer,大致如下:
def generate(prompt: str, tokens_to_generate: int) -> str:
tokens = tokenize(prompt)
for i in range(tokens_to_generate):
next_token = model(tokens)
tokens.append(next_token)
return detokenize(tokens)这种推理方法很优雅,是 LLM 工作机制的核心。自回归 LLM 在只有数千个参数的情况下运行得很好,但对于实际模型来说就太慢了。为什么会这样,我们怎样才能让它更快?
本文整理了这个问题的解决方案,从更好的硬件利用率到巧妙的解码技巧。

为什么简单推理这么慢?
使用普通的自回归生成函数进行推理速度缓慢,主要有两个原因:算法原因和硬件原因。
从算法上讲,生成过程必须在每个周期处理越来越多的 token,因为每个周期我们都会将一个新 token 附加到上下文中。这意味着要从 10 个 token prompt 生成 100 个 token,需要在 10 + 11 + 12 + 13 + ... + 109 = 5950 个 token 上运行!(初始 prompt 可以并行处理,这就是为什么 prompt token 在推理 API 中通常更便宜的部分原因。)这也意味着模型在生成时会变慢,因为每个连续的 token 生成都有越来越长的前缀:
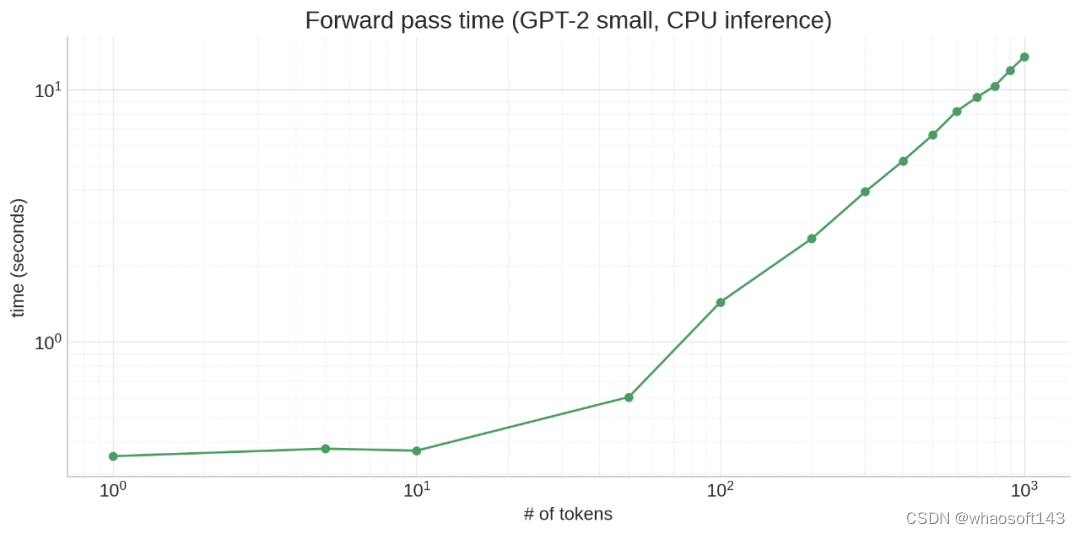
注意力(至少是普通注意力)也是一种二次算法:所有 token 都关注所有 token,导致 N^2 扩展,使一切变得更糟。
硬件原因是什么呢?很简单:LLM 规模很大。即使像 GPT-2 这样相对较小的模型也有 117M 参数,并且所有数据都必须存储在 RAM 中。RAM 确实很慢,现代处理器(CPU 和 GPU)通过在靠近处理器的地方设置大量高速缓存(cache)来弥补这一点,从而使访问速度更快。其细节根据处理器的类型和型号而有所不同,但关键是 LLM 权重不适合缓存,因此需要花费大量时间等待从 RAM 加载权重。这会产生一些不直观的效果!例如,即使激活张量(tensor)大 10 倍,对 10 个 token 进行操作也不一定比对单个 token 进行操作慢很多,因为主要的时间消耗在于移动模型权重,而不是进行计算。
指标
大模型推理速度「慢」到底是什么意思?谈到 LLM 推理,人们采用的指标有很多:
- Time to First Token(TtFT)—— 收到 prompt 和返回第一个 token 之间需要多长时间?
- 生成延迟 —— 收到 prompt 和返回最终 token 之间需要多长时间?
- 吞吐量
- 硬件利用率 —— 我们使用硬件的计算、内存带宽和其他功能的效率如何?
不同的优化对这些指标的影响不同。例如,批处理可以提高吞吐量并更好地利用硬件,但会增加 TtFT 和生成延迟。
硬件
加速推理的一个直接方法就是购买更好的硬件(通常是某种加速器 ——GPU 或 TPU),或者更好地利用您拥有的硬件。
使用加速器可以显著提高速度,但请记住,CPU 和加速器之间存在传输瓶颈。如果模型不适合加速器的内存,则需要在整个前向传播过程中进行交换,这会大大减慢速度。这也是 Apple M1/M2/M3 芯片在推理方面表现出色的原因之一 —— 它们具有统一的 CPU 和 GPU 内存。
关于 CPU 和加速器推理,另一个关键是充分利用硬件,适当优化程序。例如,在 PyTorch 中将注意力写入 F.softmax (q @ k.T/sqrt (k.size (-1)) + mask) @ v,能提供正确的结果,但如果使用 torch.nn.function.scaled_dot_product_attention,会将计算委托给可用的 FlashAttention,这可以更好地利用缓存的手写内核产生 3 倍的加速。
编译器
torch.compile、TinyGrad 和 ONNX 等编译器可以将简单的 Python 代码融合到针对硬件优化的内核中。例如,我可以编写以下函数:
def foo(x):
s = torch.sin(x)
c = torch.cos(x)
return s + c简单来说,这个函数需要:
1. x.shape () 为 s 分配的内存
2. 对 x 进行线性 scan 以计算每个元素的 sin
3. x.shape () 为 c 的另一种内存分配
4. 线性 scan x 以计算每个元素的 cos
5. x.shape () 为结果张量分配的内存
6. 线性 scan s 和 c,将它们添加到结果中
这些步骤每一个都很慢,并且某些步骤需要跨越 Python 和本机代码之间的界限。如果我使用 torch.compile 编译这个函数会怎样?
>>> compiled_foo = torch.compile(foo, options={"trace.enabled": True, "trace.graph_diagram": True})
>>> # call with an arbitrary value to trigger JIT
>>> compiled_foo(torch.tensor(range(10)))
Writing FX graph to file: .../graph_diagram.svg
[2023-11-25 17:31:09,833] [6/0] torch._inductor.debug: [WARNING] model__24_inference_60 debug trace: /tmp/...zfa7e2jl.debug
tensor([ 1.0000, 1.3818, 0.4932, -0.8489, -1.4104, -0.6753, 0.6808, 1.4109,
0.8439, -0.4990])如果进入 debug 跟踪目录并打开其中的 output_code.py 文件,torch 就会为 CPU 生成一个优化的 C++ 内核,将 foo 融合到单个内核中。如果使用 GPU 运行此程序,torch 将为 GPU 生成 CUDA 内核。
#include "/tmp/torchinductor_user/ib/cibrnuq56cxamjj4krp4zpjvsirbmlolpbnmomodzyd46huzhdw7.h"
extern "C" void kernel(const long* in_ptr0,
float* out_ptr0)
{
{
#pragma GCC ivdep
for(long i0=static_cast<long>(0L); i0<static_cast<long>(10L); i0+=static_cast<long>(1L))
{
auto tmp0 = in_ptr0[static_cast<long>(i0)];
auto tmp1 = static_cast<float>(tmp0);
auto tmp2 = std::sin(tmp1);
auto tmp3 = std::cos(tmp1);
auto tmp4 = tmp2 + tmp3;
out_ptr0[static_cast<long>(i0)] = tmp4;
}
}
}现在,步骤就变成了:
1. x.shape () 为结果张量分配的内存
2. 对 x (in_ptr0) 进行线性扫描,计算 sin 和 cos 并将它们相加到结果中
对于大输入来说更简单、更快!
>>> x = torch.rand((10_000, 10_000))
>>> %timeit foo(x)
246 ms ± 8.89 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
>>> %timeit compiled_foo(x)
91.3 ms ± 14 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# (for small inputs `compiled_foo` was actually slower--not sure why)请注意,torch.compile 将上面的代码专门用于传入 ((10,)) 的张量的特定大小。如果我们传入许多不同大小的张量,torch.compile 将生成超过该大小的通用代码,但具有恒定大小可以使编译器在某些情况下生成更好的代码。
这是 torch.compile 的另一个函数:
>>> x = torch.rand((10_000, 10_000))
>>> %timeit foo(x)
246 ms ± 8.89 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
>>> %timeit compiled_foo(x)
91.3 ms ± 14 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# (for small inputs `compiled_foo` was actually slower--not sure why)该函数具有数据相关的控制流,这意味着我们会根据变量的运行时值执行不同的操作。如果以与编译 foo 相同的方式编译它,我们会得到两个图(因此有两个 debug 目录):
>>> compiled_gbreak = torch.compile(gbreak, options={"trace.enabled": True, "trace.graph_diagram": True})
>>> compiled_gbreak(torch.tensor(range(10)))
Writing FX graph to file: .../model__27_inference_63.9/graph_diagram.svg
[2023-11-25 17:59:32,823] [9/0] torch._inductor.debug: [WARNING] model__27_inference_63 debug trace: /tmp/torchinductor_user/p3/cp3the7mcowef7zjn7p5rugyrjdm6bhi36hf5fl4nqhqpfdqaczp.debug
Writing FX graph to file: .../graph_diagram.svg
[2023-11-25 17:59:34,815] [10/0] torch._inductor.debug: [WARNING] model__28_inference_64 debug trace: /tmp/torchinductor_user/nk/cnkikooz2z5sms2emkvwj5sml5ik67aqigynt7mp72k3muuvodlu.debug
tensor([ 1.0000, -0.1756, 2.6782, -0.7063, -2.5683, 2.7053, 0.9718, 0.5394,
7.6436, -0.0467])第一个内核实现了函数的 torch.sin (x) + torch.cos (x) 和 r.sum () < 0 部分:
#include "/tmp/torchinductor_user/ib/cibrnuq56cxamjj4krp4zpjvsirbmlolpbnmomodzyd46huzhdw7.h"
extern "C" void kernel(const long* in_ptr0,
float* out_ptr0,
float* out_ptr1,
bool* out_ptr2)
{
{
{
float tmp_acc0 = 0;
for(long i0=static_cast<long>(0L); i0<static_cast<long>(10L); i0+=static_cast<long>(1L))
{
auto tmp0 = in_ptr0[static_cast<long>(i0)];
auto tmp1 = static_cast<float>(tmp0);
auto tmp2 = std::sin(tmp1);
auto tmp3 = std::cos(tmp1);
auto tmp4 = tmp2 + tmp3;
out_ptr0[static_cast<long>(i0)] = tmp4;
tmp_acc0 = tmp_acc0 + tmp4;
}
out_ptr1[static_cast<long>(0L)] = tmp_acc0;
}
}
{
auto tmp0 = out_ptr1[static_cast<long>(0L)];
auto tmp1 = static_cast<float>(0.0);
auto tmp2 = tmp0 < tmp1;
out_ptr2[static_cast<long>(0L)] = tmp2;
}
}第二个内核实现了 return r - torch.tan (x) 分支:
#include "/tmp/torchinductor_user/ib/cibrnuq56cxamjj4krp4zpjvsirbmlolpbnmomodzyd46huzhdw7.h"
extern "C" void kernel(const float* in_ptr0,
const long* in_ptr1,
float* out_ptr0)
{
{
#pragma GCC ivdep
for(long i0=static_cast<long>(0L); i0<static_cast<long>(10L); i0+=static_cast<long>(1L))
{
auto tmp0 = in_ptr0[static_cast<long>(i0)];
auto tmp1 = in_ptr1[static_cast<long>(i0)];
auto tmp2 = static_cast<float>(tmp1);
auto tmp3 = std::cos(tmp2);
auto tmp4 = tmp0 - tmp3;
out_ptr0[static_cast<long>(i0)] = tmp4;
}
}
}这就是所谓的「graph break」,这会让编译后的函数变慢,因为必须离开优化后的内核并返回到 Python 来评估分支。最重要的是,另一个分支(return r + torch.tan (x))尚未编译,因为它尚未被采用。这意味着它将在需要时动态编译,在不合适的时间(例如在服务用户请求的过程中)就会很糟糕。
理解 graph break 的一个方便工具是 torch._dynamo.explain:
# get an explanation for a given input
>>> explained = torch._dynamo.explain(gbreak)(torch.tensor(range(10)))
# there's a break, because of a jump (if) on line 3
>>> explained.break_reasons
[GraphCompileReason(reason='generic_jump TensorVariable()', user_stack=[<FrameSummary file <stdin>, line 3 in gbreak>], graph_break=True)]
# there are two graphs, since there's a break
>>> explained.graphs
[GraphModule(), GraphModule()]
# let's see what each graph implements, without needing to dive into the kernels!
>>> for g in explained.graphs:
... g.graph.print_tabular()
... print()
...
opcode name target args kwargs
------------- ------ ------------------------------------------------------ ------------ --------
placeholder l_x_ L_x_ () {}
call_function sin <built-in method sin of type object at 0x7fd57167aaa0> (l_x_,) {}
call_function cos <built-in method cos of type object at 0x7fd57167aaa0> (l_x_,) {}
call_function add <built-in function add> (sin, cos) {}
call_method sum_1 sum (add,) {}
call_function lt <built-in function lt> (sum_1, 0) {}
output output output ((add, lt),) {}
opcode name target args kwargs
------------- ------ ------------------------------------------------------ ----------- --------
placeholder l_x_ L_x_ () {}
placeholder l_r_ L_r_ () {}
call_function tan <built-in method tan of type object at 0x7fd57167aaa0> (l_x_,) {}
call_function sub <built-in function sub> (l_r_, tan) {}
output output output ((sub,),) {}
# pretty cool!像 torch.compile 这样的工具是优化代码以获得更好的硬件性能,而无需使用 CUDA 编写内核。
批处理
在生成的未优化版本中,我们一次向模型传递一个序列,并在每一步要求它附加一个 token:
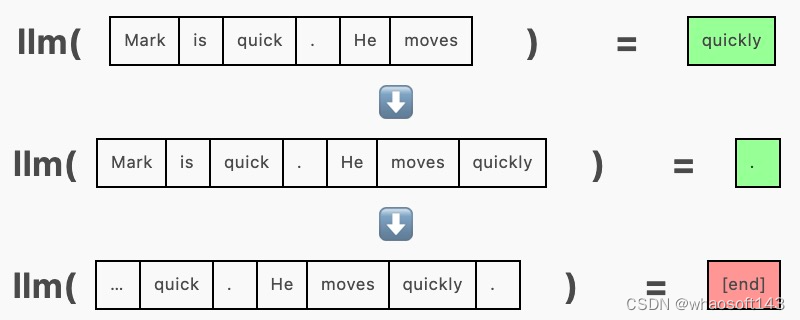
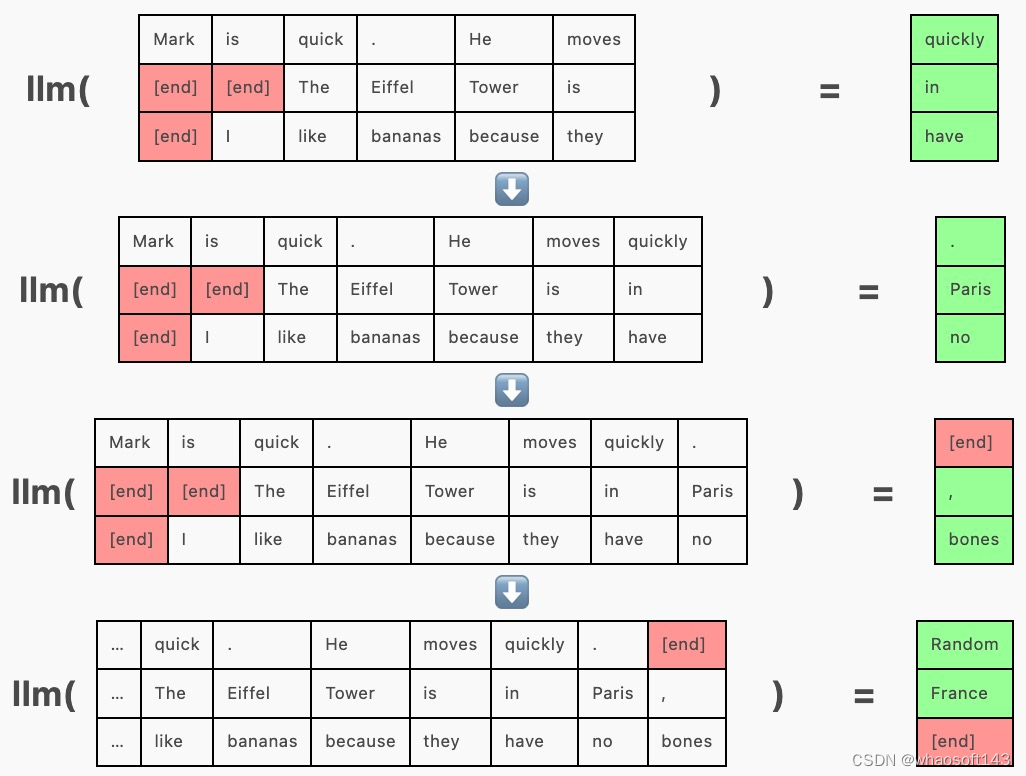
为了批量生成,我们一次向模型传递多个序列,在同一次前向传递中为每个序列生成一个补全。这需要使用填充 token 在左侧或右侧将序列填充到相等的长度。填充 token(这里使用 [end])被隐藏在注意力掩码中,这样它们就不会影响生成。
由于以这种方式批处理序列允许模型权重同时用于多个序列,因此一起运行整批序列比单独运行每个序列花费的时间更少。例如,在我的机器上,使用 GPT-2 生成下一个 token:
- 20 tokens x 1 sequence = ~70ms
- 20 tokens x 5 sequences = ~220ms (线性扩展~350ms)
- 20 tokens x 10 sequences = ~400ms (线性扩展~700ms)
连续批处理
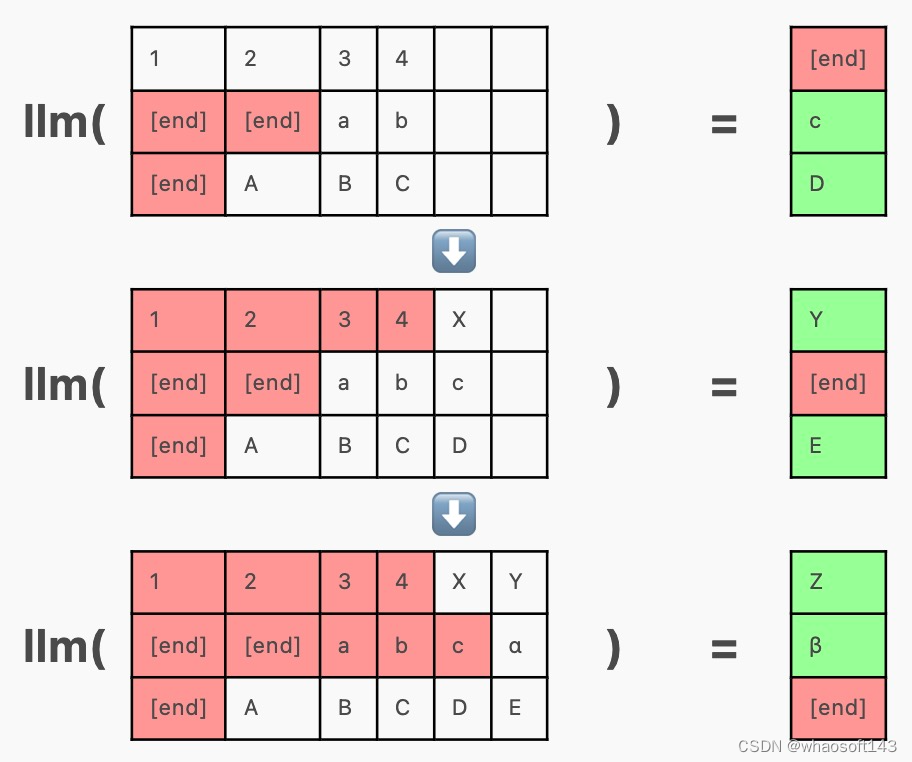
在上面的示例中,「Mark is quick. He moves quickly.」在其他序列之前完成,但由于整个批次尚未完成,我们需要继续为其生成 token("Random")。
连续批处理通过在其他序列完成时在其 [end] token 之后将新序列插入批处理来解决此问题。
缩小模型权重
浮点数有不同的大小,这对性能很重要。大多数情况下,对于常规软件,我们使用 64 位(双精度)IEEE 754 浮点,而 ML 传统上使用 32 位(单精度)IEEE 754:
>>> gpt2.transformer.h[0].attn.c_attn.weight.dtype
torch.float32模型使用 fp32 进行良好的训练和推理,这为每个参数节省了 4 个字节 (50%),这个影响是巨大的,例如 7B 参数模型在 fp64 中将占用 56Gb,而在 fp32 中仅占用 28Gb。训练和推理期间的大量时间都花在将数据从 RAM 移动到缓存和寄存器上 —— 移动的数据越少越好。
fp16(或半精度)显然可以再节省 50%!这里有两个主要选项:fp16 和 bfloat16(brain float)。
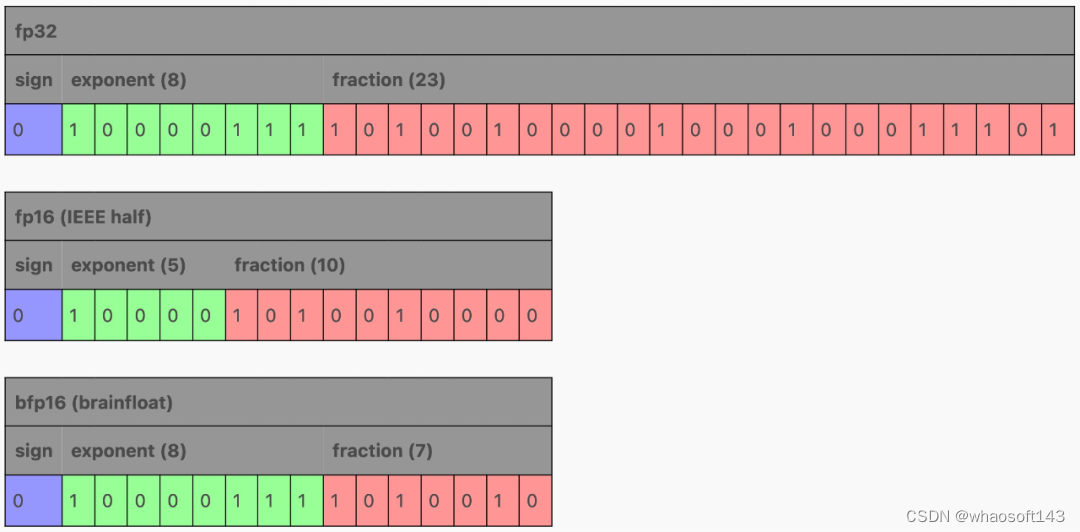
在减少 fp32 的字段时,fp16 和 bfloat16 进行了不同的权衡:fp16 试图通过缩小指数和分数字段来平衡范围和精度,而 bfloat16 通过保留 8 位指数来保留 fp32 的范围,同时将分数字段缩小到小于 fp16,损失了一些精度。范围损失有时可能会成为 fp16 训练的问题,但对于推理来说,两者都可以,如果 GPU 不支持 bfloat16,fp16 可能是更好的选择。
还能更小吗?当然可以!
一种方法是量化以更大格式(例如 fp16)训练的模型。llama.cpp 项目(以及相关的 ML 库 ggml)定义了一整套量化格式。
这些量化的工作方式与 fp16 /bfloat16 略有不同 - 没有足够的空间来容纳整个数字,因此权重以块为单位进行量化,其中 fp16 充当块尺度(scale),然后量化块每个权重都乘以该尺度。
bitsandbytes 还为非 llama.cpp 项目实现了量化。
然而,使用更广泛的参数训练的模型量化越小,它就越有可能影响模型的性能,从而降低响应的质量。因此我们要尽可能少地采用量化,才能获得可接受的推理速度。
但我们也可以使用小于 fp16 的数据类型来微调或训练模型,例如使用 qLoRA 训练量化低阶适配器。
KV cache
在 Transformer 内部,激活通过前馈层生成 qkv 矩阵,其中每一行对应一个 token:
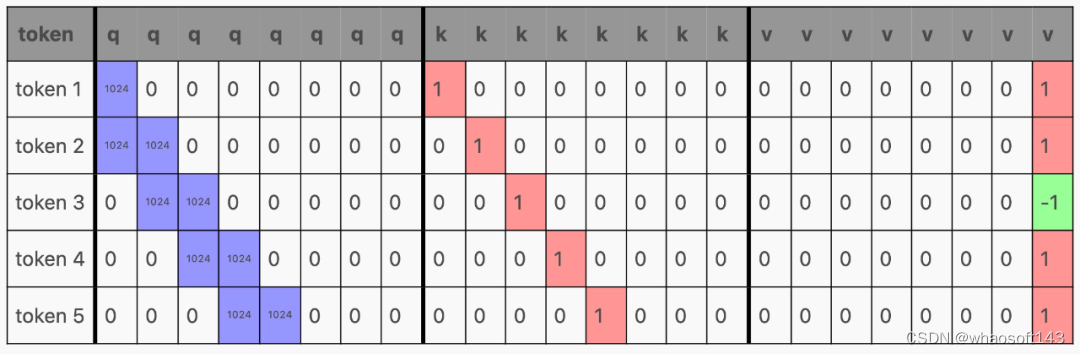
然后,qkv 矩阵被分割成 q、k 和 v,它们与注意力结合起来,如下所示:
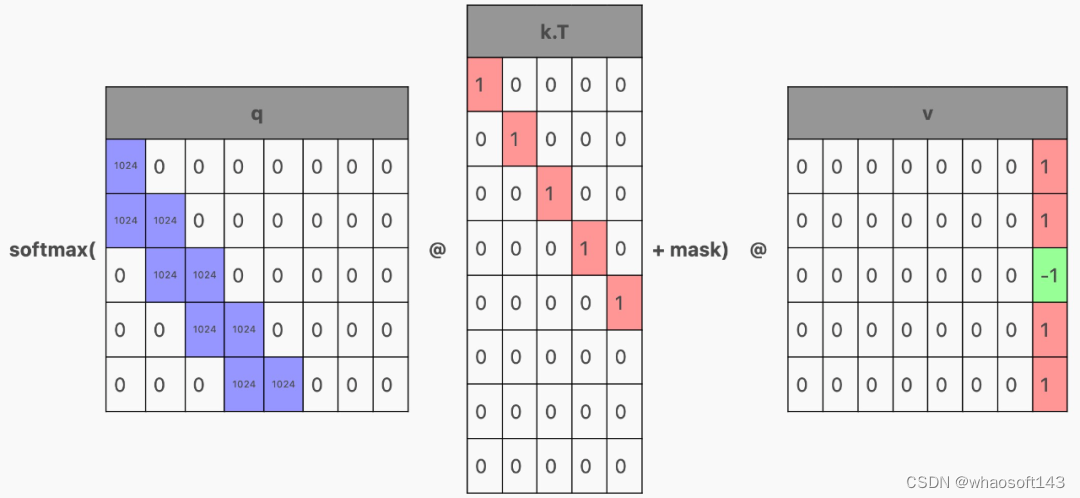
以生成这样的矩阵:
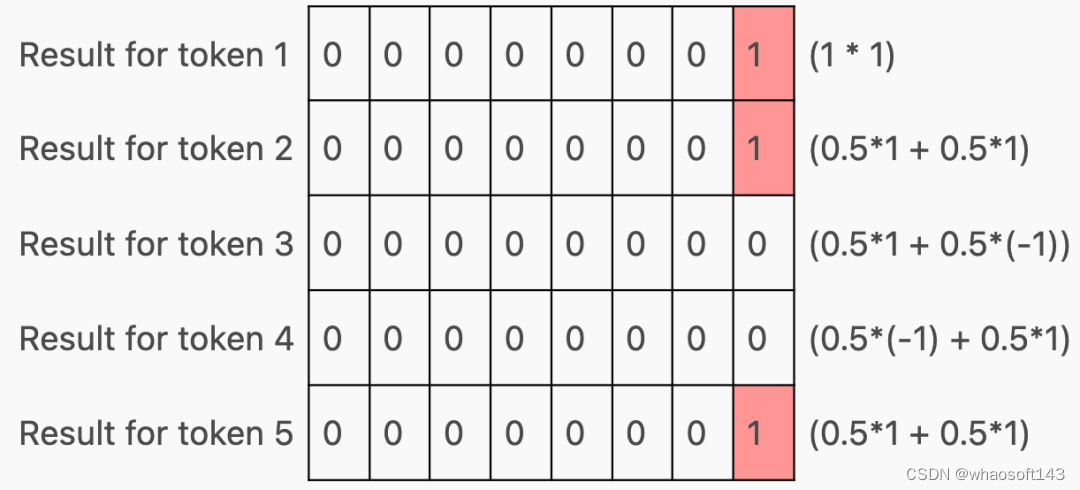
现在,根据该层在 Transformer 中的位置,这些行可能会(在通过 MLP 之后)用作下一个 Transformer 块的输入,或者作为下一个 token 的预测,但请注意,每个 token 都有一行!这是因为 Transformer 经过训练可以预测上下文窗口中每个 token 的下一个 token。
# the gpt2 tokenizer produces 3 tokens for this string
>>> tokens = tokenizer(" A B C").input_ids
>>> tokens
[317, 347, 327]
# if we put that into the model, we get 3 rows of logits
>>> logits = gpt2(input_ids=torch.tensor(tokens)).logits.squeeze()
>>> logits.shape
torch.Size([3, 50257])
# and if we argmax those, we see the model is predicting a next token
# for _every_ prompt token!
>>> for i, y in enumerate(logits.argmax(-1)):
... print(f"{tokenizer.decode(tokens[:i+1])!r} -> {tokenizer.decode(y)!r}")
' A' -> '.'
' A B' -> ' C'
' A B C' -> ' D'在训练过程中,这种行为是可取的 —— 这意味着更多的信息正在流入 Transformer,因为许多 token 都被评分。但通常在推理过程中,我们关心的只是底行,即最终 token 的预测。
我们如何才能从经过训练来预测整个上下文的 Transformer 中得到这一点呢?让我们回到注意力的计算。如果 q 只有一行(对应于最后一个 token 的行)怎么办?
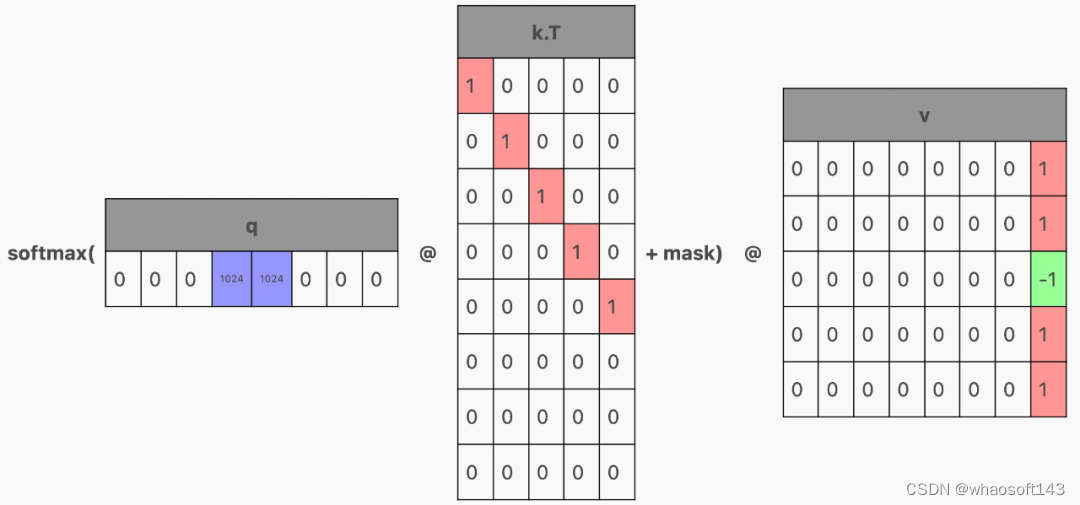
那么,这一行就将作为注意力结果,即最后一个 token 的结果。

但只生成 q 的最后一行,意味着我们也只能在单行上运行生成 qkv 矩阵的层。那么 k 和 v 的其余行从哪里来?这就需要「KV 缓存(KV cache)」。
在模型内部,我们将注意力期间计算的 KV 值保存在每个 Transformer 块中。然后在下一次生成时,只传入单个 token,并且缓存的 KV 行将堆叠在新 token 的 KV 行的顶部,以产生单行 Q 和多行 KV。
下面是使用 HuggingFace transformers API 进行 KV 缓存的示例,默认返回 KV cache 作为模型前向传递的一部分。
>>> tokens
[317, 347, 327] # the " A B C" string from before
>>> key_values = gpt2(input_ids=torch.tensor(tokens)).past_key_values
>>> tuple(tuple(x.shape for x in t) for t in key_values)
((torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),
(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])))KV cache 有助于解决 LLM 缓慢的问题,因为现在每个步骤中只传递一个 token,所以我们不必为每个新 token 重做所有事情。然而,KV cache 的大小仍然每一步都会增长,从而减慢了注意力计算的速度。
KV cache 的大小也会带来自己的新问题,例如,对于 1000 个 token 的 KV cache,即使使用最小的 GPT-2,也会缓存 18432000 个值。如果每个值都是 fp32,那么单次生成的缓存几乎为 74MB。对大模型来说,尤其是在需要处理许多并发客户端的服务器上运行的模型,KV cache 很快就会变得难以管理。
多查询注意力
多查询注意力(Multi-Query Attention,MQA)是对模型架构的改变,通过为 Q 分配多个头,为 K 和 V 只分配一个头来缩小 KV 缓存的大小。值得注意的是,使用 MQA 的模型比使用普通注意力训练的模型可以支持 KV 缓存中更多的 token。
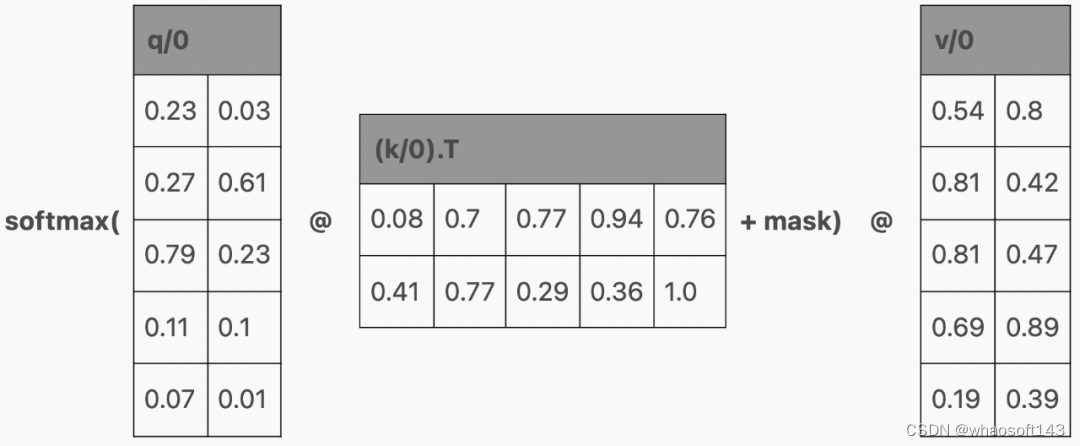
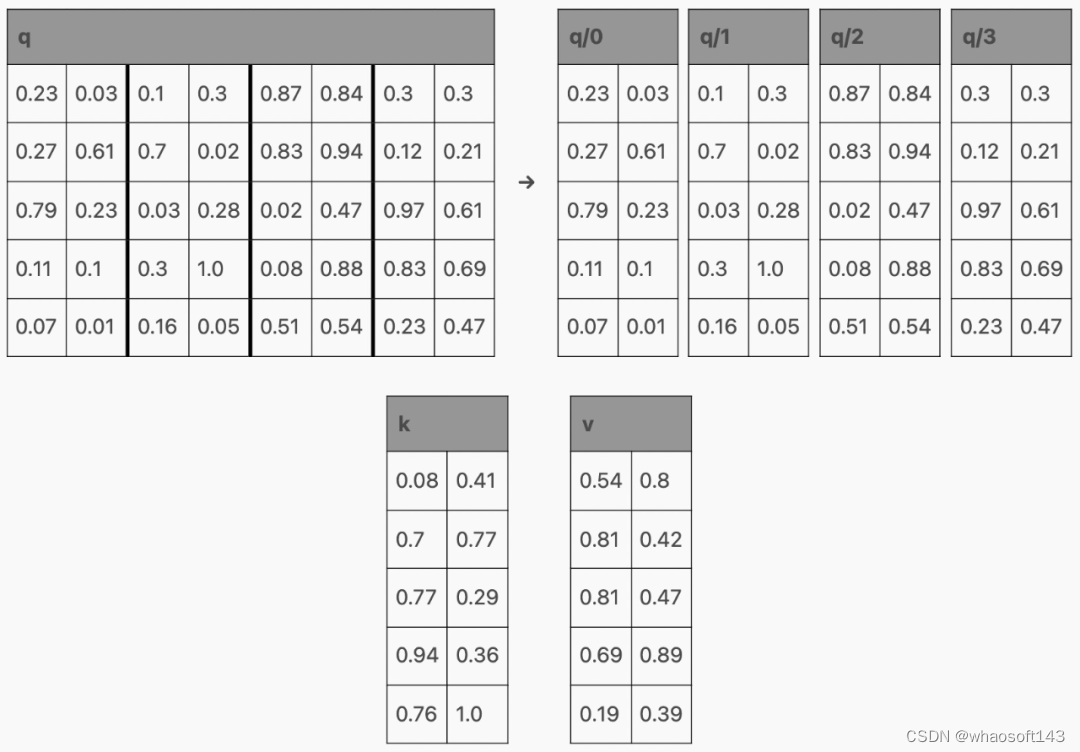
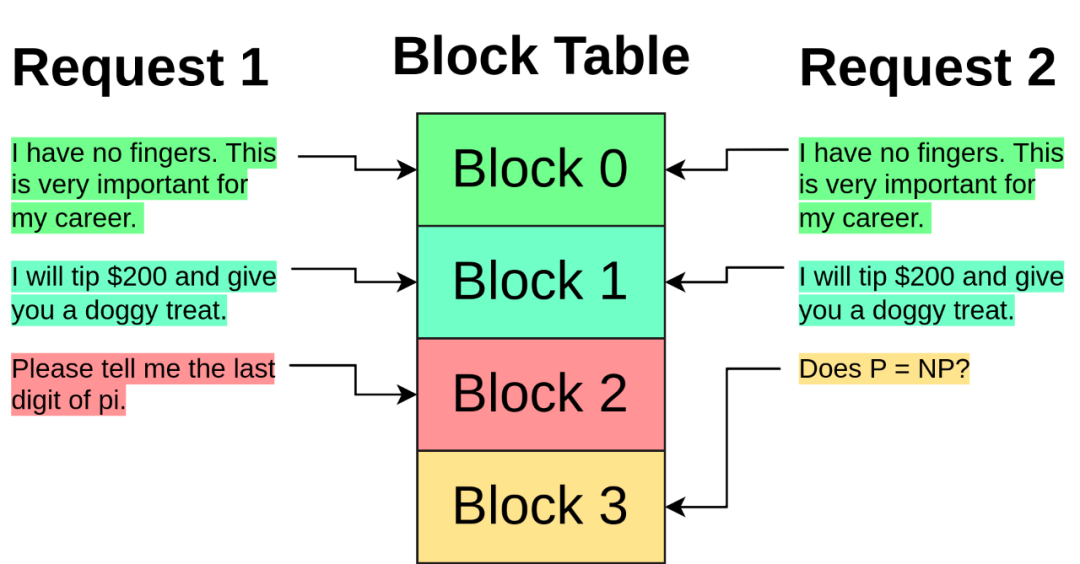
分页注意力(PagedAttention)
大型 KV cache 的另一个问题是,它通常需要存储在连续的张量中,无论当前是否所有缓存都在使用。这会导致多个问题:
- 需要预先分配比所需更多的空间;
- 该保留空间不能被其他请求使用,即使还不需要它;
- 具有相同前缀的请求不能共享该前缀的 KV 缓存。
PagedAttention 从操作系统处理内存的方法中汲取灵感,解决了这些问题。
PagedAttention 会为请求分配一个块表(block table),类似于内存管理单元(MMU)。每个请求没有与大量 KV 缓存项相关联,而是仅具有相对较小的块索引列表,类似于操作系统分页中的虚拟地址。这些索引指向存储在全局块表中的块。
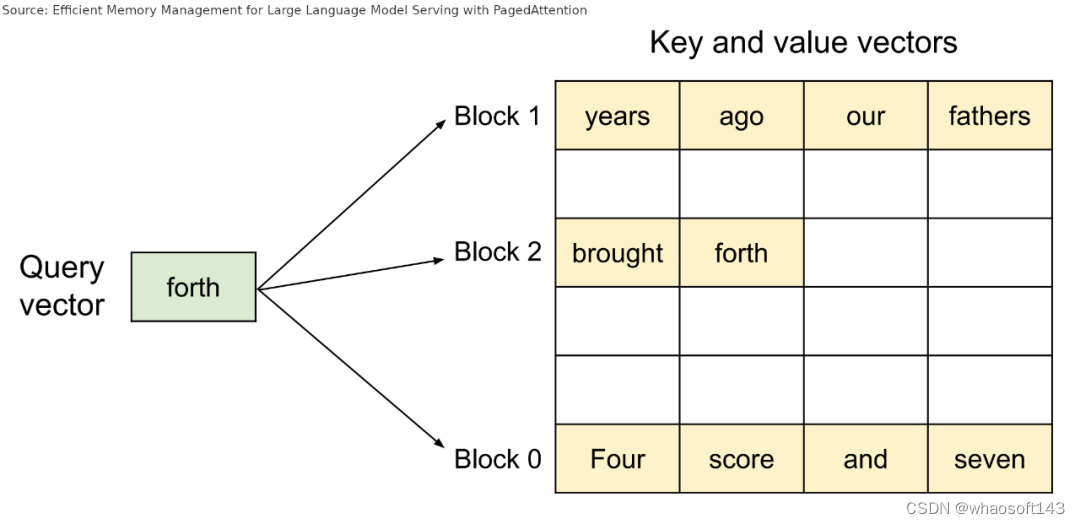
在注意力计算期间,PagedAttention 内核会遍历请求的块索引列表,并从全局块表中获取这些块,以便按照正确的顺序正常计算注意力。
猜测解码
要理解猜测解码,需要了解三件事。
首先,由于内存访问开销,模型运行少量 token 所需的时间与运行单个 token 大约相同:
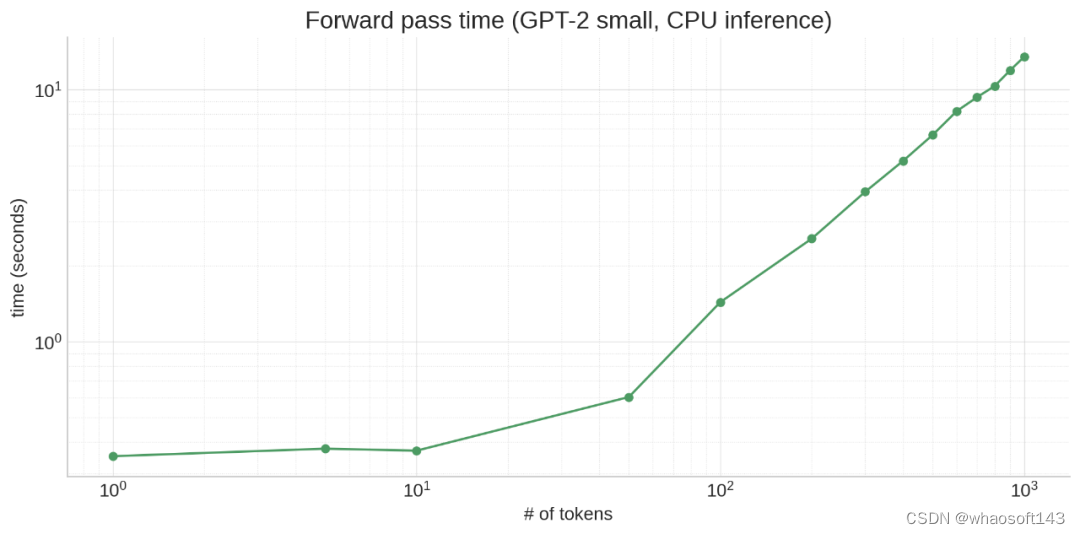
其次,LLM 为上下文中的每个 token 生成预测:
>>> for i, y in enumerate(logits.argmax(-1)):
... print(f"{tokenizer.decode(tokens[:i+1])!r} -> {tokenizer.decode(y)!r}")
' A' -> '.'
' A B' -> ' C'
' A B C' -> ' D'最后,有些词很容易预测。例如,在单词「going」之后,单词「to」极有可能是下一个 token。
def generate(prompt: str, tokens_to_generate: int) -> str:
tokens: list[int] = tokenize(prompt)
GOING, TO = tokenize(" going to")
for i in range(tokens_to_generate):
if tokens[-1] == GOING:
# do our speculative decoding trick
logits = model.forward(tokens + [TO])
# the token the model predicts will follow "... going"
going_pred = argmax(logits[-2, :])
# the token the model predicts will follow "... going to"
to_pred = argmax(logits[-1, :])
if going_pred == TO:
# if our guess was correct, accept "to" and the next token after
tokens += [TO, to_pred]
else:
# otherwise, accept the real next token
# (e.g. "for" if the true generation was "going for broke")
tokens += [going_pred]
else:
# do normal single-token generation
logits = model.forward(tokens)
tokens += [argmax(logits[-1])]
return detokenize(tokens)我们只需要使用一个足够小的「draft 模型」(运行速度足够快),并使用相同的 tokenizer,以避免需要一遍又一遍地对序列进行 detokenize 和 retokenize。
然而,猜测解码的性能可能非常依赖于上下文!如果 draft 模型与 oracle 模型相关性很好,并且文本很容易预测,那么您将获得大量 draft token 和快速推理。但如果模型不相关,猜测解码实际上会使推理速度变慢,因为要浪费时间生成将被拒绝的 draft token。
def generate(prompt: str, tokens_to_generate: int, n_draft: int = 8) -> str:
tokens: list[int] = tokenize(prompt)
for i in range(tokens_to_generate):
# generate `n_draft` draft tokens in the usual autoregressive way
draft = tokens[:]
for _ in range(n_draft):
logits = draft_model.forward(draft)
draft.append(argmax(logits[-1]))
# run the draft tokens through the oracle model all at once
logits = model.forward(draft)
checked = logits[len(tokens) - 1 :].argmax(-1)
# find the index of the first draft/oracle mismatch—we'll accept every
# token before it
# (the index might be past the end of the draft, if every draft token
# was correct)
n_accepted = next(
idx + 1
for idx, (checked, draft) in enumerate(
# we add None here because the oracle model generates one extra
# token (the prediction for the last draft token)
zip(checked, draft[len(tokens) :] + [None])
)
if checked != draft
)
tokens.extend(checked[:n_accepted])
return detokenize(tokens)
阈值解码
一种缓解使用固定数量 draft token 问题的方法是「阈值解码」—— 并不总是解码最大数量的 draft token,而是保留一个移动概率阈值,根据当前的 token 数量进行校准。draft token 会一直生成,直到 draft 的累积概率低于此阈值。
例如,如果阈值是 0.5,并且我们以 0.75 的概率生成 draft token「the」,继续下去。如果下一个 token「next」的概率为 0.5,则累积概率 0.375 将低于阈值,因此会停止生成并将两个 draft token 提交给 oracle 模型。然后,根据 draft 被接受的程度,向上或向下调整阈值,以尝试用实际接受率来校准 draft 模型的置信度。
def speculative_threshold(
prompt: str,
max_draft: int = 16,
threshold: float = 0.4,
threshold_all_correct_boost: float = 0.1,
):
tokens = encoder.encode(prompt)
# homegrown KV cache setup has an `n_tokens` method that returns the length
# of the cached sequence, and a `truncate` method to truncate that sequence
# to a specific token
model_kv = gpt2.KVCache()
draft_kv = gpt2.KVCache()
while True:
# generate up to `max_draft` draft tokens autoregressively, stopping
# early if we fall below `threshold`
draft = tokens[:]
drafted_probs = []
for _ in range(max_draft):
logits = draft_model.forward(draft[draft_kv.n_tokens() :], draft_kv)
next_id = np.argmax(logits[-1])
next_prob = gpt2.softmax(logits[-1])[next_id]
if not len(drafted_probs):
drafted_probs.append(next_prob)
else:
drafted_probs.append(next_prob * drafted_probs[-1])
draft.append(int(next_id))
if drafted_probs[-1] < threshold:
break
n_draft = len(draft) - len(tokens)
# run draft tokens through the oracle model
logits = model.forward(draft[model_kv.n_tokens() :], model_kv)
checked = logits[-n_draft - 1 :].argmax(-1)
n_accepted = next(
idx + 1
for idx, (checked, draft) in enumerate(
zip(checked, draft[len(tokens) :] + [None])
)
if checked != draft
)
yield from checked[:n_accepted]
tokens.extend(checked[:n_accepted])
if n_accepted <= n_draft:
# adjust threshold towards prob of last accepted token, if we
# ignored any draft tokens
threshold = (threshold + drafted_probs[n_accepted - 1]) / 2
else:
# otherwise, lower the threshold slightly, we're probably being
# too conservative
threshold -= threshold_all_correct_boost
# clamp to avoid pathological thresholds
threshold = min(max(threshold, 0.05), 0.95)
# don't include oracle token in kv cache
model_kv.truncate(len(tokens) - 1)
draft_kv.truncate(len(tokens) - 1)
此外,分阶段猜测解码为普通猜测解码添加了一些改进。
指导型生成
语法指导型生成可约束模型的输出遵循某些语法,从而提供保证匹配某些语法(例如 JSON)的输出。这对模型推理的可靠性和速度都有益。
前向解码
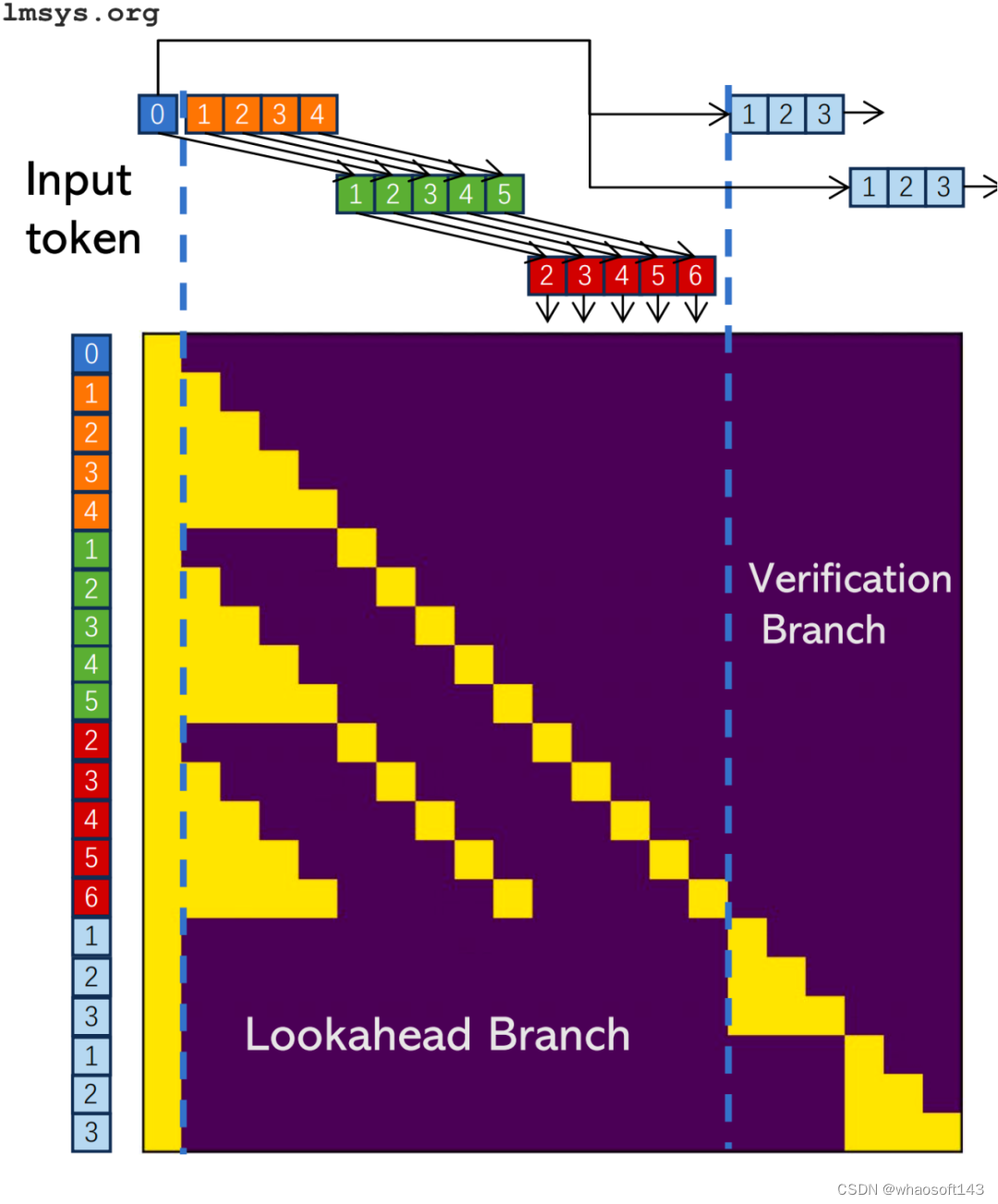
前向解码是一种新的猜测解码方法,不需要 draft 模型。相反,模型本身用于两个分支:预测和扩展候选 N-gram 的前向分支和验证候选的验证分支。前向分支类似于常规猜测解码中的 draft 模型,而验证分支与 oracle 模型具有相同的作用。
还有一种方法是 prompt 查找解码,其中 draft 模型被上下文中的简单字符串匹配所取代。
最后,作者从稀疏注意力(sparse attention)和非 Transformer 架构两个方面简单阐述了训练时间优化的方法。感兴趣的读者可以阅读博客原文,了解更多内容细节。
原文链接:https://vgel.me/posts/faster-inference/?cnotallow=dc32042695bb7e31fb9280e21ab25f8c
Training time optimizations
......
#微调预训练模型
微调预训练模型是自然语言处理(NLP)领域的一项重要实践,可以优化它们在特定任务中的性能。在Monster API,我们了解开发人员在微调模型时面临的挑战,特别是当涉及复杂设置、内存限制、高GPU成本以及缺乏标准化实践时。
地址:https://blog.monsterapi.ai/no-code-fine-tuning-llm/
这就是为什么我们很高兴推出无代码LLM微调产品,该产品旨在简化和加快微调过程,同时为您提供所需的所有功能和可能性。
什么是微调LLM?为什么它如此重要?
虽然像GPT-J、LLaMA、Falcon、StableLM和OPT这样经过预训练的模型具有广泛的语言知识,但微调使开发人员能够提高他们在特定任务中的性能。微调使模型更加准确、上下文感知,并与目标应用程序保持一致。
微调不是从头开始训练语言模型,这需要大量的数据和计算资源,而是利用预先训练的模型的现有知识,并将其调整为专门的任务。
与微调LLM相关的挑战:
微调LLaMA和其他大型语言模型带来了一些挑战。复杂的设置、内存要求、GPU成本以及缺乏标准化实践可能会阻碍微调过程,并使开发人员获得适合其需求的模型变得复杂。
然而,通过Monster API的LLM FineTuner,这些挑战得到了有效解决:
- 复杂设置:Monster API简化了为FineTuning机器学习模型设置GPU环境的复杂过程,将其封装在用户友好、直观的界面中。这种创新方法消除了手动硬件规范管理、软件依赖性安装、CUDA工具包设置和其他低级配置的需要。通过抽象这些复杂性,Monster API LLM Finetuner允许用户轻松选择所需的模型、数据集和超参数,并专注于优化机器学习模型的实际任务。
- 内存限制:微调大型语言模型(如LLaMA)可能需要大量的GPU内存,这对许多开发人员来说可能是一个限制。Monster API通过优化FineTuning过程中的内存利用率来解决这一挑战。它确保在可用的GPU内存内有效地执行该过程,从而使大型语言模型FineToning更易于访问和管理,即使存在资源限制。
- GPU成本:当微调机器学习模型时,GPU成本可能会迅速上升,这使其成为并非所有开发人员都能负担得起的奢侈品。然而,Monster API利用其分散的GPU网络实现了对超低成本GPU实例的按需访问。因此,显著降低了与访问LLM的强大计算资源相关联的成本和复杂性。
- 标准化实践:行业中缺乏标准化实践可能会使微调过程令人沮丧且耗时。Monster API通过提供直观的界面和预定义的任务,以及创建自定义任务的灵活性,简化了这一过程。我们的平台引导您了解最佳实践,无需在错综复杂的文档和论坛中导航。
可以依赖Monster API来简化和流线化复杂的微调过程,使其快速而容易地被处理。通过使用Monster API,您可以轻松地使用LoRA将大型语言模型(如LLaMA 7B)与DataBricks Dolly 15k进行3个阶段的微调。
你猜怎么着?它不会让你倾家荡产,只需花费不到20美元。
有关用于演示的LLM和数据集的上下文:
LLaMA(Large Language Model Meta AI)是Facebook AI Research(FAIR)为机器翻译任务开发的一个令人印象深刻的语言模型。LLaMA基于Transformer架构,在大量多语言数据的语料库上进行训练,使其能够在许多语言对之间进行翻译。LLaMA 7B具有70亿个参数,是该模型的最小变体。
为了展示像ChatGPT这样的交互式和引人入胜的对话能力,我们使用了Databricks Dolly V2数据集。该数据集,特别是“data bricks-doolly-15k”语料库,由Databricks员工创建的15000多条记录组成,提供了丰富多样的会话数据来源。
只需五个简单的步骤,您就可以设置微调任务并体验显著的效果。
所以,让我们一起开始探索这个过程吧!
选择一个语言模型进行微调
- 选择适合您需求的LLM。您有多种流行的开源语言模型可供选择,例如Llama 7B、GPT-J 6B或StableLM 7B
-
- 第二部选择或创建任务:接下来,定义用于微调LLM的任务。使用Monster API,您可以灵活地从预定义任务中选择,如“指令精细调整”或“文本分类”。如果您的任务是唯一的,您甚至可以选择“其他”选项来创建自定义任务。我们重视您的具体要求,并提供相应的选择
-
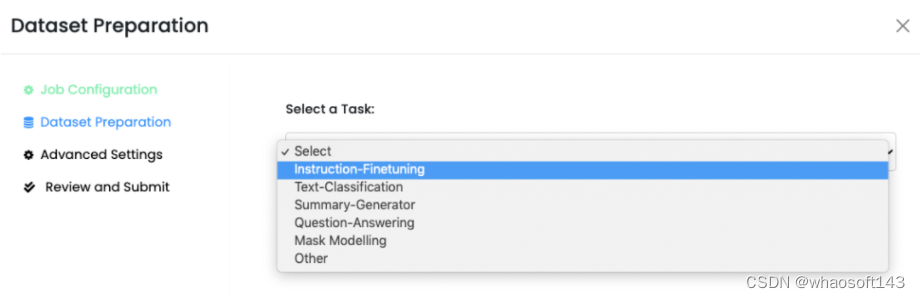
- 选择一个HuggingFace数据集:为了有效地训练你的LLM,你需要一个高质量的数据集。Monster API与HuggingFace数据集无缝集成,提供了广泛的选择。我们甚至根据您选择的任务建议相关的数据集。只需点击几下,您选择的数据集就会自动格式化并准备好使用。我们希望让您能够方便地访问所需的数据
- 指定超参数:Monster API根据您选择的LLM预先填充大多数超参数,从而简化了过程。但是,我们知道您可能有特定的偏好。您可以自由定制时间、学习率、截止长度、热身步骤等参数,确保您的LLM能够根据您的确切要求进行微调
- 审查并提交微调工作:设置完所有参数后,您可以在摘要页面上查看所有内容。我们知道准确性的重要性,因此我们提供此步骤以确保您能够完全控制。一旦你对细节有信心,只需提交工作即可。从那里开始,我们负责剩下的事情
就是这样!只需五个简单的步骤,您的作业就可以提交给您选择的LLM进行微调。我们致力于简化流程,这样您就可以专注于您的任务,而不会被复杂的配置所淹没。
使用Monster API成功设置微调作业后,可以通过WandB上的详细日志监控性能。我们相信为您提供所需的见解,以便您做出明智的决策并取得最佳结果。
Monster API的优点
Monster API的FineTuning LLM产品的价值在于它能够简化大型语言模型(LLM)的使用并使其民主化。通过消除技术复杂性、内存限制、高GPU成本和缺乏统一实践等常见障碍,该平台使人工智能模型微调变得容易和高效。通过这样做,它使开发人员能够充分利用LLM,促进更复杂的人工智能应用程序的开发。
......
#GLM-4
2024 年,国产大模型的第一个重磅消息,来自智谱 AI。最接近GPT-4的国产大模型诞生了
在 1 月 16 日举办的 2024 智谱 AI 技术开放日 Zhipu DevDay 上,智谱 AI 正式发布新一代基座大模型「GLM-4」。
经历了三个月的技术迭代,GLM-4 相比上一代基座模型 GLM-3 实现了 60% 的性能全面提升,直接逼近 GPT-4。
一方面,GLM-4 支持更长的上下文、更强的多模态能力;另一方面,GLM-4 支持更快的推理、更多并发,大大降低了推理成本。
同时,GLM-4 也增强了智能体能力,智谱 AI 正式上线了「GLM-4-All Tools」和「GLMs」个性化智能体定制能力,在产品上持续全面对标 OpenAI。
这些全新升级后的能力,目前已经在智谱 AI 开放平台上线。
「正如我们在去年年初的承诺,2023 年底要实现逼近最先进的 GPT-4 性能的全栈自主创新的 GLM-4。今天,我们来交个答卷,也希望未来能以此为基础瞄向 AGI。」智谱 AI CEO 张鹏表示。
综合能力全面跃升
国产基座大模型比肩 GPT-4
一直以来,AI 领域内的研究者和从业者都以「GPT-4」作为大模型技术的标杆。而 GLM-4 的诞生,意味着国产大模型的水平真正做到了「比肩 GPT-4」。
据张鹏介绍,GLM-4 带来了 128K 上下文窗口长度,单次提示词可处理文本达到 300 页,在总结信息、内容抽取、复杂推理、代码等多个应用场景实现了复杂长文本能力。
智谱 AI 技术团队解决了长上下文全局信息因失焦导致的精度下降问题。在 needle test 大海捞针测试中,在 128K 文本长度内, GLM-4 模型可实现几乎 100% 精度召回。
张鹏表示,GLM-4 性能已经超过 Claude 2.1,直接逼近 GPT 4 。
智谱 Al 进行的多项大模型权威评测的结果证实了这一说法,GLM-4 在 MMLU(81.5)达到 GPT-4 94% 水平,GSM8K(87.6) 达到 GPT-4 95% 水平,MATH(47.9)达到 GPT-4 91% 水平,BBH (82.25) 达到 GPT-4 99% 水平,HellaSwag (85.4) 达到 GPT-4 90% 水平,HumanEval(72)达到 GPT-4 100% 水平。
在指令跟随能力方面,GLM-4 也实现了媲美 GPT-4 的水准。根据指令跟随评估基准 IFEval 的结果,GLM-4 在 Prompt 提示词跟随(中文)方面达到了 GPT-4 88% 的水平;在指令跟随(中文)方面,达到了 GPT-4 90% 的水平。
在实际落地应用过程中,模型的中文对齐能力格外重要,GLM-4 的表现也毫不逊色。
基于公开数据集 AlignBench 的评估结果,GLM-4 超过了 GPT-4 在 6 月 13 日发布的版本,逼近 GPT-4 最新(11 月 6 日版本)效果,在专业能力、中文理解、角色扮演方面超过了最新 GPT-4 的精度,唯一有待提升的是 GLM-4 在中文推理方面的能力。
短短几个月,GLM-4 即可实现多项模型能力的飞跃,与智谱 AI 长期以来所坚持的「All in 大模型」路线密不可分。
自成立以来,智谱 AI 始终致力于打造新一代认知智能大模型,从一开始探索超大规模预训练模型算法,到训练从几十亿、几百亿到千亿级的模型,并逐步探索实现规模化的产业应用落地。
2020 年底,智谱 AI 从 0 起步研发 GLM 预训练架构,在确保性能的同时具有独立、自主、可控特性。2022 年,智谱 AI 率先推出中英双语千亿级超大规模预训练模型 GLM-130B,引发了全球关注。
在 2023 年的大模型浪潮之中,智谱 AI GLM 系列大模型保持每 3-4 个月升级一次的节奏,同时逐步具备了多模态理解、代码解释、网络搜索增强等新功能。
多模态能力的水平,是决定模型能否应用于复杂现实场景的关键因素。此次 GLM-4 的多模态能力能够实现长足的进步,正是基于不断进化的智谱 AI 多模态理解模型 CogVLM 和文生图模型 CogView。
其中,最新发布的 CogView3 效果明显超过开源最佳的 Stable Diffusion XL,逼近最新 OpenAI 发布的 DALLE・3。在对齐、保真、安全、组合布局等各个评测维度上,CogView3 的效果都达到 DALLE・3 90% 以上水平,平均达到 95% 左右的相对性能。
GLM-4-All Tools 上线
产品持续对标 OpenAI
大模型本身还不足以解决所有问题,在实际的使用过程中,我们常常需要同时借助多种工具,比如网页浏览、数据分析、图像生成。
张鹏在演讲中提到了这一难点:「一直以来,普通用户甚至是开发者,需要用像魔法咒语一样的提示词或者机器才能解读执行的代码、调用大模型的各种能力,无论是回答问题、作画还是使用外部的知识源,总觉得大模型还是没那么聪明。」
这些复杂任务,都可以依靠「Agent」来完成。
强大的 Agent 能力,同样是提升 GLM-4 模型使用体验的关键因素之一。在这一次的技术开放日,智谱 AI 正式推出了「GLM-4-All Tools」。
「GLM-4-All Tools」提供了一系列强大的内置工具,让 GLM-4 实现了自主根据用户意图,自动理解、规划复杂指令,自由调用 WebGLM 搜索增强、Code Interpreter 代码解释器和多模态生成能力以完成复杂任务。开发者和用户可以更轻松地使用 GLM-4 模型,不再需要为提示词担心。
在现场,我们也看到了多个功能演示:以文生图为例,GLM-4-All Tools 能够准确地根据上下文语境进行 AI 绘图创作:
面对涉及复杂计算的指令,GLM-4 内嵌了代码解释器,能够自动进行复杂的方程或者微积分求解。对比 GSM8K、Math 以及 Math23K 三个数据集上的结果,GLM-4 取得了与 GPT-4 All Tools 相当的性能。
此外,GLM-4-All Tools 可以自动处理各种任务,包括文件处理、数据分析、图表绘制等,处理的文件类型覆盖我们常用的 Excel、PDF、PPT 等格式。在信息检索方面,All Tools 使得 GLM-4 从早期的检索自动增强升级为目前模型对网页的自动浏览能力。
「GLM 系列模型的全家桶能力,终于实现了 All-In-One。」张鹏总结道。
从全行业的角度来说,GLM-4-All Tools 的意义或许更为突出。基于比肩 GPT-4 的基座大模型能力,这一功能的上线将为应用、行业模型和商业化落地案例开辟出更加广阔的实践空间。
立足智能体开发
携手开发者、社区构筑更繁荣生态
能力水平的高低决定了大模型能否在未来的竞争中生存下去,而围绕大模型构筑起完善的生态链能够助力它们走得更远。二者缺一不可,相互促进。
一直以来,智谱 AI 在推进自家 GLM 系列模型研发时注重能力与生态「并举」,从第一代大模型创建起便在生态建设层面下足功夫, 将广大开发者、用户、开源社区、科研界以及产业链上下游合作伙伴都纳入进来。
在这一次的技术开放日活动中,我们见证了智谱 AI 加速构建 GLM 模型生态的一系列举措。
一项重磅推出是「GLMs」个性化智能体定制能力,为包括无编程基础开发者在内的所有人提供了创建专属智能体的新渠道。
目前,该功能已经上线智谱清言官网。基于 GLM-4 模型的强大基础能力,任何用户都可以使用简单的提示词创建定制化的 GLM 智能体。
智能体创建地址:https://chatglm.cn/glms
至于效果怎样?张鹏现场让 GLM 智能体「智谱 DevDay」总结了技术开放日上午的议程,从结果来看,内容准确、没有遗漏。
GLMs 定制化智能体可以让任何人使用并充分挖掘 GLM-4 模型的潜力,结合自身所在领域以及专业知识、创意和智慧,自由创建更加多样化的智能体,实现便捷开发,进一步构建开放的大模型社区生态。同时更多人参与其中有助于更大规模地推动大模型及智能体在垂直场景和领域的部署,为应用落地提供了新的方式。
接下来,GLMs 模型应用商店以及开发者分成计划也将同期发布。这些与 GLMs 智能体一道构成了智谱 AI 在扩大开发者生态层面的重要尝试和迈出的关键步伐,让开发者应用大模型的门槛不断降低。
对于模型开源和对开源社区的贡献,智谱 AI 也一直走在国内外前列。智谱 AI 先后开源了中英双语对话大模型 ChatGLM-6B 和 ChatGLM2-6B,全球累计下载量超过了 1000 万,GitHub 星标累计超过 5.4 万。这些开源模型也「开花结果」,开发者已经在其上开发出了 600 多项优秀的大模型应用开源项目。
此次,智谱 AI 为开源社区带来了更多好消息,让我们看到了其围绕开源模型构筑更繁荣开源社区、建立更大模型生态的决心。
智谱 AI 针对开源社区发起了开源开放的大模型开源基金,概括为三个「一千」:
- 为大模型开源社区提供 1000 张卡;
- 提供 1000 万现金支持与大模型相关的开源项目;
- 为优秀的开源开发者提供 1000 亿免费 API tokens。
这些都是智谱 AI 为开发者和开源社区谋得的实打实的实惠,通过奖励为大模型普及、推广和应用做出贡献的开发者组织和个人,充分调动他们的积极性,进一步推动大模型研发,促进整个开源生态的发展。
同时面向科研界,联合中国计算机学会和中国中文信息学会社会媒体处理专委会分别发起了 CCF - 智谱大模型基金和 SMP - 智谱大模型交叉学科基金,围绕预训练大模型理论、算法、模型、应用以及与各领域的交叉创新做「深」文章。
为了助力生态伙伴走好大模型创业的「长征路」,智谱 AI 还面向全球大模型初创团队和小微企业升级了「Z 计划」创业基金,总额 10 亿人民币,覆盖大模型算法、底层算子、芯片优化、行业大模型和超级应用,旨在支持更多大模型原始创新和能力升级。
大模型的研发和应用涉及复杂的产业链条,任重而道远。从上述措施中,我们看到了智谱 AI 对于开发者生态、开源社区和客户的坚定承诺。
正如张鹏所言:「一枝独秀不是春,中国人工智能事业要繁荣、要发展,需要所有的参与者、产业链上下游合作伙伴、开发者社区、学术界一同努力。智谱不仅有意愿,而且有能力为打造繁荣的国产大模型生态贡献自己的力量。」
AGI 元年,智谱 AI 开局就要争先
自 ChatGPT 推出以来,我们见证了轰轰烈烈的百模大战、此起彼伏的 AIGC 应用落地以及成为厂商全新角逐点的 AI Agent。要想在每一个阶段都不被落下,则要事事争先、抓住每一次发展时机。
面向即将到来的更激烈的大模型之争,智谱 AI 已经做好了准备。正如此次技术开放日的一系列模型发布和能力升级,其每次都能给出及时的回应:
一方面不断夯实并升级 GLM 基座大模型的能力,并抓住 AI Agent 发展契机形成自己的 GLM 智能体发展体系,将大模型的应用做得更深、更广、更全;另一方面联动开发者、社区、科研界以及客户等各方,无死角地构筑起一个更宏大的模型生态圈层,打造更完整的生态链。
2024 年伊始,智谱 AI 带来了国产大模型带来了好消息,并以此为起点瞄准 AGI 之路。在未来的技术求索和产业应用道路上,智谱 AI 会成为最先赶超 OpenAI 的国内大模型创业力量吗?我们拭目以待。
......
#DALL·E 3
OpenAI DALL·E 3来了,集成ChatGPT,生图效果太炸了, 集成 ChatGPT 后,DALL・E 3 对上下文的理解上了一个大台阶。
终于,OpenAI 的文生图 AI 工具 DALL-E 系列迎来了最新版本 DALL・E 3,而上个版本 DALL・E 2 还是在去年 4 月推出的。
OpenAI 表示,「DALL・E 3 比以往系统更能理解细微差别和细节,让用户更加轻松地将自己的想法转化为非常准确的图像。」
是不是真如 OpenAI 所说的那样呢?眼见为实,我们来看以下 DALL・E 3 与 DALL・E 2 的生成效果比较,同样的 prompt「一幅描绘篮球运动员扣篮的油画,并伴以爆炸的星云」,左图 DALL・E 2 在细节、清晰度、明亮度等方面显然逊于右图 DALL・E 3。

除了炸裂的生图效果之外,此次 DALL・E 3 的最大特点是与 ChatGPT 的集成,它原生构建在 ChatGPT 之上,用 ChatGPT 来创建、拓展和优化 prompt。这样一来,用户无需在 prompt 上花费太多时间。
具体来讲,通过使用 ChatGPT,用户不必绞尽脑汁地想出详细的 prompt 来引导 DALL・E 3 了。当输入一个想法时,ChatGPT 会自动为 DALL・E 3 生成量身定制的、详细的 prompt。同时用户也可以使用自己的 prompt。
至于集成 ChatGPT 后的效果怎么样?OpenAI CEO 山姆・奥特曼兴奋地展示了 DALL・E 3 的连续性生成结果,简直称得上完整的「故事片」。

超级向日葵刺猬长什么样子
ChatGPT 集成并不是 DALL・E 3 唯一的新特点,它还能生成更高质量的图像,更准确地反映提示内容。DALL・E 将文本 prompt 转换成图像。即使是 DALL・E 2 ,也会经常忽略特定的措辞导致出错。但 OpenAI 的研究人员说,最新版本能更好地理解上下文,并且处理较长的 prompt 效果会更好。此外,它还能更好地处理向来困扰图像生成模型的内容,如文本和人手。

prompt:这幅插画描绘了一颗由半透明玻璃制成的人心,矗立在惊涛骇浪中的基座上。一缕阳光穿透云层,照亮了心脏,揭示了其中的小宇宙。地平线上镌刻着一行醒目的大字 「Find the universe within you」。
可以看到在上图将 prompt 中的每一个细节都表现出来了。半透明的质感、画面底部的波涛汹涌、阳光与厚厚的云层、心脏中的宇宙景象,以及难倒很多图像生成模型的文字展现,DALL・E 3 都顺利地完成了这些任务。
那么,DALL・E 3 能不能成为 Midjourney 「杀手」呢?推特用户 @MattGarciaEth 已经将二者生成的图片进行了很多比较。大家觉得哪个更好呢?

prompt 为「一个鳄梨坐在治疗师的椅子上,说『我只是觉得内心很空虚』,中间有一个坑大小的洞。治疗师、一个勺子、潦草地写笔记。」

prompt 为「一位亚裔中年妇女的黑发上散落着银丝,显得支离破碎,错综复杂地镶嵌在一片碎瓷片中。瓷器上闪烁着飞溅的颜料图案,光泽和哑光的蓝色、绿色、橙色和红色和谐地交织在一起,在动与静的超现实并置中捕捉着她的舞姿。她的肤色与瓷器一样呈浅色,为她的造型增添了一种神秘的气质。」(推特 @nickfloats,上图为 DALL・E 3 的生成结果, 下图为 Midjourney 的生成结果)
目前,DALL・E 3 处于研究预览版本。OpenAI 计划将 DALL・E 3 的发布时间错开, 将于 10 月份首先向 ChatGPT Plus 和 ChatGPT Enterprise 用户发布,随后在秋季向研究实验室及其 API 服务发布。不过,该公司没有透露何时或者是否计划发布免费的公开版本。
DALL・E 系列研究
我们简单为大家梳理介绍下 OpenAI 文本生成图像的 DALL・E 系列研究,也方便读者们了 DALL・E 系列背后的技术。
2021 年 1 月 6 日,OpenAI 博客发布了两个连接文本与图像的神经网络:DALL・E 和 CLIP。DALL・E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。这两项研究的发布,引起了社区极大的关注。
据博客介绍,DALL・E 可以将以自然语言形式表达的大量概念转换为恰当的图像,可以说是 GPT-3 的 120 亿参数版本,可基于文本描述生成图像。

DALL・E 示例。给出一句话「牛油果形状的椅子」,就可以获得绿油油、形态各异的牛油果椅子图像。
2 个月后,DALL・E 的论文和代码公开。
- 项目地址:https://github.com/openai/DALL-E
- 论文地址:https://arxiv.org/abs/2102.12092
2022 年 4 月 7 日左右,DALL・E 迎来了升级版本 ——DALL・E 2。与 DALL・E 相比,DALL・E 2 在生成用户描述的图像时具有更高的分辨率和更低的延迟。并且,新版本还增添了一些新的功能,比如对原始图像进行编辑。
OpenAI 还公布了 DALL・E 2 的研究论文《Hierarchical Text-Conditional Image Generation with CLIP Latents》。
论文地址:https://cdn.openai.com/papers/dall-e-2.pdf
遗憾的是。OpenAI 可能不会像之前一样,公布 DALL・E 3 背后的技术细节。
注重安全与版权问题
OpenAI 称其在 DALL・E 3 上投入了大量工作,包括制定强有力的安全措施,以防止创建「有害」的图像。OpenAI 表示其与外部「红队」成员(一个故意试图破坏系统以测试系统安全性的团队)合作,并依赖输入分类器(一种教语言模型忽略某些单词以避免显式或暴力 prompt 的方法)。DALL・E 3 也无法生成公众人物的图像。
OpenAI 研究员 Sandhini Agarwal 表示她对 DALL・E 3 的安全措施「高度有信心」,并表示该模型在不断改进。OpenAI 还在一封电子邮件中表示:DALL・E 3 拒绝生成在世艺术家风格的图像,这一点与 DALL・E 2 不同。
艺术家们曾起诉 DALL・E 的竞争对手 Stability AI 和 Midjourney,以及艺术网站 DeviantArt,指控它们使用他们拥有版权的作品来训练文本到图像的模型。或许是为了避免诉讼,OpenAI 将允许艺术家将其艺术作品从未来版本的文本到图像 AI 模型中删除,不用于训练。创作者可以提交一张他们拥有版权的图片,并在网站上填写表格要求将其移除。
这样,未来版本的 DALL・E 就可以屏蔽与艺术家的图像和风格相似的结果。
参考链接:
https://openai.com/dall-e-3
https://www.theverge.com/2023/9/20/23881241/openai-dalle-third-version-generative-ai
https://techcrunch.com/2023/09/20/openai-unveils-dall-e-3-allows-artists-to-opt-out-of-training/
......
#Baichuan
挖来一个说自己好厉害的~~ 全面超越LLaMA2,月下载量超三百万,国产开源大模型如何成为新晋顶流?
回想两个月前,LLaMA2 的开源,曾以一己之力改变了大模型领域的竞争格局。
相比于今年 2 月推出的第一代 LLaMA,LLaMA2 在推理、编码、精通性和知识测试等任务中都实现了性能的大幅提升,甚至可以在某些数据集上接近 GPT-3.5。由于其强大的性能和开源的特质,LLaMA2 在发布后的一周内就接收到了超过 15 万次的下载请求,并吸引了大量开发者进行「二创」。
但大模型技术的进化速度经常超乎预期。一觉醒来,发现大模型的性能上限被再次刷新,这在最近是经常发生的事情。
近期就有一位「选手」,在开源大模型社区的关注度不断攀升,逐渐超越 LLaMA2 成为了新晋顶流。
在 Huggingface 社区,「Baichuan」系列是过去一个月下载量全球最高的开源大模型,它来自一家成立仅五个月的中国公司 —— 百川智能。
在 ChatGPT 爆火之初,王小川即宣布入局大模型,并迅速组建起大模型技术团队。自成立以来,这家公司保持了平均每月更新一款大模型的惊人节奏:6 月 15 日,发布 Baichuan-7B;7 月 11 日,发布 Baichuan-13B;这两款免费可商用的中文开源大模型之后,8 月 8 日,搜索增强大模型 Baichuan-53B 面世。
9 月 6 日,百川智能又一次宣布了重量级更新:Baichuan2-7B、Baichuan2-13B 的 Base 和 Chat 版本同时开源,并提供了 Chat 版本的 4bits 量化,且均为免费可商用。
平均 28 天发布一款大模型,这是国产开源大模型的迭代速度,也代表了中国开源力量迎头赶上的决心。
迄今,Baichuan-7B 和 Baichuan-13B 这两款开源大模型目前的下载量已经突破 500 万,其中近一个月的下载量就有 300 多万。除开发者之外,也有 200 多家企业申请部署开源大模型。
未来的大模型竞争格局中,谁能占据核心地位仍是未知。但不难想象的是,既已实现对 LLaMA2 的超越,再加上惊人的迭代速度,国产开源大模型的黄金时代应该不远了。
Baichuan 2 下载地址:https://github.com/baichuan-inc/Baichuan2
国产开源大模型,全面赶超 LLaMA2
让整个领域感到惊讶的不只是「Baichuan」系列的更新速度,还有其迭代后的模型能力。
曾曝光 GPT-4 技术细节的软件开发者、Kaggle大神、 Deep trading 创始人 Yam Peleg 通读了 Baichuan 2 的技术报告,直言这是一次相当重大的改进。
他特别提到一点:「就像 GPT-4 的报告一样,团队在训练开始前就预测了最终损失。为此,他们训练了从 1 千万到 3 亿的小模型,并根据这些模型的损失预测了大模型的最终损失。据我所知,这是首个能够复制这一程序的开源模型。」
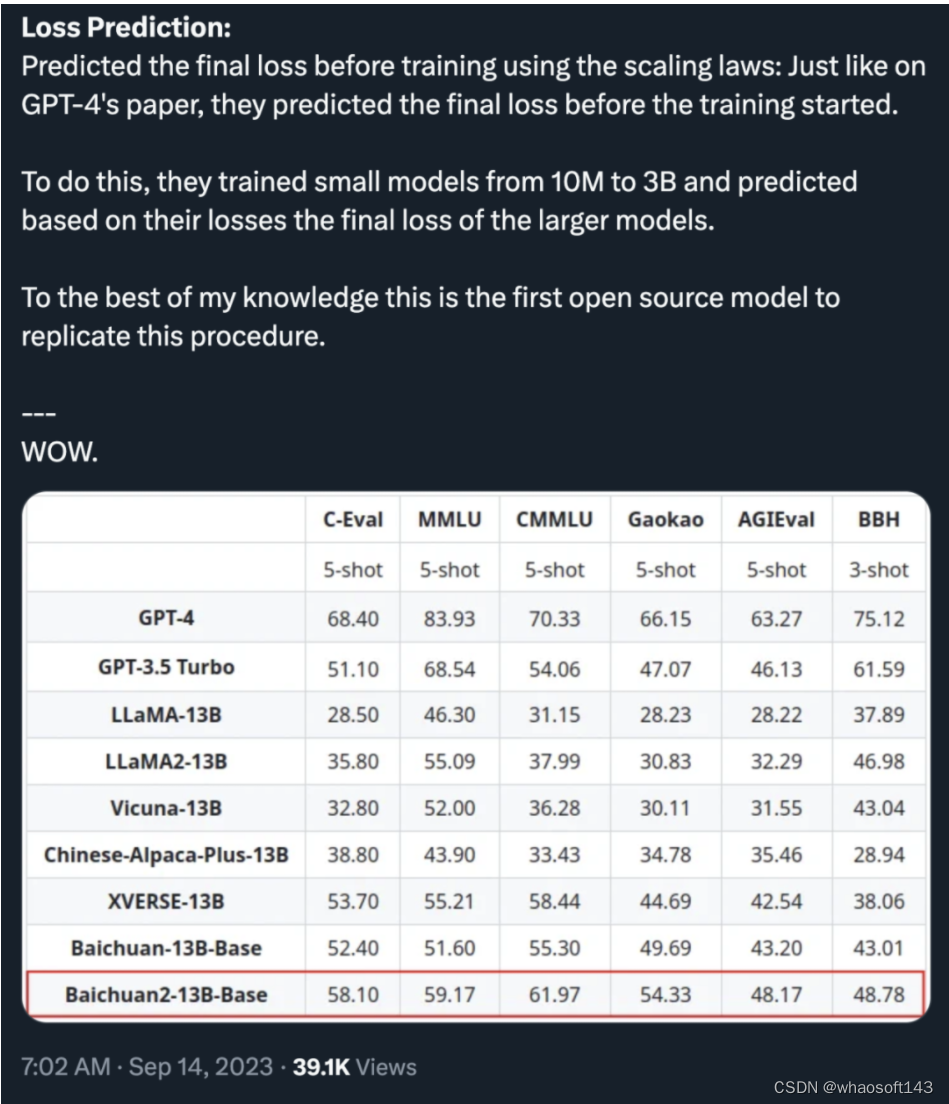
图片来源:https://twitter.com/Yampeleg/status/1702095404802637874?s=19
基于上一代 Baichuan 大模型,Baichuan 2 保留了良好的生成与创作能力、流畅的多轮对话能力以及部署门槛较低等众多特性,同时实现了数学、代码、安全、逻辑推理、语义理解等能力的大幅提升。
根据公开的 Baichuan 2 技术报告,Baichuan2-7B-Base 和 Baichuan2-13B-Base 均基于 2.6 万亿高质量多语言数据进行训练,数据来源十分广泛:
训练语料库的构成。
同时,Baichuan 2 建立了一个可在数小时内对万亿规模的数据进行聚类和重复数据删除的系统,提升了预训练中数据采样的质量。
此外,Tokenizer 需要平衡提高推理效率的高压缩率以及适当大小的词汇量,以确保每个词嵌入的充分训练。在 Baichuan 2 的训练中,词汇量从 Baichuan1 的 64,000 个扩大到了 125,696 个。
这些方法,最终使得 Baichuan 2 在计算效率和模型性能之间取得了更好的平衡。
在 MMLU、CMMLU、GSM8K 等多项权威基准上,Baichuan 2 均以绝对优势领先 LLaMA2。
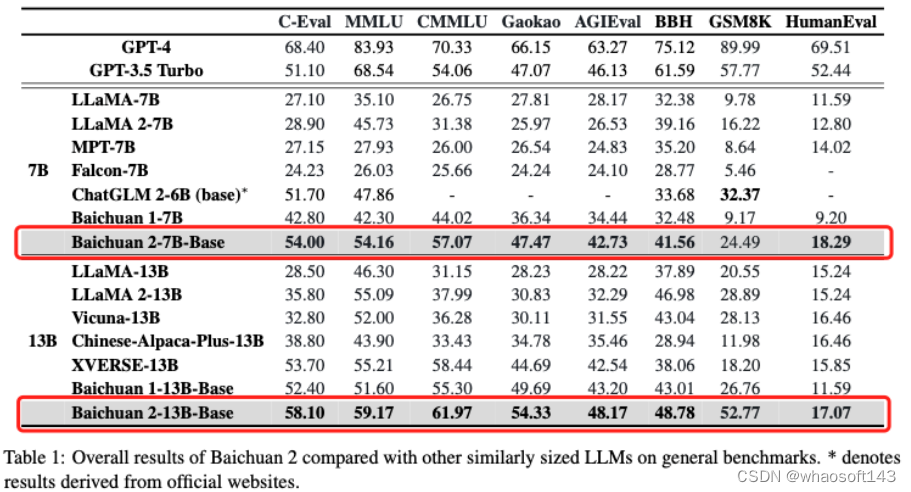
Baichuan 2 性能大幅度优于 LLaMA2 等同尺寸模型竞品。
如表 5 所示,在法律领域,Baichuan 2-7B-Base 超越了 GPT-3.5 Turbo、ChatGLM 2-6B 和 LLaMA 2-7B 等模型,仅次于 GPT-4,与 Baichuan1-7B 相比提高了近 30%;在医疗领域,Baichuan2-7B-Base 的表现明显优于 ChatGLM 2-6B 和 LLaMA 2-7B,与 Baichuan1-7B 相比也有显著提高。同样,在这两个领域,Baichuan2-13B-Base 则超越了同尺寸所有模型。
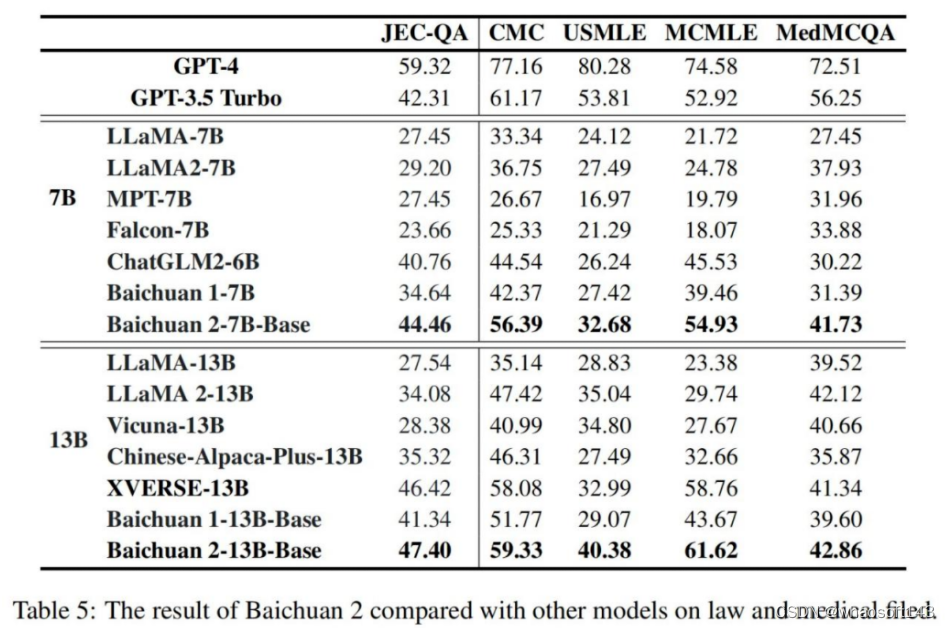
如表 6 所示,在数学领域,Baichuan2-7B Base 超越了 LLaMA 2-7B 等模型,Baichuan2-13B-Base 超越了所有相同规模的模型,接近 GPT-3.5 Turbo 的水平;在代码领域,Baichuan2-7B Base 超越了同等规模的 ChatGLM 2-6B 等模型,Baichuan2-13B-Base 优于 LLaMA 2- 13B 和 XVERSE-13B 等模型。
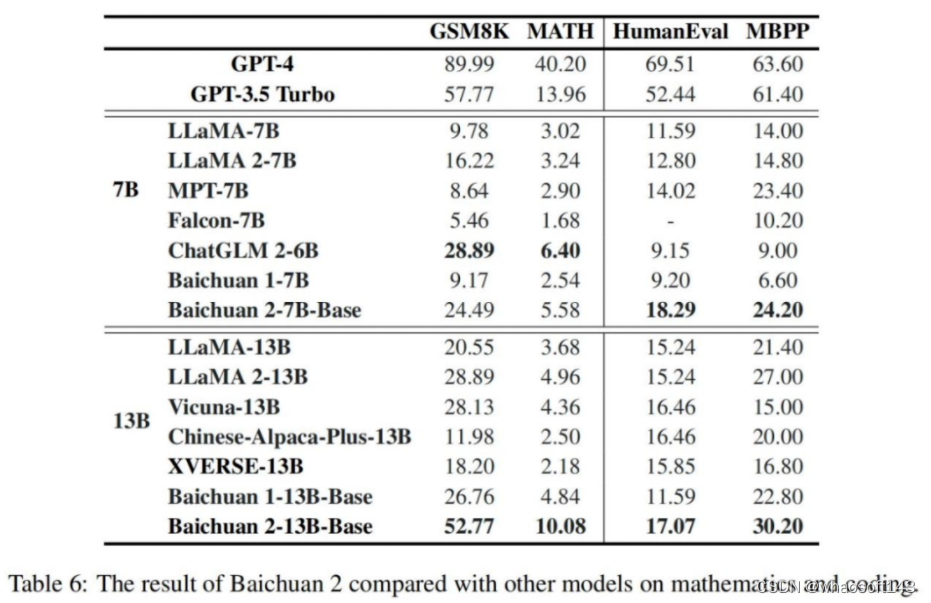
尽管 GPT-4 在多语言领域仍占主导地位,但开源模型正紧追不舍。如表 7 所示,在多语言场景的任务评估中,Baichuan2-7B-Base 在所有七项任务中都超过了所有同等规模的模型;Baichuan 2-13B 在四项任务中的表现优于相同规模的模型,其中在 zh-en 和 zh-ja 任务上超过了 GPT3.5 Turbo,达到了 GPT-4 的水平。
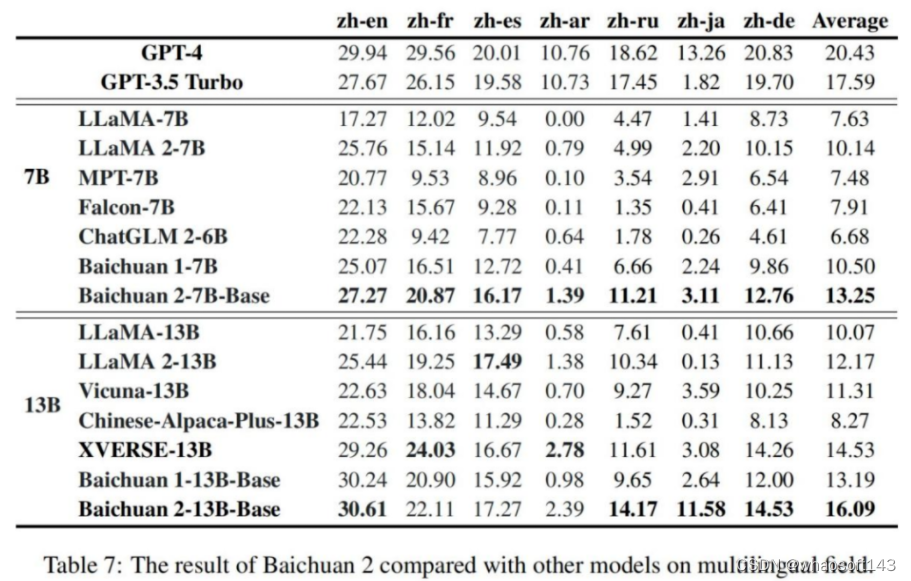
更适合中国开发者的国产开源大模型
对于中国的众多开发者来说,Baichuan 2 的开源是一个令人振奋的好消息。
这就要提到 LLaMA2 的「开源争议」。Meta 官宣的第二天,便有开发者抛出质疑:LLaMA2 不属于真正的「开源」,所谓的「可商用协议」本质上附加了许多限制。首先,Llama 2 的语料库以英文(89.7%)为主,中文仅占据其中 0.13%,因此在中文场景任务中并不占优势。其次,Llama 2 在协议中明确禁止非英文场景的商用。
Baichuan 2 的能力完全可以与 LLaMA2 相媲美,甚至超越。而且在「免费商用」这件事上,Baichuan 2 实践得更加彻底,弥补了中国开源生态的短板,让中国开发者用上了对中文场景更友好的开源大模型。Baichuan2-7B 和 Baichuan2-13B 不仅对学术研究完全开放,企业也仅需邮件申请获得官方商用许可后,即可免费商用。
更具备长期价值的一点是,这次彻底的、完全的开源,能够帮助大模型学术机构、开发者和企业用户更深入的了解 Baichuan 2 的训练过程,推动社区对大模型学术层面的深入研究。
从理论研究的角度,大模型训练包含海量高质量数据获取、大规模训练集群稳定训练、模型算法调优等多个环节。每个环节都需要大量人才、算力等资源的投入。由于大部分开源模型只能做到对外公开自身模型权重,却很少提及训练细节,所以企业、研究机构、开发者们只能自己摸索着训练模型,或是在开源模型的基础上做有限的微调,很难深入。LLaMA2 也是一样,最受关注的「数据处理」层面恰恰没有开源,因此参考意义有限。
但在总共 28 页的 Baichuan 2 技术报告中,团队详细介绍了 Baichuan 2 训练的全过程,包括数据处理、模型结构优化、Scaling law、过程指标等关键细节。
本着协作和持续改进的精神,百川智能还公布了 3000 亿到 2.6 万亿 Token 模型训练的 checkponits,供社区研究使用:
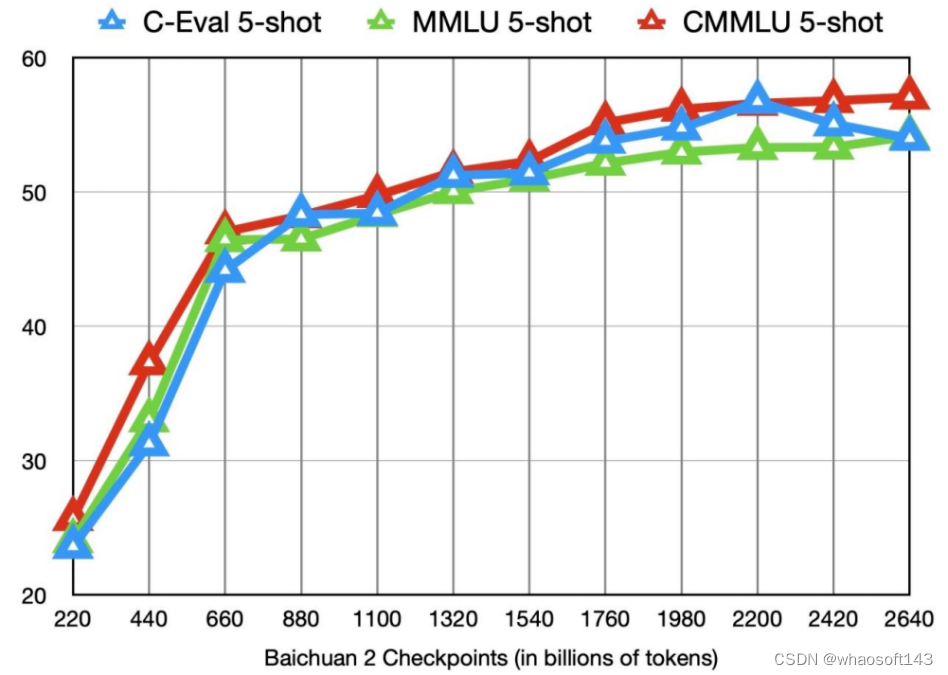
就当前的开源生态来说,这种公布训练模型过程的方式称得上「首次」。
这些技术细节的开放,对于科研机构研究大模型训练过程、模型继续训练和模型的价值观对齐等极具价值,将极大推动国内大模型的科研进展。
「开源」与「闭源」:相互竞争,相互促进
在这场由 ChatGPT 打响的大模型竞赛中,「开源」与「闭源」之争已经上演。正如今年 5 月的一篇「谷歌内部文章」所说,「谷歌、OpenAI 没有护城河」,由一两家科技公司构建和维护的技术高墙总会被打破,开源的力量将使得大模型技术真正易用和可用。
而且这种竞争态势将长期存在:今后的大模型格局中,「开源」与「闭源」最终会并驾齐驱,如同手机操作系统领域的 iOS 和 Android。不断刷新的模型性能、率先实现「免费商用」、更加全面的社区生态,都是开源大模型能获得更多开发者支持的优势所在。
纵观当前的开源大模型,达到 GPT3.5 的水平已经不再是难题,大家正在探索的重点已经变为如何实现 GPT-4 的水准。比如,前段时间 1800 亿参数的阿联酋大模型 Falcon 发布,迅速在 Hugging Face 开源大模型榜单上以 68.74 分超过 LLaMA 2 位列第一;传闻中,Meta 也在加快开发新的大语言模型,各项能力对标 GPT-4,预计明年就会推出。
开源大模型的不断进步、相互促进,对整个行业的影响是积极的。未来,开发者和中小企业可以以低成本调用先进的大模型,而不必被高昂的研发、采购成本拒之门外。
百川智能自成立之初,就将通过开源方式助力中国大模型生态繁荣作为公司的重要发展方向,并在激烈的竞争态势中确立了自己的目标:2023 年内还将发布千亿参数大模型,并在明年一季度推出 「超级应用」。
同行投来羡慕的眼光:「嫉妒Falcon和Baichuan背后的团队……不是因为资金或算力,就只因为团队本身……」
基于行业领先的基础大模型研发和创新能力,百川智能收获了行业的高度认可:最新开源的两款 Baichuan 2 大模型已经得到了上下游企业的积极响应,腾讯云、阿里云、火山方舟、华为、联发科等众多知名企业均与百川智能达成了合作。
前段时间,首批大模型公众服务牌照正式落地。在今年创立的大模型公司中,百川智能也是唯一一家通过《生成式人工智能服务管理暂行办法》备案,可以正式面向公众提供服务的企业。
而 Baichuan 系列大模型的开源,将汇聚社区中更多的创新力量,加速技术的迭代与应用的拓展。
技术的进步只是第一阶段,未来,大模型还需要走到产业中去,与各行各业的业务实践相结合。如何让大模型的能力与业务场景更好结合,同样是当下每一家大模型提供商的重点课题,也需要科技公司、学术机构和开发者共同创造。
......
#AdaLoRA
图解大模型微调系列之:AdaLoRA,能做“财务”预算的低秩适配器,无惧数学公式,图解AdaLoRA,简单明了搞懂原理和代码实现。
在“大模型微调系列”之前的文章中,我们介绍过LoRA的原理和代码实现。今天,我们就来看LoRA的改进版本:AdaLoRA(Adaptive Low-Rank Adaptation)的原理。
我猜,如果你曾读过AdaLoRA的原始论文,是不是曾被满屏的数学公式劝退过🐶。其实,AdaLoRA这篇论文写得非常非常好,它的数学符号简洁明了地表达出了算法的全部细节,而背后的数学原理(主要是SVD分解)其实一点也不复杂。毕竟大家都说,深度学习的数学怎么能叫....
AdaLoRA在做一件什么事
LoRA是怎么做微调的
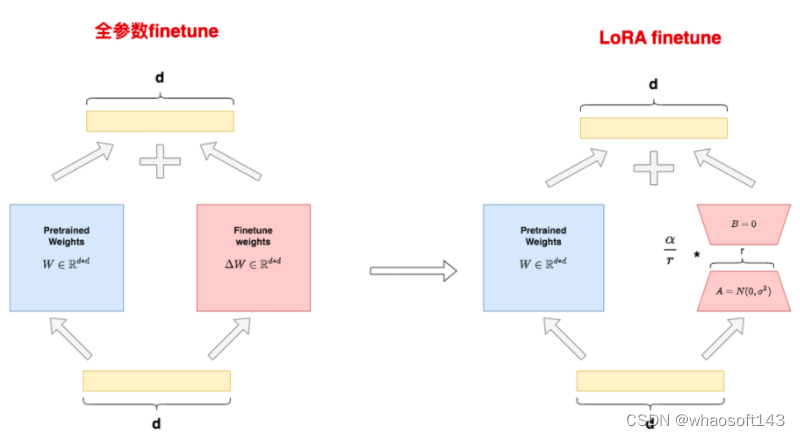

好,那么现在,问题来了:
- 对所有模块都采用同一个秩r,这是合理的吗?
- 在微调过程中,一直保持秩r不变,这是合理的吗?
我们来分别细看这两个问题。
对所有模块都采用同一个秩,是否合理
这个问题,早在AdaLoRA之前,LoRA的作者就意识到了,并做了如下实验:


所以到了AdaLoRA这里,它的作者也做了两个实验:
实验(a)对应着左图,作者使用LoRA,在模型的每个layer中微调特定的某个模块,然后去评估模型的效果。可以直观发现,微调不同模块时效果差异显著。
实验(b)对应着右图,作者使用LoRA,对模型不同layer的所有模块做微调。例如1,2,3表示对模型前三层的所有模块做lora微调。可以发现,微调不同layer时模型效果差异显著,微调最后三层的效果最好。
这些实验都证明了一件事:在使用LoRA微调时,对模型的不同模块使用相同的秩,显然是不合理的。
微调过程中一直保持秩不变,是否合理
对于这点,作者并没有做实验来说明,但我们可以从1.2的分析中得到一些思路。
在1.2中,我们通过实验证明“对不同模块采用不同秩”的必要性,那么接下来势必就要解决“每个模块的秩到底要设成多少”的问题。解答这个问题最直接的办法,就是交给模型去学。那模型学习的过程,肯定是个探索性的过程呀,理想情况下,你给模型一个初始化的秩,然后让它在训练过程中,学会慢慢调整这个秩,直到最优。 所以,在微调step的更新过程中,秩也不会保持不变。
AdaLoRA的总体改进目标
好,到此为止,AdaLoRA的总体改进目标就出来了:
找到一种办法,让模型在微调过程中,去学习每个模块参数对训练结果(以loss衡量)的重要性。然后,根据重要性,动态地调整不同模块的秩。
作者管这样的策略叫参数预算(parameter budget),作为一个学财会出身的人,这真是非常形象了。待训练的参数越多,训练代价越大,因此做好参数预算方案,集中训练最重要的那些参数,ROI才会越高。
AdaLoRA的原理
SVD分解
由于AdaLoRA重度依赖SVD分解原理,因此我把LoRA原理篇4.2节中的内容再copy一次。

我们再通过一个代码例子,更直观地感受一下这种近似,大家注意看下注释(例子改编自:https://medium.com/@Shrishml/lora-low-rank-adaptation-from-the-first-principle-7e1adec71541)
import torch
import numpy as np
torch.manual_seed(0)
# ------------------------------------
# n:输入数据维度
# m:输出数据维度
# ------------------------------------
n = 10
m = 10
# ------------------------------------
# 随机初始化权重W
# 之所以这样初始化,是为了让W不要满秩,
# 这样才有低秩分解的意义
# ------------------------------------
nr = 10
mr = 2
W = torch.randn(nr,mr)@torch.randn(mr,nr)
# ------------------------------------
# 随机初始化输入数据x
# ------------------------------------
x = torch.randn(n)
# ------------------------------------
# 计算Wx
# ------------------------------------
y = W@x
print("原始权重W计算出的y值为:\n", y)
# ------------------------------------
# 计算W的秩
# ------------------------------------
r= np.linalg.matrix_rank(W)
print("W的秩为: ", r)
# ------------------------------------
# 对W做SVD分解
# ------------------------------------
U, S, V = torch.svd(W)
# ------------------------------------
# 根据SVD分解结果,
# 计算低秩矩阵A和B
# ------------------------------------
U_r = U[:, :r]
S_r = torch.diag(S[:r])
V_r = V[:,:r].t()
B = U_r@S_r # shape = (d, r)
A = V_r # shape = (r, d)
# ------------------------------------
# 计算y_prime = BAx
# ------------------------------------
y_prime = B@A@x
print("SVD分解W后计算出的y值为:\n", y)
print("原始权重W的参数量为: ", W.shape[0]*W.shape[1])
print("低秩适配后权重B和A的参数量为: ", A.shape[0]*A.shape[1] + B.shape[0]*B.shape[1])输出结果为:
原始权重W计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
W的秩为: 2
SVD分解W后计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
原始权重W的参数量为: 100
低秩适配后权重B和A的参数量为: 40参数量变少了,但并不影响最终输出的结果。通过这个例子,大家是不是能更好体会到低秩矩阵的作用了呢~
让模型学习SVD分解的近似

AdaLoRA动态更新秩的过程
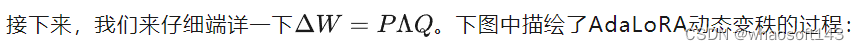
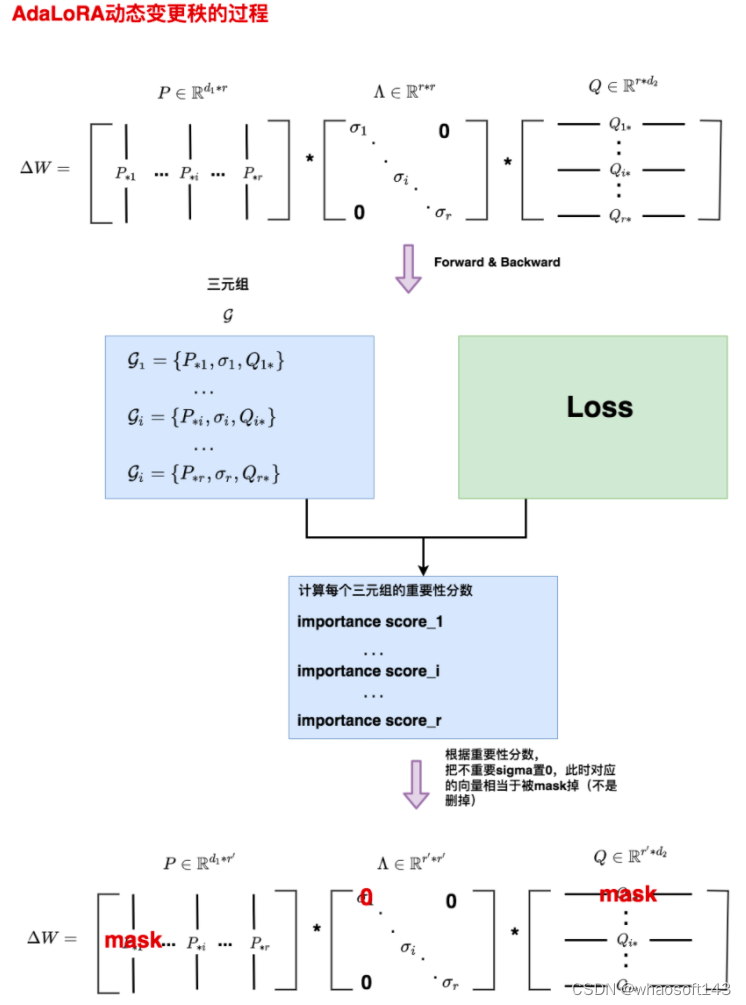
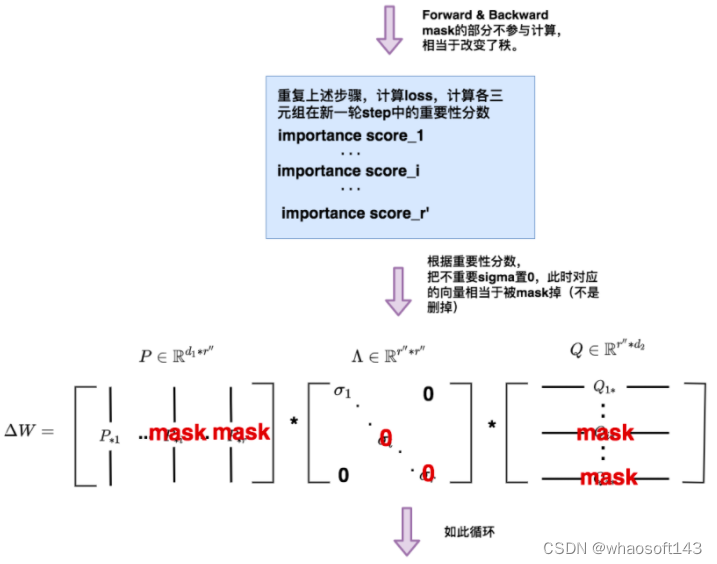
AdaLoRA变秩的整体流程如下:

好,理清了整体流程后,我们就可以来看细节了,在上述过程里,我们遗留了3个细节问题有待探讨:
- AdaLoRA中,Loss要怎么设计?
- AdaLoRA中,重要性分数要怎么算?
- AdaLoRA中,如何根据重要性分数筛选不重要的三元组,进而动态调整矩阵的秩?
我们来分别细看这三个问题。
AdaLoRA的Loss设计


其实,这也是AdaLoRA相比于LoRA效果能更好的原因之一:LoRA中是让模型学习BA,去近似SVD分解的结果,但是在训练过程中,没有引入任何SVD分解相关的性质做约束,所以模型就可能学歪了(因此LoRA作者在文章中写了很多实验,证明学出来的BA在一定程度上能近似SVD分解,能取得较好的效果)。而AdaLoRA则是直接将这一束缚考虑到了Loss中。
AdaLoRA中的重要性分数
我们依然先明确几个数学表达:

单参数重要性分数在开始正式讲重要性分数怎么算之前,我们先来看一个问题:到底什么是重要性分数?

改进:单参数重要性分数
4.1中的这个直观有效的想法,被广泛运用在前人做的参数剪枝的优化中,但它有一个显著的问题:我是在mini-batch上计算重要性分数的,不同step间重要性分数可能会受到mini-batch客观波动的影响,有啥办法能消除这种影响吗?
当然有啦,遇到这种消除波动的问题,我们肯定要祭出momentum🐶。
所以,AdaLoRA作者就提出了这样一种计算t时刻,单个模型参数重要性的方法:

三元组重要性分数
在AdaLoRA中,三元组重要性分数计算方式如下:

太好啦,到这一步为止,我们已经把AdaLoRA中难啃的Loss和三元组重要性分数讲完了,是不是比想象得简单很多?接下来我们来啃最后一块硬骨头:知道了三元组的重要性分数后,怎么动态调整矩阵的秩
动态调整矩阵的秩
老规矩,在开始讲解前,我们再来明确几个数学符号:

调整函数

top_b策略
在开始讲top_b策略前,我们先来思考一个问题:为什么每次选出的重要三元组的个数,要随着时刻t的变动而变动?
这个问题的答案还是:模型的学习是探索性的过程。
在训练刚开始,我们逐渐增加top_b,也就是逐渐加秩,让模型尽可能多探索。到后期再慢慢把top_b降下来,直到最后以稳定的top_b进行训练,达到AdaLoRA的总目的:把训练资源留给最重要的参数。这个过程就和warm-up非常相似。
具体的策略在原始论文3.3节中有讲解,不难,所以我就不另外分析啦,大家可以自行阅读。以及本文的实验部分,我也不在这边写了,实验部分一句话总结就是相比LoRA确实有了不错的提升,大家可以自己去看细节。
AdaLoRA训练流程总结(必看)
最后,我们把AdaLoRA的整体训练流程总结一下:

以此类推。😭妈呀敲字真的太累了啊。
参考
1、https://arxiv.org/abs/2303.10512
2、https://github.com/QingruZhang/AdaLoRA
......
#Baichuan2-192K
全球最长上下文窗口来了!百川智能发布Baichuan2-192K大模型,上下文窗口长度高达192K(35万个汉字),是Claude 2的4.4倍,GPT-4的14倍!
长上下文窗口领域的新标杆,来了!
百川智能正式发布全球上下文窗口长度最长的大模型——Baichuan2-192K。
与以往不同的是,此次模型的上下文窗口长度高达192K,相当于约35万个汉字。
再具体点,Baichuan2-192K能够处理的汉字是GPT-4(32K上下文,实测约2.5万字)的14倍,Claude 2(100K上下文,实测约8万字)的4.4倍,可以一次性读完一本《三体》。
laude一直以来保持的上下文窗口记录,在今天被重新刷新
把三体第一部《地球往事》丢给它,Baichuan2-192K稍加咀嚼,便立刻对整个故事了如指掌。
汪淼看到的倒计时里第36张照片上的数字是多少?答:1194:16:37。
他使用的相机是什么型号?答:徕卡M2。
他和大史一共喝过几次酒?答:两次。
再看看第二部《黑暗森林》,Baichuan2-192K不仅一下就答出了地球三体组织建立了两个红岸基地,「水滴」是由强互作用力材料制作的。
而且,就连「三体十级学者」都未必能答上来的冷门问题,Baichuan2-192K也是对答如流,信手拈来。
谁的名字出现次数最多?答:罗辑。
可以说,当上下文窗口扩展到了35万字,大模型的使用体验,仿佛忽然打开了一个新世界!
全球最长上下文,全面领先Claude 2
大模型,会被什么卡脖子?
以ChatGPT为例,虽然能力让人惊叹,然而这个「万能」模型却有一个无法回避的掣肘——最多只支持32K tokens(2.5万汉字)的上下文。而律师、分析师等职业,在大部分的时间里需要处理比这长得多的文本。
更大的上下文窗口,可以让模型从输入中获得更丰富的语义信息,甚至直接基于全文理解进行问答和信息处理。
由此,模型不仅能更好地捕捉上下文的相关性、消除歧义,进而更加精准地生成内容,缓解「幻觉」问题,提升性能。而且,也可以在长上下文的加持下,与更多的垂直场景深度结合,真正在人们的工作、生活、学习中发挥作用。
最近,硅谷独角兽Anthropic先后获得亚马逊投资40亿、谷歌投资20亿。能获得两家巨头的青睐,当然跟Claude在长上下文能力技术上的领先不无关系。
而这次,百川智能发布的Baichuan-192K长窗口大模型,在上下文窗口长度上远远超过了Claude 2-100K,而且在文本生成质量、上下文理解、问答能力等多个维度的评测中,也取得了全面领先。
10项权威评测,拿下7个SOTA
LongEval是由加州大学伯克利分校联合其他高校发布的针对长窗口模型评测的榜单,主要衡量模型对长窗口内容的记忆和理解能力。
上下文理解方面,Baichuan2-192K在权威长窗口文本理解评测榜单LongEval上大幅领先其他模型,窗口长度超过100K后依然能够保持非常强劲的性能。
相比之下,Claude 2窗口长度超过80K后整体效果下降非常严重。
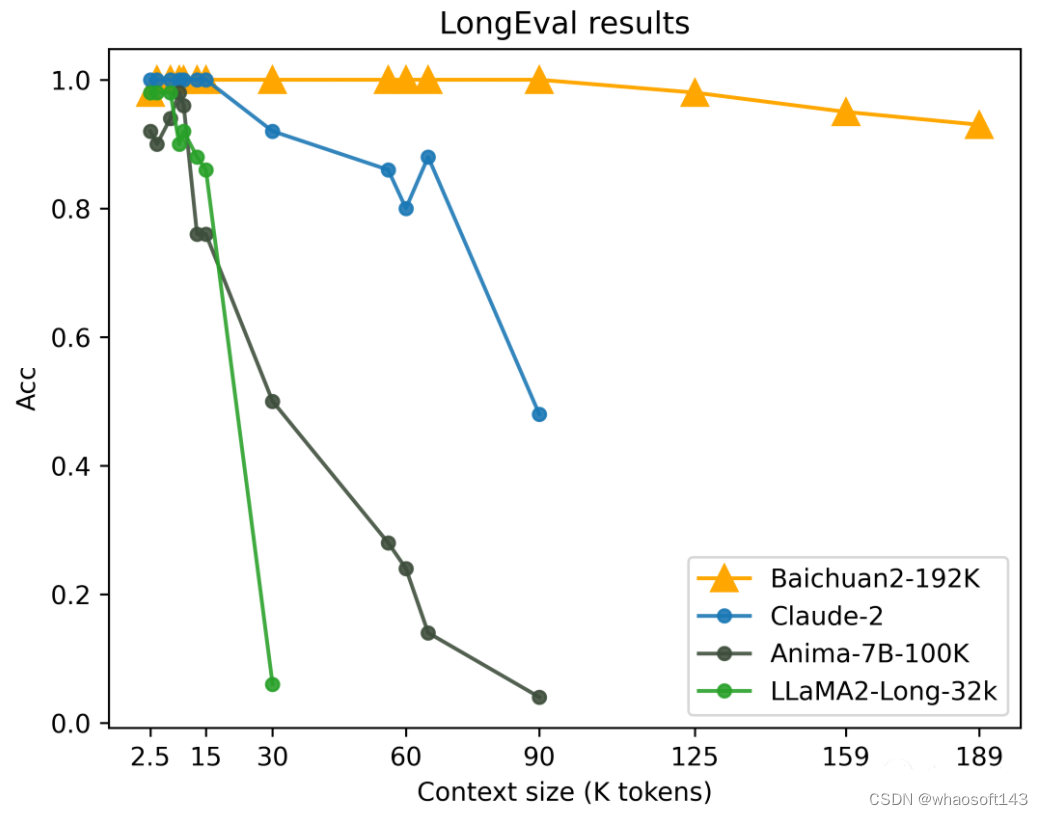
此外,Baichuan2-192K在Dureader、NarrativeQA、LSHT、TriviaQA等10项中英文长文本问答、摘要的评测集上表现同样优异。
其中,有7项取得了SOTA,性能显著超过其他长窗口模型。
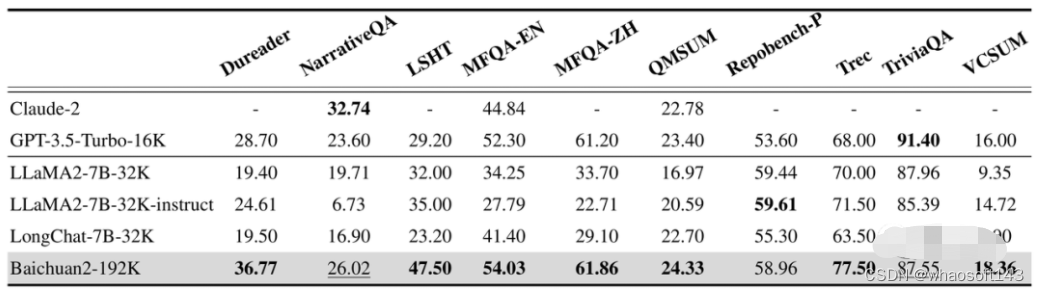
在文本生成质量方面,困惑度是一个非常重要的标准。
可以简单理解为,将符合人类自然语言习惯的高质量文档作为测试集时,模型生成测试集中文本的概率越高,模型的困惑度就越小,模型也就越好。
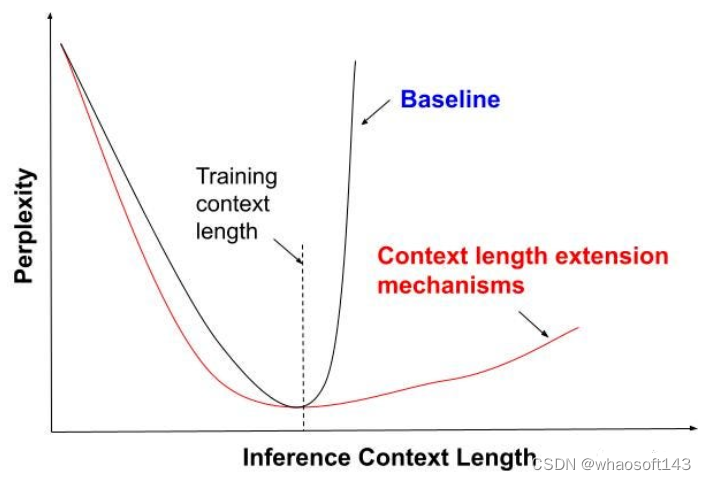
根据DeepMind发布的「语言建模基准数据集PG-19」的测试结果,Baichuan2-192K的困惑度在初始阶段便很优秀,并且随着窗口长度扩大,Baichuan2-192K的序列建模能力也持续增强。
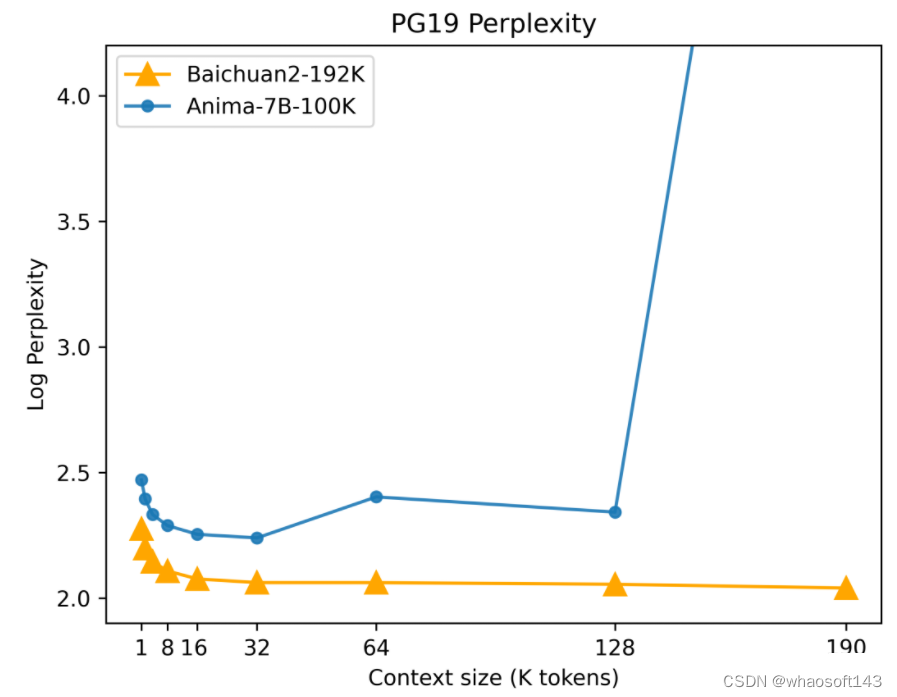
工程算法联合优化,长度性能同步提升
虽然长上下文可以有效提升模型性能,但超长的窗口也意味着需要更强的算力,以及更多的显存。
目前,业界普遍的做法是滑动窗口、降低采样、缩小模型等等。
然而,这些方式都会在不同程度上,牺牲模型其他方面的性能。
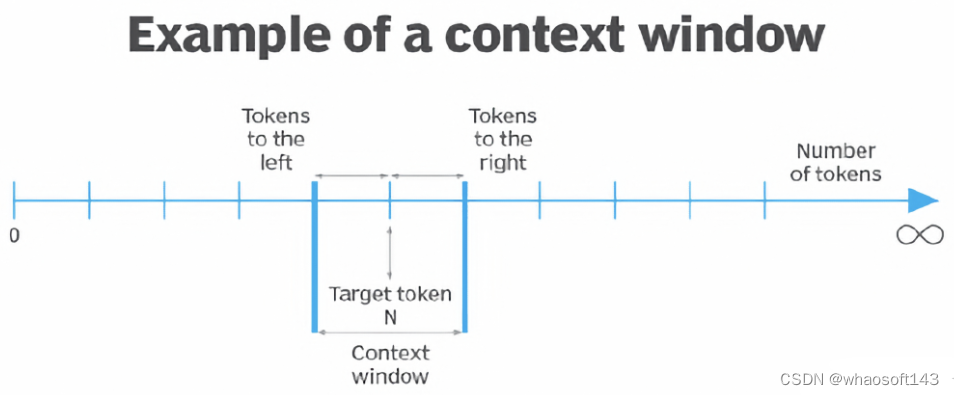
为了解决这一问题,Baichuan2-192K通过算法和工程的极致优化,实现了窗口长度和模型性能之间的平衡,做到了窗口长度和模型性能的同步提升。
首先,在算法方面,百川智能提出了一种针对RoPE和ALiBi动态位置编码的外推方案——能够对不同长度的ALiBi位置编码进行不同程度的Attention-mask动态内插,在保证分辨率的同时增强了模型对长序列依赖的建模能力。
其次,在工程方面,百川智能在自主开发的分布式训练框架基础上,整合了包括张量并行、流水并行、序列并行、重计算以及Offload等市面上几乎所有的先进优化技术,独创出了一套全面的4D并行分布式方案——能够根据模型具体的负载情况,自动寻找最适合的分布式策略,极大降低了长窗口训练和推理过程中的显存占用。
内测正式开启,一手体验出炉
现在,Baichuan2-192K已经正式开启内测!
百川智能的核心合作伙伴已经通过 API 调用的方式将Baichuan2-192K 接入到了自己的应用和业务当中,现在已有财经类媒体、律师事务所等机构和百川智能达成了合作。
可以想象,随着Baichuan2-192K全球领先的长上下文能力应用到传媒、金融、法律等具体场景中,无疑会给大模型落地拓展出更广阔的空间。
通过API,Baichuan2-192K能有效融入更多垂直场景,与之深度结合。
以往,巨量内容的文档,往往成为我们在工作、学习中难以跨越的大山。
而有了Baichuan2-192K,就能一次性处理和分析数百页的材料,进行关键信息的提取和分析。
无论是长文档摘要/审核,长篇文章或报告的编写,还是复杂的编程辅助,Baichuan2-192K都将提供巨大的助力。
对于基金经理,它可以帮忙总结和解释财务报表,分析公司的风险和机遇。
对于律师,它可以帮助识别多个法律文件中的风险,审核合同和法律文件。
对于开发者,它可以帮忙阅读数百页的开发文档,还能回答技术问题。
而广大科研人员,从此也有了科研利器,可以快速浏览大量论文,总结最新的前沿进展。
除此之外,更长的上下文还蕴涵着更加巨大的潜力。
Agent、多模态应用,都是当前业内研究的前沿热点。而大模型有了更长的上下文能力,就能更好地处理和理解复杂的多模态输入,实现更好的迁移学习。
上下文长度,兵家必争之地
可以说,上下文窗口长度,是大模型的核心技术之一。
现在,许多团队都开始以「长文本输入」为起点,打造底座大模型的差异化竞争力。如果说参数量决定了大模型能做多复杂的计算,上下文窗口长度,则决定了大模型有多大「内存」。
Sam Altman就曾表示,我们本以为自己想要的是会飞的汽车,而不是140/280个字符,但实际上我们想要的是32000个token。
国内外,对扩大上下文窗口的研究和产品可谓是层出不穷。
今年5月,拥有32K上下文的GPT-4,就曾引发过激烈的讨论。
当时,已经解锁这一版本的网友大赞称,GPT-4 32K是世界上最好的产品经理。
很快,初创公司Anthropic宣布,Claude已经能够支持100K的上下文token长度,也就是大约75,000个单词。
换句话说就是,一般人用时大约5个小时读完等量内容后,还得用更多的时间去消化、记忆、分析。对于Claude,不到1分钟就搞定。
在开源社区,Meta也提出了一种可以有效扩展上下文能力的方法,能够让基础模型的上下文窗口达到32768个token,并在各种合成上下文探测、语言建模任务上都取得了显著的性能提升。
结果表明,70B参数量的模型就已经在各种长上下文任务中实现了超越gpt-3.5-turbo-16k的性能。
论文地址:https://arxiv.org/abs/2309.16039
港中文和MIT团队研究人员提出的LongLoRA方法,只需两行代码、一台8卡A100机器,便可将7B模型的文本长度拓展到100k tokens,70B模型的文本长度拓展到32k tokens。
论文地址:https://arxiv.org/abs/2309.12307
而来自DeepPavlov、AIRI、伦敦数学科学研究所的研究人员则利用循环记忆Transformer(RMT)方法,将BERT的有效上下文长度提升到「前所未有的200万tokens」,并且保持了很高的记忆检索准确性。
不过,虽然RMT可以不增加内存消耗,能够扩展到近乎无限的序列长度,但仍然存在RNN中的记忆衰减问题,并且需要更长的推理时间。
论文地址:https://arxiv.org/abs/2304.11062
目前,LLM的上下文窗口长度主要集中在4,000-100,000个token这个范围之间,并且还在持续增长。
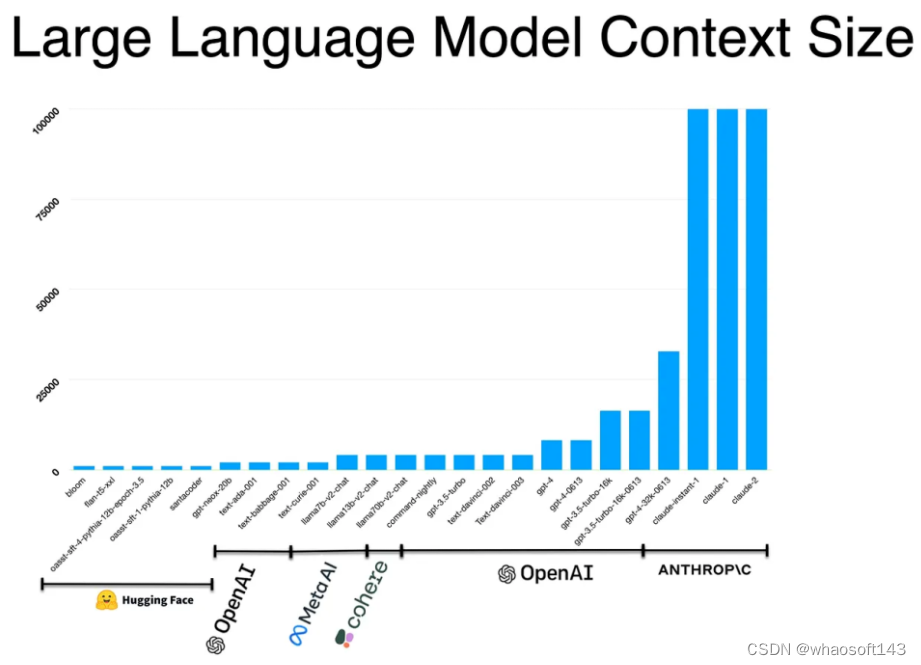
通过AI产业界和学术界对上下文窗口的多方面研究,足见其对于LLM的重要性。
而这一次,国内的大模型迎来了最长上下文窗口的历史高光时刻。
刷新行业纪录的192K上下文窗口,不仅代表着百川智能这家明星公司在大模型技术上又一次突破,也是大模型发展过程中的又一里程碑式进展。而这,必然会给产品端形态改革带来新一轮的震动。
成立于2023年4月的百川智能,用了仅仅6个月的时间,便接连发布了Baichuan-7B/13B,Baichuan2-7B/13B四款开源可免费商用大模型,以及Baichuan-53B、Baichuan2-53B两款闭源大模型。
这么算来,基本上是一月一更LLM。
现在,随着Baichuan2-192K的发布,大模型长上下文窗口技术也将全面走进中文时代!
#上面肌肉说到了大模型 下面在说一下模型下载把
如何利用huggingface的镜像网站,来解决大模型下载困难的问题。
不知道大家最近有没有这种痛苦,大模型下载太困难了。(不涉及国外的朋友们)
主要由于huggingface必须要上网才能访问,而7B规模的模型一般在14G大小左右,13B规模的模型一般在28G左右,这还是模型按照ft16或bf16存贮,如果是float32存储还需要翻一倍,流量是真的吃不消。(有不限量的另说!毕竟我只有100G,下载几个就GG了...)
如何能解决上面的问题呢,具体有两个方法:
- 用阿里的魔搭社区来下载模型,但缺点是并不是所有模型魔搭上都有;
- 找一些huggingface的镜像网站,不是所有的镜像网站模型都是全的。
正好有群友搭了一个huggingface镜像网站,特此宣传一波,反正我现在使用时速度飞起(可能用的人还不是很多)。
Huggingface镜像网站:https://hf-mirror.com
对于很多人来说,在网页上点击下载是一个办法,但一个一个点会有些麻烦,因此,这里这里也介绍一下通过代码下载大模型的整体方法。
@huggingface官网下载
from huggingface_hub import snapshot_download
snapshot_download(repo_id='Qwen/Qwen-7B',
repo_type='model',
local_dir='./model_dir',
resume_download=True)其中,repo_id为huggingface模型仓库ID,repo_type仓库类型,包含model和data两种,local_dir本地保存路径,如果没有会下载到 /root/.cache/huggingface目录下,resume_download为是否断点续传。
huggingface镜像网站下载
由于snapshot_download函数中默认的下载路径为"https://huggingface.co",只需将镜像网站地址设置为"https://hf-mirror.com"即可。
linux中执行
export HF_ENDPOINT=https://hf-mirror.com再使用下面代码进行模型下载即可。
from huggingface_hub import snapshot_download
snapshot_download(repo_id='Qwen/Qwen-7B',
repo_type='model',
local_dir='./model_dir',
resume_download=True)PS:附上群友的Github,纯纯为爱发电。
@阿里魔搭社区下载
需要安装modelscope包。
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('qwen/Qwen-7B',
cache_dir='./model_dir',
revision='master')PS:其实huggingface不能访问的这一阵子,魔搭真的吃了不少流量,只希望模型可以越来越多,希望国产社区越做越好。
......
#Qwen-VL
阿里开源大模型,又上新了~
继通义千问-7B(Qwen-7B)之后,阿里云又推出了大规模视觉语言模型Qwen-VL,并且一上线就直接开源。
具体来说,Qwen-VL是基于通义千问-7B打造的多模态大模型,支持图像、文本、检测框等多种输入,并且在文本之外,也支持检测框的输出。
举个🌰,我们输入一张阿尼亚的图片,通过问答的形式,Qwen-VL-Chat既能概括图片内容,也能定位到图片中的阿尼亚。

测试任务中,Qwen-VL展现出了“六边形战士”的实力,在四大类多模态任务的标准英文测评中(Zero-shot Caption/VQA/DocVQA/Grounding)上,都取得了SOTA。
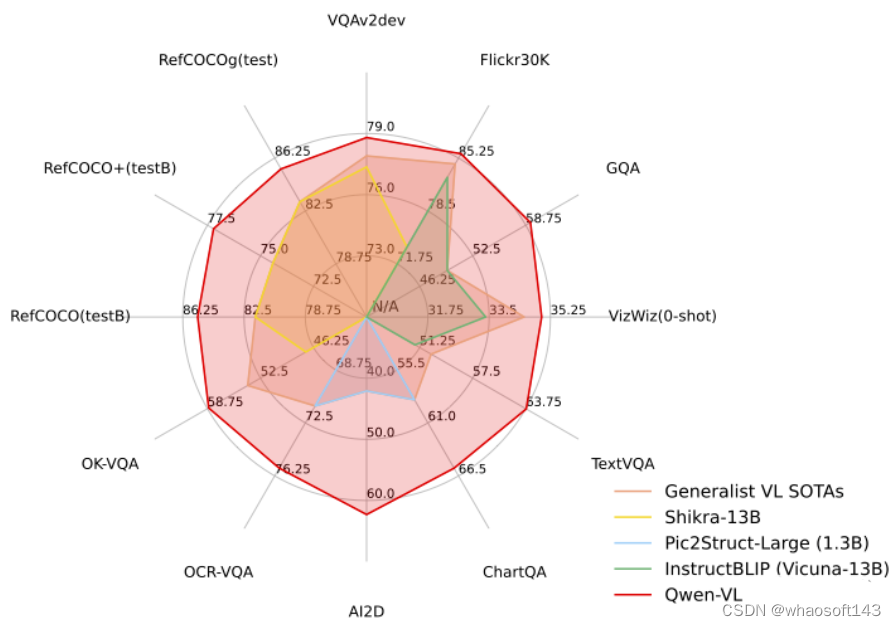
开源消息一出,就引发了不少关注。

首个支持中文开放域定位的通用模型
先来整体看一下Qwen-VL系列模型的特点:
- 多语言对话:支持多语言对话,端到端支持图片里中英双语的长文本识别;
- 多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;
- 首个支持中文开放域定位的通用模型:通过中文开放域语言表达进行检测框标注,也就是能在画面中精准地找到目标物体;
- 细粒度识别和理解:相比于目前其它开源LVLM(大规模视觉语言模型)使用的224分辨率,Qwen-VL是首个开源的448分辨率LVLM模型。更高分辨率可以提升细粒度的文字识别、文档问答和检测框标注。
按场景来说,Qwen-VL可以用于知识问答、图像问答、文档问答、细粒度视觉定位等场景。
比如,有一位看不懂中文的外国友人去医院看病,对着导览图一个头两个大,不知道怎么去往对应科室,就可以直接把图和问题丢给Qwen-VL,让它根据图片信息担当翻译。

再来测试一下多图输入和比较:
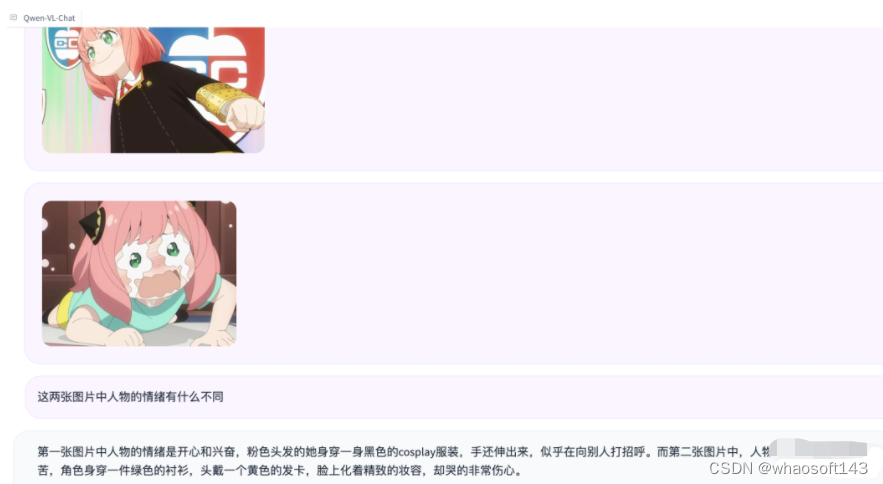
虽然没认出来阿尼亚,不过情绪判断确实挺准确的(手动狗头)。视觉定位能力方面,即使图片非常复杂人物繁多,Qwen-VL也能精准地根据要求找出绿巨人和蜘蛛侠。
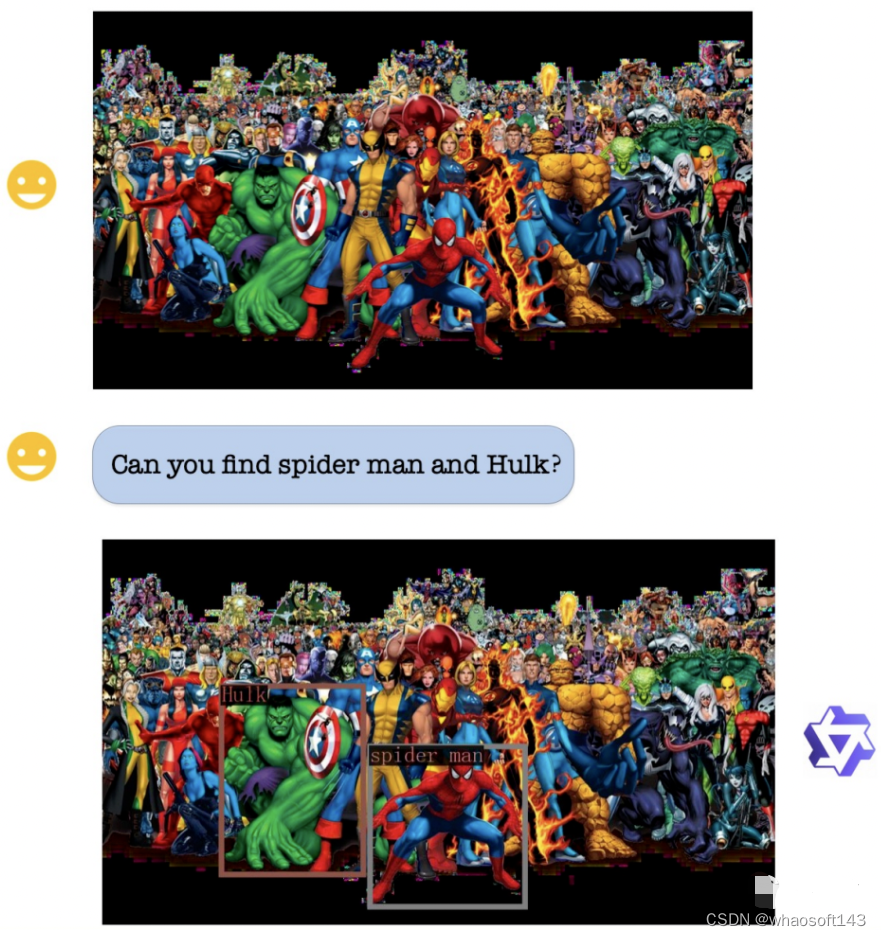
技术细节上,Qwen-VL是以Qwen-7B为基座语言模型,在模型架构上引入了视觉编码器ViT,并通过位置感知的视觉语言适配器连接二者,使得模型支持视觉信号输入。
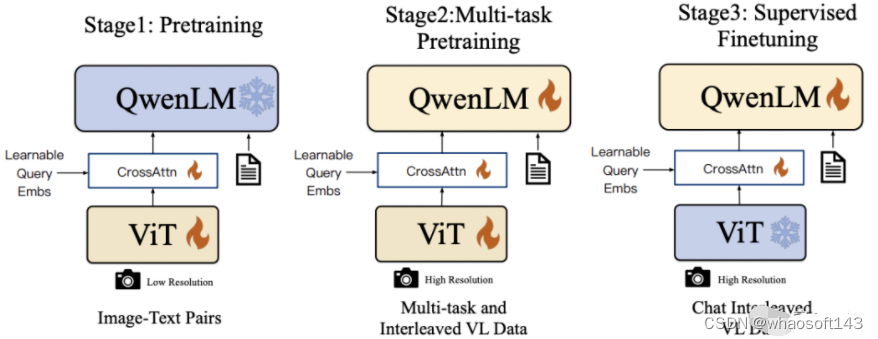
具体的训练过程分为三步:
- 预训练:只优化视觉编码器和视觉语言适配器,冻结语言模型。使用大规模图像-文本配对数据,输入图像分辨率为224x224。
- 多任务预训练:引入更高分辨率(448x448)的多任务视觉语言数据,如VQA、文本VQA、指称理解等,进行多任务联合预训练。
- 监督微调:冻结视觉编码器,优化语言模型和适配器。使用对话交互数据进行提示调优,得到最终的带交互能力的Qwen-VL-Chat模型。
研究人员在四大类多模态任务(Zero-shot Caption/VQA/DocVQA/Grounding)的标准英文测评中测试了Qwen-VL。
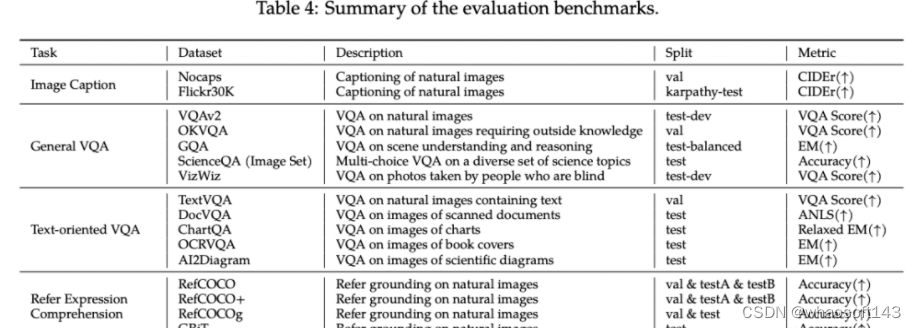
结果显示,Qwen-VL取得了同等尺寸开源LVLM的最好效果。另外,研究人员构建了一套基于GPT-4打分机制的测试集TouchStone。
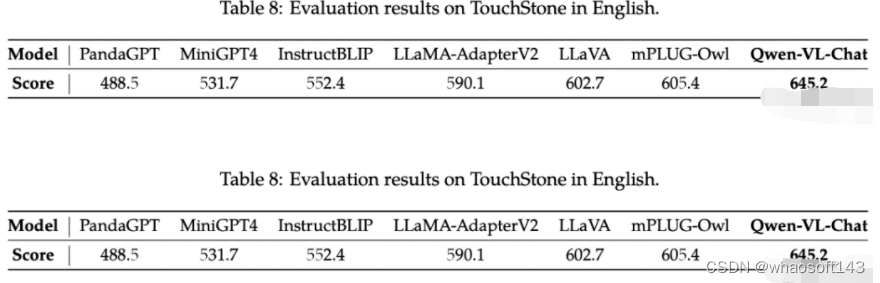
在这一对比测试中,Qwen-VL-Chat取得了SOTA。
如果你对Qwen-VL感兴趣,现在在魔搭社区和huggingface上都有demo可以直接试玩,链接文末奉上~
Qwen-VL支持研究人员和开发者进行二次开发,也允许商用,不过需要注意的是,商用的话需要先填写问卷申请。
项目链接:
https://modelscope.cn/models/qwen/Qwen-VL/summary https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary https://huggingface.co/Qwen/Qwen-VL https://huggingface.co/Qwen/Qwen-VL-Chat https://github.com/QwenLM/Qwen-VL
论文地址:
https://arxiv.org/abs/2308.12966
......
#MiniGPT-5
统一图像和文字生成的MiniGPT-5来了:Token变Voken,模型不仅能续写,还会自动配图了,OpenAI 的 GPT-5 大模型似乎还遥遥无期,但已经有研究者率先推出了创新视觉与语言交叉生成的模型 MiniGPT-5。这对于生成具有连贯文本描述的图像具有重要意义。
大模型正在实现语言和视觉的跨越,有望无缝地理解和生成文本和图像内容。在最近的一系列研究中,多模态特征集成不仅是一种不断发展的趋势,而且已经带来了从多模态对话到内容创建工具等关键进步。大型语言模型在文本理解和生成方面已经展现出无与伦比的能力。然而,同时生成具有连贯文本叙述的图像仍然是一个有待发展的领域。
近日,加州大学圣克鲁兹分校的研究团队提出了 MiniGPT-5,这是一种以 「生成式 voken」概念为基础的创新型交错视觉语言生成技术。
- 论文地址:https://browse.arxiv.org/pdf/2310.02239v1.pdf
- 项目地址:https://github.com/eric-ai-lab/MiniGPT-5
通过特殊的视觉 token「生成式 voken」,将 Stable Diffusion 机制与 LLM 相结合, MiniGPT-5 为熟练的多模态生成预示了一种新模式。同时,本文提出的两阶段训练方法强调了无描述基础阶段的重要性,使模型在数据稀缺的情况下也能「茁壮成长」。该方法的通用阶段不需要特定领域的注释,这使得本文解决方案与现有的方法截然不同。为了确保生成的文本和图像和谐一致,本文的双损失策略开始发挥作用,生成式 voken 方法和分类方法进一步增强了这一效果。
在这些技术的基础上,这项工作标志着一种变革性的方法。通过使用 ViT(Vision Transformer)和 Qformer 以及大型语言模型,研究团队将多模态输入转换为生成式 voken,并与高分辨率的 Stable Diffusion2.1 无缝配对,以实现上下文感知图像生成。本文将图像作为辅助输入与指令调整方法相结合,并率先采用文本和图像生成损失,从而扩大了文本和视觉之间的协同作用。
MiniGPT-5 与 CLIP 约束等模型相匹配,巧妙地将扩散模型与 MiniGPT-4 融合在一起,在不依赖特定领域注释的情况下实现了较好的多模态结果。最重要的是,本文的策略可以利用多模态视觉语言基础模型的进步,为增强多模态生成能力提供新蓝图。
如下图所示,除了原有的多模态理解和文本生成能力外,MiniGPT5 还能提供合理、连贯的多模态输出:
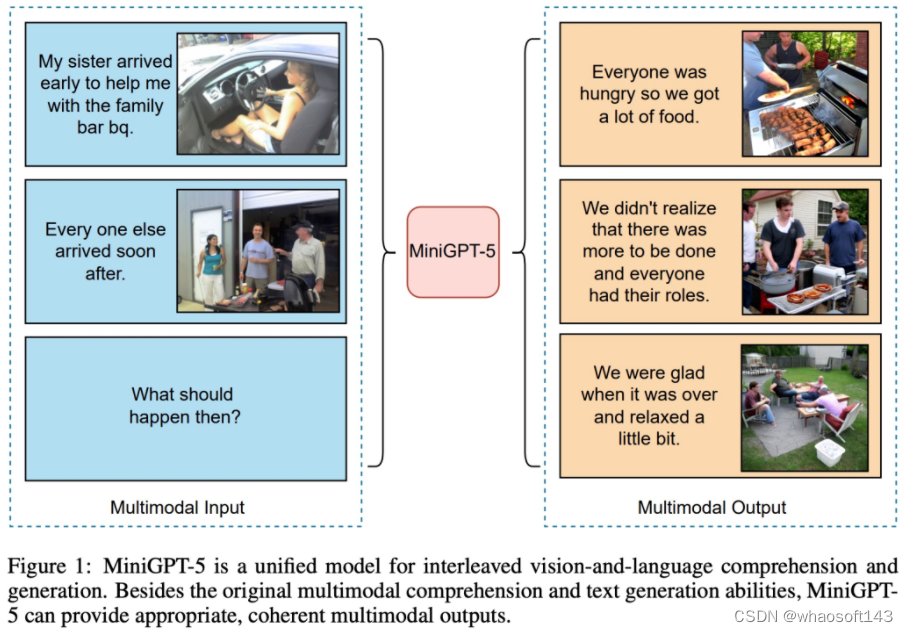
本文贡献体现在三个方面:
- 建议使用多模态编码器,它代表了一种新颖的通用技术,并已被证明比 LLM 和反转生成式 vokens 更有效,并将其与 Stable Diffusion 相结合,生成交错的视觉和语言输出(可进行多模态生成的多模态语言模型)。
- 重点介绍了一种新的两阶段训练策略,用于无描述多模态生成。单模态对齐阶段从大量文本图像对中获取高质量的文本对齐视觉特征。多模态学习阶段包括一项新颖的训练任务,即 prompt 语境生成,确保视觉和文本 prompt 能够很好地协调生成。在训练阶段加入无分类器指导,进一步提高了生成质量。
- 与其他多模态生成模型相比, MiniGPT-5 在 CC3M 数据集上取得了最先进的性能。MiniGPT-5 还在 VIST 和 MMDialog 等著名数据集上建立了新的基准。
接下来,我们一起来看看该研究的细节。
方法概览
为了使大型语言模型具备多模态生成能力,研究者引入了一个结构化框架,将预训练好的多模态大型语言模型和文本到图像生成模型整合在一起。为了解决不同模型领域之间的差异,他们引入了特殊的视觉符号「生成式 voken」(generative vokens),能够直接在原始图像上进行训练。此外,还推进了一种两阶段训练方法,并结合无分类器引导策略,以进一步提高生成质量。
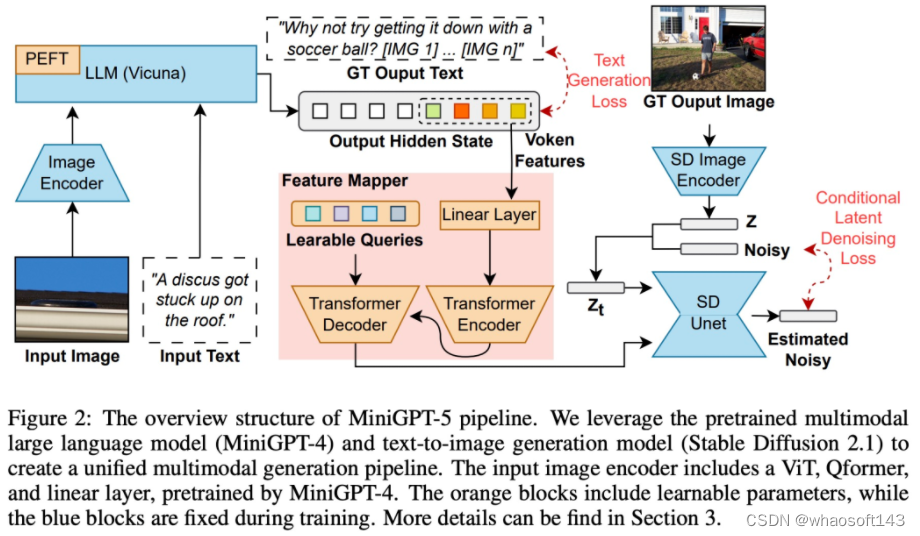
多模态输入阶段
多模态大模型(如 MiniGPT-4)的最新进展主要集中在多模态理解方面,能够处理作为连续输入的图像。为了将其功能扩展到多模态生成,研究者引入了专为输出视觉特征而设计的生成式 vokens。此外,他们还在大语言模型(LLM)框架内采用了参数效率高的微调技术,用于多模态输出学习。
多模态输出生成
为了使生成式 token 与生成模型精确对齐,研究者制定了一个用于维度匹配的紧凑型映射模块,并纳入了若干监督损失,包括文本空间损失和潜在扩散模型损失。文本空间损失有助于模型学习 token 的正确定位,而潜在扩散损失则直接将 token 与适当的视觉特征对齐。由于生成式符号的特征直接由图像引导,因此该方法不需要全面的图像描述,从而实现了无描述学习。
训练策略
鉴于文本域和图像域之间存在不可忽略的领域偏移,研究者发现直接在有限的文本和图像交错数据集上进行训练可能会导致错位和图像质量下降。
因此,他们采用了两种不同的训练策略来缓解这一问题。第一种策略包括采用无分类器引导技术,在整个扩散过程中提高生成 token 的有效性;第二种策略分两个阶段展开:最初的预训练阶段侧重于粗略的特征对齐,随后的微调阶段致力于复杂的特征学习。
实验及结果
为了评估模型功效,研究者选择了多个基准进行了一系列评估。实验旨在解决几个关键问题:
- MiniGPT-5 能否生成可信的图像和合理的文本?
- 在单轮和多轮交错视觉语言生成任务中,MiniGPT-5 与其他 SOTA 模型相比性能如何?
- 每个模块的设计对整体性能有什么影响?
为了评估模型在不同训练阶段的不同基准上的性能,MiniGPT-5 的定量分析样本如下图 3 所示:

此处的评估横跨视觉(图像相关指标)和语言(文本指标)两个领域,以展示所提模型的通用性和稳健性。
VIST Final-Step 评估
第一组实验涉及单步评估,即根据最后一步的 prompt 模型生成相应的图像,结果如表 1 所示。
在所有三种设置中,MiniGPT-5 的性能都优于微调后的 SD 2。值得注意的是,MiniGPT-5(LoRA)模型的 CLIP 得分在多种 prompt 类型中始终优于其他变体,尤其是在结合图像和文本 prompt 时。另一方面,FID 分数凸显了 MiniGPT-5(前缀)模型的竞争力,表明图像嵌入质量(由 CLIP 分数反映)与图像的多样性和真实性(由 FID 分数反映)之间可能存在权衡。与直接在 VIST 上进行训练而不包含单模态配准阶段的模型(MiniGPT-5 w/o UAS)相比,虽然该模型保留了生成有意义图像的能力,但图像质量和一致性明显下降。这一观察结果凸显了两阶段训练策略的重要性。
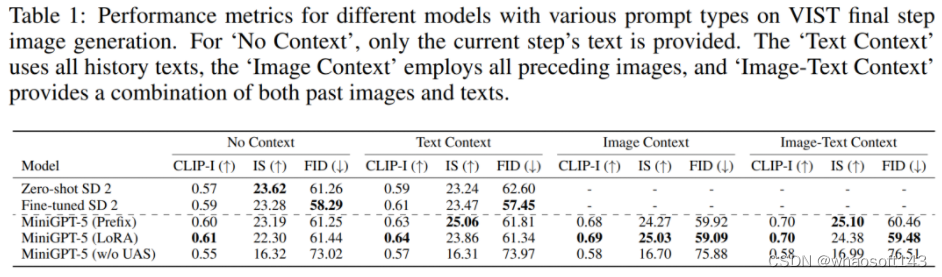
VIST Multi-Step 评估
在更详细全面的评估中,研究者系统地为模型提供了先前的历史背景,并随后在每个步骤中对生成的图像和叙述进行评估。
表 2 和表 3 概述了这些实验的结果,分别概括了图像和语言指标的性能。实验结果表明,MiniGPT-5 能够在所有数据中利用 long-horizontal 多模态输入 prompt 生成连贯、高质量的图像,而不会影响原始模型的多模态理解能力。这凸显了 MiniGPT-5 在不同环境中的功效。

VIST 人类评估
如表 4 所示,MiniGPT-5 在 57.18% 的情况下生成了更贴切的文本叙述,在 52.06% 的情况下提供了更出色的图像质量,在 57.62% 的场景中生成了更连贯的多模态输出。与采用文本到图像 prompt 叙述而不包含虚拟语气的两阶段基线相比,这些数据明显展示了其更强的多模态生成能力。
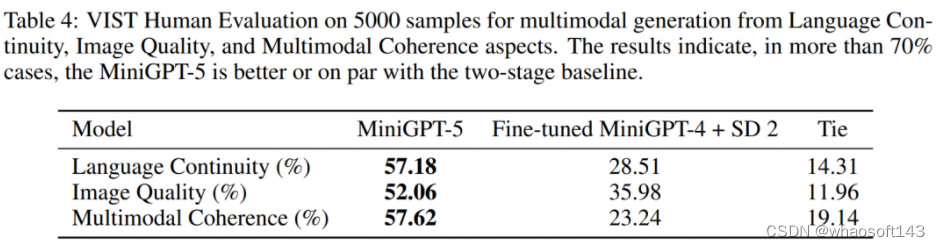
MMDialog 多轮评估
结果如表 5 所示,MiniGPT-5 在生成更准确的文本回复方面优于基线模型 Divter。虽然生成的图像质量相似,但与基准模型相比,MiniGPT-5 在 MM 相关性方面更胜一筹,表明其可以更好地学习如何适当定位图像生成,并生成高度一致的多模态响应。
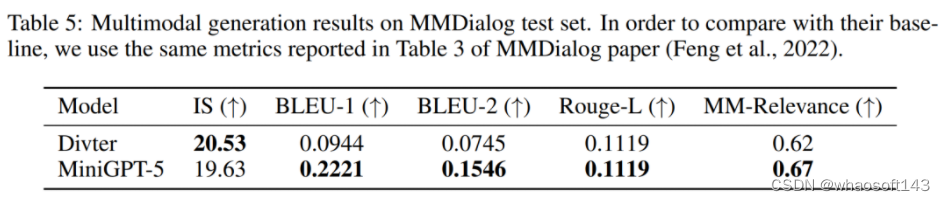
效果如何呢?我们来看一下 MiniGPT-5 的输出结果。下图 7 为 MiniGPT-5 与 CC3M 验证集上的基线模型比较。

下图 8 为 MiniGPT-5 与 VIST 验证集上基线模型的比较。

下图 9 为 MiniGPT-5 与 MMDialog 测试集上基线模型的比较。


......
#AutoGen
正如网友所说的,借助 AutoGen,以后完成某项任务,用户只需给出需求,敲下回车,中间过程完全不用管,任务自动就完成了。智能体聊聊天就把问题解决了
一个项目,用了短短两个星期的时间,星标量从 390 狂增到 10K,并在 Discord 上吸引了 5000 多名成员,如此爆火的项目便是微软最近发布的全新工具 AutoGen。
我们可以将 AutoGen 理解为一个框架,其允许多个 LLM 智能体通过聊天来解决任务。LLM 智能体可以扮演各种角色,如程序员、设计师,或者是各种角色的组合,对话过程就把任务解决了。
不仅如此,AutoGen 是可定制的、可对话的,并且允许人类参与。AutoGen 的运作方式包括借助 LLM 完成任务、人类输入和各种工具的相互组合。
项目地址:https://github.com/microsoft/autogen
有用过该项目的用户给与了极高的评价,表示道:「给出需求,敲下回车,中间过程完全不用管……」

还有网友表示:「AutoGen 在几秒钟内帮我制作了一个贪吃蛇游戏」。
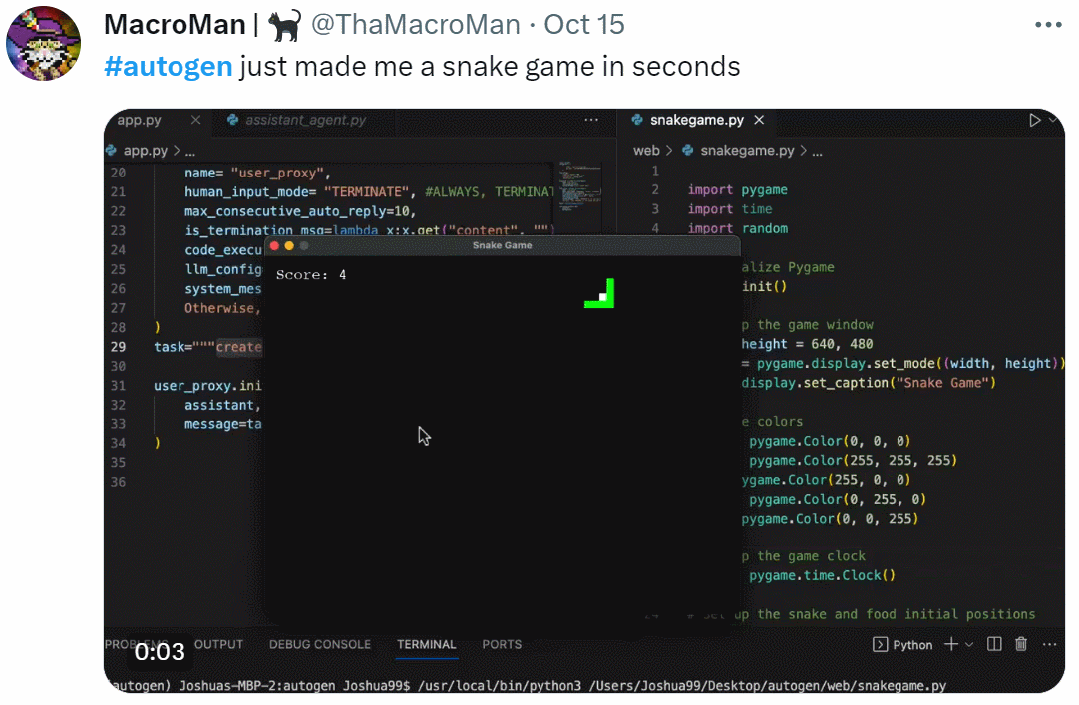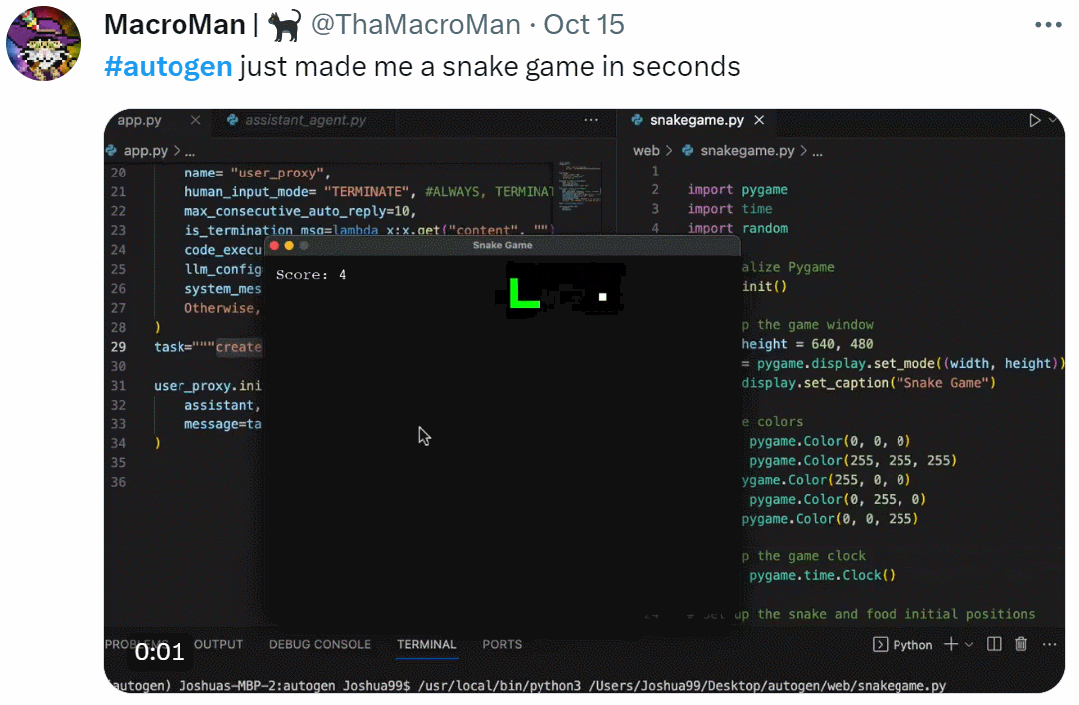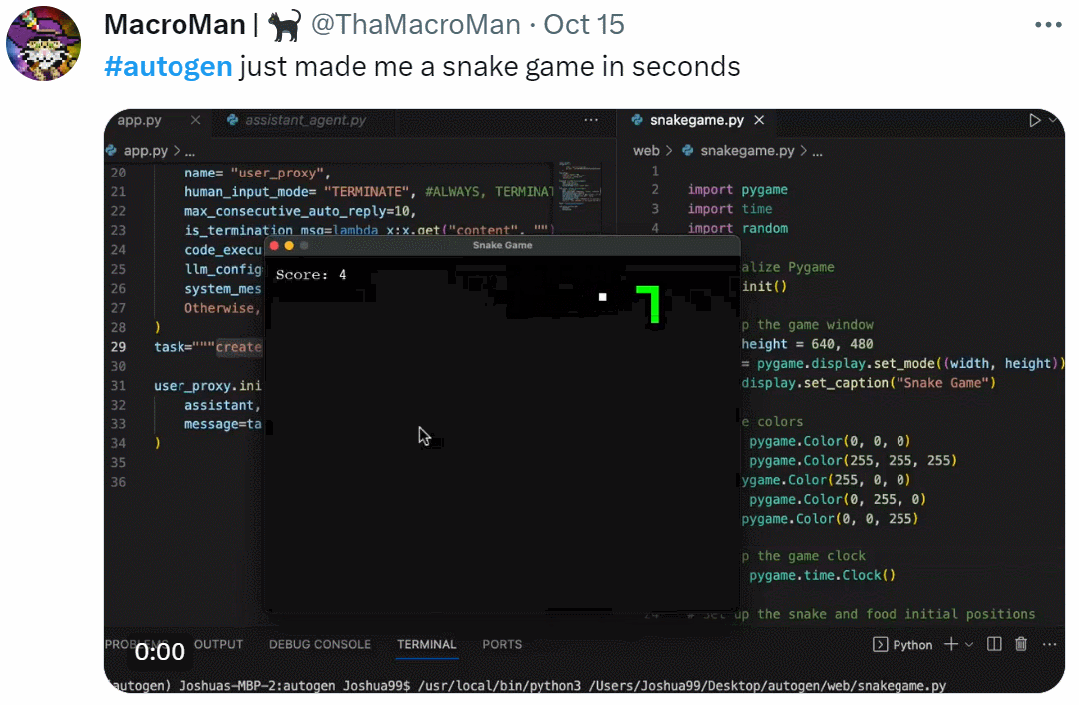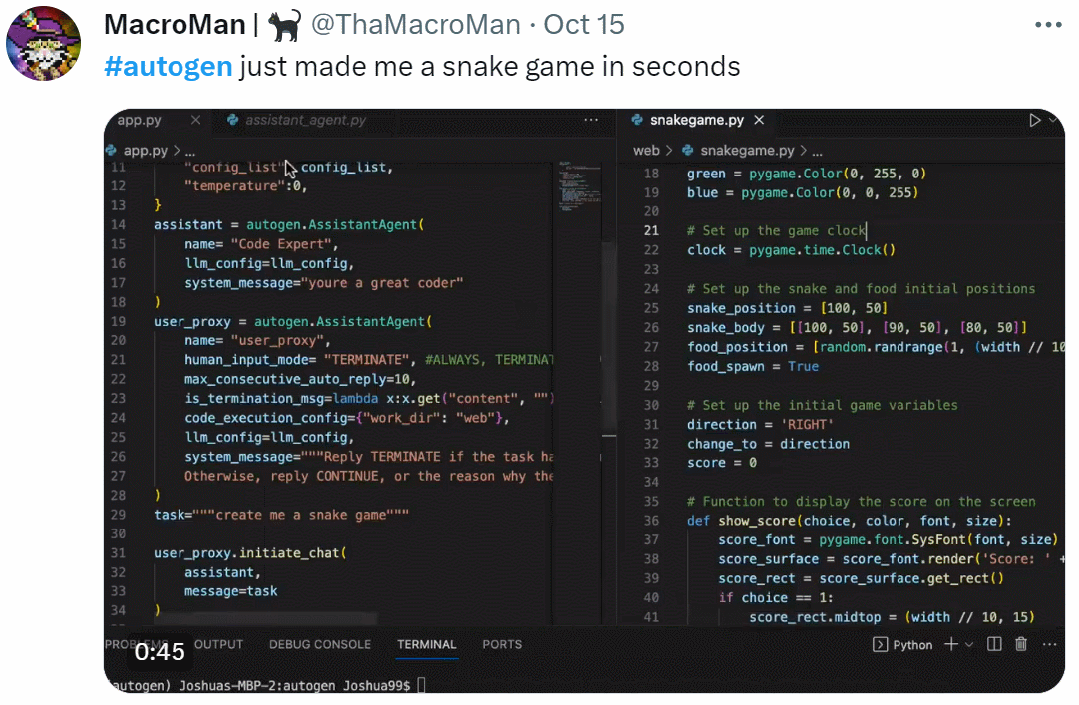
那么大家纷纷叫好的项目,到底有哪些优点呢,具体来说:
- AutoGen 基于多智能体对话可以轻松构建下一代 LLM 应用程序,它简化了复杂 LLM 的工作流程,最大限度地提高了 LLM 模型的性能并克服了它们的弱点。
- AutoGen 支持多种对话模式,因而开发人员基于 AutoGen 可以构建广泛的对话模式。
- AutoGen 提供了一系列具有不同复杂性的工作系统,不同领域和各种应用都包含在内。
- AutoGen 提供了 openai.Completion 或 openai.ChatCompletion 的直接替代,作为增强推理的 API。
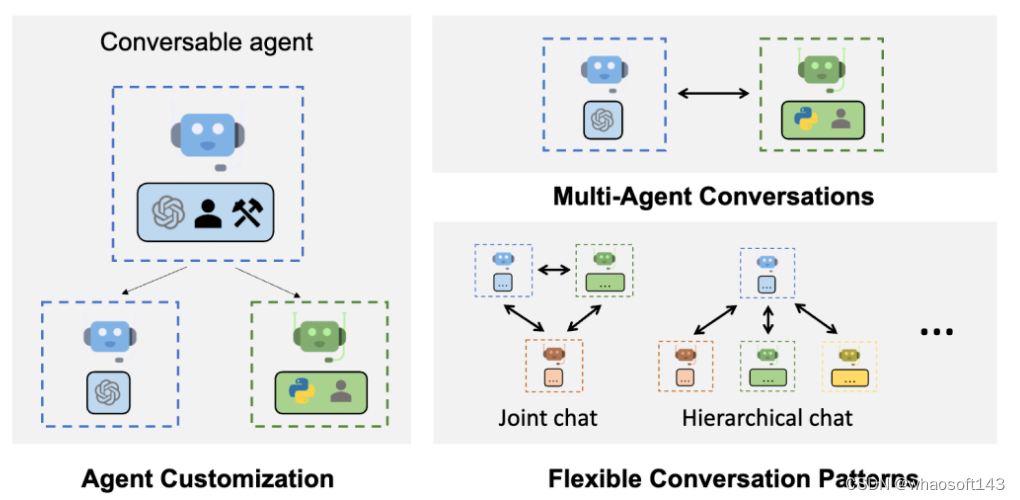
另外,项目中也给出了许多示例来帮助大家更好的运用 AutoGen。举例来说,根据一位网友的说法,假如想要实现一个爬虫程序,并且抓取并保存网页图片。用 ChatGPT 来实现的话,会返回执行代码,一般来说代码不能直接使用,需要人类进行修正。但是,如果将这个任务交给 AutoGen,你只需要定义几个智能体就可以实现了。
如下示例展示了借助 AutoGen 框架,使用 MathChat 解决数学问题时,运行代码中出现了构建智能体这一步骤,并对其进行了初始化:
下图显示了使用 AutoGen 构建的六个应用程序示例,包括数学问题解决、多智能体编码、在线决策制定、检索增强聊天、动态群聊以及对话式国际象棋。
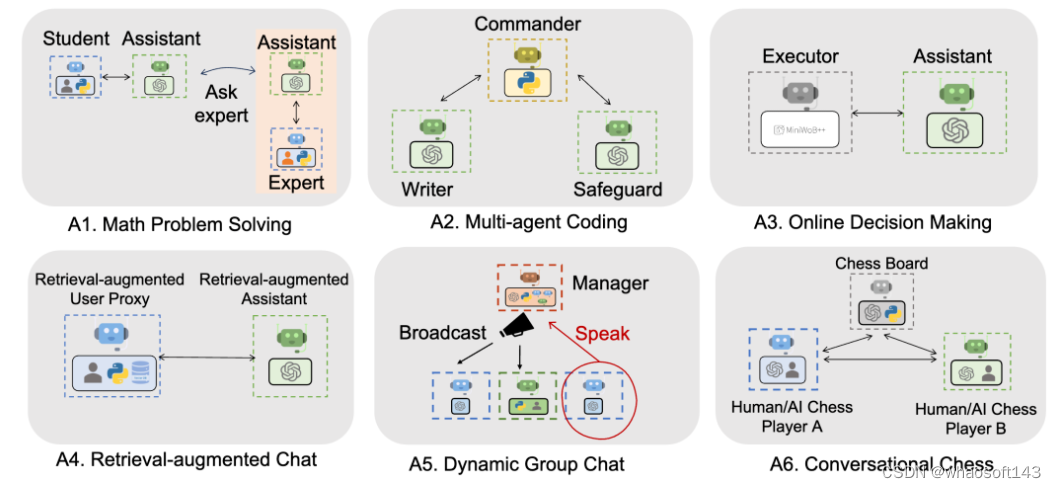
AutoGen 还有助于最大限度地提高 ChatGPT 和 GPT-4 等 LLM 的效用。就如前面提到的,AutoGen 提供了 openai.Completion 或 openai.ChatCompletion 的直接替代,还添加了更多功能,如调优、缓存、错误处理和模板。例如,用户可以使用自己的调优数据,在预算范围内来优化 LLM 的生成内容。
# perform tuning
config, analysis = autogen.Completion.tune (
data=tune_data,
metric="success",
mode="max",
eval_func=eval_func,
inference_budget=0.05,
optimization_budget=3,
num_samples=-1,
)
# perform inference for a test instance
response = autogen.Completion.create (context=test_instance, **config)以上这些用例显示了 AutoGen 在解决各种问题上的广泛适用性,使其成为开发者的宝贵工具。还没体验的小伙伴,根据官方提供的安装步骤,可以上手一试了。
参考链接:
https://twitter.com/Barret_China/status/1712408323851788505
......
#EMO~~
端侧轻量级小模型也「EMO 」?结合 Attention 重新思考移动端小模型中的基本模块
作者简单地结合了 IRB 和 Transformer 的设计思路,希望结合 Attention 重新思考移动端小模型中的基本模块。不但在多个视觉任务中超越了以往的边缘设备轻量级小模型,同时具有更高的吞吐量。
EMO:结合 Attention 重新思考移动端小模型中的基本模块
论文名称:Rethinking Mobile Block for Efficient Neural Models
论文地址:
https://arxiv.org/pdf/2301.01146.pdf
近年来,由于存储和计算资源的限制,移动应用的需求不断增加,因此,本文的研究对象是端侧轻量级小模型 (参数量一般在 10M 以下) 。在众多小模型的设计中,值得注意的是 MobileNetv2[1] 提出了一种基于 Depth-wise Convolution 的高效的倒残差模块 (Inverted Residual Block, IRB) ,已成标准的高效轻量级模型的基本模块。此后,很少有设计基于CNN 的端侧轻量级小模型的新思想被引入,也很少有新的轻量级模块跳出 IRB 范式并部分取代它。
近年来,视觉 Transformer 由于其动态建模和对于超大数据集的泛化能力,已经成功地应用在了各种计算机视觉任务中。但是,Transformer 中的 Multi-Head Self-Attention (MHSA) 模块,受限于参数和计算量的对于输入分辨率的平方复杂度,往往会消耗大量的资源,不适合移动端侧的应用。所以说研究人员最近开始结合 Transformer 与 CNN 模型设计高效的混合模型,并在精度,参数量和 FLOPs 方面获得了比基于 CNN 的模型更好的性能,代表性的工作有:MobileViT[2],MobileViT V2[3],和 MobileViT V3[4]。但是,这些方案往往引入复杂的结构或者混合模块,这对具体应用的优化非常不利。
所以本文作者简单地结合了 IRB 和 Transformer 的设计思路,希望结合 Attention 重新思考移动端小模型中的基本模块。如下图1所示是本文模型 Efficient MOdel (EMO) 与其他端侧轻量级小模型的精度,FLOPs 和 Params 对比。EMO 实现了新的 SoTA,超越了 MViT,EdgeViT 等模型。
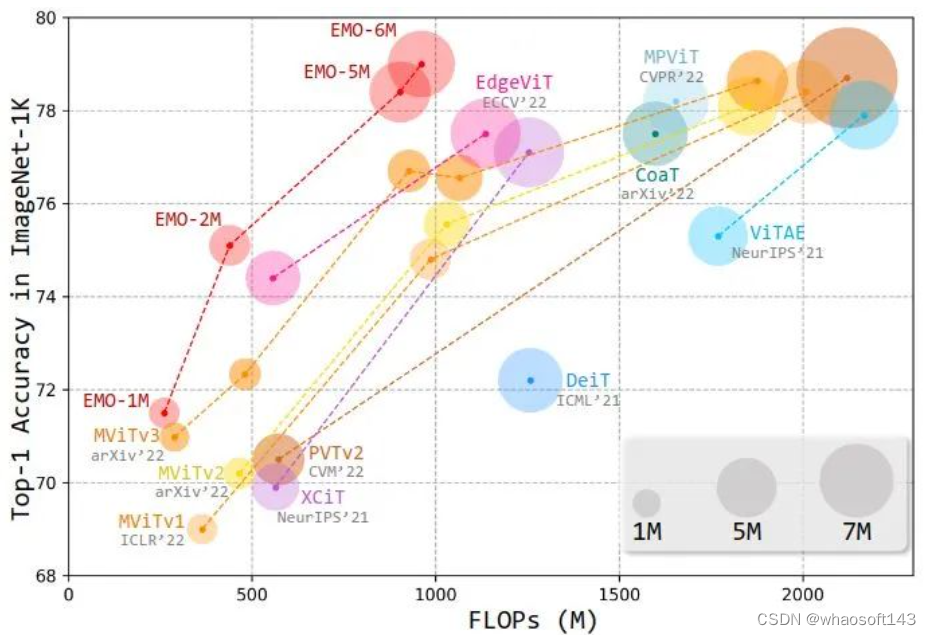
图1:EMO 与其他端侧轻量级小模型的精度,FLOPs 和 Params 对比
Meta Mobile Block
如下图2所示,作者首先结合 Transformer 中的多头注意力机制 (MHSA) 和 FFN 模块以及 MobileNet-v2中的倒残差模块 (Inverted Residual Block, IRB),引入了一种 Meta Mobile Block。
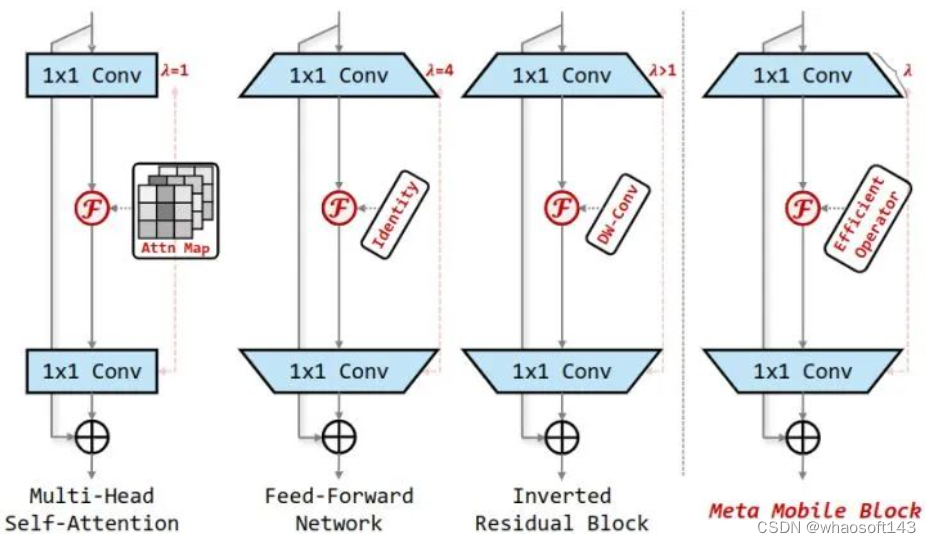
图2:抽象的 Meta Mobile Block

倒移动残差模块 (Inverted Residual Mobile Block)
在 Meta Mobile Block 的基础上,作者进一步设计了一种高效的倒残差模块,就是既有 CNN 的局部建模,也依赖 Transformer 的全局建模能力 (级联的 MHSA 和 Convolution 操作)
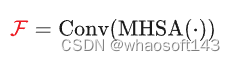
为了节约计算开销 (MHSA 的参数和计算量的对于输入分辨率的平方复杂度),作者使用 DW-Conv 来实现卷积,借助 Window-Based MHSA (W-MHSA) 使得计算复杂度变为线性。
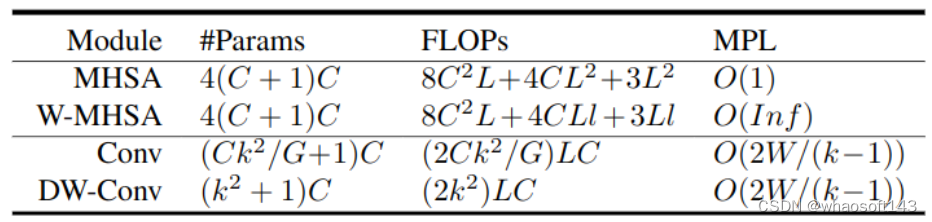
图3:不同模块的计算复杂度和 Maximum Path Length (MPL) 对比

作者称这样实现的 MHSA 为 Expanded Window MHSA (EW-MHSA),所以最后倒移动残差模块的表达式可以写成:
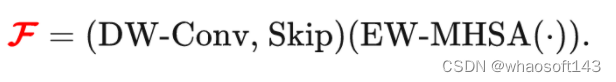
结构如下图5所示。
高效模型应该满足的标准
作者在本文中定义了高效模型应该满足以下标准:
- 可用性: 实现简单,不使用复杂的操作符,优化方案比较容易。
- 一致性: 尽量少的核心模块,以降低模型的复杂度。
- 有效性: 具有良好的分类和密集预测性能。
- 高效性: 参数计算量,与精度的权衡。
作者按照自己定的4条标准,对以往的高效边缘侧模型进行了对比,结果如下图4所示。作者认为 MobileNet 系列的精度目前看来略低,参数量也较大。MobileViT 系列,EdgeNeXt 和 EdgeViT 取得了显著的性能,但它们的 FLOPs 较高,且有复杂的模块。
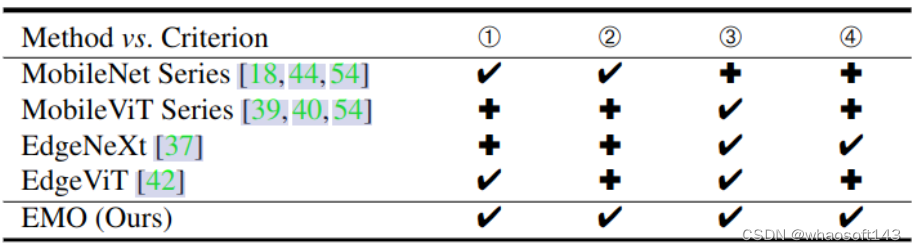
图4:以往的高效边缘侧模型的对比
基于上述标准,作者基于倒移动残差模块设计了一个类似 ResNet 的四阶段高效模型 (EMO),如下图5所示。
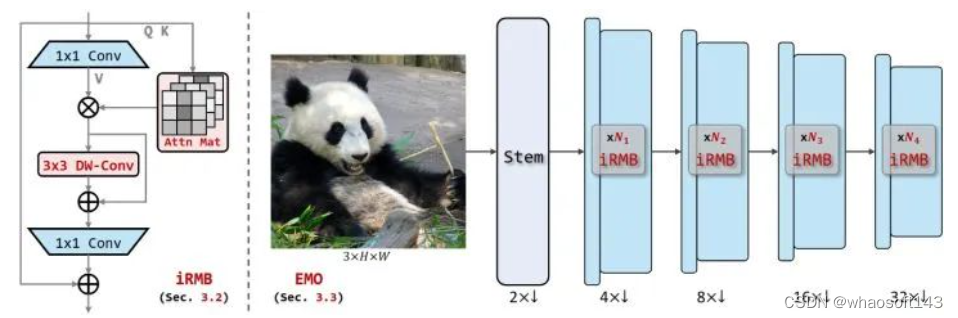
图5:EMO 模型
- 在整体框架上,EMO 仅由 iRMB 组成,没有其他复杂的操作符。
- iRMB 仅由标准卷积和 MHSA 组成,没有其他复杂的操作符。此外,得益于 DW-Conv, iRMB 可以通过 stride 来完成下采样操作。
- EMO 模型的详细架构配置如下图5所示。由于 MHSA 更适合为更深层次的语义特征建模,所以作者只在 Stage3 和 Stage4 使用 MHSA。为了进一步提高 EMO 的稳定性和效率,在 Stage1 和 Stage2 使用 BN + SiLU,在 Stage3 和 Stage4 使用 LN + ReLU。
实验结果
ImageNet-1K 实验结果
每个模型在 224×224 上从头开始300个 Epochs,优化器使用 AdamW,权重衰减设为 5e−2,学习率设为 6e−3,Batch Size 大小设置为2048。不使用 LayerScale,Dropout,MixUp,CutMix,Random Erasing,位置编码,Token Labeling 和多尺度训练。EMO 基于 PyTorch 实现,基于 timm 库,使用 8×V100 GPU 进行训练。
实验结果如下图6所示,EMO 在没有使用复杂模块和 MobileViT V2 类强训练方法的情况下获得了更好的结果。比如,最小的 EMO-1M 获得了 71.5% Top1 精度,超过了基于 CNN 的 MobileNetv3-L-0.50,和基于 Transformer 的 MobileViTv2-0.5。更大的 EMO-1M 达到了 75.1% 的 Top-1 精度。在将 EMO-5M Stage4 的通道从288增加到320后,新的 EMO-6M 达到 79.0% Top1 精度,且只有 961M FLOPs。
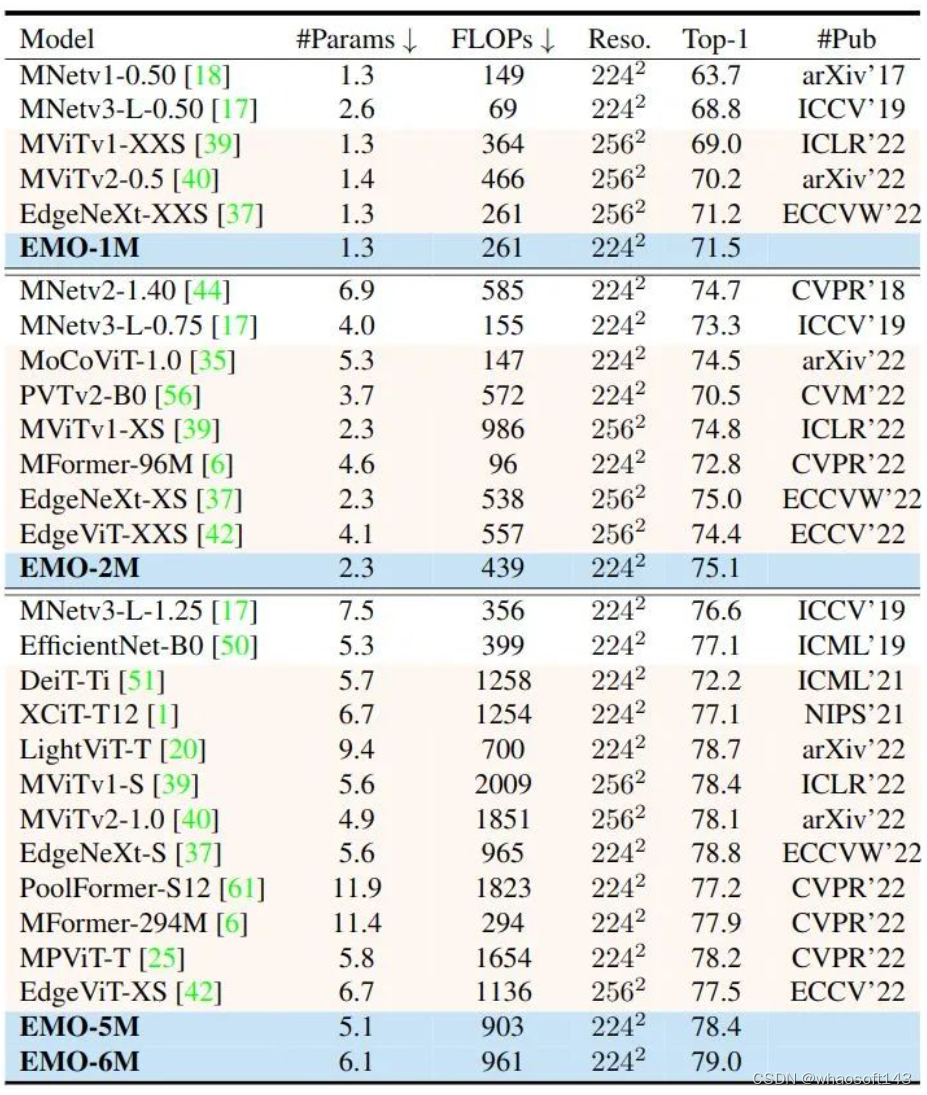
图6:ImageNet-1K 实验结果
目标检测实验结果
实验设置: ImageNet-1K 预训练的 EMO 模型,检测模型使用 SSDLite 和 RetinaNet,数据集使用 MS-COCO 2017,结果如下图6和图7所示。EMO 优于同类方法,而且优势明显。比如,配备 EMO-1M 的 SSDLite 实现了 22.0的 mAP,且只有 0.6G FLOPs 和 2.3M 的参数。EMO-5M 获得了最高的 27.9 mAP,且 FLOPs 更少 (少于 MobileViT-S 的 3.4G 和 EdgeNeXt-S 的 0.3G)。
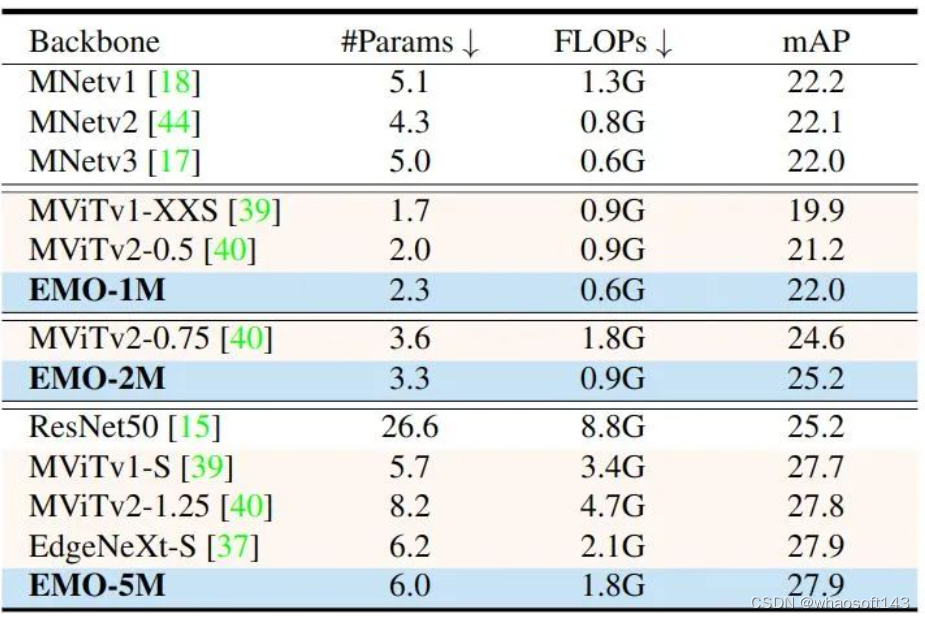
图7:SSDLite 目标检测实验结果
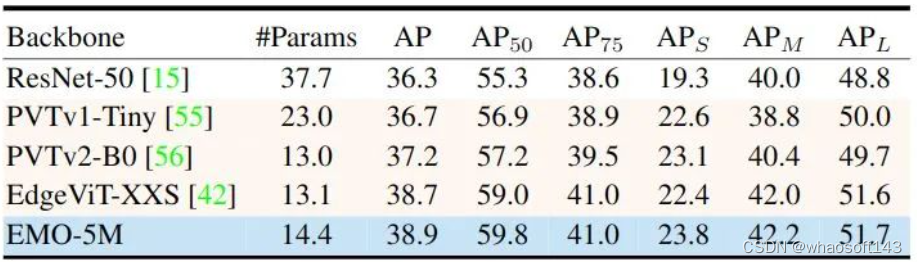
图8:RetinaNet 目标检测实验结果
语义分割实验结果
实验设置: ImageNet-1K 预训练的 EMO 模型,语义分割模型使用 DeepLabv3 和 PSPNet,数据集使用 ADE20K。实验结果如图9所示,EMO 在整合到分割框架时,在各个尺度上都明显优于基于 Ttransformer 的MobileViT V2。将 EMO 作为 PSPNet 的骨干网络模型,可以得到一致的结论。
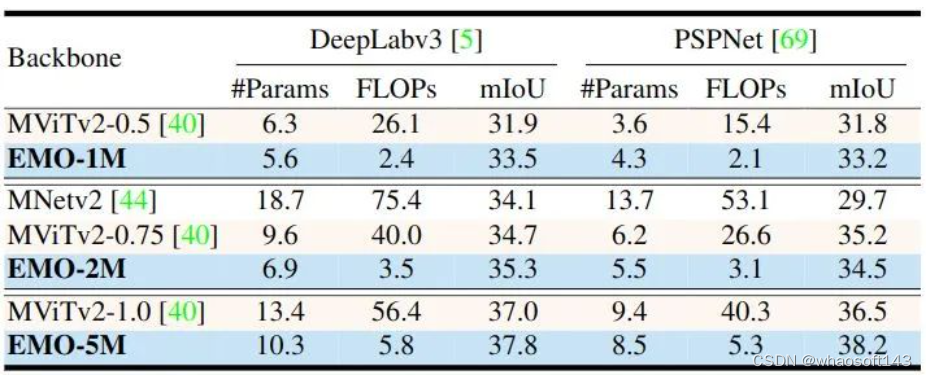
图9:语义分割实验结果
消融实验结果
如下图10所示,作者给出了与 SoTA EdgeNeXt 相比的吞吐量评估结果。测试平台为 AMD EPYC 7K62 CPU 和 V100 GPU,Batch Size 的大小为256。结果表明,EMO 模型在两个平台上都有明显更快的速度,尽管两种方法的 FLOPs 是相似的。例如,EMO-1M 与 EdgeNeXt-XXS 相比,在相同的 FLOPs 下,GPU 速度提升 +20%↑,CPU 速度提升 +116%↑。这是因为 EMO 只使用了一个简单的 iRMB,没有其他复杂的结构。
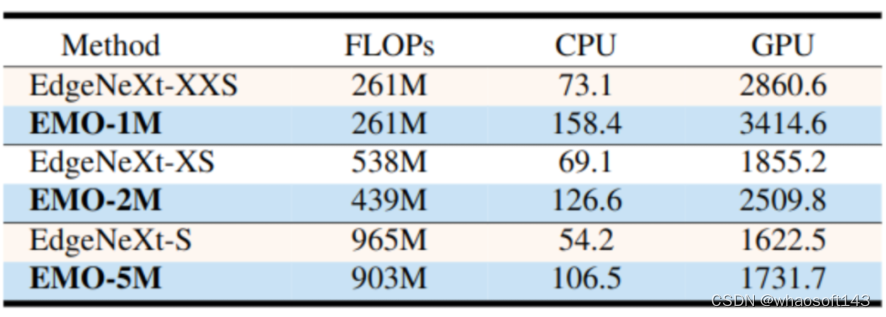
图10
总结
本文作者简单地结合了 IRB 和 Transformer 的设计思路,希望结合 Attention 重新思考移动端小模型中的基本模块。具体而言,作者结合 Transformer 中的多头注意力机制 (MHSA) 和 FFN 模块以及 MobileNet-v2中的倒残差模块 (Inverted Residual Block, IRB),引入了一种 Meta Mobile Block。不但在多个视觉任务中超越了以往的边缘设备轻量级小模型,同时具有更高的吞吐量。
......

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)