AI学习笔记整理(20)—— AI核心技术(深度学习4)
1、卷积神经网络使用一个三层的序列组合:卷积、下采样(池化)、非线性映射(LeNet-5最重要的特性,奠定了目前深层卷积网络的基础)2、使用卷积提取空间特征3、使用映射的空间均值进行下采样4、使用TANH或sigmoid进行非线性映射5、多层神经网络MLP作为最终分类器。
神经网络类算法
-
前馈神经网络(FFNN):基础结构,信息单向流动,适用于简单任务如手写数字识别 。
-
卷积神经网络(CNN):专为网格数据设计,通过卷积核和池化操作处理图像、音频等数据,广泛应用于图像分类、目标检测 。
-
循环神经网络(RNN):处理序列数据,但存在梯度消失问题,变体如LSTM和GRU改进了长期依赖处理能力 。
CNN与传统FNN的区别
卷积神经网络(Convolutional Neural Networks,CNN)是前馈神经网络(Feed - Forward Neural Network,FFNN)的一种特殊形式,其核心结构符合前馈神经网络的定义,但通过引入卷积层、池化层等机制优化了图像等数据的处理能力。
前馈神经网络(FFNN)是一种信号单向传播的人工神经网络,由输入层、隐含层和输出层组成,各层神经元仅与相邻层连接,无反馈或循环结构 。
主要区别:
CNN在FFNN基础上增加了卷积层(提取局部特征)、池化层(下采样(downsamples),对输入的特征图进行压缩,降低数据维度)和全连接层(最终分类),但整体仍保持单向传播特性 。
- 特征提取:CNN通过卷积核自动提取图像局部特征(如边缘、纹理),而传统FNN需手动设计特征 。
- 参数共享:CNN的卷积核在图像上滑动时共享参数,显著减少计算量 。
- 平移不变性:CNN对图像平移具有鲁棒性,适合视觉任务 。
- 应用场景
CNN因高效处理图像数据,成为计算机视觉的核心模型,而传统FFNN更适用于通用非时序任务 。
卷积神经网络(CNN)常见架构
参考链接:https://cloud.tencent.com/developer/article/1885536
卷积神经网络是一种包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。
常见的CNN网络有LeNet-5、AlexNet、VGGNet、GoogleNet、ResNet、DenseNet、MobileNet等。
LeNet-5
LeNet5卷积神经网络源于Yann LeCun在1998年发表的论文:Gradient-based Learning Applied to Document Recognition,是一种用于手写数字识别的卷积神经网络。LeNet-5是CNN网络架构中最知名的网络模型,是卷积神经网络的开山之作。
Lenet模型总结:
1、卷积神经网络使用一个三层的序列组合:卷积、下采样(池化)、非线性映射(LeNet-5最重要的特性,奠定了目前深层卷积网络的基础)
2、使用卷积提取空间特征
3、使用映射的空间均值进行下采样
4、使用TANH或sigmoid进行非线性映射
5、多层神经网络MLP作为最终分类器
AlexNet
Alexnet模型由5个卷积层和3个池化Pooling 层 ,其中还有3个全连接层构成。
ALexnet模型小结:
1、AlexNet 跟LeNet结构类似,但使⽤了更多的卷积层和更⼤的参数空间来拟合⼤规模数据集 ImageNet。它是浅层神经⽹络和深度神经⽹络的分界线。。
2、由五层卷积和三层 全连接组成,输入图像为三通道224×224大小,网络规模远大于LeNet(32×32)。
3、所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快。
4、在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模。
5、使用**随机丢弃技术(dropout)**选择性地忽略训练中的单个神经元, 可以作为正则项防止过拟合,提升模型鲁棒性,避免模型的过拟合。
VGGNet
VGGNet由牛津大学提出,是首批把图像分类的错误率降低到10%以内的模型,该网络采用3×3卷积核的思想是后来许多模型基础。VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。到目前为止,VGG仍然被用来提取图像特征。VGG可以看成是加深版本的AlexNet。都是conv layer + FC layer
VGGNet基本单元都一样:卷积、池化、全连接模块,常用的是VGG16-3以及VGG19。
VGG模型小结:
1、整个网络都使用 了同样大小的卷积核尺寸3 X3和最大池化尺寸2 X2。
2、1 X1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
3、两个3 X3的卷积层串联相当于1个5 X5的卷积层,感受野大小为5 X5。同样地,3个3 X3的卷积层串联的效果则相当于1个7 X7的卷积层。这样的连接方式使得网络参数量更小。而且多层的激活函数令网络对特征的学习能力更强。
4、VGGNet 在训练时有一个小技巧,先训练浅层的的简单网络VGGII,再复用VGG11的权重来初始化VGG13,如此反复训练并初始化VGG19,能够使训练时收敛的速度更快。
GoogleNet
googlenet作为2014年ILSVRC在分类任务上的冠军,以6.65的错误率%超过VGG等模型,其网络结构核心部分为inception块,它是一个并联网络块,经过不断的迭代优化,发展出了Inception-v1、Inception-v2、Inception-v3、Inception-v4、Inception-ResNet共5个版本。Inception家族的迭代逻辑是通过结构优化来提升模型泛化能力、降低模型参数。VGG在深度做扩展;Googlenet在广度上做扩展,inception块模型如下:
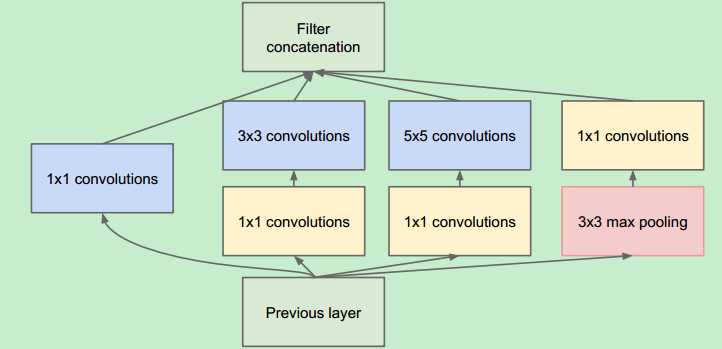
Googlenet模型小结
1、采用不同大小的卷 积核意味着不同大小的感受紧,最后拼接意味着不同尺度特征的融合:
2、之所以卷积核 大小采用1.3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0. 1. 2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了:
3、网络越到后面, 特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3×3 和5×5卷积的比例也要增加。但是,使用5×5的卷积核仍然会带来巨大的计算量。为此, 采用1×1卷积核来进行降维。
ResNet
通俗来讲,就是在一个浅层的网络模型上进行改造,然后将新的模型与原来的浅层模型相比较,这里有个底线就是,改造后的模型至少不应该比原来的模型表现要差。因为新加的层可以让它的结果为0,这样它就等同于原来的模型了。这个假设是ReNet的出发点,核心就是残差块。
ResNet模型小结
1.超深的网络结构(突破1000层)
2.提出residual模块(残差结构)
3.使用Batch Normalization加速训练(丢弃dropout)
4.除了残差块,还使用批量归一化:BN层
DenseNet
CVPR2017年的Best paper,从特征角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少网络的参数量,又在一定程度上缓解了gradient vanishing问题。
DenseNet模型小结
1、相比ResNet拥有更少的参数数量;
2、旁路加强了特征的重用;
3、网络更易于训练,并具有一定的正则效果;
4、缓解了gradient vanishing(梯度消失)和model degradation(模型退化)的问题。
MobileNet
MobileNet是谷歌在2017年提出,专注于移动端或者嵌入式设备中的轻量级CNN网络。
MobileNet的基本单元是深度可分离卷积,其可以分解为两个更小的操作:depthwise convolution和pointwise convolution。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)