Spotting LLMs with Binoculars:零样本“抓 AI 写作”的双筒望远镜
论文在解决什么问题?大模型写的文本越来越像人,传统基于训练的检测器往往只对特定模型(比如 ChatGPT)有效,一旦换成别的 LLM 或新版本,性能就会大幅下降。论文提出Binoculars——一种只用两只预训练语言模型、完全不需要训练数据的零样本 LLM 文本检测方法,目标是在不知道“谁写的”的前提下区分「人类写作」和「机器生成」。有什么历史意义 / 性能突破?在完全零样本的前提下,Binocu
1. 论文基本信息
标题:Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
作者:Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, Tom Goldstein
年份 / 会议:ICML 2024
领域关键词:Large Language Model (LLM) 检测、零样本检测、perplexity、cross-perplexity、ChatGPT 检测、公平性、鲁棒性
2. 前言:为什么读这篇论文?
-
论文在解决什么问题?
大模型写的文本越来越像人,传统基于训练的检测器往往只对特定模型(比如 ChatGPT)有效,一旦换成别的 LLM 或新版本,性能就会大幅下降。论文提出 Binoculars——一种只用两只预训练语言模型、完全不需要训练数据的 零样本 LLM 文本检测方法,目标是在不知道“谁写的”的前提下区分「人类写作」和「机器生成」。 -
有什么历史意义 / 性能突破?
在完全零样本的前提下,Binoculars 在多种数据集上对 ChatGPT 文本的检测 TPR 超过 90%,FPR 控制在 0.01%,效果和甚至超过使用专门 ChatGPT 数据训练出来的商业/学术检测器(如 GPTZero、Ghostbuster)。同时同一个检测器还能识别 LLaMA、Falcon 等不同家族的模型输出。
3. 基础概念铺垫:看懂 Binoculars 需要的“最小知识集”
要理解 Binoculars,我们先把几个概念讲清楚,但尽量不用公式轰炸。
3.1 语言模型 & 概率视角
大语言模型本质上是在做一件事:给定前面一串 token,预测下一个 token 的概率分布。所以模型看到一段文本时,既能“续写”,也能算出自己觉得这段话 有多“顺口”、多“不意外”——这就是下面要说的 perplexity。
3.2 Perplexity(困惑度)
Perplexity 可以理解为“模型读完一段话之后的疑惑程度”:
- 模型看到自己训练风格的句子,会觉得“很顺”,困惑度低;
- 看到结构怪异、拼写混乱的句子,就会很疑惑,困惑度高。
因此很多早期工作直接用 perplexity 来做检测:如果一段文本在某个 LLM 眼里特别“顺”,就怀疑它是机器写的。
但问题马上来了:perplexity 非常依赖上下文和主题。同一句话,在不同场景下“惊不惊喜”完全不同,这就引出了论文里著名的 “水豚问题(capybara problem)”。
3.3 “水豚问题”:只看 perplexity 会严重翻车
作者给了一个例子:让 GPT-4 写一段关于“当天文学家的水豚”故事。生成的文本中有 “capybara”“astrophysicist” 等词,如果你只看这段生成文本本身,在一个通用 LLM 眼里,出现这样奇怪组合的词会非常少见,perplexity 反而很高,像是人类异想天开的产物。
也就是说:
- 这段话明明是 LLM 写的;
- 但因为我们不知道前面那句 prompt(“写一个当天文学家的水豚”),单看回复就会觉得它“太奇怪”,从而被错误地标记为人类写作。
这种“缺失 prompt 导致的错判”,就是 Binoculars 想要解决的核心难题。
3.4 Cross-Perplexity(交叉困惑度)
为了解决“水豚问题”,作者引入了第二个量:cross-perplexity。简单说,就是:
> 拿模型 A 写下一 token 的预测分布,让模型 B 来“打分”这些预测分布到底有多惊讶。
直觉上:
- 如果 A 和 B 都是类似的 LLM,它们对下一 token 的预测会比较接近,cross-perplexity 会比较低;
- 如果是真人写作,人的选择和两个模型的“共识”会差很多,cross-perplexity 会更高。
于是,和只看文本 perplexity 不同,cross-perplexity 在某种程度上帮我们估计了“在当前语境下,LLM 们自己本应有多困惑”。
3.5 关键想法:用“比值”而不是“绝对值”
Binoculars 的核心出发点其实很人话:
> 在某个上下文下,LLM 自己写出来的东西,应该比人写的那份 离“LLM 共识”更近。
所以与其盯着“这段话本身有多奇怪”,不如去看:
- 真人写的文本: 它的 perplexity 相对 “LLM 在同一上下文下的预期困惑度” 是不是更大?
- 机器写的文本: 它的 perplexity 更接近 “LLM 对自己输出的期望困惑度”?
这个“相对关系”,就是后面正式定义的 Binoculars score。
4. 历史背景与前置技术:LLM 检测是怎么一路走来的?
LLM 文本检测可以粗粗划成三大流派,每一派都直接影响了 Binoculars 的设计。
4.1 预防派:记录 & 水印
这类方法假设我们能控制生成模型本身:
1. 记录所有生成:服务端把每一条生成都存档,后面只要查日志就能知道是不是机器写的。
2. 加入水印:在采样策略里对 token 做细微偏置,让输出里带有统计意义上的“印记”,再设计检测器去读这些印记。
这些方法理论上很干净,但前提是:你能控制生成模型。对于开放 API、多家模型甚至离线模型的世界,这个前提往往不成立。
4.2 训练派:把“AI / Human”当成监督任务
第二类是把检测本身当成一个二分类任务:
- 拿大量「人类文本 + 某个 LLM 的输出」作为训练集,
- 在预训练模型(RoBERTa、GPT 等)上 finetune 出一个“AI 文本判别器”。
比如:
- Grover、GLTR 等早期工作针对 GPT-2;
- Ghostbuster 专门对 ChatGPT 做了大规模训练与调参。
这条路的问题在论文里说得很直白:
- 对训练目标 LLM 很强(比如 ChatGPT),
- 但迁移到别的模型就崩了,Ghostbuster 在 LLaMA 文本上几乎失效。
- 新模型一出,就得重新收集数据、再训练一轮。
4.3 统计派:不训练,只抓“机器笔迹”
第三类方法更像“法医”:不关心训练细节,只盯着文本的统计特征:
- perplexity(人写的比机器“乱”);
- perplexity 曲率(DetectGPT 看的是扰动前后 log-prob 的曲线);
- log-rank / n-gram 频率 / 本征维度 等奇形怪状的统计量。
好处是:
- 不需要专门的数据集训练,迁移能力好。
坏处是:
- 单一特征往往不稳,在“水豚式”prompt 里很容易翻车;
- 很多论文只报 AUC,在真实需要极低 FPR 的场景下表现并不好。
4.4 评测困境:只看 AUC 是不够的
文章专门吐槽了一点:检测器如果不能保证极低的误伤率,就很危险。
- 真正高风险的问题是:把人写的错判成机器写的(false positive)。
- 像学术场景,如果 1% 的正常作文都被判成 AI,会比漏掉一些 AI 作文更糟。
因此作者坚持使用:
- TPR@0.01% FPR 作为主指标,而不是只看 AUC / F1。
- 并且强调要在 多领域、多语言、分布外数据集 上评测,而不是只在训练数据的同分布上做实验。
Binoculars 就是在这样的背景下提出:要在零样本、黑盒、跨模型的前提下,把检测做得尽可能稳。
5. 论文核心贡献(叙述版)
如果用一句话概括,这篇论文做的是:
用两只语言模型“对视”同一段文本,通过 perplexity / cross-perplexity 的比值,构造出一个能在零样本下泛化到多种 LLM 的强力检测器。
更展开一点,核心贡献可以分为四层:
第一,方法层面:
作者提出 Binoculars score:用一个“观察者”模型计算文本的 perplexity,同时用一个“表演者”模型给出下一 token 的预测分布,再用观察者去评估这些分布的 cross-perplexity,最后取两者的比值作为检测信号。这个简单的比值,就基本解决了“水豚问题”,使得在各种奇怪 prompt 下,机器文本依然有明显可分的统计特征。
第二,效果层面:
在完全不依赖 ChatGPT 训练样本的前提下,Binoculars 在新闻、创意写作、学生作文等数据集上,对 ChatGPT 文本的检测 TPR 超过 90%,FPR 控制在 0.01%,超过 GPTZero、Ghostbuster、DetectGPT 等代表性方法。对 LLaMA、Falcon 输出也有很高的检出率。
第三,鲁棒性与公平性层面:
论文非常系统地测试了各种现实场景:非母语写作者、低资源语言、多风格 prompt、模型记忆的名句、随机 token 序列等。Binoculars 在这些场景下 几乎不对非母语写作者产生偏见,且有清晰可解释的行为模式。
第四,分析层面:
作者不仅给出结果,还做了大量 ablation,比如不同模型组合、只用 PPL / 只用 X-PPL 的效果、调 performer 的指令微调程度、文档长度的影响等,基本把这个方法的适用边界和潜在问题都“挖干净”了,对后续工作非常有参考价值。
6. 方法详解:Binoculars 到底在算什么?
6.1 整体架构:两只模型、一段文本、一个分数
从工程视角看,Binoculars 非常简单,整体流程可以用一句话描述:
> 用模型 M₁ 当“观察者”,用模型 M₂ 当“表演者”,对同一段文本各算一遍,然后用一个公式把结果揉成一个分数。
更具体一点,流程大致是:
-
输入一段待检测文本
s。 -
用 tokenizer 把
s切成 token 序列x₁,…,x_L。 -
用 观察者模型
M₁(论文默认用 Falcon-7B-Instruct)对整段文本做前向:-
得到每个位置上的预测分布
M₁(s)_i, -
计算该文本在
M₁眼中的 log-perplexity。
-
-
用 表演者模型
M₂(默认用 Falcon-7B)对同一文本做前向:-
得到每个位置上的预测分布
M₂(s)_i。
-
-
用
M₁来评估M₂的预测分布,算出 log cross-perplexity。 -
计算比值
B = log PPL / log X-PPL,即 Binoculars score。 -
和事先在参考数据集上调好的全局阈值比较:
-
分数低于阈值 → 更像机器;
-
分数高于阈值 → 更像人类写作。
-
你可以把它想象成:两个 LLM 站在一起看同一篇文章,互相比对“你会不会这么写”,如果文本更接近“LLM 共识”,就怀疑是机器写的。
6.2 数学定义与直觉解释
6.2.1 记号约定
设一段文本 s,经过 tokenizer T 得到 token 序列 x = (x₁,…,x_L)。
语言模型 M 在每个位置输出一个对整个词表 V 的概率分布向量 Y_i,第 j 个维度表示
P( v_j | x₁,…,x_{i-1} )。
6.2.2 Log-Perplexity(对数困惑度)
对 M 而言,这段文本的 log-perplexity 定义为
也就是:把每个真实 token 的对数概率取负,再在全句上做平均。
直觉:
- 文本越符合模型习惯 → 每个 token 概率越大 → log PPL 越小;
- 文本越“离谱” → 概率越小 → log PPL 越大。
6.2.3 Cross-Perplexity(交叉困惑度)
给定两个模型 M₁ 与 M₂,它们在每个位置的预测向量分别是 M₁(s)_i、M₂(s)_i,作者定义:
这里的点乘代表用 M₁ 的分布当权重,计算 M₂ 的 log-prob 期望,也就是典型的 交叉熵。
直觉:
- 如果 M₂ 的分布和 M₁ 很像,那么 M₁ 不会觉得 M₂ 的预测“很惊讶”,X-PPL 会比较小;
- 如果 M₂ 完全乱来,X-PPL 就会大。
6.2.4 Binoculars score:比值胜于绝对值
综合这两个量,Binoculars score 定义为
观察几个极端情况:
1. 机器写的文本
- 这段文本是某个 LLM G 写的;
- M₁、M₂ 和 G 都是类似架构、类似训练数据的模型;
- 文本在 M₁ 看来 perplexity 不高;
- 而 M₂ 对每一步的预测和 M₁ 差别也不大,X-PPL 也不高;
- 因此 分子 / 分母 相近,B 会接近 1 甚至略小。
2. 人写的文本
- 人的选择往往比 LLM 更“跳脱”,比如突然用一个冷门比喻、跨领域联想;
- 在 M₁ 看来 perplexity 会更高;
- 同时人类选择的 token 分布与两只 LLM 的“共识”差距更大,X-PPL 也高;
- 但关键是:perplexity 的抬升幅度通常比 X-PPL 更大,于是 B 会显著大于 1。
这就形成了一个有区分力的统计量:
- B 偏小 → 更像 LLM 输出;
- B 偏大 → 更像人写。
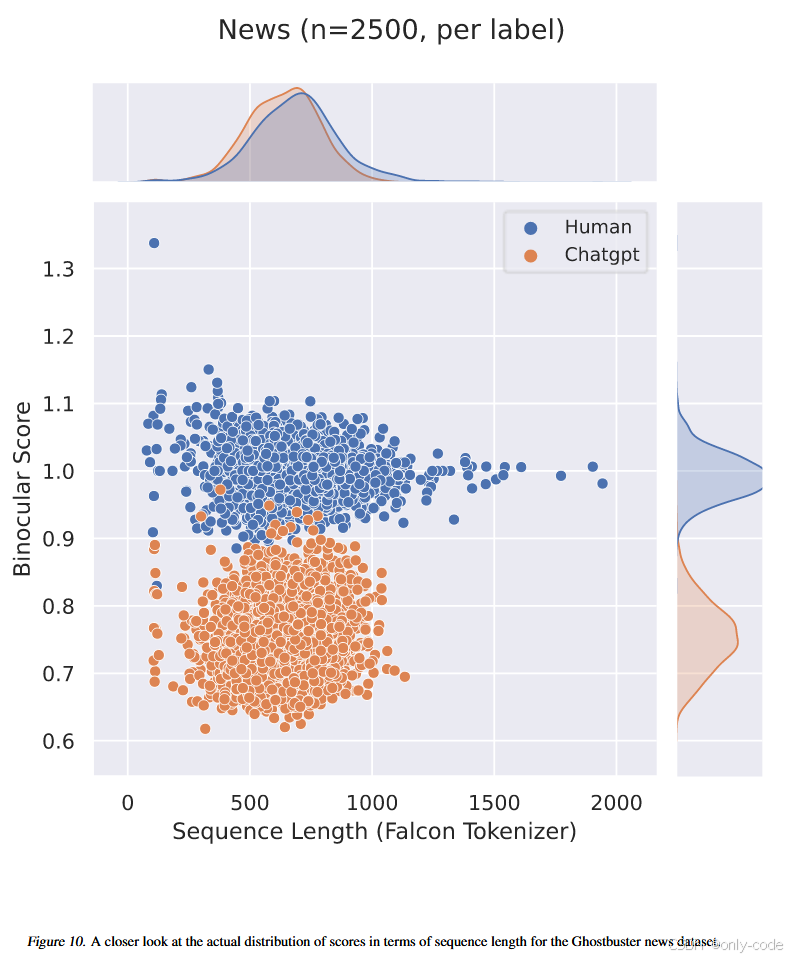
【插图:Binoculars score 对人类文本与 ChatGPT 文本的分布直方图】
6.3 “水豚问题”是怎么被解决的?
回到那段“天文学家水豚”的 GPT-4 输出:
- 用 Falcon-7B-Instruct 直接算 perplexity,会得到一个 远高于人类与机器均值 的数;
- 只看这个数,很容易把它当做人写的。
但在 Binoculars 视角下,我们会再做一步:
- 让 Falcon-7B(未指令微调版)对同一段文本给下一 token 分布,
- 然后看 Falcon-7B-Instruct 对这些预测分布的 X-PPL。
由于这段文本本身就是 LLM 写的,所以 Falcon-7B 的预测其实和 Falcon-7B-Instruct 很接近,X-PPL 不会特别夸张,于是 B 的比值会明显偏向“机器”一侧。事实上,论文里给出的例子中 Binoculars score 只有 0.73,远低于阈值 0.901,成功判为机器。
6.4 实现细节与伪代码
如果要在工程里落地 Binoculars,大致可以按下面的伪代码来实现:
输入:文本 s
模型:观察者 M1 = Falcon-7B-Instruct
表演者 M2 = Falcon-7B
参数:全局阈值 τ(在参考数据集上调好)
1. x = tokenize(s)
2. 使用 M1 前向,得到:
- 对每个位置 i 的预测分布 Y_i^M1
- 对应 token x_i 的 log 概率 log p_i^M1
3. 计算 logPPL_M1(s) = - (1/L) * Σ_i log p_i^M1
4. 使用 M2 前向,得到:
- 对每个位置 i 的预测分布 Y_i^M2
5. 计算 logX-PPL_M1,M2(s) = - (1/L) * Σ_i ( Y_i^M1 · log Y_i^M2 )
6. 计算 B(s) = logPPL_M1(s) / logX-PPL_M1,M2(s)
7. 如果 B(s) < τ:
输出 “更像 LLM 生成”
否则:
输出 “更像人类写作”
可以看到,除了两次前向和一些简单的标量运算,没有任何训练步骤,这也是它能零样本泛化的基础。
6.5 关键 trick 与设计考量
-
模型选型:要“相似但不一样”的双模
论文大量实验表明:
-M₁和M₂性能靠得越近,Binoculars 的效果越好;
- 极强 + 极弱 的组合反而不理想。
这和对比解码 / speculative decoding 中“强+弱”的设计刚好相反,原因在于 Binoculars 要利用的是 “相似模型对同一文本的共识程度”,而不是差异。
-
阈值调节:只在参考数据集上调一次
作者在新闻、学生作文等若干数据集上(包含 ChatGPT、LLaMA、Falcon 生成)用准确率最大化来选择一个 全局阈值,之后在所有其他数据集上都不再调整,保证 “out-of-domain” 评价的严谨性。 -
只用 PPL / 只用 X-PPL 都不行
论文在附录里专门做了 ablation:
- 单独用 PPL:AUC 高,但在低 FPR 下 TPR 明显不足;
- 单独用 X-PPL:区分度更差;
- 只有 用比值 B 才能在 0.01% FPR 下保持很高 TPR。 -
文档长度:越长越好,但短文也不差
在 128 / 256 / 512 token 三种截断长度下,Binoculars 的检测性能随长度上升而稳定提升,尤其在新闻类文本中,128 token 就有不错效果,512 token 基本接近饱和(Figure 2)。
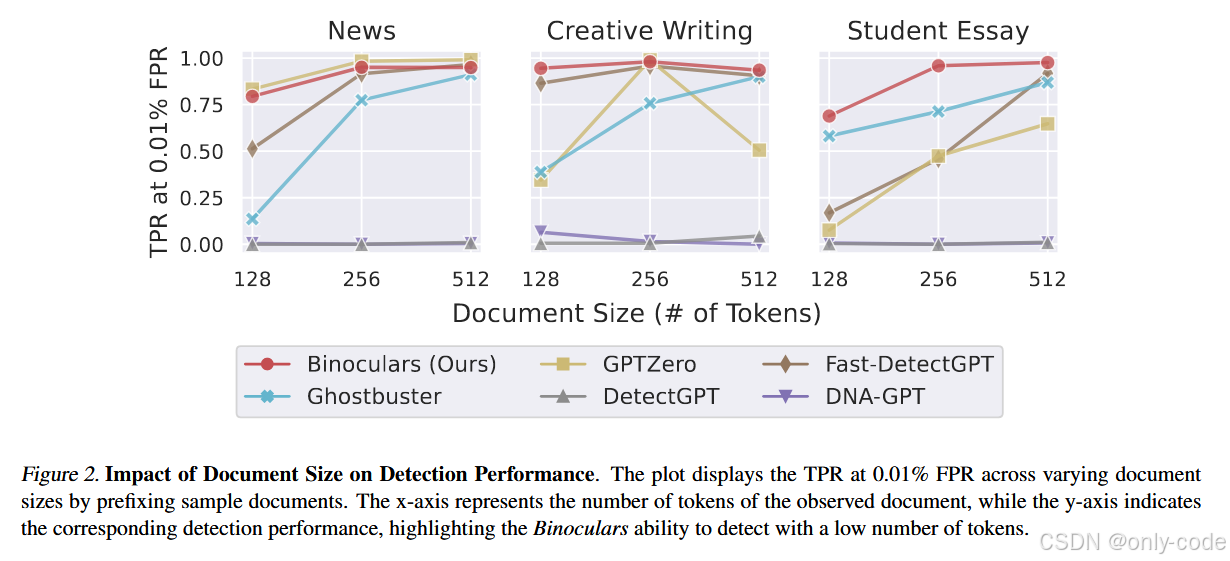
【插图:文档长度对 TPR@0.01% FPR 的影响曲线,对应原文 Figure 2】
7. 实验结果与性能分析
7.1 实验设置:数据集与对比方法
论文的实验可以分成几大块:
-
Ghostbuster 三个数据集(Verma et al., 2023)
- News(新闻)、Creative Writing(创意写作)、Student Essay(学生作文);
- 每个数据集都是 人类文本 + ChatGPT 生成文本 各 2500 篇左右。 -
开放模型生成数据集
- 从 CCNews、PubMed、CNN 提取人类文本首 50 个 token 作为 prompt;
- 让 LLaMA-2-7B、LLaMA-2-13B、Falcon-7B 继续生成最多 512 token;
- 去掉 prompt,只保留生成部分作为机器样本。 -
OpenOrca 指令数据集
- 包含大量指令 + GPT-3 / GPT-4 回答;
- 用于测试对高性能 API(包括 GPT-4、Gemini-Pro)的检测能力。 -
M4 多语言,多域检测数据集(Wang et al., 2023)
- 来源包括 Arxiv、Reddit、WikiHow、Wikipedia;
- 语言包括英语、乌尔都语、俄语、保加利亚语、阿拉伯语等;
- 机器文本来源主要是 ChatGPT。 -
公平性与极端情况数据集
- EssayForum:非母语英语学习者的作文,包含原始和语法纠正版本;
- 若干著名文本(宪法、马丁·路德·金演讲、名著片段、Bob Dylan 歌词等);
- 完全随机 token 序列。
对比方法包括:
- Ghostbuster(RoBERTa + 特征 + 线性头);
- GPTZero(商业检测器);
- DetectGPT 及其高效版本 Fast-DetectGPT;
- DNA-GPT 等统计算法;
- 以及在 M4 数据集上官方提供的 RoBERTa 等基线。
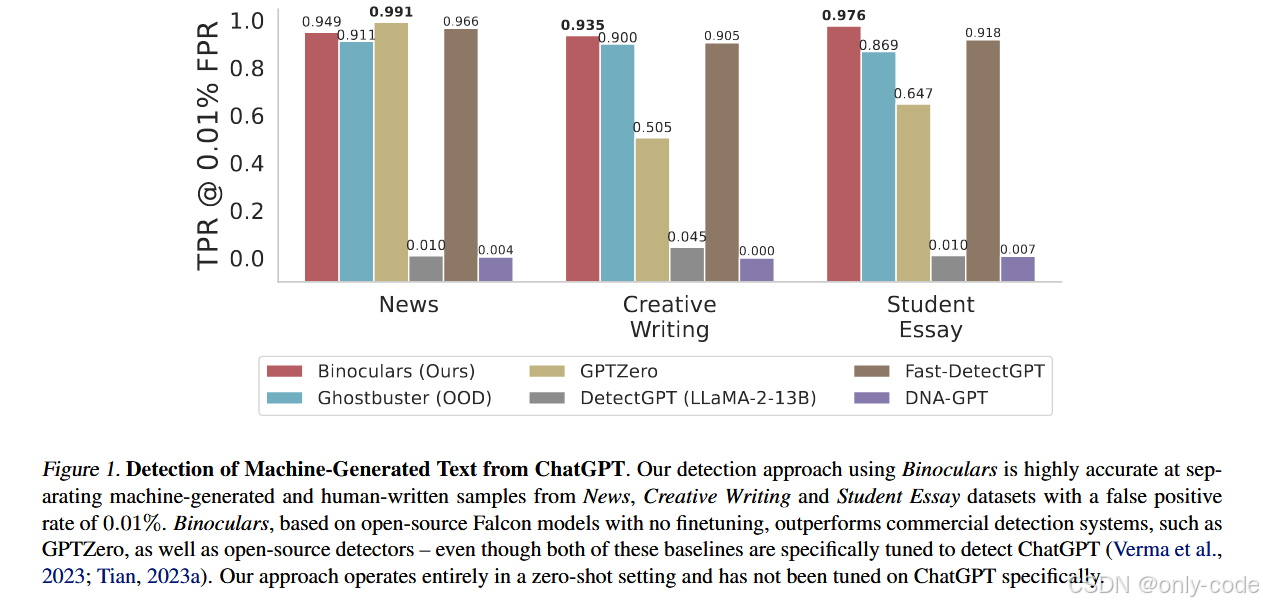
【插图:主要检测方法在三大数据集上的性能对比条形图,对应原文 Figure 1】
7.2 ChatGPT 文本检测:零样本碾压“有监督”对手
在 Ghostbuster 的三个数据集上,论文报告了 TPR@0.01% FPR 和 F1-score:
-
在 News / Creative Writing / Student Essay 上,
-
Binoculars 的 TPR@0.01% FPR 分别约为 0.949、0.935、0.976;
-
Ghostbuster 的 TPR 顶多在 0.91 左右,GPTZero、DetectGPT 在这一指标下要么明显偏低,要么波动很大。
-
更重要的是:Binoculars 完全没用 ChatGPT 的训练样本,而 Ghostbuster 与 GPTZero 都对 ChatGPT 做了专门调参。这意味着:
> 在“被针对训练”的对手面前,一个零样本的纯统计方法,靠着精巧的设计,反而取得了更好的实战表现。
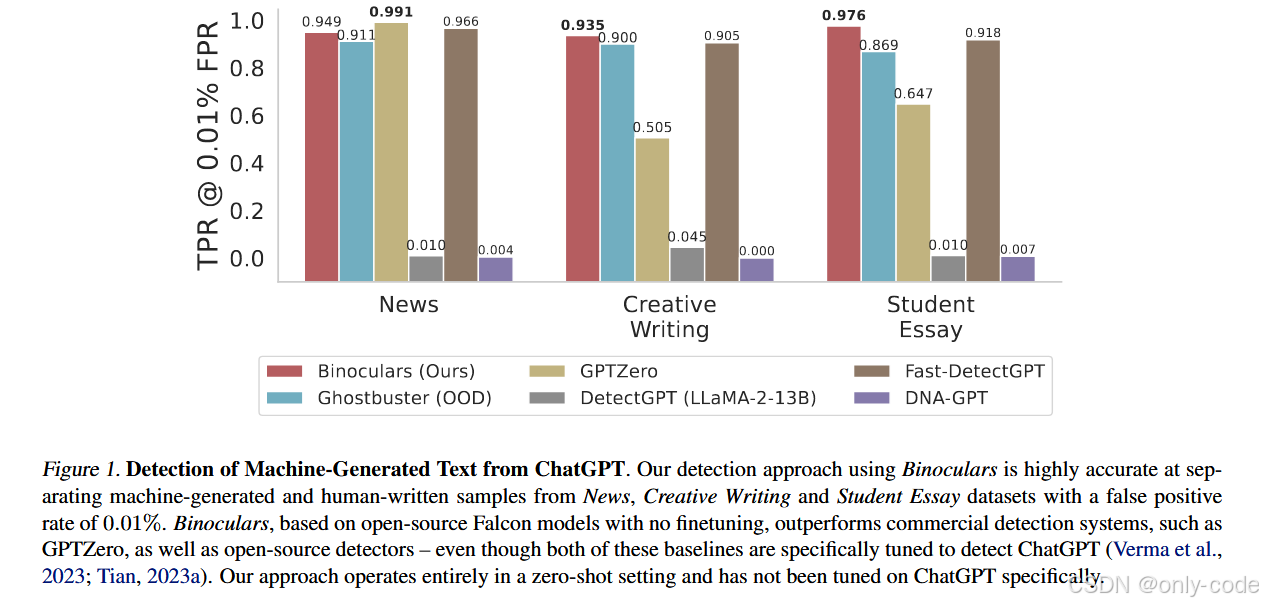
【插图:Figure 1 中 Binoculars 与 Ghostbuster 等方法的 TPR 条形图】
如果看 F1-score,几家方法都接近 0.98–0.99,差距不大。但论文强调:F1 掩盖了低 FPR 区域的差异,在实际高风险场景里,应该更看重 TPR@超低 FPR。
7.3 LLaMA / Falcon 文本检测:泛化到“完全不同”的模型
当机器文本由 LLaMA-2-13B 或 Falcon-7B 生成时,情况就有趣了:
- Ghostbuster 在这些模型上的检测几乎失效,TPR 曲线在低 FPR 附近非常难看;
- Binoculars 则在 PubMed、CCNews、CNN 三个数据集上,
- ROC 曲线在低 FPR 段明显高于其他方法;
- AUC 接近 1,TPR@0.01% FPR 也保持在高位。
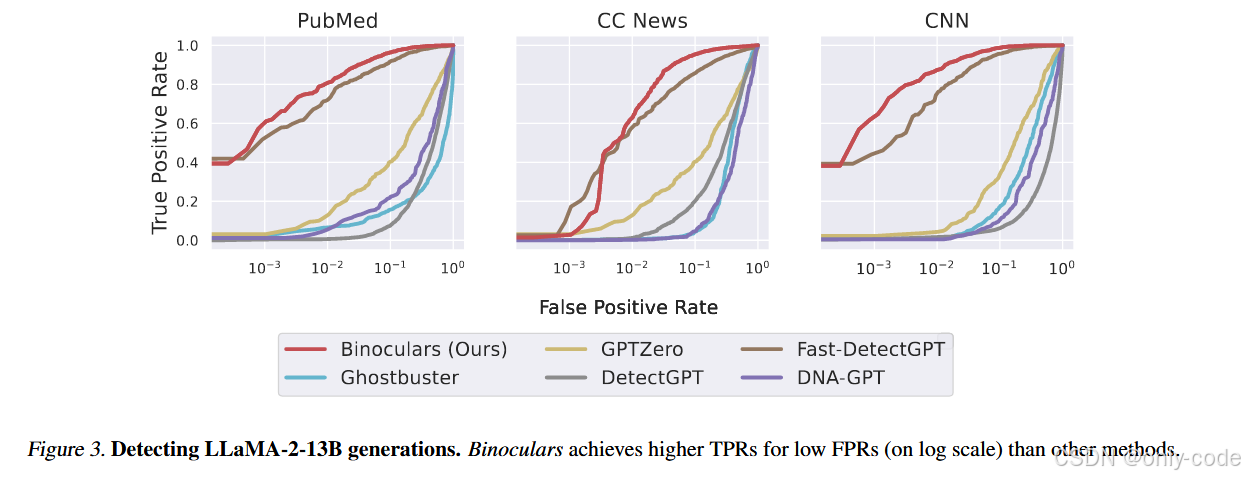
【插图:LLaMA-2-13B 生成文本的 ROC 曲线,对应原文 Figure 3】
这验证了作者的关键 claim:Binoculars 不需要知道“是谁写的”,只要写的人是“像 Falcon / LLaMA 那样训练出来的 transformer”,它就有很大机会把它抓出来。
7.4 多语言、多域检测:M4 数据集上的表现
在 M4 数据集上,作者用 precision–recall 点来展示不同检测器的表现:
-
在 Arxiv、Reddit、WikiHow、Wikipedia 四个域上,
-
Binoculars 的 precision 往往在 90%–100%,recall 也处在较高区间;
-
相比之下,RoBERTa 分类器、GLTR、Stylistic、NELA 等方法要么精度低,要么召回明显不足。
-
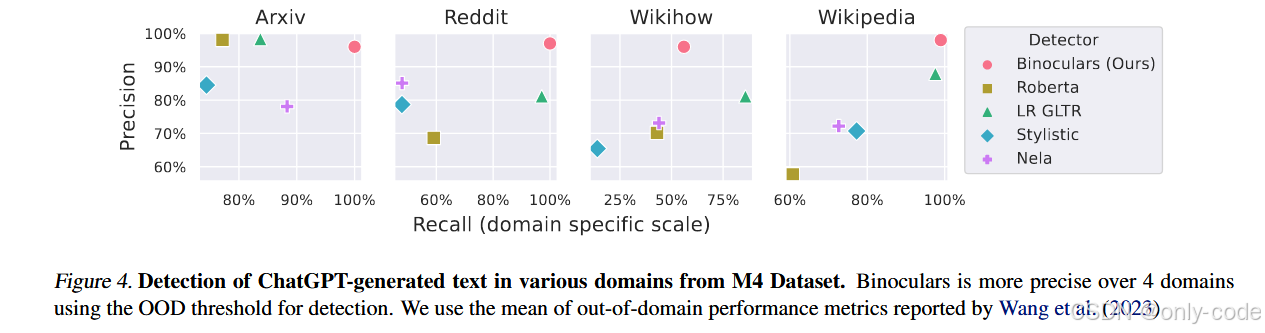
【插图:四个域上的 Precision–Recall 散点图,对应原文 Figure 4】
作者总结说:在不用任何 M4 训练数据的情况下,Binoculars 在大部分域上都能做到更高的精度,尤其适合作为“宁愿漏检也不轻易误杀”的第一道筛选器。
7.5 低资源语言与非母语写作者:公平性视角
7.5.1 低资源语言
在阿拉伯语、俄语、保加利亚语、乌尔都语等语言上,结果有点不对称:
- Binoculars 的 precision 很高(误伤几乎为零);
- 但 recall 较低,很多机器文本被当成人类写作漏掉。

【插图:低资源语言上的 Precision–Recall 图,对应原文 Figure 6】
作者的解释也很合理:
- Falcon 系列在这些语言上的建模能力本身就一般;
- 这意味着“机器输出”和“人类输出”在 Falcon 眼中都显得很奇怪,自然难以区分。
这既是一个局限,也是一种“保守”:宁可放过机器,也不要错杀人类。
7.5.2 非母语英语写作者(ESL)
Liang 等人的工作曾指出,很多商业检测器(包括 GPTZero)严重偏向于把非母语英语写作者的作文误判为 AI 文本。
作者在 EssayForum 数据集上做了一个很漂亮的实验:
- 同一篇作文有原始版(带各种语法错误)和语法纠正版;
- 分别算出 Binoculars score 的分布。
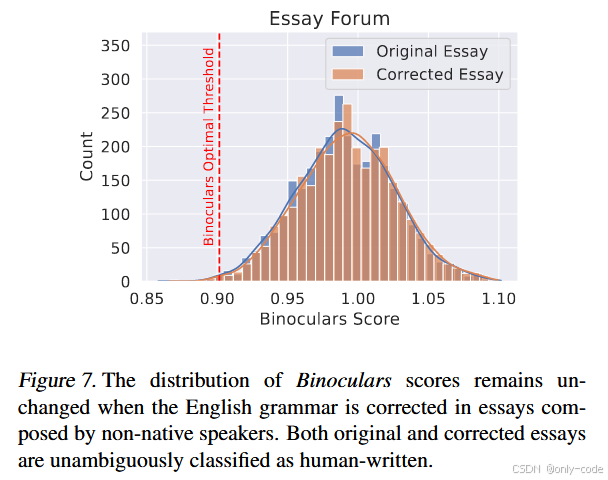
【插图:ESL 原始 vs 纠正作文的 score 分布直方图,对应原文 Figure 7】
结果非常干脆:
- 两种版本的分布几乎完全重合,
- 都远远落在“人类写作”一侧,
- 分类正确率高达 99.67%,对语法是否标准几乎不敏感。
这意味着:Binoculars 基本不会因为写作“有点像机器(太规范)”就把非母语作者冤枉成 AI,在公平性上明显优于许多已有检测器。
7.6 记忆文本与随机序列:极端情况的行为
7.6.1 强记忆文本
作者选取了 11 段极有可能被 LLM 完全背下来的文本,包括:
- 美国宪法、马丁·路德·金 “I have a dream”、Cosmos 文本片段、名著段落、Bob Dylan 歌曲等。
结果:
- 宪法和几段非常著名的文本得到的 Binoculars score 接近 0.76–0.85,被判为“机器”;
- 其余大部分文本(包括一些并不广为流传的歌)仍被判为“人类”。
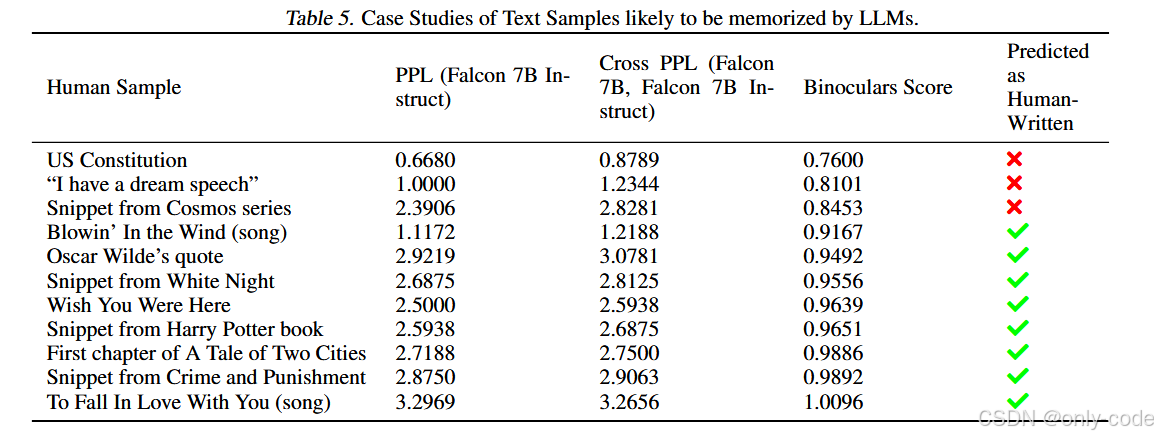
【插图:著名文本的 PPL / X-PPL / Binoculars score 表,对应原文 Table 5】
作者的态度也很坦诚:
从“谁更可能写出这一段”的角度看,某些经典语句确实更像 LLM 输出,这种行为对查重类场景甚至是有益的;但在其他场景(比如只想过滤训练数据中的机器文本)就需要谨慎。
7.6.2 随机 token 序列
当输入是完全随机采样的 token 序列时,Binoculars 的 score 反而 远大于阈值,被非常自信地判为“人类”。
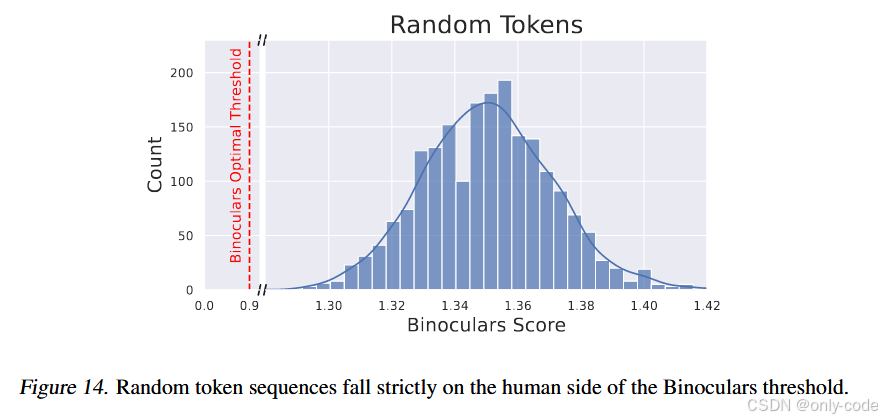
【插图:随机 token 的 score 直方图,对应原文 Figure 14】
这其实很好理解:
- 随机序列在任何 LLM 看来都极其不自然;
- 无论是 PPL 还是 X-PPL 都极高,
- 但从“谁更可能写出这种鬼东西”的角度,人类胡乱敲键盘的可能性明显更高,LLM 几乎不可能生成这种串。
所以 Binoculars 把它归为“人类”是符合直觉的,也再次说明:这个检测器的目标是“机器文本检测器”,而不是“人类文本检测器”。
7.7 Prompt 风格攻击:让模型装成“海盗”有没有用?
利用 OpenOrca 指令数据集,作者还实验了多种系统 prompt:
- 正常风格;
- 模仿 Carl Sagan 的文风;
- 禁止使用“机械/逻辑”等词,要求写得像普通人;
- 要求像海盗一样说话。
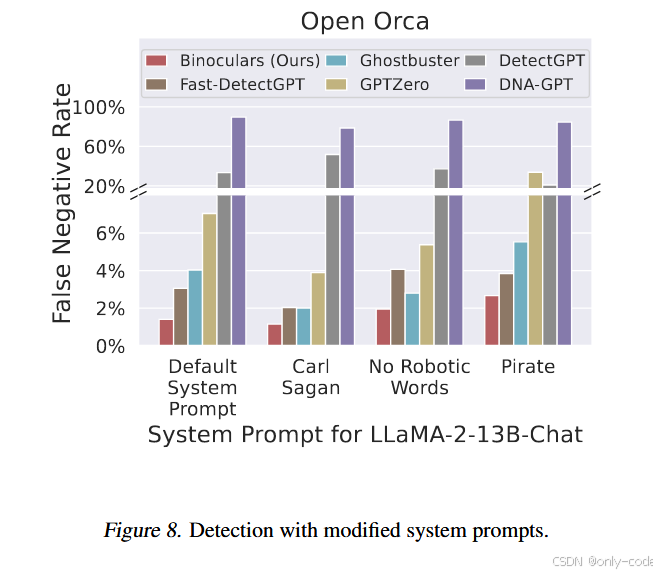
【插图:不同系统 prompt 下的误检率条形图,对应原文 Figure 8】
结果非常有趣:
- 对 Binoculars 来说,这些风格修改几乎不会改变检测性能;
- 只有“海盗风格”会让 false negative rate 上升约 1 个百分点;
- 其他统计方法在某些风格下会出现明显退化。
这说明:简单地调 prompt 风格,并不能轻易骗过 Binoculars。
7.8 GPT-4 与 Gemini-Pro:最新 API 的检测情况
作者还在 OpenOrca 指令上分别用 GPT-4 和 Gemini-1.0-Pro 生成文本,测试 Binoculars 的 false negative rate:

【插图:GPT-4 与 Gemini-Pro 的误检率表】
-
对 Gemini-Pro:
-
检测准确率约 96.9%,
-
false negative rate 约 3.1%。
-
-
对 GPT-4:
-
准确率约 41.9%,
-
false negative rate 高达 58.1%。
-
换句话说:在当前配置下,Binoculars 对 GPT-4 的检测明显吃力,而对 Gemini 这一代模型仍然相当有效。这也直接暴露了方法的一个现实局限(后面会展开)。
8. 亮点与创新点总结
通篇看下来,Binoculars 最让我印象深刻的有这么几件事:
第一,它真正做到了“零样本 + 多模型 + 高精度”三件事同时成立。
传统训练型检测器通常在自己训练的目标模型上很强,但一旦换模型就会崩溃。Binoculars 则通过一个极简的 perplexity 比值,在 ChatGPT、LLaMA、Falcon、Gemini 等模型上都取得了不错甚至 SOTA 的结果。
第二,它把“水豚问题”讲透了,也给出了优雅的解决方案。
很多人都直觉知道“只看 perplexity 不够”,但这篇论文用一个非常具体的例子(天文学家水豚)和一个自然的数理构造(perplexity / cross-perplexity),让这个问题从“直觉上的尴尬”变成了“公式上的洞察”。
第三,它非常认真地对待“公平性”和“极端情况”。
从非母语写作者到低资源语言,从名句记忆到随机 token 序列,作者都给出了清晰的实验和解释。这使得 Binoculars 作为实际部署候选时,优缺点是透明的,而不是只拿一条 ROC 曲线就草草了事。
第四,它是一个非常“可拓展”的范式。
论文里不仅用 Falcon 组合,还测试了多种 LLaMA 组合、不同指令微调阶段的 performer 模型。随着更强、更多语言覆盖的开源模型出现,可以在不改框架的前提下,替换 M₁、M₂ 得到更强、更公平的检测器。
9. 局限性与不足
论文的讨论部分已经很诚实了,这里再结合结果稍微挑剔一下。
-
对强模型(尤其是 GPT-4)的检测明显不足。
在 OpenOrca 上,Binoculars 对 GPT-4 的 false negative rate 超过 50%。这说明:
- 当生成模型的表达能力、分布多样性进一步逼近人类时,
- 仅靠“和 Falcon 系列的共识度”区分机器与人已经远远不够。
未来可能需要 更强、更接近 GPT-4 的开源模型作为观察者 / 表演者,或者引入额外信号。 -
高度依赖“模型家族相似性”的假设。
Binoculars 的核心假设是:M₁、M₂ 彼此比它们与人类更相似。如果出现一类风格完全不同、训练数据完全不重叠的 LLM,那么这个假设可能被打破。
换言之:Binoculars 在“现有主流 LLM 生态(CommonCrawl + Transformer)”下工作得很好,但对未来架构也许没有保证。 -
多语言能力受限于基模型。
在低资源语言上表现出的“高精度、低召回”本质上是 Falcon 自身语言能力的反映。
从产品角度看,这意味着:
- 想要在多语言环境中使用 Binoculars,需要选择更强的多语言开源模型作为基础;
- 否则,可能在某些语言上几乎无法捕捉机器生成。 -
对记忆文本的“机器化倾向”是双刃剑。
将美国宪法等文本判为“机器”在某些场景是合理的(比如查重:确实应该提示“你在大段引用已知文本”),但在只关心“是不是 LLM 写的”的场景中,却可能带来误伤。
这提示我们:Binoculars 的输出需要结合业务语境解释,而不是作为“是否作弊”的唯一裁决依据。 -
复杂度和延迟:需要两次大模型前向。
虽然不需要训练,但每次检测要跑两次 7B 模型,对大规模平台(比如社交网络级别)来说仍然是显著成本。
论文没有深入讨论压缩 / 蒸馏方案,这是未来工程化需要补的环节。 -
对有针对性的对抗攻击尚未系统讨论。
作者明确说明:他们只关注“自然使用场景下的机器文本”,没有保证面对刻意绕过检测的攻击(例如多次 paraphrase、插入特定噪声)的表现。
考虑到已有工作证明 paraphrasing 能显著破坏包括 DetectGPT 在内的检测器,这同样是 Binoculars 的潜在弱点,需要后续研究。
10. 全文总结:三分钟回顾 Binoculars 的精髓
如果把整篇论文压缩成几个关键点,我会这样讲:
第一,问题是什么?
在一个多模型、黑盒的世界里,我们需要一种 不依赖训练样本、能在极低误伤率下识别 LLM 文本的检测器,还要尽量避免对非母语写作者等群体的偏见。
第二,Binoculars 怎么做?
它让两只相似的语言模型(观察者 M₁ 与表演者 M₂)“同时看”同一段文本:
- 用 M₁ 算文本的 perplexity;
- 用 M₂ 预测下一 token,再让 M₁ 对这些预测分布算 cross-perplexity;
- 用 B = log PPL / log X-PPL 作为检测分数。
这个比值天然解决了“水豚问题”,在不同 prompt、不同主题下都保持稳定。
第三,核心贡献和实证支持是什么?
在 News、Creative Writing、Student Essay 等数据集上,Binoculars 在 0.01% FPR 下对 ChatGPT 文本的 TPR 超过 90%,在 LLaMA、Falcon、Gemini 文本上同样表现优异。多语言、多域、ESL、记忆文本、随机序列等一系列实验展示了它在鲁棒性、公平性上的优点和边界。
第四,这篇论文改变了什么观念?
它告诉我们:
- LLM 检测不一定非得大量标注训练,巧妙利用现成模型的统计结构就能走很远;
- 评估检测器时,要把目光从漂亮的 AUC 转向极低 FPR 下的表现;
- 对检测器而言,“公平性”和“解释清晰的失败模式”同样重要。
Binoculars 不是在问“这段话像不像人写的”,而是在问“在今天这个 LLM 生态里,这段话更像是谁写的?”——而在绝大多数我们关心的场景里,这个问题,比前者现实得多。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)