多模态大模型开发实战 -- Deepseek-OCR
DeepSeek-OCR以“上下文光学压缩”的理论创新为基石,以轻量部署、高精度解析、全场景适配为核心优势,打破了传统OCR与通用VLM之间的能力鸿沟。它不仅是一款OCR工具,更是多模态时代连接视觉信息与文本知识的关键桥梁,为科研创新、企业数字化转型、个人高效办公提供了强大动力。随着多模态RAG技术的普及,DeepSeek-OCR正成为文档理解领域的“标配引擎”,推动数字化处理迈入“精准理解”的新
一、多模态崛起
1.1 让大模型看懂世界
而在 2023 年之后,大模型技术的爆发彻底改变了视觉理解的格局。以 GPT-4V、Gemini 2、Qwen-VL、InternVL 等为代表的 多模态大模型(VLM,Vision-Language Model) 出现,让人工智能真正具备了“同时理解文字与图像”的能力。
多模态技术的核心思想是:将图像和语言映射到同一个语义空间中,让模型能够同时处理视觉信息和文本信息。这意味着,模型既能“看图识字”,又能“看图明意”——它能读懂论文 PDF、解析图表、理解建筑图纸、甚至生成 Markdown 结构的文本。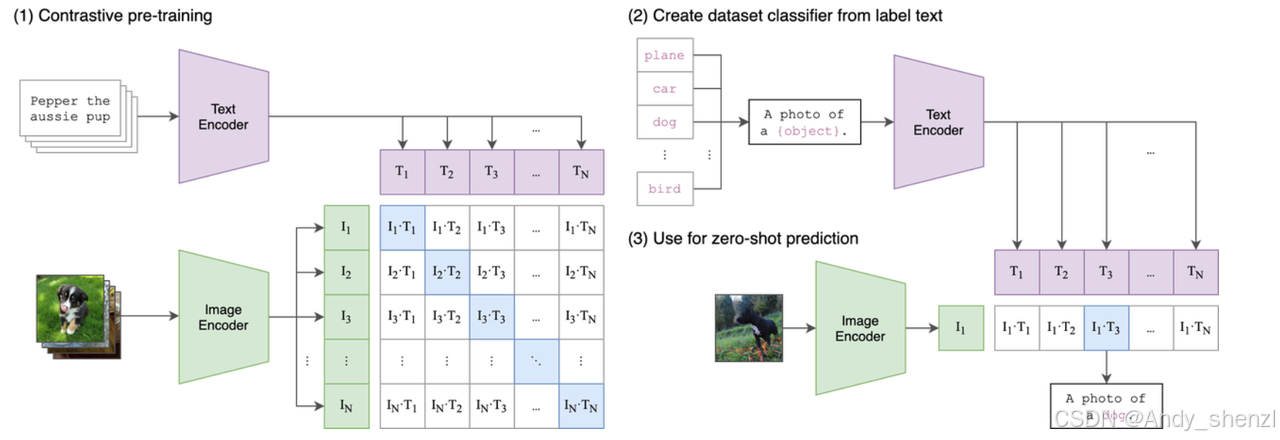
多模态技术的本质,是要让机器能够“同时理解文字与图像”。而实现这一点的关键,就是将图像与文本映射到同一个语义空间(Shared Semantic Space)中。换句话说,无论输入是一句话,还是一张图,模型都能在同一个高维表示空间里找到它们之间的语义对应关系。
这就像人类在看图表或阅读论文时,不仅识别出图形和文字,还能在大脑中把它们融合成“意义”:看到“上升趋势”这个图形,你会自动想到“增长”;看到公式,你能联想到逻辑推理。多模态模型正是试图在计算机中复现这种语义联想机制。而基于VLM进行OCR的工作,包括文字识别、版面识别(文档结构关系识别)等等,也被称为OCR 2.0。
1.2 VLM技术核心:视觉特征的语义映射(Vision-Language Alignment)
在现代多模态模型中,这种“图文对齐”通常分为三个关键步骤:
- 视觉编码(Vision Encoding)
首先,模型需要将图像转换为一组高维视觉特征向量(visual embeddings)。这一过程由 视觉编码器(Vision Encoder) 完成,最早的代表就是 CLIP 的 ViT 模块。视觉编码器通常采用 Transformer 架构(ViT 或 Swin Transformer),把一张图像切分为若干个小块(patch),每个 patch 都会映射成一个 token,最终得到一串图像向量序列:
[I=v1,v2,...,vn,vi∈Rd][I = {v_1, v_2, ..., v_n}, \quad v_i \in \mathbb{R}^d][I=v1,v2,...,vn,vi∈Rd]
这些向量就像语言模型中的单词嵌入(word embeddings),代表图像中不同区域的语义内容。 - 语言编码(Text Encoding)
与此同时,文本会被输入到 语言编码器(Text Encoder)(例如 GPT、LLaMA、T5 等)中,转换为相同维度的语言向量:
[T=t1,t2,...,tm,ti∈Rd][T = {t_1, t_2, ..., t_m}, \quad t_i \in \mathbb{R}^d][T=t1,t2,...,tm,ti∈Rd]
至此,图像和文本都被表示成一串高维 token。但这两种 token 来自不同模态,尚未处于“同一个语义空间”中。 - 图文对齐(Cross-Modal Alignment)
对齐机制的核心目标是:让视觉向量与语言向量在同一个空间中具有可比较的语义距离。实现方式主要有三种典型路径:
| 对齐方式 | 技术实现 | 特点 |
|---|---|---|
| 对比学习(Contrastive Learning) | 如 CLIP:通过大规模图文配对数据,让图像与文本 embedding 在向量空间中靠近 | 简单高效,训练稳定;但语义理解有限(主要停留在关联层面) |
| 特征投影(Projection Head) | 使用 MLP / Linear 层将视觉特征投射到语言模型 embedding 空间 | 可直接与 LLM 融合,但训练依赖下游任务 |
| 跨模态注意力(Cross-Attention) | 如 BLIP-2、LLaVA:通过交叉注意力层实现图像 token 与语言 token 的动态交互 | 理解深度强,可进行生成与推理任务 |
这三种方法可以理解为“从对齐到融合”的三步演进:
CLIP —— 对齐;BLIP —— 语义交互;LLaVA / DeepSeek-OCR —— 语义生成。
- 典型多模态架构
让我们看看目前主流的视觉语言模型是如何设计的:
| 模型 | 核心组成 | 技术特点 | 代表任务 |
|---|---|---|---|
| CLIP(OpenAI) | ViT(视觉编码器) + Transformer(文本编码器) | 大规模对比学习;统一特征空间 | 图文检索、图像分类、Zero-shot |
| BLIP / BLIP-2(Salesforce) | 图像编码器 + Q-Former + 语言模型 | 引入 Q-Former 作为视觉语义中介;提升语义对齐 | 图文生成、图像理解 |
| LLaVA(Visual Instruction Tuning) | CLIP ViT + 投影层 + LLaMA | 将视觉 token 直接映射到 LLM 输入 | 图文问答、多模态对话 |
| Qwen-VL / InternVL | 自研视觉编码器 + LLM 联合训练 | 支持复杂文档理解与视觉推理 | OCR 2.0、图文RAG |
| DeepSeek-OCR(DeepSeek-AI) | ViT 视觉编码器 + 文本解码器 + Prompt路由机制 | 专注文档解析;融合OCR任务 | PDF转Markdown、公式/表格解析 |
注:DeepSeek-OCR 正是在 LLaVA 类架构基础上,结合了高效的视觉压缩与 OCR 微调机制,形成了一种专用的 “视觉语言对齐 + 结构生成”模型。
二、DeepSeek-OCR:多模态时代的文档理解新标杆
在数字化浪潮下,传统OCR技术早已无法满足复杂文档(如科研论文、CAD图纸、多栏PDF)的解析需求——它们仅能识别字符,却难以理解版面结构、语义关联与跨模态信息。DeepSeek-OCR的横空出世,以“上下文光学压缩”为核心创新,打造了OCR 2.0时代的标杆产品,实现了从“看见文字”到“理解内容”的跨越,成为多模态RAG系统与企业级文档处理的核心引擎。
2.1模型定位:不止于识别的文档理解专家
DeepSeek-OCR是DeepSeek-AI于2025年开源的轻量级多模态OCR模型,专为文档理解与检索场景设计。它并非单纯的文字识别工具,而是融合视觉语言模型(VLM)能力的“文档全解析系统”——既继承了传统OCR的高精度文字提取能力,又具备版面分析、图表理解、结构化生成等高阶功能。
核心定位可概括为三点:
- 多模态入口:作为多模态RAG系统的“视觉皮层”,将图像、PDF等非结构化数据转化为可检索的结构化信息;
- 高效解析引擎:参数量仅3B左右,却能在A100单卡上实现2500 tokens/s的推理速度,平衡精度与部署成本;
- 全场景适配:支持图片、PDF、CAD图纸、公式表格等多种输入类型,覆盖科研、企业、个人等多元使用场景。
2.2 核心技术:上下文光学压缩的突破性创新
DeepSeek-OCR的核心竞争力源于其原创的“上下文光学压缩(Contexts Optical Compression)”技术与DeepEncoder架构,从理论到工程实现均实现了关键突破。
1. 理论核心:上下文光学压缩
这一创新范式颠覆了传统VLM的设计逻辑,以“视觉模态作为文本压缩媒介”,解决了大模型处理长文本时的计算复杂度难题。其核心机制是:将文档文本渲染为图像后,通过视觉编码生成远少于文本Token的视觉Token,实现高效压缩与语义保留。
实验数据验证了其强大性能:
- 压缩比<10×时,OCR解码精度可达97%以上;
- 即使压缩比提升至20×,准确率仍维持在60%左右;
- 这种压缩方式还能模拟人类记忆衰退机制,为LLM长上下文处理提供新思路。
2. 架构支撑:DeepEncoder视觉编码器
作为模型的核心引擎,DeepEncoder专为高分辨率文档解析设计,通过“窗口注意力+全局注意力”的串联结构,在低激活内存占用下实现高压缩比:
- 前端基于SAM-base(80M参数)提取局部视觉感知特征;
- 后端通过CLIP-large(300M参数)捕捉全局知识特征;
- 中间通过16×Token压缩器衔接,将1024×1024图像的4096个原始Token压缩至256个,有效控制计算开销。
3. 图文对齐机制
遵循“视觉编码→语言编码→跨模态对齐”的三阶流程,通过交叉注意力层实现图像与文本的深度语义交互,确保解析结果既精准又符合逻辑:
- 视觉编码:将图像切分为Patch并转化为高维视觉向量;
- 语言编码:通过LLM解码器将文本转化为同源维度向量;
- 跨模态对齐:通过动态交互实现图文语义映射,理解“标题-内容”“表格-数据”等关联关系。
2.3核心功能:覆盖全场景的文档解析能力
DeepSeek-OCR以“结构化输出+语义理解”为核心,提供7大核心功能,覆盖从轻量提取到复杂解析的全需求:
1. 纯文字提取(Free OCR)
支持截图、票据、合同片段等任意图像的文字快速提取,不依赖版面结构,适用于轻量文本获取场景,识别准确率媲美专业OCR工具。
2. 版面格式保留
自动识别文档的段落、标题、页眉页脚、多栏布局等结构,将扫描件还原为可编辑的结构化文本,无需二次排版即可归档使用。
3. 图表&表格解析
精准识别表格边界、合并单元格、流程图逻辑与建筑图纸尺寸,自动生成可机读的表格数据或文本描述,支持CAD图纸、实验图表等复杂结构化信息提取。
4. 图片信息描述
基于多模态理解能力,对图像进行语义级分析,生成自然语言总结,适用于科研论文图像解读、视觉报告生成等场景。
5. 指定元素位置锁定
通过“视觉定位(Grounding)”功能,精准返回目标元素的坐标位置,支持“定位签名”“查找特定公式”等语义检索需求。
6. Markdown文档转化
一键将PDF、图像文档转化为结构化Markdown文本,自动保留标题层级、表格格式、列表结构,是知识库构建与多模态RAG的核心前置工具。
7. 目标检测
识别图片中的多个物体并生成带标签的边界框,支持视觉标注与精准识别,扩展至多模态扩展任务。
三、部署与调用:低门槛适配多环境
DeepSeek-OCR支持本地推理,提供两条主流调用路径,部署门槛低,适配科研与企业级场景:
1. 环境要求
- 系统:Ubuntu 20.04+/22.04
- Python:3.10–3.12(推荐3.10/3.11)
- 硬件:GPU显存≥7GB(大图/多页PDF建议16–24GB)
- 依赖:CUDA 11.8/12.1/12.2、PyTorch 2.6.0+、vLLM 0.8.5+
2. 调用方式
(1)Transformers调用
适合快速测试与轻量部署,通过Hugging Face/魔搭社区下载权重后,三行核心代码即可实现推理,支持自定义提示词与输出路径配置。
import os
import torch
from transformers import AutoTokenizer, AutoModel
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = '/root/autodl-tmp/models/deepseek-ocr'
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True,
local_files_only=True
)
# 加载 model(保留 flash_attention_2,补充 flash_attn 兼容配置)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2', # 仅当安装了 flash-attn 时保留
trust_remote_code=True,
use_safetensors=True,
local_files_only=True,
torch_dtype=torch.bfloat16,
device_map='auto' # 自动分配到 GPU,避免手动 cuda() 兼容问题
)
model = model.eval() # device_map='auto' 已自动加载到 GPU,无需重复 .cuda()
prompt = "<image>\nDescribe this image in detail."
image_file = './test.png'
output_path = '/root/autodl-tmp/image_output'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
=====================
BASE: torch.Size([1, 256, 1280])
PATCHES: torch.Size([4, 100, 1280])
=====================
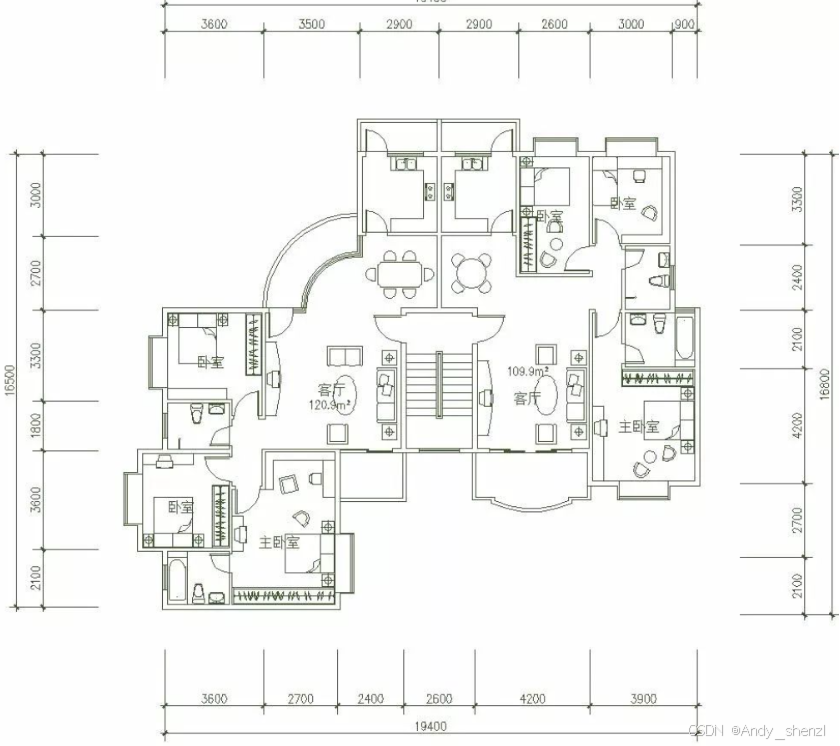
This image displays an architectural floor plan layout.
### Detailed Description:
#### Layout:
1. **Overall Shape**:
- The overall shape appears rectangular.
2. **Dimensions (in millimeters)**:
- Top left corner shows dimensions ranging approximately between 0 - 3600 mm horizontally across various sections labeled on top right side vertically which includes numbers like 19400, 3600, 3500, 2900, 2900, 2600, 3000, 1900, 2700, 2400, 2100, 1800, 1600, 1400, 1200, 1000, 800, 600, 400, 200, 100, 50, 20, 10, 5, 2, 1 respectively along both vertical sides indicating height measurements at different points around perimeter edges marked out clearly showing exact lengths measured in millimeters
3. **Rooms & Spaces**:
- There's one large room centrally located towards bottom center designated as "客厅" ("Living Room") measuring about 120.9 square meters (~1297 sq ft).
4. **Bedrooms/Beds**:
- Four bedrooms distributed throughout; each bedroom contains two beds indicated via small rectangles inside them denoted as "卧室" ("Bed").
5. **Bathrooms/WC**:
- Two bathrooms shown near central areas identified under labels including "卫生间" ("Bathroom"), one bathroom situated closer toward upper middle part while another bathroom positioned slightly lower than first mentioned bathroom also having similar labeling details.
6. **Kitchen Area**:
- A kitchen area located adjacent to living room featuring counter space likely used for cooking activities denoted through specific symbols representing appliances/furniture typically found therein.
7. **Additional Features/Symbols**:
- Various other smaller rooms/squares scattered strategically placed throughout suggesting additional functionalities possibly storage spaces/corridors leading off main pathways connecting primary living zones directly linking back again forming complex interconnected network ensuring smooth flow movement among these designated sections
8. **Textual Elements**:
- Text labels written predominantly in Chinese character format providing clear identification markers for respective parts e.g., "客厅", "卧室", "卫生间", "厨房", "餐厅", "阳台", "楼梯", "洗手间", "卧室", "书房", "卫生间", "厨房", "餐厅", "阳台", "楼梯", "洗手间"
### Style:
- This type of illustration falls squarely within technical drawing category often utilized during construction planning stages focusing primarily upon spatial distribution rather than aesthetic appeal emphasizing clarity over artistic expression hence straightforward black-and-white line-drawing representation devoid of coloration shading gradients textures thus maintaining focus solely onto structural elements themselves facilitating easy comprehension understanding amongst stakeholders involved project development process itself.
In summary, this detailed blueprint provides comprehensive visual guide outlining precise arrangement configuration intended purpose serving practical utility guiding builders architects designers alike facilitating smooth execution phase seamlessly integrating diverse functional segments harmoniously blending together creating cohesive whole encapsulating essence modern residential architecture design principles.
==================================================
image size: (1010, 904)
valid image tokens: 629
output texts tokens (valid): 625
compression ratio: 0.99
==================================================
===============save results:===============
(2)vLLM调用
适合批量推理与服务化部署,通过官方提供的脚本(run_dpsk_ocr_image.py/run_dpsk_ocr_pdf.py)实现高吞吐、低延迟推理,支持多页PDF批量转化。
3. PDF
推理完成后自动生成标准化输出文件,包含:
- images文件夹:中间处理图像与带边界框的可视化结果;
- result_ori.mmd:原始识别结果(未经过后处理,便于调试);
- result_with_boxes.jpg:带检测框的可视化图片(用于人工校验);
- result.mmd:结构化整理后的最终Markdown文件(可直接使用)。
进入路径:/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/
首先修改config.py文件中的模型地址、输入输出路径信息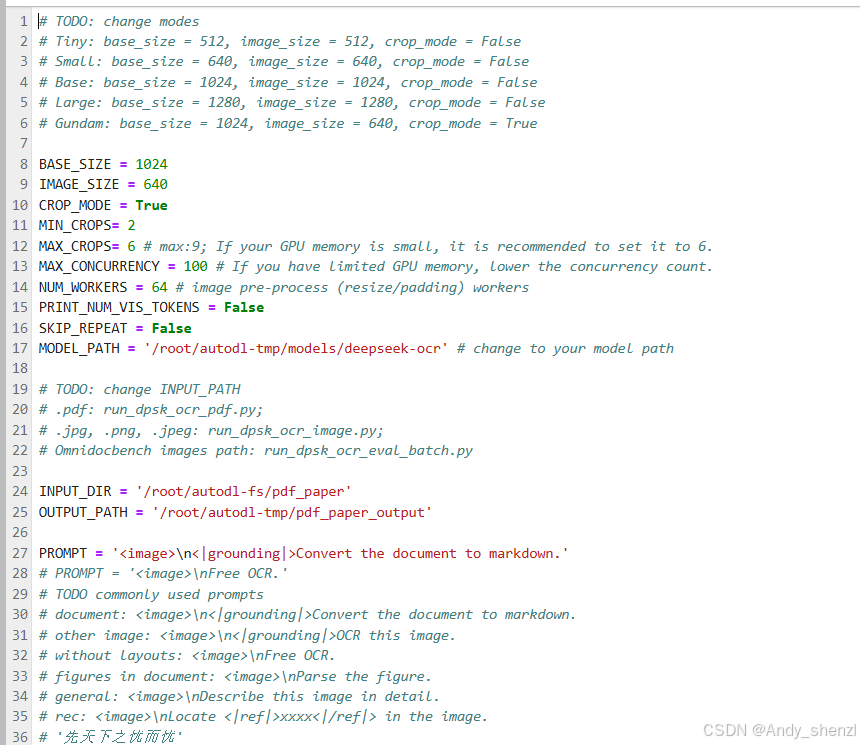
然后运行python run_dpsk_ocr_pdf.py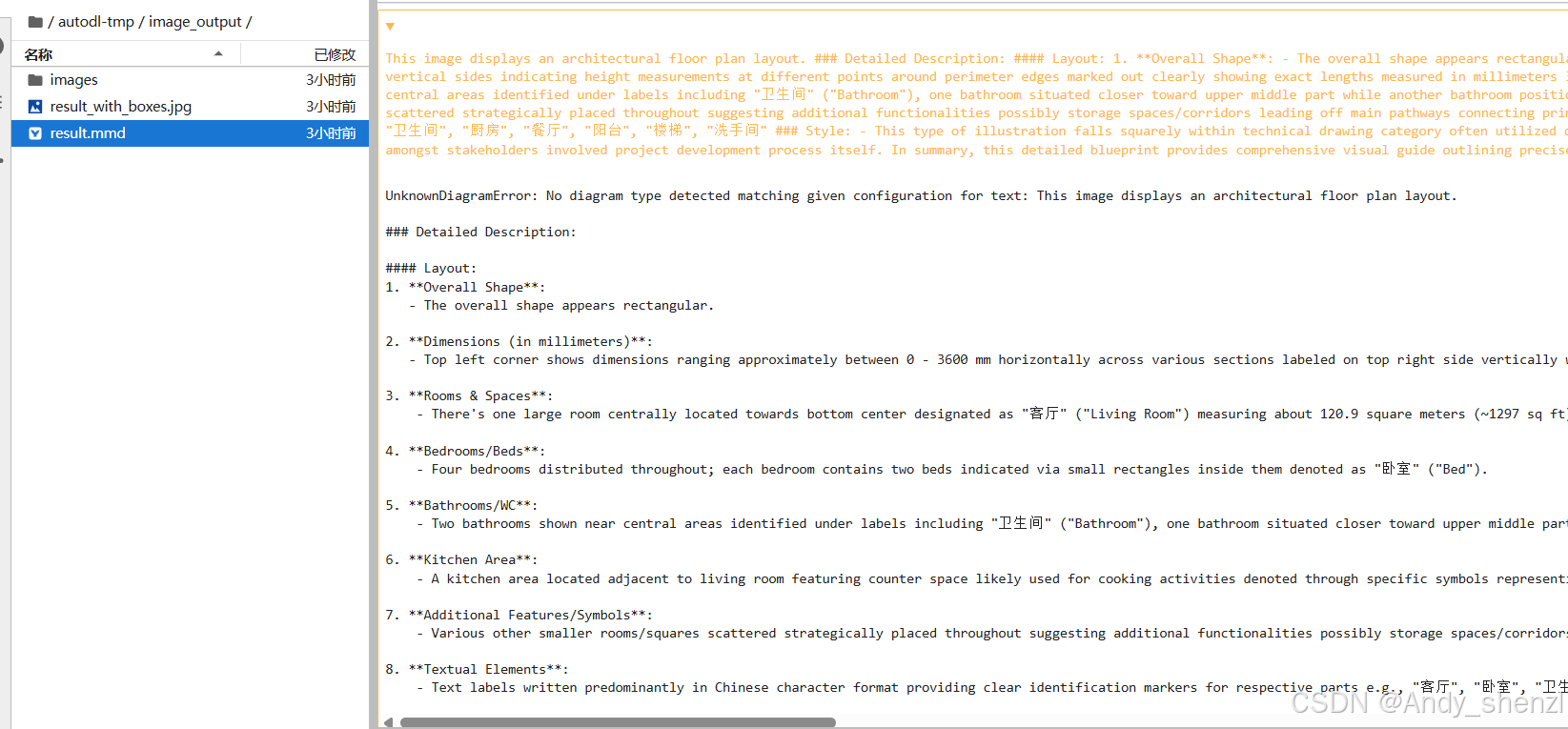
批量识别PDF
将单个识别的代码封装一下
def process_single_pdf(pdf_path: str, output_dir: str):
filename = os.path.basename(pdf_path)
base_name = os.path.splitext(filename)[0] # 论文名(如“北京大兴区典型生态系统服务评价”)
# 创建图片目录:output/images/[论文名]
images_root = os.path.join(output_dir, "images")
paper_images_dir = os.path.join(images_root, base_name)
os.makedirs(paper_images_dir, exist_ok=True) # 自动创建多级目录
# PDF渲染为图像(不变)
print(f'{Colors.RED}PDF: {filename} loading .....{Colors.RESET}')
images = pdf_to_images_high_quality(pdf_path)
# 图像预处理(不变)
prompt = PROMPT
from functools import partial
process_func = partial(process_single_image, prompt=prompt)
with ThreadPoolExecutor(max_workers=NUM_WORKERS) as executor:
batch_inputs = list(tqdm(
executor.map(process_func, images),
total=len(images),
desc=f"[{base_name}] Pre-processing images"
))
# VLLM推理(不变)
print(f'{Colors.GREEN}[{base_name}] Starting vLLM generation...{Colors.RESET}')
outputs_list = llm.generate(
batch_inputs,
sampling_params=sampling_params
)
# 结果后处理与写入
mmd_det_path = os.path.join(output_dir, f'{base_name}_det.mmd')
mmd_path = os.path.join(output_dir, f'{base_name}.md') # Markdown文件
pdf_out_path = os.path.join(output_dir, f'{base_name}_layouts.pdf')
contents_det = ''
contents = ''
draw_images = []
jdx = 0
for output, img in zip(outputs_list, images):
content = output.outputs[0].text
if '<|end of sentence|>' in content:
content = content.replace('<|end of sentence|>', '')
else:
if SKIP_REPEAT:
continue
page_num = f'\n<--- Page Split --->'
contents_det += content + f'\n{page_num}\n'
image_draw = img.copy()
matches_ref, matches_images, mathes_other = re_match(content)
# 处理图片并保存到论文专属目录
result_image = process_image_with_refs(image_draw, matches_ref, jdx, base_name, paper_images_dir)
draw_images.append(result_image)
# 替换图片引用路径为:images/[论文名]/[图片名].jpg
for idx, a_match_image in enumerate(matches_images):
image_caption = f"图{jdx+1}-{idx+1}"
image_relative_path = os.path.join("images", base_name, f"{base_name}_{jdx}_{idx}.jpg")
content = content.replace(a_match_image, f'\n')
# 清理其他标记(不变)
for idx, a_match_other in enumerate(mathes_other):
content = content.replace(a_match_other, '').replace('\\coloneqq', ':=').replace('\\eqqcolon', '=:').replace('\n\n\n\n', '\n\n').replace('\n\n\n', '\n\n')
contents += content + f'\n{page_num}\n'
jdx += 1
# 写入文件(不变)
with open(mmd_det_path, 'w', encoding='utf-8') as afile:
afile.write(contents_det)
with open(mmd_path, 'w', encoding='utf-8') as afile:
afile.write(contents)
pil_to_pdf_img2pdf(draw_images, pdf_out_path)
print(f"{Colors.YELLOW}[{base_name}] ✅ 处理完成。Markdown 结果已保存至: {mmd_path}{Colors.RESET}")

需要批量识别代码,可关注公众号:不懂乱问,回复Deepseek-OCR获取
四、应用场景:从科研到企业的全维度落地
DeepSeek-OCR的结构化输出与高效推理能力,已在多场景实现落地:
1. 科研场景
- 论文PDF转Markdown,保留公式、表格与图表关联;
- 科研图表解析,自动提取数据与趋势描述;
- 批量处理文献,构建结构化知识库。
2. 企业场景
- 企业文档检索:将合同、财报、专利转化为可检索结构;
- 票据与证照处理:自动提取关键信息(如金额、日期、证照编号);
- 工业文档解析:CAD图纸尺寸提取、技术手册结构化转化。
3. 个人与教育场景
- 扫描件数字化:教材、笔记转化为可编辑文本;
- 轻量项目开发:个人多模态应用快速集成OCR能力;
- 教学实验:低算力环境下的多模态技术实践。
五、模型优势:对比传统OCR与通用VLM的核心差异
| 对比维度 | 传统OCR(1.0) | 通用VLM | DeepSeek-OCR |
|---|---|---|---|
| 信息提取 | 仅识别文本字符 | 多模态但结构化弱 | 文本+表格+公式+图像语义 |
| 文档结构 | 无层级保留 | 基础版面分析 | 自动生成Markdown/HTML |
| 语义理解 | 无上下文关联 | 强但部署成本高 | 精准理解逻辑关系,轻量部署 |
| 部署成本 | 低 | 高(需大显存) | 低(7GB显存即可运行) |
| 核心优势 | 字符识别快 | 多模态通用 | 文档解析专用,结构化输出 |
六、开源资源与生态支持
DeepSeek-OCR已完全开源,提供完整的技术生态支持:
- 模型权重:Hugging Face、魔搭社区均可下载;
- 项目地址:https://github.com/deepseek-ai/DeepSeek-OCR;
- 技术文档:包含详细部署指南、API说明与实战案例;
- 配套资源:提供测试文档、课件代码、自研前端工具源码。
总结:重新定义文档理解的效率与精度
DeepSeek-OCR以“上下文光学压缩”的理论创新为基石,以轻量部署、高精度解析、全场景适配为核心优势,打破了传统OCR与通用VLM之间的能力鸿沟。它不仅是一款OCR工具,更是多模态时代连接视觉信息与文本知识的关键桥梁,为科研创新、企业数字化转型、个人高效办公提供了强大动力。随着多模态RAG技术的普及,DeepSeek-OCR正成为文档理解领域的“标配引擎”,推动数字化处理迈入“精准理解”的新阶段。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)