在大模型班学算法的笔记记录-七种梯度下降算法汇总
转行学习笔记分享
梯度下降是机器学习中优化模型参数的核心方法,梯度指损失函数对各参数的偏导数构成的向量
![]()
以下是七种常见梯度下降算法的核心内容:
1. 朴素/经典梯度下降(SGD,随机梯度下降)
作为梯度下降的基础形式,它的参数更新逻辑是:让当前参数向量沿着梯度的反方向调整
具体计算式为:
![]()
2. 动量(Momentum)算法
该算法引入“动量”来优化更新过程,参数更新分为两步:
- 先计算动量项:以上一轮动量项的衰减值(乘以系数),加上学习率与当前梯度的乘积
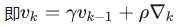
- 再用当前参数减去动量项,得到新参数
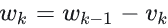
这个过程可以理解为:参数总变化量是“上一轮变化量的衰减值 + 本轮梯度对应的变化量”。
优势:
- 加速收敛:若本轮与上一轮梯度方向一致,动量会放大参数变化量;
- 缓解震荡:若梯度方向相反,变化量会被缩小;即便参数越过极值点,也能及时回调,更易逼近最优值。
3. NAG算法
它是动量算法的改进版,核心是提前预判梯度变化。
具体迭代方式为:
- 动量项的计算,基于“当前参数减去上一轮动量衰减值”对应的梯度,公式为

- 再通过
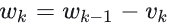 更新参数
更新参数
优点:
- 继承了动量算法的加速收敛特性;
- 能提前预估下一轮梯度趋势,修正当前更新方向——比如参数接近极值点时,可提前减速避免越过最优值。
4. Adagrad算法
该算法的核心是让学习率自适应调整:梯度持续较大的参数,学习率会减小(避免震荡);梯度持续较小的参数,学习率会增大(加快更新)。这种机制能让学习率适配梯度与数据分布的变化,同一轮迭代中不同参数、不同迭代轮次的学习率都有差异。
它能解决“不同参数逼近最优解速度不一致”的问题(原因包括损失函数本身的特性,以及数据分布——比如稀疏数据会导致部分参数并非每轮都更新)。
其参数更新步骤为:
- 计算当前参数的梯度:
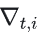
- 累计历史梯度的平方和:
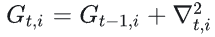
- 更新参数:
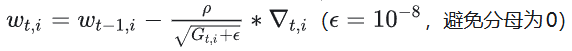
它的不足是:学习率易衰减过快导致训练提前终止,且依赖全局初始学习率;但适合处理稀疏数据场景。
5. RMSprop算法(均方根传播)
它是为解决Adagrad学习率衰减过快的问题而提出的,核心是对历史梯度的平方做加权平均(引入衰减系数,让更早的梯度影响逐渐减弱)。
其迭代过程为:
- 计算当前梯度
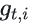
- 计算历史梯度平方的加权期望:
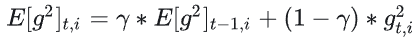
- 更新参数:
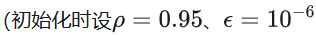
优势:
解决了Adagrad的学习率衰减问题。改进点包括引入时间窗口机制(衰减系数降低旧梯度影响)、用加权平均替代累计平方和等;适合非平稳目标(比如RNN)。 但它仍依赖全局学习率这一超参数。
6. AdaDelta算法
该算法的特点是无需手动指定全局学习率,完整步骤![]()
![]()
- 计算当前梯度
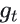
- 计算历史梯度平方的加权平均:
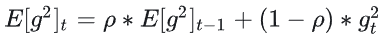
- 计算梯度的均方根:
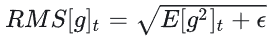
- 计算历史参数更新量的均方根:
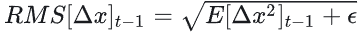
- 计算本轮参数更新量:
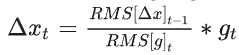
- 更新历史参数更新量的平方期望:
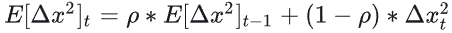
- 更新参数:
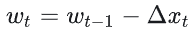
它的表现是:训练初期加速效果好,后期易在局部最小值附近波动。
7. Adam算法
该算法融合了Adagrad的自适应学习率与动量算法的优势,既能适配稀疏梯度场景(如自然语言、计算机视觉任务),也能缓解梯度震荡。其标准迭代流程(默认超参数:步长![]() 向量操作按元素运算)为:
向量操作按元素运算)为:
- 初始化参数
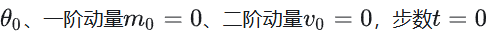
- 当参数未收敛时:
- 步数加1:
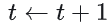
- 计算当前梯度:
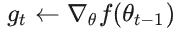
- 更新一阶动量:
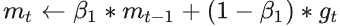
- 更新二阶动量:
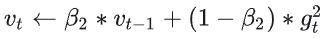
- 修正一阶动量偏差:
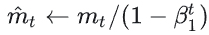
- 修正二阶动量偏差:
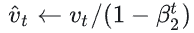
- 更新参数:
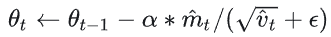
3.返回最终参数![]()
偏差修正的作用是:迭代初期较小,![]() 较大,缓解历史动量偏小的问题;后期
较大,缓解历史动量偏小的问题;后期![]() 增大,
增大,![]() 接近1,几乎无需修正。
接近1,几乎无需修正。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)