大模型如何评估大模型?LLM as a Judge完全指南!
本文全面回顾了"LLM as a Judge"的发展历程,从早期GPT-4评估语义相似性到AlpacaEval等系统性应用。文章指出,尽管LLM评估成本低廉,但仍存在位置偏差、冗长偏见和自我增强偏见等问题。建议在模型迭代中使用LLM进行快速粗粒度测试,但在关键节点和产品上线前仍需人工评估以确保质量。未来研究需进一步消除LLM评估中的偏差问题。
LLM as a Judge 已经越来越多的参与到大模型的评估中。下面先通过一系列的论文来回顾一下 LLM as a Judge 的发展。
Sparks of artificial general intelligence: Early experiments with gpt-4
GPT4 的出现,让人们第一次认为看到了 AGI 的曙光。在论文《Sparks of artificial general intelligence: Early experiments with gpt-4.》中,使用了 GPT4 来评估语义之间的相似性。
从下表中可以看到,在人类必须二选一的情况下,GPT4 和人类选择的一致性是很高的,但是在人类没有约束的情况下,一致性则并不那么高。这个应该是受限于 prompt 的设定。
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
Vicuna 采用了 ShareGPT 上人类与 ChatGPT 的对话数据,在 Llama-13B 上进行了微调。还有一项比较容易让人忽视的工作就是 Vicuna 采用了 GPT-4 来评估评估不同模型的输出。具体来说,Vicuna 的作者先借助 GPT-4 构造来 80 个有挑战的问题(https://github.com/lm-sys/vicuna-blog-eval/blob/main/eval/table/question.jsonl),然后要求GPT-4从有用性、相关性、准确性和细节方面对生成的输出进行评级。 针对不同类型的问题,设置了不同的 prompt 如下:https://github.com/lm-sys/vicuna-blog-eval/blob/main/eval/table/prompt.jsonl
从提示中可以看到,在编码和数学问题上,prompt要求提供了更多的细节,比如要求不借助输入答案的情况下独立解决问题后再进行评估。
实际上 Vicuna 可以任务是 LLM-as-a-Judge 的初步尝试,在不久之后,Vicuna 的团队更深入和系统对的研究了 LLM-as-a-Judge 的可行性和优缺点。
AlpacaEval : An Automatic Evaluator for Instruction-following Language Models
Alpaca 的团队当时试图用 LLM 来模拟 RLHF 中人类反馈的流程,论文中使用了 LLM 来作为 pair rank 的 Judger,同步提出了 AlpacaEval。
评估的方法也很简单,就是对于同一个问题,让 LLM 来判断两个不同模型的好坏。prompt 见: https://github.com/tatsu-lab/alpaca_eval/blob/main/src/alpaca_eval/evaluators_configs/alpaca_eval_gpt4/alpaca_eval.txt
<|im_start|>systemYou are a helpful assistant, that ranks models by the quality of their answers.<|im_end|><|im_start|>userI want you to create a leaderboard of different of large-language models. To do so, I will give you the instructions (prompts) given to the models, and the responses of two models. Please rank the models based on which responses would be preferred by humans. All inputs and outputs should be python dictionaries.Here is the prompt:{ "instruction": """{instruction}""",}Here are the outputs of the models:[ { "model": "model_1", "answer": """{output_1}""" }, { "model": "model_2", "answer": """{output_2}""" }]Now please rank the models by the quality of their answers, so that the model with rank 1 has the best output. Then return a list of the model names and ranks, i.e., produce the following output:[ {'model': <model-name>, 'rank': <model-rank>}, {'model': <model-name>, 'rank': <model-rank>}]Your response must be a valid Python dictionary and should contain nothing else because we will directly execute it in Python. Please provide the ranking that the majority of humans would give.<|im_end|>
在 2.5k 的测试数据上,LLM 产生的模型胜率和人类标注的模型胜率有极高的相关性,
后来,Alpaca 的研究人员发现 LLM-as-a-Judge 存在较严重的 length bias,也就是更喜欢长度更长的答案。所以专门做了个回归模型来去除 length bias.
进一步提升了与人类标注的一致性。
Can Large Language Models Be an Alternative to Human Evaluations?
本文用 LLM 来判断 story fragment 的质量,共有4点:
- Grammar
- Cohesiveness
- Likability
- Relevance
同时让英语老师来也来写 story fragment 和 LLM 产生的进行对比。有如下结论:
- 较弱的 LLM 不能很好的区分 AI 和人类质量。
- 人类和更强大的 LLM 都偏向于人类写的故事。
- ChatGPT 除了可以准确的评估故事质量,还可以给出合理的解释
- Likability 这种主观的指标对于人类和 LLM 都有挑战。
LLM-as-a-judge 的 bias 目前很难消除,所以人工评估依然是有价值的。
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
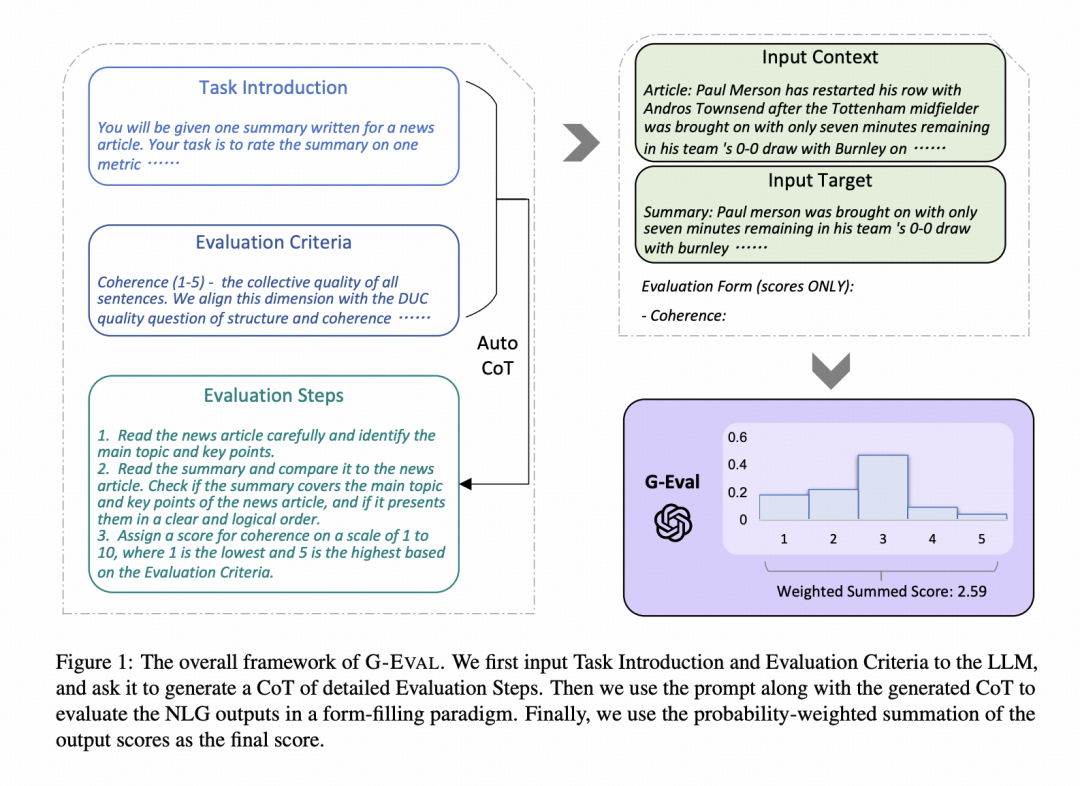
一方面是引入了 cot 来指导 llm 做评估,再一个采用了分数 token 的期望值(weighted summed score) 来作为最终的得分,主要是基于下面两点。
- For some evaluation tasks, one digit usually dominates the distribution of the scores, such as 3 for a 1 - 5 scale. This may lead to the low variance of the scores and the low correlation with human judgments.
- LLMs usually only output integer scores, even when the prompt explicitly requests decimal values. This leads to many ties in evaluation scores which do not capture the subtle difference between generated texts.
Large Language Models are Not Fair Evaluators
这篇论文探讨了位置 bias,当交换两个 response 的位置的时候,结果会有很大不同。 解决方法:
- 平衡位置校准 (Balanced Position Calibration,BPC):通过交换两个答案的位置。为了确定特定答案的最终评分,我们计算其作为第一个回答和第二个回答时的平均分数。这种平均化过程有助于确保更平衡的评估,并减少评分过程中位置偏差的影响。
- 多证据校准(Multiple Evidence Calibration, MEC):让模型先生成解释,然后给出评分。这样,评分可以通过更多的支持证据进行校准。此外,模型不仅生成一条证据,而是采样多个证据链,并将平均分数作为最终评分。但是多个证据链也并不是越多越好,实验表明 k = 3 的时候取得了最好的效果。
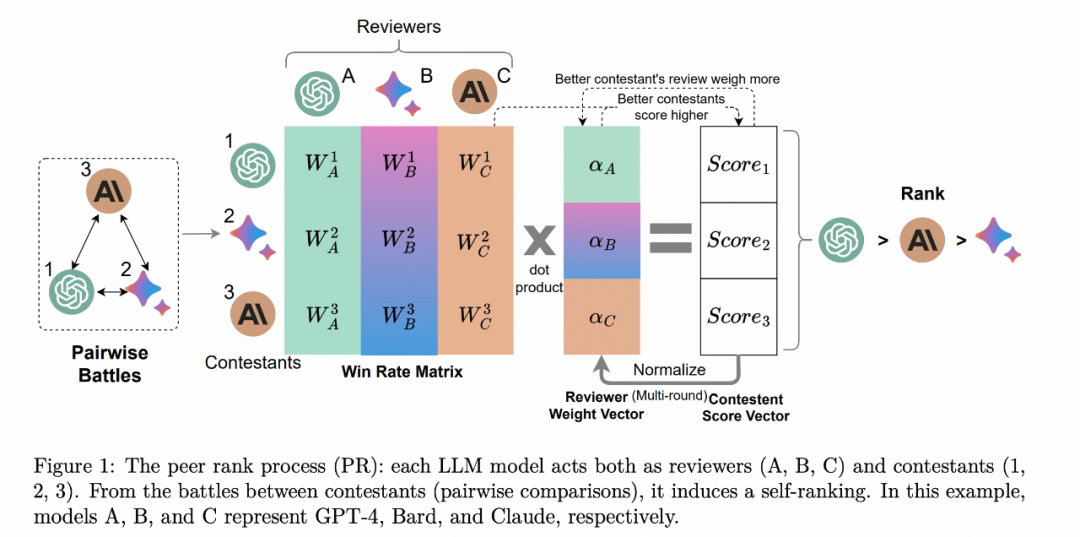
PRD: Peer Rank and Discussion Improve Large Language Model based Evaluations
这篇提出了一个 Peer Rank 的方法来消除 bias,处理的过程有点类似 PageRank,来获取到一个稳定的得分。
总结
总结来说,目前 LLM as a Judge 很省钱,但是依然存在一些问题。
目前最主要的问题是 Bias,包括但不限于:
- 位置偏差:裁判可能会根据输出在提示中的位置(例如,成对提示中的第一个响应)。
- 冗长偏见:法官可能会根据输出的长度给它们分配更好的分数(即,较长的回答获得较高的分数)。
- 自我增强偏见:法官倾向于倾向于自己产生的反应(例如,GPT-4给自己的输出分配高分)。
前面论文已经提了很多方法来改善 Bias,但是仍旧很难消除,这也凸显出人工评估的价值。
一个比较可行的评估流程是使用 LLM as a Judge 来做一些快速和粗粒度的测试,以指导大模型快速迭代。但是一些关键的研发节点,和最终上线到产品之前,依然需要人工评估来保证大模型等质量。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献550条内容
已为社区贡献550条内容

所有评论(0)