LLM - RAG的文本分块最佳实践:原理、细节与工程化落地
本文深入探讨了RAG系统中文本分块的关键技术与优化策略。针对机械切分导致的语义断裂问题,提出基于语义完整性的智能分块原则,并对比基础版与进阶版分块算法的差异。通过引入内容类型识别、段落智能合并和动态Token控制,有效解决了表格/图片拆分、层级丢失等典型问题。文章还提供了可直接落地的代码实现,并强调分块策略对RAG系统召回率和准确率的重要影响。最后指出,贴近人类阅读方式的语义重构是提升AI理解能力
文章目录

引言
随着AI大模型(如GPT、Llama)技术的快速发展,RAG(Retrieval Augmented Generation)系统在企业级智能问答、知识库、搜索增强等场景日益普及。RAG的核心在于将长文档拆分为易于检索的语义块(Chunk),但分块方法直接决定系统的召回率、上下文理解与最终效果。本文将深入解析RAG文本分块的原理、常见误区、典型算法与项目落地细节,帮助开发者和研究者理解文本切分在RAG中的关键地位,并附有可直接应用的实战代码。
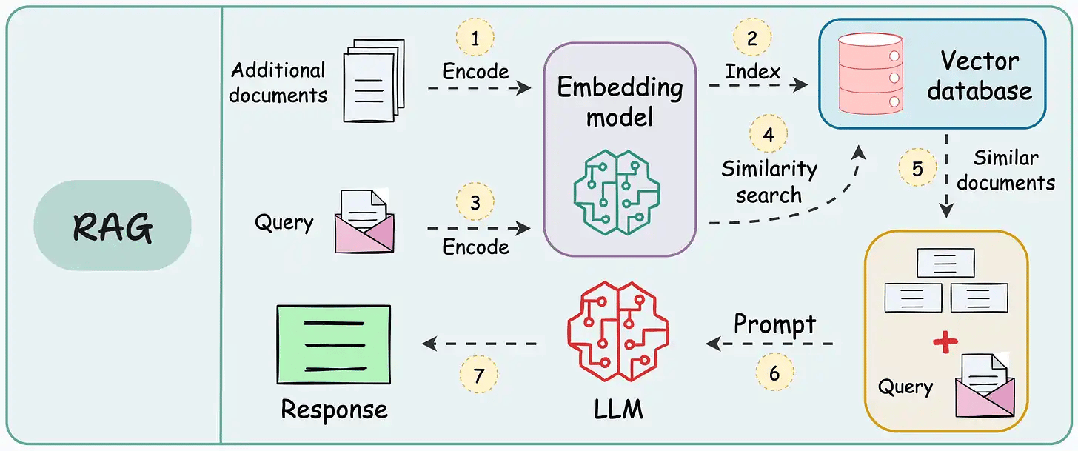
1. 分块理解:语义不是机械切分
初入RAG领域,许多人容易将分块等同于“定长切分”,例如每128个token一块。但这种做法简便却危险——直接打断语义、切散结构,严重影响模型的理解能力和检索精度。
1.1 错误示例
假设原文为:
通过对多个实验场景的分析,我们发现,在同等环境条件下,使用算法A可以将预测准确率从85%提高到90%以上;与算法B相比,算法A的训练时间也更短。
如果直接按照token切块:
- Chunk1:通过对多个实验场景的分析,我们发现,在同等环境条件下,
- Chunk2:使用算法A可以将预测准确率从85%提高到90%以上;
- Chunk3:与算法B相比,算法A的训练时间也更短。
此时主语与谓语、对比对象全部被拆散,后续检索时模型难以理解上下文关系,影响答案准确性。
1.2 结构化数据拆分风险
表格、图片等结构化信息若被机械切分,标题与内容脱节,数据丢失结构,导致无法正确检索:
| 序号 | 数据值 | 备注 |
|---|---|---|
| 001 | 23.7 | 正常 |
| 002 | 19.6 | 待观察 |
| 003 | 30.2 | 波动较大 |
机械切分后,表格、标题均可能“各自为政”,上下文丢失严重。
2. 正确的Chunk切分原则:语义完整性至上
优秀的分块不是定长处理,而是保证每个块都是完整、有意义的语义单元。具体要解决四类典型问题:
| 问题类型 | 表现 | 后果 |
|---|---|---|
| 表格/图片被拆开 | 标题和内容脱节 | 检索不到关联内容 |
| 段落被截断 | 句子断裂 | 语义丢失 |
| 层级丢失 | 标题正文混合 | 丢失文档结构上下文 |
| Chunk超长 | Token超限 | 模型截断、生成不精准 |
每项问题都足以让RAG系统精度严重偏离。
3. 分块算法实战:智能切分代码解析
3.1 基础版代码
def naive_merge(sections, chunk_token_num=128, delimiter="\n。;!?"):
if not sections: return []
if isinstance(sections[0], str):
sections = [(s, "") for s in sections]
cks = [""]
tk_nums = [0]
def add_chunk(t, pos):
nonlocal cks, tk_nums
tnum = num_tokens_from_string(t)
if not pos: pos = ""
if tnum < 8: pos = ""
if tk_nums[-1] > chunk_token_num:
if t.find(pos) < 0: t += pos
cks.append(t)
tk_nums.append(tnum)
else:
if cks[-1].find(pos) < 0: t += pos
cks[-1] += t
tk_nums[-1] += tnum
for sec, pos in sections:
add_chunk(sec, pos)
return cks
优点: 简单,稳定,易于上手。
缺点: 完全不理解语义与结构,容易引发上述问题。
3.2 进阶智能版代码
def advanced_merge(sections, chunk_token_num=128):
normalized_sections = []
for item in sections:
if isinstance(item, str):
normalized_sections.append((item, "", "text"))
elif len(item) == 2:
normalized_sections.append((item[0], item[1], "text"))
else:
normalized_sections.append(item)
cks = [""]
tk_nums = [0]
last_paragraph_id = None
def add_chunk(text_str):
nonlocal cks, tk_nums
tnum = num_tokens_from_string(text_str)
cks[-1] += text_str
tk_nums[-1] += tnum
def new_chunk(text_str):
nonlocal cks, tk_nums
tnum = num_tokens_from_string(text_str)
cks.append(text_str)
tk_nums.append(tnum)
for text, pos, ctype in normalized_sections:
tnum = num_tokens_from_string(text)
# 不可拆分类型(表格、图片)
if ctype in ("table", "image"):
if tnum > chunk_token_num:
new_chunk(text)
elif tk_nums[-1] + tnum > chunk_token_num:
new_chunk(text)
else:
add_chunk(text)
continue
# 段落智能合并
paragraph_id = None
if "paragraph_id=" in pos:
paragraph_id = pos.split("paragraph_id=")[-1]
is_same_paragraph = (paragraph_id is not None) and (paragraph_id == last_paragraph_id)
if is_same_paragraph and (tk_nums[-1] + tnum <= chunk_token_num):
add_chunk(text)
else:
if tk_nums[-1] + tnum > chunk_token_num and tk_nums[-1] > 0:
new_chunk(text)
else:
add_chunk(text)
last_paragraph_id = paragraph_id
return cks
核心优化:
- 表格/图片整体分块,结构不被拆散(chunk_type标签)。
- 段落内容智能合并,按语义保持完整,不随意断句。
- Token计数动态控制,超过阈值才新建块。
项目实战应用:
from service.ragflow.rag.nlp import advanced_merge
sections = [
("表1 实验结果统计", "(p1)", "title"),
("| 序号 | 数据值 | 备注 |", "(p1)", "table"),
("001 | 23.7 | 正常", "(p1)", "table"),
("结合上述数据可见,算法A表现稳定。", "(p1)", "text")
]
chunks = advanced_merge(sections, chunk_token_num=128)
# 输出结构化、语义完整chunks,后续可送Embedding/FAISS库
4. 切分优化的工程
Chunk切分:设计基于Token计数与内容类型的智能切分策略,保障表格/图片整体性与段落连续性,将跨页信息缺失率从30%降至5%。
扩展描述:
针对表格/图片在跨页断行易被拆分问题,引入智能切分策略,实现结构化信息完整保留、标题独立存储、段落语义合并,结构准确率提升至90%,RAG召回精度显著增强。
为什么RAG流程要Chunk切分?
RAG将长文档拆为可检索块,否则无法向量化。但切分不能盲目细化,需保证语义完整。我们的策略结合内容类型和Token限制动态切分,表格和图片保持整体、段落智能合并,并在超限时新建块,有效提升召回准确率与上下文连贯性。
问:如何防止表格和标题被拆开?
答:
在解析阶段标记chunk_type,切分时检测表格/图片整体保留,表格标题自动绑定到表格组,检索时上下文不丢。
5. RAG分块的系统价值
RAG Chunk切分是系统“脊梁骨”,决定模型记忆边界和理解能力。
分块太碎,语义丢失,模型答错可能性陡增。本质是技术约束下的语义重构,越贴近人类读文档方式,AI越能理解世界。
如今AI大模型市场高速发展,大模型岗位需求剧增,无论是应届毕业生还是传统技术人,都应掌握RAG落地方案。对开发者而言,切分策略的工程实践是迈向“AI智能体”时代关键门槛之一。
结论
- 分块不是机械断句,而是语义与结构完整性的重建。
- 切分算法需结合内容类型、结构语义、Token阈值实现智能分块,保障表格/图片/段落信息不丢失。
- 工程优化能显著提升RAG系统召回率、上下文连贯性与最终问答准确度。
- 技术博客、简历与面试环节要重点突出分块策略创新,反映工程能力与业务价值。
随着AI大模型技术进步与行业落地加速,文本切分技术将在RAG/Agent/知识问答等系统持续发挥核心作用。理解分块本质,优化分块策略,是每位技术人迈向AI新时代的必修课。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)