【必藏】万字长文:一文搞懂Agent开发核心链路,小白也能快速上手!
在人工智能领域,Agent并非一个全新的概念,但在大模型时代,它被赋予了全新的生命力。简单来说,Agent是一个能够自主感知环境、理解任务、制定计划、调用工具并完成目标的智能实体。它不仅仅是与你对话的聊天机器人,更是能够代理你完成复杂工作的"数字员工"。
本文系统介绍了Agent的概念、四大核心能力及开发核心链路,包括规划模块、记忆系统和工具调用机制。详细阐述了上下文工程在Agent开发中的关键作用,并结合腾讯Dola案例展示了Agent的商业价值。最后为AI产品经理提供了从"对话"到"任务"的思维转变、建立信任机制和多Agent协作等思考方向,是Agent开发者的实用指南。
一、回归本源:到底什么是Agent?
在人工智能领域,Agent 并非一个全新的概念,但在大模型时代,它被赋予了全新的生命力。简单来说,Agent是一个能够自主感知环境、理解任务、制定计划、调用工具并完成目标的智能实体。它不仅仅是与你对话的聊天机器人,更是能够代理你完成复杂工作的"数字员工"。
想象一下,当你对一个Agent说"帮我分析一下上个季度的销售数据,找出增长最快的三个产品类别,并预测下个季度的趋势",它不会只是回复你"好的,我来帮你分析",而是会真正地去连接你的数据库、执行SQL查询、运行Python代码进行数据处理、生成可视化图表,最后给你一份完整的分析报告。这就是Agent的魅力所在——从理解到执行的闭环能力。
Agent的四大核心能力
一个成熟的Agent系统通常具备以下四大核心能力,它们共同构成了Agent的"智能循环":
1. 环境感知(Perception)
Agent需要能够通过多种"感官"获取信息。这些"感官"可能是文本输入、语音识别、图像理解,甚至是传感器数据。在企业级应用中,环境感知更多体现为对业务系统状态的实时监控和数据获取能力。
2. 智能决策(Reasoning)
这是Agent的"大脑",通常由大语言模型(如GPT-4、Claude 3.5、通义千问等)担当。它负责理解用户意图、分析当前情境、进行逻辑推理,并制定出合理的行动方案。决策能力的强弱直接决定了Agent的"智商"上限。
3. 任务执行(Action)
光有想法不够,还得能干活。Agent通过调用各种工具(API、数据库、代码执行环境等)来与外部世界交互,完成实际的操作任务。这是Agent从"空谈"到"实干"的关键一步。
4. 持续学习(Learning)
优秀的Agent不仅能完成任务,还能从每一次执行中学习经验,不断优化自己的决策和行动策略。这种能力让Agent能够适应动态变化的环境,实现真正的"智能进化"。
二、核心链路拆解:Agent的"大脑"与"四肢"
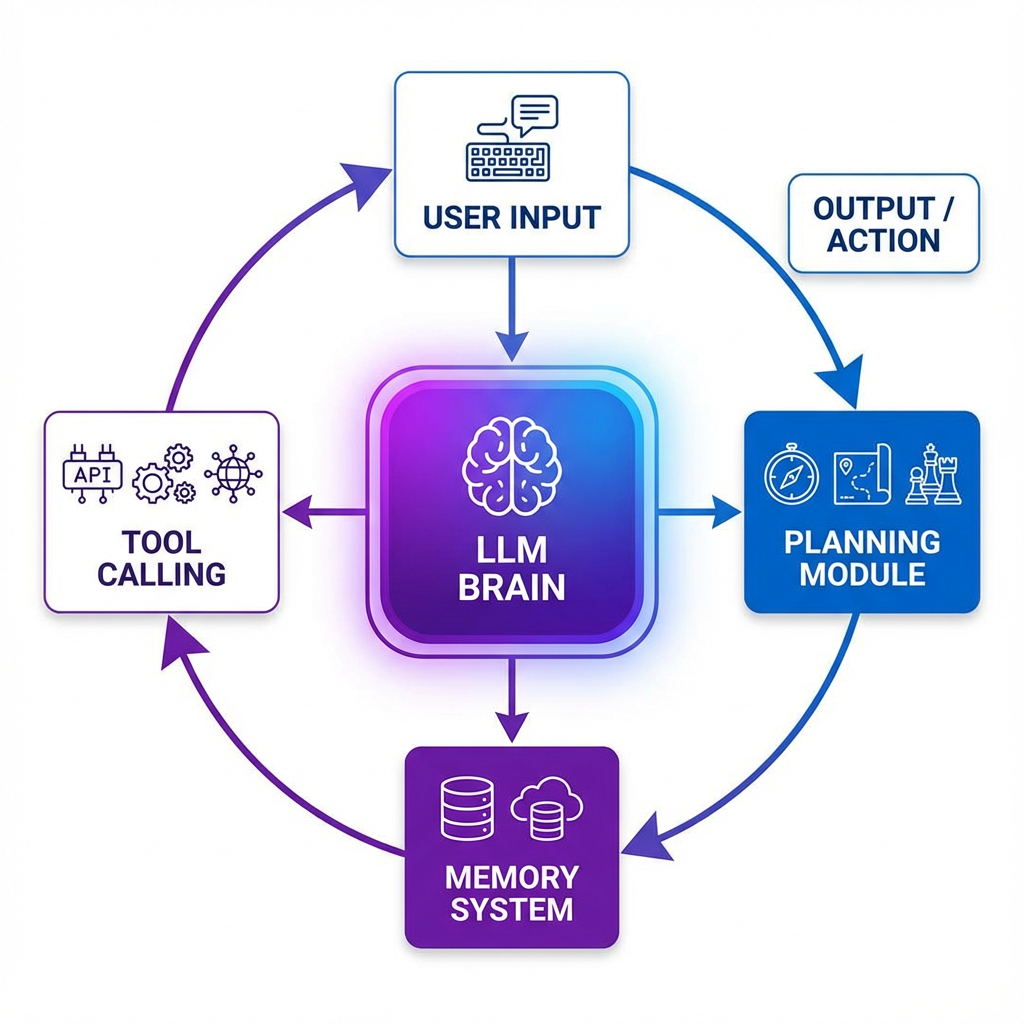
了解了Agent的基本概念,我们再深入到技术架构的"引擎室",看看每个关键模块是如何运转和协同的。一个完整的Agent系统可以抽象为 AI Agent = 大脑(LLM)+ 规划 + 记忆 + 工具使用 这样一个公式。
1. 规划模块:让Agent"想清楚再干"
在面对复杂任务时,一个没有规划能力的Agent就像无头苍蝇,可能会陷入低效的试错循环。规划能力赋予了Agent"谋定而后动"的智慧,让它能够将大目标分解为可执行的小步骤,并在执行过程中根据反馈动态调整策略。
目前业界最主流的规划思想之一是 ReAct (Reasoning + Acting) 框架。ReAct的核心思想是指导Agent通过 “思考 → 行动 → 观察” 的循环来完成任务:
- 思考(Thought):分析当前任务状态和已有信息,推理出下一步应该采取什么行动。
- 行动(Action):根据思考结果,选择并调用一个具体的工具或执行一个操作。
- 观察(Observation):查看工具执行返回的结果,将这些新信息纳入上下文,为下一轮"思考"提供依据。
- 循环迭代:重复上述过程,直到任务完成或达到终止条件。
这个过程极大地提升了Agent在复杂、动态环境中的问题解决能力,也让Agent的决策过程更加透明和可解释。
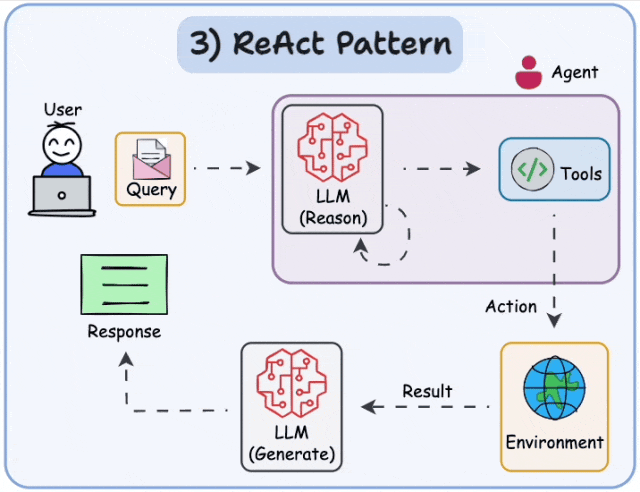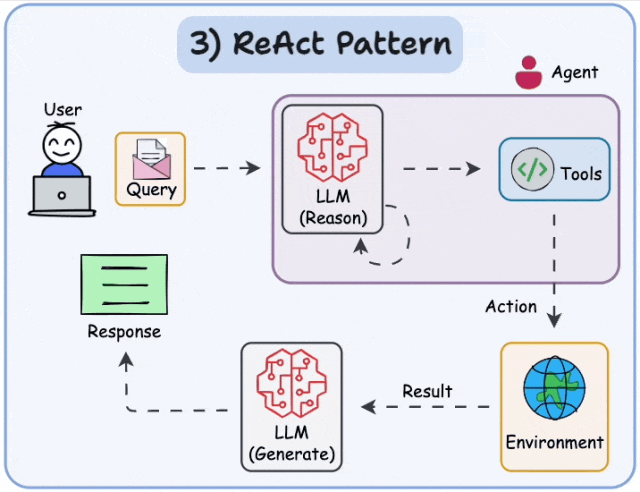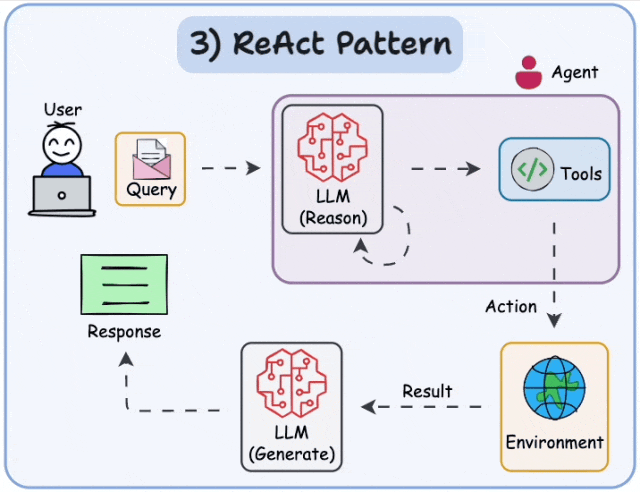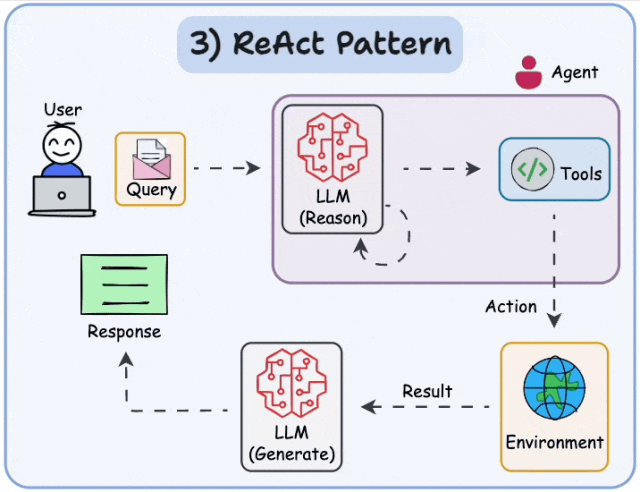
规划模式的实现方式
在实际开发中,规划能力可以通过两种主要方式实现:
| 实现方式 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 模型微调 | 高度适配特定业务场景,响应速度快 | 缺乏灵活性,难以快速扩展到新场景 | 垂直领域的专业Agent |
| 上下文工程(Prompt Engineering) | 灵活性强,可快速迭代和扩展 | 对提示词设计要求高,可能消耗更多tokens | 通用型Agent,需要快速适应多场景 |
在实践中,我们发现上下文工程配合少量示例(Few-shot Learning) 是一个性价比较高的方案,既保证了灵活性,又能在大多数场景下达到不错的效果。
2. 记忆模块:赋予Agent"过目不忘"的能力
大模型的上下文窗口是有限的(即使是最新的长上下文模型,也有其物理极限),这导致了它在长对话或复杂任务中容易"失忆"。为了构建一个能与用户建立长期关系、积累经验的Agent,一个分层的记忆系统至关重要。
三层记忆架构
借鉴人类记忆的认知模型,我们可以将Agent的记忆系统分为三个层次:
短期记忆(Short-Term Memory, STM)
短期记忆存储当前对话或任务的即时信息,通常直接放在模型的上下文窗口中。它的特点是容量有限(受限于模型的最大token数),但访问速度极快。短期记忆就像人类的"工作记忆",用于处理眼前正在进行的任务。
中期记忆(Mid-Term Memory, MTM)
当短期记忆即将溢出时,Agent需要对历史信息进行总结和提炼,形成关键信息摘要。中期记忆通过分段分页策略组织信息,并基于热度算法(访问频率、时间衰减等)动态更新。这就像人类会对一段时间内的经历进行归纳总结,保留核心要点。
长期记忆(Long-Term Memory, LTM)
长期记忆负责持久化存储用户的核心信息,如用户偏好、身份特征、历史互动中的关键知识等。在技术实现上,长期记忆通常通过向量数据库(如Pinecone、Weaviate)或知识图谱来存储,并通过RAG(检索增强生成)技术在需要时召回相关信息。
记忆管理策略
在实际开发中,记忆管理是一个需要精细设计的环节。以下是几种常见的记忆管理策略:
# 记忆管理伪代码示例
class MemoryManager:
def __init__(self, max_short_term_tokens=4000):
self.short_term = [] # 短期记忆队列
self.mid_term = [] # 中期记忆摘要
self.long_term_db = VectorDatabase() # 长期记忆向量库
self.max_tokens = max_short_term_tokens
def add_interaction(self, user_input, agent_response):
"""添加新的交互到记忆系统"""
interaction = {"user": user_input, "agent": agent_response}
self.short_term.append(interaction)
# 如果短期记忆超出阈值,触发压缩
if self.count_tokens(self.short_term) > self.max_tokens:
self.compress_to_mid_term()
def compress_to_mid_term(self):
"""将短期记忆压缩为中期记忆摘要"""
# 调用LLM对最早的一批对话进行摘要
summary = self.llm.summarize(self.short_term[:5])
self.mid_term.append(summary)
self.short_term = self.short_term[5:] # 移除已摘要的部分
def retrieve_relevant_memory(self, query):
"""根据当前查询检索相关的长期记忆"""
relevant_memories = self.long_term_db.similarity_search(query, top_k=3)
return relevant_memories
3. 工具调用:Agent连接现实世界的桥梁
如果说LLM是Agent的"大脑",那么工具就是Agent的"手"。工具调用(Function Calling)是Agent能力的无限延伸,它允许LLM将自然语言指令转化为对外部API或函数的结构化调用。无论是查询最新的天气、预订一张机票,还是执行一段Python代码进行数据分析,都离不开工具调用。
Function Calling的工作原理
Function Calling的核心流程可以概括为以下几个步骤:
- 工具注册:开发者预先定义好一系列工具(函数),每个工具都有明确的名称、描述和参数定义。
- 意图识别:用户提出需求后,LLM分析意图,判断是否需要调用工具。
- 参数生成:如果需要调用工具,LLM会根据用户输入生成符合工具参数规范的结构化数据。
- 工具执行:系统根据LLM返回的指令,实际调用对应的工具函数。
- 结果整合:将工具执行的结果返回给LLM,由LLM将其转化为自然语言响应给用户。
下面是一个简单的Python代码示例,展示了如何为模型定义一个"获取天气"的工具:
from openai import OpenAI
import json
# 初始化OpenAI客户端
client = OpenAI(api_key="your-api-key")
# 定义工具(函数)
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取指定城市的当前天气信息",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如:北京、上海",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位,celsius表示摄氏度,fahrenheit表示华氏度"
},
},
"required": ["location"],
},
},
}
]
# 用户输入
messages = [
{"role": "user", "content": "北京今天天气怎么样?"}
]
# 第一次调用:让模型决定是否需要调用工具
response = client.chat.completions.create(
model="gpt-4",
messages=messages,
tools=tools,
tool_choice="auto" # 让模型自动决定是否调用工具
)
# 检查模型是否要调用工具
if response.choices[0].message.tool_calls:
tool_call = response.choices[0].message.tool_calls[0]
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# 实际执行工具(这里简化为模拟返回)
if function_name == "get_current_weather":
weather_data = {
"location": function_args["location"],
"temperature": "22",
"unit": function_args.get("unit", "celsius"),
"condition": "晴朗"
}
# 将工具执行结果返回给模型
messages.append(response.choices[0].message)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(weather_data)
})
# 第二次调用:让模型基于工具结果生成最终回复
final_response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
print(final_response.choices[0].message.content)
# 输出示例:"北京今天天气晴朗,气温22摄氏度。"
工具设计的最佳实践
作为产品经理,在设计Agent的工具体系时,需要重点关注以下几个方面:
- 工具的原子性:每个工具的功能应该尽量单一、明确,避免一个工具承担过多职责。例如,"获取天气"和"预测未来天气"应该是两个独立的工具。
- 清晰的描述:工具的名称和参数描述必须清晰、无歧义,以便LLM能正确理解和使用。描述应该包含足够的上下文信息和使用示例。
- 完备的异常处理:需要为工具调用失败(如网络错误、API返回异常、参数不合法等)设计兜底逻辑,确保Agent不会因为单个工具失败而整体崩溃。
- 权限与安全:对于涉及敏感操作的工具(如支付、删除数据等),必须设计严格的权限校验和用户确认机制。
4. MCP协议:工具管理的新标准
在Agent开发的演进过程中,工具管理一直是一个痛点。不同的应用系统有各自的工具定义方式,导致工具难以复用和共享。MCP(Model Context Protocol) 协议的出现,为这个问题提供了一个标准化的解决方案。
MCP协议由Anthropic提出,旨在为AI应用提供一个统一的工具和资源访问接口。它定义了清晰的客户端-服务器架构,让工具的开发和集成变得更加规范和高效。

MCP的核心组件
- MCP主机(Host):发起请求的应用程序(如AI编程助手、IDE插件)
- MCP客户端(Client):与服务器保持1:1连接的通信模块
- MCP服务器(Server):运行于本地或远程的轻量级程序,负责访问数据或执行工具
- 资源层:包括本地文件、数据库和远程服务(如云平台API)
MCP的优势与挑战
| 维度 | 优势 | 挑战 |
|---|---|---|
| 标准化 | 统一接口降低开发复杂度,工具可跨应用复用 | 需要学习新的协议规范 |
| 扩展性 | 可随时增减工具,无需修改主应用代码 | 多了一层服务交互,增加了系统复杂度 |
| 生态 | 快速接入社区开发的优质工具 | 需要仔细评估第三方工具的安全性和稳定性 |
| 性能 | 工具独立部署,便于横向扩展 | 缺乏连接池,高并发场景下可能存在性能瓶颈 |
在实际项目中,我们发现MCP协议在快速原型开发和工具生态建设方面确实有其价值,但也不是银弹。如果你的Agent应用不需要频繁接入外部工具,或者团队有能力自建一套工具管理体系,那么直接使用Function Calling可能是更轻量的选择。
三、上下文工程:Agent效果的"隐形杠杆"
如果说架构设计决定了Agent的"能力上限",那么上下文工程(Context Engineering)就决定了Agent的"实际表现"。上下文工程不仅仅是写几个Prompt那么简单,它涉及到如何高效地组织信息、管理记忆、约束行为,以及如何让Agent在有限的上下文窗口内发挥最大效能。
以下是一些在实战中总结出的上下文工程核心要点:
1. 围绕KV-Cache优化设计
大模型在推理时会使用KV-Cache来缓存已计算的键值对,以加速后续token的生成。如果我们能让上下文的前半部分保持稳定,就能最大化地利用缓存,显著降低延迟和成本。
优化策略:
- 稳定提示前缀:避免在系统提示词中加入动态内容(如秒级时间戳),保持前缀的稳定性。
- 追加式上下文:禁止修改历史动作和观察记录,确保序列化的确定性。
- 显式缓存断点:对于支持缓存控制的模型(如Claude),可以手动标记缓存断点位置。
2. 动态约束行为选择
当Agent拥有几十个甚至上百个工具时,如果每次都把所有工具信息塞进上下文,不仅浪费tokens,还会让模型"选择困难"。更好的做法是根据当前任务状态,动态地约束Agent的行为选择范围。
实现方法:
- Logits掩码:通过屏蔽非法动作的token(如在浏览器未打开时屏蔽所有
browser_*前缀的工具),从根本上约束模型的选择。 - 状态机管理:根据上下文预填充响应模式(Auto/Required/Specified),不修改工具定义本身。
3. 文件系统作为扩展上下文
即使是128K的上下文窗口,在处理大规模数据或长文档时仍然不够用。一个创新的思路是**将文件系统作为Agent的"外部记忆"**。
设计理念:
- 外化存储:将大段的文本、数据、代码等内容保存到文件中,在上下文中只保留文件路径的引用。
- 可逆压缩:内容可以随时通过读取文件还原,避免信息丢失。
- 按需加载:只在需要时读取文件内容,避免上下文污染。
4. 注意力操控:复述目标
大模型的注意力机制对上下文末尾的信息更加敏感。利用这一特性,我们可以通过"复述目标"的方式来强化Agent对长期目标的记忆。
**实践案例:**一些先进的Agent系统(如Manus)会创建一个todo.md文件,并在任务执行过程中动态更新,勾选已完成的项目。这种做法本质上是将长期目标"背诵"到上下文末尾,强化模型的近期注意力。
5. 保留错误以促进学习
很多开发者在Agent出错时会选择"掩盖"错误(如自动重试、重置状态),但这实际上剥夺了Agent的学习机会。一个更好的做法是保留错误动作及环境反馈,让Agent能够从失败中学习。
关键实践:
- 失败即证据:将错误信息作为新的观察结果纳入上下文。
- 智能体标志:错误恢复能力是真实智能行为的核心指标。
四、落地为王:从腾讯Dola看Agent的商业价值
理论讲了这么多,Agent在真实世界中的应用效果如何?让我们通过一个具体的案例来感受Agent的商业价值。
案例:腾讯Dola——全自动的AI数据分析师
腾讯PCG大数据平台部推出的新一代数据分析AI助手 Dola,是一个基于Agentic AI能力开发的典型案例。Dola的设计目标是成为一个"全自动的AI数据分析师",让产品经理、运营同学无需编写一行代码,就能完成复杂的数据分析任务。

Dola的核心能力
- 自主规划分析路径
当用户提出一个分析需求(如"分析一下上个季度A产品的用户流失原因"),Dola会自动将这个复杂任务拆解为多个步骤:
- 理解业务背景和分析目标
- 确定需要的数据表和字段
- 设计分析框架(如漏斗分析、队列分析)
- 规划数据提取、清洗、处理、可视化的流程
- 自动编写和执行代码
Dola能够自行编写SQL从数据库中取数,调用Python库(如Pandas、Matplotlib)进行数据处理和可视化。整个过程完全自动化,用户只需等待结果。
# Dola自动生成的数据分析代码示例
import pandas as pd
import matplotlib.pyplot as plt
# 从数据库查询结果加载数据
df = pd.read_sql("""
SELECT
user_id,
product_category,
last_active_date,
churn_flag
FROM user_behavior
WHERE quarter = 'Q3_2024'
""", connection)
# 计算各产品类别的流失率
churn_rate = df.groupby('product_category')['churn_flag'].mean()
# 可视化
plt.figure(figsize=(10, 6))
churn_rate.plot(kind='bar', color='steelblue')
plt.title('各产品类别用户流失率对比')
plt.xlabel('产品类别')
plt.ylabel('流失率')
plt.savefig('churn_rate_analysis.png')
- 智能纠错与迭代
如果SQL执行出错(如字段名错误、表不存在等),Dola会根据错误信息自行修正并重试,而不是简单地把错误抛给用户。这种"自我修复"能力大大提升了用户体验。
- 生成完整分析报告
最终,Dola会将所有分析结果汇总,生成一份结构清晰、图文并茂的分析报告,包括:
- 执行摘要:核心发现和建议
- 数据概览:样本量、时间范围等基本信息
- 详细分析:各维度的深入分析和可视化图表
- 结论与建议:基于数据的业务洞察
商业价值分析
Dola的成功实践证明,Agent不仅能极大地提升专业人员的工作效率,更有潜力将复杂的数据分析能力"平民化"。过去需要数据分析师花费数小时甚至数天完成的工作,现在通过自然语言对话就能在几分钟内完成。这种效率提升带来的商业价值是显而易见的:
- 降低人力成本:减少对专业数据分析师的依赖
- 加快决策速度:从"周级"分析周期缩短到"分钟级"
- 民主化数据能力:让每一个业务同学都能从数据中获取洞察
- 提升分析质量:AI不会因为疲劳或情绪而降低工作质量
五、给AI产品经理的几点思考
Agent的浪潮已至,对于我们AI产品经理而言,这既是机遇也是挑战。在设计Agent产品时,我们或许需要从以下几个方面进行更深入的思考:
1. 从"对话"到"任务"的思维转变
传统的聊天机器人产品,核心价值在于"对话体验"——如何让它说得更自然、更有趣、更像人。但Agent产品的核心价值在于"完成任务"——如何让它做得更好、更快、更可靠。这要求我们的设计焦点从"对话流畅度"转向"任务完成率",从"回复质量"转向"执行效果"。
在产品设计中,我们需要更多地关注:
- 任务的可分解性和可验证性
- 工具的完备性和可靠性
- 错误处理和异常恢复机制
- 任务执行的可观测性和可控性
2. "上下文工程"是重中之重
如果说大模型是Agent的"发动机",那么上下文工程就是"燃油"。再强大的模型,如果喂给它的上下文信息混乱、冗余、不相关,也无法发挥出应有的能力。
上下文工程不仅仅是写Prompt,还涉及到:
- 如何高效地管理记忆(短期、中期、长期)
- 如何动态地组织工具信息
- 如何保留错误日志以供学习
- 如何利用文件系统扩展上下文容量
- 如何通过注意力操控强化关键信息
这些细节决定了Agent的"智商"和"情商",值得我们投入大量精力去打磨。
3. 建立信任是关键
用户需要多大的勇气,才会放心让一个AI去操作自己的数据库、执行支付操作、或者代表自己发送邮件?信任是Agent产品成功的基石,而建立信任需要从产品设计的每一个细节入手:
- 清晰的权限管理:明确告知用户Agent能做什么、不能做什么
- 关键操作的人工确认:对于高风险操作(如删除数据、支付),必须有人工确认环节
- 可追溯的执行日志:让用户能够随时查看Agent做了什么、为什么这么做
- 透明的决策过程:尽可能让Agent的推理过程可解释、可理解
- 可撤销的操作机制:为用户提供"后悔药",允许撤销或回滚
4. 多Agent协作的想象空间
当多个拥有不同专业技能的Agent(如"数据分析Agent"、“报告撰写Agent”、“市场洞察Agent”、“代码审查Agent”)协同工作时,它们能完成的将是远超单个Agent的复杂任务。
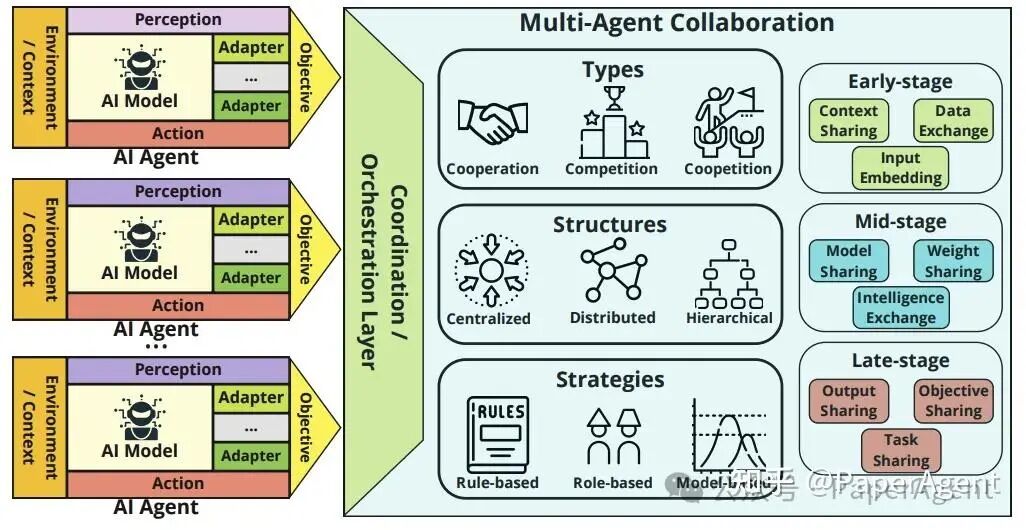
多Agent协作为我们设计企业级解决方案打开了全新的想象空间:
- 专业化分工:每个Agent专注于自己擅长的领域,提升整体效率
- 并行处理:多个Agent可以同时工作,大幅缩短任务完成时间
- 知识共享:Agent之间可以共享知识和经验,形成"集体智慧"
- 容错能力:单个Agent的失败不会导致整个系统崩溃
5. 持续迭代与用户反馈
Agent产品的开发不是一次性的,而是一个持续迭代的过程。在初期,Agent可能会犯很多错误,这是正常的。关键是要建立一个快速的反馈-迭代循环:
- 收集真实用户反馈:了解Agent在哪些场景下表现好,哪些场景下表现差
- 分析失败案例:深入研究Agent为什么会失败,是规划问题、工具问题还是上下文问题
- 快速迭代优化:基于反馈快速调整Prompt、工具定义、记忆策略等
- 建立评估体系:设计合理的指标来衡量Agent的表现(如任务完成率、用户满意度、执行效率等)
结语
Agent的时代已经拉开序幕。从Workflow到Agentic AI,从被动响应到主动执行,我们正在见证人工智能从"内容智能"向"行为智能"的跨越。对于AI产品经理来说,现在正是投身其中,理解其核心原理,并用它来创造真正解决用户问题的产品的最佳时机。
Agent不是未来,Agent就是现在。 让我们一起拥抱这个充满可能性的新时代,用Agent的力量去创造更多的价值!
限时免费!CSDN 大模型学习大礼包开放领取!
从入门到进阶,助你快速掌握核心技能!
资料目录
- AI大模型学习路线图
- 配套视频教程
- 大模型学习书籍
- AI大模型最新行业报告
- 大模型项目实战
- 面试题合集
👇👇扫码免费领取全部内容👇👇

📚 资源包核心内容一览:
1、 AI大模型学习路线图
- 成长路线图 & 学习规划: 科学系统的新手入门指南,避免走弯路,明确学习方向。

2、配套视频教程
- 根据学习路线配套的视频教程:涵盖核心知识板块,告别晦涩文字,快速理解重点难点。

课程精彩瞬间

3、大模型学习书籍

4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

6、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献248条内容
已为社区贡献248条内容

所有评论(0)