首个聚焦多无人机协同具身感知与推理的综合基准AirCopBench:14.6k问题覆盖四大维度,40个MLLM评估揭示24.38%性能差距
清华大学&香港科技大学&南洋理工大学&吉林大学联合研究的多无人机协同具身感知与推理基AirCopBench,这是首个聚焦多无人机协同具身感知与推理的综合基准,验证了模拟到真实迁移的可行性,填补了现有基准缺乏具身协同推理评估的空白。
摘要:清华大学&香港科技大学&南洋理工大学&吉林大学联合研究的多无人机协同具身感知与推理基AirCopBench《AirCopBench: A Benchmark for Multi-drone Collaborative Embodied Perception and Reasoning》:这是首个聚焦多无人机协同具身感知与推理的综合基准,包含 2.9k + 多视图图像(模拟 + 真实数据)、14.6k + 视觉问答(VQA)对,覆盖 4 大任务维度 14 个细分任务,全面纳入遮挡、噪声、运动模糊等 8 类感知退化场景。通过评估 40 个主流 MLLM,发现最优模型准确率仅 59.17%,较人类水平(78.25%)差距 24.38%,微调后模型性能最高提升 26.97%,验证了模拟到真实迁移的可行性,填补了现有基准缺乏具身协同推理评估的空白。
一、现有协同感知基准的核心技术缺口
当前多无人机协同感知相关基准存在的关键局限,制约 MLLM 在真实场景的落地:
-
感知退化覆盖不足:仅考虑遮挡等少数场景,缺乏对噪声、数据丢失、远距离小目标等真实飞行中常见退化类型的支持;
-
缺乏具身推理支持:多为非第一视角设计,依赖全局数据融合,无法评估无人机的角色化、人性化协同决策能力;
-
任务与模态单一:聚焦基础感知任务(如检测),缺乏感知评估、协同决策等高级任务,且多为单 RGB 模态,未整合点云等航空常用数据;
-
数据质量与规模有限:VQA 数量少(多在 10k 以下),生成流程缺乏严格质量控制,存在常识可回答的无效问题。
二、核心创新:AirCopBench 的四大设计突破
基准以 “真实场景协同感知需求” 为核心,四大创新点如下:
1. 四维 14 任务体系:全面覆盖协同感知全流程
-
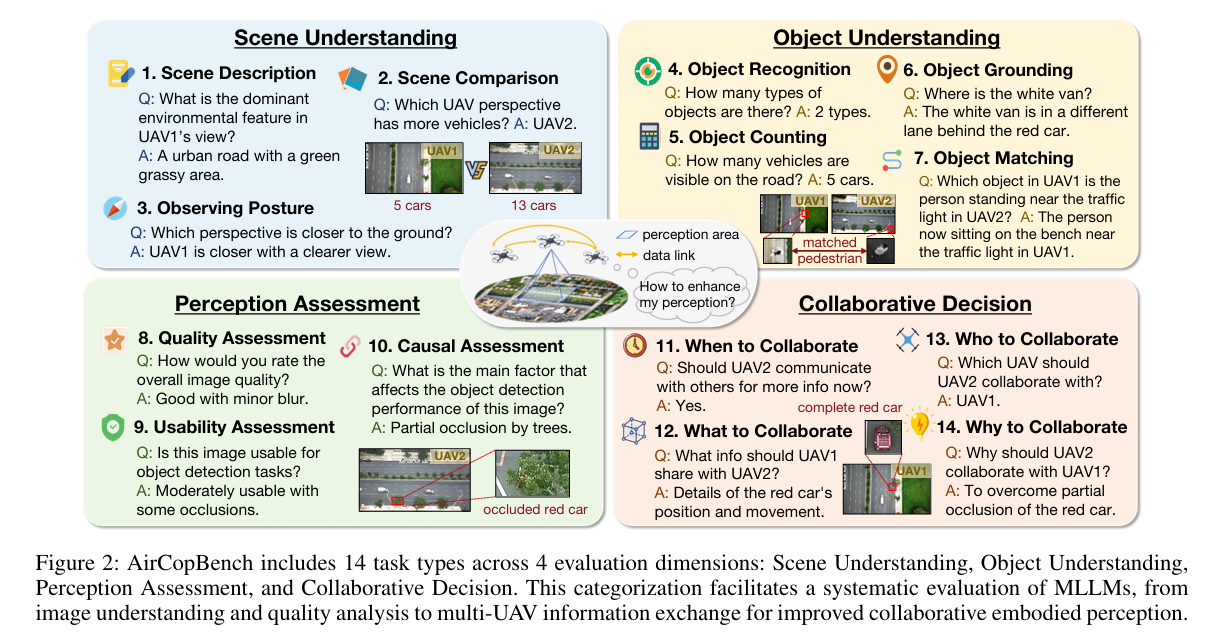
定义:构建 “场景理解 - 目标理解 - 感知评估 - 协同决策” 四层任务架构,覆盖从基础图像解读到高级协同推理的完整链路(图 2);
-
核心设计:包含场景描述 / 对比、目标识别 / 计数 / 匹配、图像质量 / 可用性评估、协同时机 / 对象 / 内容决策等 14 个细分任务,覆盖多无人机协同的核心需求;
-
优势:首次将协同决策纳入基准,突破传统基准 “重感知、轻推理” 的局限,可全面评估 MLLM 的具身协同能力。
2. 多感知退化 + 多模态数据:贴近真实飞行场景
-
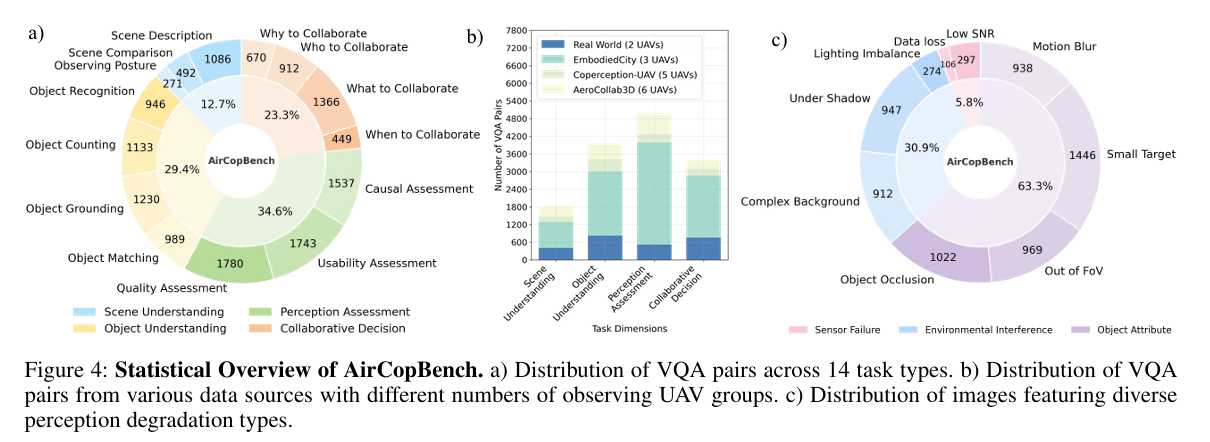
定义:整合模拟与真实数据,纳入 8 类感知退化,支持 RGB、文本、点云多模态输入;
-
核心设计:数据来源包括 Carla/AirSim 模拟数据、MDMT 真实数据,通过噪声注入、部分遮挡生成衍生数据,覆盖 occlusion、shadow、noise 等 8 类退化(图 4c);
-
优势:数据规模达 2.9k + 多视图图像,感知退化类型较现有基准提升 3 倍以上,多模态支持适配无人机多传感器配置。
3. 三重生成 + 三重质控:保障 VQA 高质量
-
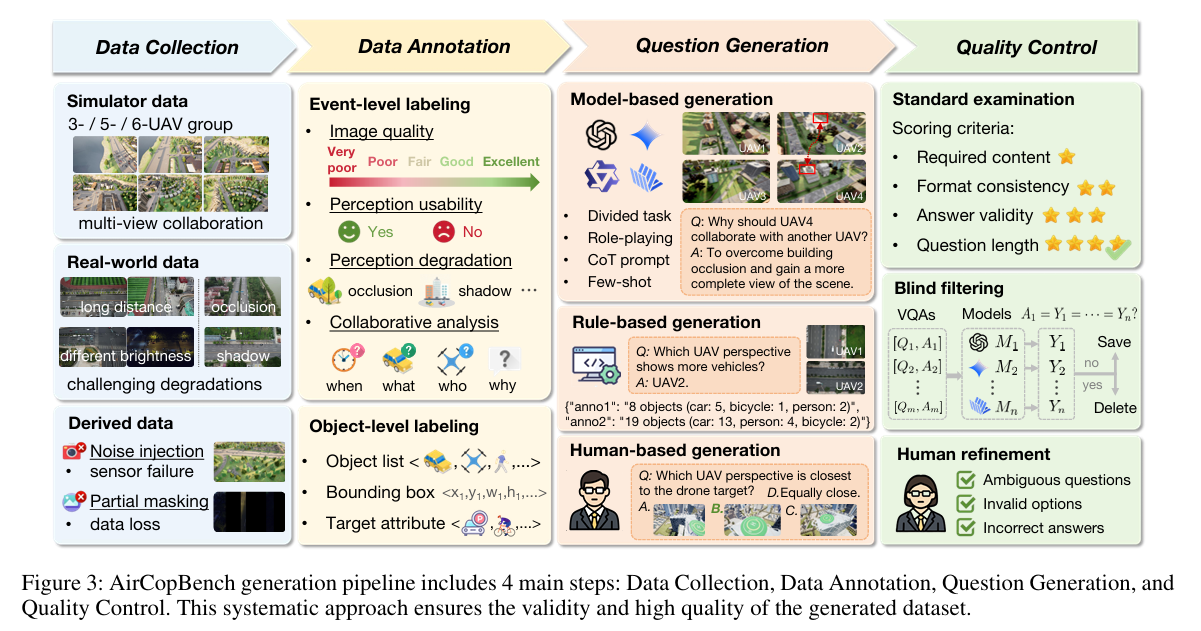
定义:通过模型、规则、人类三重方式生成问题,结合标准检查、盲筛、人工优化确保数据有效性(图 3);
-
核心设计:模型生成用 GPT-4o/QwenVL-Max,规则生成适配结构化任务,人类生成负责复杂空间推理任务;质控移除常识可答问题,修正模糊 / 错误选项,人工优化耗时超 800 小时;
-
优势:最终保留 14.6k + 高质量 VQA,无效问题占比低于 3%,较现有基准数据质量提升显著。
4. 模拟 - 真实双数据:支持迁移能力评估
-
定义:同时包含大规模模拟数据(20 种地图场景)和真实飞行数据,专门设计模拟到真实迁移验证实验;
-
核心设计:模拟数据聚焦可控感知退化,真实数据来自双无人机协同感知场景,通过微调验证迁移效果;
-
优势:首次在多无人机基准中验证 MLLM 的模拟到真实迁移能力,为实际部署提供数据支撑。
三、实验验证:40 个 MLLM 的协同感知能力全面评估
基于 AirCopBench 的实验覆盖零样本评估、微调验证、模拟到真实迁移,核心结果如下:
1. 零样本评估:MLLM 表现分化,与人类差距显著
-
40 个 MLLM 中,最优模型(Ovis2-16B)准确率仅 59.17%,较人类水平(78.25%)差距 24.38%;
-
任务偏置明显:场景描述 / 对比任务表现较好(准确率 60%+),可用性评估、协同时机决策任务表现极差(准确率 < 30%);
-
开源模型表现亮眼:Ovis2-16B、Kimi-VL-A3B-Thinking 等开源模型性能持平甚至超越部分专有模型(如 GPT-4o 准确率 51.79%)。
2. 微调验证:领域适配显著提升性能
-
对 Qwen2.5-VL(3B/7B)、LLaVA-NeXT-13B 进行微调后,性能大幅提升:
-
Qwen2.5-VL-7B:从 47.33% 提升至 74.30%(+26.97);
-
Qwen2.5-VL-3B:从 47.33% 提升至 66.44%(+19.11);
-
LLaVA-NeXT-13B:从 38.31% 提升至 57.61%(+19.30)。
3. 模拟到真实迁移:效果显著
-
仅用模拟数据微调的 AirCop-7B,在真实无人机数据上准确率达 67.41%,较原始 Qwen2.5-VL-7B(47.77%)提升 19.64%;
-
重点提升任务:目标定位(+50.00%)、目标计数(+38.89%)、可用性评估(+53.20%),验证模拟数据的实用价值。
4. 误差分析:三大核心错误类型
-
感知幻觉错误:因图像退化导致目标误识别或漏识别;
-
空间推理错误:无法正确解读多视图中目标的位置、方向关系;
-
多图像理解错误:难以整合跨无人机视图信息,导致协同决策失误。
四、核心价值与适用场景
1. 核心价值
-
填补基准空白:首个支持多无人机协同具身感知与推理的综合基准,覆盖真实场景感知退化与协同决策需求;
-
多维度评估体系:从基础感知到高级推理,全面衡量 MLLM 的航空协同能力;
-
支持技术迭代:提供模拟 + 真实数据、严格质控的 VQA 数据集,支持 MLLM 微调与模拟到真实迁移验证。
2. 适用场景
-
多无人机协同系统研发:评估与优化无人机集群的感知协同、决策效率;
-
MLLM 具身智能评估:为航空场景下 MLLM 的具身感知与推理能力提供标准化测试;
-
航空智能系统落地:支撑搜救、巡检、测绘等无人机应用的算法验证与优化。
五、结语
AirCopBench 通过多维度任务设计、丰富的感知退化场景、大规模高质量数据,构建了多无人机协同具身感知与推理的标准化评估体系。实验结果揭示了当前 MLLM 在协同感知任务中的显著短板,而微调与模拟到真实迁移的成功验证,为后续技术迭代提供了明确方向。该基准的推出将推动多智能体具身智能与航空智能系统的融合发展。
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)