Ludwig:Uber开源的无需编码的AI模型构建神器
Ludwig是Uber开源的基于TensorFlow的深度学习工具箱,于2019年2月正式对外开放。该项目采用Apache 2.0开源协议,其核心理念是让开发者无需编写代码就能够训练和测试深度学习模型。与其他AI开发框架不同,Ludwig最大的特点是其声明式的模型定义方法。用户只需要通过一个YAML配置文件来指定输入输出特征,无需关心底层的实现细节。这种设计使得AI开发变得异常简单,即使是经验较少
在AI技术日益复杂的今天,Uber开源的Ludwig正以其独特的"零代码"理念,降低AI应用开发的门槛,让开发者能够更专注于模型本身而非实现细节。
项目简介:AI开发的民主化实践
Ludwig是Uber开源的基于TensorFlow的深度学习工具箱,于2019年2月正式对外开放。该项目采用Apache 2.0开源协议,其核心理念是让开发者无需编写代码就能够训练和测试深度学习模型。
与其他AI开发框架不同,Ludwig最大的特点是其声明式的模型定义方法。用户只需要通过一个YAML配置文件来指定输入输出特征,无需关心底层的实现细节。这种设计使得AI开发变得异常简单,即使是经验较少的深度学习开发者也能轻松为不同任务训练模型。
Uber开发Ludwig的初衷是为AI开发者提供更好的深度学习能力理解工具,并推进模型快速迭代。对于AI专家来说,Ludwig可以简化原型设计和数据处理过程,让他们能专注于开发深度学习模型架构。

核心功能:全方位简化AI开发流程
Ludwig提供了一系列强大的功能,使AI模型开发变得简单而高效:
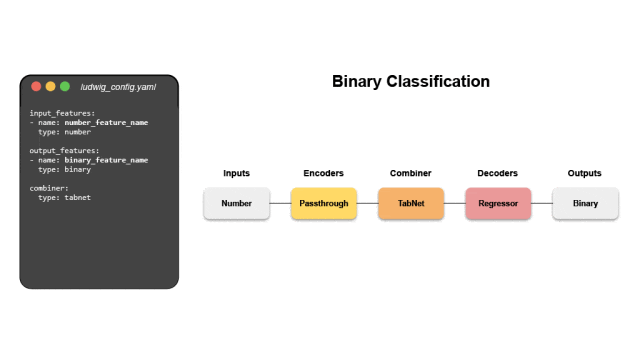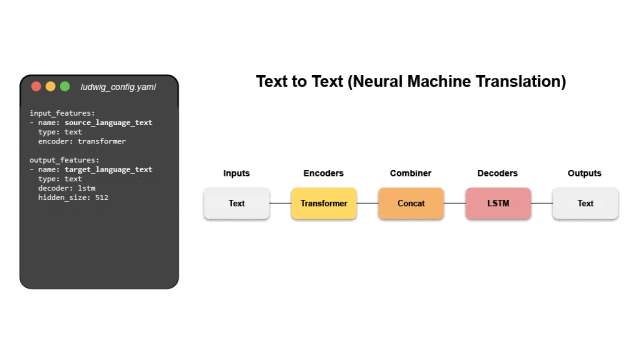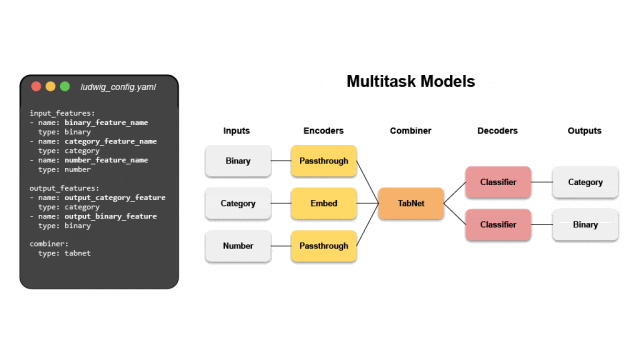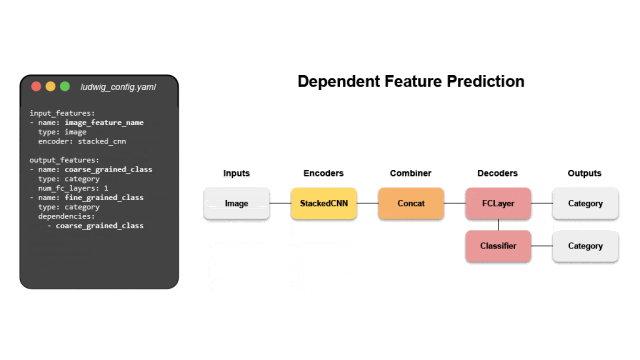
1. 声明式模型定义
只需一个表格数据文件(如CSV)和一个YAML配置文件,就能开始模型训练。配置文件中指定数据文件哪些列是输入特征,哪些列是输出目标变量,支持多输入多输出场景。
2. 灵活的编码器-解码器架构
Ludwig为每种支持的数据类型提供了将原始数据映射到张量的编码器,以及将张量映射到原始数据的解码器。内置的组合器能够自动将所有输入编码器的张量组合在一起进行处理。
3. 多数据类型支持
Ludwig支持多种数据类型,每种类型有多个编码器和解码器。例如:
-
文本:可以用CNN、RNN或其他编码器编码
-
图像:支持多种图像编码方式
-
数值数据:支持二进制值、浮点数、类别等
4. 广泛的适用任务
通过组合特定于数据类型的组件,用户可以将Ludwig用于各种任务,包括:
-
文本分类和目标分类
-
图像字幕和序列标签
-
回归和语言建模
-
机器翻译和时间序列预测
-
问答系统等
5. 分布式训练支持
Ludwig能够使用开源分布式培训框架Horovod,在多个GPU上训练模型,并快速迭代。
6. 可视化与评估工具
提供丰富的可视化工具,用于评估模型并通过可视化比较预测结果。可以直观展示训练过程中损失和准确性的变化趋势。
安装与使用方法:快速入门指南
环境要求与安装
Ludwig支持多种安装方式,最简单的是通过pip安装:
pip install ludwig
基本使用流程
使用Ludwig通常包含以下几个步骤:
-
准备数据:将训练数据整理为CSV格式,确定输入特征列和输出目标列
-
创建配置文件:编写YAML文件定义模型结构,例如:
input_features:
-
name: title
type: text
-
name: author
type: category
-
name: description
type: text
-
name: cover
type: image
output_features:
-
name: genre
type: category
-
name: price
type: numerical
training:
epochs: 10
citation:1
-
训练模型:使用命令行开始训练:
ludwig train --data_csv path/to/file.csv --model_definition_file model_definition.yaml
-
模型预测与评估:使用训练好的模型进行预测并评估性能
Python API使用
除了命令行,Ludwig还提供了Python编程API:
from ludwig import LudwigModel
# 训练模型
model_definition = {...}
model = LudwigModel(model_definition)
train_stats = model.train(training_dataframe)
# 或加载模型
model = LudwigModel.load(model_path)
# 获取预测
predictions = model.predict(test_dataframe)
model.close()
citation:1
技术架构:模块化设计的精妙之处
Ludwig的技术架构基于编码器-解码器模式,每个数据类型都有对应的编码器和解码器实现。这种设计提供了极大的灵活性,用户可以根据需要组合不同的组件。
核心架构包括:
-
输入特征编码器:将原始输入数据转换为模型可处理的特征表示
-
组合器:将所有编码后的特征组合成一个统一表示
-
输出特征解码器:将模型输出解码为目标任务所需的格式
训练过程中,Ludwig会自动进行数据预处理、模型训练和验证,无需用户干预。系统还支持从训练好的模型中提取配置和参数,便于后续的模型部署和使用。
优势对比:Ludwig的差异化价值
与其他深度学习框架相比,Ludwig具有多个明显优势:
|
特性 |
Ludwig |
传统深度学习框架 |
|---|---|---|
|
上手难度 |
低(无需编码) |
高(需要编写大量代码) |
|
开发效率 |
高(快速迭代) |
低(调试耗时) |
|
灵活性 |
高(组合式架构) |
中(依赖预定义模型) |
|
可维护性 |
高(配置驱动) |
低(代码分散) |
|
适用人群 |
从初学者到专家 |
主要面向专业人士 |
实际应用案例:从理论到实践
案例:书籍信息预测
在一个实际例子中,Ludwig被用于根据书名、作者、描述和封面来预测一本书的类型和价格。数据集包含这些字段,模型配置指定了四个输入特征(书名、作者、描述、封面)和两个输出目标(类型、价格)。
通过简单的配置,Ludwig自动处理了不同数据类型的编码:
-
文本数据(书名、描述)使用文本编码器
-
分类数据(作者)使用类别编码器
-
图像数据(封面)使用图像编码器
-
输出包括分类结果(类型)和数值预测(价格)
训练完成后,用户可以可视化训练过程中的损失和准确性变化,并使用模型对新数据进行预测。
项目发展与未来规划
自开源以来,Ludwig一直在积极发展中。Uber计划为每种数据类型添加新的编码器,如用于文本的Transformer、ELMo和BERT,以及用于图像的DenseNet和FractalNet。还将添加其他的数据类型,比如音频、点云和图形。
项目也在不断集成更多可扩展的解决方案来管理大数据集,如Petastorm。这些持续的改进使得Ludwig在处理复杂实际问题时能力不断增强。
总结
Ludwig作为一款开创性的深度学习工具箱,通过其独特的零编码理念、灵活的架构设计和丰富的功能支持,极大地降低了AI应用开发的门槛。无论是AI初学者还是资深专家,都能从中受益——初学者可以快速上手深度学习概念,专家则可以专注于模型创新而非实现细节。
随着AI技术的普及和民主化,像Ludwig这样降低技术门槛的工具将发挥越来越重要的作用。其开源特性也意味着社区可以共同推动项目发展,让AI技术惠及更广泛的开发者群体。
项目地址:[https://github.com/ludwig-ai/ludwig]
前些天小妖发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给 大家。点击https://www.captainbed.cn/13y跳转到网站。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)