从固定流程到主动思考,LangGraph 重构智能体 RAG,医疗问答多步推理能力爆发
摘要: 医疗领域对AI问答系统的精准性和可靠性要求极高,传统检索增强生成(RAG)技术因固定流程难以应对医疗场景的复杂需求,易出现无关检索或幻觉生成。智能体RAG(Agentic RAG)通过引入推理和决策层,动态选择检索源、验证信息并迭代优化答案,结合LangGraph的多步推理编排能力,显著提升医疗问答的准确性。本文以Python、LangGraph、ChromaDB等技术栈为基础,通过医疗问
在医疗健康、医疗设备这类高风险领域,AI问答系统的精准性和可靠性直接关系到使用价值,甚至可能影响决策判断。检索增强生成(RAG)作为融合信息检索与大语言模型的技术方案,本应成为医疗问答的核心支撑,但传统RAG的固定流程却难以适配医疗场景的复杂需求,面对跨知识库的问题、未覆盖的新信息,传统RAG要么返回无关内容,要么产生幻觉,无法满足医疗领域对事实性和全面性的要求。
正是在这样的背景下,智能体RAG(Agentic RAG)应运而生。它在传统RAG的基础上增加了推理和决策层,能够动态选择检索源、验证信息相关性、迭代优化答案,而LangGraph则为这种多步推理能力提供了灵活的工作流编排能力。本文将结合医疗问答和医疗设备手册两大场景,手把手教你搭建一套具备多步推理能力的智能体RAG系统,让AI在医疗领域的问答更精准、更可靠。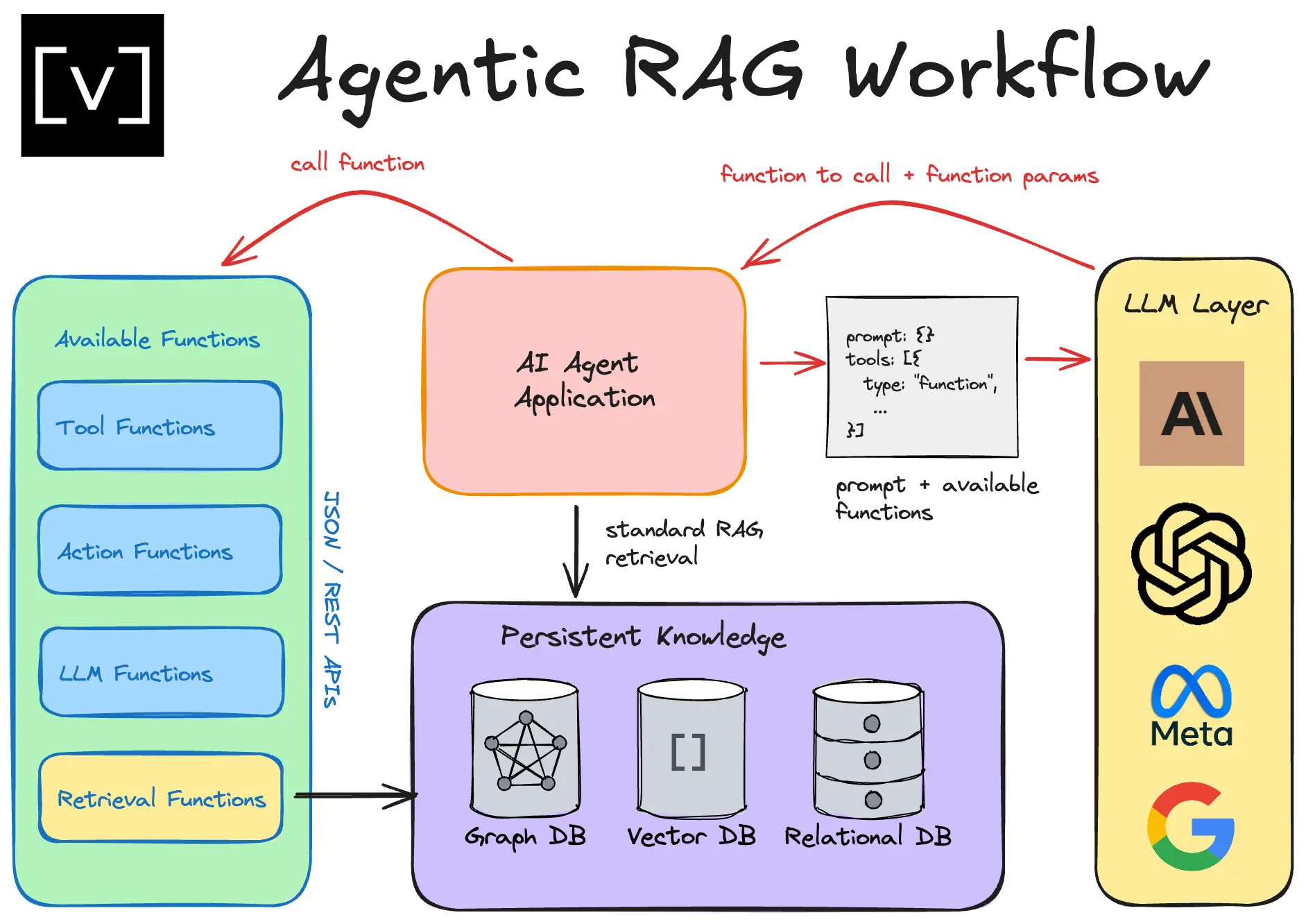
一、RAG的核心价值与医疗场景的特殊挑战
RAG的核心逻辑很简单:当用户提出问题时,系统不会直接让大模型“凭空”回答,而是先从外部知识库中检索最相关的信息,再将这些信息作为上下文交给大模型生成答案。这种“检索+生成”的模式,既解决了大模型上下文窗口有限的问题,又能有效减少幻觉,让答案更有事实依据。
但医疗场景对RAG提出了远超通用场景的要求。首先,医疗知识高度专业且细分,既包含疾病诊疗、症状判断这类通用医疗问答,也涉及医疗设备的使用说明、禁忌症这类设备手册信息,不同类型的问题需要匹配不同的知识库;其次,医疗信息更新快,比如新的新冠治疗药物、政策层面的医疗关税调整等,仅靠本地知识库无法覆盖;最后,医疗问答容不得半点差错,必须确保检索到的信息与问题高度相关,否则可能给出误导性答案。
传统RAG在应对这些挑战时,暴露了明显的短板:
第一,单次检索的局限性。传统RAG只能执行一次检索操作,无法进行多跳推理,比如先从问答库找基础治疗方案,再从设备库找配套设备信息,最后通过网页搜索补充最新指南;
第二,检索内容不相关与幻觉。传统RAG仅依靠语义相似度检索,可能会把“川崎病治疗”和“克拉伯病治疗”这类语义相近但上下文完全不同的内容检索出来,大模型基于这些无关信息生成答案,就会出现事实性错误;
第三,静态且不具适应性。传统RAG的检索源是固定的,不管用户问的是医疗设备问题还是最新医疗政策,都只会从同一个知识库检索,无法根据问题类型动态调整;
第四,可扩展性差。受限于上下文窗口大小,传统RAG难以聚合多源信息,面对大规模医疗数据时,计算开销高且信息整合效果差。
要解决这些问题,就需要给RAG增加“思考”能力——让系统能判断问题类型、选择合适的检索源、验证信息相关性,甚至在检索结果不理想时主动切换检索方式,这就是智能体RAG的核心思路。
二、技术栈选型:为什么是LangGraph+ChromaDB+SerperAPI?
搭建智能体RAG的第一步是选对工具,结合医疗场景的需求和落地成本,我们选择了一套轻量化且易上手的技术栈:
- Python:作为核心开发语言,生态丰富,能快速对接各类AI工具和数据处理库;
- LangGraph:替代传统的线性RAG流程,支持节点定义、条件边编排,能轻松实现“决策-检索-校验-生成”的多步推理流程;
- LangChain:作为LangGraph的补充,提供现成的工具封装,比如SerperAPI的调用接口;
- Chroma DB:轻量级的向量数据库,无需复杂部署,支持快速创建集合、存储文本嵌入,适合医疗问答和设备手册这类结构化程度中等的数据集;
- SerperAPI:对接Google搜索的API,免费套餐提供2500次调用,能快速补充本地知识库未覆盖的最新医疗信息;
- OpenAI API:选用gpt-5-nano模型完成决策、校验和答案生成,轻量化模型能降低实验成本,实际落地时可替换为gpt-5-mini或gpt-5提升效果。
实验中我们选用了两个医疗相关的CSV数据集(均采样至500行,兼顾实验效率和数据多样性):
一是医疗问答数据集,包含疾病症状、治疗方案等问答内容,我们将每行数据合并为“Question: … Answer: … Type: …”的格式,方便向量检索;
二是医疗设备手册数据集,涵盖设备名称、型号、适用场景、禁忌症等信息,合并为“Device Name: … Model: … Manufacturer: … Indications: … Contraindications: …”的格式,适配设备相关问题的检索需求。
三、从零搭建基础环境:数据处理与向量库构建
在编写核心的RAG逻辑前,需要先完成数据预处理和工具配置,这是整个系统的基础。
1. 数据加载与预处理
首先读取并处理两个医疗数据集,采样500行以简化实验,同时构建适合向量检索的文本格式:
import pandas as pd
import os
from dotenv import load_dotenv
# 加载环境变量(后续API调用需要)
load_dotenv()
# 处理医疗问答数据集
df_qa = pd.read_csv("medical_q_n_a.csv")
df_qa = df_qa.sample(500, random_state=0).reset_index(drop=True)
df_qa['combined_text'] = (
"Question: " + df_qa['Question'].astype(str) + ". " +
"Answer: " + df_qa['Answer'].astype(str) + ". " +
"Type: " + df_qa['qtype'].astype(str) + ". "
)
# 处理医疗设备手册数据集
df_medical_device = pd.read_csv("medical_device_manuals_dataset.csv")
df_medical_device = df_medical_device.sample(500, random_state=0).reset_index(drop=True)
df_medical_device['combined_text'] = (
"Device Name: " + df_medical_device['Device_Name'].astype(str) + ". " +
"Model: " + df_medical_device['Model_Number'].astype(str) + ". " +
"Manufacturer: " + df_medical_device['Manufacturer'].astype(str) + ". " +
"Indications: " + df_medical_device['Indications_for_Use'].astype(str) + ". " +
"Contraindications: " + df_medical_device['Contraindications'].fillna('None').astype(str)
)
这样的文本格式能让向量模型更好地理解上下文,检索时也能更精准地匹配用户问题。
2. 搭建ChromaDB向量库
ChromaDB的优势在于无需提前部署,直接创建本地持久化客户端即可。我们为两个数据集分别创建集合,相当于在数据库中建立两个“表”,分别存储医疗问答和设备手册的嵌入数据:
import chromadb
# 创建ChromaDB持久化客户端
client = chromadb.PersistentClient(path="./chroma_db")
# 创建医疗问答集合并添加数据
collection1 = client.get_or_create_collection(name="medical_q_n_a")
collection1.add(
documents=df_qa['combined_text'].tolist(),
metadatas=df_qa.to_dict(orient="records"),
ids=df_qa.index.astype(str).tolist(),
)
# 创建医疗设备手册集合并添加数据
collection2 = client.get_or_create_collection(name="medical_device_manual")
collection2.add(
documents=df_medical_device['combined_text'].tolist(),
metadatas=df_medical_device.to_dict(orient="records"),
ids=df_medical_device.index.astype(str).tolist(),
)
添加完成后,我们可以简单测试检索效果:比如查询“川崎病的治疗方案”,能从医疗问答集合中检索到相关的问答内容;查询“适用于新生儿的医疗设备”,能从设备手册集合中返回起搏器、输液泵等相关信息,说明向量库搭建有效。
3. 对接外部工具:SerperAPI与OpenAI API
接下来配置网页搜索和大模型接口,这是智能体RAG能处理超纲问题的关键:
# 配置SerperAPI网页搜索
from langchain_community.utilities import GoogleSerperAPIWrapper
SERPER_API_KEY = os.getenv("SERPER_API_KEY")
search = GoogleSerperAPIWrapper()
# 测试搜索效果
test_search = search.run("2025年新冠治疗药物有哪些")
print(test_search)
# 配置OpenAI API
from openai import OpenAI
openai_api_key = os.getenv("OPEN_AI_KEY")
client_llm = OpenAI(api_key=openai_api_key)
def get_llm_response(prompt: str) -> str:
"""调用LLM生成回答的通用函数"""
response = client_llm.chat.completions.create(
model="gpt-5-nano",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
# 测试LLM响应
test_prompt = "用30个字简单解释相对论"
test_response = get_llm_response(test_prompt)
print(test_response)
配置完成后,网页搜索能返回最新的医疗信息,LLM能根据提示词生成简洁、准确的回答,为后续搭建智能体RAG做好准备。
四、传统RAG的实现:固定流程的局限
在搭建智能体RAG前,我们先实现一套传统RAG,直观感受其局限性。传统RAG的流程是固定的“检索-构建提示词-生成”,我们用LangGraph的StateGraph定义这三个节点:
1. 定义传统RAG的工作流
from typing import List
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
# 定义状态结构
class GraphState(TypedDict):
query : str
prompt : str
context : List[str]
response : str
# 定义节点函数
def retrieve_context(state):
"""从医疗问答集合检索上下文"""
query = state["query"]
results = collection1.query(query_texts=[query], n_results=3)
context = "\n".join(results["documents"][0])
state["context"] = context
return state
def build_prompt(state):
"""构建RAG提示词"""
query = state["query"]
context = state["context"]
prompt = f"""
根据以下上下文回答问题,答案控制在50字以内。
上下文:
{context}
问题:{query}
"""
state["prompt"] = prompt
return state
def call_llm(state):
"""调用LLM生成答案"""
prompt = state["prompt"]
answer = get_llm_response(prompt)
state["response"] = answer
return state
# 构建并编译工作流
workflow = StateGraph(GraphState)
workflow.add_node("Retriever", retrieve_context)
workflow.add_node("Augment", build_prompt)
workflow.add_node("Generate", call_llm)
# 定义固定边
workflow.add_edge(START, "Retriever")
workflow.add_edge("Retriever", "Augment")
workflow.add_edge("Augment", "Generate")
workflow.add_edge("Generate", END)
rag_agent = workflow.compile()
2. 测试传统RAG的效果
我们用“川崎病的治疗方案”测试,传统RAG能从医疗问答集合中检索到相关内容,生成的答案也符合要求;但如果问“2025年印度医疗片剂出口美国的关税是多少”这类超纲问题,传统RAG仍会从医疗问答集合中检索无关内容,生成的答案完全错误。这印证了传统RAG的核心问题:检索源固定,无法根据问题类型调整,也无法验证信息相关性。
五、智能体RAG的核心升级:多步推理与动态决策
智能体RAG的核心是给系统增加“决策”和“校验”能力,流程升级为“查询-路由器(选择数据源)-检索-相关性检查-生成(或网页搜索重试)”。我们依然用LangGraph实现,但增加了条件边和重试机制,让工作流能动态调整。
1. 定义智能体RAG的核心节点
首先定义智能体RAG的关键节点,包括路由器、多源检索、相关性校验、提示词构建和生成:
from typing import Literal
# 定义状态结构(新增源、相关性、迭代次数)
class GraphState(TypedDict):
query: str
context: str
prompt: str
response: str
source: str # 记录使用的检索源
is_relevant: str # 上下文是否相关
iteration_count: int # 迭代次数,限制最大重试
# 1. 多源检索节点
def retrieve_context_q_n_a(state):
"""从医疗问答集合检索"""
query = state["query"]
results = collection1.query(query_texts=[query], n_results=3)
context = "\n".join(results["documents"][0])
state["context"] = context
state["source"] = "Medical Q&A Collection"
return state
def retrieve_context_medical_device(state):
"""从医疗设备手册集合检索"""
query = state["query"]
results = collection2.query(query_texts=[query], n_results=3)
context = "\n".join(results["documents"][0])
state["context"] = context
state["source"] = "Medical Device Manual"
return state
def web_search(state):
"""网页搜索补充信息"""
query = state["query"]
search_results = search.run(query=query)
state["context"] = search_results
state["source"] = "Web Search"
return state
# 2. 路由器节点:决策检索源
def router(state: GraphState) -> Literal["Retrieve_QnA", "Retrieve_Device", "Web_Search"]:
"""根据问题类型选择检索源"""
query = state["query"]
decision_prompt = f"""
你是路由智能体,根据用户问题选择检索源:
- Retrieve_QnA:通用医疗知识、症状、治疗相关问题
- Retrieve_Device:医疗设备、手册、使用说明相关问题
- Web_Search:最新新闻、政策、外部数据相关问题
问题:"{query}"
仅返回Retrieve_QnA、Retrieve_Device、Web_Search其中一个
"""
router_decision = get_llm_response(decision_prompt).strip()
state["source"] = router_decision
return router_decision
# 3. 相关性校验节点:判断上下文是否相关
def check_context_relevance(state):
"""校验检索到的上下文是否与问题相关"""
query = state["query"]
context = state["context"]
relevance_prompt = f"""
检查以下上下文是否与用户问题相关,仅回答Yes或No。
上下文:
{context}
用户问题:{query}
"""
relevance_decision = get_llm_response(relevance_prompt).strip()
state["is_relevant"] = relevance_decision
return state
# 4. 提示词构建和生成节点(与传统RAG类似)
def build_prompt(state):
query = state["query"]
context = state["context"]
prompt = f"""
根据以下上下文回答问题,答案控制在50字以内。
上下文:
{context}
问题:{query}
"""
state["prompt"] = prompt
return state
def call_llm(state):
prompt = state["prompt"]
answer = get_llm_response(prompt)
state["response"] = answer
return state
# 5. 条件路由函数:处理相关性决策和重试
def route_decision(state: GraphState) -> str:
"""路由器的条件边函数"""
return state["source"]
def relevance_decision(state: GraphState) -> str:
"""相关性校验的条件边函数,限制最多3次迭代"""
iteration_count = state.get("iteration_count", 0)
iteration_count += 1
state["iteration_count"] = iteration_count
if iteration_count >= 3:
state["is_relevant"] = "Yes" # 达到最大迭代,强制生成
return state["is_relevant"]
2. 编译智能体RAG工作流
接下来定义节点间的边,重点是条件边的配置,实现“决策-检索-校验-重试”的动态流程:
# 构建工作流
workflow = StateGraph(GraphState)
# 添加节点
workflow.add_node("Router", router)
workflow.add_node("Retrieve_QnA", retrieve_context_q_n_a)
workflow.add_node("Retrieve_Device", retrieve_context_medical_device)
workflow.add_node("Web_Search", web_search)
workflow.add_node("Relevance_Checker", check_context_relevance)
workflow.add_node("Augment", build_prompt)
workflow.add_node("Generate", call_llm)
# 定义边:START→路由器
workflow.add_edge(START, "Router")
# 路由器的条件边:根据决策选择检索源
workflow.add_conditional_edges(
"Router",
route_decision,
{
"Retrieve_QnA": "Retrieve_QnA",
"Retrieve_Device": "Retrieve_Device",
"Web_Search": "Web_Search",
}
)
# 所有检索源都指向相关性校验
workflow.add_edge("Retrieve_QnA", "Relevance_Checker")
workflow.add_edge("Retrieve_Device", "Relevance_Checker")
workflow.add_edge("Web_Search", "Relevance_Checker")
# 相关性校验的条件边:相关则生成,不相关则网页搜索重试
workflow.add_conditional_edges(
"Relevance_Checker",
relevance_decision,
{
"Yes": "Augment",
"No": "Web_Search",
}
)
# 提示词构建→生成→结束
workflow.add_edge("Augment", "Generate")
workflow.add_edge("Generate", END)
# 编译智能体RAG
agentic_rag = workflow.compile()
3. 多场景测试验证智能体RAG的效果
我们用四个典型场景测试智能体RAG,验证其多步推理能力:
场景1:常规医疗问答(川崎病治疗)
路由器决策选择“Retrieve_QnA”,从医疗问答集合检索到相关内容,相关性校验为“Yes”,直接生成准确答案,效果与传统RAG一致,但流程更规范。
场景2:医疗设备查询(透析机的用途)
路由器决策选择“Retrieve_Device”,从设备手册集合检索到透析机的型号、用途、禁忌症等信息,相关性校验通过,生成的答案精准匹配设备场景。
场景3:超纲政策问题(2025年印度医疗片剂出口美国关税)
路由器直接决策“Web_Search”,通过SerperAPI检索到2025年美国对印度药品征收100%关税的信息,相关性校验通过,生成的答案符合事实。
场景4:陷阱问题(新冠治疗药物)
路由器先决策“Retrieve_QnA”,但医疗问答集合中无新冠相关内容,相关性校验为“No”,系统自动切换到“Web_Search”,检索到最新的新冠治疗药物(Paxlovid、Remdesivir等),最终生成准确答案。
这四个场景的测试结果表明,智能体RAG能根据问题类型动态选择检索源,验证信息相关性,甚至在检索结果不理想时重试,完美解决了传统RAG的核心痛点。
六、智能体RAG的价值与落地思考
从传统RAG升级到智能体RAG,看似只是增加了几个节点和条件边,但本质上是让RAG系统从“机械执行”变成了“主动思考”。在医疗这个高风险领域,这种升级带来的价值是显著的:
首先,精准度大幅提升。通过路由决策和相关性校验,系统能避免使用无关上下文生成答案,减少幻觉,这对医疗问答至关重要;其次,适配性更强。既能处理本地知识库中的常规问题,也能通过网页搜索覆盖最新医疗信息、政策等超纲内容;最后,轻量化实现降低落地成本。我们选用的都是轻量级工具,无需复杂的基础设施,中小企业或医疗机构也能快速部署。
当然,这套智能体RAG还有优化空间:比如路由策略可以更精准,结合医疗领域的关键词词典,减少LLM决策的误差;可以增加多轮对话能力,支持用户追问;可以接入更多医疗数据源,比如最新的临床指南、药品说明书等。但即便如此,这套轻量化的智能体RAG已经能满足大部分医疗问答场景的需求,是传统RAG向更智能、更可靠方向演进的重要一步。
结语
RAG的核心价值是让AI的回答有事实依据,而智能体RAG则是在这个基础上,赋予系统推理和决策的能力。本文结合医疗场景,用LangGraph搭建了一套具备多步推理能力的智能体RAG系统,从数据处理、向量库搭建,到传统RAG实现,再到智能体RAG的升级,完整展示了整个流程。
这套思路不仅适用于医疗领域,也能迁移到金融、法律等对精准性要求高的领域。关键在于抓住智能体RAG的核心:不是堆砌复杂的技术,而是给RAG增加“判断”和“校验”的环节,让系统能根据问题动态调整策略。未来,随着大模型和工作流工具的不断发展,智能体RAG会成为RAG的主流形态,让AI在更多高风险、高要求的场景中发挥价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)