【读点论文】Revisiting Class-Incremental Learning with Pre-Trained Models冻结基础模型,构建对比原型,余弦求解距离,新旧分类头分开计算损失
类增量学习使学习系统能够在不忘记旧概念的情况下不断融入新概念。典型的CIL方法可以分为几类。基于范例的方法保存和重放旧类中的范例以恢复以前的知识。除了直接保存范例外,其他方法还可以保存特征或使用生成模型,构建记忆。基于知识蒸馏的方法旨在更新期间对齐新旧模型的输出,从而维护旧概念的知识。对齐可以在几个方面建立,iCaRL 和LwF 利用logit蒸馏,这要求旧类的输出logit相同。LUCIR 利用
Revisiting Class-Incremental Learning with Pre-Trained Models: Generalizability and Adaptivity are All You Need
Abstract
- 类增量学习(Class-incremental learning,CIL)的目标是在不遗忘旧类的情况下适应新类的出现。传统的CIL模型是从头开始训练的,随着数据的发展不断获取知识。最近,预训练取得了实质性的进展,使得大量的预训练模型(Pre-trained models,PTM)可以用于CIL。与传统方法相反,PTM具有可泛化的嵌入,可以很容易地转移到CIL中。在这项工作中,
- 1)我们首先揭示了冻结的PTM已经可以为CIL提供可推广的嵌入。令人惊讶的是,一个简单的基线(SimpleCIL),它不断地将PTM的分类器设置为原型特征,即使没有对下游任务进行训练,也可以击败最先进的技术。2)由于预训练数据集和下游数据集之间的分布差距,PTM可以通过模型自适应来进一步培养自适应性。我们提出了AdaPt和mERge(Aper),它聚合了PTM和自适应模型的嵌入用于分类器构建。Aper是一个通用框架,可以与任何参数有效的调整方法正交组合,3)考虑到已有的基于ImageNet的基准测试由于数据重叠而不适合PTM时代,本文提出了四个新的基准测试,即 ImageNet-A,通过大量的实验验证了Aper的有效性,它提供了一个统一、简洁的框架。代码位于GitHub - LAMDA-CL/RevisitingCIL: Revisiting Class-Incremental Learning with Pre-Trained Models: Generalizability and Adaptivity are All You Need (IJCV 2024)
- 该论文重新探讨了基于预训练模型(PTMs)的类增量学习(CIL),指出 CIL 的核心要素是适应性(模型更新能力) 与泛化性(知识迁移能力);首先提出简单基线SimpleCIL,通过冻结 PTM 的嵌入函数、以类平均嵌入(原型)作为分类器,无需下游任务训练即可超越现有 SOTA 方法;针对 PTM 与下游数据的分布差距,设计Aper 框架(融合 PTM 与自适应模型的嵌入特征),可正交结合全微调、VPT、SSF 等任意参数高效调优技术,同时保留 PTM 的泛化性与自适应模型的适应性。
- 类增量学习(CIL)定义:持续学习新类,不遗忘旧类,传统CIL局限从头训练,存在灾难性遗忘。预训练模型(PTMs)潜力:泛化嵌入强,可迁移至CIL。冻结PTM的泛化性,SimpleCIL基线无需下游训练超SOTA。适应性需求,PTM与下游数据存在分布差距,需模型自适应。SimpleCIL,核心冻结PTM的嵌入函数φ(·),分类器:类平均嵌入,Aper框架(AdaPt and mERge)训练流程:1.第一阶段用D¹自适应PTM;2.冻结φ*(·)与φ(·);3.融合嵌入[φ*(x),φ(x)];4.后续阶段仅更新原型分类器。自适应技术:全微调、VPT(Deep/Shallow)、SSF、Adapter、BN调优。PTM泛化性是CIL关键,Aper平衡泛化与适应,新基准更适合PTM评估。
- 本文围绕预训练模型(PTMs)驱动的类增量学习(CIL) 提出两类关键算法:
- SimpleCIL:作为基础基线,验证冻结 PTM 的泛化性 —— 无需下游任务训练,仅通过 “冻结 PTM 嵌入 + 原型分类器” 即可超越现有 SOTA 方法,核心是直接利用 PTM 的通用视觉表征能力;SimpleCIL:定位为 “PTM 泛化性验证基线”,证明 “冻结 PTM 的嵌入已足够支撑 CIL”,为 Aper 的设计提供理论依据(若 SimpleCIL 性能差,则无需后续融合设计);
- Aper(AdaPt and mERge):本文提出的核心算法框架,针对 SimpleCIL 无法解决的 “PTM 与下游数据分布差距” 问题,通过 “单阶段自适应 + 嵌入融合” 平衡泛化性(PTM 固有) 与适应性(下游任务特异性),实现无灾难性遗忘的高效增量学习。为 “PTM-based CIL 的通用优化框架”,解决 SimpleCIL 的 “分布差距短板”,同时兼容 ViT/CNN 等骨干网络与多种参数高效调优技术(如 VPT、SSF)。
Introduction
-
随着深度学习的发展,深度模型在许多领域取得了令人印象深刻的成就。然而,大多数研究都集中在静态环境中识别有限数量的类。在真实的世界中,应用程序经常处理带有传入新类的流数据。为了解决这个问题,分类增量学习(Class-Incremental Learning,CIL)允许模型从不断变化的数据中学习,并不断建立统一的分类模型。然而,当新的类按顺序添加时,会发生臭名昭著的灾难性遗忘,这会擦除先前学习的知识。
-
虽然典型的CIL方法假设模型是“从头开始训练”的,但预训练的最新进展使预训练模型(PTM)更容易用于下游任务中的模型设计。这些PTM通常在大量语料库或大量图像上训练,具有 handcrafted tricks ,从而具有很强的泛化能力。因此,几种方法建议利用PTM进行更好的增量学习。
-
强大的PTM减轻了CIL的负担。然而,当我们重新审视CIL的目标时,我们发现这些协议之间有本质的区别。没有PTM,CIL模型从随机初始化训练到不断获取新类的知识并构建统一的嵌入空间,这需要顺序更新的自适应性。相比之下,PTM是用大量数据集训练的,这使得更容易实现具有强泛化能力的强大嵌入空间。使用人类学习类比,非PTM方法旨在教婴儿成长并通过大学不断获得知识,而基于PTM的方法教有经验的成年人做同样的事情,这要容易得多。
-
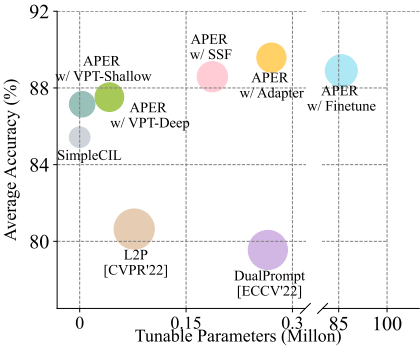
为了评估PTM的通用性,我们使用VTAB 数据集制定了CIL任务,并使用图1中的预训练ViT-B/16-IN 1 K测试了最先进的基于PTM的方法的性能。作为比较,我们提出了一个简单的基线SimpleCIL来评估预训练特征的质量。随着预训练嵌入函数的冻结,SimpleCIL将分类器权重设置为每个新分类的平均嵌入。平均嵌入是用训练图像计算的。通过这种方式,SimpleCIL可以作为预训练特征质量的直接指标。如果PTM具有可推广的特征,直接将平均模式匹配到每个查询实例也可以获得有竞争力的结果。令人惊讶的是,图1显示SimpleCIL比当前的SOTA高出5%,即使没有对这些下游任务进行任何调整,验证了其在知识转移中的较强的泛化能力。
-
-
图 1:不同基于 PTM 的 CIL 方法在 VTAB 数据集上的比较。 X 轴代表可调参数的数量,Y 轴代表平均精度。半径代表训练时间。尽管消耗更多的调整参数和训练时间,但当前最先进的技术(即 L2P 和 DualPrompt)仍然表现出比基线方法 SimpleCIL 差的性能。相比之下,我们的 Aper 以极小的成本持续改善基线。为了公平比较,所有方法均基于预训练的 ViT-B/16IN1K。 SimpleCIL 利用训练集来计算平均嵌入。
-
-
虽然PTM可推广到CIL,但预训练和增量数据集之间仍然存在领域差距。例如,ImageNet预训练模型可能无法很好地推广到分布外或专门任务。在这种情况下,冻结知识转移的嵌入不是“灵丹妙药”。因此,自适应性对于使模型能够掌握特定任务的特征变得至关重要。然而,顺序调整PTM会损害结构信息并削弱泛化能力,导致不可逆转地遗忘先前的知识。有没有一种方法可以统一PTM的泛化能力和适应模型的适应性?
-
在本文中,我们提出了AdaPt和mERge(Aper)的CIL,它采用PTM在一个统一的框架中增强泛化性和自适应性。我们在第一个增量阶段通过参数有效调整来调整PTM。调整模型有助于获得任务-然后,我们将自适应模型与PTM连接,以提取平均Aper在第一阶段限制了模型的调整,在自适应性和泛化性之间取得了平衡。
-
此外,典型的基于ImageNet的CIL基准不适合于评估,这是由于预先训练的任务和下游任务之间的重叠。因此,我们使用四个新的数据集对基于PTM的CIL进行基准测试,这些数据集与预训练数据具有较大的域间隙。在各种设置下的大量实验证明了Aper的有效性。我们的主要贡献可以总结如下:
- 通过广泛的实证评估,我们发现一个简单的基线(即SimpleCIL)可以直接将PTM的强泛化性转移到CIL中,甚至在没有下游任务训练的情况下,其性能优于当前最先进的技术。
- 本文提出了Aper算法,该算法在统一的框架下利用PTM来增强泛化能力和自适应能力,它既利用基于原型的分类器来实现PTM的泛化能力,又利用模型自适应来实现下游任务的强自适应能力,由于它的一致性,Aper算法可以应用于不同的网络结构和不同的调优技术。
- 由于预训练数据和传统CIL基准测试之间的重叠,我们使用几个与ImageNet具有较大领域差距的新数据集对预训练的基于模型的CIL进行基准测试。在这些基准数据集上进行的大量实验验证了Aper的最新性能。
-
CIL 定义:模型需从持续流入的新类数据中学习,同时保留旧类知识,核心痛点是灾难性遗忘(新类学习覆盖旧类知识)。多假设模型 “从头训练”,缺乏泛化性,难以应对动态数据。PTM 的潜力:PTM(如 ViT、ResNet)经大规模数据(ImageNet-1K/21K)预训练,具备强泛化嵌入,可降低 CIL 的知识获取成本,但需解决 “泛化性与适应性平衡” 问题。
Related Work
Class-Incremental Learning (CIL)
- 类增量学习使学习系统能够在不忘记旧概念的情况下不断融入新概念。典型的CIL方法可以分为几类。基于范例的方法保存和重放旧类中的范例以恢复以前的知识。除了直接保存范例外,其他方法还可以保存特征或使用生成模型,构建记忆。基于知识蒸馏的方法旨在更新期间对齐新旧模型的输出,从而维护旧概念的知识。对齐可以在几个方面建立,iCaRL 和LwF 利用logit蒸馏,这要求旧类的输出logit相同。LUCIR 利用特征提取并强制输出特征在模型之间相同。一些后续工作提取其他特征产品以抵抗遗忘,例如,注意力图,加权特征图,池化特征,因果效应,子空间特征和空间/时间特征。
- 此外,其他工作也考虑在一组实例中提取关系信息。第三组在增量模型中发现归纳偏差,并设计校正算法进行无偏预测。BiC 和IL2M 校准新旧类别之间的logit标度,以防止忘记以前的类别。WA 直接对全连接层进行归一化,以减轻其对最终预测的影响。SDC 通过新的类实例估计以前类的原型漂移。TEEN 设计了一个原型校准过程来调整新类别的小样本原型,以实现更好的分类。以下工作还考虑纠正有偏差的 BN 统计数据 和特征表示 。
- 最近,基于网络扩展的方法已经显示出有竞争力的性能,可以进一步分为神经元-wise、骨干-wise和令牌-wise。 Neuron-wise 扩展旨在扩展网络的宽度以增强其表示能力。 Backbone-wise 扩展方法旨在通过为每个新任务训练单独的主干并将它们聚合为最终表示来构建整体嵌入。最后,tokenwise 扩展旨在添加轻量级令牌以适应模型,同时保留其知识。 CIL 算法也广泛应用于其他实际应用中,例如联邦学习 、语义分割 、文本到图像扩散 和对象检测 。
CIL with Pre-Trained Models
-
随着预训练模型 的日益普及,基于预训练模型的 CIL 变得越来越流行。目的是顺序调整 PTM 以流式传输新类别的数据而不会忘记。L2P 基于预训练的 Vision Transformer 将视觉提示调整 应用于 CIL,并学习提示池来选择特定于实例的提示。在训练期间,L2P 检索距离查询实例最近的提示并将其附加以获得特定于实例的嵌入。 DualPrompt 通过一般提示和专家提示扩展了 L2P。具体来说,一般提示被平等地分配给所有任务,而专家提示则通过提示检索过程为特定任务选择。
-
与L2P中的键值搜索不同,CODA-Prompt 通过注意机制改进了提示选择过程,使得重新加权的提示可以反映所有看到的类的特定于任务的信息。此外,DAP 学习了一个提示生成器,它可以生成特定于实例的提示,而不是复杂的提示检索过程。 SLCA 探索了模型更新期间的分类器修正过程 。 ESN采用基于锚的能量自归一化策略来聚合多个预训练的分类器。 CPP 设计了具有对比学习目标的特定于任务的提示调整。 LAE 利用在线和离线模型之间的指数移动平均线(EMA)来防止遗忘。虽然它也考虑学习 CIL 的多个模型,但我们的工作在推理格式和更新策略上与它不同。除了视觉识别的单一模式之外,最近的研究还涉及预训练视觉语言模型的增量学习。
-
当将 ViT 更改为 CLIP 时,S-Prompts 和 Pivot 通过学习文本和图像模式的提示来扩展 L2P 。当代的一项工作 探索了 PTM 在类增量新类发现中的应用 ,这表明冻结的 PTM 可以高性能地检测和学习新类。然而,除了冻结的PTM之外,本文还探讨了下游数据在适应模型中的作用,旨在统一PTM的泛化性和下游数据的适应性。
Parameter-Efficient Tuning for Pre-Trained Models
-
参数高效调整旨在通过仅调整少量(额外)参数来使预训练模型适应下游任务。与完全微调相比,参数高效调整可以以更低的成本获得有竞争力甚至更好的性能。视觉提示调整(VPT)将可调整的前缀标记添加到输入层或隐藏层。 LoRA 学习低秩矩阵来近似参数更新。 AdaptFormer 通过缩小和放大投影来学习额外的适配器 模块。 AdapterFusion 将学习到的适配器与融合模块合并。SSF 解决了模型调整的缩放和移位操作。 BitFit 仅调整预训练模型中的偏差项,而 FacT 将每个 ViT 的权重张量化为单个 3D 张量,并在微调期间更新它。
-
除了网络中的附加模块之外,视觉提示建议学习输入空间中的可调参数。 MAM-Adapter将这些工作制定在统一的框架中,NOAH为下游任务寻找提示模块的优化设计。除了调整预先训练的 Vision Transformer 之外,CoOp 和 CoCoOp 还通过学习文本提示探索了 CLIP 提示调整的应用。 Maple 进一步促进视觉语言提示之间的强耦合,以确保相互协同。
-
研究领域 核心内容 传统 CIL 方法 分三类:1. 样例基于(保存旧类样例 / 特征,如 iCaRL);2. 知识蒸馏基于(对齐新旧模型输出,如 LwF);3. 网络扩展基于(扩展神经元 / 骨干,如 MEMO) PTM-based CIL 代表方法:L2P(视觉提示池)、DualPrompt(通用 + 专家提示)、CODA-Prompt(注意力提示选择),均依赖 ViT 骨干,缺乏通用性 参数高效调优 核心技术:VPT(视觉提示)、LoRA(低秩矩阵)、SSF(缩放偏移)、Adapter(瓶颈模块),仅调少量参数实现 PTM 自适应
From Old Classes to New Classes
-
算法 核心模块 具体功能 作用与意义 SimpleCIL 1. 冻结 PTM 嵌入模块 固定 PTM(如 ViT-B/16)的嵌入函数 φ(・),不进行任何下游参数更新 保留 PTM 的泛化性,避免微调导致的旧类遗忘 2. 原型分类器模块 计算每个新类的平均嵌入(原型) 作为分类器权重 w i = p i w_i=p_i wi=pi 无需训练分类器,直接利用类中心匹配实现分类,降低增量学习成本 Aper 1. 单阶段自适应模块 仅在第一个增量任务 D¹ 上,用参数高效调优(如 SSF、VPT)适配 PTM,得到 φ*(・) 填补 PTM 与下游数据的分布差距,获取任务特异性特征,提升新类适应性 2. 嵌入融合模块 拼接 φ*(x)(自适应嵌入)与 φ(x)(PTM 嵌入),得到融合嵌入 [φ*(x), φ(x)] 同时保留 PTM 的泛化性与自适应模型的适应性,避免单嵌入的局限性 3. 动态原型更新模块 后续增量任务(D²~Dᴮ)仅计算新类的融合原型 ,更新分类器 无需更新嵌入参数,彻底避免灾难性遗忘,同时高效学习新类 4. 余弦分类器模块 对融合嵌入与原型进行 L2 归一化,计算余弦相似度作为分类依据 避免特征尺度差异影响分类,提升原型匹配的稳定性(尤其适合高维融合嵌入)
Class-Incremental Learning
-
CIL 旨在从不断变化的数据流中学习新的类,以构建统一的分类器 。存在 B 个训练任务序列 { D 1 , D 2 , . . . , D B } \{D^1 , D^2 ,..., D^B\} {D1,D2,...,DB} ,其中 D b = { ( x i b , y i b 0 } i = 1 n b D^b = \{(x^b_i , y^b_i0\} ^{nb}_{i=1} Db={(xib,yib0}i=1nb 是具有 nb 个实例的第 b 个增量步骤。这里,训练实例 x i b ∈ R D x^b_i ∈ \R^D xib∈RD 属于类 y i ∈ Y b y_i ∈ Y_b yi∈Yb,其中 Yb 是任务 b 的标签空间。 Y b ∩ Y b ′ = ∅ Y_b∩ Y_b ′ = ∅ Yb∩Yb′=∅ 对于 b ≠ b ′ b \neq b ′ b=b′ 。在第b个训练阶段,我们只能访问Db中的数据进行模型更新。
-
本文重点关注无样本的 CIL 设置 ,其中无法获取历史数据进行排练。CIL 的目标是增量地为所有见过的类构建统一的模型,即从新类中获取知识,同时保留以前类中的知识。在每个增量任务之后,模型的能力会在所有可见类 Y b = Y 1 ∪ ⋅ ⋅ ⋅ Y b Y_b = Y_1 ∪ · · · Y_b Yb=Y1∪⋅⋅⋅Yb 上进行评估。正式而言,目标是拟合模型 f ( x ) : X → Y b f(x) : X → Y_b f(x):X→Yb,以最小化所有测试数据集的经验风险:
-
1 N ∑ ( x j , y j ) ∈ D t 1 ∪ ⋅ ⋅ ⋅ D t b ℓ ( f ( x j ) , y j ) , ( 1 ) \frac1N \sum_{(x_j ,y_j )∈D^1_t ∪···D^b_t} ℓ (f (x_j ), y_j ) , (1) N1(xj,yj)∈Dt1∪⋅⋅⋅Dtb∑ℓ(f(xj),yj),(1)
-
其中 ℓ(·,·) 衡量预测与真实标签之间的差异。 D t b D^b_t Dtb 表示任务b 的测试集,N 是实例数。一个好的 CIL 模型满足 Eq. 1 所有类别之间具有区分性,在学习新类别和记住旧类别之间取得平衡。
-
-
我们假设 ImageNet 上有预训练模型(例如 ViT 或 ResNet ),我们将其用作 f(x) 的初始化。为了清楚起见,我们将深度模型解耦为两部分: f ( x ) = W ⊤ ϕ ( x ) f(x) = W^⊤\phi(x) f(x)=W⊤ϕ(x),其中 ϕ ( ⋅ ) : R D → R d \phi(·) : \R^D → \R^d ϕ(⋅):RD→Rd 是嵌入函数, W ∈ R d × ∣ Y b ∣ W ∈ R^{d×|Yb|} W∈Rd×∣Yb∣ 是分类头。我们将 k 类的分类器表示为 w k : W = [ w 1 , ⋅ ⋅ ⋅ , w ∣ Y b ∣ ] w_k:W = [w_1, · · · , w_{|Y_b|} ] wk:W=[w1,⋅⋅⋅,w∣Yb∣] 。对于卷积网络,我们将池化后的特征称为 ϕ ( x ) \phi(x) ϕ(x) 。在普通 ViT 中,输入编码层将图像转换为输出特征序列 x e ∈ R L × d x_e ∈ \R^{L×d} xe∈RL×d ,其中 L 是序列长度。为了简化符号,我们假设 xe 中的第一个标记是 [CLS] 标记。然后 xe 被输入到后续层(即多头自注意力和 MLP)以产生最终的嵌入。我们将嵌入的 [CLS] 标记视为 ViT 的 ϕ ( x ) \phi(x) ϕ(x)。
Adaptivity and Generalizability in Class-Incremental Learning
-
具有适应性的 CIL:在将 PTM 引入 CIL 之前,模型从头开始训练,逐渐获取新类别的知识。常见的解决方案是使用交叉熵损失来更新增量模型,这使模型具有适应性以适应新任务:
-
L = ∑ ( x i , y i ) ∈ D b ℓ ( f ( x i ) , y i ) + L r e g , ( 2 ) L = \sum_{(x_i,y_i)∈D^b} ℓ (f (x_i), y_i) + L_{reg} , (2) L=(xi,yi)∈Db∑ℓ(f(xi),yi)+Lreg,(2)
-
其中 L r e g L_{reg} Lreg 代表防止遗忘的正则化项,例如知识蒸馏 或参数正则化。
-
-
具有泛化性的CIL:随着CIL引入PTM,持续学习者天生就具有泛化性,可以直接转移到下游任务而无需学习。相应地,我们定义了一个简单的基线SimpleCIL,来传输增量任务的PTM。在整个学习过程中冻结嵌入函数 ϕ ( ⋅ ) \phi(·) ϕ(⋅) 的情况下,我们提取每个类的平均嵌入(即原型):
-
p i = 1 K ∑ j = 1 ∣ D b ∣ I ( y j = i ) ϕ ( x j ) , ( 3 ) p_i = \frac1 K\sum^{|D_b|}_{j=1} I(y_j = i)ϕ(x_j ), (3) pi=K1j=1∑∣Db∣I(yj=i)ϕ(xj),(3)
-
其中 K = ∑ j = 1 ∣ D b ∣ I ( y j = i ) K = \sum^{|D_b |}_{j=1}I(y_j = i) K=∑j=1∣Db∣I(yj=i) ,I(·)为指示函数。平均嵌入代表相应类别的最常见模式。我们将原型设置为分类器,即 wi = pi ,以直接调整 CIL 的 PTM。 SimpleCIL 在图 1 中展示了具有竞争力的性能,证实了预训练模型的强大通用性。
-
-
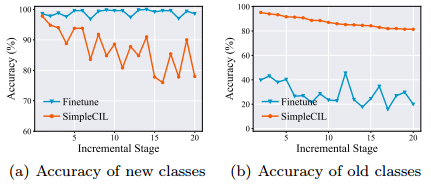
普遍性与适应性:等式 2 和等式 3 解决了 CIL 模型的不同方面。前者旨在通过逐步调整模型来增强适应性。相比之下,后者通过在整个学习过程中冻结模型来强调模型的普遍性。为了了解它们在 CIL 中的作用,我们在 CIFAR100 上进行了 20 个增量任务的实验,并比较了微调与 SimpleCIL 的性能。这些方法基于预先训练的 ViT-B/16-IN21K,我们在图 2 中分别报告了新 ( Y b Y_b Yb) 和旧 ( Y b − 1 Y_{b−1} Yb−1) 类的性能。具体来说,SimpleCIL 依赖于 PTM 的泛化性,即使没有对目标数据集进行训练,它也能具有竞争力。然而,它可以进一步改进以掌握特定于任务的特征,并且微调在自适应性的帮助下在新类中显示出更好的性能。然而,由于功能不断变化,微调会导致旧类的灾难性遗忘。
-
-
图 2:使用 PTM 的 CIL 中新旧类的性能。依次微调模型可以填补领域空白并在新类上表现更好,而冻结模型则具有更好的泛化性并在旧类上表现更好。
-
-
总而言之,这些特征是 CIL 的两个核心方面——适应性使模型能够弥合预训练和增量学习之间的领域差距。同时,泛化性鼓励知识从预训练到增量学习的转移。因此,两者都应该训练以促进CIL。
Aper: AdaPt and mERge PTMs for CIL
- 出于增强通用性和适应性的潜力,我们能否在统一的框架中实现这些特征?具体来说,我们将从两个方面来实现这一目标。一方面,为了弥合 PTM 和下游数据集之间的领域差距,模型自适应对于将 PTM 转向增量数据至关重要。另一方面,由于适应模型可能会失去高级特征的泛化性,因此我们尝试将适应模型和 PTM 合并到一个统一的网络中以用于未来的任务。合并的嵌入函数在整个增量学习过程中保持冻结,将模型集的可泛化嵌入转移到传入的新类中。这样,就在统一的框架下实现了通用性和适应性。我们首先介绍Aper的框架,然后讨论模型适配的具体技术。
Training Procedure of Aper
-
尽管 PTM 具有区分特征,但预训练数据集和增量数据之间可能存在显着的领域差距。例如,PTM 经过优化以捕获 ImageNet 中类的特征,而增量数据流可能对应于需要领域知识的专门数据或与 ImageNet 具有广泛的概念漂移。为了弥补这一差距,可以利用增量数据开发一个适应过程:
-
f ∗ ( x ) = F ( f ( x ) , D , Θ ) , ( 4 ) f^∗ (x) = F(f(x), D, Θ), (4) f∗(x)=F(f(x),D,Θ),(4)
-
其中自适应算法 F 将当前模型 f(x) 和数据集 D 作为输入。它优化参数集 θ 并生成自适应模型 f ∗ ( x ) f^* (x) f∗(x) ,从而获得相应数据集中的特定领域知识。我们在 4.2 节中介绍了 F 的变体。如果我们能够一次获得所有增量训练集,通过 F ( f ( x ) , D 1 ∪ D 2 ⋅ ⋅ ⋅ ∪ D B , θ ) F(f(x), D^1∪D^2 · · ·∪D^B, θ) F(f(x),D1∪D2⋅⋅⋅∪DB,θ) 调整模型可以将知识从 PTM 转移到增量数据集并掌握特定于任务的特征以获得更好的性能。
-
-
然而,由于 CIL 中的数据是按顺序到达的,因此我们无法一次保存所有训练集。不断调整模型将导致灾难性遗忘(如图 2(b) 所示)。因此,另一种选择是仅在第一个增量阶段调整模型:
-
f ∗ ( x ) = F ( f ( x ) , D 1 , Θ ) . ( 5 ) f ^∗ (x) = F(f(x), D^1 , Θ). (5) f∗(x)=F(f(x),D1,Θ).(5)
-
由于 D 1 D^1 D1 是增量数据流的子集,因此它还拥有可以促进模型适应的特定领域知识。调优过程增强了CIL模型的适应性,接下来的问题是确保泛化性。由于方程5 迫使原来的可泛化特征变得更加专门化到下游任务,与 D 1 D^1 D1 无关的高级特征将被覆盖和遗忘。因此,更好的解决方案是将 PTM 提取的特征和适应模型连接起来,即 [ ψ ∗ ( x ) , ψ ( x ) ] [ψ ^∗ (x), ψ(x)] [ψ∗(x),ψ(x)],其中 ψ ∗ ( x ) 和 ψ ( x ) ψ^∗ (x) 和 ψ(x) ψ∗(x)和ψ(x) 分别代表适应的嵌入函数和预训练的嵌入函数。为了保持普适性,我们在适应后冻结串联嵌入函数 [ ϕ ∗ ( ⋅ ) , ϕ ( ⋅ ) ] [\phi^∗ (·), \phi(·)] [ϕ∗(⋅),ϕ(⋅)] 并提取以下类的原型:
-
p i = 1 K ∑ j = 1 ∣ D b ∣ I ( y j = i ) [ ϕ ∗ ( x j ) , ϕ ( x j ) ] , ( 6 ) p_i = \frac1 K\sum^{|D^b |}_{j=1} I_{(y_j = i)}[ϕ ^∗ (x_j ), ϕ(x_j )] , (6) pi=K1j=1∑∣Db∣I(yj=i)[ϕ∗(xj),ϕ(xj)],(6)
-
其中 K = ∑ j = 1 ∣ D b ∣ I ( y j = i ) K = \sum^{|D_b |}_{j=1} I_{(y_j = i)} K=∑j=1∣Db∣I(yj=i) 。与等式3, 等式6相比。图包含来自适应模型的附加信息,该模型结合了特定于领域的特征以实现更好的识别。这些原型揭示了改编和预训练模型中最常见的模式,确保了通用性和适应性。我们直接采用类原型作为分类器权重,即 w i = p i w_i = p_i wi=pi ,并利用余弦分类器进行分类: f ( x ) = ( W ∥ W ∥ 2 ) ⊤ ( [ Φ ∗ ( x ) , Φ ( x ) ] ∥ [ Φ ∗ ( x ) , Φ ( x ) ] ∥ 2 ) f(x) = ( \frac W {∥W∥}^2 )^ ⊤(\frac{[Φ^∗ (x),Φ(x)]} {∥[Φ^*(x),Φ(x)]∥}^2 ) f(x)=(∥W∥W2)⊤(∥[Φ∗(x),Φ(x)]∥[Φ∗(x),Φ(x)]2)。基于实例嵌入和类原型之间的相似性,它为具有更相似原型的类分配更高的概率。
-
-
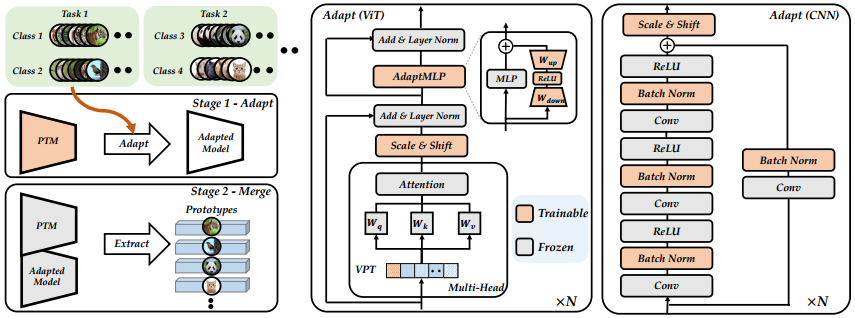
适应和合并的效果:我们在图 3(左)中给出了 Aper 的可视化。尽管 D1 是整个训练集的子集,但对其进行调整仍然有助于将 PTM 从上游数据集转移到下游任务。适应过程可以被视为进一步的预训练过程,它将 PTM 适应增量数据集并弥合领域差距。通过合并 PTM 和自适应模型的嵌入函数,提取的特征比单独使用其中任何一种特征都更具代表性。此外,由于模型只能在第一个增量任务中进行训练,因此 Aper 的效率与不需要顺序调优的 SimpleCIL 相当。
-
-
图 3:Aper 的插图。左:Aper 的训练协议。我们使用第一阶段训练集 D1 来调整 PTM,然后将 PTM 的嵌入函数和调整后的模型连接起来,以保持通用性和适应性。聚合嵌入函数 [ψ*(·), ψ(·)] 在接下来的阶段中被冻结,我们通过方程 6 提取原型。 设置分类器。中:针对 CIL 调整预训练的 ViT。我们提供VPT Deep/Shallow、Scale & Shift、Adapter用于模型适配。右:针对 CIL 调整预训练的 CNN。我们提供 BN 调优和 Scale & Shift 来进行模型适配。Aper是一个可以与这些适配技术正交结合的通用框架。图中红色模块是可训练的,灰色模块是冻结的。
-
-
另一方面,由于模型在后续任务中被冻结,因此它不会遭受对先前概念的灾难性遗忘。我们给出了算法1中Aper的伪代码。给定预先训练的模型,我们首先通过等式5使用第一个训练数据集对其进行调整。 得到适配模型。之后,我们冻结预训练模型和适应模型并合并嵌入。对于后续任务,我们获得一个新的数据集,并用原型特征(即类中心)替换分类器权重。在极端情况下,方程5中的适应过程。 对 PTM 没有任何作用,Aper 将降级为 SimpleCIL,这保证了性能下限。

Adapting the PTM
-
为了弥合预训练数据集和增量数据集之间的分布差距,Aper 的性能取决于有效的自适应算法 F。在本节中,我们讨论 Aper 中 F 的六个专业化,它们可以处理不同类型的 PTM,例如 ViT 和 CNN。
-
完全微调:是将模型转移到下游任务时的常见解决方案。它涉及调整适应过程中的所有参数,即 θ = θ ψ ∪ θ W θ = θ_ψ∪θ_W θ=θψ∪θW ,并最小化模型输出与真实情况之间的差异:
-
min θ ϕ ∪ θ W ∑ ( x j , y j ) ∈ D 1 ℓ ( f ( x j ) , y j ) . ( 7 ) \min_{θ_ϕ∪θ_W}\sum_{(x_j ,y_j )∈D^1} ℓ (f (x_j ), y_j ) . (7) θϕ∪θWmin(xj,yj)∈D1∑ℓ(f(xj),yj).(7)
-
然而,对于大规模的PTM,例如ViT,调谐成本可能相对较高,因此,一些参数有效的调谐技术可以减轻调谐成本,并且是更好的解决方案。
-
-
Visual Prompt Tuning(VPT):是一种用于自适应ViT的轻量级调优技术,它只预先添加一些可学习的提示 P ∈ R p × d P ∈ \R^{p×d} P∈Rp×d 以形成扩展特征 [ P , x e ] [P,x_e] [P,xe],其中xe是输入图像的编码特征。然后将扩展特征馈送到ViT的后续层以计算最终嵌入。VPT有两种变体:VPT-Deep,在每个注意层都预先添加提示,VPT-Shallow,只在第一层添加提示。在优化过程中,它冻结嵌入函数中的预训练权重,并优化这些提示和分类头,即 Θ = θ P ∪ θ W Θ = θ_P ∪θ_W Θ=θP∪θW。
-
Scale & Shift(SSF):旨在通过缩放和移位来调整特征激活。它在每个操作层(即MSA和MLP)之后添加额外的SSF层,并调整这些操作的输出。给定输入 x i ∈ R L × d x_i ∈ \R^{L×d} xi∈RL×d ,输出 x o ∈ R L × d x_o ∈ \R^{L×d} xo∈RL×d 被公式化为:
-
x o = γ ⊗ x i + β , ( 8 ) x_o = γ ⊗ x_i + β , (8) xo=γ⊗xi+β,(8)
-
其中 γ ∈ R d γ ∈ \R^d γ∈Rd 和 β ∈ R d β ∈ \R^d β∈Rd 分别是尺度因子和移位因子,θ是Hadamard乘积(元素乘),该模型通过优化SSF层和分类器,即 Θ = θ S S F ∪ θ W Θ = θ_{SSF} \cup θ_W Θ=θSSF∪θW,来跟踪新任务的特征.
-
-
适配器:是一个瓶颈模块,它包含一个用于降低特征维数的下投影 W d o w n ∈ R d × r W_{down} ∈ \R^{d×r} Wdown∈Rd×r,一个非线性激活函数,以及一个用于投影回原始维数的上投影 W u p ∈ R r × d W_{up} ∈ \R^{r×d} Wup∈Rr×d。我们按照为ViT中的原始MLP结构配备适配器。我们将MLP层的输入表示为x,AdaptMLP的输出格式为:
-
M L P ( x ℓ ) + R e L U ( x ℓ W d o w n ) W u p . ( 9 ) MLP(x_ℓ) + ReLU(x_ℓW_{down})W_{up} . (9) MLP(xℓ)+ReLU(xℓWdown)Wup.(9)
-
通过冻结预训练的权重,它优化了适配器和分类头,即 Θ = θ W d o w n ∪ θ W u p ∪ θ W Θ = θ_{Wdown} \cup θ_{Wup} \cup θ_W Θ=θWdown∪θWup∪θW。
-
-
批量归一化调整:如果PTM是卷积网络,例如CNN,我们可以调整BN 参数。由于BN中的运行均值和方差与上游数据分布兼容,因此它们对于下游任务可能不稳定。相应地,我们可以重置BN中的运行统计数据,并通过前向传递适应当前数据。不需要反向传播,使预训练模型变得快速而简单。
-
讨论:我们在图3中可视化了Aper的自适应过程。与完全微调相比,参数高效调优通过轻量级模块将PTM调整到下游任务。此外,最近的参数高效调优方法显示出比完全微调更强的性能,这表明自适应过程具有更强的自适应性。适应后的模型可以捕获增量数据中的专业特征,从而带来更好的自适应性。由于L2 P和DualPrompt基于预先训练的ViT,因此它们不能与CNN一起部署。相比之下,Aper是一个有效处理不同结构的通用框架。具体来说,Aper可以与ViT的VPT/SSF/Adapter和CNN的SSF/BN Tuning相结合。由于Aper采用基于原型的分类器,在自适应之后将丢弃线性分类器W。
Discussions on related concepts
-
CIL中有一个著名的概念,即“稳定性-可塑性困境”。具体而言,“稳定性”表示持续学习者记忆旧知识的能力,而“可塑性”则表示学习新概念的能力。这些概念与本文中的“概括性和适应性”概念相似,但有一些主要差异需要强调。
-
首先,“稳定性-可塑性困境”主要是指从无到有的训练问题(即随机初始化的权重),其中模型需要平衡学习新概念和记忆旧概念,这些概念是持续学习的两个最终目标,与本文提出的“泛化性和适应性”并不冲突。其次,本文中的“泛化和自适应”是PTM时代的新特征,具体来说,随机初始化的模型不具有这种“泛化性”,不能直接应用于下游任务。
-
然而,如果从PTM开始,持续学习者天生就具有“泛化能力”,我们观察到简单的基线表现出很强的性能。此外,我们发现“泛化能力”对于所有下游任务都是不够的,特别是当下游任务来自不同的分布时。在这种情况下,我们需要通过进一步调整PTM来增强PTM的“适应性”。最后,通过聚集由预训练和适应的模型提取的特征,我们将这些特征统一在单个模型中。
-
综上所述,本文中的“泛化性和自适应性”是类增量学习中的一个新特性–使用预训练模型。我们的目标是将这些特性统一到CIL中,并通过聚合自适应和预训练模型来提出我们的Aper。
Experiments
- 本节在基准数据集上将Aper与最先进的方法进行比较,以显示其优越性。由于预训练数据集与传统的类增量学习基准之间的重叠,我们还提出了四个新的基准来评估基于PTM的方法。消融和可视化验证了Aper对新类的有效性。我们还探索了不同预训练模型在类增量学习中的性能。
Implementation Details
-
数据集:在之后,我们评估了CIFAR 100 ,CUB 200 和ImageNet R的性能。由于PTM通常使用ImageNet 21 K 进行训练,因此使用ImageNet评估基于PTM的方法是没有意义的。因此,我们提出了四个与ImageNet具有较大领域差距的新数据集,即ImageNet-A ,ObjectNet ,Omnibenchmark 和VTAB 。其中,ImageNet-A和ObjectNet包含ImageNet预训练模型无法处理的挑战性样本,而Omnibenchmark和VTAB包含来自多个复杂领域的不同类。
-
为了构建CIL任务,我们从ObjectNet和ImageNet-A中抽取200个类,从Omnibenchmark中抽取300个类。我们从VTAB中抽取5个数据集,每个数据集包含10个类,以构建跨域CIL设置。使用子集的目的是确保训练类的简单拆分。在之后,我们使用相同的随机种子对类进行洗牌,并将它们拆分为“B/Base-m”,Inc-n。'表示第一个数据集包含m个类,后面的每个数据集包含n个类。m = 0表示总类平均分配到每个任务中。
-
比较方法:我们首先比较了基于SOTA PTM的CIL方法L2 P ,DualPrompt ,CODA-Prompt ,CPP 和LAE 。此外,我们还修改了经典的CIL方法LwF ,SDC ,iCaRL ,LUCIR ,DER ,FOSTER ,MEMO ,FACT 使用相同的PTM作为初始化。除了SimpleCIL,我们还报告基线,顺序调整模型,表示为Finetune。
-
训练详情:我们使用PyTorch 和Pilot 在具有相同网络骨干的Tesla V100上部署所有模型。由于有各种PTM公开可用,我们遵循选择最具代表性的PTM,表示为ViT-B/16-IN 1 K和ViT-B/16-IN 21 K。两者都在ImageNet 21 K上进行了预训练,而前者在ImageNet 1 K上进行了额外的微调。在自适应过程中,我们以48的批量训练模型20个epochs,并使用带有动量的SGD进行优化。学习率从0.01开始,以余弦退火衰减。对于VPT,提示长度p为5,适配器的投影调光器为16。
-
评价方案:在之后,我们将第b个阶段之后的精度表示为 A b A_b Ab。我们使用 A B A_B AB(最后一个阶段之后的性能)和 A ˉ = 1 B ∑ b = 1 B A b \bar A =\frac 1 B \sum^B_{b=1} A_b Aˉ=B1∑b=1BAb(沿着递增阶段的平均性能)作为测量值。
Benchmark Comparison
-
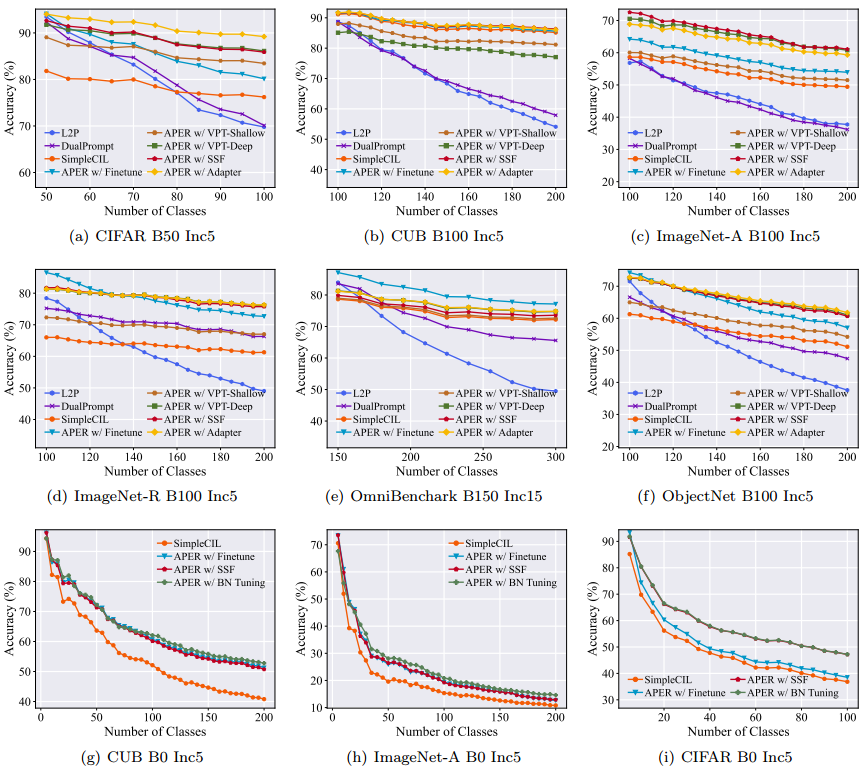
我们在表1中报告了SOTA方法的性能,其中所有方法都基于预训练的ViT-B/16-IN 21 K。我们还使用预训练的ViT-B/16-IN 1 K训练这些模型,并在图4(a)和图4(f)中显示了增量趋势。这些数据分割包括用于整体评估的大小基类设置。
-
-
图 4:(a)∼(f):当总类的一半是基类时,以 ViT-B/16-IN1K 作为骨干的增量性能。 (g)∼(i):使用 ResNet18 作为主干时的增量性能。由于 L2P 和 Dualprompt 无法与 ResNet 一起部署,因此我们没有在 (g)∼(i) 中报告它们的性能。 Aper 不断提高不同主干网(即 ViT 和 CNN)的性能。
-
-
首先,我们可以推断PTM的嵌入是可推广的,可以直接应用于CIL以击败SOTA。具体来说,基线SimpleCIL在CUB上的表现优于DualPrompt 20%,在ImageNet-A上的表现优于AB 8%。但是,如果通过Aper进行调整,则可以进一步改进强PTM,因为下游任务与预训练数据集有很大的域差距。具体来说,我们发现Aper在七个基准数据集上的表现一直优于SimpleCIL。相比之下,顺序微调模型会遭受严重的遗忘,这验证了adapt和merge协议的有效性。具体来说,L2 P和DualPrompt由于提示在后期被覆盖以及线性层的不平衡权重规范而遭受遗忘。在第一阶段调整PTM,它需要比L2 P和DualPrompt更少的训练时间和额外的参数,如图1所示。在适应技术的变体中,我们发现SSF和Adapter比VPT更有效。我们还将其与最先进的传统CIL方法进行比较,并将其骨干修改为预训练的ViT。然而,我们可以从表2中推断出,这些方法在没有样本的情况下效果很差。因此,在公平比较下,Aper实现了与各种CIL算法相比的最佳性能。
-
除了ViTs,Aper也能很好地与预训练的CNN配合使用。我们采用ImageNet 1K预训练的ResNet 18 进行评估,并在图4(g),4(h),4(i)中绘制了增量性能。结果表明,Aper始终提高了预训练ViTs和CNN的性能。具体来说,我们发现一种简单的BN调整技术比完全或部分微调ResNet实现了更好的性能。
-
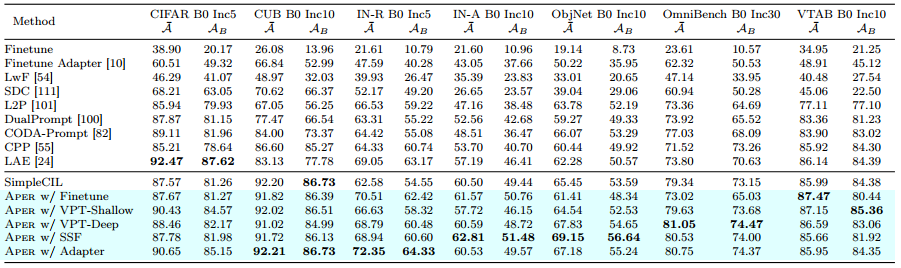
-
表 1:以 ViT-B/16-IN21K 作为骨干的七个数据集的平均和最后性能比较。 “IN-R/A”代表“ImageNet-R/A”,“ObjNet”代表“ObjectNet”,“OmniBench”代表“OmniBenchmark”。最佳性能以粗体显示。
-
-
最后,如表1所示,典型基准测试的性能接近饱和,因为它们与ImageNet之间的域差距很小。相比之下,由于我们新建立的基准测试与ImageNet之间的域差距很大,仍然有改进的空间,表明这些新基准测试的有效性和必要性。
-
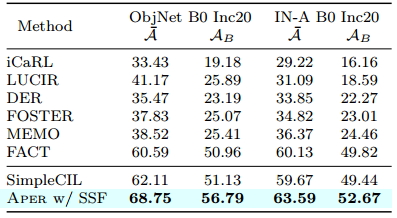
-
表 2:与使用 ViT-B/16-IN1K 的 SOTA 经典 CIL 方法进行比较。所有方法均在没有示例的情况下进行部署。
-
Ablation Study
- 在本节中,我们进行了消融研究,以调查Aper中每个部分的影响,例如,使用采样特征,其组件的一部分,以及不同的调谐阶段。我们还分析了不同方法的参数数量。
Downscale features
-
由于Aper的特征是与PTM和自适应模型聚合在一起的,因此它具有比普通PTM更大的特征维度(例如,1536对768)。具体来说,我们在第一阶段训练PCA 模型,以减少后续阶段的嵌入维数。将目标维度表示为k,我们训练PCA模型 P C A ( [ k ( x ), k ( x ) ] ): R d → R k PCA([k(x),k(x)]):\R^d → \R^k PCA([k(x),k(x)]):Rd→Rk,并将其附加到特征提取器。因此,特征和原型被投影到k维。我们在图5(a)中绘制了性能随k的变化。具体来说,我们发现Aper获得了与 DualPrompt(具有768个dims)竞争的性能,即使特征被投影到30个dims。
-
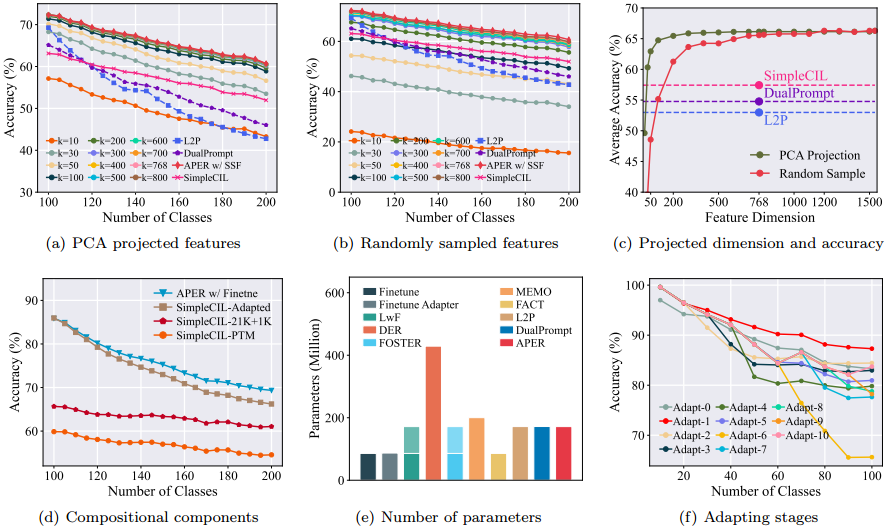
-
图 5:消融研究。 (a)-©:我们使用 PCA 或随机样本来缩小聚合嵌入的维度。(d):我们将 Aper 与其子模块进行消融比较。 (e):不同比较方法的总参数数量。带阴影的条表示训练期间使用但推理期间丢弃的参数。 (f):随着适应阶段变化的准确率趋势。 Adapt-T 表示模型适用于前 T 个增量任务。 T = 0 表示 SimpleCIL。
-
-
除了PCA投影,我们还从原始特征空间中随机抽取k个特征进行实验,并在图5(B)中报告结果。结论与前面的一致,表明在级联空间中随机抽取200个维度可以实现与DualPrompt相同的性能尺度。我们在图5(c)中显示了准确度-维度曲线。
Sub-modules
-
由于Aper与PTM和适配模型串联在一起,因此我们使用ViT-B/16-IN 21 K在ImageNet-A Base 100 Inc 5上进行消融,以比较Aper w/ Finetune及其子模块。具体来说,我们分别使用SimpleCIL(·)和SimpleCIL(·)构建SimpleCIL,表示为SimpleCIL-PTM和SimpleCIL-Adapted。前者代表PTM的能力,另外,我们基于级联预训练的ViT-B/16-IN 21 K和ViT-B/16-IN 1 K构建SimpleCIL,记为SimpleCIL 21 K +1 K。它利用了两个嵌入函数的聚合特征,其具有与Aper相同的尺寸。
-
如图5(d)所示,SimpleCIL-PTM在所有变体中表现最差,表明尽管预训练的特征是有效的和可推广的,但它仍然需要提取下游任务的特征以更好地表示。相比之下,SimpleCIL-Adapted优于SimpleCIL-PTM,表明模型自适应和自适应性的重要性。然而,自适应模型也覆盖了高级特征,这降低了模型的泛化能力,适应后的模型比普通SimpleCIL遭受更广泛的性能下降,表明泛化能力在抵抗遗忘方面的作用。最后,Aper w/ Finetune在统一的自适应性和通用性的帮助下优于任何这些子模块。
Parameter scale
- 参数规模是影响CIL算法在现实世界应用中的另一个核心因素,例如边缘设备或移动的手机。在本节中,我们比较了不同方法的参数规模,以研究实际应用的可能性。在比较中,所有方法都基于预训练的ViT。对于需要主干扩展的方法(例如,DER,MEMO和FOSTER),我们还使用预训练的ViT作为新主干的初始化。
- 我们在图5(e)中列出了所有比较方法的参数总数,这表明Aper比具有相同规模或更少参数的比较方法获得更好的性能。由于L2P和DualPrompt具有提示池,它们依赖于另一个预先训练的ViT作为“检索器”来搜索特定于实例的提示。因此,Aper与这些方法共享相同规模的总参数。此外,由于Aper使用参数有效的调整技术来获得自适应模型,因此自适应模型中的大多数参数与预训练的权重相同。因此,Aper的内存预算可以进一步减轻,我们将在未来的工作中探索。
Influence of Adapting Stages
-
在Aper中,我们只使用D1在第一个增量阶段调整预训练的模型。原因有两个:1)顺序调整模型将遭受灾难性的遗忘。2)由于我们使用基于原型的分类器,因此调整模型多个阶段将导致前原型和新原型之间的功能不兼容。
-
在本节中,我们进行消融以确定适应阶段的影响,并在图5(f)中报告结果。我们使用预先训练的ViT-B/16-IN 21 K在CIFAR 100 Base 0 Inc 10设置上进行实验。总共有10个增量阶段。我们将调整阶段表示为T,并训练Aper w/ Adapter进行消融。具体来说,我们在{0,1,2,· · ·,10}之间改变调整阶段,以确定对最终性能的影响。在前T阶段,我们使用适配器增量地调整PTM,并使用原型替换分类器。之后,在第T阶段,我们冻结编码函数,只提取以下阶段的原型。T = 0表示vanilla SimpleCIL。为了防止遗忘,我们在学习新类时冻结以前类的分类器权重。
-
如图所示,在所有设置中,使用第一阶段调优模型可获得最佳性能。具体而言,多阶段调优会损害泛化能力,并导致前一个类和新类的功能不兼容。
Different PTMs
-
通过观察ViT-B/16-IN 21 K和ViT-B/16-IN 1 K之间的性能差距,我们试图在ImageNet-R Base 0 Inc 20上探索不同类型的PTM。我们选择公开可用的PTM,即ResNet 18/50/152 [31],ViT-B/16-IN 1 K/21 K,ViT-L/16 IN 1 K,ViT-B/16-DINO-v2 ,ViT-B/16-SAM [11],ViT-B/16-MAE 、ViT-B/16-CLIP (图像编码器)进行整体评估,并在图6中报告结果。我们可以得出三个主要结论。首先,通过使用SimpleCIL实现更好的性能,预训练的ViTs比ResNets表现出更好的泛化能力。主要原因来自更广泛的训练数据和参数。其次,较大的ViT比较小的ViT更好地泛化,并且用监督损失训练的ViT比无监督的ViT表现得更好。
-
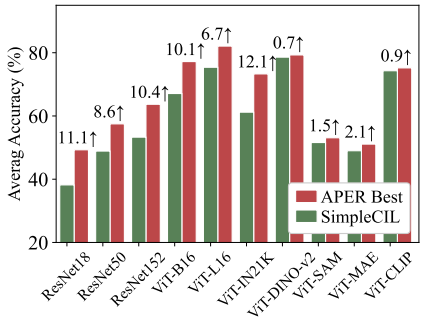
-
图 6:ImageNet-R Base0 Inc20 上具有不同类型 PTM 的 CIL。 Aper 持续改进不同 PTM 的性能。我们报告了图中 Aper 的最佳变体及其相对于图中 SimpleCIL 的改进。
-
-
然而,DINO-v2由于其1.2B的训练实例而表现出最好的性能。第三,由于大量的训练语料和跨模态信息,CLIP的性能优于ImageNet 21 K预训练的ViT。最后,我们发现最好的Aper变化一致地提高了SimpleCIL对任何PTM的性能,从而验证了其有效性。
Visualization of Incremental Sessions
-
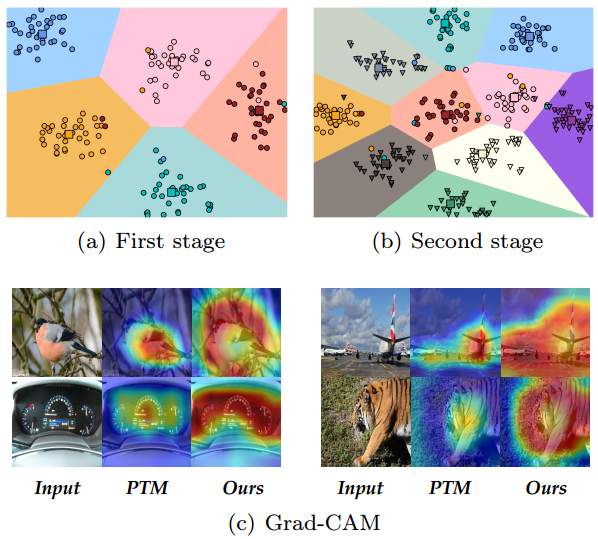
在本节中,我们在CIFAR 100数据集上使用t-SNE 可视化两个增量阶段之间的学习决策边界,如图7(a),7(B)所示。我们用彩色点和三角形可视化第一个和第二个增量任务的类。相应地,类原型用正方形表示。从这些图中可以推断,PTM具有竞争力,该模型将实例划分为相应的类,类原型位于每个类的中心,验证了类原型在识别中的代表性,从第一阶段扩展到第二阶段,我们发现Aper在新老类上都有很好的表现,可视化验证了Aper的泛化能力和自适应能力.
-
-
图 7:顶部:CIFAR100 上两个增量任务之间决策边界的可视化。点代表旧类,三角形代表新类。
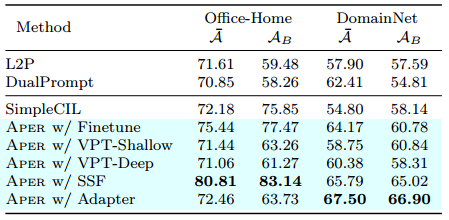
决策边界用阴影区域显示。底部:PTM 和 Aper 的 Grad-CAM 可视化。重要区域用暖色突出显示。
-
-
我们还基于预训练的ResNet 18 在 OmniBenchmark数据集上可视化了Grad-CAM 结果。Grad-CAM用于突出图像中的关键区域以预测相应的概念。结果如图7(c)所示,表明Aper比vanilla PTM更关注任务特定特征。因此,可视化验证了自适应在基于PTM的类增量学习中的重要性。
Experiments with Multiple Domains
-
本文主要考虑CIL设置,其中所有数据都来自同一个域。然而,我们也考虑了两个具有挑战性的任务来研究具有显著域差距的性能。1):使用Domain-Home数据集的域增量学习。Bull-Home是一个领域适应的基准数据集,包含四个领域,每个领域由65个类别组成。
-
这四个领域是:艺术,剪贴画,产品和现实世界,平均每个类大约70张图像,最多99张图像。我们按照组织领域增量学习场景,其中每个任务包含一个新领域的类。2):跨域数据的类增量学习。我们遵循并将DomainNet 分为五个任务。具体来说,DomainNet是六个不同领域中常见对象的数据集。所有领域包括345个对象类。这些领域包括剪贴画,真实的,草图,信息图,绘画和快速绘制。为了构建类增量学习设置,我们将数据集分为五个任务,每个域包含69类单独的域。
-
上述设置包含来自多个域的数据集,我们在表3中报告了实验结果。我们对所有比较方法采用相同的预训练ViT-B/16-IN 1 K。尽管Aper没有专门设计多个阶段,但在这些跨域任务中,它仍然表现出与L2 P和DualPrompt竞争的性能。
-
-
表3:领域增量学习和跨领域CIL实验。所有方法均使用预先训练的 ViT-B/16-IN1K 来实现。
-
Conclusion
-
增量类学习在实际应用中具有重要意义,它要求具有更新的自适应性和知识转移的泛化性。本文系统地回顾了具有PTM的CIL,并得出三个结论。首先,冻结PTM可以为CIL提供可泛化的嵌入,使基于原型的分类器能够超越当前的最新技术水平。其次,由于预训练数据集和下游数据集之间的分布差距,可以进一步利用PTM来增强其自适应性。
-
为此,我们提出了Aper,它可以与任何参数有效的调整方法正交组合,以统一CIL的通用性和自适应性。最后,由于数据重叠,传统的基于ImageNet的基准测试不适合在PTM时代进行评估。因此,我们提出了四个新的基准来评估基于PTM的CIL方法。大量的实验验证了Aper的最先进的性能。未来的工作包括探索特定于任务的调优方法和结构。
-
局限性:该模型的局限性有两个方面。首先,由于适应模型应该充分反映下游特征,因此该模型不能充分利用样本。如果有足够的旧类实例可用,则会变成基于样本的CIL,其中可以通过数据排练进一步解决适应性问题。其次,由于Aper仅在第一个增量阶段进行适应,当持续学习过程中存在广泛的领域差距时,它将面临挑战,即领域增量学习。总之,将Aper扩展到这些更具挑战性的场景是未来有趣的工作。
Aper 框架:泛化性与适应性的统一
-
核心流程,自适应阶段:仅用第一个增量任务 D¹,通过参数高效调优(如 VPT、SSF)得到自适应模型 φ*(x),获取下游任务特异性特征。融合阶段:冻结 φ*(x) 与原始 PTM 的 φ(x),将二者嵌入拼接为 [φ*(x),φ(x)],保留泛化性与适应性。增量阶段:后续任务(D² 至 Dᴮ)仅计算新类的原型(基于拼接嵌入),更新分类器,不调整嵌入函数,避免遗忘。
-
技术类型 适用骨干 调优对象 核心优势 全微调 ViT/CNN 所有 PTM 参数 适应性强,成本高 VPT(Deep/Shallow) ViT 输入 / 隐藏层的可学习提示 轻量,ViT 专用 SSF ViT/CNN 缩放因子 γ、偏移因子 β 计算量小,通用性强 Adapter ViT 瓶颈模块(下投影 + 激活 + 上投影) 参数效率高 BN 调优 CNN BN 层的运行均值 / 方差 无需反向传播,速度快
-
-
PTM 的泛化嵌入是 CIL 的关键,SimpleCIL 可直接利用该特性超越 SOTA;Aper 通过 “单阶段自适应 + 嵌入融合” 平衡泛化性与适应性;新基准更适合评估 PTM-based CIL。
-
核心原因是预训练模型(PTM)的强泛化嵌入能力。PTM 经 ImageNet-1K/21K 等大规模数据预训练,已学习到通用视觉特征,其嵌入函数 φ(・) 可对不同类别形成具有区分度的表征;SimpleCIL 通过冻结 φ(・)、计算类平均嵌入(原型)作为分类器,本质是直接利用 PTM 的泛化知识进行类别匹配,无需下游训练即可实现有效分类;而 L2P、DualPrompt 等 SOTA 虽引入提示调优,但需动态更新提示池 / 分类器,易因参数调整破坏 PTM 的原始泛化性,且训练过程中可能出现 “提示过拟合”,反而降低分类性能。
-
Aper 框架如何避免 “自适应导致泛化性丢失” 的矛盾,实现泛化性与适应性的平衡?通过 “三阶段设计” 解决矛盾:
- 自适应限制:仅在第一个增量任务 D¹ 上对 PTM 进行参数高效调优(如 VPT、SSF),获取下游任务特异性特征(φ*(x)),避免多阶段调优导致的旧类知识遗忘;
- 嵌入融合:将自适应模型的 φ*(x) 与原始 PTM 的 φ(x) 拼接为 [φ*(x),φ(x)],同时保留 “下游适应性特征” 与 “PTM 泛化特征”;
- 后续冻结:融合后的嵌入函数在后续增量任务(D² 至 Dᴮ)中完全冻结,仅通过计算新类原型更新分类器,既避免嵌入特征漂移,又确保新类学习不影响旧类知识,最终实现 “泛化性不丢失、适应性不削弱” 的平衡。
-
PTM 泛化性优先:认为 PTM 的大规模预训练已学习到通用视觉特征,冻结嵌入可直接迁移至 CIL(SimpleCIL 的核心思想);原型学习简化分类:用 “类平均嵌入” 代表类别典型特征,替代传统训练的线性分类器,减少增量阶段的参数更新(降低遗忘风险);单阶段自适应控风险:仅在第一个增量任务适配 PTM,避免多阶段微调导致的泛化性丢失(解决 “微调 - 遗忘” 矛盾);嵌入融合平衡矛盾:通过 “泛化嵌入 + 适应嵌入” 拼接,实现 “旧类不遗忘(泛化性)、新类学得好(适应性)” 的双赢。
-
原型计算:SimpleCIL 原型,类平均嵌入, p i = 1 K ∑ j = 1 ∣ D b ∣ I ( y j = i ) ⋅ ϕ ( x j ) p_i = \frac{1}{K} \sum_{j=1}^{|D^b|} \mathbb{I}(y_j=i) \cdot \phi(x_j) pi=K1∑j=1∣Db∣I(yj=i)⋅ϕ(xj)。其中,K 是第i类在 D b D^b Db 中的样本数, I ( ⋅ ) \mathbb{I}(\cdot) I(⋅) 是指示函数( y j = i y_j=i yj=i时为 1,否则为 0), ϕ ( x j ) \phi(x_j) ϕ(xj) 是 PTM 对 x j x_j xj 的嵌入。意义:用类内样本的平均嵌入代表 “类别中心”,符合人类对 “类别典型特征” 的认知,且计算简单无需训练。Aper 融合原型 p i = 1 K ∑ j = 1 ∣ D b ∣ I ( y j = i ) ⋅ [ ϕ ∗ ( x j ) , ϕ ( x j ) ] p_i = \frac{1}{K} \sum_{j=1}^{|D^b|} \mathbb{I}(y_j=i) \cdot [\phi^*(x_j), \phi(x_j)] pi=K1∑j=1∣Db∣I(yj=i)⋅[ϕ∗(xj),ϕ(xj)]。意义:在原型中融入自适应嵌入 ϕ ∗ ( x j ) \phi^*(x_j) ϕ∗(xj),补充下游任务特异性信息,提升新类分类精度。
-
单阶段自适应:模型适配,自适应模型生成, f ∗ ( x ) = F ( f ( x ) , D 1 , Θ ) f^*(x) = \mathcal{F}(f(x), D^1, \Theta) f∗(x)=F(f(x),D1,Θ)。其中, F \mathcal{F} F 是参数高效调优函数(如 SSF、VPT), Θ \Theta Θ 是待优化参数(如 SSF 的缩放因子 γ \gamma γ、偏移因子 β \beta β), D 1 D^1 D1 是第一个增量任务数据。意义:仅用少量参数(如 SSF 仅调 γ \gamma γ和 β \beta β适配 PTM,降低计算成本,同时避免 PTM 泛化性被覆盖。
-
分类决策:余弦相似度, f ( x ) = ( W ∥ W ∥ 2 ) ⊤ ⋅ ( [ ϕ ∗ ( x ) , ϕ ( x ) ] ∥ [ ϕ ∗ ( x ) , ϕ ( x ) ] ∥ 2 ) f(x) = \left( \frac{W}{\|W\|_2} \right)^\top \cdot \left( \frac{[\phi^*(x), \phi(x)]}{\|[\phi^*(x), \phi(x)]\|_2} \right) f(x)=(∥W∥2W)⊤⋅(∥[ϕ∗(x),ϕ(x)]∥2[ϕ∗(x),ϕ(x)]),其中,W是原型集合( W = [ p 1 , p 2 , . . . , p C ] W=[p_1, p_2, ..., p_C] W=[p1,p2,...,pC]), ∥ ⋅ ∥ 2 \| \cdot \|_2 ∥⋅∥2 是 L2 归一化。意义:归一化后消除特征尺度差异,使分类仅依赖 “嵌入与原型的相似性”,更适合原型学习场景。
-
损失函数:仅用于自适应阶段,自适应阶段(D¹)采用交叉熵损失,优化 Θ \Theta Θ(如 SSF 参数): L = ∑ ( x i , y i ) ∈ D 1 ℓ ( f ( x i ) , y i ) \mathcal{L} = \sum_{(x_i, y_i) \in D^1} \ell(f(x_i), y_i) L=∑(xi,yi)∈D1ℓ(f(xi),yi) 其中 ℓ ( ⋅ ) \ell(\cdot) ℓ(⋅) 是交叉熵损失, f ( x i ) f(x_i) f(xi) 是余弦分类器的输出。意义:仅在第一阶段优化自适应模块,后续阶段无损失计算(仅更新原型),彻底避免参数漂移导致的遗忘。
-
阶段 1:第一增量任务 D 1 D^1 D1(自适应 + 融合)
-
输入层: D t r a i n 1 D^1_{train} Dtrain1的预处理图像x输入 ViT-B/16(预训练权重冻结);
-
PTM 嵌入层:ViT 的 [CLS] token 输出基础嵌入 ϕ ( x ) ∈ R 768 \phi(x) \in \mathbb{R}^{768} ϕ(x)∈R768;
-
自适应层:通过 SSF 模块调整 ϕ ( x ) \phi(x) ϕ(x)—— x o = γ ⊗ ϕ ( x ) + β x_o = \gamma \otimes \phi(x) + \beta xo=γ⊗ϕ(x)+β( γ , β ∈ R 768 \gamma, \beta \in \mathbb{R}^{768} γ,β∈R768为可学习参数),得到自适应嵌入 ϕ ∗ ( x ) ∈ R 768 \phi^*(x) \in \mathbb{R}^{768} ϕ∗(x)∈R768;
-
融合层:拼接 ϕ ∗ ( x ) \phi^*(x) ϕ∗(x)与 ϕ ( x ) \phi(x) ϕ(x),得到融合嵌入 [ ϕ ∗ ( x ) , ϕ ( x ) ] ∈ R 1536 [\phi^*(x), \phi(x)] \in \mathbb{R}^{1536} [ϕ∗(x),ϕ(x)]∈R1536;
-
原型计算:用 D t r a i n 1 D^1_{train} Dtrain1的融合嵌入计算 5 个类的原型 P 1 = { p 1 1 , p 2 1 , . . . , p 5 1 } P^1 = \{p_1^1, p_2^1, ..., p_5^1\} P1={p11,p21,...,p51};
-
分类层:融合嵌入与 P 1 P^1 P1通过余弦分类器输出预测概率 f ( x ) f(x) f(x)。
-
-
阶段 2:第二增量任务 D 2 D^2 D2(仅原型更新)
-
输入层: D t r a i n 2 D^2_{train} Dtrain2的预处理图像x输入模型;
-
嵌入层:直接使用阶段 1 冻结的 ϕ ( x ) \phi(x) ϕ(x)和 ϕ ∗ ( x ) \phi^*(x) ϕ∗(x),输出融合嵌入(无参数更新);
-
原型计算:计算 D 2 D^2 D2的 5 个类的原型 P 2 = { p 1 2 , . . . , p 5 2 } P^2 = \{p_1^2, ..., p_5^2\} P2={p12,...,p52};
-
分类器更新:将 P 2 P^2 P2加入原型集合,新分类器权重 W = [ P 1 , P 2 ] W = [P^1, P^2] W=[P1,P2](无其他参数更新)。
-
-
仅阶段 1(D¹)有优化:损失函数为交叉熵损失 L = ∑ x ∈ D t r a i n 1 ℓ ( f ( x ) , y ) \mathcal{L} = \sum_{x \in D^1_{train}} \ell(f(x), y) L=∑x∈Dtrain1ℓ(f(x),y),优化对象仅为 SSF 的 γ \gamma γ和 β \beta β(PTM 参数冻结);优化器:SGD(动量 0.9),学习率 0.01,余弦退火衰减,batch size=48,训练 20 epoch;阶段 220(D²D²⁰)无优化:仅计算新类原型,不更新任何嵌入参数,无损失回传与梯度下降。
-
保存内容冻结的 PTM 嵌入函数 ϕ ( ⋅ ) \phi(·) ϕ(⋅)的参数(ViT 预训练权重);冻结的自适应嵌入函数 ϕ ∗ ( ⋅ ) \phi^*(·) ϕ∗(⋅)的参数(如 SSF 的 γ \gamma γ、 β \beta β);所有增量阶段的类原型集合 { P 1 , P 2 , . . . , P 20 } \{P^1, P^2, ..., P^{20}\} {P1,P2,...,P20}(即分类器权重W)。
-
推理阶段操作与后处理输入处理:测试图像 x t e s t x_{test} xtest经预处理(resize + 归一化);嵌入计算:输出融合嵌入 [ ϕ ∗ ( x t e s t ) , ϕ ( x t e s t ) ] [\phi^*(x_{test}), \phi(x_{test})] [ϕ∗(xtest),ϕ(xtest)];相似度计算:计算融合嵌入与所有已见类原型的余弦相似度;分类决策:取相似度最大的原型对应的类别作为预测结果;后处理:无额外操作(如阈值过滤),直接输出类别标签。
-
本文中 “基础训练阶段” 特指PTM 的预训练阶段(如 ViT 在 ImageNet-1K 的训练,非本文实验阶段),而 “增量阶段” 是本文的核心实验阶段(含 “自适应阶段 D¹” 和 “后续增量阶段 D²~Dᴮ”)。二者区别如下表:
-
维度 基础训练阶段(PTM 预训练) 增量阶段(本文实验) 数据范围 大规模通用数据(如 ImageNet-1K,1.2M 样本) 小规模增量数据(如 CIFAR100 D¹,2500 样本) 目标 学习通用视觉特征(泛化性) 1. D¹:补充分布差距(适应性);2. D²~Dᴮ:学新类不遗忘 参数更新 全量参数微调(如 ViT 的所有注意力 + MLP 层) 1. D¹:仅更新自适应模块参数;2. D²~Dᴮ:无更新 分类器设计 线性分类器(适配预训练数据集类别) 原型分类器(动态添加新类原型) 遗忘风险 无(仅学固定数据集,无增量) 1. D¹:低(仅调少量参数);2. D²~Dᴮ:无(冻结嵌入)
-
-
Aper 的本质是解决 “PTM 泛化性” 与 “下游适应性” 的矛盾:矛盾表现:SimpleCIL(纯泛化)在分布差距大的数据集(如 ImageNet-A)性能差;全微调(纯适应)导致灾难性遗忘。解决逻辑:用 “单阶段自适应” 补适应,用 “嵌入融合” 保泛化,用 “原型更新” 免遗忘 —— 每个模块均对应矛盾的一个维度,需结合消融实验验证(如去掉融合模块,性能下降 10%+,证明融合的必要性)。
-
原型计算的核心是 “用统计均值近似类别分布”:PTM 的嵌入已将同类样本聚集、异类分离(t-SNE 可视化显示类内紧凑),平均嵌入能准确代表类中心;为何用余弦分类器?高维融合嵌入(1536 维)的尺度差异会干扰距离计算,L2 归一化后余弦相似度仅反映 “方向一致性”,更适合原型匹配。
-
Aper 的两大局限,可反向加深对算法的认知:未充分利用旧类样例:若引入样例回放,可进一步提升旧类准确率 —— 思考 “如何将 Aper 与样例基方法结合(如原型 + 样例蒸馏)”;多域增量学习挑战:当增量任务来自不同域(如从 “自然图像” 到 “医疗图像”),单阶段自适应无法应对动态域差距 —— 思考 “如何设计多阶段自适应策略(如域感知自适应)”。
-
本文算法的核心是 “以 PTM 泛化性为基础,用最小化的自适应代价填补分布差距,用原型学习简化增量更新”。深入理解需从 “矛盾→设计→实验→局限” 层层拆解,尤其关注 “单阶段自适应” 和 “嵌入融合” 的创新点 —— 这两个模块是 Aper 区别于传统 CIL 方法的关键,也是平衡泛化与适应的核心。
代码整体定位
-
在预训练模型时代,CIL 的关键在于两点 ——预训练模型的泛化性(无需下游训练即可提供有效特征)和模型的适应性(通过参数高效调优缩小预训练与下游数据的分布差距)。基于此,论文提出了两个核心方法:
- SimpleCIL:冻结预训练模型,仅通过 “原型特征” 动态更新分类器,无需下游训练即可超越传统 SOTA。
- Aper(AdaPt and mERge):聚合预训练模型与适应后模型的特征嵌入,结合泛化性与适应性,可兼容任意参数高效调优方法(如 VPT、Adapter 等)。
-
网络结构设计:支撑泛化性与适应性,
convs/文件夹包含多种网络结构- 基础预训练模型:如
original_resnet.py、resnet.py实现了 ResNet 系列,作为预训练模型的基础架构,提供泛化性特征。这些模型的参数可被冻结(对应 SimpleCIL 的 “不训练下游模型”)。 - 参数高效调优变体:
vision_transformer_vpt.py、vision_transformer_adapter.py、vision_transformer_ssf.py:分别实现了 VPT(Visual Prompt Tuning)、Adapter、SSF(Sparse Slot Fusion)等参数高效调优方法,对应论文中 Aper 框架的 “适应性” 模块(通过微调少量参数适配下游任务)。resnet_cbam.py、modified_represnet.py等:修改后的 ResNet 变体,可能用于验证不同架构下适应性调优的效果。 - 增量学习适配:
ucir_resnet.py等可能参考了现有 CIL 方法(如 UCIR)的网络设计,用于对比实验,突出 SimpleCIL 和 Aper 的优势。
- 基础预训练模型:如
-
数据处理:支持新基准验证,传统 ImageNet 基准因数据重叠不适合预训练模型时代,因此提出了 ImageNet-A、ObjectNet、OmniBenchmark、VTAB 四个新基准。
utils/data.py、utils/data_manager.py:负责数据集加载与管理,支持上述新基准(用户需修改路径配置),确保实验在论文提出的基准上进行。- 数据集的 “无重叠” 特性通过代码中的数据划分逻辑实现,验证预训练模型在分布差异较大的场景下的泛化性。
- 输入:预训练模型提取的特征(维度
in_features,如 ResNet50 输出 2048 维)。 - 处理:
SimpleLinear:直接矩阵乘法输出logits(维度out_features)。CosineLinear:归一化→点积→(可选)代理融合→sigma缩放→输出logits(维度out_features)。SplitCosineLinear:特征分两支→分别计算旧类 / 新类输出→拼接→代理融合→sigma缩放→输出logits、old_scores、new_scores。
- 输出:
logits用于最终分类,old_scores/new_scores用于增量阶段的损失计算。
-
训练逻辑:实现 SimpleCIL 与 Aper
- SimpleCIL 的实现:核心是 “冻结预训练模型,用原型特征更新分类器”。在
trainer.py或models/base.py中,可能包含以下逻辑:冻结convs/中预训练模型的参数(不参与训练)。对每个增量任务,通过预训练模型提取当前任务数据的特征,计算 “类原型”(如特征均值),作为分类器权重(替代传统训练的全连接层)。 - Aper 的实现:核心是 “聚合预训练模型与适应模型的特征”。在
trainer.py中设计特征聚合逻辑(如拼接、加权求和),将冻结的预训练模型特征与参数高效调优后的模型特征结合。分类器基于聚合后的特征构建,兼顾泛化性(来自 PTM)和适应性(来自调优模型)。
- SimpleCIL 的实现:核心是 “冻结预训练模型,用原型特征更新分类器”。在
-
辅助工具:分析特征泛化性,
models/base.py中的tsne方法:通过 UMAP 可视化特征分布,用于分析预训练模型与适应模型的特征差异,支撑论文中 “泛化性特征可迁移” 的论点(如展示冻结 PTM 的特征已能区分不同类别,或聚合后的特征分布更优)。
核心组件组成及作用
-
convs/linears.py定义了类增量学习(CIL)中关键的分类器组件,是论文提出的SimpleCIL和Aper框架的核心实现部分。这些组件基于线性层设计,但针对增量学习的特性(如类别累积、避免遗忘、利用预训练特征泛化性)进行了优化,主要包括以下 4 个部分: -
SimpleLinear:基础线性分类器,实现标准的线性分类(y = wx + b),作为基础分类器或基线对比组件。提供最简单的分类逻辑,用于验证 “预训练特征 + 简单分类器” 的有效性 -
class SimpleLinear(nn.Module): def __init__(self, in_features, out_features, bias=True): super().__init__() self.weight = nn.Parameter(torch.Tensor(out_features, in_features)) # 分类权重 self.bias = nn.Parameter(torch.Tensor(out_features)) if bias else None # 偏置 self.reset_parameters() # 初始化参数 def forward(self, input): return {'logits': F.linear(input, self.weight, self.bias)} # 输出原始logits -
CosineLinear:基于余弦相似度的分类器,通过对输入特征和分类权重进行 L2 归一化,将分类转化为余弦相似度计算(而非传统的内积)。缓解特征尺度差异对分类的影响,更适合预训练模型的泛化特征(强调预训练特征已具备强区分性,余弦相似度可直接度量类别相关性)。支持 “多代理(proxy)” 机制(nb_proxy),每个类别用多个权重向量表示,增强分类鲁棒性。是 SimpleCIL 的核心分类器,通过冻结预训练模型,仅用此类构建分类器即可实现高效增量学习(无需微调特征提取器)。 -
class CosineLinear(nn.Module): def __init__(self, in_features, out_features, nb_proxy=1, to_reduce=False, sigma=True): super().__init__() self.weight = nn.Parameter(torch.Tensor(out_features * nb_proxy, in_features)) # 分类权重 self.sigma = nn.Parameter(torch.Tensor(1)) if sigma else None # 缩放因子 self.nb_proxy = nb_proxy # 每个类的代理数量 self.to_reduce = to_reduce # 是否融合代理特征 def forward(self, input): # 特征和权重均做L2归一化,计算余弦相似度(点积) out = F.linear(F.normalize(input, p=2, dim=1), F.normalize(self.weight, p=2, dim=1)) if self.to_reduce: out = reduce_proxies(out, self.nb_proxy) # 融合多代理特征 if self.sigma is not None: out = self.sigma * out # 缩放输出 return {'logits': out} -
SplitCosineLinear:拆分式余弦分类器,将分类器拆分为两个分支(fc1和fc2),分别处理旧类别(已学类别)和新增类别。增量阶段中,fc1固定(或通过蒸馏约束)以保护旧类知识,fc2更新以学习新类,缓解 “灾难遗忘”。输出old_scores和new_scores,支持对新旧类分别计算损失(如旧类用蒸馏损失,新类用交叉熵损失)。是 Aper 框架的关键组件,实现 “泛化性(旧类)+ 适应性(新类)” 的平衡,兼容参数高效调优方法(如 Adapter、VPT)。 -
class SplitCosineLinear(nn.Module): def __init__(self, in_features, out_features1, out_features2, nb_proxy=1, sigma=True): super().__init__() self.fc1 = CosineLinear(in_features, out_features1, nb_proxy, False, False) # 旧类分类器 self.fc2 = CosineLinear(in_features, out_features2, nb_proxy, False, False) # 新类分类器 self.sigma = nn.Parameter(torch.Tensor(1)) if sigma else None # 全局缩放因子 def forward(self, x): out1 = self.fc1(x) # 旧类输出 out2 = self.fc2(x) # 新类输出 out = torch.cat((out1['logits'], out2['logits']), dim=1) # 拼接新旧类输出 out = reduce_proxies(out, self.nb_proxy) # 融合多代理 if self.sigma is not None: out = self.sigma * out return { 'old_scores': reduce_proxies(out1['logits'], self.nb_proxy), # 旧类分数(用于蒸馏) 'new_scores': reduce_proxies(out2['logits'], self.nb_proxy), # 新类分数 'logits': out # 总分类分数 } -
reduce_proxies:多代理特征融合函数,当每个类别有多个代理(nb_proxy > 1)时,通过注意力机制动态融合多个代理的输出,增强分类稳定性。在增量任务中,新类数据有限时,多代理可降低单一权重向量的偏差,提升小样本场景下的分类精度。 -
def reduce_proxies(out, nb_proxy): if nb_proxy == 1: return out bs, total_dim = out.shape nb_classes = total_dim // nb_proxy # 总类别数 = 总维度 / 每个类的代理数 simi_per_class = out.view(bs, nb_classes, nb_proxy) # 按类别拆分代理 attentions = F.softmax(simi_per_class, dim=-1) # 代理注意力权重 return (attentions * simi_per_class).sum(-1) # 加权融合代理特征 -
特征与权重归一化:
CosineLinear和SplitCosineLinear中,输入特征和分类权重均需通过F.normalize做 L2 归一化,否则余弦相似度计算无效。训练时需确保归一化操作稳定(如避免特征维度为 0 导致的数值问题)。 -
参数调优:
nb_proxy:每个类的代理数量(建议 1-5),增多可提升鲁棒性但增加计算量,需根据任务数据量调整。sigma:缩放因子,控制输出 logits 的尺度(影响 softmax 概率分布),通常初始化为 1,通过训练优化。权重初始化:CosineLinear用均匀分布初始化(uniform_(-stdv, stdv)),SimpleLinear用 Kaiming 初始化,需保证初始权重分布合理以加速收敛。 -
损失函数设计:基础阶段:可用交叉熵损失(
F.cross_entropy)直接优化logits。增量阶段:SplitCosineLinear需结合蒸馏损失(如约束old_scores与历史模型输出一致)和交叉熵损失(优化new_scores),避免旧类性能下降。 -
阶段 核心操作 分类器选择 数据流转逻辑 基础阶段(第 0 任务) 初始化所有类别,训练分类器(或直接用类原型初始化)。 CosineLinear或SplitCosineLinear(此时out_features1=0)预训练特征 → 分类器 → 输出 logits→ 交叉熵损失优化。增量阶段(第≥1 任务) 冻结旧类分类器,仅更新新类分类器,通过蒸馏保护旧类知识。 SplitCosineLinear(out_features1= 旧类数,out_features2= 新增类数)预训练特征 → 拆分至 fc1(旧类)和fc2(新类) → 输出old_scores/new_scores→ 蒸馏损失 + 交叉熵损失联合优化。- 两者均依赖预训练模型的特征提取(体现泛化性),分类器均基于余弦相似度设计(适配预训练特征的分布特性)。增量阶段通过拆分分类器和蒸馏损失实现 “不遗忘旧类”,而基础阶段仅需学习初始类别。
- 需保存的参数:分类器权重(
weight)、sigma、nb_proxy等(通过model.state_dict())。增量阶段加载历史模型的fc1权重(旧类),初始化fc2权重(新类),确保旧类知识继承。
-
convs/linears.py通过余弦相似度分类器和拆分式设计,实现了论文中 “泛化性与适应性” 的核心需求:CosineLinear支撑 SimpleCIL 的极简思路,直接利用预训练特征的泛化性;SplitCosineLinear支撑 Aper 框架,通过拆分新旧类分类器和蒸馏损失,平衡适应性与抗遗忘能力;多代理机制(reduce_proxies)增强了小样本增量场景的鲁棒性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)