共享与隔离的艺术—探索Gridview的“多租户”
多租户技术的本质,是在 “共享” 与 “隔离” 这对核心矛盾中寻找动态平衡。它不仅是云计算成本优势的技术根基,更是支撑数字经济规模化发展、科研创新加速推进的关键架构 —— 在 HPC 与 AI 计算领域,多租户技术的突破让昂贵的算力资源变得更普惠,中小企业与科研机构无需投入巨资即可获得顶尖算力支持。从硬件级强隔离到软件定义的灵活隔离,从静态资源分配到智能动态调度,从通用场景适配到 HPC/AI 专
1. 多租户:云计算的核心架构基石
多租户技术,常见于云计算领域,是支撑云服务高效交付的核心架构模式,其本质是 “逻辑隔离,物理共享”—— 即单个云平台或应用实例能同时为多个独立租户(租户可理解为企业、组织或团队)提供服务,租户间共享底层计算、存储、网络等物理资源,却能保持数据、配置和业务逻辑的相互独立。这种架构彻底改变了传统 IT “一对一部署” 的模式,通过资源复用实现了成本与效率的双重优化,成为 SaaS、IaaS、PaaS 等云服务形态的底层支撑,同时也在高性能计算(HPC)、AI 计算等算力密集型领域展现出巨大应用价值。
简单来说,多租户就像一栋 “云服务公寓楼”:公寓的地基、墙体等基础设施(物理资源)由所有住户(租户)共享,降低了单户居住成本;但每个住户拥有独立的房间(逻辑隔离空间),配备专属钥匙(权限控制),确保生活隐私与安全互不干扰。从商业价值看,它让中小企业能以低成本享受企业级云服务,让科研机构、AI 团队以按需付费模式使用昂贵的算力资源,同时让云厂商通过资源高密度部署提升盈利能力。

对于Gridview来说,算力集群可以看作地基,内存、CPU、加速卡等物理资源可看作基础设施;Gridview平台中,每个用户可作为租户共享基础设施,而每个团队就像是一个独立的一户,逻辑上隔离计算资源,就像每户单独计费计量水电气一样,每个团队独立计算资源用量或费用。每个团队还可配置独占队列,就像每个房间拥有自己的厨房,在运行算力作业时,无需排队等待。
2. 多租户架构的三大核心需求与现实挑战
多租户架构的设计需在 “安全、性能、成本” 三者间寻找精妙平衡,其核心需求可归纳为三点:
-
资源隔离性:租户间数据、计算、存储资源严格隔离,避免某一租户的异常行为(如流量激增、恶意攻击)影响其他租户,这是多租户信任体系的基础;
-
性能可预期性:无论其他租户负载如何变化,每个租户都能获得稳定的响应时间与吞吐量,满足业务连续性要求;
-
成本效益比:通过资源复用降低单租户使用成本,同时兼容不同租户的差异化需求(如大型企业对安全的高要求、中小企业对性价比的敏感,以及 HPC/AI 租户对算力密集型任务的专属需求)。
然而实际落地中,这些需求常存在内在矛盾,尤其在 HPC 与 AI 计算领域,挑战更为突出:
-
隔离粒度的取舍:细粒度隔离(如独立虚拟机)安全性高,但资源开销大,难以满足 HPC 大规模并行计算的低延迟需求;粗粒度隔离(如共享内核容器)效率高,却面临侧信道攻击风险,且无法适配 AI 训练中多卡协同的算力调度需求;
-
动态负载的适配:租户业务存在 “潮汐效应”(如电商大促、办公早高峰),而 HPC/AI 租户的负载波动更剧烈 ——AI 模型训练可能突发占用数百 GPU 算力,HPC 仿真任务可能持续数天占用全部 CPU 资源,静态资源分配易导致资源浪费或任务排队;
-
工作负载的冲突:不同租户可能运行计算密集型、I/O 密集型等不同类型任务,HPC 的 MPI 并行任务与 AI 的分布式训练任务共存时,会加剧网络带宽与缓存资源的竞争,导致任务执行效率大幅衰减;
-
专属资源的适配:AI 训练依赖 GPU、NPU、海光DCU 等专用算力芯片,HPC 依赖高带宽低延迟的 InfiniBand 网络,多租户共享时需解决专用硬件的隔离与调度难题,避免不同租户的芯片资源抢占。
Gridview在这方面有多种不同的方式来应对挑战,首先是会为每个团队设置计算限额,限制每个团队成员(租户)对计算资源的使用量。通过合理分配限额,可以有效避免某一租户的计算爆发对其他租户的影响。

Gridview还会为每个团队分配共享存储,并为每个成员分配家目录,这样租户间的存储空间也能实现资源隔离,避免敏感信息泄露。共享存储和家目录同样会设置存储配额,避免租户间引发资源竞争,保证高性能计算作业与AI作业的稳定运行。
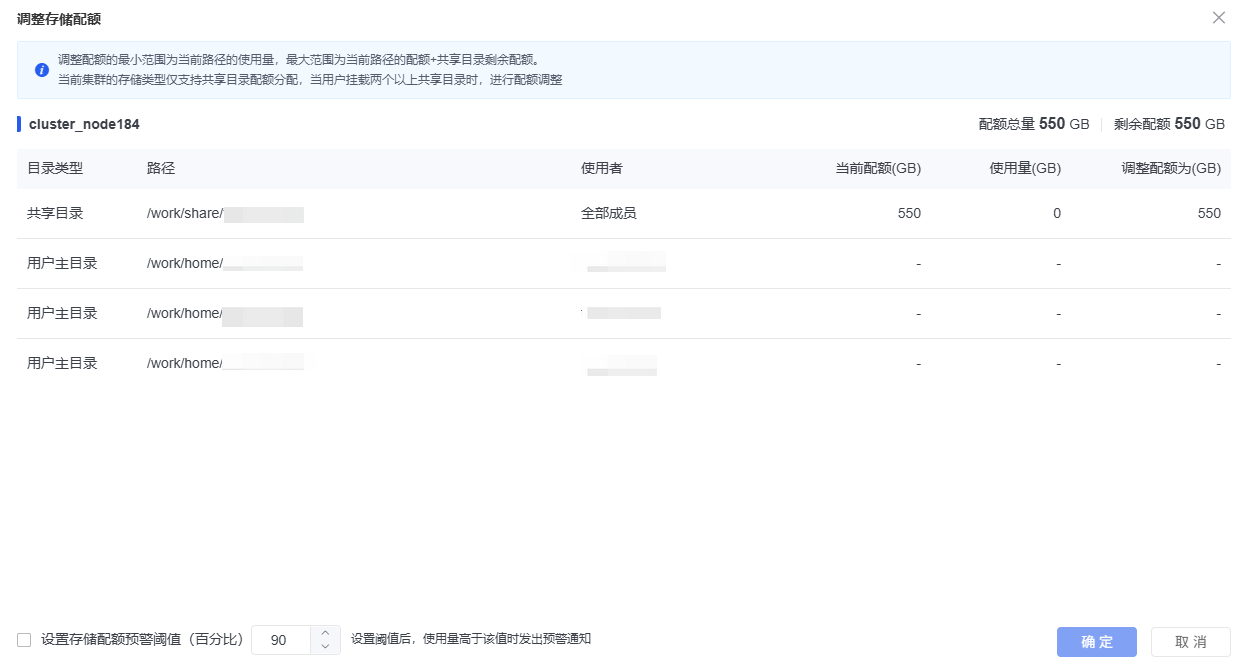
对于AI训练方面,Gridview为AI队列配置最大运行时长、最大作业数、单账户最大DCU卡数等参数配置,以此来优化多租户共享算力时的隔离与调度问题,避免租户间的芯片抢占,从而实现安全、性能、成本的平衡。

3. 多租户的核心技术:资源隔离的三重路径
资源隔离是多租户架构的技术核心,其演进始终围绕 “隔离强度” 与 “资源效率” 的权衡展开,当前主流技术路径可分为三类,其中针对 HPC 与 AI 计算的专属优化方案已成为业界重点突破方向:
3.1 硬件级隔离:安全优先的强隔离方案
通过硬件虚拟化技术(如 Intel SGX、AMD SEV)为租户创建加密 “飞地”(Enclave),实现内存、CPU 缓存等底层资源的物理隔离。在 HPC 领域,可通过 Intel OneAPI、NVIDIA HPC SDK 等硬件加速套件,为租户分配独立的 CPU 核心与 GPU 算力,结合 PCIe 通道隔离技术,避免多租户共享 GPU 时的显存带宽竞争;在 AI 领域,NVIDIA 的 Multi-Instance GPU(MIG)技术可将单块 GPU 划分为多个独立实例,每个租户获得专属显存与计算核心,支持同时运行多个训练任务,隔离粒度细至 1/7 块 GPU,兼顾资源利用率与任务独立性。
存储层方面,可为 HPC 租户分配并行文件系统(如 Lustre、GPFS)的独立存储分区,通过 RDMA 技术保障数据传输低延迟;为 AI 租户配置 NVMe-oF 高速存储池,结合数据分层缓存策略,确保训练数据的专属访问通道。这种方案适用于金融风控 AI 模型训练、气象模拟 HPC 任务等安全与性能双重敏感场景,但硬件成本较高,需针对专用芯片进行定制化部署。
3.2 轻量级虚拟化:效率与安全的平衡之选
以容器技术为代表的轻量级虚拟化,通过共享主机内核实现高密度部署与快速启动,已成为云服务的主流选择,针对 HPC 与 AI 的容器优化方案已形成成熟生态:
-
命名空间隔离增强:在传统 PID、Network 命名空间基础上,新增 GPU 命名空间(如 NVIDIA Container Runtime)、RDMA 命名空间,实现 GPU 资源与高速网络的专属分配,适配 HPC MPI 任务与 AI 分布式训练的通信需求;
-
安全容器适配:Kata Containers 针对 HPC 场景优化了虚拟机启动速度,支持秒级部署千级容器实例,配合 InfiniBand 网络透传技术,将容器间通信延迟降低至微秒级;Firecracker 结合 AWS Trainium/Inferentia 芯片,为 AI 租户提供轻量级虚拟机隔离,支持 TensorFlow、PyTorch 等框架的无缝适配;
-
侧信道防护升级:针对 AI 训练中 GPU 共享的安全风险,通过 NVIDIA GPU Shield 技术实现显存加密与访问控制,避免租户间通过显存侧信道窃取模型参数;HPC 场景则通过 CPU 缓存分区技术(如 Intel CAT),隔离不同租户的缓存资源,减少并行任务的缓存抖动。
3.3 软件定义隔离:灵活适配的逻辑隔离
对于 Web 应用、无状态服务等场景,可通过软件中间件实现逻辑隔离,而 HPC 与 AI 计算领域的软件定义隔离更侧重算力调度与任务编排的精细化:
-
调度器定制化:采用 HPC 专用调度器(如 Slurm、PBS)与 AI 调度器(如 Kubeflow、Volcano)的融合方案,Slurm 负责 CPU/HPC 任务的资源分配,Volcano 负责 GPU/AI 任务的调度,通过租户配额管理(Tenant Quota)限制单个租户的最大算力占用;
-
数据库与存储隔离:AI 训练数据常存储于对象存储(如 S3、OSS),通过租户专属存储桶与访问密钥实现数据隔离,结合数据湖分层管理(热数据存 NVMe、冷数据存 OSS)优化访问效率;HPC 仿真数据则通过并行文件系统的租户配额与目录隔离,确保不同租户的数据集互不干扰;
-
权限控制增强:通过 RBAC 与 ABAC 结合的权限模型,为 HPC/AI 租户分配细粒度权限 —— 科研租户可访问特定 GPU 集群,企业租户可限制训练任务的最大运行时长,同时支持基于项目角色的资源共享(如多团队协作训练同一 AI 模型时的资源临时授权)。
4. 结语
多租户技术的本质,是在 “共享” 与 “隔离” 这对核心矛盾中寻找动态平衡。它不仅是云计算成本优势的技术根基,更是支撑数字经济规模化发展、科研创新加速推进的关键架构 —— 在 HPC 与 AI 计算领域,多租户技术的突破让昂贵的算力资源变得更普惠,中小企业与科研机构无需投入巨资即可获得顶尖算力支持。
从硬件级强隔离到软件定义的灵活隔离,从静态资源分配到智能动态调度,从通用场景适配到 HPC/AI 专属优化,多租户技术的每一次演进,都在推动云服务向更安全、更高效、更普惠的方向发展。在云原生、边缘计算、AI 大模型的技术浪潮下,多租户将持续成为云计算与算力服务创新的核心赛道,为企业数字化转型、科研突破与产业升级提供更坚实的技术支撑。
Gridview的用户资源体系将在多租户领域不断深耕,从上层用户逻辑结构到底层资源物理结构,简化了租户数据的高效管理,同时又依托多租户架构保障了系统的安全性、扩展性,实现 “租户数据独立可控、操作体验简洁高效” 的核心目标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)