【LLM】DeepSeekMath-V2模型
研究问题:这篇文章要解决的问题是如何在大型语言模型(LLMs)中进行自我验证的数学推理。具体来说,现有的基于最终答案奖励的强化学习方法在数学推理中存在根本局限性,因为正确答案并不能保证推理的正确性,特别是在定理证明任务中。研究难点:该问题的研究难点包括:如何在不依赖最终答案的情况下验证推理的正确性;如何在生成和验证之间建立有效的迭代改进循环;如何在没有已知解决方案的开放问题上扩展测试时计算。相关工
note
DeepSeek 正式发布了 DeepSeekMath-V2 模型,基于 DeepSeek-V3.2-Exp-Base。展示了自我验证的数学推理能力。通过训练模型识别和解决自身推理中的问题,超越了基于最终答案的奖励方法。
https://github.com/deepseek-ai/DeepSeek-Math-V2/blob/main/DeepSeekMath_V2.pdf,https://huggingface.co/deepseek-ai/DeepSeek-Math-V2,https://github.com/deepseek-ai/DeepSeek-Math-V2。
一、研究背景
DeepSeekMath-V2 模型
DeepSeek 正式发布了 DeepSeekMath-V2 模型,基于 DeepSeek-V3.2-Exp-Base,https://github.com/deepseek-ai/DeepSeek-Math-V2/blob/main/DeepSeekMath_V2.pdf,https://huggingface.co/deepseek-ai/DeepSeek-Math-V2,https://github.com/deepseek-ai/DeepSeek-Math-V2
已官宣拿下金牌的两大模型,一款来自谷歌Gemini Deep Think,另一款便来自OpenAI的内部模型。模型效果:
IMO 2025:破解5题(共6题),达到了金牌水平;
CMO 2024(中国数学奥林匹克):达到金牌水平;
Putnam 2024:得分118接近满分(120分),超越人类参赛者最高分(90分)。
- 研究问题:这篇文章要解决的问题是如何在大型语言模型(LLMs)中进行自我验证的数学推理。具体来说,现有的基于最终答案奖励的强化学习方法在数学推理中存在根本局限性,因为正确答案并不能保证推理的正确性,特别是在定理证明任务中。
- 研究难点:该问题的研究难点包括:如何在不依赖最终答案的情况下验证推理的正确性;如何在生成和验证之间建立有效的迭代改进循环;如何在没有已知解决方案的开放问题上扩展测试时计算。
- 相关工作:该问题的研究相关工作有:OpenAI的推理模型在定量推理竞赛中取得了显著进展;DeepMind的DeepThink在IMO 2025中获得了金牌;Gemini 2.5 Pro展示了某种程度的自我验证能力;DeepSeek-Prover-V2和Seed-Prover在定理证明方面也取得了显著进展。
二、研究方法
这篇论文提出了DeepSeekMath-V2模型,用于解决自我验证的数学推理问题。具体来说,
1、证明验证:首先,训练一个验证器来识别证明中的问题并给证明打分。验证器的训练目标是通过强化学习生成证明分析,并根据以下两个奖励组件进行优化:
- 格式奖励 ( R format R_{\text{format}} Rformat):确保模型生成规范的“问题总结”和“证明分数”格式。
- 分数奖励 ( R score R_{\text{score}} Rscore):根据模型预测的分数 ( s i ′ s_{i}^{\prime} si′) 与真实标注分数 ( s i s_{i} si) 的接近程度给予奖励。
分数奖励的具体计算公式为:
R score ( s i ′ , s i ) = 1 − ∣ s i ′ − s i ∣ R_{\text{score}}\left(s_{i}^{\prime}, s_{i}\right) = 1 - \left| s_{i}^{\prime} - s_{i} \right| Rscore(si′,si)=1−∣si′−si∣
2、引入元验证:为了提高验证器的可靠性,引入了元验证,即通过另一个验证器评估初步验证器发现的问题是否存在,并且这些问题是否逻辑上合理地证明了预测的分数。元验证的训练过程与初步验证器类似,但使用了不同的奖励机制。
3、证明生成:其次,使用验证器作为生成奖励模型来训练一个证明生成器。生成器的训练目标是生成高质量的证明,并通过自我验证进行迭代改进。自我验证的奖励函数结合了格式奖励和分数奖励,以确保生成器能够准确评估自己的工作。
4、生成与验证的协同作用:最后,证明验证器和生成器之间形成了一个协同循环:验证器改进生成器,生成器生成新的证明,这些证明又成为验证器进一步改进的目标。通过自动标记难以验证的证明,提高了验证器的性能。
三、实验设计
- 数据收集:通过从Art of Problem Solving (AoPS)竞赛中爬取问题,并使用DeepSeek-V3.2-Exp-Thinking生成候选证明,然后由数学专家根据评价标准打分,构建了初始的训练数据集。
- 训练设置:使用Group Relative Policy Optimization (GRPO)进行强化学习,迭代优化证明验证和生成能力。每次迭代先优化验证器,然后从验证器的检查点初始化生成器进行优化。
- 评估基准:在内部CNML级别问题、IMO 2025、CMO 2024、Putnam 2024、ISL 2024和IMO-ProofBench等基准上进行评估。
四、结果分析
一次性生成:在内部问题上,DeepSeekMath-V2在所有类别(代数、几何、数论、组合和不等式)上均优于GPT-5-Thinking-High和Gemini 2.5-Pro,展示了卓越的定理证明能力。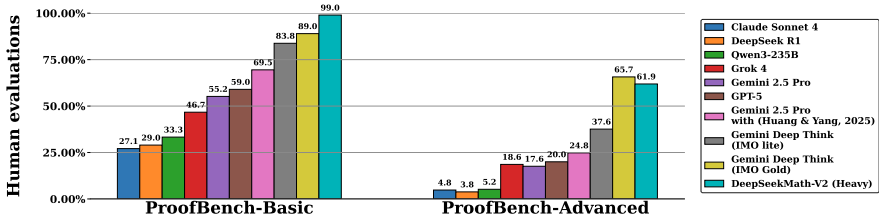
顺序改进与自我验证:对于IMO和CMO等竞赛中的挑战性问题,通过顺序改进和自我验证,证明质量显著提高。Pass@1和Best@32指标均显示出显著的改进。
高计算搜索:通过扩展验证和生成计算,解决了最具挑战性的问题。在IMO 2025和CMO 2024上取得了金牌成绩,在Putnam 2024上得分118/120,超过了人类最高分90分。
Reference

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)