2026精选课题-基于springboot的智能笔记的设计与实现
摘要:本文介绍了一个基于SpringBoot的智能笔记系统开发项目,面向高校师生提供毕业设计辅导服务。系统采用微服务架构,整合SpringBoot、Vue、MySQL等技术栈,实现笔记管理、智能分析、知识图谱等核心功能。项目包含开题报告、系统实现、论文辅导等全流程服务,提供从功能设计到答辩辅导的一站式解决方案。技术范围涵盖Java、Python、大数据等多个领域,旨在帮助学生完成高质量的计算机毕业
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/学生代理交流合作✌。
技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
精彩专栏推荐订阅:见下方专栏👇🏻
【2026计算机毕业设计选题】10套易过的精品毕设项目分享-CSDN博客
2025-2026年 最新计算机毕业设计 本科 选题大全 汇总版-CSDN博客
🍅文末获取源码联系🍅
在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

一、开发背景
在信息技术浪潮席卷全球的今天,知识已成为个人与社会发展的核心驱动力。信息的产生、获取与消费速度呈指数级增长,我们正身处一个“信息爆炸”的时代。在此背景下,如何高效地管理个人知识、整合碎片化信息、并激发创造性思维,已成为现代人面临的普遍挑战。传统笔记工具因其功能单一、数据孤岛、智能化程度低等局限,已难以满足日益增长的高效知识管理需求。因此,构建一个基于现代技术栈,特别是以SpringBoot为核心的智能笔记系统,不仅是对技术发展的积极响应,更是对个人乃至组织知识生产力的一次深刻变革,具有极其重要的现实背景与深远意义。
一、 系统建设的现实背景
1. 信息过载与知识管理的迫切需求
我们每天被海量的信息所包围:新闻资讯、社交媒体、工作报告、学术论文、灵感碎片……这些信息若不加以有效整理,便会转瞬即逝,或杂乱无章地堆积,形成“数字废墟”。传统的纸质笔记或简单的电子文档管理方式,在检索、关联和更新方面效率低下,导致大量有价值的信息被埋没。用户迫切需要一种能够“理解”内容、主动建立关联、并能随时随地安全访问的知识管理工具,以将信息转化为结构化的、可用的知识资产。
2. 传统笔记工具的局限与瓶颈
尽管市场上有许多笔记应用(如早期版本的Evernote、OneNote等),但它们普遍存在一些共性问题:
数据孤岛:笔记数据常被锁定在特定应用或平台中,难以与其他系统(如日程管理、项目管理、代码仓库)进行数据交互和整合。
智能化水平不足:大多停留在“记录”与“分类”的初级阶段,缺乏对笔记内容的深度理解和智能处理能力,如自动摘要、主题提取、智能推荐等。
协作功能薄弱:团队间的知识共享和协同编辑体验不佳,版本管理混乱,难以支撑高效的团队知识沉淀。
定制化与扩展性差:功能固定,难以根据个人或企业的特定工作流进行个性化定制和功能扩展。
这些局限性催生了市场对下一代“智能”笔记系统的渴望。
3. 技术成熟的驱动与赋能
任何软件系统的兴起都离不开底层技术的成熟。智能笔记系统的建设,正得益于以下几个关键技术的飞速发展:
微服务架构的普及:以SpringBoot为代表的微服务框架,以其快速开发、内嵌服务器、自动化配置和强大的生态集成能力,极大地降低了构建复杂、高可用、易扩展的分布式系统的门槛。这使得开发团队能够快速迭代,灵活地为其笔记系统添加新的智能功能模块。
人工智能(AI)与自然语言处理(NLP)技术的实用化:诸如词向量、命名实体识别、文本分类、情感分析、文本生成等NLP技术,为笔记的智能化提供了核心引擎。这使得系统能够实现自动标签化、内容摘要、语义搜索(而非简单关键词匹配)、以及基于内容的智能关联。
云计算与大数据技术:云平台提供了弹性、可扩展的计算与存储资源,使得处理海量用户笔记数据成为可能。大数据技术则能对这些数据进行深度分析,挖掘用户行为模式,优化推荐算法。
前端技术的革新:Vue.js、React等现代前端框架,使得构建富交互、体验流畅、支持Markdown等高效编辑语法的用户界面变得轻而易举,极大地提升了用户的使用体验。
在这些技术背景的共同作用下,基于SpringBoot构建一个集记录、管理、智能分析与协作为一体的智能笔记系统,不仅在技术上可行,更在成本和控制力上具备了显著优势。
二、 系统建设的深远意义
建设一个基于SpringBoot的智能笔记系统,其意义远不止于开发出一款新软件,它更是在个人效率、团队协作、技术实践乃至知识生态层面的一次系统性升级。
1. 对个人用户:提升知识生产力与思维创造力
从“记录”到“理解”的飞跃:系统通过NLP技术自动为笔记打上标签、提取关键词、生成摘要,使用户能够快速把握笔记核心,实现了从被动记录到主动理解的转变。
构建个人知识图谱:系统能自动发现并建立不同笔记之间的语义关联,将孤立的笔记点连接成知识网络(图谱)。当用户回顾某一笔记时,系统能呈现所有相关的想法、项目和参考资料,极大地促进了知识的融会贯通和创造性思维的迸发。
极致高效的检索与回顾:基于语义的智能搜索,让用户即使用模糊的记忆也能精准定位所需内容。定期的智能复习提醒、基于遗忘曲线的推送,能有效对抗遗忘,巩固学习成果。
无缝的全平台体验:基于SpringBoot构建的稳健后端,可轻松支持Web、移动App(Android/iOS)等多种客户端,确保用户在任何设备上都能获得一致、流畅的笔记体验,真正实现“随时随地记录与思考”。
2. 对团队与组织:赋能协同创新与知识沉淀
打破信息孤岛,促进知识共享:系统为团队提供了一个统一、结构化的知识库。通过精细的权限管理,团队成员可以安全地共享笔记、协同编辑,避免知识分散在个人的邮箱、聊天记录和本地文件中。
加速新成员融入与组织学习:新员工可以通过访问团队的知识库,快速了解项目背景、技术方案和最佳实践,大幅缩短培训周期。组织内的隐性知识得以显性化、系统化地沉淀下来,形成可传承的组织智慧。
提升项目协作效率:将笔记与任务、代码库、文档等关联,可以形成以项目为中心的知识上下文,使团队协作更加聚焦和高效,减少沟通成本。
3. 对技术发展与行业实践:示范现代软件工程最佳实践
微服务架构的典范应用:基于SpringBoot + Spring Cloud的微服务架构,将用户服务、笔记服务、搜索服务、AI服务等解耦,实现了系统的高内聚、低耦合。这不仅提升了系统的可维护性和可扩展性,还便于独立部署和弹性伸缩,是云原生应用的一个典型范例。
AI能力与传统业务的有效融合:该项目成功地将前沿的AI/NLP技术融入到传统的笔记管理业务中,为其他领域的“+AI”转型提供了可行的技术路径和架构参考,展示了如何利用技术为传统应用赋能,创造超额价值。
全栈开发的综合演练场:从后端的SpringBoot、MyBatis、Redis、Elasticsearch,到前端的Vue/React,再到容器化部署,一个智能笔记系统几乎涵盖了现代Web开发的所有核心技术栈,对于开发者学习和掌握全栈技术具有极高的实践价值。
4. 对社会知识生态的潜在贡献
当无数个体和组织的知识被有效地结构化、网络化后,将可能孕育出更大规模的社会化知识网络。虽然涉及隐私和数据安全等复杂问题,但其远景是:一个互联互通的知识生态,能够更高效地促进科学发现、技术创新和文化传播,加速整个人类社会的知识迭代与进步。
二.技术环境
JDK版本:1.8 及以上
Node版本:16.9.0及以上(指定版本)
IDEA工具 :IDEA或者其他、VsCode
数据库:Mysql5.7可视化工具:Navicat、Sqlyog
编程语言:Java、Vue
Java框架:SpringBoot
详细技术:HTML+CSS+JAVA+SpringBoot+Mysql+VUE+Maven
一、 系统架构设计
构建一个智能笔记系统,需要采用分层、模块化的架构,以确保系统的可扩展性、可维护性和高性能。基于Spring Boot生态,我们可以设计如下核心架构:
-
表示层: 采用前后端分离模式。前端可以使用Vue.js、React等现代框架构建富客户端应用,通过RESTful API与后端进行数据交互。这有助于实现敏捷开发和良好的用户体验。
-
应用层: 基于Spring Boot构建,作为系统的核心业务逻辑处理层。它负责接收前端请求,协调各个服务模块,并返回处理结果。这一层包含了控制器、服务接口、数据传输对象等。
-
服务层: 这是智能功能的核心实现层。我们将业务逻辑拆分为多个高内聚的服务模块,例如:
-
用户服务: 负责用户认证、授权和个人信息管理。
-
笔记核心服务: 负责笔记的增、删、改、查、版本管理等基础CRUD操作。
-
智能分析服务: 集成了自然语言处理和机器学习能力,是智能功能的大脑。
-
搜索服务: 基于Elasticsearch,提供全文检索和语义搜索能力。
-
文件服务: 负责附件的上传、存储和管理。
-
-
数据持久层: 使用Spring Data JPA或MyBatis-Plus等框架,简化数据库操作。
-
关系型数据库: 选用MySQL或PostgreSQL,用于存储结构化数据,如用户信息、笔记元数据(标题、创建时间、标签等)、目录结构。
-
NoSQL数据库: 选用Elasticsearch,专门用于存储笔记的全文内容,以实现高效的全文检索和高亮显示。
-
缓存数据库: 选用Redis,用于缓存热点数据(如用户会话、热门标签)、存储临时任务状态以及作为分布式锁。
-
-
AI能力层: 这是智能化的引擎。可以有两种集成方式:
-
内部集成: 通过Java调用本地运行的Python AI服务(如使用gRPC或HTTP通信)。这种方式延迟低,但部署复杂。
-
外部API调用: 通过HTTP Client调用第三方AI服务提供商(如OpenAI GPT系列、国内大模型、专有NLP服务)的API。这种方式开发快捷,但依赖外部服务且有网络开销。
-
-
基础设施层: 包括消息队列(如RabbitMQ/Kafka,用于异步处理耗时任务,如笔记内容分析)、对象存储(如MinIO/阿里云OSS,用于存储附件)、以及应用监控(如Spring Boot Actuator + Prometheus + Grafana)。
二、 核心智能功能模块实现
1. 笔记内容解析与结构化
技术实现: 当用户创建或更新笔记后,系统通过异步事件机制(如@Async注解或消息队列)触发内容解析任务。
解析过程:
文本提取: 如果笔记包含附件(如图片、PDF),首先调用OCR(光学字符识别)服务或PDF解析库(如Apache PDFBox)提取纯文本。
关键信息抽取: 将纯文本内容发送至智能分析服务。该服务利用命名实体识别技术,自动识别并提取出文本中的人名、地名、组织机构名、时间、日期、金额等实体。
自动摘要: 利用文本摘要模型(如TextRank、BERTSUM或调用大模型的摘要能力),生成笔记内容的简短摘要,用于在笔记列表页快速预览。
数据存储: 提取出的实体和生成的摘要,将与笔记ID关联,存储到MySQL或Elasticsearch的特定字段中,便于后续的索引和查询。
2. 智能标签与分类
技术实现:
关键词提取: 使用TF-IDF、TextRank等算法或预训练模型,从笔记内容中提取出关键短语作为候选标签。
主题模型: 应用LDA等主题模型,对用户的全部笔记进行无监督学习,自动聚类出若干主题(如“工作项目”、“学习心得”、“生活记录”)。新笔记可以基于其内容被自动归入最相关的主题类别。
分类模型: 对于有明确分类需求的用户,可以训练一个监督学习的文本分类模型。首先由用户手动创建一些分类并标记部分笔记,系统利用这些数据训练一个分类器(如SVM、FastText或基于BERT的微调模型),之后新笔记即可被自动分类。
用户反馈循环: 系统推荐的标签和分类应允许用户一键确认或修改。这些修改行为可以作为反馈数据,用于后续模型的优化和再训练,实现越用越准的个性化效果。
3. 知识图谱与关联推荐
这是智能笔记的高级功能,旨在连接孤立的笔记,形成知识网络。
技术实现:
实体关系抽取: 在NER的基础上,进一步利用关系抽取模型,识别笔记中实体之间的关系(如“张三-就职于-甲公司”)。
图谱构建: 将抽取出的实体作为“节点”,关系作为“边”,持久化到图数据库(如Neo4j)中,构建个人知识图谱。
关联推荐:
基于内容的推荐: 当用户浏览某篇笔记时,系统计算该笔记与其它笔记的文本相似度(如使用词袋模型+余弦相似度,或更先进的Sentence-BERT生成向量后计算相似度),将最相似的几篇笔记推荐为“相关内容”。
基于图谱的推荐: 在图数据库中,查询与当前笔记中实体直接或间接相连的其它笔记。例如,两篇笔记都提到了同一个项目或人名,即使文本内容不相似,它们也可能存在逻辑关联。
可视化: 在前端提供一个“知识图谱”视图,以交互式网络图的形式向用户展示其笔记间的关联,帮助用户发现隐藏的知识联系。
4. 智能搜索与问答
超越传统的关键词匹配,实现语义层面的搜索。
技术实现:
向量化搜索:
嵌入: 使用Sentence Transformer等模型,将每篇笔记的标题和内容转换为一个高维度的向量(Embedding)。
存储: 将这些向量存储在专用的向量数据库(如Milvus、Pinecone)或支持向量搜索的Elasticsearch插件中。
查询: 当用户输入搜索词时,同样将其转换为向量。
匹配: 在向量空间中进行最近邻搜索,找出与查询向量最相似的笔记向量。这种方法能理解同义词和语义相关性,例如搜索“人工智能”,也能返回包含“AI”、“机器学习”但未出现“人工智能”关键词的笔记。
问答系统:
检索式QA: 结合上述搜索技术。首先根据用户提出的自然语言问题(如“我上个月关于Spring Boot的笔记总结了哪些要点?”),检索出最相关的笔记片段。然后,利用一个阅读理解模型(如基于BERT)或直接调用大语言模型,从这些片段中精准提取出答案,并以高亮形式呈现给用户。
生成式QA: 直接连接大语言模型API。将用户的问题和检索到的相关笔记内容作为上下文(Context)和提示(Prompt)发送给大模型,由模型直接生成一个结构化的答案。
三、 技术细节与优化
-
异步处理与性能: 笔记的智能分析(如NER、摘要、向量化)通常是计算密集型的。必须采用异步处理(如Spring的
@Async、消息队列),避免阻塞主请求线程,保证用户操作的流畅性。任务状态可通过Redis或数据库进行跟踪。 -
数据一致性: 由于数据存储在多种数据库中(MySQL, ES, 向量库,图数据库),需要保证数据最终一致性。可以采用“事件溯源”或“发件箱模式”,在MySQL中完成主数据写入后,发布一个领域事件,由不同的监听器去同步其它数据源。
-
安全性:
-
认证与授权: 使用Spring Security + JWT,确保用户只能访问自己的笔记数据。
-
数据加密: 敏感笔记内容在传输和存储时都应加密(HTTPS,数据库字段加密)。
-
AI服务安全: 调用外部AI API时,需妥善管理API Key,并对传输的数据进行脱敏处理,防止隐私泄露。
-
-
扩展性与插件化: 将每个智能功能(如标签、摘要、图谱)设计为独立的、可插拔的模块。通过定义清晰的接口,可以方便地替换底层的算法或服务提供商,例如从TF-IDF切换到更先进的深度学习模型。
四、 持续学习与个性化
一个真正智能的系统应具备持续进化的能力。
反馈机制: 在UI上提供便捷的反馈入口(如“推荐不准”按钮)。用户的接受、拒绝、修改行为都是宝贵的标注数据。
增量学习: 定期(如每周)利用用户的新增数据和反馈数据,对现有的分类、标签模型进行增量训练或微调,使模型更贴合用户的个人用语习惯和知识领域。
A/B测试: 对于新上线的智能功能或算法,通过A/B测试平台来评估其效果(如点击率、用户停留时间),用数据驱动决策,持续优化用户体验。
系统实现效果
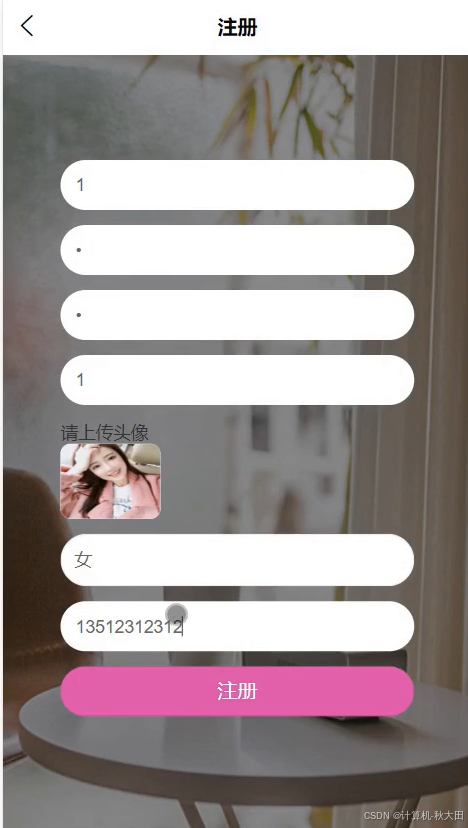

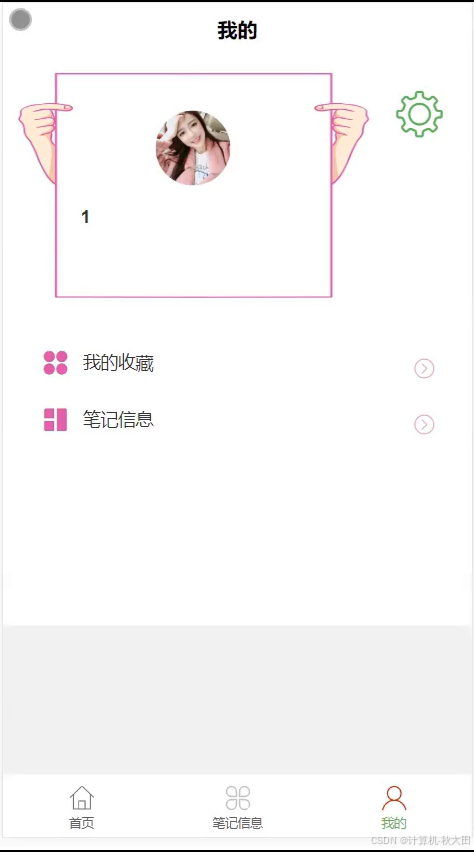

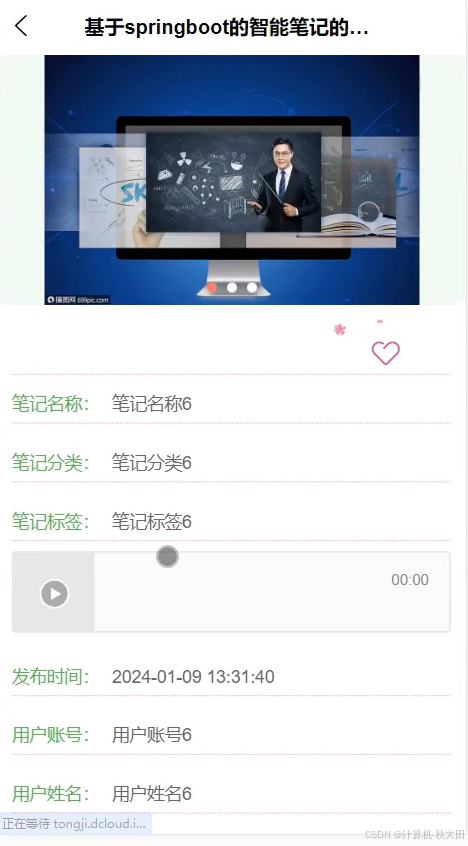
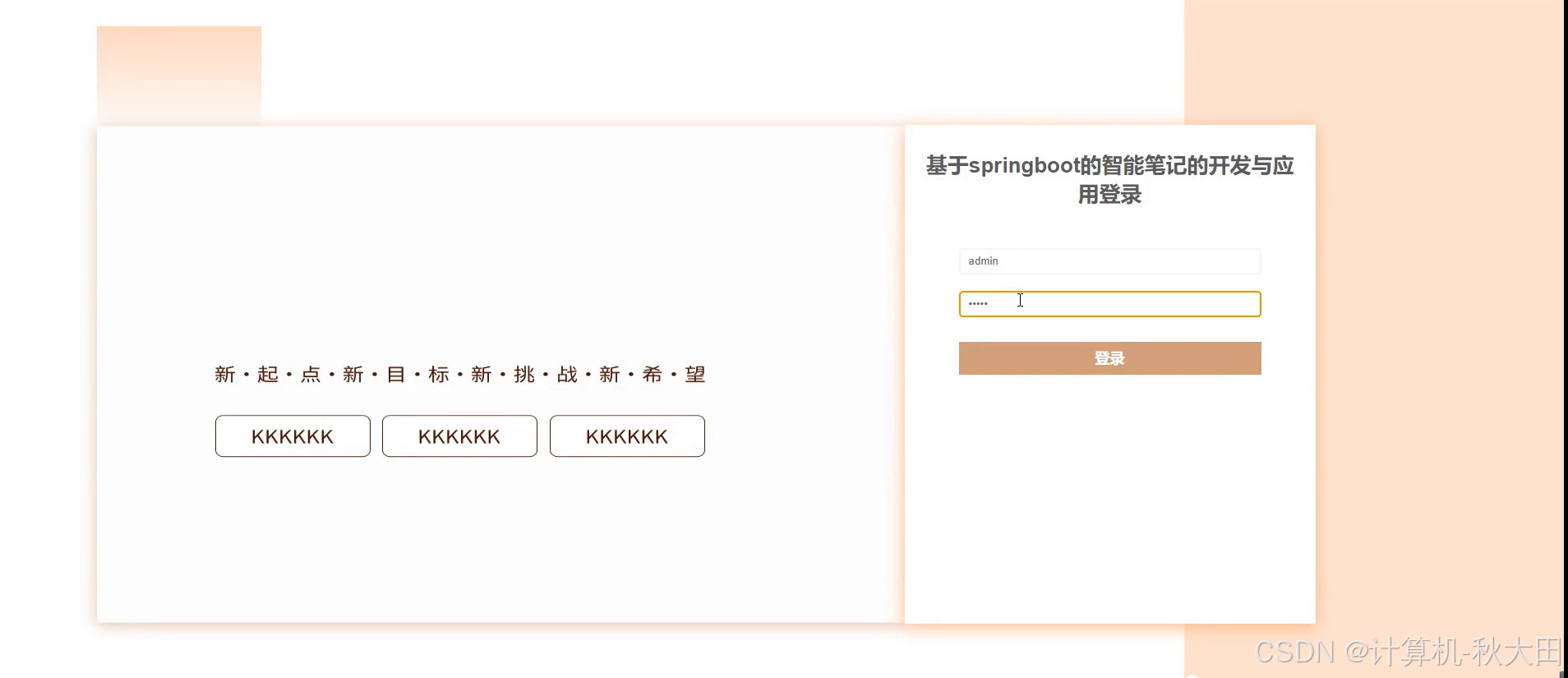

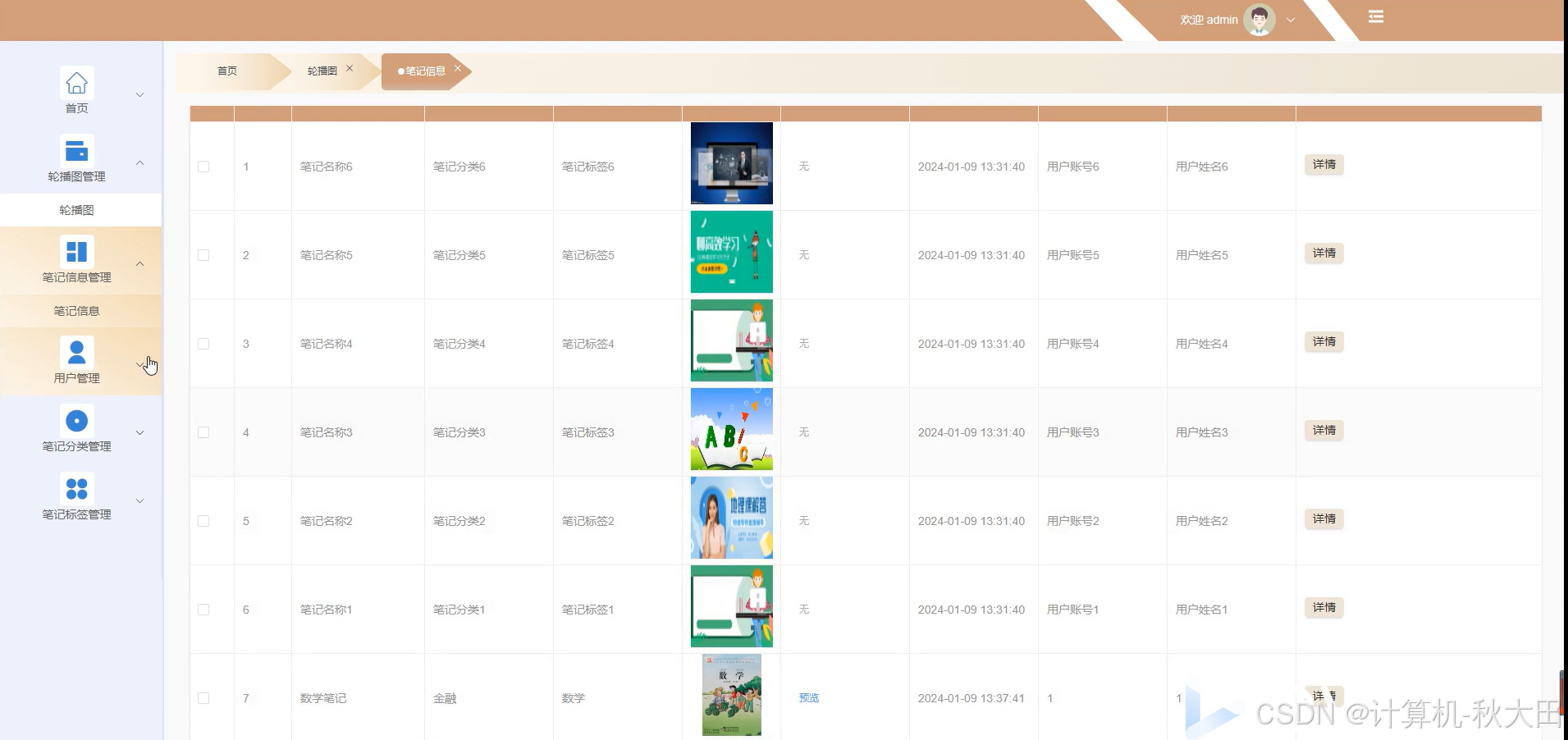
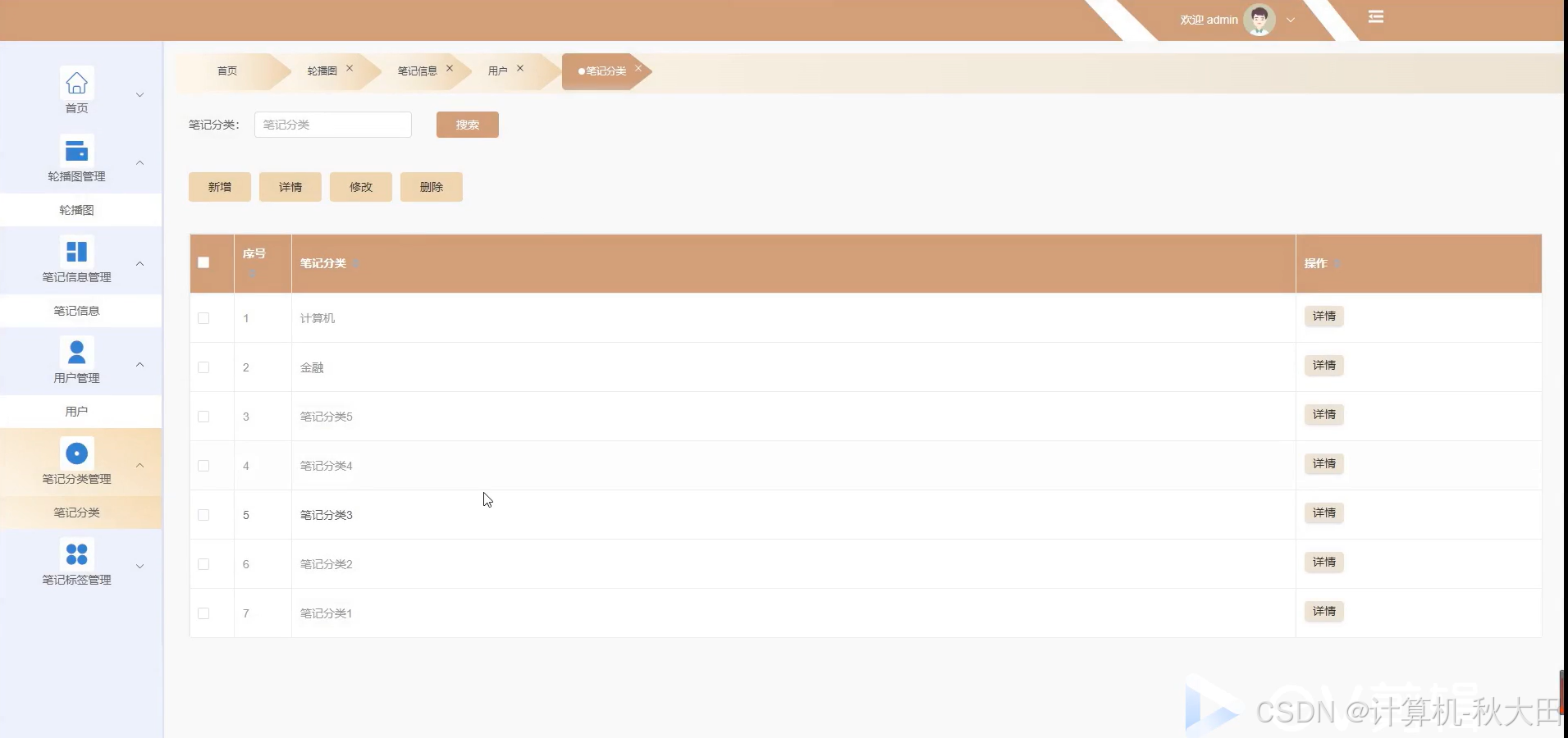
文档部分参考
精彩专栏推荐订阅:见下方专栏👇🏻
【2026计算机毕业设计选题】10套易过的精品毕设项目分享-CSDN博客
源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)