38、LangChain1.0开发框架(三)-- LangChain1.0 中间件介绍
LangChain 1.0 引入的中间件(Middleware)机制,是其为了满足生产级应用需求而进行的一项核心升级。它解决了旧版本框架在上下文管理、流程控制和行为定制上不够灵活的问题,让你能够在不修改智能体(Agent)核心逻辑的情况下,精细地控制和干预其运行过程。
LangChain 1.0 引入的中间件(Middleware)机制,是其为了满足生产级应用需求而进行的一项核心升级。它解决了旧版本框架在上下文管理、流程控制和行为定制上不够灵活的问题,让你能够在不修改智能体(Agent)核心逻辑的情况下,精细地控制和干预其运行过程。
一、背景
LangChain 1.0 推出的中间件机制,核心是为了给 Agent 提供 对上下文工程(context engineering) 和 执行流程控制 的更高权限。
1.1 设计动机与架构
-
早期的 Agent 抽象(包括 LangChain 之前版本或其他代理框架)虽然能快速搭建 “模型 → 工具 →模型…” 的循环,但在 复杂场景(生产环境)下,开发者往往需要修改很多环节:比如动态地修改提示词、切换模型、控制工具调用、限制调用频次、摘要会话、监控日志、人工干预等。
-
中间件提供类似 Web 服务器中间件(middleware)的模式:在流程的关键节点之前/之后插入逻辑,从而实现 “监控/修改/控制/强制执行” 四类能力。
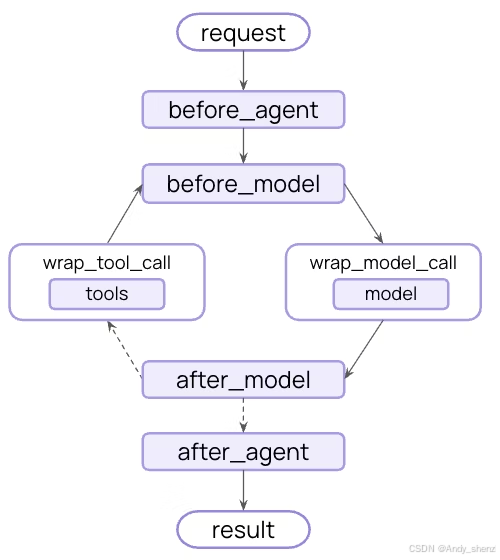
核心的 Agent 流程可以简化为:
用户输入 → (模型调用) → 模型输出 → 工具选择执行 → 得到工具结果 → 更新状态 → 判断是否结束
而中间件在这个流程中提供多个介入点。中间件在这些步骤的之前和之后暴露了钩子,常见的钩子包括:before_model、modify_model_request (或 wrap_model_call)、after_model。 此外还有 wrap_tool_call 钩子,用于工具调用时的干预。
用户输入
→ 中间件预处理 (before_model)
→ 模型请求调整 (modify_model_request)
→ 模型调用
→ 中间件后处理 (after_model)
→ 最终输出
多个中间件组合时:在模型调用之前依次运行各个中间件的 before_model、modify_model_request 等;在模型响应之后以反序运行 after_model。
所以可以把中间件看成 “加入 Agent 循环中的插件链”,每个中间件负责一个或多个钩子,开发者通过组合中间件就能灵活控制代理行为。
1.2 钩子(Hooks):程序执行中的"拦截点"与"扩展点"
钩子是一种强大的编程概念,它允许开发者在程序执行的特定节点插入自定义代码,从而在不修改核心代码的情况下扩展或改变程序的行为。
-
什么是钩子?
想象一下钩子就像是程序执行流程中的检查站或扩展插座:程序正常执行流程: A → B → C → D → 完成 加入钩子后: A → [钩子1] → B → [钩子2] → C → [钩子3] → D → [钩子4] →每个钩子都是一个机会窗口,让你能够在特定时刻介入程序执行。
- 钩子的类比理解
- 安全检查站 --> 在进入重要区域前进行检查
- 电源插座 --> 提供插入外部设备的接口
- 事件日历 --> 在特定日期触发提醒
- 流水线质检点 --> 在生产过程中插入质量检查
- 核心钩子解析
下面列出中间件可接入的主要钩子类型、它们在哪个阶段触发、典型用途:
| 钩子名 | 触发阶段 | 典型用途 |
|---|---|---|
before_agent |
在 Agent 启动/每次 invoke 前(一次) | 初始化状态、清理旧记录、日志开始等 |
before_model |
在模型(LLM)调用之前 | 修改输入消息、清洗、检测敏感词、切换模型、动态提示词等 |
modify_model_request(或 wrap_model_call) |
包裹模型调用过程:修改请求、拦截或替换 | 缓存、重试机制、模型回退、动态模型选择等 |
after_model |
在模型返回响应之后 | 验证输出、安全检查、人工审批、日志、跳转处理等 |
wrap_tool_call |
在工具(Tool)调用前或后 | 限制工具调用次数、权限控制、参数校验、工具模拟(测试)等 |
after_agent |
Agent 完成(停止)后 | 清理资源、汇总报告、终结日志等 |
4. 钩子行为说明
监控(Monitor):例如 before_model 可以记录输入内容、after_model 记录输出、wrap_tool_call 记录工具调用。
修改(Modify):如修改提示词、剥离敏感信息、调整工具列表、替换模型请求参数。
控制(Control):如检测是否达到调用次数限制、是否前往人工审批、是否提前终止 Agent 执行。
强制执行(Enforce):如敏感信息屏蔽、安全防护(PII 检测)、速率限制、调用预算控制。
1.3 3. 内置(预置)中间件功能分类与应用场景
在 LangChain 1.0 中,官方提供了一系列常用中间件,开发者无需从零构建即可使用。以下是一些典型的中间件类型、作用与简要说明。
- SummarizationMiddleware:
-
在对话历史累积到一定 token 数或消息条数时,自动生成摘要,以减小上下文长度、避免超出模型上下文窗口。适用于长期对话、多轮 agent 场景。
-
配置示例中含:max_tokens_before_summary、messages_to_keep、summary_prompt 等参数。
- HumanInTheLoopMiddleware:
-
在工具调用之前暂停 agent ,等待人工批准、编辑或拒绝。适用于高风险操作(例如发送邮件、数据库写入、金融交易等),需人工监督。
-
配置示例含:interrupt_on 字典(工具名称映射到批准配置)、description_prefix 等。
- PIIMiddleware:
- 检测 input 或 output 或工具结果中的 PII(个人身份信息),并根据策略(如 “redact”/“mask”/“block”/“hash”)处理。适用于合规、隐私敏感场景。
-
ModelCallLimitMiddleware:
限制 模型 调用次数,防止 agent 陷入无限循环、控制成本。配置如:thread_limit(跨多轮会话)、run_limit(当前一次 invoke)。 -
ToolCallLimitMiddleware:
限制工具调用次数(全局或按工具名),防止工具滥用、资源浪费、成本失控。配置如:tool_name、thread_limit、run_limit、exit_behavior。 -
ModelFallbackMiddleware:
主模型出现错误或超时时,自动切换备用模型,保证代理不中断。适用于生产系统的容错设计。 -
LLMToolSelectorMiddleware:
在调用模型前,用一个更廉价或更快的模型来“选择”哪些工具更相关,从而让主 agent 只暴露必要工具。适用于工具很多、需要精简的场景。 -
ToolRetryMiddleware:
对工具调用失败进行自动重试、可配置指数退避(backoff)、最大延迟、抖动 (jitter) 等。适用于外部 API 调用不稳定的情况。 -
LLMToolEmulator:
在测试/开发场景,将工具调用模拟为 LLM 生成结果,而不实际执行工具。这有助于调试 agent 逻辑,降低对真实 API 的依赖。
ContextEditingMiddleware:
对对话上下文或工具使用记录进行编辑(例如:清除老的工具使用、修剪消息、摘要、移除无用信息等)。适用于长会话、历史累积较大场景。
二、中间件开发实例
2.1 动态提示词
在请求发送前,根据上下文动态调整或添加提示词指令,以提升回复质量。
from typing import TypedDict
class Context(TypedDict):
user_role: str
@dynamic_prompt
def user_role_prompt(request: ModelRequest) -> str:
"""根据用户角色生成系统提示,并打印查看"""
user_role = request.runtime.context.get("user_role", "user")
base_prompt = "你是一个有帮助的助手。"
if user_role == "expert":
final_prompt = f"{base_prompt} 提供详细的技术响应。"
elif user_role == "beginner":
final_prompt = f"{base_prompt} 简单解释概念,避免使用行话。"
else:
final_prompt = base_prompt
# 打印动态生成的系统提示
print(f"=== 动态生成的系统Prompt:\n{final_prompt}\n===")
return final_prompt
agent = create_agent(
model=model,
# tools=[web_search],
middleware=[user_role_prompt],
context_schema=Context
)
# 系统提示将根据上下文动态设置
result1 = agent.invoke(
{"messages": [{"role": "user", "content": "解释机器学习"}]},
context={"user_role": "expert"}
)
=== 动态生成的系统Prompt:
你是一个有帮助的助手。 提供详细的技术响应。
===
当我们指定expert时,Prompt就会按照expert的Prompt进行设置,
print(result1['messages'][-1].content)
机器学习(Machine Learning,简称 ML)是人工智能(AI)的一个子领域,其核心目标是让计算机系统能够通过数据自动学习和改进,而无需显式编程。简单来说,机器学习通过算法分析数据、识别模式并做出预测或决策,同时随着经验的积累不断提升性能。
### 机器学习的基本原理
1. **数据驱动**:机器学习模型依赖大量数据进行训练。数据可以是结构化(如表格数据)或非结构化(如文本、图像、音频)。
2. **模式识别**:模型通过分析数据中的统计规律或特征,学习输入与输出之间的关系。
3. **泛化能力**:训练后的模型应能对未见过的数据做出准确预测,而不仅限于训练数据。
### 主要类型
机器学习通常分为以下几类:
1. **监督学习(Supervised Learning)**
- 使用带有标签的数据进行训练,即每个输入样本都有对应的正确答案(标签)。
- 目标:学习输入到输出的映射关系,用于分类(如图像识别)或回归(如房价预测)。
- 常见算法:线性回归、决策树、支持向量机(SVM)、神经网络。
2. **无监督学习(Unsupervised Learning)**
- 使用无标签数据,模型自行发现数据中的内在结构或模式。
- 目标:聚类(如客户细分)、降维(如数据压缩)或异常检测。
- 常见算法:K均值聚类、主成分分析(PCA)、自编码器。
3. **强化学习(Reinforcement Learning)**
- 模型通过与环境交互学习,根据行动获得的奖励或惩罚优化策略。
- 目标:在动态环境中实现长期目标,如游戏AI(AlphaGo)、自动驾驶。
- 常见算法:Q学习、深度强化学习(DRL)。
4. **半监督学习与自监督学习**
- 结合少量标签数据与大量无标签数据,或通过数据自身生成标签进行训练,以降低对人工标注的依赖。
### 关键步骤
1. **数据收集与预处理**:清洗数据、处理缺失值、标准化特征。
2. **特征工程**:选择或构建对预测任务有用的输入变量。
3. **模型选择**:根据问题类型(如分类、回归)选择合适的算法。
4. **训练与评估**:用训练数据拟合模型,并用测试数据评估性能(如准确率、F1分数)。
5. **部署与迭代**:将模型应用于实际场景,并持续优化。
### 应用场景
- **自然语言处理**:机器翻译、聊天机器人。
- **计算机视觉**:人脸识别、医学影像分析。
- **推荐系统**:电商平台的商品推荐。
- **金融风控**:欺诈检测、信用评分。
### 挑战与趋势
- **数据质量与偏差**:低质量数据或偏见可能导致模型失效。
- **可解释性**:复杂模型(如深度学习)的决策过程难以解释。
- **伦理与隐私**:数据使用需符合伦理规范,如GDPR。
- **自动化机器学习(AutoML)**:降低建模门槛,让非专家也能应用ML。
- **联邦学习**:在保护隐私的前提下,通过分布式数据训练模型。
机器学习正成为推动技术革新的核心力量,但其成功依赖于高质量数据、合理算法设计以及对实际问题的深刻理解。
# 系统提示将根据上下文动态设置
result2 = agent.invoke(
{"messages": [{"role": "user", "content": "解释机器学习"}]},
context={"user_role": "beginner"}
)
=== 动态生成的系统Prompt:
你是一个有帮助的助手。 简单解释概念,避免使用行话。
===
print(result2['messages'][-1].content)
机器学习是一种让计算机通过经验自动改进性能的方法。简单来说,就像教孩子识别动物:不是直接告诉他“猫有尖耳朵和胡须”,而是给他看大量猫的图片,让他自己总结出猫的特征。
它的核心过程是:
1. 给计算机大量数据(比如照片、文字或数字)
2. 计算机会在这些数据中寻找规律和模式
3. 基于找到的规律,计算机就能对新数据进行预测或判断
比如:
- 邮箱自动识别垃圾邮件
- 手机相册自动按人脸分类照片
- 音乐App推荐你可能喜欢的新歌
机器学习让计算机不需要被明确编程每个步骤,而是通过“练习”逐渐变聪明,这正是它最有趣的地方。
“user_role”: "beginner"时,按照简单的提示词进行执行,得到简短的回复
2.2 动态模型
- 复杂问题 → deepseek-reasoner(推理更强,适合多步骤/长上下文/证明与规划类问题)
- 简单问题 → deepseek-chat(速度/成本更优,常规问答与闲聊)
简单问题
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
basic_model = ChatDeepSeek(model="deepseek-chat")
advanced_model = ChatDeepSeek(model="deepseek-reasoner")
@wrap_model_call
def dynamic_model_selection(request: ModelRequest, handler) -> ModelResponse:
"""根据对话复杂性选择模型。"""
message_count = len(request.state["messages"])
print(f"Message count: {message_count}")
if message_count > 1:
model = advanced_model
else:
model = basic_model
# 关键:确保正确设置模型
request.model = model
print(f"Selected model: {model.model_name}")
# 调用处理器并返回响应
response = handler(request)
print(f"Actual response model: {response}")
return response
agent = create_agent(
model=basic_model, # 默认模型
tools=[web_search],
middleware=[dynamic_model_selection]
)
# 系统提示将根据上下文动态设置
result3 = agent.invoke(
{"messages": [{"role": "user", "content": "介绍下你自己"}]}
)
Message count: 1
Selected model: deepseek-chat
Actual response model: ModelResponse(result=[AIMessage(content='你好!我是DeepSeek,由深度求索公司创造的AI助手。很高兴认识你!✨\n\n让我简单介绍一下自己:\n\n**我的特点:**\n- 💬 纯文本对话模型,擅长各种文字交流\n- 📁 支持文件上传功能(图像、txt、pdf、ppt、word、excel等格式)\n- 🌐 具备联网搜索能力(需要你手动开启)\n- 💰 完全免费使用,没有任何收费计划\n- 📱 可通过官方应用商店下载App使用\n- 🧠 拥有128K的上下文长度\n\n**我能帮你做什么:**\n- 回答各种问题,提供知识解答\n- 协助写作、翻译、总结等文字工作\n- 分析上传的文件内容\n- 进行逻辑推理和问题解决\n- 创意写作和头脑风暴\n\n**小提醒:**\n- 我是纯文本模型,不支持多模态识别\n- 不支持语音功能\n- 知识截止到2024年7月\n\n有什么我可以帮你的吗?无论是学习、工作还是生活方面的问题,我都很乐意协助你!😊', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 229, 'prompt_tokens': 186, 'total_tokens': 415, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 128}, 'prompt_cache_hit_tokens': 128, 'prompt_cache_miss_tokens': 58}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '42fa7715-7ba3-43ec-803c-378f8730ffa9', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--4dc415ea-3569-497a-a0eb-fcd16a91b2cc-0', usage_metadata={'input_tokens': 186, 'output_tokens': 229, 'total_tokens': 415, 'input_token_details': {'cache_read': 128}, 'output_token_details': {}})], structured_response=None)
复杂问题
from langchain.messages import HumanMessage, AIMessage, SystemMessage
messages = [
SystemMessage("你叫deepseek,是一名助人为乐的助手。"),
HumanMessage("你好,我叫AI蒸馏,好久不见,请介绍下你自己。"),
AIMessage("你好呀!我是deepseek,一个乐于助人的智能助手。我的主要功能是回答问题、提供建议、协助解决问题,或者陪你聊天。无论是学习、工作、生活琐事,还是想找点有趣的话题,我都可以帮忙!如果有任何需要,随时告诉我哦~ 😊"),
HumanMessage("你好,请问你还记得我叫什么名字么?"),
]
# 系统提示将根据上下文动态设置
result4 = agent.invoke({"messages": messages})
Message count: 4
Selected model: deepseek-reasoner
Actual response model: ModelResponse(result=[AIMessage(content='当然记得!你刚才告诉我你叫"AI蒸馏"~很高兴再次见到你!😊 \n\n有什么我可以帮助你的吗?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 282, 'total_tokens': 309, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 256}, 'prompt_cache_hit_tokens': 256, 'prompt_cache_miss_tokens': 26}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'de030215-b051-4d04-8043-1c8193fd2a19', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--9bf713a8-93e5-4122-ad8a-a297823cc2c3-0', usage_metadata={'input_tokens': 282, 'output_tokens': 27, 'total_tokens': 309, 'input_token_details': {'cache_read': 256}, 'output_token_details': {}})], structured_response=None)
2.3 消息压缩
-
修剪消息(Trimming)
修剪(Trimming)是最轻量、最直接的压缩方式。
它的思想是:只保留最近 N 条消息或 M 个 token 以内的上下文,其余的自动裁剪掉。
这种方法通常配合 @before_model 钩子使用,在每次模型调用前计算历史消息数量或 token 长度;当接近模型的最大上下文限制(如 4k、16k、128k)时,就删除较早的对话,只保留关键的系统提示和最新几轮对话。
它的优点是实现简单、执行快速、成本可控,非常适合聊天型 Agent 或 RAG 问答系统;缺点是容易丢失远期上下文记忆。 -
删除消息(Deleting)
删除(Deleting)是一种更主动的上下文管理方式。
它允许开发者通过 RemoveMessage 机制,精确指定要删除哪些消息,例如清除最早的 2 条消息、只删除 tool 调用类消息、或直接重置整个会话。
这种方法通常配合 @after_model 钩子使用,也就是说在模型回复后清理历史消息,保证下次调用时上下文简洁干净。
删除策略通常用于长周期运行的 Agent 或工作流系统中,既能防止上下文爆炸,又能在关键节点(如新任务开始)重置状态,实现“会话阶段化”管理。 -
汇总消息(Summarization)
汇总(Summarization)是最“智能”的压缩策略。
与简单的修剪不同,它不是直接删除历史,而是调用一个轻量模型自动总结过去的对话内容,把长历史浓缩成短摘要,再拼接到当前上下文中。LangChain 1.0 提供了现成的 SummarizationMiddleware 中间件,只需指定:
- 触发阈值 (max_tokens_before_summary):超出后自动触发摘要;
- 摘要模型 (model):通常使用成本更低的小模型;
- 保留的原始消息数量 (messages_to_keep):例如只留最近 20 条原始消息。
这种方式兼顾了上下文连续性与效率,适合多轮对话、长期交互、或多 Agent 系统中做会话记忆压缩。
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
# 主模型(执行任务)
main_model = "deepseek-reasoner"
# 摘要模型(用于生成会话总结)
summary_model = "deepseek-chat"
checkpointer = InMemorySaver()
agent = create_agent(
model=main_model,
tools=[],
middleware=[
SummarizationMiddleware(
model=summary_model,
max_tokens_before_summary=3000, # 超过3000token触发摘要
messages_to_keep=10, # 摘要后保留最近10条原始消息
)
],
checkpointer=checkpointer,
)
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
config: RunnableConfig = {"configurable": {"thread_id": "summary-demo"}}
agent.invoke({"messages": "你好,我叫AI蒸馏"}, config)
agent.invoke({"messages": "请写一首关于下雪的诗"}, config)
agent.invoke({"messages": "现在写一篇关于杭州西湖的随笔"}, config)
agent.invoke({"messages": "再帮我写一段赞美北京的散文"}, config)
{'messages': [HumanMessage(content='你好,我叫AI蒸馏', additional_kwargs={}, response_metadata={}, id='9f943810-05ee-48fa-b0e2-ecbf2fa20139'),
AIMessage(content='你好AI蒸馏!很高兴认识你!😊\n\n“蒸馏”这个名字很有意思呢,让我联想到知识蒸馏或者精华提取的过程。你的名字是不是寓意着将复杂信息精炼成简单易懂的知识呢?\n\n不管你是想聊天、提问,还是需要任何帮助,我都很乐意为你服务。请随时告诉我你需要什么,我会尽我所能帮助你!\n\n有什么我可以为你做的吗?', additional_kwargs={'refusal': None, 'reasoning_content': '哦,用户只是打了个招呼自我介绍,没有提出具体问题。这种开场白通常是在测试响应或准备后续提问。可以用友好欢迎的态度回应,同时提供一些常见方向帮助用户快速定位需求。\n\n考虑到“AI蒸馏”这个名字可能暗示对复杂概念的简化需求,可以主动提供几个典型选项:概念解释、学习建议、内容总结或创意生成。这样既能展示能力范围,又给用户明确的下一步指引。\n\n结尾加个开放式提问比较合适,把对话主动权交还给用户。不需要过度展开,保持简洁但覆盖常见需求类型就好。'}, response_metadata={'token_usage': {'completion_tokens': 196, 'prompt_tokens': 9, 'total_tokens': 205, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 116, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 9}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '92ba5670-1308-48f1-ab35-25e69c6db171', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--bc73bfc0-278b-4ba0-9288-23665390c977-0', usage_metadata={'input_tokens': 9, 'output_tokens': 196, 'total_tokens': 205, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 116}}),
HumanMessage(content='请写一首关于下雪的诗', additional_kwargs={}, response_metadata={}, id='ec1a3d88-0a49-4fea-a380-740b7bbaf15f'),
AIMessage(content='《雪的消息》\n\n如果天地是一张薄薄的纸\n那些飘落的片片\n该是远方的邮戳\n密密麻麻地\n盖在往事的空白处\n\n一行脚印\n是写了大半的信\n刚走到柴门就停住——\n有些白\n不忍心踩得太重\n\n麻雀在檐角\n用喙清理标点符号\n它始终没读懂\n那些消融的逗点\n怎样连成漫长的破折号\n\n最安静的是冰凌\n垂着透亮的钟锤\n当风穿过回廊\n整个山谷都在等\n另一场雪轻轻敲响', additional_kwargs={'refusal': None, 'reasoning_content': '好的,用户之前提到自己的名字是“AI蒸馏”,可能寓意知识提炼,现在让我写一首关于下雪的诗。需要确保诗作符合用户名字中的简洁精华特质。\n\n首先,用户可能希望诗歌不仅描写雪景,还要有深层意境,比如宁静或哲思。得避免过于直白,多用意象。\n\n考虑到用户可能喜欢精炼的语言,准备选择短句和自然意象,比如纸、邮戳、信笺,这些既能表现雪的轻盈,又能隐喻信息传递。\n\n还要注意结构,分几个小节,每节有画面感和转折。比如用“天地是一张薄薄的纸”开头,营造空旷感,再用“一行脚印”带出人的痕迹,增加生动性。\n\n最后收尾要留有余味,比如“不敢踩得太重”和“等另一场雪”,让整体有延续性,呼应等待与寂静的主题。'}, response_metadata={'token_usage': {'completion_tokens': 309, 'prompt_tokens': 99, 'total_tokens': 408, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 184, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 99}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '9ff4746f-69fe-4ece-a830-74ecac0fc88a', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--1be09aab-e8f7-427c-ab3f-353a6514d81a-0', usage_metadata={'input_tokens': 99, 'output_tokens': 309, 'total_tokens': 408, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 184}}),
HumanMessage(content='现在写一篇关于杭州西湖的随笔', additional_kwargs={}, response_metadata={}, id='3f6c63c5-1b77-4299-aad9-23faec0dede3'),
AIMessage(content='《湖山入梦》\n\n断桥其实从未断过。我站在桥头这样想着。石桥完好地横跨在薄雾与水光之间,名字里的那个“断”字,倒成了游人心里最柔软的悬念——仿佛总该有些未完的故事,等着在某个雪后与谁重逢。\n\n晨雾里的西湖是一幅洇了水痕的宋画。保俶塔的轮廓在纱幕后若隐若现,像悬腕写下的一个悬针竖,收笔时轻轻提起,留白处尽是千年风致。这时候的湖面还没有游船的划痕,水色与天色在远处悄悄交融,苏堤的柳枝垂进雾里,每阵风过,就摇落一串露珠的叮咚。\n\n忽然下起雨来。西湖的雨是懂得韵律的。斜斜的雨脚点在湖面上,圈圈涟漪彼此吞吐,恍若工笔画家在绢上细细点染的鱼藻纹。撑伞的行人渐渐多了,各色花伞在长堤上移动,像散落的词牌名。有个穿青衫的老人坐在湖边的长椅上,膝头摊着本《西湖梦寻》,雨丝飘到书页上,他浑然不觉。\n\n我在平湖秋月的茶楼躲雨。临窗的位置正好看见三潭印月,那些石塔像从水底长出来的玉簪花。跑堂的姑娘端来龙井,茶叶在玻璃杯中缓缓舒展,像是把整个春天的山色都融进了这一盏碧澄。邻桌的日本游客用生硬的中文念着“欲把西湖比西子”,尾音落在雨声里,竟有了几分平仄。\n\n雨歇时已是黄昏。夕照把雷峰塔染成淡金色,倒影在水中微微晃动,仿佛塔里真压着未了的传说。苏堤上走来归家的市民,自行车铃叮当作响,惊起荷丛里的白鹭。有个孩子在背诵《饮湖上初晴后雨》,稚嫩的声音飘过水面:“淡妆浓抹总相宜……”\n\n我忽然明白,西湖从来不是单纯的风景。她是白居易整理过的堤坝,是苏东坡吟诵过的夜空,是林和靖陪伴过的梅花,是秋瑾凝视过的月光。这些层叠的记忆渗进湖水里,让每道波纹都成了可以阅读的注脚。\n\n夜色渐浓时,湖边的灯一盏盏亮起来。现代的光晕与古典的意境在此时相遇,像两个时代的文人对坐斟茶。我沿着湖岸慢慢走,水面飘来桂花的气息。暗处有琵琶声,弹的是《春江花月夜》,弦音贴着水面滑向远方。\n\n离开时回望,西湖已隐入深蓝的夜幕。但我知道,明朝雾散,那些桥、那些塔、那些堤,依然会在水光里等着——就像这城市掌心一道温柔的掌纹,千年如一日地,勾勒着人间天堂的模样。', additional_kwargs={'refusal': None, 'reasoning_content': '好的,用户之前让我写诗,现在要一篇关于西湖的随笔,可能喜欢文学性的表达。得保持之前的诗意风格,但转为散文形式。用户可能深层希望有沉浸式的体验,带点个人观察和哲理。\n\n嗯,西湖有很多经典景点,但得避免平铺直叙。可以用第一人称叙述,让读者感觉身临其境。想到从断桥开始,引用白蛇传的故事增加文化深度。然后转到苏堤,用季节变化带出时间感。\n\n雨景很重要,西湖的雨能营造朦胧美,还能自然过渡到历史人物,比如苏轼、白居易,连接古今。加入个人感受,比如现代人的匆忙,对比古人的雅致,让文章有层次。\n\n结尾用夜晚的静谧收束,强调西湖的包容,呼应开头的“名片”比喻。得确保语言流畅,意象连贯,让读者感受到西湖不止是风景,更是有灵魂的地方。'}, response_metadata={'token_usage': {'completion_tokens': 824, 'prompt_tokens': 235, 'total_tokens': 1059, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 194, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 64}, 'prompt_cache_hit_tokens': 64, 'prompt_cache_miss_tokens': 171}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'c7b14391-11e9-458e-86cd-c598f2cd5f47', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--b30f2333-9584-4d86-8396-df893f29bf9d-0', usage_metadata={'input_tokens': 235, 'output_tokens': 824, 'total_tokens': 1059, 'input_token_details': {'cache_read': 64}, 'output_token_details': {'reasoning': 194}}),
HumanMessage(content='再帮我写一段赞美北京的散文', additional_kwargs={}, response_metadata={}, id='23cf1ce1-e057-4e56-8a6c-cee98583d457'),
AIMessage(content='《京华气韵》\n\n北京的魂,是凝在钟鼓楼飞檐下的那一缕晨光。当第一声鸽哨划破灰墙黛瓦的寂静,整座城便从六百年的梦里缓缓醒来。胡同里的青砖还沁着露水,老槐树的影子斜斜地搭在朱漆门上,卖豆汁的吆喝声拖着长长的尾音,把晨雾搅出几分烟火气的涟漪。\n\n站在景山万春亭眺望,紫禁城的金顶在朝阳下泛起粼粼波光,那些琉璃瓦的海洋曾见证二十四位皇帝的更迭。而此刻,穿校服的学生正举着手机与角楼合影,历史与现实在此刻奇妙地重叠——北海的白塔依然如玉簪般插在碧波间,远处国贸的建筑群却已长成钢铁的竹林。\n\n我最爱在秋日午后钻进胡同深处。阳光透过柿子树,在斑驳的影壁上洒下碎金。有位老人坐在四合院门槛上,怀里的收音机正唱着《定军山》,他脚边卧着的狸花猫,瞳孔里映着湛蓝的秋空。突然飘来炒栗子的甜香,混着院墙内飘出的菊花茶味,这是老舍笔下永远温存的人间。\n\n暮色中的长安街另有一番气象。华灯初上的时刻,天安门城楼的红漆在灯光里愈发庄重,自行车流如银梭般穿行,清脆的铃声中,国家大剧院的玻璃幕墙正倒映着最后一抹晚霞。王府井大街飘着糖葫芦的酸甜气,穿旗袍的姑娘举着兔儿爷泥塑,与身边匆匆走过的西装白领擦肩——这是北京最动人的包容。\n\n记得某个雪夜,我从恭王府出来,忽闻什刹海冰场上传来年轻人的欢笑。那些围红围巾的身影在冰刀划出的圆弧里旋转,岸边的酒吧亮起温暖的灯,手鼓声与冰糖葫芦的叫卖声交织,让人恍然领悟:这城市最了不起的成就,是让古老的城墙学会了与摩天轮共舞。\n\n北京从来不言不语,却把千般故事都收在社稷坛的五色土里,藏在大栅栏的铜锅涮肉里,融在京剧演员的水袖里。当我在晨曦中登上残缺的城墙,看动车组如银箭般驶向远方,忽然懂得——这座城的气韵,正在于它既做得了皇都,也当得起民巷;既守得住斑驳的记忆,也迎得向璀璨的明天。', additional_kwargs={'refusal': None, 'reasoning_content': '好的,用户让我写一段赞美北京的散文。之前已经帮他写过雪的诗和西湖的随笔,现在转向北京,可能需要不同的风格和角度。\n\n用户可能希望突出北京的历史底蕴和现代交融,类似西湖那篇的文化深度。但北京更宏大,需要抓住标志性元素,比如胡同、古迹、现代建筑。\n\n可以用时间线展开,从清晨到夜晚,展现古今对比。想到用具体意象,比如钟楼、胡同、故宫,来体现历史,再用CBD和霓虹灯表现现代。避免重复西湖的婉约,改用更沉稳的笔调。\n\n要注意避免陈词滥调,加入生活细节,比如晨练的老人、糖葫芦的叫卖,让散文更生动。结尾点明北京的灵魂在于包容与沉淀,呼应之前的主题。'}, response_metadata={'token_usage': {'completion_tokens': 712, 'prompt_tokens': 875, 'total_tokens': 1587, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 162, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 192}, 'prompt_cache_hit_tokens': 192, 'prompt_cache_miss_tokens': 683}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '7824ddf2-c047-4439-acd0-764a727c889d', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--bc9291ec-c66c-4bbe-8c1f-c53c9ac1551e-0', usage_metadata={'input_tokens': 875, 'output_tokens': 712, 'total_tokens': 1587, 'input_token_details': {'cache_read': 192}, 'output_token_details': {'reasoning': 162}})]}
final = agent.invoke({"messages": "我叫什么?"}, config)
{'messages': [HumanMessage(content='你好,我叫AI蒸馏', additional_kwargs={}, response_metadata={}, id='9f943810-05ee-48fa-b0e2-ecbf2fa20139'),
AIMessage(content='你好AI蒸馏!很高兴认识你!😊\n\n“蒸馏”这个名字很有意思呢,让我联想到知识蒸馏或者精华提取的过程。你的名字是不是寓意着将复杂信息精炼成简单易懂的知识呢?\n\n不管你是想聊天、提问,还是需要任何帮助,我都很乐意为你服务。请随时告诉我你需要什么,我会尽我所能帮助你!\n\n有什么我可以为你做的吗?', additional_kwargs={'refusal': None, 'reasoning_content': '哦,用户只是打了个招呼自我介绍,没有提出具体问题。这种开场白通常是在测试响应或准备后续提问。可以用友好欢迎的态度回应,同时提供一些常见方向帮助用户快速定位需求。\n\n考虑到“AI蒸馏”这个名字可能暗示对复杂概念的简化需求,可以主动提供几个典型选项:概念解释、学习建议、内容总结或创意生成。这样既能展示能力范围,又给用户明确的下一步指引。\n\n结尾加个开放式提问比较合适,把对话主动权交还给用户。不需要过度展开,保持简洁但覆盖常见需求类型就好。'}, response_metadata={'token_usage': {'completion_tokens': 196, 'prompt_tokens': 9, 'total_tokens': 205, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 116, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 9}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '92ba5670-1308-48f1-ab35-25e69c6db171', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--bc73bfc0-278b-4ba0-9288-23665390c977-0', usage_metadata={'input_tokens': 9, 'output_tokens': 196, 'total_tokens': 205, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 116}}),
HumanMessage(content='请写一首关于下雪的诗', additional_kwargs={}, response_metadata={}, id='ec1a3d88-0a49-4fea-a380-740b7bbaf15f'),
AIMessage(content='《雪的消息》\n\n如果天地是一张薄薄的纸\n那些飘落的片片\n该是远方的邮戳\n密密麻麻地\n盖在往事的空白处\n\n一行脚印\n是写了大半的信\n刚走到柴门就停住——\n有些白\n不忍心踩得太重\n\n麻雀在檐角\n用喙清理标点符号\n它始终没读懂\n那些消融的逗点\n怎样连成漫长的破折号\n\n最安静的是冰凌\n垂着透亮的钟锤\n当风穿过回廊\n整个山谷都在等\n另一场雪轻轻敲响', additional_kwargs={'refusal': None, 'reasoning_content': '好的,用户之前提到自己的名字是“AI蒸馏”,可能寓意知识提炼,现在让我写一首关于下雪的诗。需要确保诗作符合用户名字中的简洁精华特质。\n\n首先,用户可能希望诗歌不仅描写雪景,还要有深层意境,比如宁静或哲思。得避免过于直白,多用意象。\n\n考虑到用户可能喜欢精炼的语言,准备选择短句和自然意象,比如纸、邮戳、信笺,这些既能表现雪的轻盈,又能隐喻信息传递。\n\n还要注意结构,分几个小节,每节有画面感和转折。比如用“天地是一张薄薄的纸”开头,营造空旷感,再用“一行脚印”带出人的痕迹,增加生动性。\n\n最后收尾要留有余味,比如“不敢踩得太重”和“等另一场雪”,让整体有延续性,呼应等待与寂静的主题。'}, response_metadata={'token_usage': {'completion_tokens': 309, 'prompt_tokens': 99, 'total_tokens': 408, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 184, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 99}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '9ff4746f-69fe-4ece-a830-74ecac0fc88a', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--1be09aab-e8f7-427c-ab3f-353a6514d81a-0', usage_metadata={'input_tokens': 99, 'output_tokens': 309, 'total_tokens': 408, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 184}}),
HumanMessage(content='现在写一篇关于杭州西湖的随笔', additional_kwargs={}, response_metadata={}, id='3f6c63c5-1b77-4299-aad9-23faec0dede3'),
AIMessage(content='《湖山入梦》\n\n断桥其实从未断过。我站在桥头这样想着。石桥完好地横跨在薄雾与水光之间,名字里的那个“断”字,倒成了游人心里最柔软的悬念——仿佛总该有些未完的故事,等着在某个雪后与谁重逢。\n\n晨雾里的西湖是一幅洇了水痕的宋画。保俶塔的轮廓在纱幕后若隐若现,像悬腕写下的一个悬针竖,收笔时轻轻提起,留白处尽是千年风致。这时候的湖面还没有游船的划痕,水色与天色在远处悄悄交融,苏堤的柳枝垂进雾里,每阵风过,就摇落一串露珠的叮咚。\n\n忽然下起雨来。西湖的雨是懂得韵律的。斜斜的雨脚点在湖面上,圈圈涟漪彼此吞吐,恍若工笔画家在绢上细细点染的鱼藻纹。撑伞的行人渐渐多了,各色花伞在长堤上移动,像散落的词牌名。有个穿青衫的老人坐在湖边的长椅上,膝头摊着本《西湖梦寻》,雨丝飘到书页上,他浑然不觉。\n\n我在平湖秋月的茶楼躲雨。临窗的位置正好看见三潭印月,那些石塔像从水底长出来的玉簪花。跑堂的姑娘端来龙井,茶叶在玻璃杯中缓缓舒展,像是把整个春天的山色都融进了这一盏碧澄。邻桌的日本游客用生硬的中文念着“欲把西湖比西子”,尾音落在雨声里,竟有了几分平仄。\n\n雨歇时已是黄昏。夕照把雷峰塔染成淡金色,倒影在水中微微晃动,仿佛塔里真压着未了的传说。苏堤上走来归家的市民,自行车铃叮当作响,惊起荷丛里的白鹭。有个孩子在背诵《饮湖上初晴后雨》,稚嫩的声音飘过水面:“淡妆浓抹总相宜……”\n\n我忽然明白,西湖从来不是单纯的风景。她是白居易整理过的堤坝,是苏东坡吟诵过的夜空,是林和靖陪伴过的梅花,是秋瑾凝视过的月光。这些层叠的记忆渗进湖水里,让每道波纹都成了可以阅读的注脚。\n\n夜色渐浓时,湖边的灯一盏盏亮起来。现代的光晕与古典的意境在此时相遇,像两个时代的文人对坐斟茶。我沿着湖岸慢慢走,水面飘来桂花的气息。暗处有琵琶声,弹的是《春江花月夜》,弦音贴着水面滑向远方。\n\n离开时回望,西湖已隐入深蓝的夜幕。但我知道,明朝雾散,那些桥、那些塔、那些堤,依然会在水光里等着——就像这城市掌心一道温柔的掌纹,千年如一日地,勾勒着人间天堂的模样。', additional_kwargs={'refusal': None, 'reasoning_content': '好的,用户之前让我写诗,现在要一篇关于西湖的随笔,可能喜欢文学性的表达。得保持之前的诗意风格,但转为散文形式。用户可能深层希望有沉浸式的体验,带点个人观察和哲理。\n\n嗯,西湖有很多经典景点,但得避免平铺直叙。可以用第一人称叙述,让读者感觉身临其境。想到从断桥开始,引用白蛇传的故事增加文化深度。然后转到苏堤,用季节变化带出时间感。\n\n雨景很重要,西湖的雨能营造朦胧美,还能自然过渡到历史人物,比如苏轼、白居易,连接古今。加入个人感受,比如现代人的匆忙,对比古人的雅致,让文章有层次。\n\n结尾用夜晚的静谧收束,强调西湖的包容,呼应开头的“名片”比喻。得确保语言流畅,意象连贯,让读者感受到西湖不止是风景,更是有灵魂的地方。'}, response_metadata={'token_usage': {'completion_tokens': 824, 'prompt_tokens': 235, 'total_tokens': 1059, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 194, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 64}, 'prompt_cache_hit_tokens': 64, 'prompt_cache_miss_tokens': 171}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'c7b14391-11e9-458e-86cd-c598f2cd5f47', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--b30f2333-9584-4d86-8396-df893f29bf9d-0', usage_metadata={'input_tokens': 235, 'output_tokens': 824, 'total_tokens': 1059, 'input_token_details': {'cache_read': 64}, 'output_token_details': {'reasoning': 194}}),
HumanMessage(content='再帮我写一段赞美北京的散文', additional_kwargs={}, response_metadata={}, id='23cf1ce1-e057-4e56-8a6c-cee98583d457'),
AIMessage(content='《京华气韵》\n\n北京的魂,是凝在钟鼓楼飞檐下的那一缕晨光。当第一声鸽哨划破灰墙黛瓦的寂静,整座城便从六百年的梦里缓缓醒来。胡同里的青砖还沁着露水,老槐树的影子斜斜地搭在朱漆门上,卖豆汁的吆喝声拖着长长的尾音,把晨雾搅出几分烟火气的涟漪。\n\n站在景山万春亭眺望,紫禁城的金顶在朝阳下泛起粼粼波光,那些琉璃瓦的海洋曾见证二十四位皇帝的更迭。而此刻,穿校服的学生正举着手机与角楼合影,历史与现实在此刻奇妙地重叠——北海的白塔依然如玉簪般插在碧波间,远处国贸的建筑群却已长成钢铁的竹林。\n\n我最爱在秋日午后钻进胡同深处。阳光透过柿子树,在斑驳的影壁上洒下碎金。有位老人坐在四合院门槛上,怀里的收音机正唱着《定军山》,他脚边卧着的狸花猫,瞳孔里映着湛蓝的秋空。突然飘来炒栗子的甜香,混着院墙内飘出的菊花茶味,这是老舍笔下永远温存的人间。\n\n暮色中的长安街另有一番气象。华灯初上的时刻,天安门城楼的红漆在灯光里愈发庄重,自行车流如银梭般穿行,清脆的铃声中,国家大剧院的玻璃幕墙正倒映着最后一抹晚霞。王府井大街飘着糖葫芦的酸甜气,穿旗袍的姑娘举着兔儿爷泥塑,与身边匆匆走过的西装白领擦肩——这是北京最动人的包容。\n\n记得某个雪夜,我从恭王府出来,忽闻什刹海冰场上传来年轻人的欢笑。那些围红围巾的身影在冰刀划出的圆弧里旋转,岸边的酒吧亮起温暖的灯,手鼓声与冰糖葫芦的叫卖声交织,让人恍然领悟:这城市最了不起的成就,是让古老的城墙学会了与摩天轮共舞。\n\n北京从来不言不语,却把千般故事都收在社稷坛的五色土里,藏在大栅栏的铜锅涮肉里,融在京剧演员的水袖里。当我在晨曦中登上残缺的城墙,看动车组如银箭般驶向远方,忽然懂得——这座城的气韵,正在于它既做得了皇都,也当得起民巷;既守得住斑驳的记忆,也迎得向璀璨的明天。', additional_kwargs={'refusal': None, 'reasoning_content': '好的,用户让我写一段赞美北京的散文。之前已经帮他写过雪的诗和西湖的随笔,现在转向北京,可能需要不同的风格和角度。\n\n用户可能希望突出北京的历史底蕴和现代交融,类似西湖那篇的文化深度。但北京更宏大,需要抓住标志性元素,比如胡同、古迹、现代建筑。\n\n可以用时间线展开,从清晨到夜晚,展现古今对比。想到用具体意象,比如钟楼、胡同、故宫,来体现历史,再用CBD和霓虹灯表现现代。避免重复西湖的婉约,改用更沉稳的笔调。\n\n要注意避免陈词滥调,加入生活细节,比如晨练的老人、糖葫芦的叫卖,让散文更生动。结尾点明北京的灵魂在于包容与沉淀,呼应之前的主题。'}, response_metadata={'token_usage': {'completion_tokens': 712, 'prompt_tokens': 875, 'total_tokens': 1587, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 162, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 192}, 'prompt_cache_hit_tokens': 192, 'prompt_cache_miss_tokens': 683}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '7824ddf2-c047-4439-acd0-764a727c889d', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--bc9291ec-c66c-4bbe-8c1f-c53c9ac1551e-0', usage_metadata={'input_tokens': 875, 'output_tokens': 712, 'total_tokens': 1587, 'input_token_details': {'cache_read': 192}, 'output_token_details': {'reasoning': 162}}),
HumanMessage(content='我叫什么?', additional_kwargs={}, response_metadata={}, id='65db1fac-ac9f-4f83-8a8b-3cf23f0da8fa'),
AIMessage(content='您叫“AI蒸馏”呀!这是我们对话开始时您告诉我的名字。这个名字很巧妙,既有科技感又蕴含着提炼精华的意味,让我一下就记住了。', additional_kwargs={'refusal': None, 'reasoning_content': '(他突然问起自己的名字,看来是想确认我是否还记得最初的对话。AI蒸馏这个名字确实很特别,当时我还特意分析过其中知识提炼的寓意。)\n\n(从写诗到西湖随笔再到北京散文,我们这段对话跨度不小,但他始终保持着对文字美感的追求。现在突然回到最初的称呼问题,可能是想测试我的记忆连贯性,或者单纯想重温那个有趣的命名时刻。)\n\n(记得他喜欢文学性的表达,所以回复时不妨再点明名字的诗意,用“知识的清泉”呼应之前的“蒸馏”意象。保持这样带点文采的对话风格应该正合他心意。)'}, response_metadata={'token_usage': {'completion_tokens': 166, 'prompt_tokens': 1431, 'total_tokens': 1597, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 131, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 832}, 'prompt_cache_hit_tokens': 832, 'prompt_cache_miss_tokens': 599}, 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '1cb1e5e9-3a52-43d1-b848-eb8c24410b53', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--64d7d76f-6f4b-48ea-88ec-a4bbabfeb808-0', usage_metadata={'input_tokens': 1431, 'output_tokens': 166, 'total_tokens': 1597, 'input_token_details': {'cache_read': 832}, 'output_token_details': {'reasoning': 131}})]}
final["messages"][-1].pretty_print()
==================================[1m Ai Message [0m==================================
您叫“AI蒸馏”呀!这是我们对话开始时您告诉我的名字。这个名字很巧妙,既有科技感又蕴含着提炼精华的意味,让我一下就记住了。
2.4 人在闭环
在自动化系统中,尤其是 高风险任务(如数据库写入、财务操作、邮件发送) 中,完全让大模型自主执行往往并不安全。LangChain 1.0 引入的 Human-in-the-Loop Middleware(人类在环中间件)允许在关键节点 暂停 Agent 执行,等待人类对模型的行为进行批准(approve)、编辑(edit) 或 拒绝(reject),从而让「智能体」的行为真正符合企业安全、合规和伦理要求。
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model="openai:gpt-4o",
tools=[read_email_tool, send_email_tool],
checkpointer=InMemorySaver(),
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
# 要求对发送邮件进行批准、编辑或拒绝
"send_email_tool": {
"allowed_decisions": ["approve", "edit", "reject"],
},
# 自动批准读取邮件
"read_email_tool": False,
}
),
],
)
配置选项:
interrupt_on: 字典 (必需),工具名称到批准配置的映射。值可以是 True(使用默认配置中断)、False(自动批准)或一个 InterruptOnConfig 对象。
description_prefix: 字符串 (默认值: “Tool execution requires approval”),操作请求描述的前缀。
InterruptOnConfig 选项:
allowed_decisions: 字符串列表,允许的决定列表:“approve”、“edit” 或 “reject”。
description: 字符串 | 可调用对象,用于自定义描述的静态字符串或可调用函数。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)