从零打造真正好用的AI工具:Python+FastAPI+LangChain实战指南!
这篇文章介绍了如何使用Python、FastAPI和LangChain将AI模型转化为实际可用的工具。通过快速上手指南,读者可以学习创建API、添加AI功能、实现记忆功能、处理文档、添加用户界面以及部署到Docker。文章提供了分步实施计划和起步模板,帮助读者将AI实验转化为真正有用的工具,如文档分析器、聊天机器人和内部助手,适合小白和程序员学习大模型应用开发。
打造真正好用的 AI 工具:Python、FastAPI 与 LangChain 一次搞懂
为什么你的 AI 脚本值得更好的呈现方式
想象你做了个很酷的 AI 模型,会回答问题或总结文本。在 Jupyter notebook 里一切顺利。然后呢?朋友用不了,团队也访问不到。它就像一只被关在你笔记本里的鸟。
重点是:AI 的真正价值不只在模型本身,而在于“让别人能用上”。这就是 FastAPI 和 LangChain 的用武之地。它们能把你的实验性代码变成任何人都能通过浏览器使用的实际工具。
这份指南会手把手带你实现这一点——不讲花里胡哨的术语,只有真正有用、能跑的东西。

我们要做什么?
在下手前,先弄清这些工具分别干啥:
- FastAPI → 用来创建 Web API(本质上是让你的 AI 能和互联网对话)
- LangChain → 让你的应用接入 AI 模型,并提供“记忆”和“上下文”
- Python → 把一切粘在一起的胶水
把它想成开餐馆:
- Python 是你的后厨
- FastAPI 是前台点单窗口
- LangChain 是那个会记住老顾客偏好的主厨
快速上手:5 分钟搞定第一个 API
先来做一个最简单的 API。先安装 FastAPI:
pip install fastapi uvicorn
新建一个 main.py 文件:
from fastapi import FastAPIapp = FastAPI()@app.get("/")def home(): return {"message": "Hello! Your AI tool is alive!"}
运行:
uvicorn main:app --reload
打开浏览器访问 http://localhost:8000,你会看到消息。恭喜——你刚刚造好了一个 API!🎉
刚刚发生了什么?你启动了一个 Web 服务器来响应请求。当有人访问这个 URL 时,FastAPI 会运行 home() 函数并返回响应。
用 LangChain 加上 AI 大脑
现在让它聪明起来。安装 LangChain 和 OpenAI:
pip install langchain openai
把下面的代码加进去:
from fastapi import FastAPIfrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import ChatPromptTemplateapp = FastAPI()llm = ChatOpenAI(model="gpt-4", temperature=0.7)@app.post("/ask")def ask_ai(prompt: str): template = ChatPromptTemplate.from_template( "You are a helpful assistant. Answer clearly: {prompt}" ) messages = template.format_messages(prompt=prompt) response = llm(messages) return {"response": response.content}
这里发生了什么?
- 我们创建了一个 POST 类型的 endpoint(类似表单提交)
- 用户发送问题时,LangChain 会帮你把提示词格式化好
- AI 模型生成答案
- FastAPI 把答案返回给调用方
试着发个请求:
curl -X POST "http://localhost:8000/ask?prompt=What is Python?"
你刚刚造了一个迷你版 ChatGPT!🚀
让它有记忆:加上 Memory
现在你的 AI 还“失忆”,每个问题都当第一次见。我们来解决它。

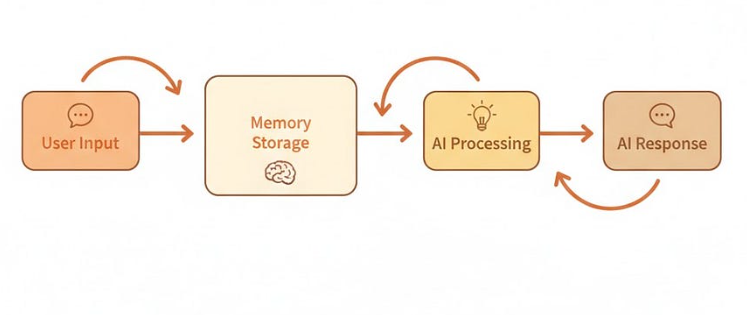
原文里的 memory 代码有些问题,这里给一版更干净的做法:
from langchain.memory import ConversationBufferMemoryfrom langchain.chains import ConversationChainmemory = ConversationBufferMemory()conversation = ConversationChain(llm=llm, memory=memory)@app.post("/chat")def chat(message: str): response = conversation.predict(input=message) return {"response": response}
现在你的 AI 会记住之前聊过的内容了。试着和它来一段真实的对话吧!
让你的 AI 会看文档
这部分开始变得很酷。让 AI 能看 PDF,然后回答相关问题。
流程如下:


上代码:
from langchain.document_loaders import PyPDFLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.vectorstores import FAISSfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.chains import RetrievalQA# Load and process the PDFloader = PyPDFLoader("data/company_report.pdf")docs = loader.load()# Split into smaller chunkssplitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=100)texts = splitter.split_documents(docs)# Create searchable databaseembeddings = OpenAIEmbeddings()vectorstore = FAISS.from_documents(texts, embeddings)# Create Q&A chainqa = RetrievalQA.from_chain_type( llm=llm, retriever=vectorstore.as_retriever())@app.post("/ask-doc")defask_document(question: str): answer = qa.run(question) return {"answer": answer}
其中的“魔法”是:
- 你的 PDF 会被切成小块
- 每一块会被转成能表达语义的数字向量(embeddings)
- 提问时,系统会检索最相关的那些小块
- AI 只阅读这些相关内容并生成答案
重要提示 📝
⚠️ 注意事项:
- API Keys:你需要 OpenAI 的 API key(设置为环境变量
OPENAI_API_KEY) - 成本:OpenAI 按请求计费——注意监控用量!
- 文件大小:很大的 PDF 处理会比较耗时
- 记忆上限:对话历史不要无限堆,否则会变慢
💡 专业建议:
- 事实型回答用
temperature=0,创作型回答用temperature=0.7+ - 文本分块的 chunk 大小很关键——1000 字符通常对大多数文档效果不错
- 生产环境一定要加上错误处理
加个简单的用户界面
API 很好用,但给它一张“脸”更友好。用 Streamlit 来个快速界面:
import streamlit as stimport requestsst.title("📄 AI Document Assistant")question = st.text_input("Ask anything about your document:")if st.button("Get Answer"): response = requests.post( "http://127.0.0.1:8000/ask-doc", params={"question": question} ) st.write("**Answer:**", response.json()["answer"])
运行:
streamlit run app.py
现在你就有了一个漂亮的网页界面!用户不需要写任何代码。
让它 24/7 运行:部署
你不可能一直开着笔记本。我们用 Docker 容器化部署:
创建一个 Dockerfile:
FROM python:3.11-slimWORKDIR /appCOPY . .RUN pip install fastapi uvicorn langchain openaiCMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建并运行:
docker build -t my-ai-tool .docker run -p 8000:8000 my-ai-tool
现在你的 AI 工具可以在世界上任何服务器上运行!🌍
真实场景示例:内部知识助手
你可以这样搭:
设置:
- 接入公司文档与 Slack 导出内容
- 自动总结团队讨论
- 回答诸如“我们对市场预算的最终决定是什么?”
- 每日发送摘要邮件
技术栈:
- FastAPI 作为后端
- LangChain 负责 AI 逻辑
- SQLite 存储对话历史
- 一台每月 5 美元的云服务器托管
结果:你的团队得到一个 24/7 的 AI 助手,了解公司的一切。再也不用在无尽的 Slack 线程里翻找!
分步实施计划
准备好动手了吗?路线图在这里:
1:地基
- 搭好 Python 环境
- 实现基础 FastAPI endpoints
- 用 LangChain 接入 OpenAI
- 用简单问题测试
2:智能
- 增加文档读取能力
- 实现记忆/上下文
- 用真实文档测试
- 优雅地处理错误
3:打磨
- 做个简易 Web 界面
- 加上认证(如有需要)
- 用 Docker 部署
- 监控并持续改进
起步模板
from fastapi import FastAPI, HTTPExceptionfrom langchain.chat_models import ChatOpenAIimport os# Initializeapp = FastAPI()llm = ChatOpenAI( model="gpt-4", api_key=os.getenv("OPENAI_API_KEY"))@app.get("/")defhome(): return {"status": "AI tool is running!"}@app.post("/ask")defask(question: str): try: response = llm.invoke(question) return {"answer": response.content} except Exception as e: raise HTTPException(status_code=500, detail=str(e))# Add your own endpoints here!
收个尾
现在你已经学会如何把 AI 实验变成真正好用的工具。你可以:
✅ 创建任何人都能用的 Web API
✅ 让 AI 连接到你的文档与数据
✅ 构建能记住上下文的工具
✅ 部署并 24/7 稳定运行
最棒的是:这只是开始。你还能做:
- 为业务定制的聊天机器人
- 节省大量阅读时间的文档分析器
- 自动处理常见问题的助手
- 让团队更高效的内部工具
你的下一步:选一个简单项目,这周就把它做出来。小范围起步——比如一个 PDF 阅读器或问答机器人。一旦跑通,你就停不下来了。
记住:把一个酷炫的 AI 演示变成真正有用的工具,只需在 FastAPI 和 LangChain 上再花上几个小时。去做点很棒的东西吧!🚀
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 2
2 0
0- 0



 已为社区贡献569条内容
已为社区贡献569条内容

所有评论(0)