本地部署 Stable Diffusion3.5超详细教程
本文详细介绍了如何在Windows系统下本地部署Stable Diffusion3.5模型,包括ComfyUI的安装配置、中文语言包的添加以及模型文件的下载设置。测试环境为Win11专业版+8GB显存,推荐使用3.5 Large Turbo版本。通过分步指导完成了文生图功能演示,并提供了团队协作的远程访问解决方案。该教程帮助用户快速搭建AI绘图环境,充分发挥Stable Diffusion3.5在
前言
Stable Diffusion3.5 是一款强大的 AI 绘图工具,能通过文本生成高质量图像,适合设计师、创作者等需要快速产出视觉内容的人群,其优点在于生成效果细腻、可控性强。
使用时需注意,不同型号模型对硬件要求不同,比如 Large Turbo 版本推荐 8G 以上显存,避免运行卡顿。
但默认情况下,它只能在局域网内使用,出门在外想调整参数或查看进度时,就会受到限制,无法随时操作。

1. 本地部署ComfyUI
本篇文章测试环境:Win11专业版,8GB显存
进入到官方Github中,下载 最新版ComfyUI
ComfyUI Github:GitHub - comfyanonymous/ComfyUI: The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface.
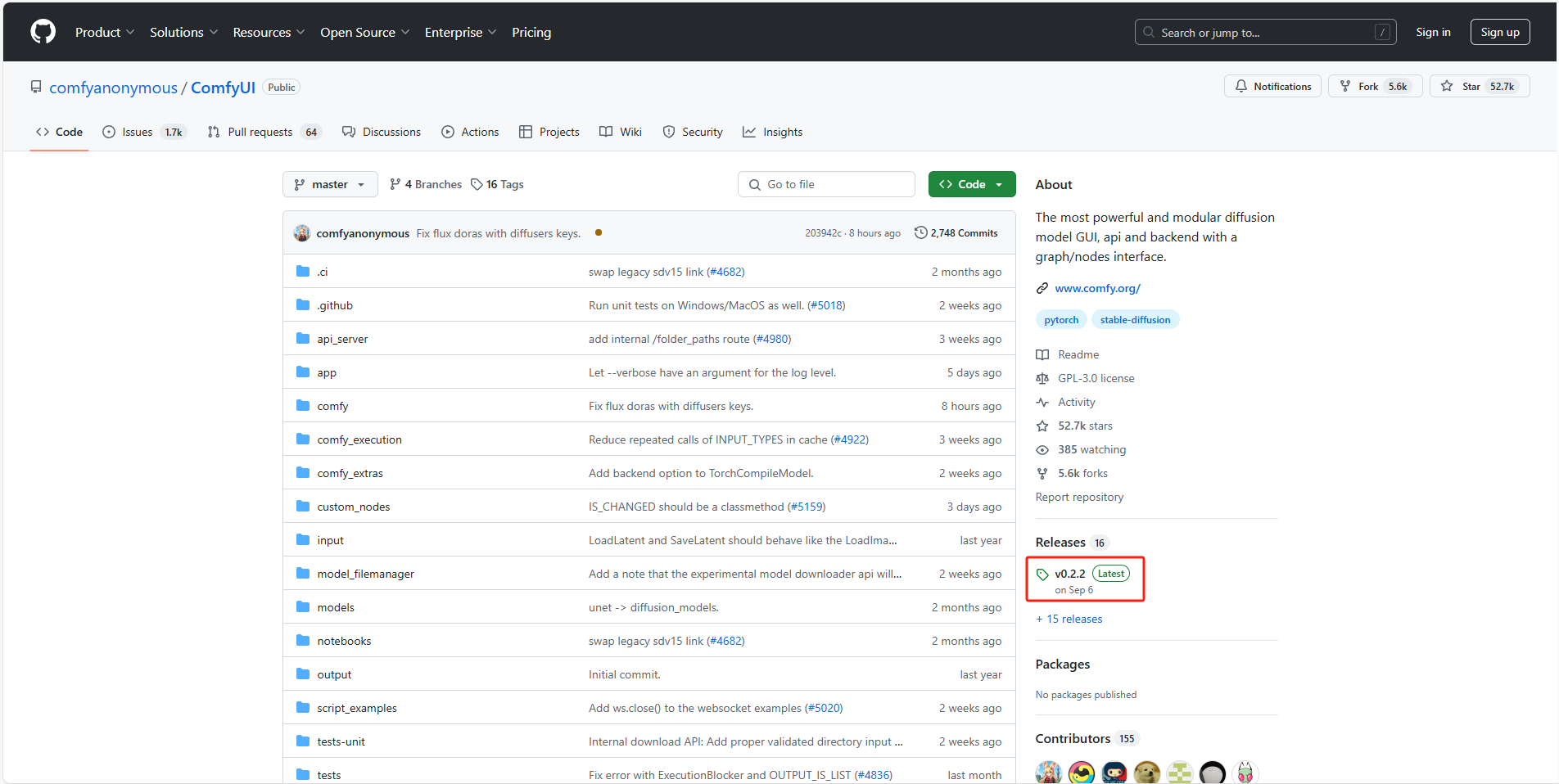
找到免安装版本
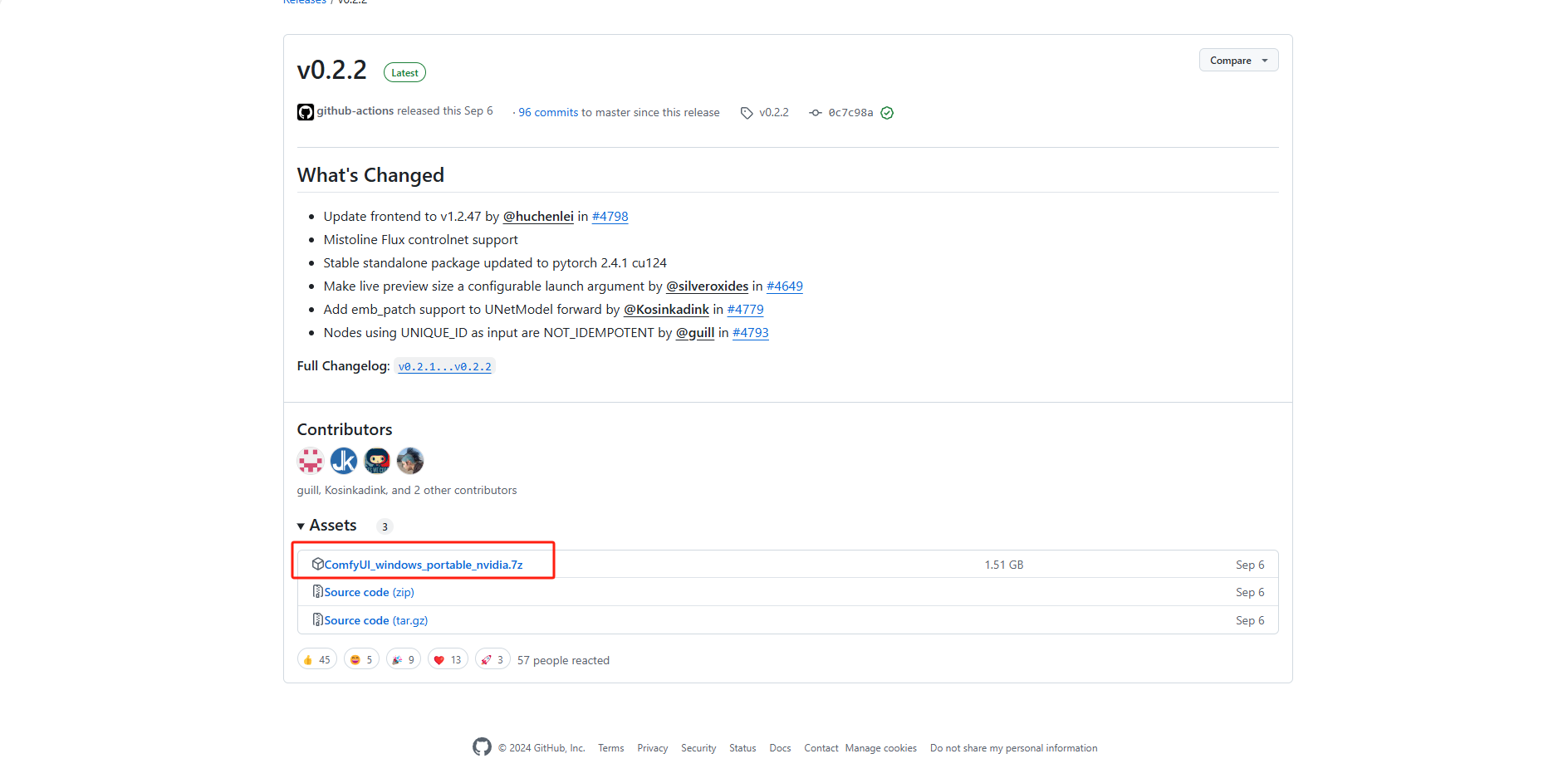
解压保存到本地打开,进入到根目录下,有 run_cpu、run_nvidia_gpu 第一个是通过CPU进行解码的,第二个是通过Nvidia显卡进行解码的,速度会更快
双击打开这两个其中哪个脚本都可以,运行脚本
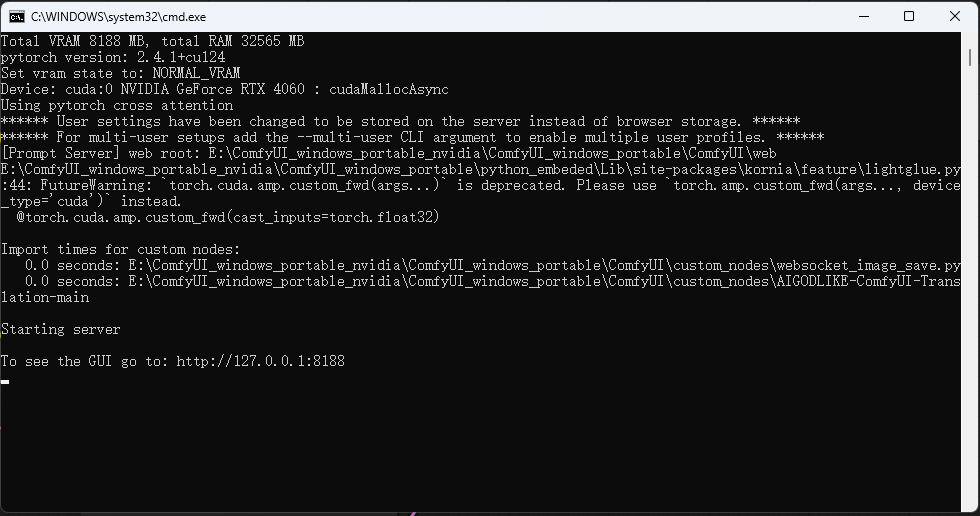
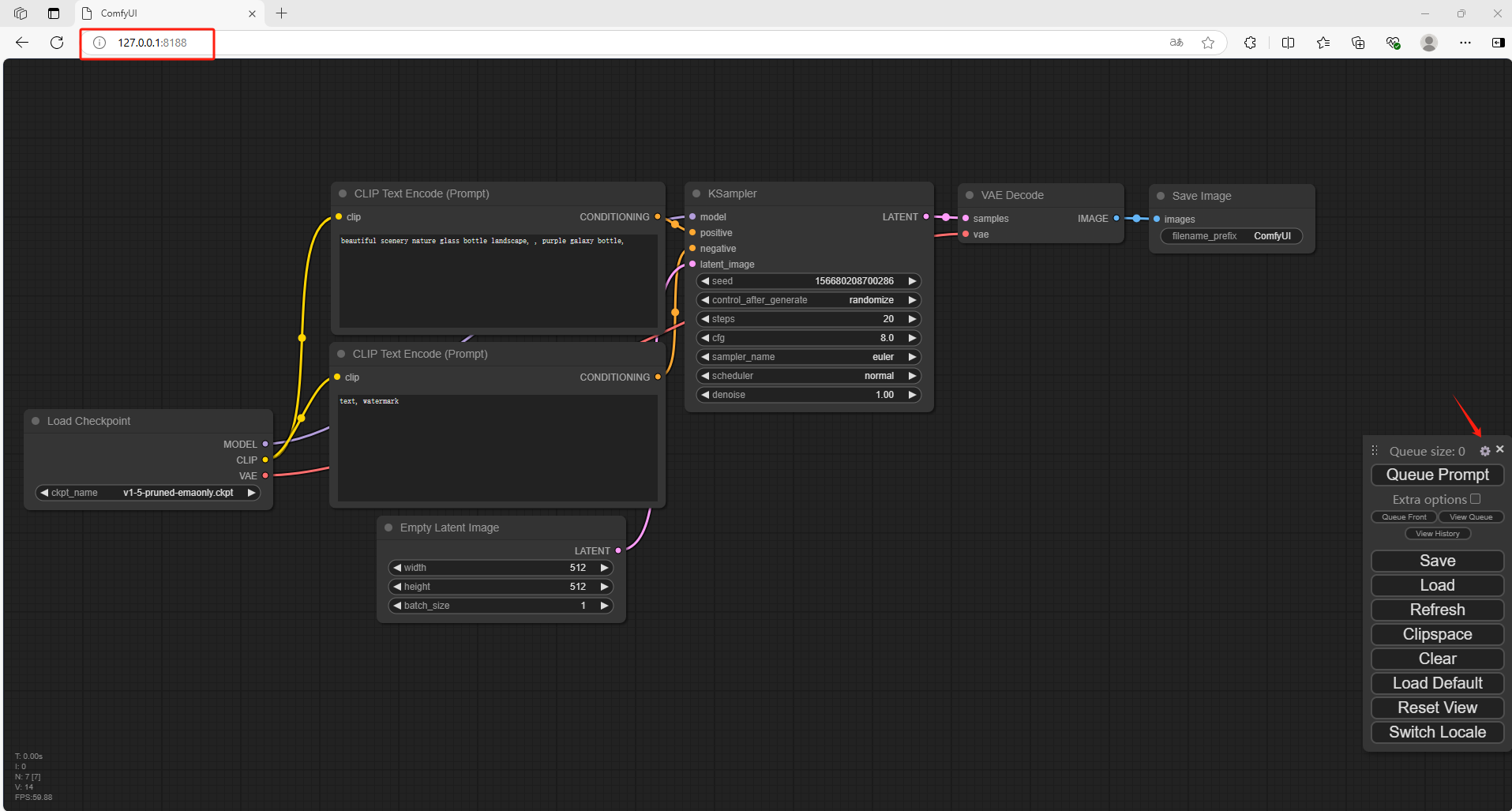
打开一个新的浏览器输入 http://127.0.0.1:8188
可以看到进入到了ComfyUI当中,但是默认情况下是英文,需要设置成中文
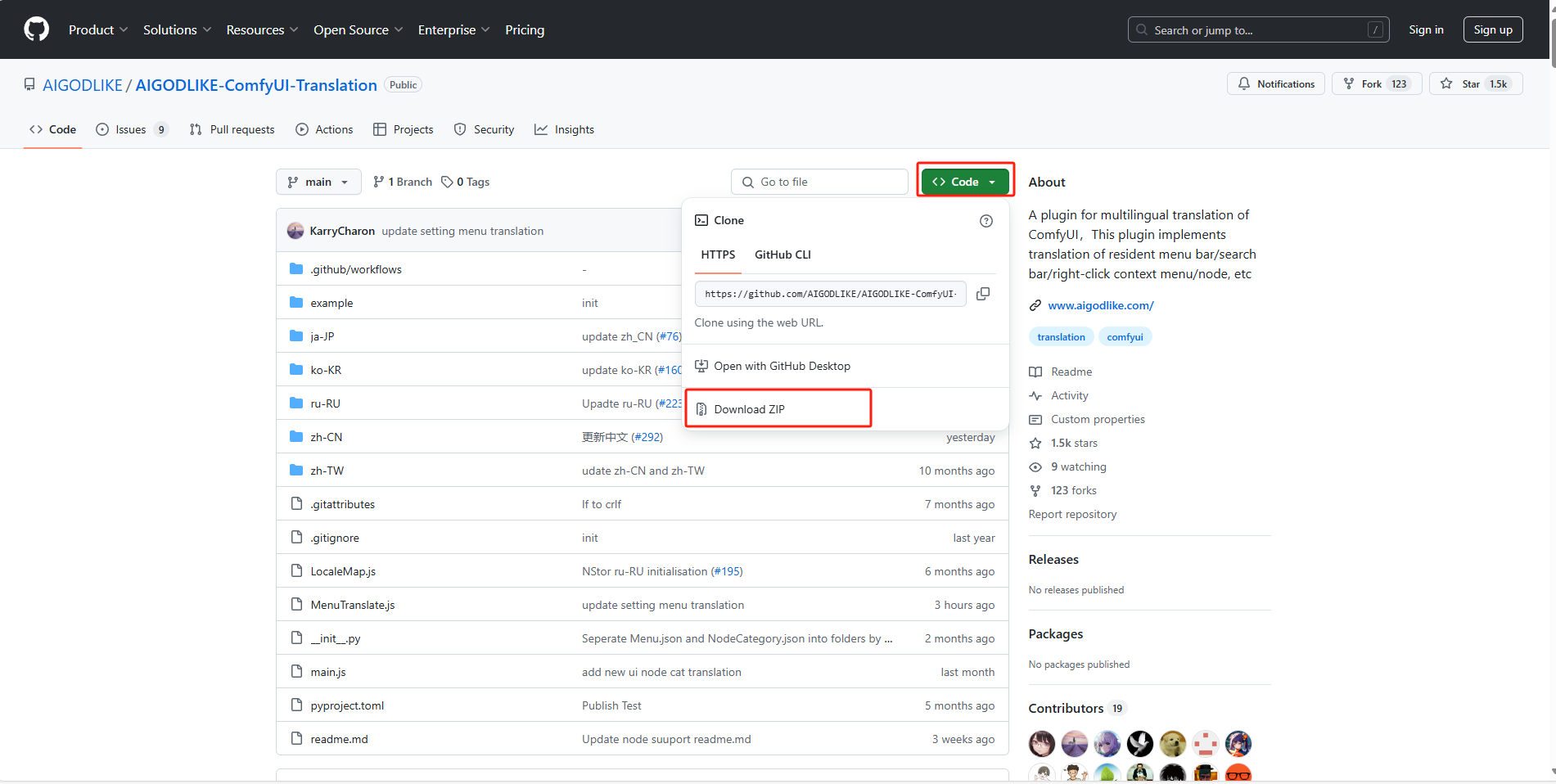
下载压缩包并解压到本地
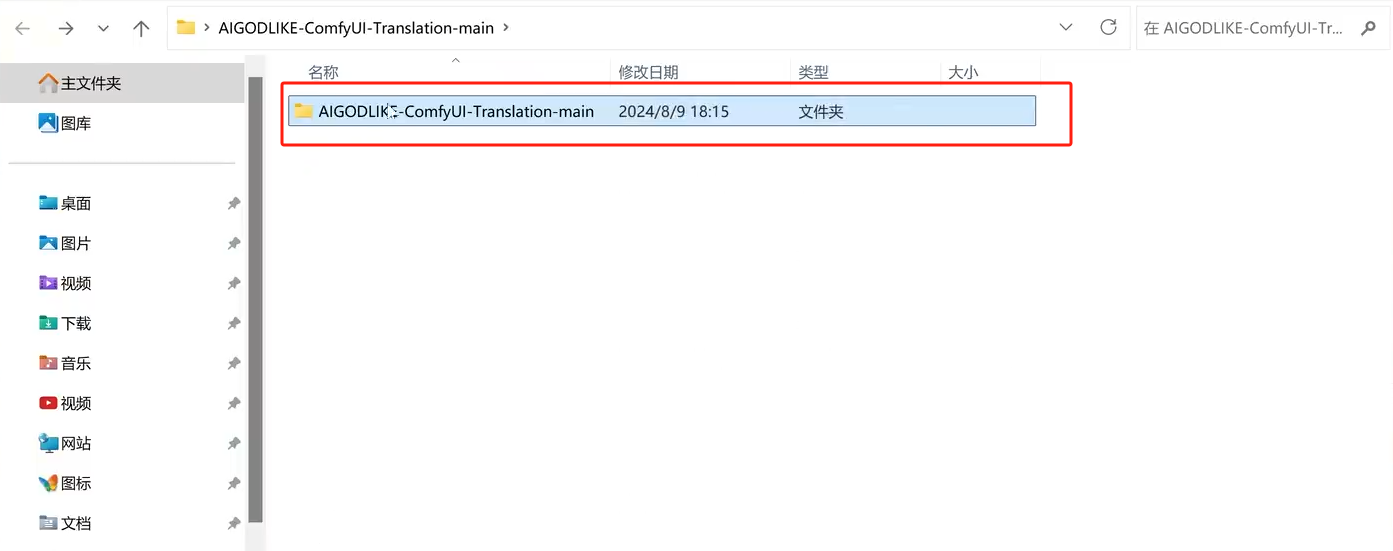
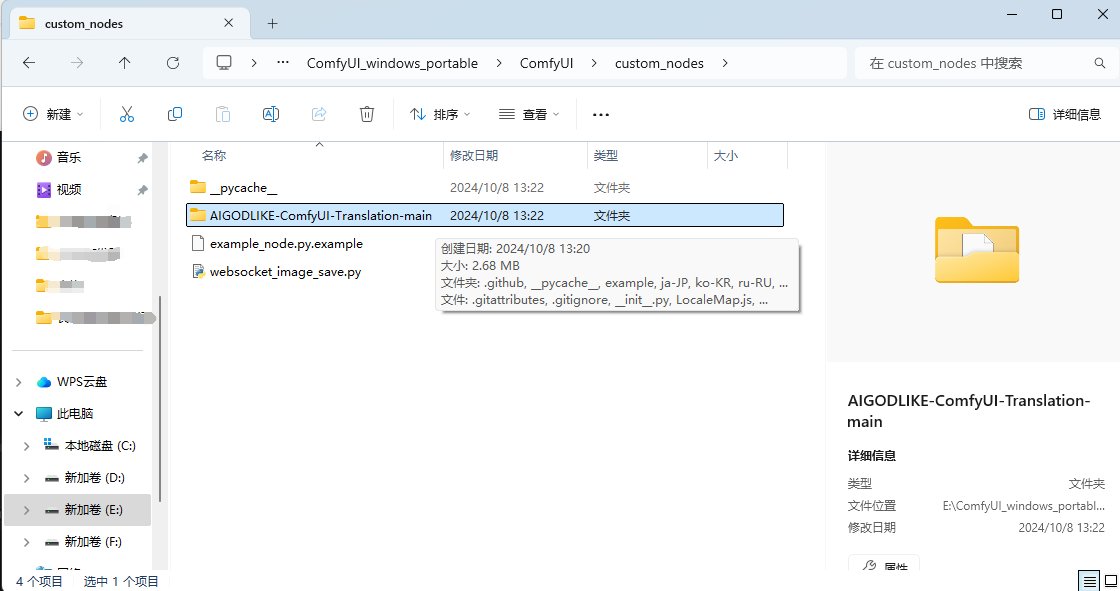
解压后,进入到根目录,把这个文件放到ComfyUI \ custom_nodes 目录中
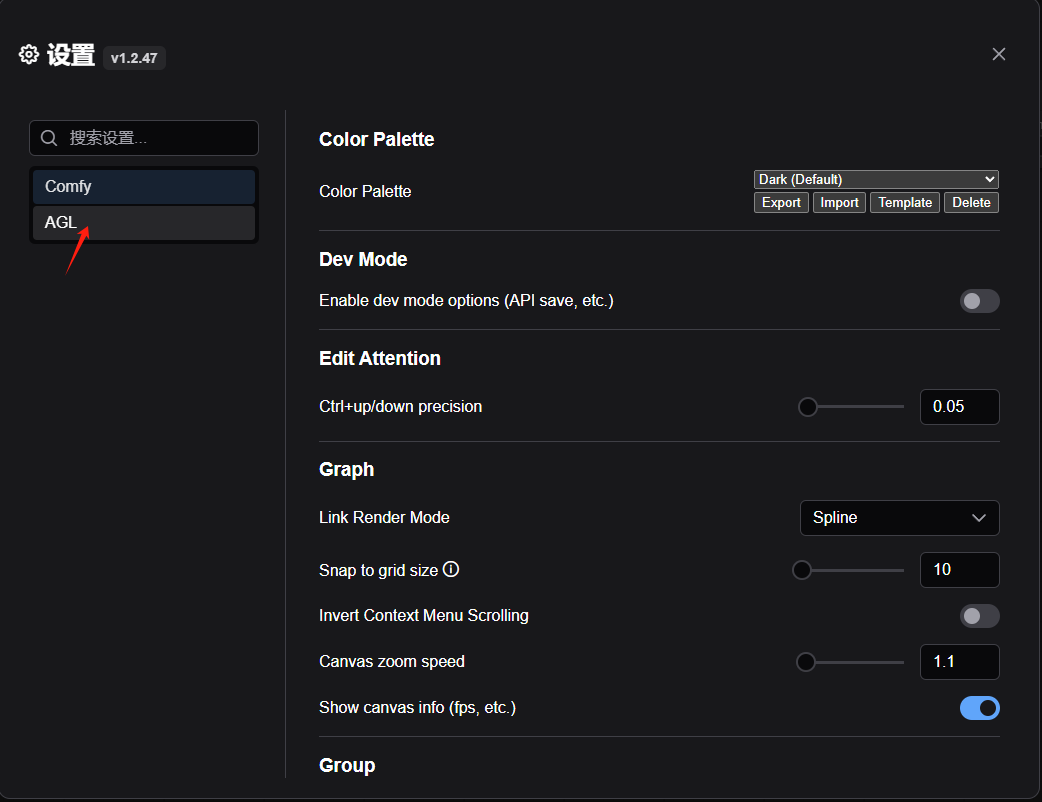
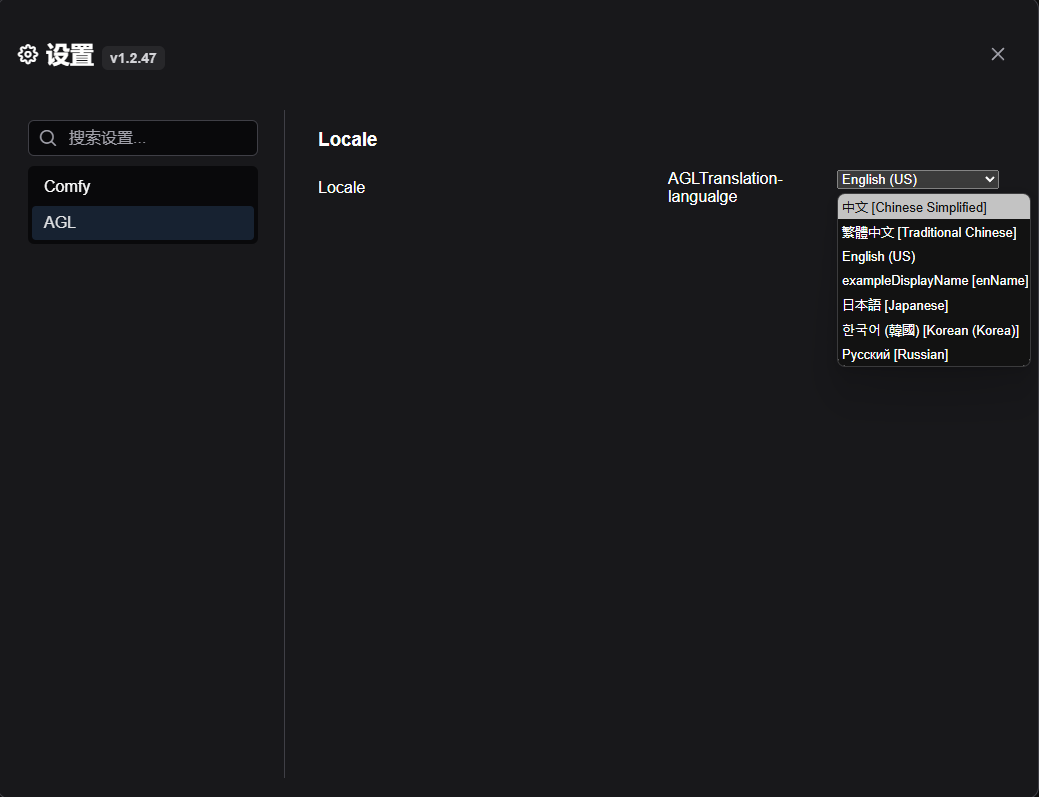
回到 Comfy UI 中,点击设置,选择语言为中文
2. 下载 Stable Diffusion3.5 模型
Stable Diffusion共发布了三款模型,分别是:
-
Stable Diffusion 3.5 Large:该基础型号拥有 80 亿个参数,质量卓越,响应迅速,是 Stable Diffusion 系列中最强大的型号。该型号非常适合 1 百万像素分辨率的专业用例。【推荐16G以上显存】
-
稳定扩散 3.5 Large Turbo:稳定扩散 3.5 Large 的精简版仅需 4 个步骤即可生成高质量图像,且具有出色的快速依从性,速度比稳定扩散 3.5 Large 快得多。【推荐8G以上显存】
-
Stable Diffusion 3.5 Medium(将于 10 月 29 日发布): 该模型拥有 25 亿个参数,采用改进的 MMDiT-X 架构和训练方法,可在消费级硬件上“开箱即用”,在质量和定制易用性之间取得平衡。它能够生成分辨率在 0.25 到 2 百万像素之间的图像。
本篇文章演示使用的是 第二种 3.5 Large Turbo版本,
点击链接下载模型:stabilityai/stable-diffusion-3.5-large-turbo · Hugging Face
找到下方这两个文件
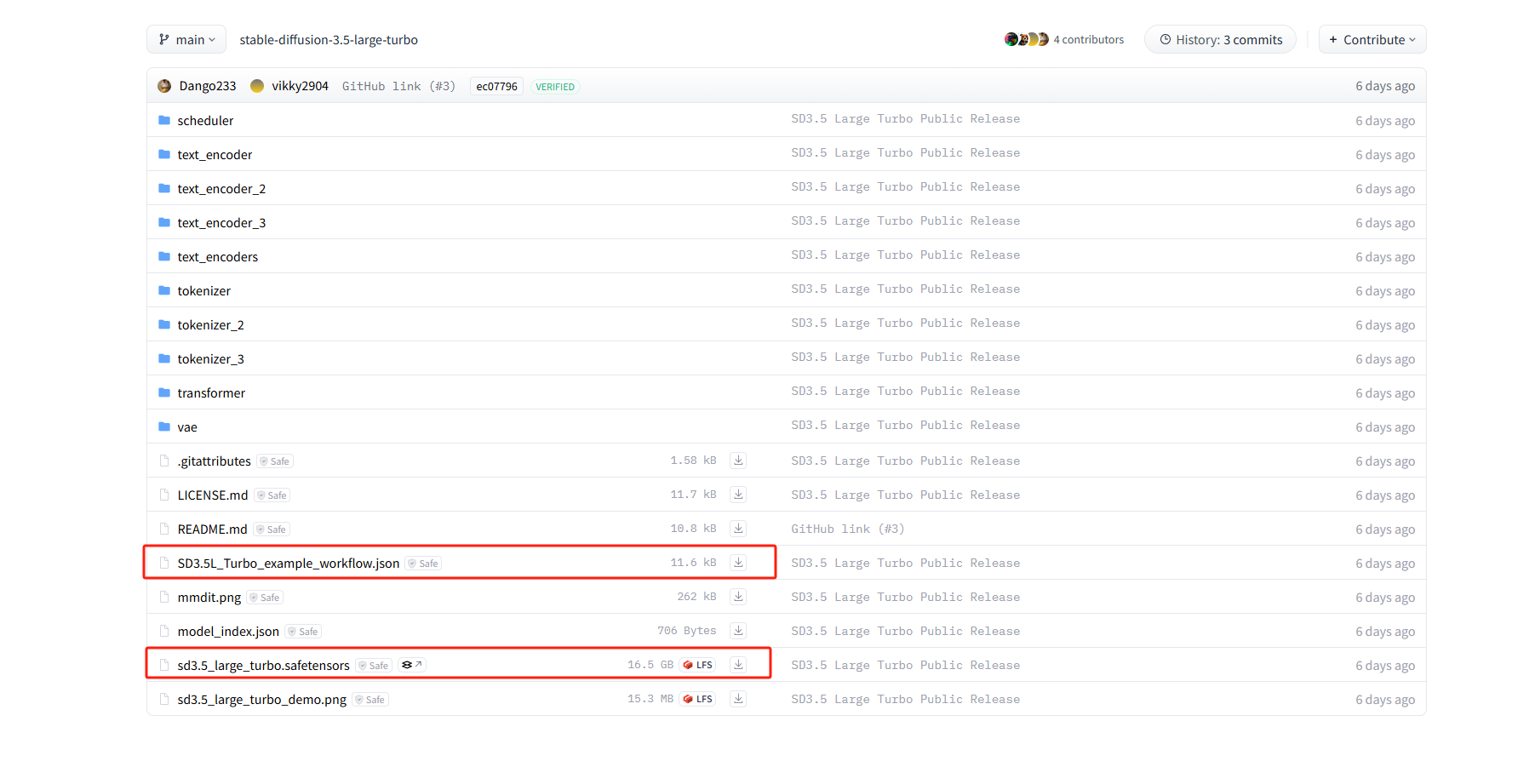
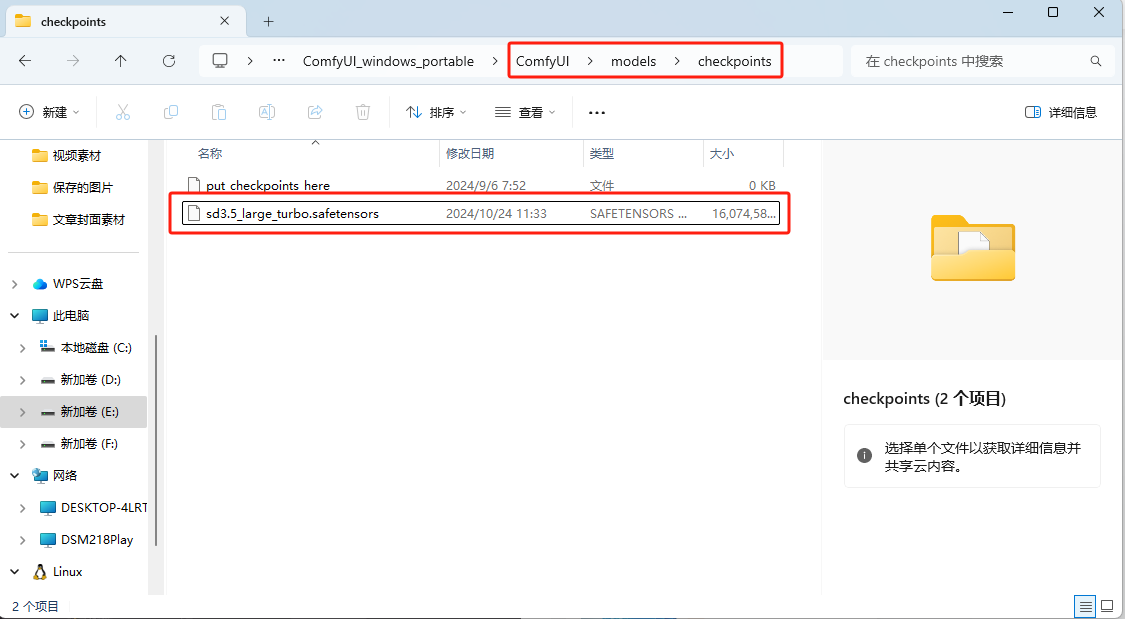
将 sd3.5_large_turbo.safetensors 文件下载到 ComfyUI/models/checkpoint 文件夹中
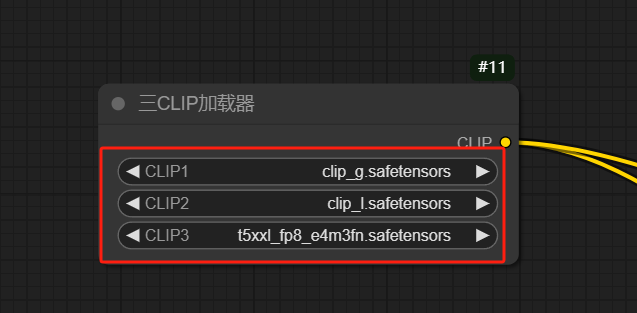
接下来下载Clip文件, 将clip_g.safetensors、clip_l.safetensors 和 t5xxl_fp8_e4m3fn.safetensors 下载到 ComfyUI/models/clip 文件夹
回到ComfyUI目录中,运行一键脚本。
重新进入到浏览器当中 http://127.0.0.1:8188
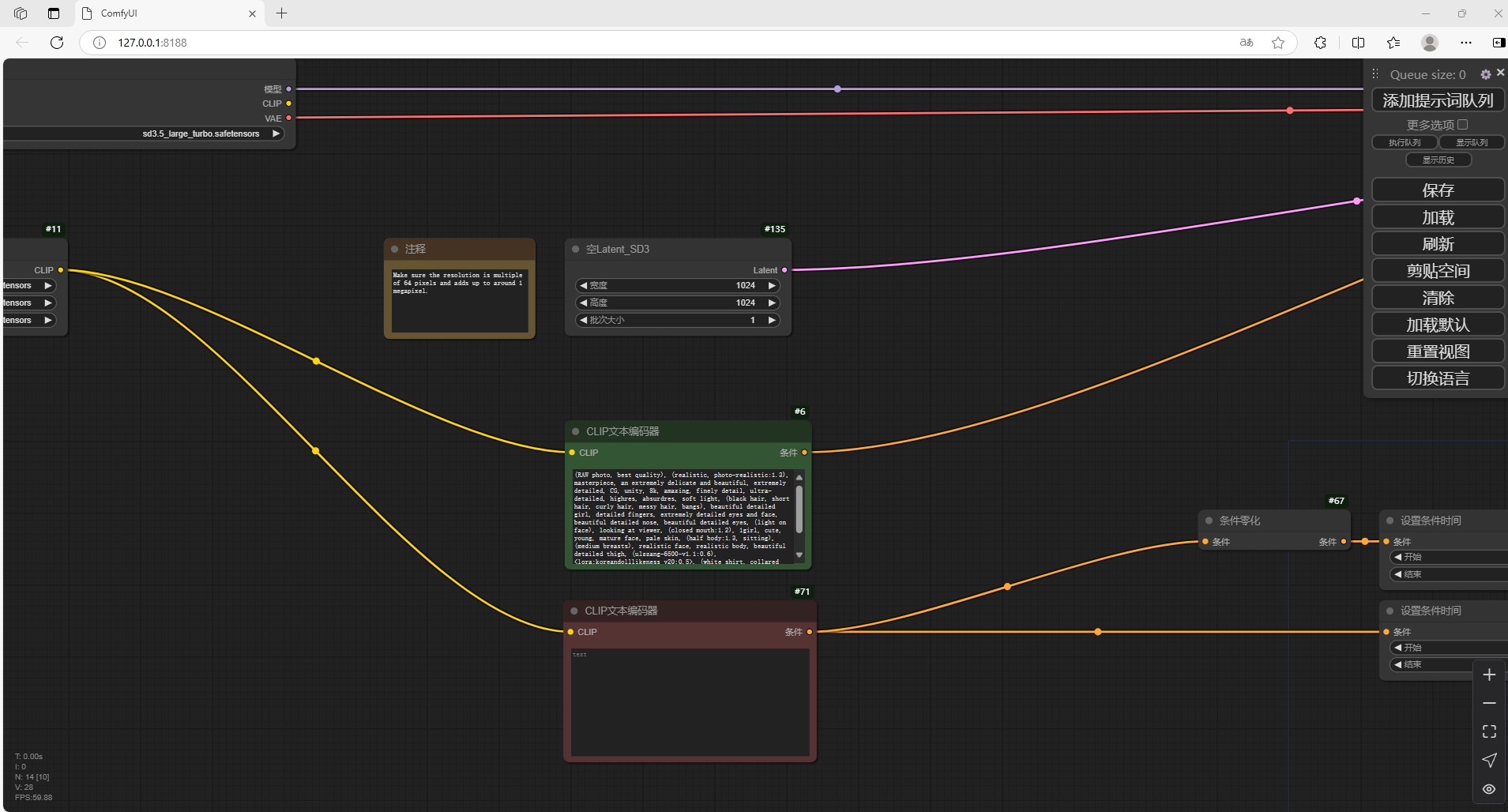
3. 演示文生图
将刚才下载好的 SD3.5L_Turbo_example_workflow.json 文件拖入到ComfyUI界面中
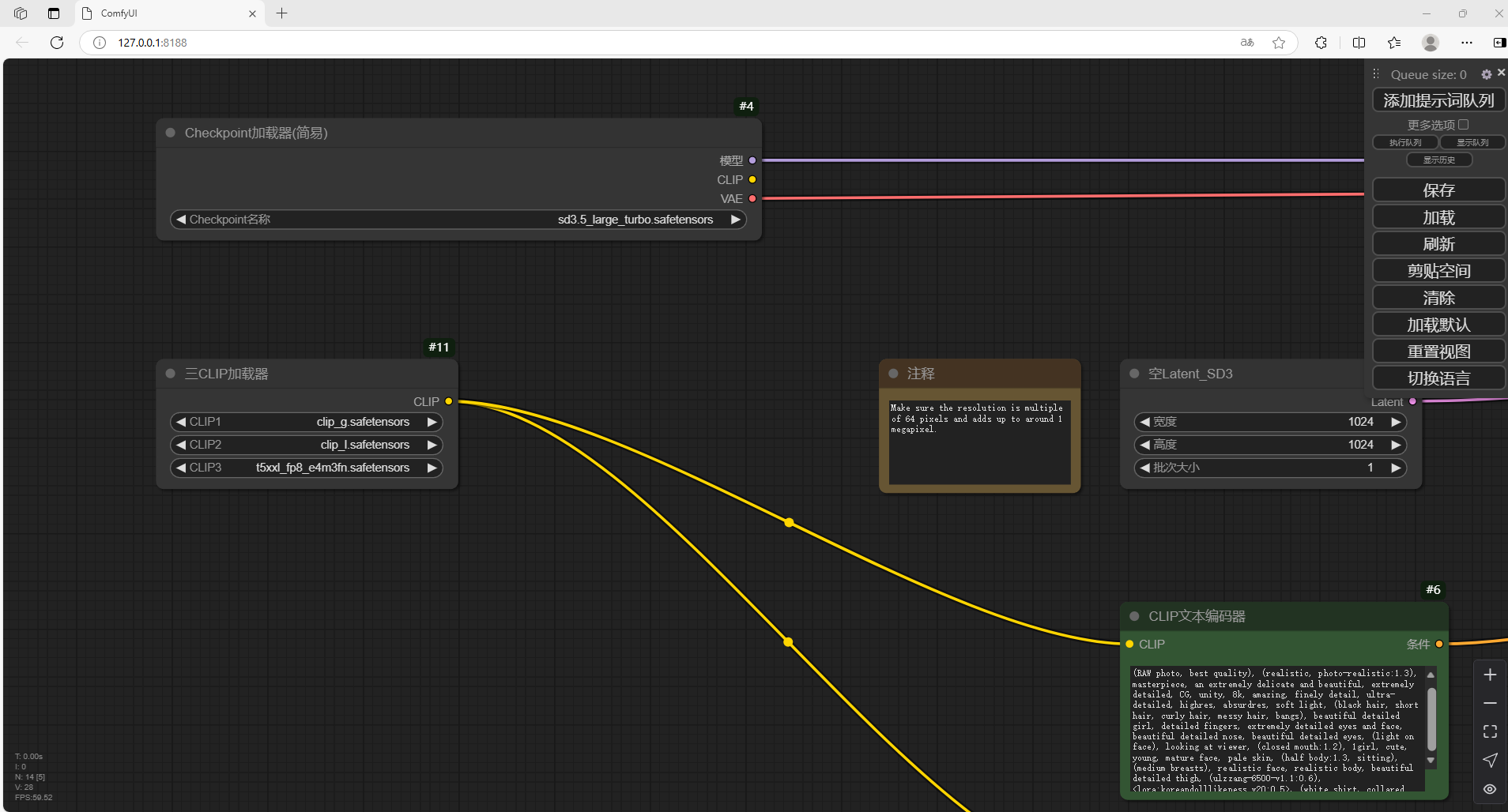
然后在左侧Clip设置中,修改成我们刚才下载的模型
在中间的CLIP文本编码器中,输入英文提示词后,点击右侧 添加提示词队列
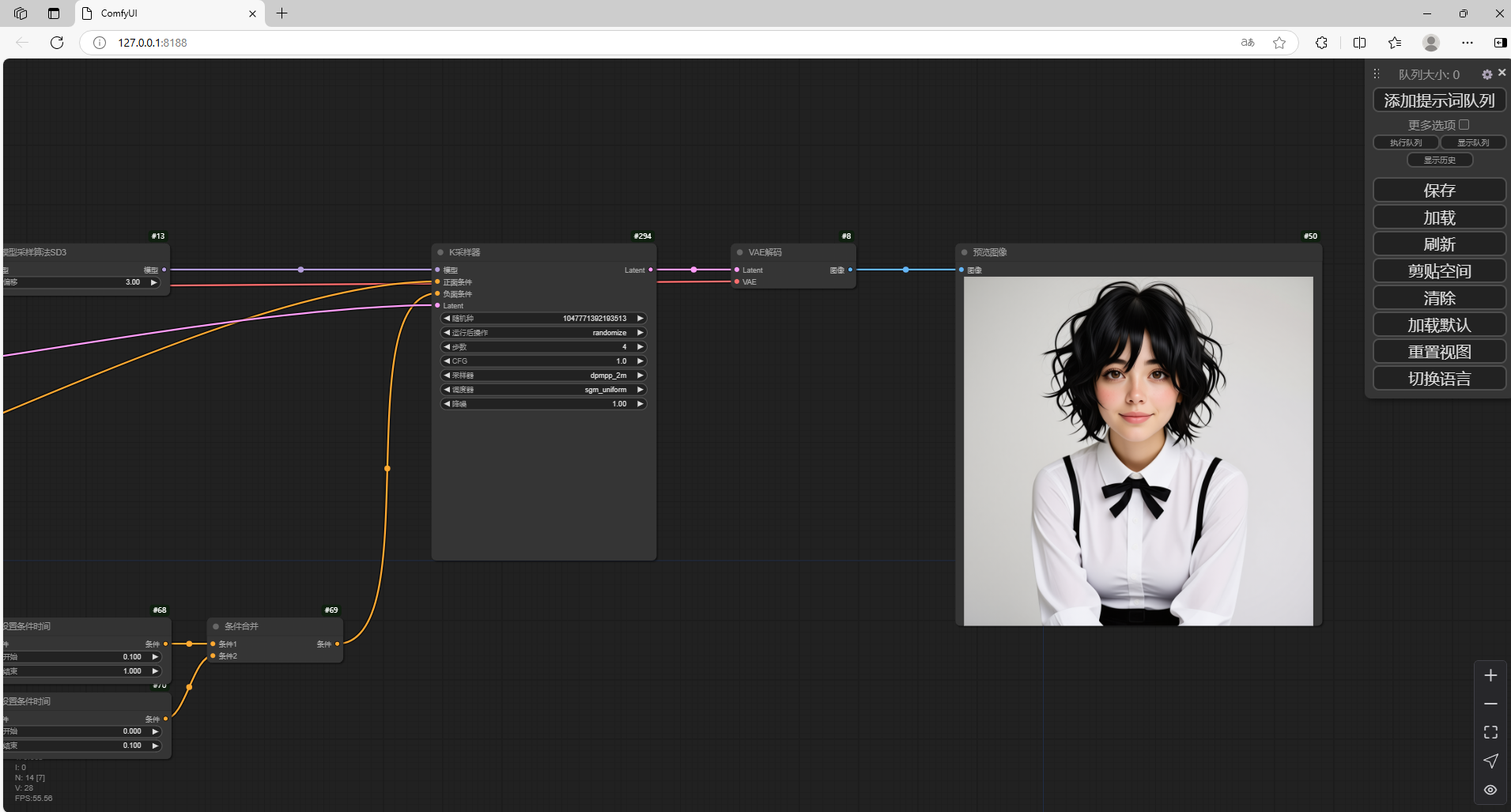
可以看到右侧已经生成了新的图片,我们在本地成功部署了Stable Diffusion 3.5 大模型,如果想团队协作多人使用, 免去了复杂得本地部署过程,只需要一个公网地址直接就可以进入到ComfyUI中来使用 Stable Diffusion 3.5文生图。
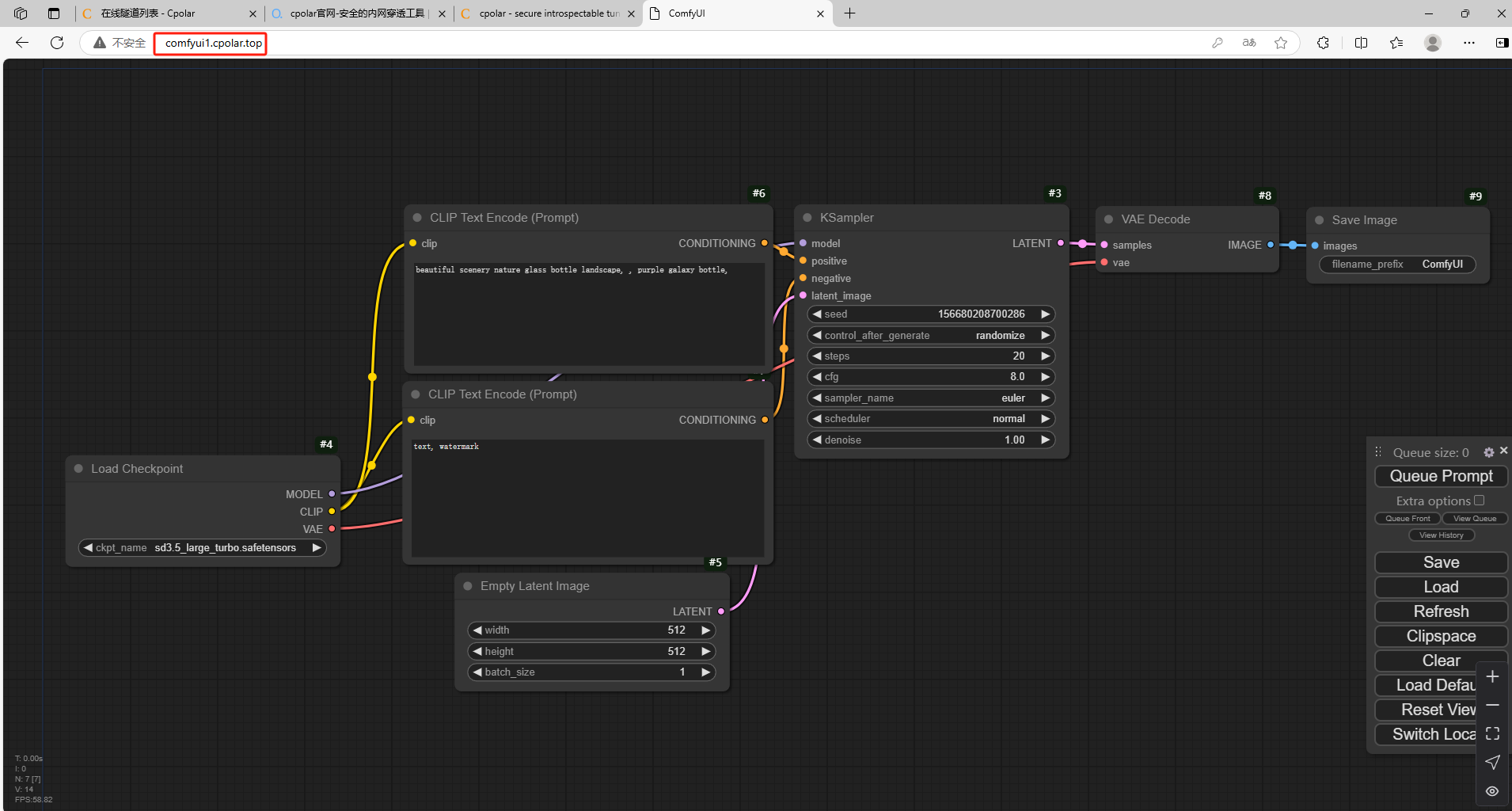
通过上述方法,既能发挥 Stable Diffusion3.5 的绘图优势,又能 让 AI 绘图更灵活。
总结
恭喜!至此,您已成功在本地部署了强大的 Stable Diffusion 3.5 模型,并搭建起了属于自己的 AI 绘画工作站。
教程核心步骤总结与后续指引
本教程旨在带您完成 Stable Diffusion 3.5 在 ComfyUI 中的本地部署,实现随时可用的 AI 绘图能力。以下是您已完成的里程碑:
✅ 第一步:搭建工作台
- 下载并解压 ComfyUI 免安装版。
- 启动服务,安装中文插件,完成基础环境配置。
✅ 第二步:安装“引擎”
- 下载 SD3.5 Large Turbo 模型文件(
safetensors)。 - 下载并放置必需的 CLIP 文本编码器文件。
- 将文件准确放入 ComfyUI 对应的
checkpoint和clip文件夹。
✅ 第三步:启动并测试
- 重启 ComfyUI 服务,加载示例工作流(
json文件)。 - 在节点中正确选择已下载的模型,输入提示词,成功生成第一张图片。
您已经成功了! 这个本地环境是您所有创意和技术探索的起点。接下来,您可以:
- 深入探索:在 ComfyUI 中尝试更多节点和高级工作流。
- 解决初衷:参考网络配置教程,将本地的
http://127.0.0.1:8188变为一个公网地址,实现随时随地访问。
感谢跟随本教程完成操作,祝您创作愉快!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)