AI论文整理:Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Mode
Sora是OpenAI于2024年2月发布的文本到视频生成AI模型,核心基于扩散Transformer(Diffusion Transformer)技术,可根据文本指令生成最长1分钟的高质量视频,具备模拟物理世界的潜力;

1. 一段话总结
Sora 是OpenAI于2024年2月发布的文本到视频生成AI模型,核心基于扩散Transformer(Diffusion Transformer) 技术,可根据文本指令生成最长1分钟的高质量视频,具备模拟物理世界的潜力;文档结合公开技术报告与逆向工程,从其背景(生成式AI视觉领域发展历史、视觉模型缩放定律与涌现能力等先进概念)、核心技术(数据预处理、建模、语言指令遵循、提示工程、可信度保障)、多行业应用(电影、教育、游戏、医疗、机器人)、当前局限性(物理真实性不足、时空复杂度处理问题等)及未来机会(学术研究、行业创新、社会影响)展开全面综述,旨在为研究社区提供参考并推动视频自动创作的民主化与开源发展。

2. 思维导图(mindmap)
## **Sora综述(OpenAI 2024.2发布)**
### 一、背景
- 发展历史
- 深度学习前:纹理合成/映射(依赖手工特征)
- 早期深度学习:GANs(2014)、VAEs(2013)→ 流模型
- 中期发展:扩散模型(2019)→ Transformer融合(ViT 2020、Swin Transformer 2021)
- 近期突破:多模态生成(ChatGPT 2022→Stable Diffusion等T2I 2023→Sora T2V 2024)
- 先进概念
- 视觉模型缩放定律:ViT性能-计算遵循幂律,Google 22B参数ViT验证有效性
- 涌现能力:Sora首个具备该能力的视觉模型(3D一致性、物体持久性等)
### 二、核心技术
- 技术概述:扩散Transformer框架(时空压缩器→ViT处理器→CLIP-like条件机制)
- 数据预处理
- 可变时长/分辨率/宽高比(原生尺寸训练,支持1920x1080p至1080x1920p)
- 统一视觉表示:视频压缩→时空补丁分解(基于VAE/VQ-VAE)
- 视频压缩网络:空间补丁压缩(ViT/MAE思路)、时空补丁压缩(3D卷积)
- 时空Latent补丁:Patch n’ Pack(PNP)策略解决维度 variability
- 建模
- 图像扩散Transformer:DiT(AdaLN)、U-ViT(长跳连接)、MDT(掩码建模)、DiffiT(TMSA)
- 视频扩散Transformer:借鉴Imagen Video(级联扩散)、Video LDM(2D→3D扩展)
- 语言指令遵循:借鉴DALL-E 3,训练视频标题生成器→混合数据微调→GPT-4V提示扩展
- 提示工程:文本Prompt(细节描述)、图像Prompt(视觉锚点+动效)、视频Prompt(扩展/编辑/连接)
- 可信度:安全(防越狱攻击,检测分类器)、防滥用(降幻觉/偏见/隐私保护)、RLHF模型对齐
### 三、应用场景
- 电影:自动生成影片片段、竖屏短视频(MobileVidFactory)、vlog(Vlogger)
- 教育:文本课程→动态视频、静态资源→互动内容(科学模拟/历史场景)
- 游戏:实时生成动态环境、NPC动作、匹配音效
- 医疗:动态异常检测(细胞凋亡/皮肤病变)、医疗图像分割(MedSegDiffV2)
- 机器人:增强视觉感知、生成模拟训练场景、动作预测
### 四、局限性
- 物理真实性:复杂交互模拟偏差(如咬饼干无咬痕)、刚体变形不自然
- 时空复杂度:位置方向混淆、相机运动失准、复杂场景插入无关元素
- 人机交互:难精细修改视频元素、复杂指令语义理解不足
- 使用限制:未公开部署、最长仅1分钟视频
### 五、未来机会
- 学术:推动T2V扩散/Transformer融合、原生尺寸训练方法研究
- 行业:提升视频模拟真实度(游戏/广告)、降低创作门槛
- 社会:赋能社交媒体创作、辅助编剧/记者可视化创意
### 六、结论
- 价值:首篇全面综述,为研究社区提供参考
- 目标:推动开源版本开发,实现AIGC视频创作民主化
3. 详细总结
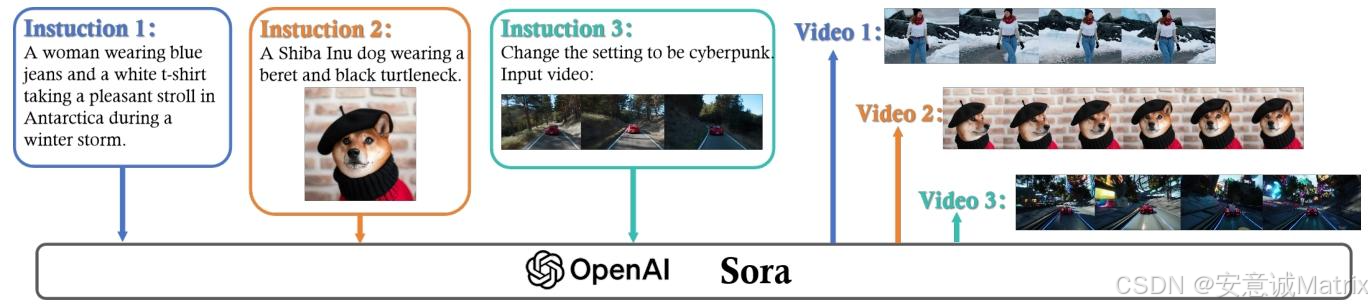
1. 引言:Sora的定位与核心价值
- 发布背景:继2022年11月ChatGPT引发AI交互变革后,OpenAI于2024年2月推出Sora,填补“文本到长视频生成”的技术空白,成为生成式AI视觉领域的里程碑。
- 核心能力:
- 时长突破:可生成最长1分钟的高质量视频,远超Pika(2023)、Gen-2(2023)等模型“仅几秒片段”的限制,且保持从首帧到末帧的视觉连贯性与文本指令一致性。
- 场景复杂度:能生成包含多角色、特定动作与精细背景的场景(如“东京霓虹街道上的时尚女性行走”),具备理解复杂人类指令的能力,被视为“世界模拟器”雏形。
- 研究意义:践行AI核心使命——让AI理解并交互物理世界,为人类-AI协作创作、生产力提升提供新范式。
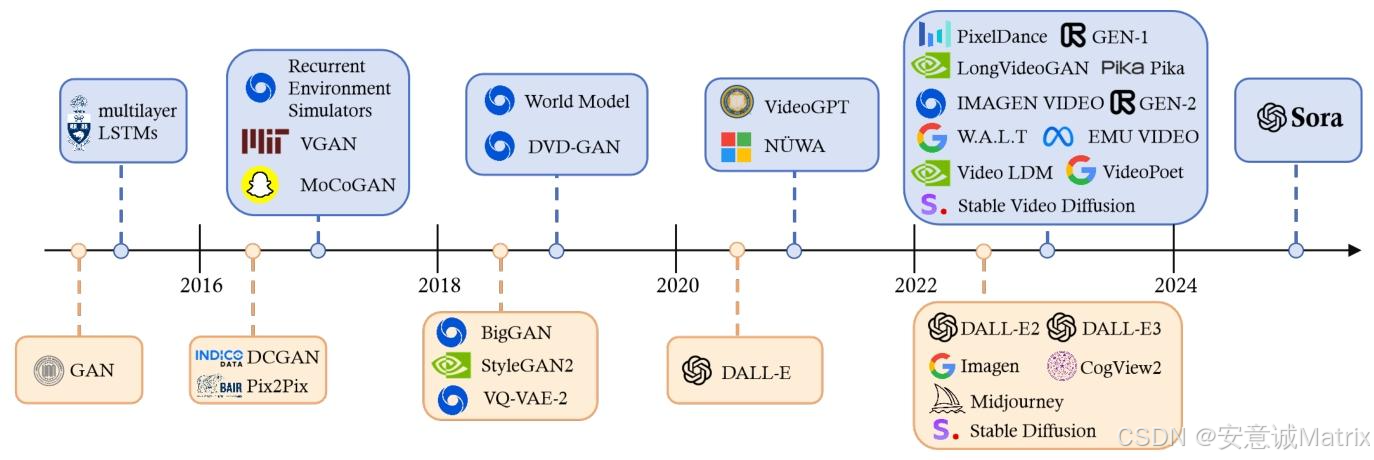
2. 背景:生成式AI视觉领域的发展脉络
2.1 发展历史(分阶段演进)
| 阶段 | 技术方法 | 关键成果 | 局限性 |
|---|---|---|---|
| 深度学习前 | 纹理合成、纹理映射 | - | 依赖手工特征,无法生成复杂、生动图像 |
| 早期深度学习(2013-2018) | GANs(2014)、VAEs(2013)、流模型(2014) | 首次实现端到端生成,拓展图像生成可能性 | 生成质量低、细节缺失,视频生成未起步 |
| 中期发展(2019-2021) | 扩散模型(2019)、Transformer+视觉(ViT 2020、Swin Transformer 2021) | 扩散模型提升生成细节;ViT实现图像Transformer化 | 多模态能力弱,视频生成仅支持短片段 |
| 近期突破(2022-2024) | 多模态生成(LLM+视觉) | ChatGPT(2022)、Stable Diffusion/Midjourney/DALL-E 3(2023,T2I)、Sora(2024,T2V) | 此前T2V模型时长受限,Sora突破至1分钟 |
2.2 先进概念(支撑Sora的核心理论)
- 视觉模型缩放定律:
- 规律:类似LLM,ViT模型在训练数据充足时,性能-计算前沿遵循(饱和)幂律(Zhai et al., 2022)。
- 验证:Google Research训练22B参数ViT模型,通过“冻结模型生成嵌入+训练浅层”实现高效性能,证明大视觉模型(LVM)的缩放价值,Sora作为LVM符合该规律。
- 涌现能力:
- 定义:模型在特定规模(参数/数据)下展现的、未显式编程的复杂行为,无法通过小模型性能外推预测。
- Sora的突破:首个被证实具备涌现能力的视觉模型,可实现3D一致性(动态相机运动)、物体持久性、简单物理交互模拟(如Minecraft环境)。
3. 核心技术:Sora的技术架构与实现细节
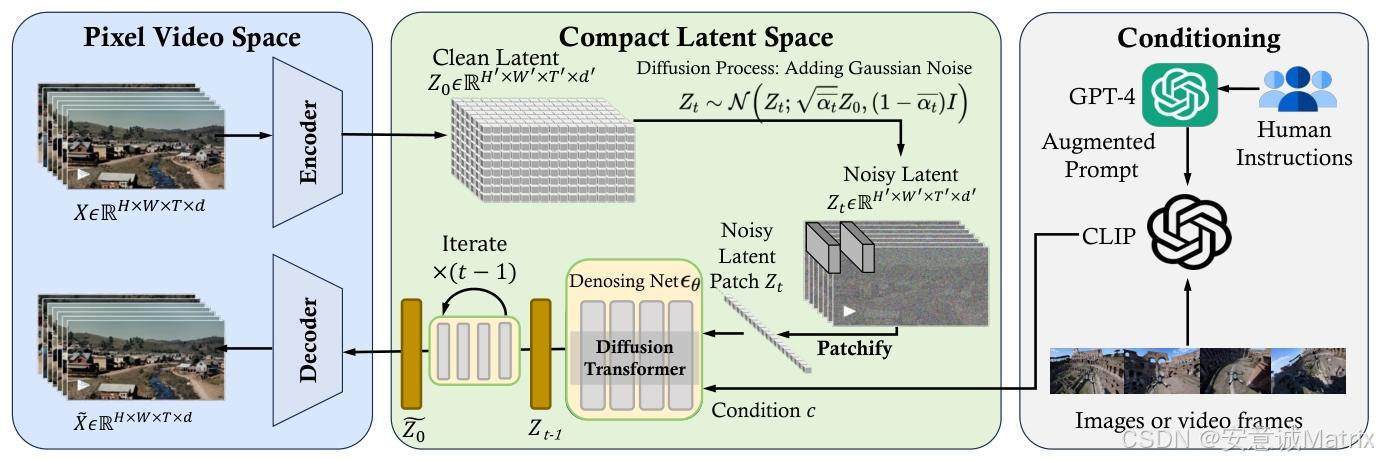
3.1 技术概述
Sora本质是扩散Transformer(Diffusion Transformer) 模型,核心框架分三步:
- 时空压缩器:将原始视频映射到低维latent空间,降低计算复杂度;
- ViT处理器:将latent表示token化后,通过Transformer处理并输出去噪后的latent表示;
- CLIP-like条件机制:结合GPT-4V增强的用户指令与视觉提示(图像/视频),引导扩散模型生成符合需求的视频,最终通过解码器映射回像素空间。
3.2 数据预处理:突破“统一尺寸”瓶颈
- 3.2.1 可变时长、分辨率与宽高比:
- 创新点:摒弃传统模型“裁剪/缩放至统一尺寸(如方形低分辨率)”的做法,支持原生尺寸训练/生成,覆盖1920x1080p(宽屏)至1080x1920p(竖屏)等格式。
- 优势:避免画面截断(如方形裁剪导致角色不完整),提升视觉叙事自然性,符合真实场景的格式多样性。
- 3.2.2 统一视觉表示:
- 流程:先通过视频压缩网络将视觉数据(图像/视频)转化为低维latent表示,再分解为时空补丁,实现“不同格式→统一token”的转化,支撑大规模训练。
- 技术基础:基于VAE或Vector Quantised-VAE(VQ-VAE),文档通过逆向工程推测其未依赖现有预训练编码器(如Stable Diffusion的VAE),而是自研时空压缩方案。
- 3.2.3 视频压缩网络:两种核心实现路径
压缩方式 原理 优势 挑战 空间补丁压缩 参考ViT/MAE,拆帧为固定尺寸补丁→编码为spatial token→按时间序列组织 适配可变分辨率,可复用预训练视觉编码器(如Stable Diffusion VAE) 需额外机制聚合时间信息,单独处理动态维度 时空补丁压缩 用3D卷积提取跨帧的时空tubelets(同时包含空间与时间信息)→编码为时空token 直接捕捉动态交互,无需额外时间聚合模块 固定卷积参数可能导致latent维度波动,需适配可变时长 - 3.2.4 时空Latent补丁:Patch n’ Pack(PNP)策略
- 问题:不同视频的latent补丁数量不同,无法直接输入Transformer(需固定序列长度)。
- 解决方案:借鉴NLP的示例打包思想,将多个视频的补丁打包成固定长度序列(贪心填充+令牌丢弃),推测OpenAI采用超长上下文窗口避免细节丢失,保障3D一致性。
3.3 建模:扩散Transformer的核心实现
3.3.1 图像扩散Transformer(奠定基础)
| 模型 | 核心创新 | 性能优势 |
|---|---|---|
| DiT(2023) | 用Transformer替代传统U-Net,结合自适应层归一化(AdaLN)与零初始化MLP | 稳定训练,支持更大参数与数据量,成为扩散模型新骨干 |
| U-ViT(2023) | 将时间、条件、噪声图像均视为token,引入长跳连接 | 无需CNN下采样/上采样,图像生成FID分数破纪录 |
| MDT(2023) | 融合掩码latent建模,训练时增加掩码token预测任务 | 学习上下文感知位置嵌入,性能与训练速度优于DiT |
| DiffiT(2023) | 用时间依赖自注意力(TMSA)替代AdaLN处理时间条件 | 在像素/ latent 空间均实现SOTA生成效果 |
3.3.2 视频扩散Transformer(适配时间维度)
- 关键挑战:处理视频的时间维度(压缩、补丁转换、长程时空依赖与一致性)。
- 核心借鉴方案:
- Imagen Video(Google, 2022):7个子模型的级联架构,3D U-Net(时空分离卷积/注意力)捕捉帧间依赖,结合v-预测参数化(数值稳定)、分类器-free引导(提升 prompt 保真度),生成高清视频;
- Video LDM(2023):将2D Latent Diffusion Model扩展为视频模型,通过添加时间层对齐帧,分“关键帧生成→帧插值→上采样”步骤生成长视频,可将Stable Diffusion转化为T2V模型。
- Sora推测方案:
- 架构:采用级联扩散(基础模型生成低分辨率视频+时空优化模型提升质量);
- 训练策略:优先用低分辨率长视频训练,保障时间一致性;
- 编码器:自研时空VAE编码器,联合训练图像与视频数据,同时压缩空间与时间信息(避免传统“2D编码器+后验时间调优”的低效问题)。
3.4 语言指令遵循:提升文本-视频对齐度
- 核心思路:借鉴DALL-E 3的“标题优化”方法,通过高质量(视频-描述)对微调模型,解决“指令理解偏差”问题。
- 实现步骤:
- 训练视频标题生成器:基于VideoCoCa(扩展CoCa架构,输入多帧图像)、mPLUG-2等模型,生成包含物体、背景、风格、动作的详细描述;
- 混合数据微调:用“标题生成器输出(批量)+人工标注数据(高质量)”混合数据集微调Sora,确保覆盖多样化场景;
- 提示扩展:用GPT-4V将用户短提示(如“柴犬玩球”)扩展为详细描述(如“一只黄色柴犬在绿色草坪上追红色皮球,阳光明媚”),对齐训练数据格式。
3.5 提示工程:引导模型生成目标内容
- 文本Prompt:需包含动作、场景、角色外观、氛围等细节(示例:“穿黑色皮夹克、红色长裙的时尚女性,戴红色口红与墨镜,在东京霓虹街道自信行走,地面潮湿反光,周围有行人与发光招牌”),核心是“桥梁人类创意与AI执行”。
- 图像Prompt:以静态图像为视觉锚点(如DALL-E生成的“云组成‘SORA’字样”),结合文本指令添加运动(如云的流动)、交互(如字符渐变),实现“静态→动态”转化。
- 视频Prompt:支持三类任务:
- 视频扩展:按指令向前(追溯前情)或向后(延伸后续)扩展时间线;
- 视频编辑:修改视频风格(如“将写实场景转为卡通风格”)、场景(如“将街道背景改为沙漠”);
- 视频连接:平滑过渡两个不同场景(如“从城市夜景过渡到森林日出”),需平衡指令特异性(明确目标)与灵活性(保留创作空间)。
3.6 可信度:保障安全与伦理
- 安全问题:
- 越狱攻击:如AutoDAN(梯度 adversarial 攻击)、视觉越狱(多模态输入扩大攻击面);
- 应对措施:OpenAI部署视频检测分类器(识别Sora生成视频)、文本分类器(过滤有害输入),同时加强模型自身抗攻击能力。
- 滥用风险:
- 幻觉:生成看似合理但虚假的内容(如不存在的人物/场景),需通过“评估工具(如Hallusionbench)+ mitigation 方法(鲁棒指令调优)”降低;
- 偏见:训练数据蕴含的社会偏见(如性别/种族刻板印象),需通过Fair Diffusion等方法识别并修正;
- 隐私:大规模训练数据可能泄露用户隐私,需采用差分隐私、数据脱敏等技术保护。
- 模型对齐:采用RLHF(基于人类反馈的强化学习),通过人类标注偏好数据训练奖励模型,引导Sora输出符合人类意图与伦理标准的内容,类似LLM的对齐思路。
4. 应用场景:多行业的变革潜力
| 行业 | 具体应用案例 | 核心价值 |
|---|---|---|
| 电影 | 1. MovieFactory:从ChatGPT生成的脚本自动生成电影片段; 2. MobileVidFactory:生成竖屏短视频(适配手机端); 3. Vlogger:用户输入文本生成1分钟个人vlog |
降低制作门槛,实现“文本→视频”自动化,推动电影创作民主化,让个人也能成为内容生产者 |
| 教育 | 1. 课程可视化:将数学公式、物理定律(如自由落体)转化为动态视频; 2. 历史还原:生成历史事件场景(如“文艺复兴时期的佛罗伦萨”); 3. 静态资源活化:将教材插图转为互动视频(如“细胞分裂过程动画”) |
提升学生注意力与知识吸收效率,支持个性化教学(按学生兴趣调整视频风格),缩小优质教育资源差距 |
| 游戏 | 1. 动态环境生成:实时生成天气变化(如晴天转暴雨)、地形变形(如平原隆起山脉); 2. NPC动作定制:根据玩家指令生成NPC独特动作(如“骑士挥剑砍树”); 3. 音效匹配:从视频生成逼真音效(如“角色跑步的脚步声”) |
突破预渲染环境的局限性,提升游戏沉浸感,减少开发成本(无需手动设计所有场景/动作) |
| 医疗 | 1. 动态异常检测:识别早期细胞凋亡、皮肤病变进展(如黑色素瘤扩散)、异常肢体运动(如帕金森症状); 2. 医疗图像分割:如MedSegDiffV2,高精度分割CT/MRI图像中的病灶; 3. 手术模拟:生成手术操作视频(如“腹腔镜手术步骤”),辅助医生培训 |
辅助早期疾病诊断,提升医学影像分析精度,降低手术培训成本,推动精准医疗 |
| 机器人 | 1. 视觉感知增强:让机器人通过视频理解复杂环境(如“识别客厅内物品位置与状态”); 2. 模拟训练:生成多样化模拟场景(如“家庭环境中家具摆放变化”),缓解真实训练数据稀缺问题; 3. 动作预测:根据语言指令生成机器人动作视频(如“抓取杯子的步骤”),指导实际操作 |
提升机器人环境交互精度,降低训练成本,推动机器人在家庭、工业等复杂场景的应用 |
5. 局限性与未来机会
5.1 局限性(需突破的核心问题)
- 物理真实性不足:复杂物理交互模拟偏差(如咬饼干无咬痕、液体流动不符合重力),刚体结构(如椅子、桌子)变形不自然,偶尔出现“幽默化”错误(如物体漂浮)。
- 时空复杂度处理问题:
- 空间层面:偶尔混淆物体/角色位置方向(如“向左走”生成“向右走”);
- 时间层面:难以维持指定相机运动序列(如“环绕拍摄”变为“平移拍摄”);
- 场景复杂度:多元素场景(如“拥挤的市场”)易插入无关元素(如多余的动物/人物),破坏原创意。
- 人机交互(HCI)局限:用户难以精细修改视频元素(如调整角色动作幅度、优化场景过渡效果),对复杂语言指令(如“让角色先挥手再微笑,背景同时从白天渐变到黄昏”)的语义理解不足,输出与预期偏差较大。
- 使用限制:OpenAI尚未公布公开部署时间,当前视频最长仅1分钟,无法满足长时内容需求(如完整教学视频、电影片段),灵活性受限。
5.2 未来机会(多维度发展方向)
- 学术领域:
- 推动文本到视频模型的“扩散+Transformer”深度融合,探索更高效的时空建模方法;
- 拓展“原生尺寸训练”的应用范围,减少对人工设计特征(如固定分辨率)的依赖,提升模型通用性;
- 深入研究视觉模型的涌现能力,揭示“规模→能力”的内在机制,指导更大规模LVM的设计。
- 行业领域:
- 提升视频模拟真实度,推动游戏开发(生成开放世界)、广告制作(快速响应市场变化,定制化投放);
- 开发轻量化版本,降低硬件门槛,让中小企业与个人创作者便捷使用;
- 融合多模态输入(如文本+音频),生成“视频+音效+字幕”的一体化内容,提升创作效率。
- 社会领域:
- 赋能社交媒体:降低TikTok、Reels等平台的视频创作门槛,实现“全民高质量内容生产”;
- 辅助创意行业:编剧可将脚本快速转化为视频样片,记者可生成新闻解释性视频(如“台风形成过程”),提升信息传播效率;
- accessibility 提升:为视觉障碍者提供“文本→视频描述”服务,或生成手语视频,推动内容 inclusivity。
6. 结论
文档基于公开技术报告与逆向工程,首次全面综述了Sora的背景、技术、应用、局限与机会,核心目标是为开源研究社区提供参考,推动“开源版Sora”的开发;未来将在Sora API发布、技术细节进一步公开后更新内容,呼吁跨领域协作(技术、法律、心理学),共同解决可信度与伦理问题,最终实现AIGC时代视频自动创作的民主化。
4. 关键问题(含答案,侧重不同维度)
问题1:Sora作为首个能生成1分钟高质量视频的文本到视频模型,其核心技术中“时空Latent补丁”是如何解决传统视频生成模型“可变格式处理”与“计算效率”之间的矛盾的?
答案:Sora通过“时空压缩网络+Patch n’ Pack(PNP)策略”解决该矛盾,具体路径如下:① 先通过时空压缩网络(基于VAE/VQ-VAE)将可变格式(时长、分辨率、宽高比)的原始视频转化为低维latent表示,再分解为时空补丁——若为“空间补丁压缩”则拆帧为固定尺寸补丁并按时间序列组织,若为“时空补丁压缩”则通过3D卷积提取跨帧tubelets,确保不同格式视频转化为统一结构的补丁;② 采用PNP策略,借鉴NLP的示例打包思想,将不同视频的时空补丁打包成固定长度序列(通过贪心算法填充剩余空间,结合令牌丢弃优化效率),满足Transformer“固定输入序列长度”的需求;③ 推测OpenAI采用超长上下文窗口,避免令牌丢弃导致的细节丢失,同时保障3D一致性(如物体持久性),最终平衡“原生尺寸训练(保留视频格式多样性)”与“批量计算(提升效率)”的矛盾。
问题2:Sora在教育行业的应用如何体现“降低内容创作门槛”与“提升学习效率”的双重价值?请结合具体场景说明。
答案:Sora在教育行业的应用通过“文本驱动自动化”实现双重价值:① 降低内容创作门槛:传统动态教育内容(如科学模拟、历史场景)需专业团队制作(如3D建模、视频剪辑),而Sora允许教师直接输入文本指令(如“生成‘地球围绕太阳公转,同时自转导致昼夜交替’的动画,包含太阳、地球、月球,标注赤道、北极圈”),无需任何专业技能,即可生成高质量视频;对于静态资源(如教材中的“细胞分裂插图”),教师可通过图像Prompt+文本指令(“让插图中的细胞从间期过渡到分裂期,标注染色体、纺锤体”),快速转化为互动视频,大幅缩短制作周期;② 提升学习效率:动态视频比静态资源更能吸引学生注意力,尤其对抽象概念(如数学函数图像变化、物理力学原理),Sora可生成可视化过程(如“生成‘y=x²函数图像随x从-5到5变化,同时标注顶点、对称轴’的视频”),帮助学生理解因果关系;此外,教师可根据学生兴趣定制视频风格(如“将‘工业革命场景’生成卡通风格视频”),适配不同学习偏好,进一步提升知识吸收效率。
问题3:针对Sora当前“物理真实性不足”的局限性(如物体交互不符合物理规律),文档中隐含或提及了哪些可行的技术解决方向?
答案:结合文档内容,可行的解决方向包括三类:① 借鉴成熟的视频扩散Transformer时空建模方法:如Imagen Video的3D U-Net架构,通过“时空分离卷积/注意力”分别捕捉空间细节与时间依赖,增强对物理交互(如物体碰撞、液体流动)的建模能力;或Video LDM的“关键帧生成+帧插值”策略,先生成符合物理规律的关键帧(如“杯子掉落至地面”的起始与结束帧),再通过插值优化中间帧的运动连贯性,减少物理偏差;② 引入显式物理知识约束:在扩散模型的采样过程中添加物理引擎规则(如重力、摩擦力公式),或结合物理知识图谱,让生成过程遵循客观规律(如“生成‘苹果从树上掉落’的视频时,强制苹果运动轨迹符合自由落体公式”),避免“漂浮、无重力”等错误;③ 优化训练数据与模型微调:通过人工标注“物理正确的视频-描述对”(如“咬饼干后出现咬痕、杯子倒后水流出”),扩充训练数据中的物理交互样本;同时采用“物理真实性评估指标”(如设计专门检测物体运动是否符合物理规律的工具),在微调阶段针对性修正偏差,提升模型对物理规律的建模能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)