Rust:所有权
深入讲解Rust的所有权机制,移动语义,RAII,NLL等
Rust:所有权
所有权
编程中老生常谈的一个问题就是内存安全。对于一些解释语言,往往会使用垃圾回收器处理,但是它的回收时机不确定,性能也会有所损失。另一种则是自行管理,比如C语言,这需要程序员本身有足够的实力。在C的基础上,C++引入了RAII思想的智能指针,极大降低了内存泄露的可能性,但仍无法杜绝。
在Rust的探索过程中,采用了C++的智能指针方案,在这个基础上引入了所有权系统,既保证了安全性,又没有带来效率损失,可以说Rust是目前最领先的一套方案。
所有权基本原则:
- 一块内存必须被唯一的变量所拥有
- 当变量生命周期结束,将其拥有的资源一起释放(RAII)
而当一个变量拥有某块内存的所有权,它可以进行以下操作:
- 释放资源
- 移动所有权
- 出借所有权
接下来三个小节,分别对应以上的三个操作。
- 值语义与引用语义:移动所有权
- RAII:释放资源
- 借用:出借所有权
值语义 与 引用语义
不论哪一门语言编写出的程序,都需要运行在操作系统上,而操作系统将堆区和栈区开放给用户自行操作,因此任何语言都要遵循堆栈这套内存模型。
当一个数据类型完全在栈区,那么就称它是一个值类型。而如果在堆区存放数据,而在栈区保留指向堆区的指针,就称为引用类型。所有语言的类型系统都可以被分为这两种类型,甚至在部分面向对象语言中,只保留了引用类型,而弱化值类型的概念。
但是如果有一些数据在堆区和栈区都存储了有效数据,这又算哪一种类型?
这种类型在Rust中广泛存在,因为Rust很多地方都使用了胖指针,胖指针就同时在堆和栈存储了数据。
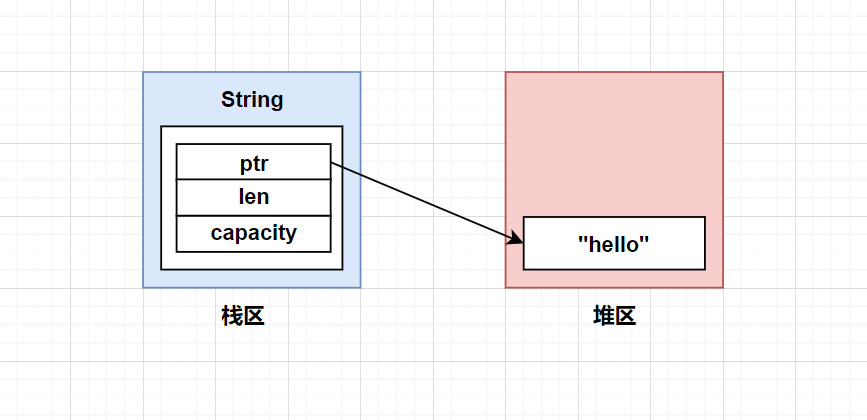
以上是String的示意图,它在栈区存储了元信息,在堆区存储了字符串本体。
为了更好的描述,这里引入了值语义和引用语义。
- 值语义:按位拷贝后,与原始对象无关
- 引用语义:一般是指将数据存放在堆内存中,在栈区使用指针访问的数据。如果直接拷贝,会导致多个指针指向同一数据。
值语义和引用语义在内存模型上是数据存放位置的不同,而在编写程序上带来的是拷贝时的行为不同。
值语义的拷贝:
let x = 10;
let y = x;
以上代码中,i32是一个很常见的值类型,拷贝示意图如下:

整个过程只是把栈区中的数据进行一次简单的拷贝,由于数据本身就完全处于栈中,因此此时生成了两份完全独立的数据。
引用语义的拷贝:
let s1 = String::from("hello");
let s2 = s1;
字符串String在栈中存储胖指针,将字符串本体存储在堆区。直接进行拷贝示意如下:
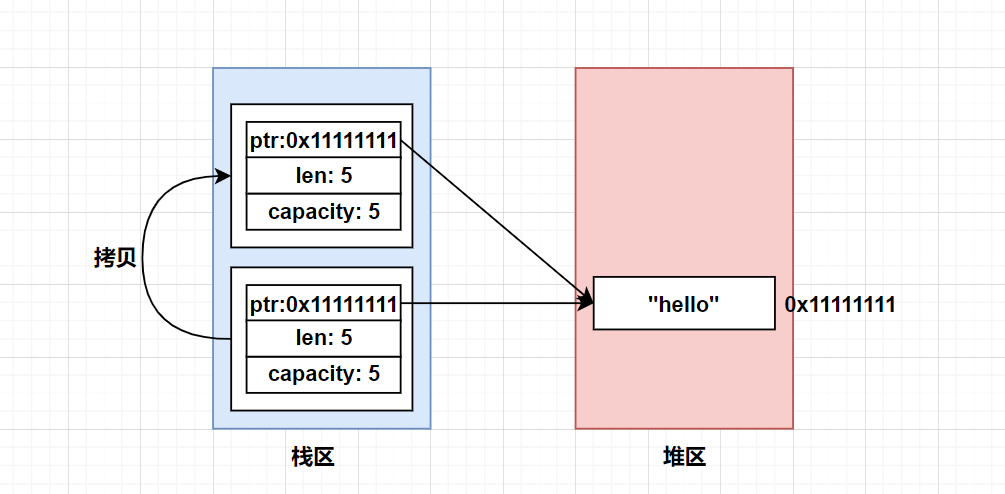
整个拷贝过程,同样只是把栈区的数据简单的拷贝了一份。对于len和capacity来说已经变成了两份,而ptr也是直接拷贝,导致两个ptr指向了堆区的同一个字符串。
这个过程叫做浅拷贝,也就是只拷贝了栈区的数据。对于值类型来说,浅拷贝没有任何问题,但是对于引用类型,浅拷贝会导致一个数据被多个所有者持有,这违背了所有权的要求。
所以在Rust中,引用语义不会发生简单的浅拷贝。
拷贝 与 移动
在Rust中,值语义的类型默认发生拷贝,而引用语义的类型默认发生移动。
如图:
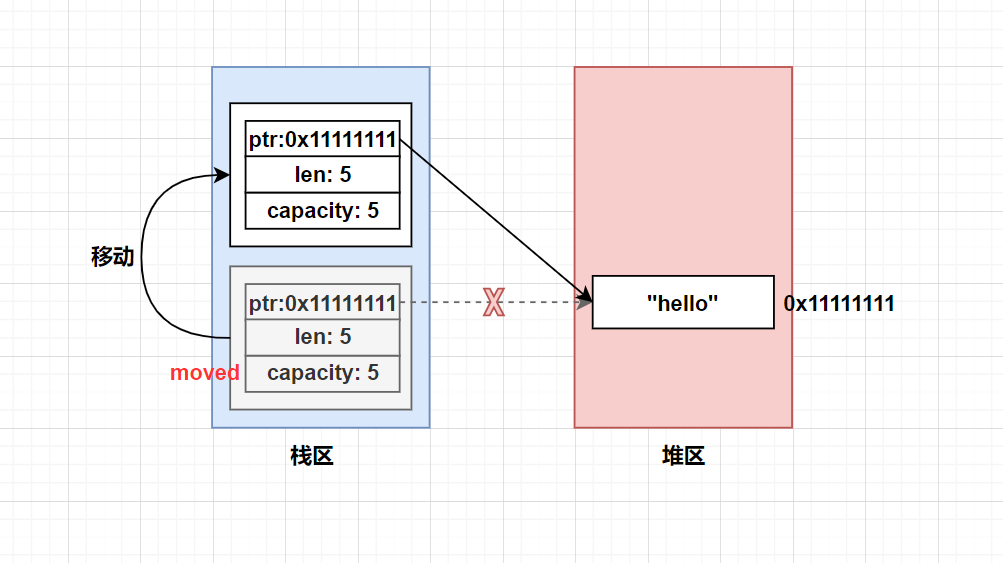
在let s2 = s1;的过程中,确实会发生一次栈区的浅拷贝,但是堆区的数据只能有一个拥有者,因此编译器会把s1标记为已移动moved,后续用户无法再使用s1这个变量。这样就保证了引用语义下,堆区的数据只被一个变量拥有。
事实上,移动其实就是一次 栈区浅拷贝 + 移动标记,不允许用户再使用原变量。
那如果我确实需要对String进行拷贝怎么办?String实现了Clone这个Trait,可以调用clone方法进行深拷贝。
let s1 = String::from("hello");
let s2 = s1.clone();
图示:
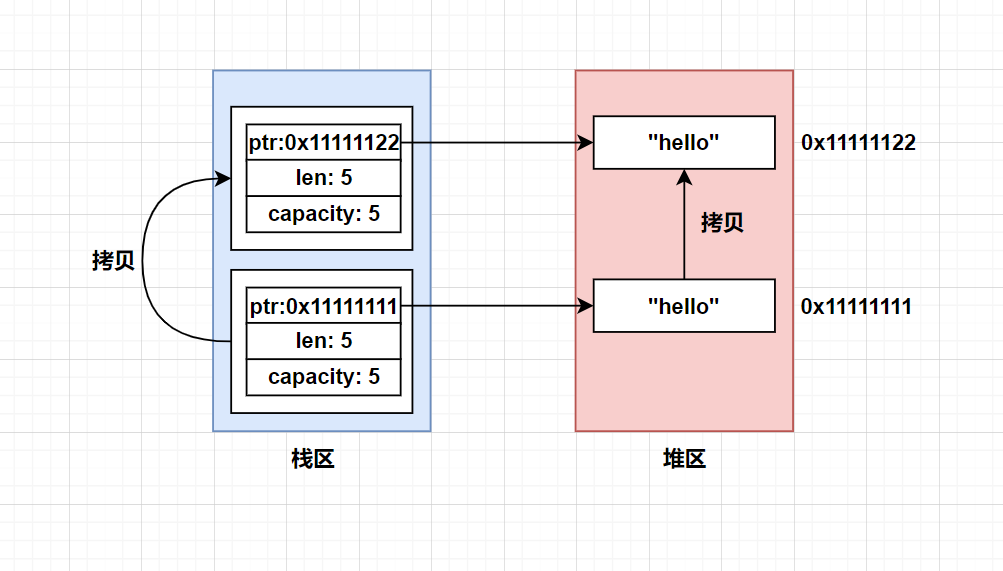
在调用clone方法后,会进行一次深拷贝,堆区和栈区的数据都会进行分别拷贝,并且会把栈区的指针进行修改,指向新的堆区内存。此时s1和s2就是两份完全独立的数据,可以同时使用s1和s2两个变量。这也不会违背所有权的规则,因为此时是两个变量指向两份不同的数据,没有出现第一个数据被多个变量拥有的情况。
现在已经了解了值语义和引用语义在Rust中的行为模式。那么问题来了,Rust怎么知道一个数据是值类型还是引用类型?
答案是,Rust无法区分。但是最后把它当成哪一种语义进行处理,这依赖于Copy这个Trait。
当一个类型实现了
Copy,默认当做值语义处理;反之默认当做引用语义处理
Rust已经对一系列基础类型实现了Copy,比如所有纯数值标量类型i32等数值、浮点型、布尔、字符,以及裸指针等等。
当一个元组所有类型都实现了Copy,元组也会自动实现Copy。而当一个结构体所有类型都实现了Copy,结构体也不会自动实现。
例如:
let t1 = (1, 3.14);
let t2 = t1;
println!("{}, {}", t1.0, t1.1);
println!("{}, {}", t2.0, t2.1);
以上代码是正确的。t1是一个元组,它的所有元素都是标量类型,所以元组也会自动实现Copy。最后可以同时使用t1和t2两个变量。
struct Val {
x: i32,
y: f64,
}
let v1 = Val { x: 1, y: 1.0 };
let v2 = v1;
println!("{}, {}", v1.x, v1.y); // Value used after beging moved
println!("{}, {}", v2.x, v2.y);
以上代码无法编译通过,类型Val结构体是一个值类型没错,但是Rust可区分不出它是不是值类型。Rust只知道它没有实现Copy,所以当做一个引用语义处理,let v2 = v1;时就已经被移动了,所以后续访问v1时直接报错。
Rust提供了属性,可以自动实现Copy:
#[derive(Copy, Clone)]
struct Val {
x: i32,
y: f64,
}
关于Copy和Clone在前一篇博客也已经讲解过了,当使用#[derive(Copy, Clone)]就会自动实现Copy和Clone特征,此时let v2 = v1;触发的就是值语义,直接进行拷贝。
表达式 与 上下文
以上内容主要讲的是所有权的移动能力。当一个变量持有资源的所有权,在进行值操作时,如果其实现了Copy则直接拷贝,如果没有则触发移动,此时所有权也会被转移到新的变量。
那么问题来了,什么是“值操作”,也就是说什么时候会触发这个"移动还是拷贝"的判定逻辑?
位置表达式 与 值表达式
如果你跟着我的这一套博客看下来,本系列博客第一节就深入讲解了Rust中“一切皆表达式”这个核心概念。
Rust语法由语句和表达式构成,而表达式可以进一步细分为位置表达式和值表达式两大情况。官方文档:Expressions - The Rust Reference。
- 当表达式表示一个实际的值,这就是一个值表达式。
- 当表达式可以表示一个内存位置,这就是一个位置表达式。
位置表达式包括:
- 指向局部变量或静态变量的路径
- 解引用(
*expr) - 数组索引(
expr[expr]) - 字段访问(
expr.f) - 括号包裹的位置表达式
例如:
let mut arr = [10, 20, 30];
let x = arr; // 变量本身是位置表达式
let y = arr[1]; // 数组索引是位置表达式
// 字段访问是位置表达式
struct Point { x: i32, y: i32 }
let mut p = Point { x: 1, y: 2 };
let z = p.x;
// 解引用是位置表达式
let mut v = 42;
let r = &mut v;
*r = 100;
在这些例子中,arr[1]、p.x、*r 都是典型的 位置表达式。
其实想要区分值表达式和位置表达式很简单,你看这个表达式能不能取地址:&arr[1]、&x都是允许的,因此它们是位置表达式。&100是不允许的,所以它是值表达式。
当一个表达式可以取地址就是位置表达式,反之就是值表达式。这其实来自于C++的经验,所谓值表达式和位置表达式,其实就是C++的左值和右值,在C++社区中,往往用一个表达式能不能取地址来判断它是左值还是右值。
位置表达式既能提供一个位置,也能提供该位置的值。
比如说arr[1],它既可以是数组arr第一个元素的位置,因此你可以&arr[1]拿到地址,它也可以是第一个元素的值,例如let y = arr[1];就是拿到第一个元素的值。
let mut arr = [1, 2, 3];
// 作为值使用
let x = arr[0]; // arr[0] 在这里表示“第0个元素的值”
// 作为位置使用
arr[0] = 42; // arr[0] 在这里表示“第0个元素的存储位置”
何时作为值使用,何时作为位置使用呢?这又是另一个概念:上下文 context。
位置上下文 与 值上下文
上下文分为值上下文和位置上下文。
- 值上下文
Value Context:语法环境要求你提供一个“值,包括:- 赋值语句右边:
let x = arr[0]; - 表达式求值:
foo(arr[0] + 1) - 模式按值绑定:
let y = p.x;
- 赋值语句右边:
在这些地方,编译器会把位置表达式当作“值”来处理:
- 位置上下文
Place Context:语法环境要求你提供一个“位置”,包括:- 赋值语句左边:
arr[0] = 42; - 借用:
let r = &arr[0]; - 可变借用:
let r = &mut arr[0]; - 模式绑定中的
ref或ref mut:let ref mut x = arr[0];
- 赋值语句左边:
在这些地方,编译器不会取出值,而是把表达式当作一个“可寻址的内存位置”来使用。
- 值表达式一般放在值上下文
- 位置表达式放在位置上下文则提供一个位置,放在值上下文则提供一个值
讲了这么一大堆,终于可以回到所有权了,何时会触发“拷贝还是移动”的判定呢?
当位置表达式出现在值上下文,就会触发“拷贝还是移动”的判定
比如说:
let s1 = String::from("hello");
let s2 = s1;
此处s2 = s1是一个值上下文,而s1作为一个变量,它可以做位置表达式,也就是可以取地址。位置表达式出现在值上下文,因此会触发机制,发现String没有实现Copy于是发生移动。这才是一个所有权规则下发生移动的完整逻辑链。
提问,以下代码合法吗?
let s1 = String::from("hello");
s1; // 一个表达式语句
println!("{}", s1); // error
答案是不合法,编译器会直接报错,因为s1失去了所有权。
有人就要问了,为什么?s1的所有权去哪里了?又被移动给了谁?
表达式的目的是为了求值,s1;这一行语句,内部是一个求值表达式,因此这是一个值上下文,而s1是一个位置表达式。也就是说这里把位置表达式放到了一个值上下文,会发生什么?
铺垫了这么久,你多少该悟出些啥了吧?这里进行判断,String没有实现Copy,所以移动,s1被移动走了。
在这个地方,s1;这行代码要做的是求出一个值,求完值后直接就把值丢掉了。相当于:
let tmp = s1;
drop(tmp);
用了一个tmp转移走s1的所有权,然后立马销毁。这个drop函数马上会讲到,它会销毁一个变量的所有资源,包括堆区和栈区。
RAII
当一个变量生命周期结束,它会把它拥有的所有数据进行销毁。这种把资源的生命周期与变量生命周期绑定在一起的机制,叫做RAII。
如果某个变量本身就是值语义,那么在函数调用结束后,数据会随着栈区自动销毁。但如果它是引用语义,就需要考虑将堆区的数据一起销毁,这需要通过Drop这个Trait实现。
Drop 是一个特殊的 Trait,用于在值生命周期结束时自动执行清理逻辑。它是 Rust 实现 RAII 模式的关键。
定义如下:
pub trait Drop {
fn drop(&mut self);
}
当一个值离开作用域时,Rust 会自动调用它的 drop 方法,释放资源或执行收尾工作,这个drop方法也叫做析构函数(源自C++的叫法)。
使用NewType模式创建两个新类型:
struct NewString(String);
impl Drop for NewString {
fn drop(&mut self) {
println!("Dropping string: {}", self.0);
}
}
struct NewBox<T: std::fmt::Display>(Box<T>);
impl<T: std::fmt::Display> Drop for NewBox<T> {
fn drop(&mut self) {
println!("Dropping box: {}", self.0);
}
}
分别给NewString和NewBox实现Drop,当Drop被调用是输出。
随后定义Heap类型:
struct Heap {
str: NewString,
ptr: NewBox<i32>,
}
impl Drop for Heap {
fn drop(&mut self) {
println!("Dropping heap:");
}
}
fn main() {
println!("=== main start ===");
{
let h = Heap{
str: NewString(String::from("hello")),
ptr: NewBox(Box::new(5)),
};
} // Drop
println!("=== main end ===");
}
Heap中两个成员分别是两个新类型,再给Heap实现Drop。
最后在main中定义一个Heap变量h,将其放在一个块作用域中。
输出结果如下:
=== main start ===
Dropping heap:
Dropping string: hello
Dropping box: 5
=== main end ===
在main函数中,当h离开自己的块作用域就会自动调用drop方法,输出Dropping heap:。
当调用完自己的drop方法后,结构体会依次调用所有成员的drop方法,因此再分别调用NewString和NewBox的drop方法。
而NewString的drop结束后,也会调用它内部String的drop,实现堆内存的回收,不过这已经由标准库实现好了。Box同理,会在NewBox析构结束后,自动调用Box析构。
关于析构函数的其它内容,会在后续深入讲解。此处只要知道,drop是由编译器自动调用的,只要变量离开生命周期,就会递归式的触发变量自己以及所有子类型析构函数,保证所有资源正常释放。
不允许给同一个类型实现Copy和Drop两个特征,否则编译失败。
如果某个类型实现了Copy,说明它是值类型,所有数据都放在了栈区。那么当栈帧销毁,会自动把这个类型的数据进行销毁,根本不需要Drop。反过来,如果某个类型实现了Drop,往往说明它有一些其它的资源需要管理,如果直接通过Copy按位拷贝,那么就可能导致多个变量指向一个资源的问题,这违背了所有权的基本要求。
由于一个数据只能被一个变量拥有,因此谁拥有这个数据,谁就负责在drop中回收这个数据。
例如:
fn main() {
let s1 = NewString(String::from("hello"));
println!("block start");
{
let s2 = s1;
}
println!("block end");
}
输出结果:
block start
Dropping string: hello
block end
起初s1拥有字符串的所有权,进入块作用域后,s2转移走了s1的所有权。当s2离开块作用域,生命周期结束,就会调用drop直接把字符串回收。因此先输出Dropping string: hello,后输出block end。
而对于s1,由于它失去了所有权,最后不会调用它的drop方法。
这也就是所有权的第一点操作:
持有所有权的变量,才有资格释放它指向的资源
借用
我们之前已经讲过借用了,包括不可变借用&和可变借用&mut,本篇博客中回顾一下它的规则,因为它的规则最终也是为所有权机制服务的。
fn print_string(s: String) {
println!("{}", s);
}
let str = String::from("hello");
print_string(str);
str.push_str(", world!");
这是一个很经典的所有权导致的错误代码。print_string中,s接收一个String类型参数,它是一个值上下文,传入的str是一个位置表达式,因此所有权从外部的str移动到内部的s。这导致外部str失去所有权,无法push_str了。
有没有一种办法,可以暂时让函数内部使用字符串,但是不占有字符串的所有权?有的,这个办法就是借用。
借用是一种经过封装的指针,对于一个位置表达式,通过&操作符即可获取对一个变量的借用。其中&是不可变借用、&mut是可变借用。
例如:
// 不可变借用
let s1 = String::from("hello");
let borrow = &s1;
println!("print by borrow: {}", borrow);
// 可变借用
let mut s2 = String::from("hello");
let borrow_mut = &mut s2;
borrow_mut.push_str(", world");
println!("print s2: {}", s2);
第一段代码中,通过 &s1创建了一个不可变借用,并通过println!直接输出了这个不可变借用。
第二段代码中,通过&mut s2创建了一个可变借用,并通过可变借用直接修改了字符串。最后输出的s2是已经修改后的"hello, world!"。
借用也属于所有权的模块,甚至可以说是所有权的重要组成部分。当一个变量拥有所有权,就可以对其持有的数据进行出借,并且借用遵循以下规则:
- 一个变量允许存在多个不可变借用,或一个可变借用
- 如果存在不可变借用,所有者暂时失去写权限,只能读取
- 如果存在可变借用,所有者暂时失去读写权限
- 只要存在任意借用,所有者暂时失去释放与移动权限
- 一个变量允许存在多个不可变借用,或一个可变借用
以下两段代码都是合法的:
let s = String::from("hello");
let b1 = &s;
let b2 = &s;
let b3 = &s;
println!("print by borrow: {}", b1);
println!("print by borrow: {}", b2);
println!("print by borrow: {}", b3);
let mut s = String::from("hello");
let b1 = &mut s;
b1.push_str(", world");
第一段代码是一个变量被多次不可变借用,此时多个不可变借用可以同时使用,依次进行println!操作。
第二段代码是一个变量进行了一次可变借用,并通过可变借用修改数据。
除了以上两种情况,其它借用场景都不合法。例如同时存在可变借用和不可变借用,或者存在多个可变借用。
- 如果存在不可变借用,所有者暂时失去写权限,只能读取
let s = String::from("hello");
let b1 = &s;
let b2 = &s;
// s.push_str(", world"); error
println!("print by borrow: {}", s);
println!("print by borrow: {}", b1);
println!("print by borrow: {}", b2);
以上代码中,s是字符串的所有者,当它进行两次不可变借用后,依然可以通过s读取字符串的内容,但是不允许进行s.push_str。也就是存在不可变借用会失去写权限,保留读权限。
- 如果存在可变借用,所有者暂时失去读写权限
let mut s = String::from("hello");
let b1 = &mut s;
// println!("print by s: {}", s); error
// s.push_str(", world"); error
println!("print by borrow: {}", b1);
以上代码,s进行了一次可变借用,期间s尝试读取和修改字符串都失败了。因为存在可变借用期间,所有者会失去读写权限。
- 只要存在任意借用,所有者暂时失去释放与移动权限
let s = String::from("hello");
let r = &s;
// let s2 = s; error
// drop(s); error
println!("{}", r);
以上代码,同样是字符串s进行了借用,在借用期间分别尝试移动所有权到s2,以及通过drop回收这个字符串的资源。编译器报错了,因为r还在借用,如果移动所有权或者释放,那么r就可能变成垂悬引用,这是Rust不允许的。
以上四条规则实现了Rust的一大重要原则:写独占,读共享。不允许你通过多个借用进行写入,否则就可能导致多个变量同时写入的场景。而如果保证没有任何人会修改数据,那么这一份数据可以同时被多个借用同时读取。
可以打个比方,一块资源就是学校的公告栏。这个公告栏只允许一个人进行写公告,当没有人写公告的时候,允许一群人读公告。
假如允许一个人写公告的同时,其他人读取公告,就有可能读取到错误的信息,因此读写要互斥。而假如允许多个人同时写公告,那么就可能导致内容相互覆盖,排版混乱,因此写写要互斥。这也是典型的多线程环境下的读写锁思想。
NLL
Rust 2018引入了智能的借用检查Non-Lexical Lifetimes (NLL) 优化,能够分析借用的实际使用范围:
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
println!("{} and {}", r1, r2); // r1 和 r2 在这里不再被使用,生命周期结束
let r3 = &mut s; // 现在可以创建可变引用
println!("{}", r3); // r3 生命周期结束
编译器能够分析出r1和r2在println!之后不再使用,所以允许后续创建可变引用。这比简单的词法作用域更智能,提高了代码的灵活性。
重新借用
基于NLL,Rust可以更灵活地判断借用的生命周期,于是衍生出了重新借用的语法。
对一个已经存在的借用,可以再次进行借用
- 原借用为可变借用,此时原借用暂时失效,直到新借用生命周期结束
- 原借用为不可变借用,原借用仍然生效
例如:
fn main() {
let mut s = String::from("hello");
let b1 = &mut s; // b1 start
let b2 = &*b1; // b2 start
print!("{}", b2); // b2 end
b1.push_str(", world!"); // b1 end
}
首先b1对s进行了一次可变借用,随后let b2 = &*b1;就是重新借用,b2基于b1进行重新借用,在b2生命周期期间,b1无法使用,当b2结束才把所有权归还b1。
分析一下这个语法&*b1,b1本身是一个借用,*b1拿到的是b1指向的值,这是一个位置表达式。随后对其进行借用&*b1,相当于对b1指向的值进行借用。
有人问,这个重新借用难道不是破坏了之前的借用规则吗?这里同时存在了可变借用和不可变借用,实际上没有。
因为NLL的存在,Rust可以非常智能地分析借用的生命周期,在任意时刻,都是遵循之前的借用规则的。
当一个可变借用被重新借用后,在重新借用存在期间,原借用不能使用,分析借用规则时暂时当做原借用不存在。
一起分析以下代码:
fn main() {
let mut s = String::from("hello");
let b1 = &mut s; // 可变借用: b1
let b2 = &*b1; // 不可变借用: b2
let b3 = &*b1; // 不可变借用: b2 b3
print!("{}", b3); // 不可变借用: b2 b3
print!("{}", b2); // 不可变借用: b2
b1.push_str(", world!"); // 可变借用: b1
}
一开始,只有b1这个可变借用,并且没有其他借用,合法。
创建b2后,此时b1暂时不能使用了,当做b1不存在,只有b2不可变借用独占,合法。
创建b3后,此时相当于有两个不可变借用b2和b3,允许存在多个不可变借用,合法。
当b2和b3依次离开生命周期,此时b1所有权恢复,只有b1可变借用独占,合法。
可以看出来,将代码拆成一行一行看,把已经被重新借用的原借用暂时忽略,任何时刻都是符合借用规则的。
再看一个重新借用的例子:
fn main() {
let mut s = String::from("hello");
let b1 = &mut s; // 可变借用: b1
let b2 = &mut *b1; // 可变借用: b2
print!("{}", b2); // 可变借用: b2
b1.push_str(", world!"); // 可变借用: b1
}
和刚才一样分析:
一开始,只有b1这个可变借用,并且没有其他借用,合法。
创建b2后,此时b1暂时不能使用了,当做b1不存在,只有b2可变借用独占,合法。
当b2离开生命周期,此时b1所有权恢复,只有b1可变借用独占,合法。
可以看出,重新借用是对借用规则的锦上添花,而不是对借用规则的破坏性改写。基于重新借用,你可以将一个可变借用的权限临时缩小为不可变借用,在传参时也可以创建一个生命周期更短的临时引用。
复合类型所有权
之前提到的所有权都是针对单一的元素,而在复合类型中,所有权会分为两种情况。
聚合所有权
对于数组这种类型,它的所有元素共享所有权,对单一元素的所有权操作会影响到整体。
let mut arr = [String::from("a"), String::from("b")];
let borrow_one = &arr[0];
arr[1] = String::from("c"); // error
println!("print by borrow: {}", borrow_one);
以上代码中,先对arr[0]进行了一次借用,随后修改arr[1],但是第三行代码会进行报错。
因为Rust的编译器起始无法确定每次操作是不同位置的元素。因此当你借用一个元素,就相当于整个数组都被借用出去了,各个元素之间是相互影响的,它们共享所有权机制。
字段所有权
对于结构体、枚举、元组这些类型,它们的各个字段所有权独立。
struct Person {
name: String,
age: u8,
email: String,
}
let mut p = Person {
name: String::from("zhangsan"),
age: 18,
email: String::from("123456@123.com"),
};
let s = p.name; // 移动
let b = &mut p.email; // 借用
println!("age: {}", p.age);
println!("email: {}", b);
以上代码中,Person有三个字段,并且三个字段的所有权分别独立。对name进行移动后,可以在对email借用,与此同时还能对age进行输出。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)