猫头虎的创作5周年纪念日:猫头虎,不知不觉今天已经是成为创作者的 第1825天(5年) 啦,为了纪念这一天,特写此文
摘要: 本文回顾了作者"猫头虎"作为科技自媒体人5年来的创作历程。从技术爱好者到全职创作者,作者分享了实战经验、学习记录和技术交流的创作初衷。5年间收获46万粉丝、2200万+博客访问量,发布2000+篇技术文章,涵盖全栈开发、AI等领域。通过代码示例帮助开发者解决问题,并计划未来拓展视频内容与线下交流。文章展现了技术分享的价值与个人成长的喜悦,表达了对持续创作的期待与行业贡献
我的创作5周年纪念日:猫头虎
今天,已经是我作为创作者的第1825天(也就是5年)了。在这五年的时光里,我从一个技术爱好者成长为了一名全职的科技自媒体人,走过了无数个日日夜夜,也收获了丰厚的成果和难忘的经历。为了纪念这个特别的时刻,我写下这篇文章,与大家分享我的创作历程、所获得的成就,以及未来的展望。
机缘
回顾我成为创作者的初心,主要源自几个方面的契机和动机。
-
实战项目中的经验分享
作为一名开发工程师,我参与了多个实际项目,遇到了许多技术难点和挑战。每解决一个问题,我都会有强烈的分享欲望,尤其是面对复杂的系统架构、技术选型、以及性能优化等问题时。于是,我决定将自己的实践经验通过文章的方式与大家分享,帮助更多同行少走弯路。 -
日常学习过程中的记录
学习是永无止境的,尤其是在技术领域,每天都会接触到新的知识和技能。我常常在学习过程中遇到疑惑,解决了问题后就想通过文章总结并记录下来,这不仅能帮助自己加深理解,还能帮助其他人克服类似的困难。记录学习过程成为了我创作的一部分。 -
通过文章进行技术交流
创作的初衷之一也是为了更好地与同行进行技术交流。通过文章发布,不仅能够获得其他开发者的反馈,还能够与他们一起探讨解决方案、分享思路,推动自己的成长。
收获
在这五年的创作过程中,我获得了很多的收获。以下是我在创作过程中所取得的一些成就和经验:
粉丝与互动数据
-
粉丝数量
在这五年间,我的粉丝数不断攀升,目前已经达到了465,908人,粉丝的关注和支持是我不断前进的动力。 -
内容互动
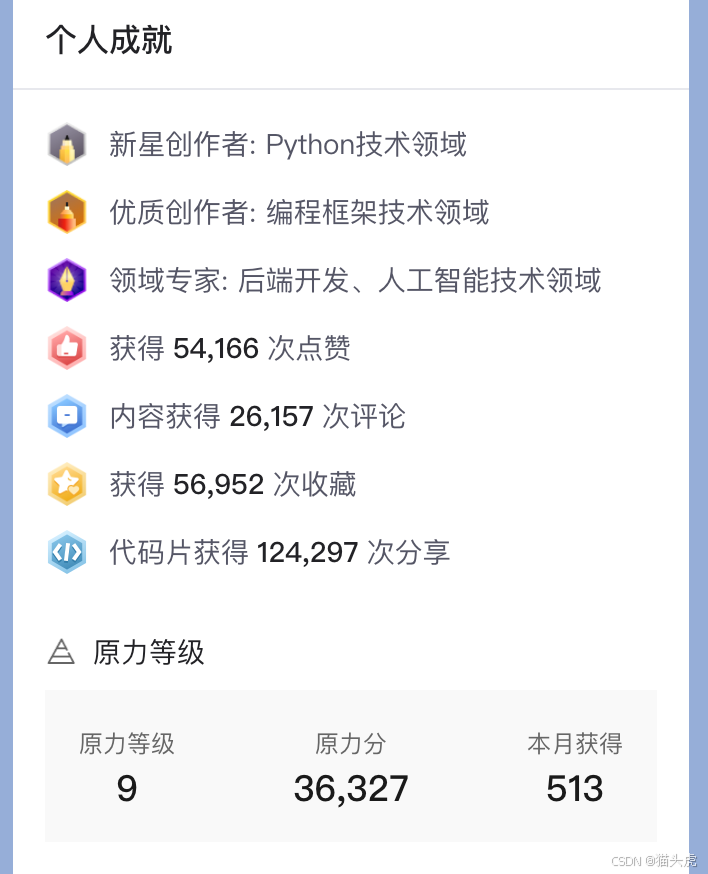
通过我的创作,我获得了:- 54,166次点赞
- 26,157次评论
- 56,952次收藏
- 其中,有124,297次分享的代码片段,说明我的技术内容在读者中得到了广泛的传播与应用。
-
博客流量
我的博客总访问量已经突破了22,258,901次,这一数字代表着无数读者的点击与关注,也象征着我的内容得到了广泛的认可与传播。
创作数量
我发布了大量的原创文章,以下是每年的文章发布情况:
| 年份 | 发布文章数量 | 粉丝数量 |
|---|---|---|
| 2025年 | 529篇 | 465,908 |
| 2024年 | 666篇 | 290,908 |
| 2023年 | 999篇 | 229,908 |
| 2022年 | 239篇 | 100,908 |
| 2021年 | 209篇 | 50,908 |
| 2020年 | 39篇 | 5,908 |
这些文章涉及广泛的技术领域,包括全栈开发、AI、云原生等。每篇文章都凝聚了我的思考与努力,尤其是其中涉及产品评测、技术教程和技术问题解决的内容,帮助了大量的技术人员。
日常
创作已经深深地融入了我的日常生活中,尤其在工作、学习和创作之间找到平衡,是我日常生活的一部分。
-
创作成为生活的一部分
通过持续的内容创作,我已经将技术写作和分享作为日常的一部分。即使在繁忙的工作之余,我也会抽时间写作、录制视频、参与技术社区活动。创作不仅是我的工作,它更是我热爱的事业。 -
如何平衡工作与创作
在有限的精力下,如何平衡工作、学习与创作,是我一直思考的问题。我的方法是充分利用碎片化时间进行创作。比如在晚上或周末,我会专注于写作或录制视频内容,同时在工作中遇到问题时,我会将解决过程记录下来,形成文章或教程。这种平衡让我在忙碌的工作中也能坚持创作。
成就
在这五年的创作历程中,我觉得最值得骄傲的成就就是帮助无数开发者解决问题,提供高质量的技术内容。我写过的最好的一段代码是某个AI项目中的数据处理和模型训练部分,以下是代码示例:
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 数据加载
data = pd.read_csv("data.csv")
# 数据预处理
X = data.drop("target", axis=1)
y = data["target"]
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
# 预测结果
y_pred = model.predict(X_test)
# 模型评估
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
这段代码帮助许多初学者理解了机器学习的基本流程,尤其是数据预处理、模型训练和评估,受到了广泛的分享与点赞。
憧憬
对于未来,我有着明确的职业规划和创作目标:
-
职业规划
作为AI全栈工程师,我将继续深化在AI、云原生等前沿技术的研究与实践,并为企业和技术团队提供更加先进的解决方案。此外,我也希望通过更多的企业合作与产品评测,推动技术创新与应用。 -
创作规划
在创作方面,我计划扩大内容的传播渠道。除了文字与代码分享,我还将逐步加强视频内容的制作,结合直播与视频教学,进一步拓展影响力。同时,我也希望能够继续参与线下技术沙龙与行业大会,与更多的技术同行面对面交流,分享心得。
通过这些努力,我希望能够继续帮助开发者成长,也为技术领域的发展贡献自己的力量。
感谢大家一直以来的支持与关注,我将继续为大家带来更多有价值的技术内容,期待与大家一起探索、一起成长!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)