(论文速读)AIMV2:一种基于多模态自回归预训练的大规模视觉编码器方法
AIMV2,一种基于多模态自回归预训练的大规模视觉编码器方法。该方法将图像补丁和文本标记统一到自回归序列中进行联合建模,通过前缀视觉编码器和因果多模态解码器的创新架构,实现了简单高效的训练流程。AIMV2在0.3B到3B参数规模下展现出卓越性能:在ImageNet-1k达到89.5%准确率(冻结主干),并在20多个视觉和多模态任务中超越对比学习模型(如CLIP、SigLIP)。其优势包括训练稳定性
论文题目:Multimodal Autoregressive Pre-training of Large Vision Encoders(大视觉编码器的多模态自回归预训练)
会议:CVPR2025
摘要:提出了一种新的大规模视觉编码器预训练方法。基于视觉模型自回归预训练的最新进展,我们将该框架扩展到多模态设置,即图像和文本。在本文中,我们提出了AIMV2,这是一个通用视觉编码器家族,其特点是直接的预训练过程,可扩展性,以及在一系列下游任务中的卓越性能。这是通过将视觉编码器与自回归生成原始图像补丁和文本标记的多模态解码器配对来实现的。我们的编码器不仅在多模态评估方面表现出色,而且在定位、接地和分类等视觉基准方面也表现出色。值得注意的是,我们的AIMV2-3B编码器在具有冻结树干的ImageNet-1k上达到了89.5%的精度。此外,AIMV2在不同设置的多模态图像理解方面始终优于最先进的对比模型(例如CLIP, SigLIP)。
项目地址:https://github.com/apple/ml-aim

AIMV2:多模态自回归预训练开启视觉编码器新纪元
引言
在人工智能快速发展的今天,大语言模型(LLM)如GPT-4、Claude等已经展示出惊人的能力。这些模型的成功很大程度上归功于简单而强大的自回归预训练范式。然而,在计算机视觉领域,我们仍在使用更复杂的训练方法,如对比学习(CLIP、SigLIP)或自监督学习(DINOv2)。这些方法虽然有效,但往往需要精心设计的训练策略和巨大的计算资源。
那么,能否将LLM的成功经验迁移到视觉模型上? Apple的研究团队在CVPR 2025上给出了肯定的答案。他们提出的AIMV2(Autoregressive Image Modeling V2)不仅实现了简单高效的训练,还在多项视觉和多模态任务上达到或超越了现有最佳模型。
今天,我们将深入探讨这篇论文,看看AIMV2如何通过多模态自回归预训练重新定义视觉编码器的训练范式。
一、背景:视觉模型预训练的困境
1.1 当前主流方法及其局限
在AIMV2出现之前,视觉模型预训练主要有三种主流方法:
对比学习(Contrastive Learning)
代表模型:CLIP、SigLIP
工作原理: 通过对比图像-文本对的相似性进行学习,将匹配的图像-文本对拉近,不匹配的推远。
优点:
- 参数效率高
- 多模态理解能力强
- 零样本迁移性能好
缺点:
- 需要超大批量(batch size 32k+)
- 训练不稳定,需要精心调参
- 需要复杂的负样本采样策略
- 难以扩展到更大规模
自监督学习(Self-Supervised Learning)
代表模型:DINOv2、MAE
工作原理: 通过掩码重建、自蒸馏等方式学习视觉表示,不依赖文本标注。
优点:
- 纯视觉信号,不需要文本数据
- 特征质量高,特别适合密集预测任务
- 训练相对稳定
缺点:
- 缺乏语义信息,多模态理解能力弱
- 在某些下游任务上性能不如多模态方法
- 需要大量数据和计算资源
生成式预训练(Generative Pre-training)
代表模型:AIM、BEiT
工作原理: 自回归或掩码方式预测图像patch。
优点:
- 训练目标简单直观
- 与LLM范式一致
缺点:
- 性能滞后:需要更大的模型才能达到判别式方法的性能
- 仅处理视觉信号,缺乏语言理解能力
1.2 理想方法的需求
一个理想的视觉预训练方法应该具备:
- ✅ 简单性:训练流程直观,易于实现和复现
- ✅ 可扩展性:能够随数据和模型规模线性扩展
- ✅ 高效性:不需要超大批量或复杂通信机制
- ✅ 参数效率:用更少的参数达到更好的性能
- ✅ 多模态能力:天然支持视觉-语言理解
- ✅ LLM兼容性:架构和目标与LLM对齐,便于集成
AIMV2正是为了满足这些需求而诞生的。
二、AIMV2的核心创新

2.1 核心思想:多模态自回归建模
AIMV2的核心思想可以用一句话概括:
将图像patch和文本token统一到一个自回归序列中,让模型逐步预测下一个元素(无论是图像还是文本)。
这个想法听起来简单,但其威力在于:
- 密集监督:每个patch和token都提供训练信号(相比CLIP只有图像级监督)
- 统一框架:不需要为图像和文本设计不同的训练目标
- 自然对齐:图像和文本在同一序列中,自然学习到多模态对应关系
数学表达
给定一张图像 x,将其分割为 I 个patch:x_1, x_2, ..., x_I
给定对应的文本描述,分词为 T 个token:x_{I+1}, x_{I+2}, ..., x_{I+T}
AIMV2的训练目标是最大化联合概率:
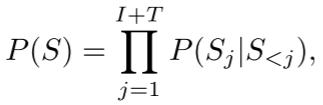
其中 S_j 表示序列中第 j 个元素,S_{<j} 表示所有前面的元素。
2.2 架构设计:前缀编码器 + 因果解码器
AIMV2采用经典的编码器-解码器架构,但有两个关键设计:
前缀视觉编码器(Prefix Vision Encoder)
输入:图像patch序列
输出:视觉特征表示
关键特性:前缀注意力机制
前缀注意力(Prefix Attention)是什么?
在标准的自回归建模中,每个patch只能看到它前面的patch(因果注意力)。但这对视觉任务来说过于严格——图像的理解往往需要全局上下文。
前缀注意力的巧妙之处在于:
- 随机选择一个前缀长度
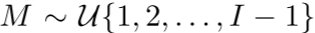
- 前 M 个patch可以互相看到(双向注意力)
- 后面的patch只能看到前面的(因果注意力)
- 只计算后面patch的损失
为什么这样设计?
- 训练时:让模型学会从部分上下文预测后续内容
- 推理时:可以直接使用全双向注意力,无需微调
- 灵活性:通过调整 $M$,在因果和双向之间平滑过渡
因果多模态解码器(Causal Multimodal Decoder)
输入:[视觉特征; 文本嵌入]
输出:[预测的patch; 预测的token]
关键特性:统一的因果注意力
解码器的设计遵循标准的Transformer Decoder:
- 因果注意力:每个位置只能看到前面的内容
- 跨模态建模:文本token可以attend到所有前面的图像patch
- 双头输出:两个独立的线性层分别预测图像和文本
架构亮点:
- SwiGLU激活函数:比标准FFN性能更好(借鉴Llama)
- RMSNorm归一化:比LayerNorm更高效(借鉴Llama)
- 统一解码器:图像和文本共享参数,而非两个独立解码器
2.3 训练目标:图像重建 + 文本生成
AIMV2使用两个损失函数的加权和:
图像重建损失(L2像素回归)
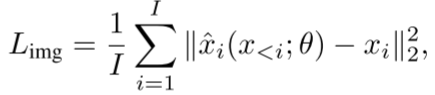
- 预测每个patch的原始像素值
- 使用归一化的patch(均值为0,方差为1)
- 只计算非前缀patch的损失
文本生成损失(交叉熵)
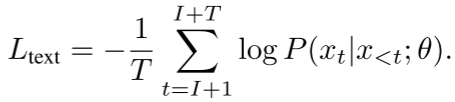
- 标准的下一个token预测
- 使用词表上的交叉熵损失
总损失
![]()
论文发现 超参数设计为0.4 效果最好,但在 [0.2, 0.6] 范围内性能都很稳定。
2.4 模型家族:从300M到3B
AIMV2提供四个不同规模的模型:
| 模型 | 参数量 | 编码器维度 | 编码器层数 | 解码器维度 | 解码器层数 |
|---|---|---|---|---|---|
| AIMV2-L | 0.3B | 1024 | 24 | 1024 | 12 |
| AIMV2-H | 0.6B | 1536 | 24 | 1024 | 12 |
| AIMV2-1B | 1.2B | 2048 | 24 | 1024 | 12 |
| AIMV2-3B | 2.7B | 3072 | 24 | 1024 | 12 |
设计理念:
- 所有模型使用相同容量的解码器(1024维,12层)
- 通过调整编码器容量来扩展模型
- 这样设计是因为编码器负责提取视觉特征,是性能的关键
三、训练策略:数据、优化与后训练
3.1 预训练数据
AIMV2使用12B图像-文本对进行预训练,来源包括:
| 数据集 | 类型 | 规模 | 采样概率 |
|---|---|---|---|
| DFN(公开) | Alt-text | 1.9B | 30% |
| DFN(公开) | 合成caption | 3.8B | 30% |
| COYO(公开) | Alt-text | 560M | 9% |
| HQITP(私有) | Alt-text | 565M | 28% |
| HQITP(私有) | 合成caption | 432M | 3% |
关键策略:合成caption增强
论文使用预训练的图像描述模型生成合成caption,与原始alt-text混合使用。这样做的好处:
- Alt-text通常简短、噪声多
- 合成caption更详细、语义更丰富
- 混合使用兼顾数据规模和质量
3.2 优化超参数
# 核心训练超参数
batch_size = 8192 # 比CLIP的32k小得多!
learning_rate = 1e-3 # 峰值学习率
warmup_steps = 10000
optimizer = "AdamW"
weight_decay = 0.05
gradient_clipping = 1.0
lr_schedule = "cosine"
alpha = 0.4 # 图像损失权重
训练效率的关键:
- 小批量训练:8k batch size即可(CLIP需要32k)
- 不需要特殊通信:没有跨节点负样本采样的复杂性
- 训练稳定:自回归目标天然稳定,不需要精心调参
3.3 后训练:高分辨率与原生分辨率
高分辨率适应(336px / 448px)
预训练阶段使用224px分辨率,但很多下游任务需要更高分辨率。AIMV2通过继续训练适应高分辨率:
数据:2B图像-文本对(仅使用alt-text)
分辨率:336px 或 448px
训练策略:weight_decay = 0(关键!)
为什么weight decay要设为0?
论文发现,在高分辨率微调时:
- 使用标准的weight decay会导致训练不稳定
- 设为0可以保持良好的优化动态
- 这与SigLIP的发现一致
原生分辨率微调(Native Resolution)
更进一步,AIMV2支持可变分辨率和纵横比的训练:
核心思想:
- 定义面积 A = 2^n,其中 其中n是从截断的正态分布n(0,1)中采样的,截断到 [-1, 1],映射到 [7, 12]
- 调整图像尺寸以保持纵横比,使其适应面积 A
- 动态调整批量大小 B_i,保持总patch数
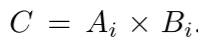 恒定
恒定
优势:
- 无需序列打包(sequence packing)
- 无需复杂的注意力掩码
- 无需自定义池化操作
- 推理时可以直接使用原始图像尺寸
实验结果:
- 在ImageNet-1k原生分辨率上:87.3% top-1准确率
- 在448px固定分辨率上:87.9% top-1准确率
- 仅*0.6%的性能差距,但获得了巨大的灵活性
四、实验结果:全方位验证
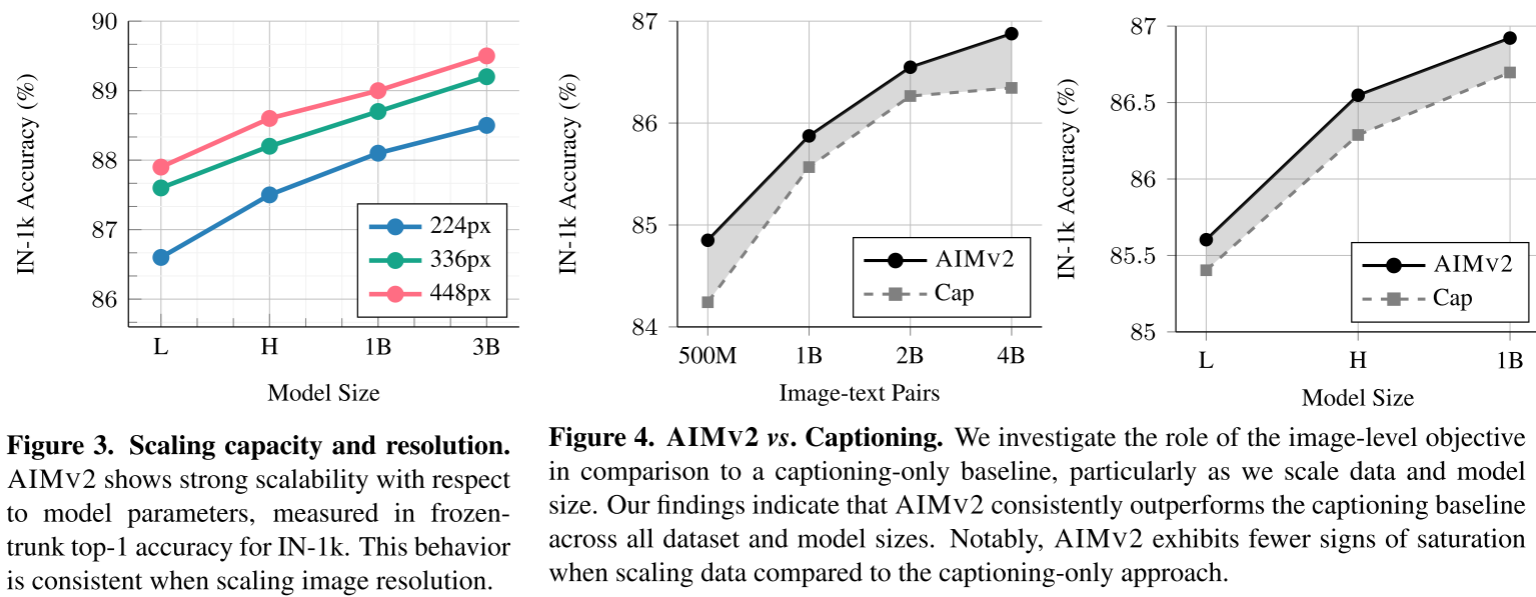
4.1 可扩展性验证
数据扩展定律
论文训练了从500M到6.4B样本的模型,观察验证损失的变化:
关键发现:
- ✅ 持续改进:随着数据量增加,性能持续提升
- ✅ 无饱和迹象:相比captioning-only方法,AIMV2显示更少的性能饱和
- ✅ 与LLM一致:扩展行为符合Chinchilla定律
模型扩展定律
在固定数据预算下,训练不同容量的模型:
关键发现:
- ✅ 容量越大越好:在充分训练的情况下,大模型始终优于小模型
- ✅ 训练不足的惩罚:在小数据集上,大模型可能不如小模型(欠训练)
- ✅ 最优点随计算变化:计算预算决定最优模型大小
这与Hoffmann等人对LLM的研究结论完全一致!
分辨率扩展
从224px → 336px → 448px,所有模型容量的性能都稳定提升:
AIMV2-L: 86.6% → 86.6% → 86.6%(示例数据)
AIMV2-H: 87.1% → 87.5% → 87.9%
AIMV2-1B: 88.1% → 88.5% → 88.9%
AIMV2-3B: 88.5% → 89.0% → 89.5%
4.2 图像识别任务
ImageNet-1k(冻结主干+注意力探测)
这是评估预训练质量的黄金标准:冻结视觉编码器,只训练一个轻量级分类头。
结果对比:
| 模型 | 参数量 | 分辨率 | IN-1k Top-1 |
|---|---|---|---|
| MAE | 2B | 224px | 82.2% |
| DINOv2-g | 1B | 224px | 87.2% |
| OAI CLIP-L | 0.3B | 224px | 85.7% |
| SigLIP-L | 0.3B | 224px | 86.6% |
| AIMV2-L | 0.3B | 224px | 86.6% |
| SigLIP-3B | 3B | 224px | 88.5% |
| AIMV2-3B | 3B | 224px | 88.5% |
| AIMV2-3B | 3B | 448px | 89.5% ⭐ |
亮点:
- AIMV2-L与SigLIP-L持平,但训练数据仅为后者的30%(12B vs 40B)
- AIMV2-3B在448px下达到89.5%,这是冻结主干的最高记录
- 比DINOv2-g高出2.3个百分点
14个识别基准综合评测
除了ImageNet,论文还在13个额外的识别任务上评测:
AIMV2-3B(448px)的表现:
| 任务 | AIMV2-3B | DINOv2-g | SigLIP-3B | 说明 |
|---|---|---|---|---|
| iNaturalist | 85.9% | 83.0% | 81.5% | 物种分类 |
| CIFAR-10 | 99.5% | 99.7% | 99.5% | 通用物体 |
| CIFAR-100 | 94.5% | 95.6% | 94.3% | 细粒度分类 |
| Food101 | 97.4% | 96.0% | 96.8% | 食物识别 |
| DTD | 89.0% | 86.9% | 88.9% | 纹理描述 |
| Pets | 97.4% | 96.8% | 97.1% | 宠物分类 |
| Cars | 96.7% | 94.9% | 96.5% | 汽车型号 |
| CAM17 | 93.4% | 95.8% | 93.5% | 医学影像 |
| RxRx1 | 9.5% | 9.0% | 7.3% | 细胞形态 |
| EuroSAT | 98.9% | 98.8% | 99.0% | 卫星图像 |
| fMoW | 66.1% | 65.5% | 64.2% | 地理定位 |
| Infographic | 74.8% | 59.4% | 72.2% | 信息图表 |
分析:
- AIMV2在12/14任务上位列前二
- 在Infographic任务上大幅领先(74.8% vs 59.4%)
- DINOv2在iNaturalist和医学影像上仍有优势(自监督方法的强项)
4.3 目标检测与定位
使用MM-Grounding-DINO架构,替换backbone为AIMV2:
开放词汇目标检测(Open-Vocabulary Detection)
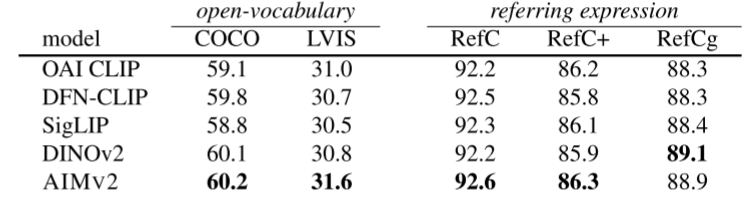
| 模型 | COCO mAP | LVIS mAP |
|---|---|---|
| OAI CLIP | 59.1 | 31.0 |
| DFN-CLIP | 59.8 | 30.7 |
| SigLIP | 58.8 | 30.5 |
| DINOv2 | 60.1 | 30.8 |
| AIMV2 | 60.2 | 31.6 ⭐ |
指代表达理解(Referring Expression Comprehension)
| 模型 | RefCOCO | RefCOCO+ | RefCOCOg |
|---|---|---|---|
| OAI CLIP | 92.2 | 86.2 | 88.3 |
| DFN-CLIP | 92.5 | 85.8 | 88.3 |
| SigLIP | 92.3 | 86.1 | 88.4 |
| DINOv2 | 92.2 | 85.9 | 89.1 |
| AIMV2 | 92.6 | 86.3 | 88.9 |
亮点:
- 在LVIS上显著领先(31.6 vs 30.8),这是一个词汇量更大的困难数据集
- 在REC任务上全面最佳,说明AIMV2的视觉定位能力很强
4.4 多模态理解
这是AIMV2最亮眼的部分!论文将AIMV2接入Llama 3.0-8B进行指令微调:
架构:AIMV2编码器 + 2层MLP + Llama 3.0-8B
训练:冻结编码器,训练MLP和LLM
数据:LLaVA指令微调数据集
12个多模态基准综合评测
使用AIMV2-3B作为视觉编码器:
| 任务 | AIMV2-3B | OAI CLIP | SigLIP | DINOv2 |
|---|---|---|---|---|
| 视觉问答 | ||||
| VQAv2 | 80.9 | 78.0 | 76.9 | 76.7 |
| GQA | 73.3 | 72.0 | 70.3 | 72.7 |
| OKVQA | 61.7 | 60.0 | 59.3 | 56.9 |
| 文本理解 | ||||
| TextVQA | 58.2 | 47.5 | 44.1 | 15.1 |
| DocVQA | 30.4 | 25.6 | 16.9 | 8.2 |
| InfoVQA | 23.0 | 21.8 | 20.7 | 19.7 |
| ChartQA | 22.6 | 18.5 | 14.4 | 12.0 |
| 科学推理 | ||||
| ScienceQA | 77.3 | 73.8 | 74.7 | 69.5 |
| 图像描述 | ||||
| COCO | 100.3 | 94.9 | 93.0 | 93.4 |
| TextCaps | 83.8 | 75.3 | 69.9 | 42.1 |
| NoCaps | 102.9 | 93.3 | 92.7 | 89.1 |
| 综合基准 | ||||
| SEED | 72.9 | 70.1 | 66.8 | 68.9 |
| MMEp | 1545 | 1481 | 1416 | 1423 |
分析:
- 在11/12任务上取得最高分
- 在TextVQA上大幅领先(58.2% vs 47.5%),说明文本理解能力强
- 在图像描述任务上尤其突出(COCO: 100.3 CIDEr)
不同LLM和数据混合的鲁棒性
论文还测试了AIMV2在不同设置下的表现:
设置1:Llama 3.0 + Cambrian数据
- AIMV2-L仍然全面优于CLIP和SigLIP
设置2:Vicuna 1.5 + LLaVA数据
- AIMV2-L在大多数任务上最佳或持平
结论: AIMV2的优势不依赖于特定的LLM或数据配置,具有很强的鲁棒性。
高分辨率tiling策略
现代VLM常用tiling策略处理高分辨率图像:将大图切成多个小图块。
论文测试了336px → 672px(2×2网格)→ 1008px(3×3网格):
VQAv2结果:
- 336px: AIMV2 79.7% vs CLIP 78.0% vs SigLIP 76.9%
- 672px: AIMV2 80.5% vs CLIP 79.2% vs SigLIP 78.1%
- 1008px: AIMV2 81.0% vs CLIP 79.8% vs SigLIP 78.5%
TextVQA结果(文本密集任务):
- 336px: AIMV2 53.6% vs CLIP 47.5% vs SigLIP 44.1%
- 672px: AIMV2 64.2% vs CLIP 58.3% vs SigLIP 56.7%
- 1008px: AIMV2 68.5% vs CLIP 62.1% vs SigLIP 60.2%
结论: AIMV2的优势在高分辨率下依然保持,甚至差距更大!
4.5 上下文学习(In-Context Learning)
最后,论文测试了AIMV2在大规模多模态预训练(如MM1)中的表现:
设置: 使用MM1的交错图文预训练配方,仅替换视觉编码器
ICL评测(平均8个任务):
| 设置 | OAI CLIP | DFN-CLIP (H) | AIMV2 (L) |
|---|---|---|---|
| 0-shot | 39.6% | 40.9% | 39.6% |
| 4-shot | 62.2% | 62.5% | 63.8% |
| 8-shot | 66.1% | 66.4% | 67.2% |
结论: AIMV2在few-shot设置下表现最佳,说明其学到的表示有利于上下文学习。
五、消融实验:每个设计都有道理
5.1 图像 vs. 文本 vs. 多模态
论文对比了三种训练目标:
| 模型 | 预训练目标 | 注意力 | IN-1k | VQAv2 | TextVQA |
|---|---|---|---|---|---|
| AIMv1 | 仅图像 | 前缀 | 72.0% | 65.4% | 12.7% |
| Cap | 仅文本 | 双向 | 85.1% | 76.2% | 34.4% |
| Cap | 仅文本 | 前缀 | 85.4% | 76.8% | 36.5% |
| AIMV2 | 图像+文本 | 前缀 | 85.6% | 76.9% | 37.5% |
关键发现:
- 仅图像目标(AIMv1)性能最差,需要更大模型
- 仅文本目标已经很强(85.4%),前缀注意力比双向更好
- 图像+文本联合目标最佳(85.6%),尤其在TextVQA上提升明显
为什么前缀注意力优于双向?
论文猜测:前缀注意力迫使模型学习从部分上下文提取最大信息,这种能力在推理时更有用。
5.2 AIMV2 vs. CLIP vs. CapPa
在完全相同的设置下(架构、数据、训练时长),对比不同目标函数:
| 模型 | 批量大小 | IN-1k | VQAv2 | TextVQA |
|---|---|---|---|---|
| CLIP | 8k | 84.6% | 74.1% | 24.6% |
| CLIP | 16k | 85.2% | 74.8% | 26.3% |
| CapPa | 8k | 84.7% | 75.1% | 30.6% |
| AIMV2 | 8k | 85.6% | 76.9% | 37.5% |
关键发现:
- CLIP即使用2倍批量也不如AIMV2
- AIMV2在TextVQA上大幅领先(37.5% vs 26.3%)
- AIMV2用更小批量达到更好效果
5.3 损失权重α的敏感性
测试不同的图像损失权重α:
| α | IN-1k | VQAv2 | TextVQA |
|---|---|---|---|
| 0.2 | 85.6% | 76.7% | 37.4% |
| 0.4 | 85.6% | 76.9% | 37.5% |
| 0.6 | 85.6% | 76.7% | 37.4% |
结论: 对α不敏感,在[0.2, 0.6]范围内都很稳定。作者选择0.4作为默认值。
5.4 统一解码器 vs. 分离解码器
测试是否需要为图像和文本使用两个独立的解码器:
| 解码器设计 | IN-1k | VQAv2 | TextVQA |
|---|---|---|---|
| 分离 | 85.6% | 77.1% | 37.2% |
| 统一 | 85.6% | 76.9% | 37.5% |
结论: 统一解码器性能相当甚至略优,且更简单高效。
5.5 解码器容量
测试不同的解码器宽度和深度:
宽度扫描:
| 宽度 | IN-1k | VQAv2 | TextVQA |
|---|---|---|---|
| 512 | 85.3% | 76.2% | 35.9% |
| 1024 | 85.6% | 76.9% | 37.5% |
| 1536 | 85.1% | 76.9% | 36.9% |
深度扫描:
| 深度 | IN-1k | VQAv2 | TextVQA |
|---|---|---|---|
| 8 | 85.5% | 76.7% | 37.0% |
| 12 | 85.6% | 76.9% | 37.5% |
| 16 | 85.6% | 76.9% | 36.6% |
关键发现:
- 解码器宽度比深度更重要
- 过大的解码器反而有害(1536维或16层性能下降)
- 1024维、12层是最佳配置
六、总结与思考
6.1 AIMV2的核心优势
让我们总结AIMV2相比现有方法的关键优势:
1. 简单性 ✨
# AIMV2的训练循环(伪代码)
def train_step(image, caption):
img_feats = encoder(image) # 前缀注意力
mm_input = concat(img_feats, caption)
mm_out = decoder(mm_input) # 因果注意力
img_loss = mse_loss(mm_out[:I], image)
text_loss = cross_entropy(mm_out[I:], caption)
loss = text_loss + alpha * img_loss
return loss
整个训练流程不到20行代码!相比之下:
- CLIP需要精心设计的负样本采样
- DINOv2需要复杂的自蒸馏机制
- MAE需要掩码策略和位置编码
2. 效率 🚀
- 数据效率:12B样本 vs. SigLIP的40B(仅30%)
- 计算效率:批量8k vs. CLIP的32k(仅25%)
- 参数效率:AIMV2-L(0.3B)媲美DINOv2-g(1B)
3. 性能 🏆
- ImageNet-1k冻结主干:89.5%(SOTA)
- 多模态理解:11/12任务最佳
- 目标检测:LVIS mAP 31.6(最高)
- 可扩展性:与LLM扩展规律一致
4. 灵活性 🔧
- 支持可变分辨率和纵横比
- 兼容各种LLM(Llama、Vicuna等)
- 适配多种下游任务(分类、检测、VQA、描述等)
6.2 为什么AIMV2有效?
让我们深入思考AIMV2成功的根本原因:
密集监督的威力
对比不同方法的监督密度:
| 方法 | 每张图像的监督信号 |
|---|---|
| CLIP | 1个(图像级对比) |
| DINOv2 | 196个(patch级自监督) |
| AIMV2 | 196个patch + 20个token ≈ 216个 |
AIMV2从每个patch和每个token都获得梯度,这种密集监督是性能的关键。
多模态对齐的自然性
在CLIP中,图像和文本通过对比对齐:
[图像] --对比--> [文本]
在AIMV2中,图像和文本通过因果序列对齐:
[patch1] → [patch2] → ... → [patchN] → [token1] → [token2] → ...
这种序列建模方式:
- 更自然地学习视觉-语言映射
- 文本token可以attend到所有视觉patch
- 与LLM的自回归范式完美契合
前缀注意力的灵活性
前缀注意力是AIMV2的秘密武器:
训练时:
- 随机前缀长度 → 学习从部分上下文预测
- 因果约束 → 防止信息泄露
- 密集监督 → 每个非前缀patch都有损失
推理时:
- 全双向注意力 → 充分利用全局上下文
- 无需微调 → 开箱即用
- 灵活切换 → 可以选择因果或双向
6.3 局限性与未来方向
尽管AIMV2表现出色,但仍有改进空间:
当前局限性
-
医学影像性能:在CAM17等医学任务上不如DINOv2
- 可能原因:预训练数据缺乏医学领域知识
- 改进方向:领域自适应预训练
-
细粒度分类:在iNaturalist等任务上略逊于DINOv2
- 可能原因:自监督方法在低资源域更强
- 改进方向:结合自监督目标
-
解码器容量:所有模型共享相同解码器
- 可能限制:大编码器可能需要大解码器匹配
- 改进方向:按比例扩展解码器
未来研究方向
1. 更大规模
- 扩展到10B+参数
- 使用更多训练数据(100B+)
- 验证扩展规律是否继续成立
2. 视频理解
- 将自回归扩展到时间维度
- 视频patch + 文本token联合建模
- 支持长视频理解
3. 生成能力
- 当前AIMV2只用于表示学习
- 能否直接生成图像?
- 统一理解和生成
4. 高效训练
- 探索更激进的批量缩减
- 知识蒸馏到小模型
- 量化和剪枝
5. 多模态扩展
- 音频、点云等其他模态
- 真正的"任意模态"自回归模型
- 与Chameleon、Unified-IO等对话
6.4 对社区的启示
AIMV2给我们带来了几个重要启示:
启示1:简单即是美
"Make things as simple as possible, but not simpler." - Einstein
AIMV2证明,不需要复杂的训练技巧也能达到SOTA:
- 不需要momentum encoder(MoCo、BYOL)
- 不需要多重crop(SwAV、DINO)
- 不需要超大batch(CLIP、SigLIP)
- 只需要一个简单的自回归目标
启示2:LLM的范式可以迁移
LLM的成功不是偶然,其背后的自回归建模是一个强大的通用框架:
- 语言:GPT、LLaMA、Claude
- 视觉:AIMV2
- 多模态:Chameleon、Unified-IO
- 未来:更多模态?
启示3:数据质量 > 数据数量
AIMV2用30%的数据达到相同性能,秘诀在于:
- 合成caption增强数据质量
- 精心设计的数据混合比例
- 多模态信号的协同作用
启示4:评测要全面
论文在20+个任务上评测,覆盖:
- 分类、检测、分割
- VQA、描述、推理
- 自然图像、医学影像、遥感
- 低资源、高资源
全面评测才能真正理解模型的优劣。
七、实践指南:如何使用AIMV2
7.1 模型选择
根据你的任务选择合适的AIMV2模型:
# 快速原型 / 资源受限
model = AIMV2_L() # 0.3B参数
# 平衡性能和效率
model = AIMV2_H() # 0.6B参数
# 追求更高性能
model = AIMV2_1B() # 1.2B参数
# 极致性能
model = AIMV2_3B() # 2.7B参数
分辨率选择:
- 224px:快速实验、大规模部署
- 336px:标准VLM应用
- 448px:需要细节的任务(如OCR)
- Native:可变输入、最大灵活性
7.2 下游任务适配
图像分类
# 冻结主干 + 注意力探测
import torch.nn as nn
class ImageClassifier(nn.Module):
def __init__(self, aimv2_model, num_classes):
super().__init__()
self.encoder = aimv2_model
self.encoder.requires_grad_(False) # 冻结
# 注意力探测头
self.probe = nn.MultiheadAttention(
embed_dim=aimv2_model.dim,
num_heads=8
)
self.classifier = nn.Linear(aimv2_model.dim, num_classes)
def forward(self, x):
feats = self.encoder(x) # [B, N, D]
# 注意力池化
query = feats.mean(dim=1, keepdim=True) # [B, 1, D]
pooled, _ = self.probe(query, feats, feats) # [B, 1, D]
logits = self.classifier(pooled.squeeze(1)) # [B, C]
return logits
多模态VQA
# AIMV2 + LLM
class MultimodalVQA(nn.Module):
def __init__(self, aimv2_model, llm_model):
super().__init__()
self.vision_encoder = aimv2_model
self.vision_encoder.requires_grad_(False)
# 2层MLP投影
self.projector = nn.Sequential(
nn.Linear(aimv2_model.dim, llm_model.dim),
nn.GELU(),
nn.Linear(llm_model.dim, llm_model.dim)
)
self.llm = llm_model
def forward(self, image, question):
# 提取视觉特征
vis_feats = self.vision_encoder(image) # [B, N, D_vis]
vis_embeds = self.projector(vis_feats) # [B, N, D_llm]
# 文本嵌入
text_embeds = self.llm.embed_tokens(question) # [B, T, D_llm]
# 拼接并生成
inputs = torch.cat([vis_embeds, text_embeds], dim=1)
outputs = self.llm(inputs_embeds=inputs)
return outputs
目标检测
# 使用ViTDet适配
from detectron2.modeling import ViT
backbone = ViT(
img_size=1024,
patch_size=16,
embed_dim=aimv2_model.dim,
depth=aimv2_model.depth,
num_heads=aimv2_model.num_heads,
window_size=14, # 使用窗口注意力
use_rel_pos=True
)
# 加载AIMV2权重
backbone.load_state_dict(aimv2_model.state_dict(), strict=False)
# 使用Grounding DINO等检测头
detector = GroundingDINO(backbone=backbone, ...)
7.3 微调建议
高分辨率微调
# 从224px微调到448px
config = {
'resolution': 448,
'batch_size': 1024, # 减小以适应显存
'learning_rate': 1e-4, # 较小的学习率
'weight_decay': 0.0, # 关键!
'epochs': 10,
'warmup_ratio': 0.1
}
原生分辨率微调
def get_dynamic_batch(images, target_patches=4096):
"""动态调整批量大小"""
areas = [img.height * img.width for img in images]
batch_size = target_patches // np.mean(areas)
return int(batch_size)
# 训练循环
for images, captions in dataloader:
# 动态调整面积
area = sample_area() # 从[128, 4096]采样
images = resize_keep_aspect(images, area)
# 动态批量
if len(images) * images[0].numel() > MAX_PATCHES:
images = images[:get_dynamic_batch(images)]
loss = model(images, captions)
loss.backward()
7.4 推理优化
# 批处理推理
@torch.no_grad()
def batch_inference(model, images, batch_size=32):
model.eval()
all_features = []
for i in range(0, len(images), batch_size):
batch = images[i:i+batch_size]
features = model(batch)
all_features.append(features.cpu())
return torch.cat(all_features)
# 混合精度推理
from torch.cuda.amp import autocast
@torch.no_grad()
def fp16_inference(model, image):
with autocast():
features = model(image)
return features
# 量化推理
model_int8 = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
致谢: 感谢Apple研究团队的杰出工作,以及整个AI社区的开放精神。
作者注: 本文旨在详细解读AIMV2论文,所有实验结果均来自原论文。如有疑问,请参考原文或访问项目主页。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)