快手开源模型/项目介绍:
概述、Keye-VL、KwaiAgents、Thyme、架构、SFT、RL、测评、KwaiYii、KAT-V1、KAT-Coder、CodeFlicker、SeamlessFlow、HiPO、VANS、UniSearch、架构、UniDex、参考。
概述
几个官网:
- 可图:https://kolors.kuaishou.com,即将下线,使用可灵代替;
- 可灵创作平台官网:https://app.klingai.com,支持音效、图片、视频、创意特性创作
- 可灵AI官网:https://klingai.com,包括开发者平台以及跳转到可灵的链接
快手集团GitHub开源主页包括:
- https://github.com/kwai
- https://github.com/Kwai-Keye
- https://github.com/KwaiKEG
- https://github.com/KlingTeam
- https://github.com/Kwaipilot
HuggingFace(HF)或ModelScope(MS)也可按照这个命名去搜索开源模型。
Keye-VL
论文,开源(GitHub,)多模态大模型,在视频理解方面表现出色,能够将视频内容转化为高效解决方案,能够智能选择思考模式,兼顾效率与创意;逻辑推理也出色。
架构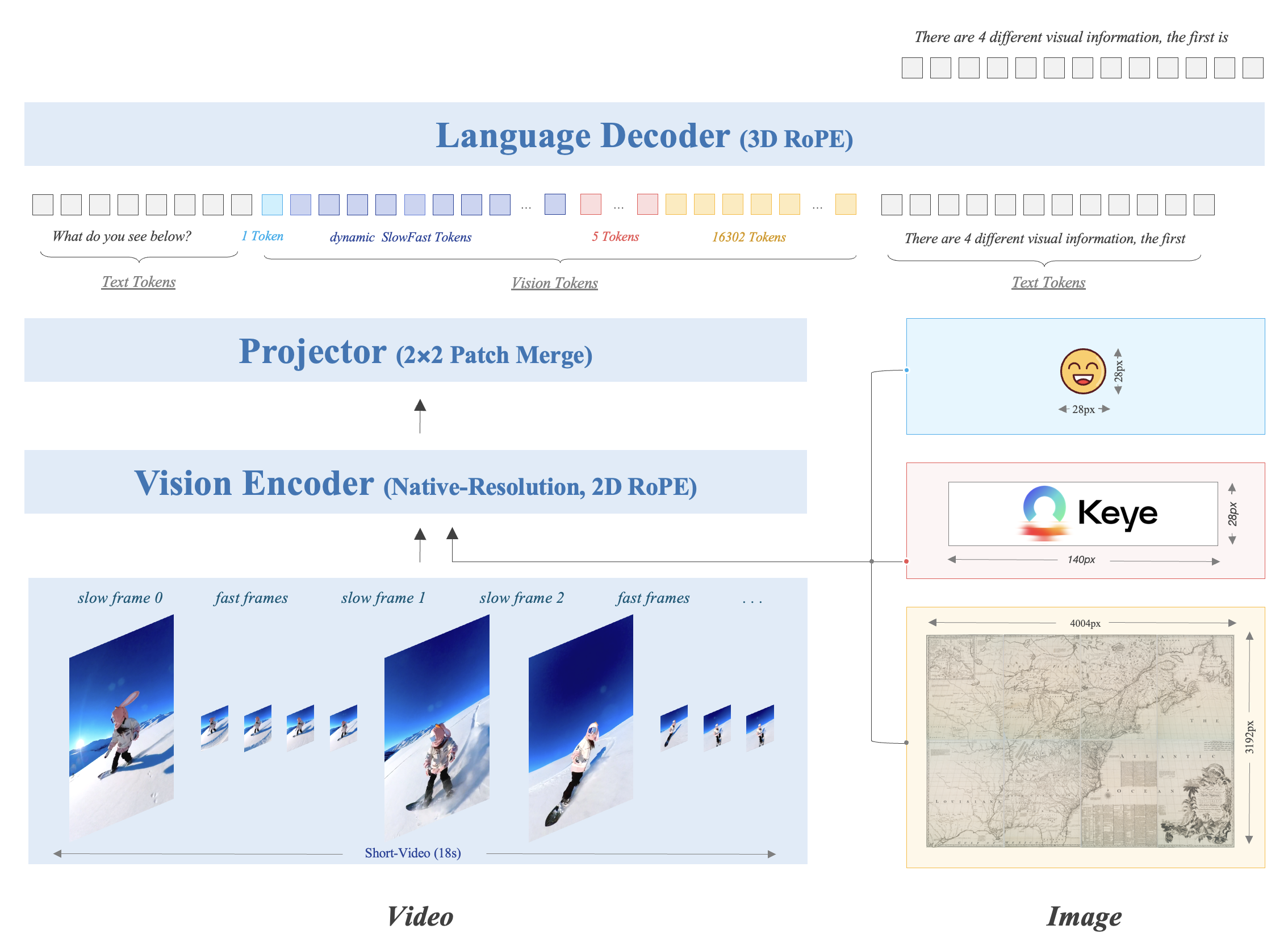
和经典MLLM架构类似,由ViT+MLP+LLM组成。视觉侧有两点创新:
- 具有原生分辨率的视觉编码器
MLLMs使用预训练的固定分辨率ViT作为视觉编码器。然而,这些ViT通常是为处理粗粒度的图像-文本匹配任务而设计的,而MLLMs需要处理更细粒度的生成任务。因此,Kwai Keye-VL模型实现一个原生分辨率的ViT,以自然地处理原始分辨率的图像,避免复杂的图像拼接或分割操作。Kwai Keye-VL的ViT是基于SigLIP-400M-384-14进行初始化。为保持图像的结构完整性和细节,采用插值技术将固定的位置嵌入扩展为自适应分辨率的位置嵌入,并引入二维旋转位置嵌入(RoPE)来增强视觉信息的建模能力。
- 视觉编码
为确保语言解码器能够充分感知和理解图像和视频中的视觉信号,模型为图像和视频建模保留足够的token缓冲区。
对于不同分辨率的图像,每个图像的总token数设置为16384,这足以覆盖超过一百万像素的图像,并帮助模型在大多数情况下看到图像的细节。对于视频建模,模型设计一种动态分辨率策略,平衡最大帧数和总token数。
预训练
- 训练数据概述:使用超过600B token,来源包括公共数据集和专有的内部数据。训练数据主要涵盖六个类别:图像字幕、OCR和VQA、定位和计数、交错文本-图像、视频理解和纯文本数据。
- 预训练管道:采用四阶段渐进式训练策略
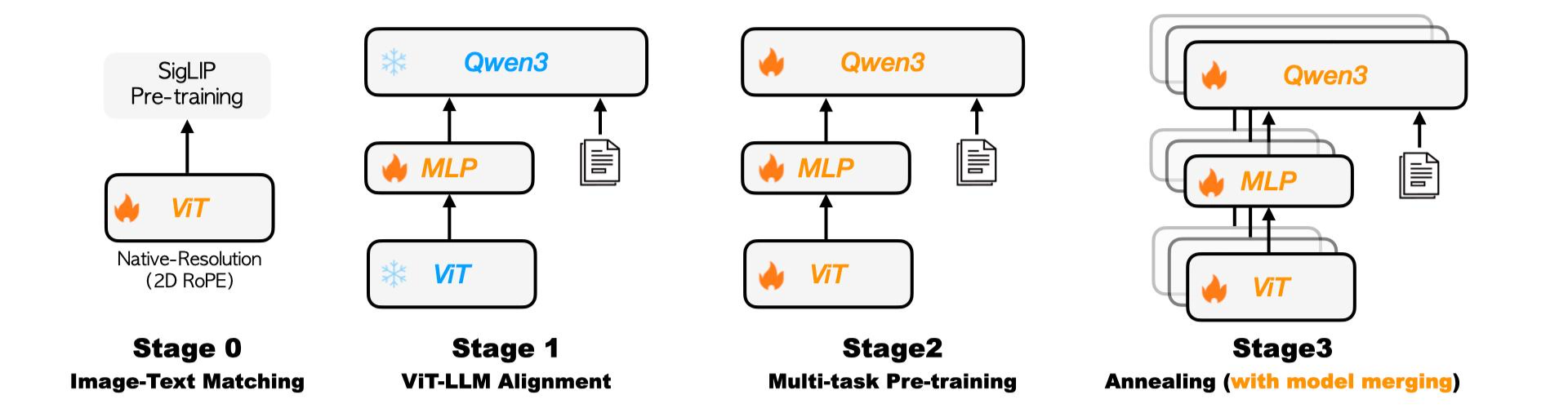
- 阶段0:视觉预训练,预训练视觉编码器,以使其适应内部数据分布并支持动态分辨率;
- 阶段1:跨模态对齐,从Qwen3-8B初始化,视觉和语言模型的参数被冻结,专注于优化投影MLP层。通过大规模数据集建立跨模态特征的强对齐,为后续学习阶段奠定基础;
- 阶段2:多任务预训练。解冻所有模型参数,进行端到端优化,使用多样化的多任务训练数据。数据涵盖常见的视觉-语言任务,如图像字幕、OCR、定位、VQA和交错图像-文本数据,显著增强模型的基本视觉理解能力。
- 阶段3:退火,在精选高质量数据上进行微调,目标是解决在大规模训练中缺乏高质量样本暴露的问题。通过优化的学习策略和数据混合,进一步细化模型的细微理解能力。
- 模型合并,最后阶段,探索同质-异质合并技术,通过平均不同数据混合的模型权重,减少整体偏差并增强模型鲁棒性。
后训练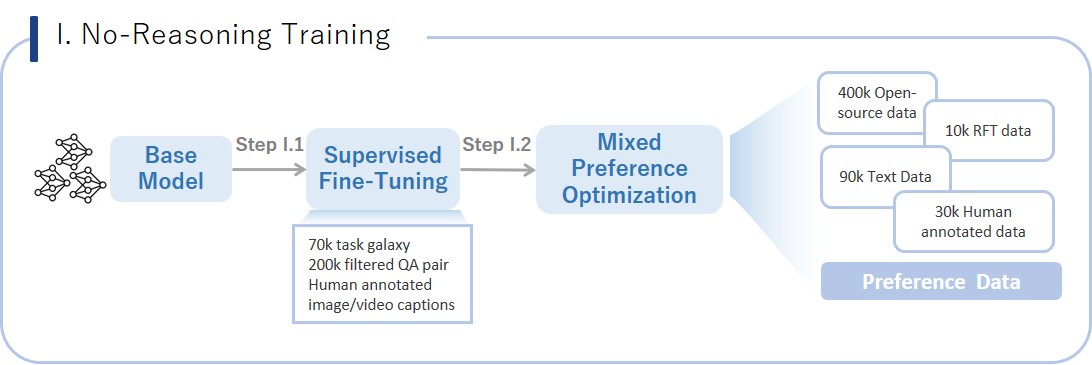
分为两个阶段,训练模型的综合能力。初始阶段专注于建立自然图像理解和文本交互的基础性能,后续阶段则集中于逐步增强模型的复杂推理能力。
1、无推理训练:建立基础性能
通过两个连续步骤建立模型在非推理场景中的核心性能和稳定性。由SFT+MPO两步骤构成,
1.1、SFT
SFT数据候选池包含超过500万个多模态QA样本。为确保任务的多样性和数据的质量,采取以下方法:
- 任务多样性:使用TaskGalaxy框架,将数据分类为7w种不同的多模态任务类型。
- 数据挑战性:通过MLLMs生成多个推理路径,测量每个样本的复杂性,过滤过于简单的样本。
- 数据可靠性:人类注释者为训练集中的图像和视频精心制作字幕。
训练策略包括动态学习率,并在训练后期进行退火处理,以提高性能。
1.2、混合偏好优化(MPO)
在SFT之后,模型通过MPO进一步优化其性能。数据集包括开源样本、重建偏好样本、自我改进样本、仅文本样本和人类注释样本。MPO算法用于优化模型在非推理环境中的整体性能。
2、推理训练:复杂认知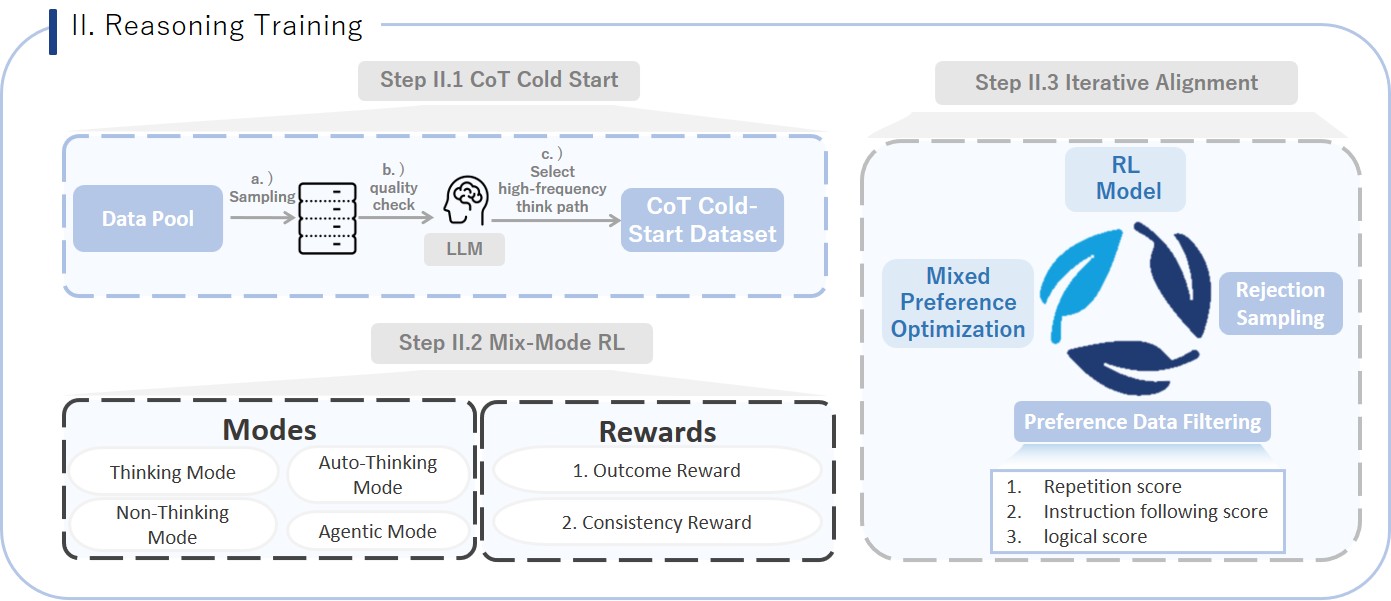
通过引入混合模式的CoT冷启动和强化学习机制,显著增强模型的多模态感知、推理和思考与图像能力。分三步:
- CoT冷启动:初始化模型的链式思维能力,结合长CoT数据和指示性数据,促进复杂问题的结构化思考,同时保持开放任务的风格多样性和响应灵活性。
- 混合模式RL:在CoT冷启动的基础上,使用RL进一步增强模型的能力,特别是在多模态感知、推理和数学推理方面。通过GRPO算法,模型在短视视频理解等任务上表现出显著的性能提升。
- 迭代对齐:用于解决重复崩溃和逻辑错误问题。使用拒绝采样数据,通过多轮迭代优化模型,使其能够根据任务难度自动选择合适的推理模式。
汇总
| 阶段 | 子阶段 | 数据集组成 | 数据类型 | 数据来源和构建方法 |
|---|---|---|---|---|
| 无推理训练:建立基础性能 | SFT | 超过500万个多模态QA样本 | 多样化的任务类型,包括复杂的推理路径 | 使用TaskGalaxy框架分类为7w种不同的多模态任务类型;通过MLLMs生成多个推理路径,过滤过于简单的样本;人类注释者为图像和视频制作字幕 |
| MPO | 40w个开源样本、5w个重建偏好样本、1w个自我改进样本、9w个仅文本样本、3w个人类注释样本 | 开源数据、重建偏好数据、自我改进数据、仅文本数据和人类注释数据 | - 开源数据进行简单去重和过滤,保留40w个样本 - 重建偏好数据:使用现有多模态偏好数据集(如MM-RLHF),并使用开源LLM生成高质量负例 - 强化微调(RFT)数据:针对SFT模型的弱点构建偏好对 - 仅文本数据:包括9w个内部仅文本偏好对 - 人类注释数据:使用MM-RLHF流程生成3w个人类注释偏好对 |
|
| 推理训练:复杂认知的核心突破 | CoT冷启动 | 33w个非推理样本、23w个推理样本、2w个自动推理样本、10w个代理推理样本 | 长CoT数据和指示性数据,结合推理和非推理数据 | 结合长CoT数据和指示性数据,促进复杂问题的结构化思考 |
| 混合模式RL | 多模态感知和推理数据、基于文本的数学推理数据、代理推理数据 | MMPR、MM-Eureka等数据集,DeepEyes数据集中的4.7w个样本 | 使用MMPR、MM-Eureka等数据集,以及DeepEyes数据集中的样本,通过GRPO算法增强模型的能力 | |
| 迭代对齐 | 来自指令跟随、OCR、数学、图表、计数、仅文本内容、安全和认知领域的拒绝采样数据 | 拒绝采样数据,用于选择“好案例”和“坏案例” | 通过多轮迭代,选择“好案例”和“坏案例”来构建偏好对,使用MPO算法更新模型 |
KwaiAgents
论文,联合哈工大开源(GitHub,1.2K Star,117 Fork)智能体框架。
开源内容包含:
- 系统(KAgentSys-Lite):轻量级Agents系统,并配备事实、时效性工具集;
- 模型(KAgentLMs):Meta-Agent Tuning后,具有Agents通用能力的系列大模型及其训练数据;
- KAgentInstruct:超过20w(部分人工编辑)的Agent相关的指令微调数据;
- 评测(KAgentBench):开箱即用的Agent能力自动化评测Benchmark与人工评测结果。
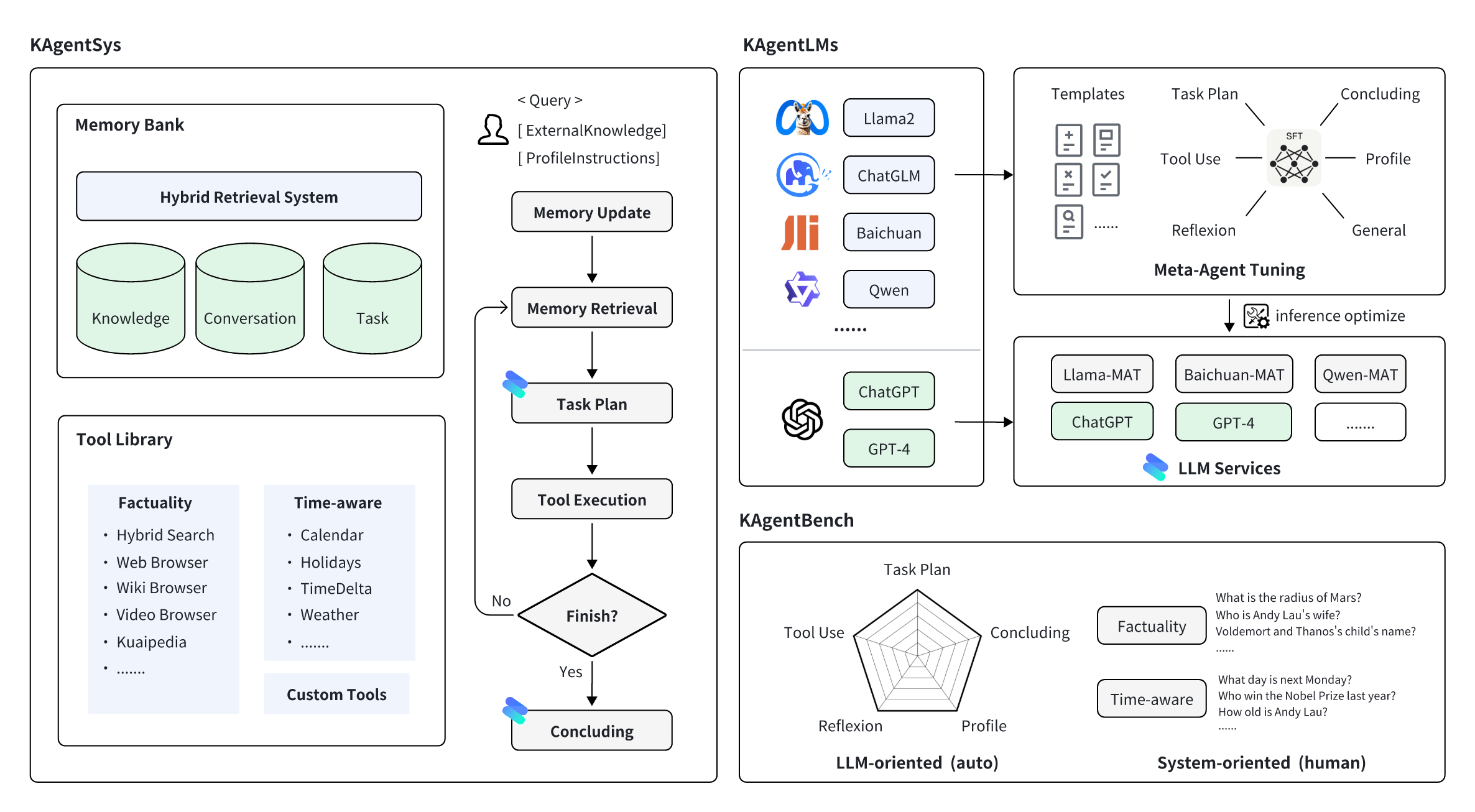
KAgentSys系统,基于LLM作为认知内核,配以记忆机制、工具库,形成的迭代式自动化系统。其主要包含:
- 记忆机制:包含知识库、对话、任务历史三类记忆,依托于混合向量检索、关键词检索等技术的检索框架,在每一次规划路径中检索所需的信息;
- 工具集:包含事实性增强工具集,异构的搜索和浏览机制能够汇集网页、文本百科、视频百科等多个来源的知识;包含日历、节日、时间差、天气等常见的时效性增强工具集;
- 自动化Loop:在一轮对话中,用户会给予一个问题,可选知识库及额外人设整体进行输入,系统会先进行记忆的更新和检索,再调用大模型进行任务的规划,如果需要调用工具则进行调用,如果不用则进入总结阶段,大模型综合历史的信息给出符合预期的回答。
Thyme
主要贡献
- 提出一个全新的多模态交互范式Thyme
- 核心思想:让MLLM不再局限于被动地看图,而是能够主动地通过生成并执行代码,来调用各种工具完成复杂的图像处理和数学计算;
- 功能丰富:模型可以即时进行裁剪、旋转、缩放、对比度增强等多种图像操作,还能处理复杂的数学问题;
- 高度自主:模型能自主判断何时需要使用工具、使用何种工具,并动态生成代码来执行,无需人工为特定任务进行干预。
- 设计一套高效的两阶段训练策略SFT+RL
- SFT:利用精心构建的约50万条高质量样本数据集,快速教会模型生成代码来执行各种操作。这个阶段仅需约200 GPU小时,性价比极高;
- RL:在SFT基础上,通过RL进一步优化模型的决策能力。为解决RL阶段的挑战,研究者还:
- 构建高质量RL数据集:手动收集和标注1万张高分辨率、高难度的图像问答对,以增强模型在复杂场景下的感知能力;
- 提出创新的RL算法GRPO-ATS:能为文本生成和代码生成设置不同的采样温度。为文本使用较高温度以鼓励探索和创造性,为代码使用极低温度(0.0)以确保生成代码的精确性和可执行性,巧妙地平衡推理灵活性和代码稳定性。
- 构建并开源完整的配套资源
- 高质量数据集:开源用于SFT和RL阶段的全部数据集,包括超过400万的原始数据源和精心筛选标注的数据;
- 安全的沙箱环境:开发一个可以安全执行模型生成的代码并返回结果的沙箱。还简化代码生成难度,能自动处理格式、变量定义等问题,提高代码可用性。
案例:
- 裁剪+放大:定位细节
- 对比度增强:可用于OCR任务,按需增强图像对比度,让需要识别的文字更加清晰
- 图像旋转:OCR识别时,可自动发现输入图像的方向不正确,进而旋转图像
- 复杂计算:图文混合
架构
整体流程主要由两个组件构成:模型和沙盒
- 模型接收用户输入问题,输出推理思路;
- 模型判断问题复杂度,决定是否生成Python代码执行图像处理或计算任务;
- 若无需代码(简单问题或先前代码已解决),直接输出答案;
- 如果需要生成代码,模型将自主生成代码。训练数据涵盖几种类型的图像操作,如裁剪、缩放、旋转、对比度增强和计算。生成代码后,交付给外部沙箱安全执行,其主要功能是安全地处理输入代码并返回执行结果,沙箱负责格式校验、参数调整、错误修正等处理。
- 最后,沙箱返回执行结果(图像或数值),模型基于结果继续推理,多轮交互直至输出最终答案。
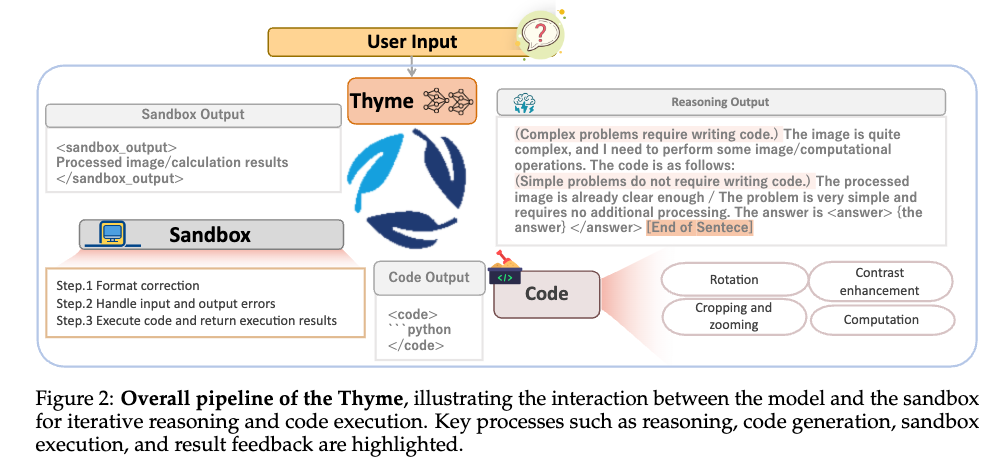
沙盒需要做的一些事情,主要包括一些自动纠错机制,尽量保证代码可用性
- 使用autopep8模块格式化代码,统一缩进和风格;
- 利用ast解析代码变量,自动调整图像裁剪坐标边界,避免越界错误;
- 预置必要变量及模块导入(如
cv2、image_path),保证环境一致; - 记录代码分段变量依赖,解决多段代码执行时上下文丢失问题。
SFT
首先,从现有数据集中采集样本,并根据目标函数(如裁剪、旋转等)构建提示。模型根据提示生成思考过程和对应代码。代码随后在沙盒环境中执行,以过滤掉运行不正常的样本。剩余样本由另一个MLLM进行审核,验证代码执行结果是否与思考过程一致,并有效回答问题,从而剔除无效代码样本。最后,进行人工审核以移除低质量样本,确保冷启动数据集的质量。
SFT主要构造三类任务:
- 无需代码直接答复:简单问题直接回答,训练模型判定是否需要代码生成;
- 基于代码的图像操作和计算:包含裁剪、旋转、对比度增强、数学计算等;
- 多轮交互数据:针对图像操作失败的错误修正、连续增强等多轮迭代任务。
对代码生成样本进行严格执行与语义审核,剔除不执行或执行结果错误的代码片段,提高训练样本有效性。手工构建多轮对话数据,教会模型基于上一轮代码执行结果调整策略,具备错误纠正能力。
训练策略
训练过程模型基于输入图片(I)和问题(Q)生成推理流程(T)及可选代码©,通过沙箱执行代码获得结果(S),多轮循环迭代直到生成最终答案(a):
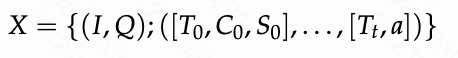
t t t表示样本的最大交互轮数。
在训练过程中遇到的几个挑战:
- 两轮对话数据的特殊性,出现一些意想不到的模式:模型在第一轮倾向于生成错误或不充分的分析和代码,然后在第二轮进行修正,使得第一轮基本上无效。
- 数学数据相对于图像处理数据的数量相对较少;在联合训练时,模型几乎无法学习生成与计算相关的代码。
使用SFT策略保证多种功能能被成功激活:
- 强制模型仅学习输出最终一轮的有效推理和代码,早期输出轮次内容被遮蔽,避免模型过度依赖第二轮纠正;
- 训练时排除沙箱执行输出标签,防止模型直接模仿沙箱结果,提高推理过程质量;
- 对数学计算数据采用退火训练策略:初始阶段训练图像操作数据,再用较低学习率微调数学推理数据,避免数据不均衡问题。
RL
除了从开源数据进行搜集和筛选外,额外补充10k的人工标注数据,标注任务包括OCR、属性识别、数量识别等,要求模型能够从高分辨率图像中提取细节信息并正确回答相关问题,增强感知难度。
训练策略 GRPO-ATS
格式化奖励:模型输出需要严格遵循特定结构,由标签和标签包围。这鼓励模型在生成最终答案前明确进行推理,提高可解释性。采用on policy的GRPO。
奖励函数包括:
- 结果奖励:比较模型输出与地面真值答案的匹配程度,确保模型输出的正确性;
- 一致性奖励:检查推理过程是否与最终答案一致,以确保推理步骤的合理性;
- 格式奖励:确保输出符合严格的结构规范,增强推理过程的可解释性。
适应性温度采样
温度调整:对于代码生成任务,如图像处理和计算任务,使用低温度( τ = 0 τ=0 τ=0)进行采样,以确保代码生成过程的准确性和一致性。对于推理过程,使用较高温度( τ = 1 τ=1 τ=1)来鼓励模型探索更多的解决方案。有效避免模型在生成代码时的过度多样化问题,提高代码生成的稳定性,并使得推理过程更加灵活多样。
采样优化:
- 为了减少计算资源浪费,运用Rabin-Karp滚动哈希算法检测过多重复内容;当重复子串长度超过输出长度50%,立即判定为重复并提前终止当前轨迹采样,有效避免资源浪费;
- 在训练中还强制限制最大对话轮次,避免模型陷入无意义的循环,提高训练效率。
测评
在测试时的扩展策略对感知任务十分有效。
在推理任务中,通过将复杂的计算转化为可执行代码,推理能力上取得显著提升。然而,在这一领域,模型规模的扩展带来的优势更为显著,表明推理和逻辑推理能力主要依赖于模型本身的知识量。
感知与推理能力的提升,在许多通用任务中取得显著进展,尤其是在减少幻觉现象方面。
KwaiYii
中文名:快意,AI团队开源(GitHub,230 Star,5 Fork,即官方文档)从零到一独立自主研发的一系列LLM,包括预训练模型和对话模型。
官方文档(但在HF或MS搜不到):
- KwaiYii-13B-Base:预训练模型,具备优异的通用技术底座能力
- KwaiYii-13B-Chat:对话模型,具备出色的语言理解和生成能力
多个权威Benchmark结果表明KwaiYii-13B模型在各领域具备领先水平。
有个测试地址,https://kuaiyi-test.kuaishou.com,无注册按钮,疑似内部使用。
KAT-V1
论文,Kwaipilot团队发布自动思考AutoThink大模型,融合思考与非思考能力,可根据问题难度自动切换思考形态。
提供两个版本:
- 40B:自动思考模式下,性能可追平DeepSeek-R1-0528(参数量为6850亿);
- 200B:未开源,在多项基准测试中超过Qwen、DeepSeek和Llama三大开源模型家族中的旗舰模型。
多一个Judge过程,用来分析输入以决定是否需要思考:
KAT-Coder
项目主页,
KAT-Coder模型强化学习的实验版本,基于快手自研SeamlessFlow工业级RL框架,通过创新数据平面架构实现训练逻辑与Agent完全解耦,成功支持多智能体和在线强化学习等复杂场景。
可通过StreamLake平台提供API调用。
在传统大模型Agent训练中,由于模型在执行任务时会产生包含分支与回溯的树状Token轨迹,业界普遍采用拆分为多条线性序列的简化训练方案。然而,这种方法忽略轨迹之间的共享结构,容易造成计算冗余。
团队重新设计训练引擎与注意力内核,并通过树形梯度修复权重机制,将共享前缀的正反向计算合并,实现在树形轨迹上的高效训练。
技术创新
- Trie Packing:通过重新设计训练引擎与注意力内核,以及树形梯度修复权重机制,将共享前缀的正反向计算合并,实现在树形轨迹上的高效训练,训练速度平均提升2.5倍,大幅增加RL训练的吞吐量。
- 熵感知优势缩放:对每个rollout样本计算策略熵(Policy Entropy),并将其归一化后用作优势的放大系数,对高熵样本(探索性强)放大优势,对低熵样本(确定性强)适度抑制。在保留GRPO组内优化结构的同时有效增强策略探索性,改善RL训练过程中探索-利用的平衡。
开源模型:
- KAT-Dev:32B参数
- KAT-Dev-72B-Exp:72B参数
- KwaiCoder-23B-A4B-v1:23B参数
- KwaiCoder-DS-V2-Lite-Base:16B参数
- OASIS-code-1.3B:1B参数,论文,OASIS是Order-Augmented Strategy for Improved code Search缩写
- OASIS-code-embedding-1.5B:1B参数
CodeFlicker
官网,快手推出的AI IDE。
感兴趣,可参考AI辅助编程系列:
SeamlessFlow
论文,
技术创新:
- 引入独立数据平面层,其核心是轨迹管理器(Trajectory Manager),彻底解耦RL训练和智能体实现。轨迹管理器在智能体与语言模型服务之间静默记录所有交互细节,包括输入输出及多轮对话的分支结构,从而构建完整轨迹树。不仅避免重复计算、提升存储效率,还支持精确的在线与离线策略区分。
- 推理管理器(Rollout Manager),实现对模型更新与资源调度的无感控制,使得智能体无需适配训练框架即可实现任务的无缝暂停与恢复,大幅提升系统灵活性与训练效率。
- 标签驱动的资源调度范式,通过为计算资源赋予如训练或推理等能力标签,统一集中式(Colocated)与分布式架构(Disaggregated)的资源管理模式。持时空复用机制,使得具备多标签的机器可根据任务需求动态切换角色,将GPU闲置率降至5%以下,彻底缓解传统架构中的流水线空闲问题。
HiPO
系列模型包括:
VANS
UniSearch
论文。
直播搜索是快手重要的搜索流量来源,也是短视频应用场景中的新业务领域,为应对直播业务场景高时效性要求的挑战,快手搜索技术团队设计了统一的生成式搜索架构,提升用户体验并优化搜索效率。
架构
与以往依赖多阶段模型的级联系统不同,采用统一架构,在同一框架内完成端到端训练与推理,消除各阶段目标之间的不一致性,降低系统复杂度。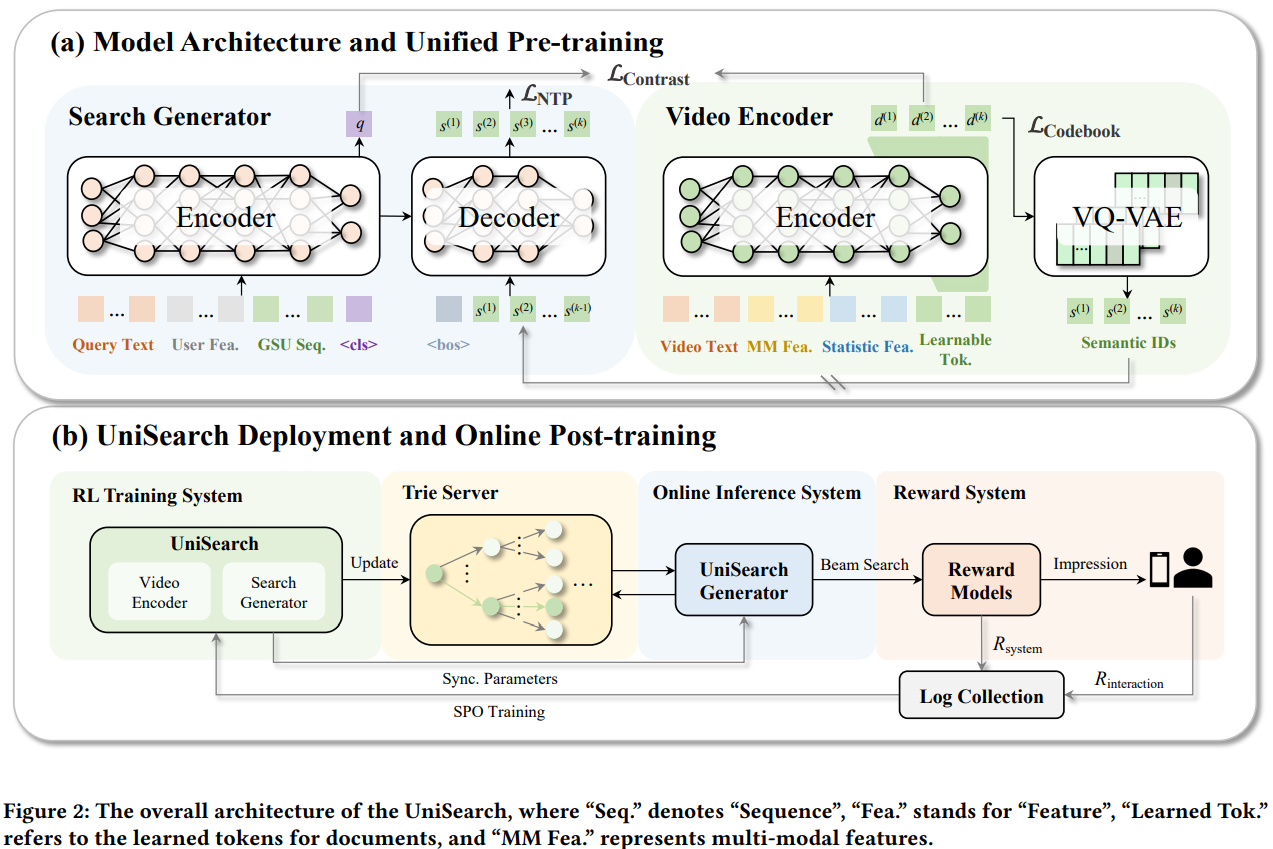
UniTouch建模:真端到端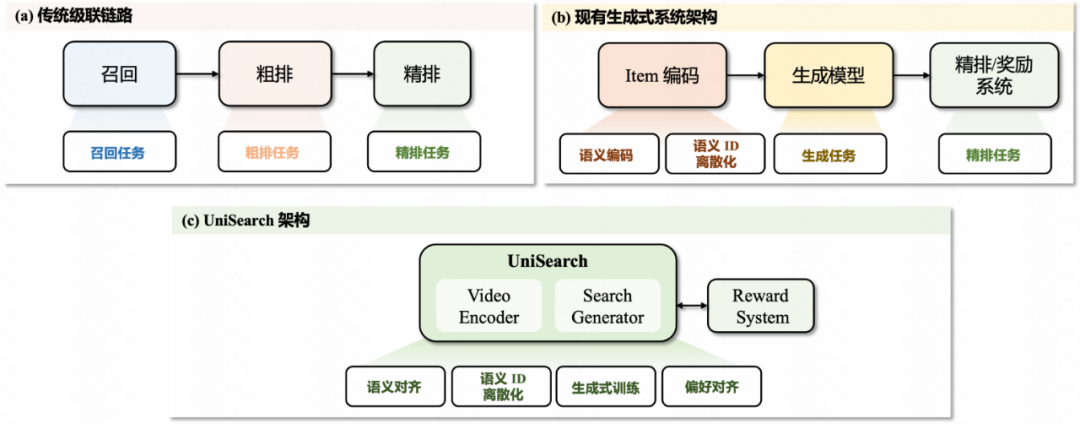
先前的生成式搜推模型(如OneRec)采用两阶段训练,item离散化表示和item生成任务,这会导致两阶段目标不一致。为此,设计真端到端训练架构UniSearch,将Search Generator和Video Encoder统一到一个训练框架。
Search Generator采用Encoder-Decoder架构,输入为搜索词、用户特征序列等。使用<cls>来表征query侧整体语义向量。Decoder侧自回归地预测出视频的语义ID。
Video Encoder,为每个视频学习潜在embedding表示和语义ID。Encoder的输入为视频侧特征,输出为Learnable Token对应的语义序列表征。同时Video Encoder有一个用于离散化的VQ Codebook,用于将连续的Embedding转化为语义ID。
通过联训Search Generator和Video Encoder,UniSearch能够缓解item生成和item表征之间的鸿沟,实现整个生成搜索框架的统一与连贯性。
离线训练:残差渐进式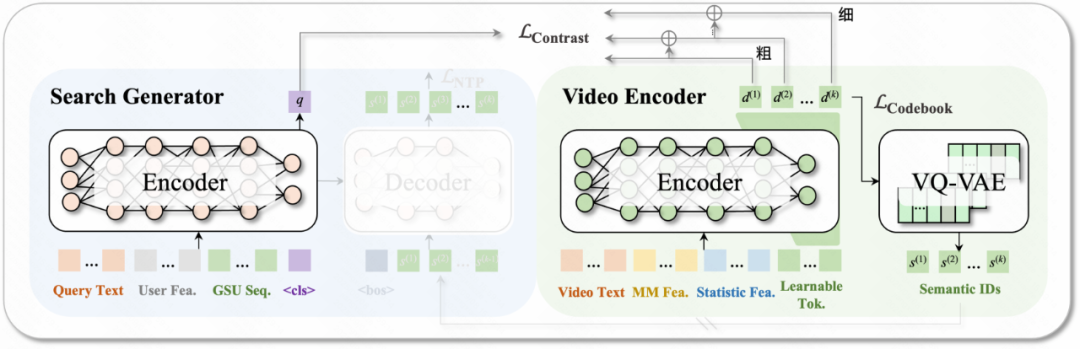
UniDex
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)