第208期 如何借助AI辅助编程的实用方法?
如今,大多数代码的编写都有AI辅助。问题不在于我们在开发过程中是否会使用大型语言模型(LLMs),而在于如何使用它们。在三个月的时间里,我利用大型语言模型在前端、后端和AI管道中构建实际功能,发现极端的方式是行不通的:完全手动编写代码速度太慢,而当代码库扩大时,纯粹的“氛围编程”(vibe coding)会崩溃。目前最实用的工作流程是混合式的:由人类定义架构,AI辅助实现,最后由人类监督并完善结果
AI拉呱,专注于人工智领域与AI工具、前沿技术解读。AI技术书单+提示词+优秀项目(含源码)+教程 ==网盘链接:https://pan.quark.cn/s/e4ada86e0476
如今,大多数代码的编写都有AI辅助。问题不在于我们在开发过程中是否会使用大型语言模型(LLMs),而在于如何使用它们。在三个月的时间里,我利用大型语言模型在前端、后端和AI管道中构建实际功能,发现极端的方式是行不通的:完全手动编写代码速度太慢,而当代码库扩大时,纯粹的“氛围编程”(vibe coding)会崩溃。目前最实用的工作流程是混合式的:由人类定义架构,AI辅助实现,最后由人类监督并完善结果。
如何在工程团队中利用大型语言模型编写可维护代码
在使用大型语言模型编写了大量代码后,我决定采用一种中间路线的工作流程,介于完全手动编写代码和纯粹“氛围编程”之间,大概处于38%的位置。以下是一些能帮助我为长期项目编写高质量代码的方法:

- 如果你计划长期使用某些新工具,就要学习这些新工具和相关架构,并在自己完全不熟悉的领域亲自练习编写代码
- 当使用较新的框架时,多进行手动编码,直到自己对架构和设计有了清晰的理解后,再转而使用AI辅助
- 与智能体(agent)协作时,要进行细致的规划,并采用规范驱动开发(spec-driven development)的方式
- 让AI生成测试并自行测试功能,但之后仍需进行手动测试。有时候AI过于“想帮上忙”,为了满足你实现某个功能的要求,它甚至会删除那些难以覆盖到的测试用例
- 每次只使用一个智能体,并密切关注它的工作情况。这样一来,如果智能体出现偏离方向的情况,你就能尽早中断它的工作
- 对待AI要像对待初级开发人员一样。你需要自己清楚要实现什么目标以及如何实现,然后让AI去处理那些小型且描述清晰的功能模块
- 对AI生成的代码进行精简和简化,尤其是当你知道其他开发人员还会继续在此基础上工作时
我认为,我们永远不会完全信任大型语言模型,将所有工作都交给它们,从而完全失去对代码库中情况的掌控。正因为如此,我相信升级代码库最实用的方法是与AI协作,并且能够理解AI所做的每一项工作。也正因为如此,代码的未来发展方向介于极端的“氛围编程”和完全手动编程之间。
何时使用极端的“氛围编程”
“氛围编程”仍然有其用武之地,在以下场景中,不进行任何代码编辑就使用“氛围编程”是有效的:
- 快速搭建原型以传达你的想法
- 搭建非常简单的项目,例如登录页面
- 在已有的结构化代码库中实现定义明确、规模较小且常规的更改(比如在前端代码库中添加第50个组件,或者在后端应用中实现第5个路由)
- 编写一次性的脚本和模块,且这些脚本和模块不会被代码库中的其他部分调用
完整内容
开始“氛围编程”之前
众所周知,只需一个提示词(prompt),你就能得到出色的结果并完成原型搭建。但是,如果沿着这条路走下去,短短几个小时后,你就会陷入困境——你会发现自己面对的是一个包含2000多行代码的文件,由于这个文件中的上下文和逻辑量过大,没有任何大型语言模型能帮你在这个项目中再添加任何功能了。

极端的“氛围编程”往往会让你以100倍的速度遇到软件开发周期中常见的问题😉。
如果你使用自己熟悉的语言和框架进行“氛围编程”,还能很容易地发现问题所在,并引导大型语言模型重新编写代码。但如果在过去几个月里你一直采用“氛围编程”的方式,可能会逐渐忘记如何手动编写代码,也会忘记哪种技术栈和方法才是最合适的😅。
因此,我可以肯定地说,与大型语言模型协作的首要原则是掌握基础知识并自行搭建架构。即使大型语言模型能够生成良好的架构模式,你仍然需要理解这些模式;否则,你将完全不清楚代码库中发生了什么。而当你无法验证AI输出的结果时,就无法对系统进行升级。
目前,像Replit这样的在线编辑器正试图通过添加多智能体系统来解决这个问题——一个智能体负责编写代码,另一个架构师智能体负责审查代码。但这些多智能体系统还处于初级阶段,它们生成的结果仍然不可靠。
如果你确实想从零开始用大型语言模型编写代码,且现有代码库中没有可参考的示例,那么最好的办法是将“氛围编程”生成的部分与代码的其他部分明确区分开,并确保不会有外部模块从这个“氛围编程”生成的模块中导入内容。所以,第二条原则就是将“氛围编程”的部分与其他代码区分开。
“氛围编程”的主要挑战之一是调试大型语言模型编写的代码,尤其是当这些代码是由其他人通过“氛围编程”生成的时候。我认为出现这种情况的原因是,大型语言模型是基于互联网上的大量数据进行训练的,对于普通的提示词,它生成的结果也是互联网上的平均水平。但这个平均水平的结果往往比你实际需要的更冗长,而且可能已经过时。
因此,第三条原则是不要在冷门语言或新框架中使用“氛围编程”。大型语言模型在某个领域的训练数据越少,生成的结果可靠性就越低。我在使用Cursor智能体编程时,见过最糟糕的情况是用它编写使用LangChain技术栈的代码。LangChain问世才几年时间,发展速度非常快,最近已经经历了三次重大更新。用AI生成的LangChain相关代码不仅冗长程度是实际需要的2到10倍,而且往往根本无法运行。
当然,也有一些方法可以部分解决这个问题,比如对最新的文档进行索引,或者使用Context7 MCP工具。
但对我而言,我意识到如果要在一个新的环境中开展大量工作,在切换到智能体模式之前,仍然需要阅读相关文档并手动编写一些代码。
工作流程
我认识的大多数开发人员都是这样使用大型语言模型的:
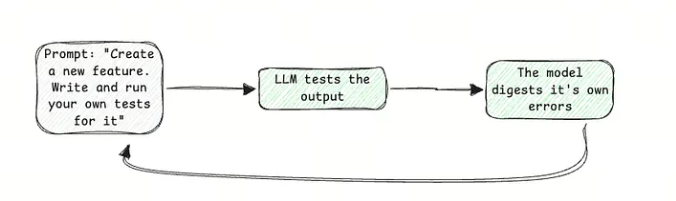
你仍然需要进行手动验证,但在此之前得到的结果会好得多。
这个循环的效果相当不错。不过,在这个流程中存在一个问题:有时你会发现AI生成的结果并不理想,这时要么需要进行大量手动修改,要么就得完全重写。要应对这个问题,你还需要遵循以下几条额外的原则:
提供尽可能多的相关上下文
不妨站在AI的角度思考,从AI的视角看待你交给它的任务。如果你是AI,仅凭提供的上下文,能完成这项任务吗?
有一些方法可以改进你的工作流程,比如在任务跟踪工具或Notion数据库中使用MCP(可能指某种项目管理或上下文管理工具)。但我在这方面的尝试收效甚微,因为使用10个以上的工具会让上下文变得臃肿,AI也难以正确使用这些工具。而且这些MCP工具还处于早期阶段,即便只是从Jira(项目管理工具)工单中获取信息,我也常常需要非常明确地让AI去查询某个特定工单,运气好的话,尝试三次才能成功🙃。
对我来说,有效的方法是在第一个提示词中使用元提示(meta-prompting),具体操作如下:
- 告诉AI:“我想实现一个新功能,这里有很多关于这个功能的非结构化上下文信息。请生成一个能帮助我实现这个功能的提示词。”
- 找出与你要处理的任务相关的所有上下文信息(包括任务的非结构化描述、文档、相关数据、通话记录等),并将每个上下文片段用标签包裹起来
- 对生成的文本进行优化,满意后就可以将其作为在集成开发环境(IDE)中使用的初始提示词
处理小型功能模块
在Nebius学院(Nebius.Academy)的指导工作中,我设计了一个挑战,用于练习AI辅助编程。我提供了一个吃豆人(PacMan)游戏的代码仓库,并要求学生对这个游戏进行一些修改。
你可以通过这里查看这个挑战,并亲自尝试一下。
简单的挑战往往无需查看代码库就能完成。
中等难度的挑战则更棘手一些——你需要将任务分解,一步一步完成。但如果试图一次性完成,AI虽然会很“乐意”生成一些内容,但那些内容往往毫无意义。
这是Replit AI智能体完成中等难度挑战的情况——有些功能能正常运行,但“外星人”的行为却很反常。
而高难度的挑战在工作坊中从未有人能完成,这类挑战需要对代码库有更深入的理解,并且需要进行非常细致的规划。
像对待初级/中级开发人员一样对待AI
在确认AI生成的计划合理之前,不要让它开始执行任务。
小贴士:目前已经出现了一些有助于实现这一点的模式和库,比如.cursorrules、Kiros规划阶段等。其中,OpenSpec是我使用后取得了不错效果的工具,它有助于生成项目描述,而且你要开发的每个功能都能遵循清晰的流程。
OpenSpec模式下与AI协作进行修改的流程
不过,即便使用了像OpenSpec这样的工作流程,我在使用过程中还是会遇到一些不确定的问题——如果在规划阶段遗漏了某些内容该怎么办?目前,大家似乎更倾向于在规范中补充信息,然后重新生成代码,但这种方法可能会耗费大量时间。还有一种更实用的方法是通过额外的指令引导AI,但之后你还需要单独修改规范。
此外,当你积累了大量规范后,可能需要通过索引或检索增强生成(RAG)技术来高效管理这些规范。更糟糕的是,如果规范与代码不同步,那么这些规范很可能完全派不上用场。或许我们需要调整工作流程,让每一项任务都通过规范来生成——这样既能提供最新的文档,也能为AI提供大量相关的上下文。但这需要所有开发人员都遵循相同的规范驱动开发流程,而我个人尚未在团队中尝试过这种方式。
关注AI的工作,在其偏离方向时及时中断
我曾与Anthropic公司的一位销售人员交流,他提到Anthropic的工程师能同时运行6个智能体。我也尝试过这样做,但即便同时运行2到3个智能体,那种感觉也像是最糟糕的多任务处理。因此,目前我认为,即使在规划阶段做得很充分,也应该密切关注智能体的工作,并与它协同合作。这就好比在开发阶段发现bug,而非在代码审查阶段才发现bug——如果在AI生成代码出现问题时及时阻止它,就能更快得到理想的结果。
未来展望
在国际象棋领域,曾有一个时期,人类与AI协作的实力强于单独的人类或单独的AI。但这一时期在大约十年后就结束了,AI凭借自身实力成为了最强者。
如今,编程领域也正处于类似的阶段——一个懂得如何与AI协作的优秀程序员,其效率是单独的程序员或单独的AI的10倍。
展望未来,我愿意相信,与国际象棋领域的情况不同,我们总能找到与AI协作并发挥自身作用的方式。让我们从现在开始,实践这种协作方法吧。
关注“AI拉呱”,评论+转发此文即可私信获取一份教程+一份学习书单!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)