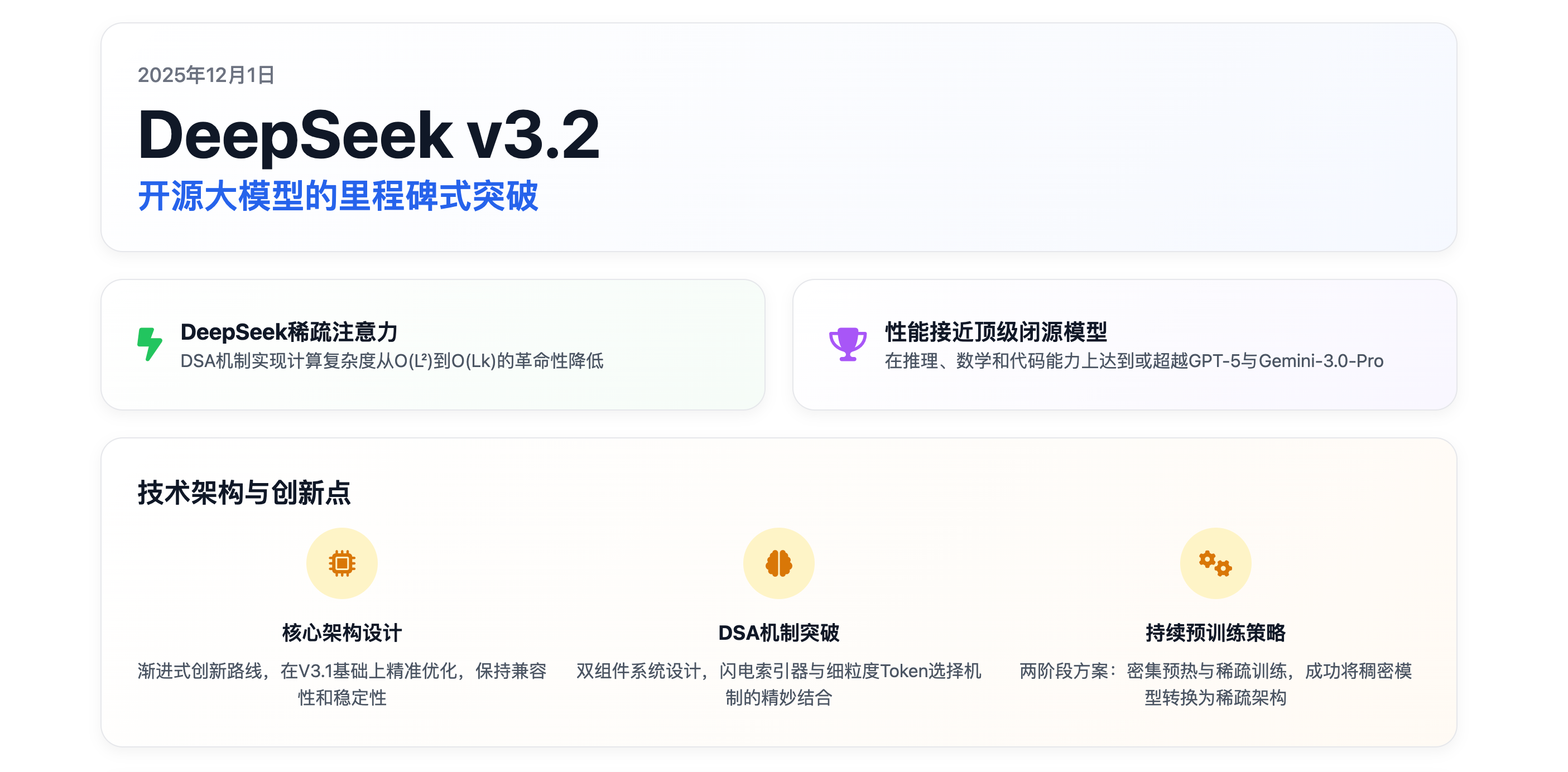
DeepSeek v3.2
DeepSeek公司于2025年12月发布新一代开源大模型DeepSeek v3.2,在推理、数学和代码能力上达到甚至超越顶级闭源模型。其核心创新是DeepSeek稀疏注意力(DSA)机制,通过闪电索引器和细粒度Token选择实现计算复杂度从O(L²)降至O(Lk),在128K长文本处理中计算量减少84%。模型采用两阶段持续训练策略,保持性能的同时完成架构转换,并通过大幅增加后训练算力投入(超预训
2025 年 12 月 1 日,DeepSeek 公司正式发布了其最新一代大语言模型 DeepSeek v3.2,这一发布标志着开源大模型在技术架构和性能表现上实现了重大突破。作为 DeepSeek 系列的第三代产品,v3.2 版本在保持开源优势的同时,在推理能力、数学能力和代码能力等核心维度上已经接近甚至达到了闭源顶级模型的水平,特别是在某些领域实现了对 GPT-5 和 Gemini-3.0-Pro 的超越(10)。
当前,大语言模型的发展正处于从 “参数竞赛” 向 “能力竞赛” 转型的关键时期。在这一背景下,DeepSeek v3.2 的发布具有特殊意义:它不仅展示了开源模型在技术创新上的可能性,更重要的是通过DeepSeek 稀疏注意力(DSA)机制这一原创性架构创新,在保持性能的同时显著提升了长文本处理效率(3)。同时,通过大幅增加后训练算力投入(超过预训练成本的 10%),DeepSeek v3.2 在多项关键基准测试中取得了突破性进展。
本文将从技术架构与创新点、性能表现两个核心维度,对 DeepSeek v3.2 进行全面深入的分析。通过对比分析官方技术报告、学术论文以及第三方评测数据,揭示这款模型在推动大语言模型技术发展中的重要价值和深远影响。
一、技术架构与创新点
1.1 核心技术架构设计
DeepSeek v3.2 的技术架构设计体现了 **“渐进式创新”** 的技术路线,其最大特点是在 DeepSeek-V3.1-Terminus 基础上进行了精准的架构优化,而非颠覆性的重新设计。这种设计哲学确保了模型在引入新架构的同时,能够保持与前代模型的兼容性和稳定性。
从整体架构来看,DeepSeek v3.2 采用了与 DeepSeek-V3.2-Exp 完全相同的架构,相较于 DeepSeek-V3.1-Terminus,唯一的架构修改是通过持续训练引入了 DeepSeek 稀疏注意力(DSA)机制。这一设计决策具有重要的工程意义:它证明了通过精确的架构改进而非大规模的重新训练,同样可以实现模型性能的显著提升。
DSA 机制的核心创新在于其双组件系统设计。该机制主要由两个组件构成:闪电索引器(Lightning Indexer)和细粒度 Token 选择机制(Fine-grained Token Selection Mechanism)。闪电索引器负责计算查询 Token 与前序 Token 之间的索引得分,从而确定哪些 Token 将被查询 Token 选中;细粒度 Token 选择机制则基于索引得分,仅检索对应前 k 个索引得分的键值条目。这种设计的精妙之处在于实现了 **“先筛选,后计算”** 的稀疏化策略,将稠密的注意力计算问题转化为稀疏计算问题。
在具体实现上,DeepSeek v3.2 基于 ** 多头潜在注意力(MLA)** 的多查询注意力(MQA)模式来实例化 DSA。这种实现方式的选择并非偶然,而是出于对持续训练兼容性的考虑。通过基于 MLA 架构实现 DSA,DeepSeek 团队能够从 DeepSeek-V3.1-Terminus 的检查点进行平滑的持续训练,避免了重新训练整个模型的巨大成本。

1.2 DeepSeek 稀疏注意力(DSA)机制的技术突破
DSA 机制的技术突破主要体现在三个层面:计算效率、性能保持和工程实现。
在计算效率方面,DSA 实现了从 O (L²) 到 O (Lk) 的复杂度降低,其中 k(远小于 L)是被选中 Token 的数量(3)。这一改进的实际意义在于,当处理 128K 上下文长度的长文本时,传统的稠密注意力机制需要进行约 1600 万次计算(128K×128K),而 DSA 仅需要约 260 万次计算(128K×2048),计算量减少了约 84%。这种效率提升不仅降低了推理成本,更重要的是使得处理超长文本成为可能。
在性能保持方面,DeepSeek 团队通过精心设计的训练策略,确保了 DSA 机制在大幅降低计算复杂度的同时,不会对模型性能造成损失。根据官方测试,DeepSeek-V3.2-Exp 在任何特定场景中都没有显著差于 V3.1-Terminus,这验证了 DSA 稀疏注意力机制的有效性。更令人惊讶的是,在某些长上下文任务上,如 AA-LCR(长上下文推理基准),V3.2-Exp 在推理模式下比 V3.1-Terminus 高出 4 分;在 Fictionch 测试中,V3.2-Exp 在多项指标上全面超过 V3.1-Terminus。
在工程实现方面,闪电索引器的设计体现了极致的硬件优化思维。该组件具有以下特点:使用极少量的索引器头(每个 Token 仅 128 维),能够以 FP8 精度运行,采用 ReLU 激活函数以获得最佳吞吐量。这些设计选择使得闪电索引器本身的计算成本极低,在 128K 上下文长度的实际场景中,索引器的计算成本相较被替代的稠密注意力可忽略不计。
1.3 持续预训练策略的创新
DeepSeek v3.2 在训练策略上的创新主要体现在其两阶段持续预训练方案的设计上。这一方案不仅确保了模型能够从 V3.1 平滑过渡到 V3.2,更重要的是为稀疏注意力机制的成功应用奠定了基础。
第一阶段是密集预热阶段,这是一个短暂但至关重要的初始化阶段。在这个阶段,模型保持稠密注意力机制,同时冻结除闪电索引器外的所有模型参数。训练目标是通过 KL 散度损失函数,让索引器学习模仿原始成熟稠密模型的注意力模式,即将稠密模型中关于 “哪些 Token 重要” 的知识蒸馏到轻量级索引器中。这一阶段仅持续 1000 个训练步,消耗 21 亿个 Token,体现了其作为快速高效初始化步骤的特点。
第二阶段是稀疏训练阶段,这是整个架构转换的核心。在这个阶段,细粒度的 Top-k Token 选择机制被激活,所有模型参数(包括主模型和索引器)同时解冻并进行优化。值得注意的是,DeepSeek 团队采用了分离的计算图进行优化:索引器的训练信号继续且仅来自 KL 散度损失,确保其选择与主模型在已选 Token 集上的注意力分布保持一致;主模型则仅基于标准的语言建模损失进行优化。这一阶段运行了 15,000 个训练步,总计消耗 9437 亿个 Token,反映了整个模型适应新稀疏范式所需的大量工作。
这种训练策略的创新之处在于,它成功地将一个成熟的稠密模型转换为稀疏架构,同时保持了模型的性能。这种方法为未来的模型架构创新提供了重要的方法论指导:通过精心设计的持续训练方案,可以在不损失性能的前提下实现架构的重大改进。
1.4 与主流模型的技术对比分析
在技术架构层面,DeepSeek v3.2 与 GPT-5、Gemini-3.0-Pro、Kimi-K2-Thinking 等主流模型相比,呈现出明显的差异化特征。
与 GPT-5 相比,DeepSeek v3.2 的主要优势在于架构效率和成本效益。根据官方数据,DeepSeek v3.2 在推理能力上已经达到了 GPT-5 的水平,但通过 DSA 机制实现了计算复杂度的大幅降低(41)。更重要的是,DeepSeek v3.2 的 API 价格大幅下调超过 50%,在高缓存场景下,输入成本可低至 0.2 元 / 百万 token,输出成本降至 0.16 元 / 百万 token,使得高缓存场景成本降幅最高可达 70%-80%。
与 Gemini-3.0-Pro 相比,DeepSeek v3.2 在某些特定领域已经实现了超越。特别是在数学和编程竞赛方面,DeepSeek v3.2-Speciale 在 IMO 2025、CMO 2025、ICPC World Finals 2025 和 IOI 2025 四项国际顶级竞赛中均获得金牌,其中 ICPC 与 IOI 成绩分别达到了人类选手第二名与第十名的水平。这一成就表明,在规则清晰、逻辑结构强的领域,DeepSeek 的技术架构设计具有独特优势。
与 Kimi-K2-Thinking 相比,DeepSeek v3.2 的显著优势在于输出长度的优化。根据官方测试,相比 Kimi-K2-Thinking,V3.2 的输出长度大幅降低,显著减少了计算开销与用户等待时间(41)。这种优势不仅体现在成本降低上,更重要的是提升了用户体验和系统的并发处理能力。
在技术架构的创新程度上,DSA 机制代表了稀疏注意力技术的重要突破。与传统的稀疏注意力方法(如滑动窗口或跨度注意力)相比,DSA 的优势在于其动态自适应特性。它根据具体的输入内容决定哪些 Token 是重要的,这与那些依赖固定模式的刚性稀疏方法有本质区别。这种动态性使得 DSA 能够在不同的任务和输入上都保持最优的性能表现。
1.5 后训练策略的革命性变化
DeepSeek v3.2 在技术架构创新之外,另一个重要的突破体现在其后训练策略的革命性变化上。最显著的特征是后训练算力投入的大幅增加,RL 训练预算已经超过预训练成本的 10%,这在开源模型中是极为罕见的。
这种资源配置的变化带来了显著的性能提升。根据官方数据,在过去几个月中,DeepSeek 团队观察到性能改进与 RL 训练预算的增加呈现出持续的正相关关系。具体而言,通过增加计算预算,DeepSeek v3.2 在推理基准测试上达到了与 GPT-5 相当的性能水平。
在算法层面,DeepSeek v3.2 继续采用 ** 组相对策略优化(GRPO)** 作为 RL 训练算法,但在此基础上引入了多项稳定性改进。这些改进包括:无偏 KL 估计,修正了传统 K3 估计的偏差,避免在 “当前策略远小于参考策略” 时产生极端梯度;离策略序列掩码,对那些优势为负且当前策略与采样策略 KL 偏差过大的序列不进行反向传播;保持路由机制,确保推理时使用的专家路由在训练时被强制复用;Top-p/top-k 采样掩码的保留,保证重要性采样的理论前提不被破坏。
这些技术改进的综合效果是,DeepSeek v3.2 能够在统一的 RL 阶段同时进行推理强化、Agent 能力和对齐训练,而不会出现某一能力的极端退化。对用户而言,这意味着模型表现得更加 “均衡”,而不是在某些基准测试上表现突出但在其他方面存在明显短板。

二、性能表现分析
2.1 推理能力的全面评估
DeepSeek v3.2 在推理能力方面的表现标志着开源模型实现了历史性突破。根据官方发布的数据,在公开的推理类基准测试中,DeepSeek v3.2 达到了 GPT-5 的水平,仅略低于 Gemini-3.0-Pro(41)。这一成就的取得并非偶然,而是 DeepSeek 团队在技术架构、训练策略和数据处理等多个维度进行系统性创新的结果。
在具体的基准测试表现上,DeepSeek v3.2 在多项权威测试中展现出了卓越的推理能力。在AIME 2025(美国数学邀请赛)测试中,V3.2 达到了 93.1% 的通过率,接近 GPT-5 的 94.6% 和 Gemini-3.0-Pro 的 95.0%(21)。在HMMT 2025(哈佛 - 麻省理工数学锦标赛)测试中,V3.2 得分 92.5%,与顶级闭源模型的差距进一步缩小(21)。在IMOAnch(国际数学奥林匹克锚题)测试中,V3.2 的 Pass@1 达到 78.3%,而 V3.2-Speciale 更是达到了 84.5%,超过了 GPT-5-High 的 76.0%。
这些成绩的背后,反映的是 DeepSeek v3.2 在复杂推理任务上的技术优势。与传统的基于记忆和模式匹配的推理方式不同,DeepSeek v3.2 展现出了真正的逻辑推理能力。例如,在解决 “4 升水壶问题” 等经典逻辑谜题时,模型能够自主回溯错误并重新推导解题步骤,打破了大模型逻辑链条断裂的瓶颈(36)。
在长文本推理能力方面,DeepSeek v3.2 通过 DSA 机制实现了效率与性能的双重提升。根据官方测试,在 AA-LCR(长上下文推理基准)上,V3.2-Exp 在推理模式下比 V3.1-Terminus 高出 4 分;在 Fictionch 测试中,V3.2-Exp 在多项指标上全面超过 V3.1-Terminus。这些结果表明,DSA 机制不仅提升了效率,在某些情况下还能带来性能的提升。
从推理能力的维度分析,DeepSeek v3.2 在以下几个方面表现突出:
逻辑推理能力:模型展现出了强大的演绎推理和归纳推理能力,能够处理复杂的逻辑关系和推理链条。在 GPQA(研究生级别谷歌证明问答)测试中,DeepSeek v3.2 的 GPQA-Diamond Pass@1 达到 59.1%,超越了 Qwen2.5 72B 的 49.0% 和 LLaMA3.1 405B 的 51.1%(64)。
常识推理能力:在 HellaSwag 测试中,DeepSeek v3 在 10-shot 场景下达到 95.4 分,展现出了优秀的常识理解和推理能力(19)。
多跳推理能力:模型能够进行多步骤、多层次的推理,在处理需要多跳推理的复杂问题时表现出色。例如,在处理跨学科问题时,如物理运动模拟与数学公式推导的结合,模型能够生成包含可执行代码与理论解释的综合解决方案(38)。
然而,DeepSeek v3.2 在推理能力方面也存在一些局限性。根据官方技术报告,由于总训练 FLOPs 相对较少,模型的世界知识广度仍落后于领先的专有模型。此外,在某些需要大量背景知识的推理任务上,模型可能会因为知识覆盖的不足而影响表现。
2.2 数学能力的突破性进展
DeepSeek v3.2 在数学能力方面实现了开源模型的历史性突破,特别是其长思考版本 V3.2-Speciale 在国际顶级数学竞赛中取得的成绩,标志着 AI 在数学领域达到了新的高度。
国际竞赛的金牌级表现是 DeepSeek v3.2 数学能力最直观的体现。V3.2-Speciale 模型成功斩获了四项国际顶级数学竞赛的金牌:IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)、ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛)和 IOI 2025(国际信息学奥林匹克)(40)。其中,在 ICPC 与 IOI 竞赛中,模型的成绩分别达到了人类选手第二名与第十名的水平。这些成就的取得,不仅证明了模型在数学问题求解方面的卓越能力,更重要的是展示了 AI 在需要严格逻辑推理和创造性思维的数学领域的巨大潜力。
在标准化数学测试方面,DeepSeek v3.2 同样表现出色。在 GSM8K 数学数据集上,V3.2 的准确率较前代提升了 11 个百分点。在 MATH 基准测试中,DeepSeek v3 达到了 89.3% 的准确率(62)。在更具挑战性的 MATH 竞赛级基准上,DeepSeekMath-7B 的成绩达到 51.7%,接近 Gemini-Ultra 和 GPT-4 的性能水平。
数学推理机制的技术创新是 DeepSeek v3.2 数学能力提升的核心。V3.2-Speciale 版本融合了 DeepSeek-Math-V2 的定理证明模块,在 IMO 竞赛题测试中展现出了阶梯式推理能力。当模型识别到数学符号时,会自动触发高精度计算模式,将浮点运算精度提升至原来的 4 倍。这种 “思维聚焦” 特性使得代数拓扑类问题的解决率从 38% 跃升至 67%,而常规问答的响应速度仍保持毫秒级。
在复杂数学问题求解方面,DeepSeek v3.2 展现出了真正的数学思维能力。模型不仅能够解决常规的算术和代数问题,还能够处理需要深度推理的数学证明问题。例如,在 MiniF2F 测试数据集上,DeepSeek-Prover-V2-671B 模型的通过率高达 88.9%,刷新了神经定理证明的历史新高。
从数学能力的维度分析,DeepSeek v3.2 在以下几个方面表现突出:
算术运算能力:模型具备高精度的算术运算能力,能够处理大数字计算、分数运算、科学计数等复杂算术问题。
代数求解能力:在代数方程求解、函数分析、不等式证明等方面表现出色,能够处理多元方程组、高次方程等复杂代数问题。
几何证明能力:具备空间想象和几何推理能力,能够进行几何定理证明和几何问题求解。
概率统计能力:在概率计算、统计分析、随机过程等方面表现良好,能够处理复杂的概率统计问题。
数学建模能力:能够将实际问题抽象为数学模型,并通过数学方法求解。例如,在物理运动模拟与数学公式推导结合的问题中,模型能够生成包含可执行代码与理论解释的综合解决方案(38)。
2.3 代码能力的全面提升
DeepSeek v3.2 在代码能力方面实现了全方位的提升,不仅在传统的代码生成任务上表现出色,更重要的是在实际的软件开发和编程竞赛场景中展现出了专业级的能力。
在代码生成质量方面,DeepSeek v3.2 取得了显著突破。根据官方数据,模型的首次编译通过率达到 82%,在 HumanEval 基准测试中 Python 代码一次通过率达到 72.3%-91.8%(不同版本略有差异)(60)。这些指标表明,模型生成的代码不仅在语法上正确,更重要的是在逻辑上完整且可执行。
在编程竞赛表现方面,DeepSeek v3.2-Speciale 的成绩令人瞩目。在 Codeforces 平台上,模型的Elo 评分达到 2701 分,已经接近 Gemini-3.0-Pro 的 2708 分,属于国际大师级水平(30)。这一成绩意味着模型在算法设计、代码实现和问题分析等方面已经达到了人类顶级程序员的水平。
在实际软件开发能力方面,DeepSeek v3.2 在多个基准测试中展现出了专业级的表现:
在SWE-bench Verified(软件工程师基准测试)中,V3.2 的解决率达到 73.1%,这一成绩已经接近 GPT-5-High 的 76.2% 和 Gemini-3.0-Pro 的 74.9%。SWE-bench Verified 是一个专门测试模型在真实软件开发场景中能力的基准,包括代码审查、代码修复、功能实现等多个维度。
在Terminal Bench 2.0测试中,V3.2 达到了 46.4% 的准确率(使用 Claude Code 框架),这一成绩在开源模型中处于领先地位。Terminal Bench 2.0 主要测试模型在终端环境中的操作能力,包括文件操作、命令执行、脚本编写等。
在LiveCodeBench测试中,V3.2 的得分达到 88.7 分,展现出了优秀的实时编码能力(30)。
从代码能力的维度分析,DeepSeek v3.2 在以下几个方面表现突出:
代码生成能力:模型能够根据自然语言描述生成高质量的代码,支持 Python、Java、C++、JavaScript 等多种编程语言(47)。生成的代码具有良好的可读性和可维护性,变量命名规范,逻辑清晰。
代码理解能力:能够理解和解释现有代码的功能、逻辑和实现原理。用户可以通过 DeepSeek 解释不理解的代码片段,模型能够提供详细的代码注释和功能说明(47)。
代码优化能力:具备代码性能分析和优化能力,能够识别代码中的性能瓶颈并提供优化建议。
算法设计能力:在算法设计和数据结构应用方面表现出色,能够针对具体问题设计高效的算法解决方案。
调试纠错能力:能够分析代码中的错误并提供修复建议,在代码调试方面表现出了专业级的能力。
在代码生成效率方面,DeepSeek v3.2 也实现了显著提升。根据测试数据,模型的代码生成响应速度比传统方法快 3 倍左右,平均响应时间较 OpenAI 同类模型缩短 23%。这种效率提升不仅体现在速度上,更重要的是在长序列代码生成中,模型展现出了强大的上下文关联能力和变量命名一致性。
2.4 智能体能力的创新突破
DeepSeek v3.2 在智能体(Agent)能力方面实现了重要突破,成为首个将思考融入工具使用的模型,同时支持思考模式与非思考模式的工具调用。这一创新不仅提升了模型在复杂任务处理上的能力,更重要的是为 AI 智能体的实际应用开辟了新的可能性。
为了实现这一突破,DeepSeek 团队开发了一种大规模 Agent 训练数据合成方法,构造了1800 多个环境和 85000 多条复杂指令的强化学习任务。这些任务的设计遵循 “难解答,易验证” 的原则,例如复杂的行程规划问题:解空间巨大但验证函数(如 “预算是否符合”、“多日不重复城市” 等)可以用 Python 高效实现。
在工具调用能力方面,DeepSeek v3.2 在多个基准测试中达到了当前开源模型的最高水平:
在τ²-bench测试中,V3.2 分别在航空公司(Airline)、零售(Retail)和电信(Telecom)三个类别中获得了 63.8%、81.1% 和 96.2% 的通过率。
在MCP 基准测试中,V3.2 的成功率达到 45.9%,虽然低于 GPT-5-High 的 50.7%,但已经大幅超越了其他开源模型。
在BrowseComp测试中,通过上下文管理技术,V3.2 的通过率从 51.4% 提升至 67.6%,已经逼近 GPT-5-High 的 54.9%。
这些成绩的取得,得益于 DeepSeek v3.2 在思考与工具调用融合方面的创新设计。与传统的 “看到问题马上用工具” 的模式不同,V3.2 采用了 “先分析、再规划、再调用工具、再验证、再修正” 的思考 - 行动 - 反思闭环模式。这种模式更接近人类的问题解决方式,为复杂任务(如搜索、写代码、修 Bug、规划项目)带来了指数级的能力提升。
在实际应用表现方面,DeepSeek v3.2 在多个真实场景中展现出了强大的智能体能力:
在代码智能体任务中,V3.2 在 SWE-Verified 中获得 73.1% 的解决率,在 Terminal Bench 2.0 中达到 46.4% 的准确率,显著超越了现有开源模型。
在搜索智能体评估中,通过使用标准商业搜索 API,V3.2 展现出了优秀的信息检索和结果分析能力。虽然由于 128K 上下文长度限制,约 20%+ 的测试用例需要特殊处理,但通过上下文管理方法,模型仍取得了良好的成绩。
在多模态智能体能力方面,DeepSeek 还展现出了将流程图等视觉元素自动转化为代码的能力,准确率较单模态模型提升 37%。
2.5 综合性能评估与对比分析
通过对 DeepSeek v3.2 在推理、数学、代码和智能体等多个维度的性能表现进行综合分析,可以得出以下关键结论:
整体性能水平:DeepSeek v3.2 已经将开源模型的能力提升到了与闭源顶级模型相当的水平。在推理能力上达到了 GPT-5 的水平,仅略低于 Gemini-3.0-Pro;在数学和编程竞赛方面,V3.2-Speciale 甚至实现了对闭源模型的超越(10)。
优势领域分析:
-
数学推理:在 IMO、CMO 等国际顶级数学竞赛中获得金牌,展现出了世界级的数学能力。
-
编程竞赛:在 Codeforces 上达到 2701 分,接近人类顶级选手水平。
-
长文本处理:通过 DSA 机制实现了长文本处理效率的大幅提升,同时保持了性能。
-
智能体能力:在工具调用、多模态处理等方面达到了开源模型的最高水平。
相对劣势分析:
-
世界知识广度:由于总训练 FLOPs 相对较少,模型的世界知识覆盖仍落后于顶级闭源模型。
-
Token 效率:在某些任务上,模型需要更多的 Token 才能达到与 Gemini-3.0-Pro 相当的输出质量,这直接影响了推理成本和响应时间。
-
极复杂任务处理:在处理需要极深度推理的复杂任务时,与 Gemini-3.0-Pro 等前沿模型仍有差距。
成本效益优势:DeepSeek v3.2 的最大优势之一是其出色的成本效益。通过 DSA 机制和优化的训练策略,模型在保持高性能的同时实现了推理成本的大幅降低。API 价格下调超过 50%,在高缓存场景下成本降幅可达 70%-80%。
在与其他主流模型的对比中,DeepSeek v3.2 展现出了明显的差异化特征:
与GPT-5相比,DeepSeek v3.2 在推理能力上基本持平,但在数学竞赛和编程竞赛方面表现更优,同时具有显著的成本优势。
与Gemini-3.0-Pro相比,DeepSeek v3.2 在某些特定领域(如数学竞赛、编程竞赛)已经实现超越,但在整体的知识广度和某些复杂任务处理上仍有差距。
与Kimi-K2-Thinking相比,DeepSeek v3.2 在输出长度控制、推理效率和综合能力方面具有明显优势。
与开源模型相比,DeepSeek v3.2 已经成为开源模型的新标杆,在几乎所有关键性能指标上都大幅超越了其他开源模型。
三、总结与展望
3.1 技术创新的深远影响
DeepSeek v3.2 的发布标志着开源大语言模型技术发展的一个重要里程碑。通过DeepSeek 稀疏注意力(DSA)机制这一原创性架构创新,DeepSeek 团队成功地在保持模型性能的同时,将注意力计算复杂度从 O (L²) 降低至 O (Lk),实现了长文本处理效率的革命性提升(3)。这一技术突破不仅为 DeepSeek 自身带来了竞争优势,更为整个大语言模型领域提供了新的技术思路和发展方向。
DSA 机制的成功证明了 **“精准优化优于盲目堆砌”** 的技术路线的可行性。与通过增加参数规模来提升性能的传统做法不同,DeepSeek 选择在计算资源分配这个微观层面进行创新,通过动态自适应的稀疏化策略,让每个 Token 都能获得恰到好处的 “思考强度”。这种设计哲学可能会重新定义下一代 AI 的基础架构标准。
在训练策略创新方面,DeepSeek v3.2 通过将后训练算力投入提升至预训练成本的 10% 以上,实现了模型能力的跨越式提升。这一做法打破了传统的 “预训练为主、后训练为辅” 的资源分配模式,证明了高质量的后训练对于释放模型潜力的重要性。同时,通过 GRPO 算法的改进和多任务联合训练策略,模型在保持能力均衡的同时避免了灾难性遗忘问题。
3.2 性能突破的历史意义
DeepSeek v3.2 在性能表现上的突破具有重要的历史意义,它标志着开源模型第一次真正意义上逼近了闭源顶级模型的水平(10)。在推理能力方面达到 GPT-5 水平,在数学和编程竞赛中超越部分闭源模型,这些成就的取得不仅提升了开源模型的技术地位,更为 AI 技术的民主化发展奠定了基础。
特别值得关注的是 DeepSeek v3.2-Speciale 在国际顶级竞赛中的表现。在 IMO 2025、CMO 2025、ICPC World Finals 2025 和 IOI 2025 四项竞赛中均获得金牌,其中 ICPC 和 IOI 成绩分别达到人类选手第二名和第十名的水平。这些成绩表明,在规则清晰、逻辑结构强的领域,基于深度学习的 AI 系统已经具备了超越人类专家的能力。
在实际应用价值方面,DeepSeek v3.2 的性能提升直接转化为了生产力的提升。在代码生成方面,首次编译通过率达到 82%,代码生成速度提升 3 倍;在智能体任务中,能够连续自主工作超过 30 小时,展现出了卓越的稳定性与执行力。这些能力的提升为软件开发、科学研究、教育等多个领域带来了新的可能性。
3.3 未来发展的机遇与挑战
展望未来,DeepSeek v3.2 的成功为 AI 技术发展带来了新的机遇,同时也面临着一些挑战。
从机遇的角度来看:
技术路线的多元化:DeepSeek v3.2 的成功证明了除了 “大参数 + 大算力” 之外,通过架构创新和训练策略优化同样可以实现性能突破。这为资源有限的研究机构和企业提供了新的发展路径。
成本效益的优化:通过 DSA 机制实现的效率提升和成本降低,使得高性能 AI 模型的应用门槛大幅降低。这将促进 AI 技术在更多领域的普及应用,特别是在对成本敏感的中小企业和个人用户群体中。
开源生态的发展:作为开源模型,DeepSeek v3.2 为全球开发者提供了一个高性能、低成本的技术平台。通过开源社区的力量,模型的性能和应用场景有望得到进一步提升和拓展。
多模态融合的可能性:模型在多模态处理方面展现出的潜力,为未来的多模态 AI 应用开辟了新的道路。特别是在代码生成与视觉元素结合、数学公式与文本融合等方面的能力,为创造性 AI 应用提供了新的可能。
从挑战的角度来看:
知识广度的差距:尽管在推理能力上已经接近顶级闭源模型,但 DeepSeek v3.2 在世界知识的广度和深度上仍有差距。这需要通过进一步的预训练或知识增强技术来解决。
Token 效率的优化:模型在某些任务上需要更多的 Token 才能达到理想的输出质量,这直接影响了推理成本和用户体验。提升 Token 效率将是未来技术改进的重点方向。
极复杂任务的处理能力:在处理需要极深度推理和大量背景知识的复杂任务时,与 Gemini-3.0-Pro 等前沿模型仍有差距。这需要在基础模型架构和训练方法上进行更深层次的创新。
产业化应用的挑战:将实验室的技术成果转化为稳定可靠的产业化应用,还需要在系统工程、性能优化、安全保障等多个方面进行大量工作。
3.4 对产业发展的启示
DeepSeek v3.2 的成功为 AI 产业发展提供了重要启示:
创新比规模更重要:在 AI 技术发展的现阶段,技术创新的价值已经超过了单纯的规模扩张。通过在架构设计、算法优化、训练策略等方面的创新,可以在资源有限的情况下实现性能的突破性提升。
开源模式的价值:DeepSeek v3.2 的成功再次证明了开源模式在推动技术进步和产业发展中的重要作用。通过开放技术成果,不仅能够加速技术迭代,还能够构建健康的产业生态。
成本控制的重要性:在 AI 应用日益普及的背景下,成本控制能力将成为决定技术竞争力的关键因素。DeepSeek 通过技术创新实现的成本大幅降低,为 AI 技术的大规模应用奠定了基础。
产学研合作的必要性:DeepSeek v3.2 的成功离不开学术界的理论创新和产业界的工程实践。未来的 AI 技术发展需要进一步加强产学研合作,实现理论突破与应用落地的良性循环。
3.5 结语
DeepSeek v3.2 的发布是 AI 技术发展史上的一个重要节点,它不仅展示了开源模型的技术实力,更为整个 AI 产业的发展提供了新的思路和方向。通过 DSA 机制的架构创新、大幅增加的后训练投入、以及思考与工具调用的融合设计,DeepSeek v3.2 在推理、数学、代码等多个维度实现了开源模型的历史性突破。
展望未来,随着技术的不断进步和应用场景的持续拓展,我们有理由相信,以 DeepSeek v3.2 为代表的新一代开源模型将在推动 AI 技术民主化、降低应用成本、促进产业创新等方面发挥越来越重要的作用。同时,我们也期待 DeepSeek 团队和其他研究者能够在未来的技术探索中,继续突破现有技术边界,为人类社会的智能化发展做出更大贡献。
DeepSeek v3.2 的成功告诉我们,在 AI 技术的发展道路上,创新永无止境,突破就在眼前。
参考资料
[1] 了解DeepSeek V3.2和Claude Sonnet 4.5 - 哥不是小萝莉 - 博客园 https://www.cnblogs.com/smartloli/p/19121684
[2] GLM-4.6、Claude Sonnet 4.5和DeepSeek V3.2-Exp开发能力对比-腾讯云开发者社区-腾讯云 https://cloud.tencent.com/developer/article/2591077
[3] DeepSeek发布双模型,V3.2强化日常Agent,Speciale极致推理_钱江晚报 http://m.toutiao.com/group/7578879354336248347/?upstream_biz=doubao
[4] DeepSeek V3.2:开源模型新突破,架构创新与策略升级引领能力跃升_搜狐网 https://m.sohu.com/a/960508882_362225/
[5] DeepSeek-V3.2-Exp:用稀疏注意力机制,开启长文本处理的“加速引擎”-51CTO.COM https://www.51cto.com/article/827160.html
[6] 大模型价格战背后的技术革命:剖析DeepSeek-V3.2的DSA稀疏注意力_51CTO博客_大模型 ai https://blog.51cto.com/u_17162562/14268468
[7] ChatGPT 三周年遭 DeepSeek 暴击,23 页技术报告藏着开源登顶的全部秘密_搜狐网 https://m.sohu.com/a/960482796_602994/
[8] 【深度学习新浪潮】DeepSeek V3.2深度解析:稀疏革命与Agent突破,开源模型的效率跃迁-CSDN博客 https://blog.csdn.net/agito_cheung/article/details/155466617
[9] DeepSeek-V3.2来了,Bye Gemini 3.0!_腾讯新闻 http://news.qq.com/rain/a/20251202A00V2800
[10] DeepSeek-V3.2发布:开源模型第一次,真正追上 GPT-5_浅聊AI http://m.toutiao.com/group/7578914729205318179/?upstream_biz=doubao
[11] OpenAI危,DeepSeek放大招:追平谷歌最强,手撕GPT-5 High_36氪 http://m.toutiao.com/group/7579058027039359528/?upstream_biz=doubao
[12] DeepSeek-V3.2系列开源,性能直接对标Gemini-3.0-Pro_36氪 http://m.toutiao.com/group/7579058011407270440/?upstream_biz=doubao
[13] DeepSeek V3.2正式发布:推理达GPT-5水平,智能体评测中开源模型最高水平_澎湃新闻 http://m.toutiao.com/group/7578863768609620490/?upstream_biz=doubao
[14] DeepSeek发布新模型_大象新闻 http://m.toutiao.com/group/7578854435816817161/?upstream_biz=doubao
[15] DeepSeek发布V3.2正式版推理与Agent_执着的火车XMrP9fc http://m.toutiao.com/group/7578996628762182178/?upstream_biz=doubao
[16] DeepSeek又上新!模型硬刚谷歌,承认开源与闭源差距拉大_第一财经 http://m.toutiao.com/group/7578881572636508681/?upstream_biz=doubao
[17] DeepSeek-V3评估指标:性能衡量标准-CSDN博客 https://blog.csdn.net/gitblog_01199/article/details/151034490
[18] Exploring the Technical Innovations of DeepSeek V3 https://deepseekv3.org/blog/deepseek-v3-architecture
[19] DeepSeek-V3 vs
Claude 3 Opus https://docsbot.ai/models/compare/deepseek-v3/claude-3-opus
[20] Deepseek Llm 7B Base by deepseek-ai https://llm.extractum.io/model/deepseek-ai%2Fdeepseek-llm-7b-base,u1U0Grki40J6X9xSB2DQF
[21] 开源最强!“拳打GPT 5”,“脚踢Gemini-3.0”,DeepSeek V3.2为何提升这么多?_华尔街见闻 http://m.toutiao.com/group/7578880526245773824/?upstream_biz=doubao
[22] DeepSeek V3.2双箭齐发:推理比肩GPT-5,思考与工具调用首次融合_人工智能社 http://m.toutiao.com/group/7578960669265904154/?upstream_biz=doubao
[23] DeepSeek新发V3.2及Speciale模型,推理能力升级,挑战GPT-5等头部大模型_搜狐网 https://m.sohu.com/a/960491746_362225/
[24] DeepSeek V3.2正式版发布:性能比肩GPT-5 数学推理能力突破_热点播报_太平洋科技资讯中心 http://news.pconline.com.cn/2027/20275732.html
[25] OpenAI危,DeepSeek放大招:追平谷歌最强,手撕GPT-5 High_36氪 http://m.toutiao.com/group/7579058027039359528/?upstream_biz=doubao
[26] DeepSeek V3.2 正式版发布:推理比肩 GPT-5,首推 Speciale 版本拿下奥数金牌_手机新浪网 https://tech.sina.cn/2025-12-01/detail-infzhxya3047919.d.html
[27] DeepSeek-V3.2正式发布,推理性能逼近GPT-5|代码|数学|编程|上下文|新模型|deepseek_网易订阅 https://www.163.com/dy/article/KFNS6I8805566LTA.html
[28] 深度求索(DeepSeek)发布 V3.2 系列模型 推理能力达到国际顶尖水平_可欣看世界 http://m.toutiao.com/group/7579015832170037811/?upstream_biz=doubao
[29] DeepSeek发布新模型_大象新闻 http://m.toutiao.com/group/7578854435816817161/?upstream_biz=doubao
[30] DeepSeek-V3.2震撼发布!推理能力全面超越GPT-5,与谷歌Gemini平分秋色-51CTO.COM https://www.51cto.com/article/830909.html
[31] DeepSeek发布V3.2系列模型,推理能力升级,向GPT-5等大模型发起挑战_搜狐网 https://m.sohu.com/a/960517570_362225/
[32] DeepSeek V3.2正式发布:推理达GPT-5水平,智能体评测中开源模型最高水平_澎湃新闻 http://m.toutiao.com/group/7578863768609620490/?upstream_biz=doubao
[33] DeepSeek V3.2正式版发布:性能比肩GPT-5 数学推理能力突破-太平洋科技 https://g.pconline.com.cn/x/2027/20275732.html
[34] DeepSeek V3.2正式版发布:推理比肩GPT-5_凤凰网 https://tech.ifeng.com/c/8ojeihHibNI
[35] deepseek-v3.2技术解析:动态窗口如何重塑大模型推理边界 http://m.toutiao.com/group/7578872119107519018/?upstream_biz=doubao
[36] DeepSeek V3-0324 的技术突破与核心特性_v3-0324优势-CSDN博客 https://blog.csdn.net/2501_90383114/article/details/146541878
[37] DeepSeek V3.2 - 大国Ai https://daguoai.com/sites/2254.html
[38] Deep Seek - V3 - 0324 的 四大 改进 # deep seek # deep seek V3 # deep seek R1 # deep seek v2 https://www.iesdouyin.com/share/video/7485664165391109413/?region=&mid=7485663783696976679&u_code=0&did=MS4wLjABAAAANwkJuWIRFOzg5uCpDRpMj4OX-QryoDgn-yYlXQnRwQQ&iid=MS4wLjABAAAANwkJuWIRFOzg5uCpDRpMj4OX-QryoDgn-yYlXQnRwQQ&with_sec_did=1&video_share_track_ver=&titleType=title&share_sign=KjTwFtIFlZBeupE_0M9N…xx2Z7fm3tSkLRuH1w5eQk-&share_version=280700&ts=1764596706&from_aid=1128&from_ssr=1&share_track_info=%7B%22link_description_type%22%3A%22%22%7D
[39] deepseek v3 0324更新发布!_mb67a792c899546的技术博客_51CTO博客 https://blog.51cto.com/u_17263044/13651465
[40] DeepSeek发布新模型 https://c.m.163.com/news/a/KFNHGIJI0550B6IS.html
[41] deepseekv3.2正式发布:推理达gpt-5水平,智能体评测中开源模型最高水平 http://m.toutiao.com/group/7578863768609620490/?upstream_biz=doubao
[42] openai危!deepseek放大招:追平谷歌最强,手撕gpt-5high http://m.toutiao.com/group/7578871481427984959/?upstream_biz=doubao
[43] 开源最强,逼平闭源顶流!deepseek发布v3.2系列模型,推理能力追平gpt-5 http://m.163.com/dy/article/KFNF2R0S05198NMR.html
[44] Deep Seek V3 . 2 正式 版 : 推理 能力 全球 领先 Deep Seek V3 . 2 正式 版 : 强化 Agent 能力 , 融入 思考 推理 ,
[45] DeepSeek–V3.2正式发布,推理达GPT-5水平,横扫四大奥赛金牌_未来图灵 http://m.toutiao.com/group/7578868748807897642/?upstream_biz=doubao
[46] DeepSeek V3.2系列正式版发布!推理能力追平GPT-5、奥林匹克金牌拿到手软-快科技-科技改变生活 https://m.mydrivers.com/newsview/1089893.html
[47] DeepSeek 如何帮助你写代码?_开发语言_AI X-Talk-DeepSeek技术社区 https://deepseek.csdn.net/67bdbedc6670175f992b1c74.html
[48] 初识deepseek的几个版本_语言模型_程序汪小陈-DeepSeek技术社区 https://deepseek.csdn.net/67d8e274d649b06b61d08ce7.html
[50] DeepSeek:从入门到精通\n清华大学新闻与传播学院 新(pdf) https://bambooandelephant.com/wp-content/uploads/2025/02/DeepSeek%E4%BB%8E%E5%85%A5%E9%97%A8%E5%88%B0%E7%B2%BE%E9%80%9A20250204.pdf
[51] 如何利用DeepSeek进行代码生成和优化? http://bbs.itying.com/topic/67a60bd355a429007d7d2014
[52] 最近火出圈的 deepseek 到底强在哪-CSDN博客 https://blog.csdn.net/linshantang/article/details/147830327
[53] DeepSeek V3.2 正式版发布:推理比肩 GPT-5,首推 Speciale 版本拿下奥数金牌_手机新浪网 https://tech.sina.cn/2025-12-01/detail-infzhxya3047919.d.html
[54] DeepSeek–V3.2正式发布,推理达GPT-5水平,横扫四大奥赛金牌_未来图灵 http://m.toutiao.com/group/7578868748807897642/?upstream_biz=doubao
[55] DeepSeek,重要发布_搜狐网 https://m.sohu.com/a/960450149_120988576/
[56] DeepSeek V3.2炸裂登场!Agent智能升级,会思考的AI太吓人了🚀_说科技 http://m.toutiao.com/group/7578872641503691300/?upstream_biz=doubao
[57] 重磅!DeepSeek V3.2 特别版发布:性能超越GPT-5,硬刚Gemini 3.0「IOI/IMO金牌」_腾讯新闻 http://news.qq.com/rain/a/20251201A085YG00
[58] DeepSeek V3.2系列正式版发布!推理能力追平GPT-5、奥林匹克金牌拿到手软_手机新浪网 http://finance.sina.cn/tech/2025-12-01/detail-infziefz3419962.d.html
[59] DeepSeek发布V3.2系列模型,强化Agent能力,推理能力追平GPT-5_华尔街见闻 http://m.toutiao.com/group/7578850135673717290/?upstream_biz=doubao
[60] DeepSeek 2025: Latest Breakthroughs, New Models, and Future Vision - DeepSeek App https://deepseek-en.com/deepseek-2025-latest-breakthroughs-new-models-and-future-vision.html
[61] DeepSeek V3 - Redefining AI Efficiency Standards https://deepseekv3.org/blog/deepseek-v3-breakthrough
[62] Exploring the Technical Innovations of DeepSeek V3 https://deepseekv3.org/blog/deepseek-v3-architecture
[63] DeepSeek-V3 https://ai.azure.com/catalog/models/DeepSeek-V3
[64] DeepSeek-V3性能评估:全面基准测试分析-CSDN博客 https://blog.csdn.net/gitblog_00885/article/details/150615650
[65] DeepSeek V3.2 特别版体验_围炉聊科技的技术博客_51CTO博客 https://blog.51cto.com/u_17588526/14356362
[66] Compare Models https://yourgpt.ai/tools/llm-comparison-and-leaderboard
[67] 最新发布:Gemini 3 Pro屠榜,DeepSeek开源反杀!_AI新技术研究 http://m.toutiao.com/group/7574229377454440960/?upstream_biz=doubao
[68] Gemini 3 Pro翻车实测:深度思考3分钟,算不过GPT-5.1-high的3秒钟?-CSDN博客 https://blog.csdn.net/gtj0617/article/details/155107689
[69] Gemini 3 Pro vs GPT 5 深度对比:6 大维度全面解析网页版和 API 差异 - API易-帮助中心 https://help.apiyi.com/gemini-3-pro-vs-gpt-5-comparison.html
[70] GPT-5、Gemini与DeepSeek:AI巨头之间的终极对决-CSDN博客 https://blog.csdn.net/2401_84204207/article/details/152266446

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)