从“对齐”到“理解”!深度解析QwenCLIP,看懂LLM如何为医学视觉注入“语言灵魂”?
Contrastive Language–Image Pretraining(CLIP)作为视觉语言预训练的经典框架,在计算机视觉与医学领域均展现出强大的泛化能力,但其文本编码器存在77 个 token 的输入长度限制,难以处理包含详细解剖结构描述、影像发现与诊断结论的长文本放射学报告。

Contrastive Language–Image Pretraining(CLIP)作为视觉语言预训练的经典框架,在计算机视觉与医学领域均展现出强大的泛化能力,但其文本编码器存在77 个 token 的输入长度限制,难以处理包含详细解剖结构描述、影像发现与诊断结论的长文本放射学报告。
为解决这一问题,现有研究多采用 PubMedBERT、ClinicalBERT 等领域专用编码器,虽能通过医学语料预训练提升语义理解,但仍受限于512 个 token 的输入瓶颈,且语义表征深度不足。
针对上述缺陷,本文提出QwenCLIP 框架:将 CLIP 的文本编码器替换为基于大语言模型(LLM)的嵌入模块(如 Qwen3-Embedding),同时引入可学习提示(Learnable Prompt)增强跨模态对齐。借助 LLM 的超长上下文窗口与丰富语义表征能力,QwenCLIP 可完整捕捉长文本临床报告中的医学语义,显著提升医学图文对齐效果与放射学基准任务性能。实验表明,在 ROCOv2、IRMA 等医学数据集的零样本图像检索任务中,QwenCLIP 持续超越 CLIP、ClinicalCLIP、PMC-CLIP 及 LLM2CLIP 等基线模型,验证了其在医学视觉语言任务中的优越性。
(1)突破文本长度瓶颈,重构文本编码架构
针对传统 CLIP 与医学 BERT 模型的输入长度限制,首次将专用 LLM 嵌入模型(Qwen3-Embedding) 引入医学视觉语言框架。相比通用生成式 LLM(如 LLaMA-3),Qwen3-Embedding 原生适配语义表征任务,无需复杂的 “生成转判别” 二次训练,在保留超长上下文处理能力(支持远超 512token 的长文本)的同时,降低计算开销与架构适配难度。
(2)设计混合提示调优策略,提升跨模态对齐精度
提出 “静态显式提示 + 动态可学习软提示” 的混合方案:
静态提示(如 “Instruct:”“query:”)为 LLM 提供任务导向线索,明确文本输入的 “指令属性” 与 “检索属性”;
可学习软提示(初始化文本为 “Create a dense embedding that represents the medical meaning of this text for image retrieval”,含 15 个 token)通过训练动态优化,在保留 LLM 预训练语言先验的同时,适配医学领域语义空间,解决传统固定模板(如 “a photo of a…”)在医学场景中的适配性不足问题。
(3)优化视觉语言对比学习目标,统一模态表征空间
在保留 CLIP 视觉编码器(ViT-B/16)核心结构的基础上,为 LLM 文本编码器添加两层 MLP 投影头,将高维文本嵌入映射至与视觉特征一致的 latent 空间;采用对称 InfoNCE 损失(图像到文本 + 文本到图像双向损失),强化匹配图文对的相似度,抑制不匹配对干扰,确保医学图文语义的精准对齐。
(4)构建全面实验验证体系,证实方法有效性
在 ROCOv2(多模态医学图像)、IRMA(X 射线图像)两大数据集上,设计零样本图像检索任务,采用 CUI@K(基于概念唯一标识符的检索精度)、Precision@K(top-K 检索准确率)等专业指标,系统对比 QwenCLIP 与 5 类基线模型的性能;通过消融实验单独验证 “LLM 文本编码器” 与 “可学习提示” 的贡献,形成完整的方法有效性证据链。
3.1 医学视觉语言预训练的核心价值
医学图像分析高度依赖专家标注,但人工标注存在成本高、周期长、主观性强等问题。视觉语言预训练技术通过 “图像 - 文本对” 的自监督学习,可从海量临床数据(如 PACS 系统中的放射图像与报告、PubMed 文献中的医学图注)中自动学习跨模态语义关联,为医学图像检索、诊断辅助等任务提供通用表征,大幅降低对人工标注的依赖,成为医学 AI 领域的研究热点。
3.2 现有方法的三大关键瓶颈
(1)文本输入长度限制
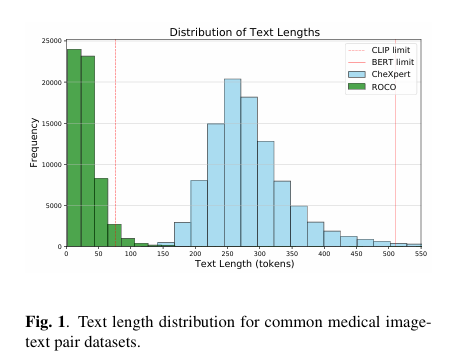
传统 CLIP 的文本编码器仅支持 77 个 token,而放射学报告常包含数百个 token(如 “胸部 CT 平扫示双肺上叶见多发磨玻璃密度影,边界模糊,最大径约 8mm,纵隔内未见明显肿大淋巴结,心影大小形态正常,双侧胸腔未见积液”),直接输入会导致关键信息截断,严重破坏图文语义对齐。
(2)语义表征深度不足
PubMedBERT、ClinicalBERT 等医学专用 BERT 模型虽能处理医学术语,但受限于 Transformer 架构的浅层语义建模能力(通常为 12 层左右),难以捕捉长文本中 “影像特征 - 解剖位置 - 诊断结论” 的复杂关联(如 “磨玻璃影” 与 “早期肺癌” 的潜在语义联系),且 512token 的输入限制仍无法覆盖多章节临床报告。
(3)LLM 集成的架构适配难题
近期研究(如 LLM2CLIP)尝试将生成式 LLM(如 LLaMA)引入 CLIP,但需通过 “caption 对比微调” 将生成模型转换为判别式编码器,存在两阶段训练流程复杂、计算开销大、生成与编码架构不匹配等问题,难以在医学场景中高效应用。
3.3 技术机遇:LLM 的超长上下文与语义能力
近年来,大语言模型(LLM)在上下文处理与语义理解上取得突破:例如 Gemini 2.5 Pro 支持 100 万 token 输入,Qwen3-Embedding 等专用嵌入模型优化了语义表征能力,可完整处理长文本临床报告,并捕捉其中的细粒度医学语义;同时,提示调优技术(Prompt Tuning)可通过少量参数微调,使 LLM 快速适配特定任务,为解决医学图文对齐难题提供了新路径。
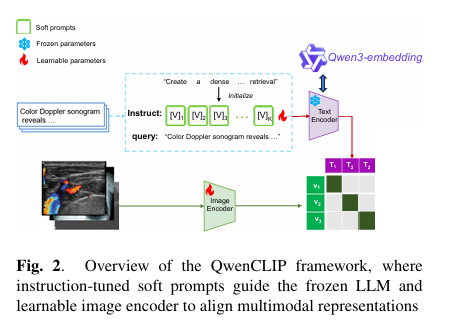
QwenCLIP 的核心设计围绕 “LLM 文本编码” 与 “跨模态对齐” 展开,整体架构分为混合提示调优模块、视觉 - 文本编码模块、对比学习训练模块三部分,具体流程如图 2 所示(原文 Fig.2)。
4.1 混合提示调优模块:适配医学文本语义
4.1.1 提示结构设计
针对医学文本的 “任务导向性” 与 “语义复杂性”,QwenCLIP 将原始文本 T 重构为 “静态提示 + 可学习软提示 + 原始文本” 的组合输入 T’,具体形式为:T’ = [Instruct: Pₛ, query: T]
静态提示(Instruct:/query:):“Instruct:” 明确后续输入为任务指令,引导 LLM 聚焦 “医学语义嵌入” 目标;“query:” 标记原始文本为检索相关内容,避免 LLM 将报告中的 “患者信息”“检查设备” 等非核心内容误判为语义重点。
可学习软提示(Pₛ):由 K 个与词嵌入维度相同的可学习向量构成(Pₛ = [V]₁[V]₂…[V]ₖ),本文中 K=15,初始化为 “Create a dense embedding that represents the medical meaning of this text for image retrieval”。训练过程中,Pₛ与模型参数联合优化,动态调整 LLM 的语义关注方向(如优先捕捉 “影像特征”“诊断结论” 等关键信息)。
4.1.2 文本编码流程
采用 Qwen3-Embedding-8B 作为文本编码器,该模型为专用语义嵌入模型,无需额外微调即可输出高维 dense 向量;为降低计算成本,训练时冻结 LLM 权重,仅通过 Pₛ与后续 MLP 投影头适配医学场景,同时采用 float16 半精度计算,减少 GPU 内存占用(适配 NVIDIA A100 80GB 显卡)。
4.2 视觉 - 文本编码模块:统一跨模态表征空间
4.2.1 视觉编码器
采用ViT-B/16作为视觉编码器,初始化权重来自原始 CLIP 预训练模型(保留通用视觉特征提取能力)。输入医学图像先 resize 至 224×224,再分割为 16×16 的图像块(patch),通过 Transformer 编码器输出 768 维的视觉特征向量 v(v = H_visual (I),I 为输入图像)。
4.2.2 模态投影层
由于 Qwen3-Embedding 输出的文本特征维度(通常为 4096 维)与视觉特征维度(768 维)不一致,在文本编码器后添加两层 MLP 投影头:第一层采用 ReLU 激活函数,将高维文本特征压缩至中间维度;第二层无激活函数,将中间特征映射至 768 维,最终得到文本特征向量 t(t = MLP (H_text (T’))),确保 v 与 t 处于同一 latent 空间,可直接计算相似度。
5.1 实验设计概述
实验核心目标是验证 QwenCLIP 在医学零样本图像检索任务中的性能 —— 即模型未经过检索任务的微调,直接利用预训练表征完成检索,更能体现通用表征能力。实验采用 “模型对比 + 消融验证” 的双维度设计,具体如下:
5.2 数据集介绍
(1)ROCOv2:多模态医学图像数据集
数据来源:PubMed Central 开源文献中的医学图像与图注;
数据规模:训练集 60163 张、验证集 9945 张、测试集 9972 张;
数据特点:涵盖超声、CT、MRI 等多种模态,图像平均文本长度 32 个 token,4.4% 的文本超过 CLIP 的 77token 限制,适合测试长文本处理能力;
任务设计:
CUI@K:基于 “概念唯一标识符(CUI)” 的检索精度,计算查询图像与候选图像的 CUI 交集(IoU),按 IoU 排序后用 NDCG 公式计算 top-K 检索精度;
Precision@K:按 “模态(如超声 / CT)”“器官(如肺 / 肝)”“模态 + 器官” 三个维度划分检索类别,计算 top-K 检索结果中相关样本的比例。
(2)IRMA:X 射线图像数据集
数据来源:14000 张人体不同部位的 X 射线图像;
标注特点:每张图像关联 13 位 “IRMA 代码”,包含模态(如 X 射线)、拍摄方向(如正位 / 侧位)、解剖部位(如胸部 / 膝关节)等信息;
任务设计:按 “器官” 维度划分检索类别,计算 Precision@K 指标,验证模型在单一模态(X 射线)下的检索能力。
5.3 基线模型选择
选择 5 类代表性模型作为对比,覆盖传统 CLIP、医学专用 CLIP、LLM 集成 CLIP 等类型,确保对比的全面性:
CLIP:原始模型,文本编码器为 GPT2-117M(77token 限制);
ClinicalCLIP:医学专用 CLIP,文本编码器为 ClinicalBERT-110M(512token 限制);
PMC-CLIP:基于 PubMed 文献预训练的 CLIP,文本编码器为 PubMedBERT-340M(512token 限制);
LLM2CLIP:集成生成式 LLM 的 CLIP,文本编码器为 Llama-3-Instruct-8B(需二次微调);
QwenCLIP:本文方法,文本编码器为 Qwen3-Embedding-8B(无明显 token 限制)。
5.4 核心实验结果
5.4.1 ROCOv2 数据集结果
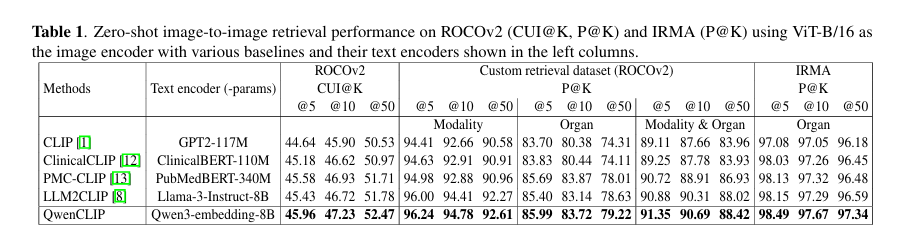
QwenCLIP 在 CUI@K 指标上全面领先,CUI@5 比 CLIP 高 1.32 个百分点,证明其医学概念表征的精准性;
在 Precision@5 指标上,QwenCLIP 在 “模态”“器官”“模态 + 器官” 任务中分别比最优基线(LLM2CLIP)高 0.24、0.59、0.47 个百分点,体现其对医学细分类别的强判别能力。
5.4.2 IRMA 数据集结果
关键结论:在 X 射线单一模态场景中,QwenCLIP 的器官 Precision@5 比 LLM2CLIP 高 0.34 个百分点,Precision@50 高 0.75 个百分点,证明其在特定医学模态下的检索稳定性更优。
5.5 消融实验结果
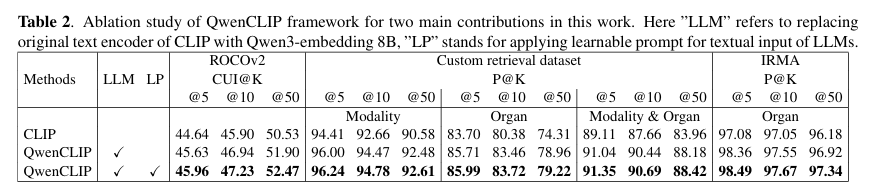
仅替换 LLM 文本编码器即可使 CUI@5 提升 0.99 个百分点,器官 Precision@5(IRMA)提升 1.28 个百分点,证明 LLM 的语义表征优势;
加入可学习提示后,CUI@5 进一步提升 0.33 个百分点,器官 Precision@5(IRMA)提升 0.13 个百分点,验证提示调优对医学语义适配的增益。
QwenCLIP 通过 “LLM 嵌入模块 + 混合提示调优” 的创新设计,有效解决了医学视觉语言预训练中的文本长度限制与语义对齐难题,主要工作总结如下:
技术突破:首次将专用 LLM 嵌入模型(Qwen3-Embedding)引入医学 CLIP 框架,突破 77/512token 的输入限制,可完整处理长文本放射学报告;混合提示调优策略实现 LLM 与医学任务的高效适配,无需复杂二次训练。
性能优势:在 ROCOv2、IRMA 数据集的零样本图像检索任务中,QwenCLIP 在 CUI@K、Precision@K 等指标上持续超越传统 CLIP、医学 BERT-based CLIP 及 LLM2CLIP,验证了其在多模态医学图像分析中的优越性。
实用价值:模型训练流程简洁(仅需冻结 LLM、微调视觉编码器与 MLP),计算成本可控(支持 A100 GPU 训练),代码开源可复现,为医学图像检索、辅助诊断等实际应用提供高质量预训练模型。
局限性:目前仅验证零样本图像检索任务,未涉及医学图像分类、分割等下游任务;LLM 嵌入模型的计算开销仍高于 BERT 模型,未来可通过模型压缩(如量化、蒸馏)进一步优化部署效率。
7.1 方法层面:LLM 为医学跨模态任务提供新范式
QwenCLIP 的成功证明,专用 LLM 嵌入模型是解决医学长文本处理的有效路径:相比生成式 LLM,专用嵌入模型无需 “生成 - 判别” 转换,架构更简洁;相比 BERT 模型,LLM 的超长上下文与深层语义建模能力更适配医学复杂文本。这为医学 NLP 与计算机视觉的交叉研究提供新思路 —— 未来可将 LLM 嵌入应用于医学图文生成(如报告自动撰写)、跨模态诊断(如 CT 与 MRI 图像的语义融合)等任务。
7.2 实验层面:建立医学跨模态任务的专业指标体系
传统跨模态任务多采用 Precision@K 等通用指标,QwenCLIP 引入CUI@K 指标,通过医学概念唯一标识符(CUI)量化图文语义关联,更贴合临床实际需求(如医生通过 “磨玻璃影” 等概念检索相似病例)。这提示科研人员在设计医学 AI 实验时,应结合医学领域知识构建专用评价体系,避免仅依赖通用指标导致的 “技术 - 临床脱节”。
7.3 应用层面:推动医学数据的高效利用
QwenCLIP 可直接从 “未标注图像 - 报告对” 中学习通用表征,无需人工标注,为海量临床数据的价值挖掘提供可能。例如,医院 PACS 系统中积累的数百万放射图像与报告,可通过 QwenCLIP 预训练形成医院专属的跨模态模型,为基层医院提供本地化诊断辅助,助力医疗资源下沉。
7.4 未来方向:多模态融合与模型轻量化
QwenCLIP 目前聚焦 “图像 - 文本” 双模态,未来可扩展至 “图像 - 文本 - 音频” 多模态(如手术视频 + 语音解说 + 手术记录);同时,LLM 嵌入模型的参数量较大(8B),可通过模型量化(如 Qwen3 量化模型,支持多平台部署)、知识蒸馏(将 8B 模型压缩为 1B 模型)等技术,降低硬件门槛,推动在移动端、边缘设备的应用(如便携式超声设备的实时诊断辅助)。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献282条内容
已为社区贡献282条内容

所有评论(0)