10-大模型评估的标准化方法与工具
大模型评估的标准化方法与工具是衡量模型性能的"标尺",更是推动技术迭代和创新的重要基石。通过这些方法和工具的应用,可以有效提升模型的可靠性和实用性,为人工智能技术的广泛应用和持续发展奠定坚实基础。

引言
随着人工智能技术的迅猛发展,大型模型(如GPT-3、BERT等)在自然语言处理、图像识别等多个领域展现出强大的能力。然而,如何科学、系统地评估这些模型的性能,成为了一个亟待解决的问题。大模型评估的标准化方法与工具应运而生,旨在为业界提供一套统一的评估标准和高效的评估工具。
标准化评估方法与工具的重要性不言而喻。首先,它们能够确保不同模型之间的性能比较具有公平性和可比性,避免了因评估标准不统一而导致的结论偏差。其次,标准化的评估流程可以提高评估效率,减少重复劳动,促进资源的合理配置。此外,通过标准化的工具,研究人员可以更便捷地复现和验证他人的研究成果,推动学术交流和技术的进步。
核心价值:大模型评估的标准化方法与工具是衡量模型性能的"标尺",更是推动技术迭代和创新的重要基石。通过这些方法和工具的应用,可以有效提升模型的可靠性和实用性,为人工智能技术的广泛应用和持续发展奠定坚实基础。
历史背景
大模型评估的标准化方法与工具的发展历程可以追溯到人工智能技术的早期阶段。20世纪50年代,随着人工智能研究的兴起,研究者们开始意识到需要一个统一的评估框架来衡量不同模型的性能。最初,这些评估方法主要依赖于简单的统计指标和人工评审,缺乏系统性和标准化。
进入20世纪80年代,随着机器学习和自然语言处理技术的迅猛发展,模型评估的需求变得更加迫切。1983年,美国国家标准与技术研究院(NIST)推出了首个广泛认可的评估工具——TREC(Text Retrieval Conference),标志着大模型评估标准化进程的重要里程碑。TREC通过一系列标准化的测试集和评估指标,为信息检索领域的模型性能提供了客观的衡量标准。
21世纪初,随着深度学习技术的突破,大模型的复杂性和多样性显著增加,传统的评估方法逐渐显得力不从心。2004年,国际语言评估会议(ILPC)提出了更为全面的评估框架,涵盖了准确性、鲁棒性、可解释性等多个维度,进一步推动了评估方法的标准化。
发展历程关键节点
- 20世纪50年代:人工智能研究兴起,开始意识到需要统一的评估框架
- 1983年:美国国家标准与技术研究院推出TREC,成为首个广泛认可的评估工具
- 2004年:国际语言评估会议提出全面评估框架,涵盖多维度评估指标
- 2018年:谷歌发布BERT,其评估工具和指标体系成为行业新标杆
- 近年:开源社区推出如Hugging Face的Model Hub等综合性评估平台
大模型评估的主要特点和挑战
大模型评估的主要特点
- 评估标准统一化:采用了一套统一的评估标准,确保不同大模型之间的性能可比性。这些标准涵盖了准确性、鲁棒性、泛化能力等多个维度,旨在全面衡量模型的综合表现。
- 工具功能多样化:提供的工具集不仅支持基本的模型性能测试,还具备数据集管理、模型调优、结果可视化等多种功能。用户可以通过这些工具进行全方位的模型评估,极大提升了评估效率。
- 性能指标全面性:不仅关注传统的准确率、召回率等指标,还引入了如计算效率、内存占用、能耗等新型指标,以适应不同应用场景的需求。
- 高度自动化:评估过程高度自动化,用户只需输入模型和相关数据,系统即可自动完成评估并生成详细的报告。这减少了人为干预,提高了评估结果的客观性和可靠性。
- 开放性与可扩展性:采用开源模式,支持第三方插件和自定义评估标准的接入,具有良好的开放性和可扩展性,能够适应不断变化的技术需求。
- 跨平台兼容性:工具设计考虑了跨平台兼容性,支持主流的操作系统和硬件架构,确保在不同环境下都能稳定运行。
大模型评估的挑战
- 数据多样性:大模型通常需要处理海量、复杂的数据,如何保证评估数据能够全面反映模型在实际应用场景中的表现,是一个重要挑战。
- 模型复杂性:大模型的结构和参数众多,对其进行全面评估需要考虑众多因素,如模型性能、泛化能力、鲁棒性等。
- 评估指标的选择:针对不同类型的大模型,需要选择合适的评估指标,以全面反映其性能和特点。
- 评估工具的局限性:现有的评估工具和方法可能无法完全满足大模型评估的需求,需要进一步研究和开发。
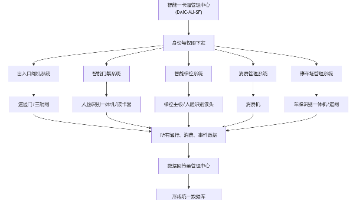
大模型评估的标准化方法和工具
大模型评估的标准化方法
- 数据集构建:构建具有代表性的数据集,涵盖各种类型、规模和难度的数据,以全面评估大模型在不同场景下的性能。
- 评估指标体系:针对不同类型的大模型,构建相应的评估指标体系,包括技术性能、安全能力、伦理合规等多个维度。
- 评估流程规范:制定统一的评估流程,包括数据准备、模型训练、评估指标计算、结果分析等环节,以确保评估过程的规范性和一致性。
- 评估结果的可解释性:对评估结果进行详细分析,解释模型性能的优缺点,为模型优化和改进提供依据。
大模型评估的指标
国家标准与评测指标
GB/T 45288.2-2025:这是中国首个针对大模型能力评估的国家标准,由国家市场监督管理总局与国家标准化管理委员会发布。该标准不仅明确了从技术性能到伦理安全的全维度评测框架,还详细规定了各维度的具体评测方法和标准,适用于模型提供者、应用服务者、应用消费者和政策制定者。
实际应用案例
- 案例一:某科技公司利用该标准对其自主研发的自然语言处理模型进行全面评估,发现并改进了模型在数据隐私保护方面的不足。
- 案例二:某金融机构应用该标准评估其风控模型,提升了模型的准确性和合规性。
评测指标体系:包括53个核心指标,涵盖基础技术能力(如语言理解与生成、逻辑推理)、安全能力和伦理合规等维度。例如,在语言理解与生成方面,具体指标包括BLEU分数、ROUGE分数等。
常用评估指标
- 准确率(Accuracy):模型预测正确的样本数占总样本数的比例。适用于多分类问题,但在不平衡数据集中可能存在误导。
- 精确率(Precision)与召回率(Recall):用于二分类问题,分别表示预测为正样本的实例中真正为正样本的比例和所有真正为正样本的实例中被正确预测的比例。在医疗诊断等领域尤为重要。
- F1分数(F1 Score):精确率和召回率的调和平均数,综合评估模型性能,特别适用于精确率和召回率同等重要的情况。
- ROC曲线与AUC值:通过绘制不同阈值下的真正率(TPR)与假正率(FPR)关系,展示模型的分类能力,广泛应用于金融风控等领域。
行业应用评估
- 2024年中国大模型行研能力年中评测:由沙利文和头豹研究院联合发布,评估大模型在行研领域的应用表现,涵盖报告撰写、行业理解和基础能力三方面。例如,评估模型在生成行业报告时的准确性和深度。
- 医疗领域应用评估:某医疗机构利用特定评估工具对其医疗诊断模型进行评估,提升了模型的诊断准确率和临床应用价值。
大模型评估的工具
- OpenCompass:一款开源的大模型评估工具,提供了丰富的数据集和预处理脚本,支持多种评估指标和评估策略,能够帮助开发者和研究者高效地评估大模型的性能。
- FullStackBench:字节跳动推出的一款代码大模型评估基准,包含超11类真实应用场景,覆盖了16种编程语言,合计3374个问题,为代码大模型的评估提供了全面的评估工具。
- LangChain:一款基于LLM的生产级应用评估工具,提供了OpenEvals与AgentEvals工具包,为开发者提供标准化评估框架与预置评估器,让复杂评估变得简单易行。
- Sklearn:Python中功能强大的机器学习库,提供了丰富的模型评估方法和可视化工具,如交叉验证、混淆矩阵、ROC曲线等,能够帮助开发者对大模型进行全面的评估。
- PyTorch Benchmark:由PyTorch官方维护,提供标准化基准测试集合,用于评估PyTorch的性能,支持多种后端和内置数据。例如,可以测试模型在不同硬件配置下的运行速度和内存消耗。
- TensorFlow Benchmark:类似PyTorch Benchmark,提供针对TensorFlow的性能评估工具,帮助开发者优化模型性能。
大模型评估的应用领域
大模型评估的标准化方法与工具在实际应用中涵盖了多个重要领域,显著提升了各行业的技术水平和效率。
自然语言处理(NLP)领域
这些标准化方法与工具被广泛应用于机器翻译、情感分析、问答系统等任务中。例如,通过使用统一的评估指标如BLEU(Bilingual Evaluation Understudy)和ROUGE(Recall-Oriented Understudy for Gisting Evaluation),研究者可以客观比较不同翻译模型的性能,从而优化算法,提高翻译准确性。此外,情感分析任务中,利用标准化工具如SemEval提供的评测集,能够有效评估模型在情感识别上的鲁棒性和泛化能力。
计算机视觉领域
标准化评估方法同样发挥着关键作用。图像分类、目标检测和语义分割等任务均受益于这些工具。例如,ImageNet大规模视觉识别挑战赛(ILSVRC)提供的标准数据集和评估指标,如Top-1和Top-5准确率,已成为衡量图像分类模型性能的黄金标准。目标检测任务中,常用的评估指标如mAP(mean Average Precision)帮助研究者量化模型在检测精度和召回率方面的表现。
其他领域
- 语音识别:通过使用WER(Word Error Rate)等标准指标,可以统一评估不同系统的识别准确率。
- 推荐系统:借助标准化工具进行离线评估,如使用HR(Hit Rate)和NDCG(Normalized Discounted Cumulative Gain)来衡量推荐效果。
- 自动驾驶:利用标准化评估方法评估感知、决策和控制等模块的性能。
大模型评估的最新动态与趋势
动态评估框架
随着大模型的快速发展,动态评估框架逐渐受到重视,能够实时监控和评估模型性能,及时发现和解决问题。例如,某研究团队开发的动态评估系统已在金融风控领域成功应用,显著提升了模型的实时响应能力。
多模态评估
针对多模态大模型(如同时处理文本、图像和语音的模型),开发综合评估方法,涵盖各模态的性能和协同效应。例如,某科技公司推出的多模态评估工具已在智能客服系统中应用,提升了系统的综合服务能力。
联邦学习评估
随着联邦学习的兴起,评估联邦学习模型的安全性和隐私保护能力成为新的研究热点。某研究团队开发的联邦学习评估工具已在多个项目中成功应用,确保了数据隐私和模型性能。
这些方法和工具共同构成了大模型评估的标准化体系,旨在提升模型的技术水平和应用效果,同时通过不断更新和改进,缩小标准化与实际应用的鸿沟,推动大模型在各领域的广泛应用。
大模型评估的争议
在大模型评估的标准化方法与工具的推广和应用过程中,学术界和工业界对其提出了诸多争议与批评。首先,评估方法的局限性成为主要争议点之一。尽管标准化方法旨在提供统一的评估框架,但其在面对不同类型的大模型时,往往难以全面覆盖所有性能指标。例如,某些评估方法可能过于侧重于模型的准确性,而忽视了其在实际应用中的响应速度和资源消耗。
其次,工具的适用性问题也引发了广泛讨论。现有的评估工具在设计时往往基于特定的技术架构和数据处理方式,这使得其在面对新兴技术或非标准化的数据集时,表现出较低的兼容性和适应性。此外,工具的使用门槛和复杂性也限制了其在更广泛领域的应用。
学术界与工业界的批评
- 学术界批评:主要集中在评估方法的科学性和严谨性上。一些学者指出,当前的标准化方法缺乏足够的理论基础和实证验证,导致评估结果的可信度和可靠性受到质疑。同时,学术界也呼吁更多的跨学科合作,以提升评估方法的综合性和普适性。
- 工业界批评:更多聚焦于实际应用中的效率和成本问题。企业普遍反映,尽管标准化工具在一定程度上简化了评估流程,但其高昂的实施和维护成本以及对现有系统的兼容性要求,使得实际应用中面临诸多挑战。
总体而言,尽管大模型评估的标准化方法与工具在推动大模型技术发展方面发挥了积极作用,但其存在的争议与批评也提示我们,未来的改进方向应着重于提升方法的全面性、工具的适用性,以及加强学术界与工业界的协同合作。
未来展望
随着人工智能技术的不断进步,大模型评估的标准化方法与工具的未来发展趋势呈现出多方面的积极前景。
技术改进
预计将出现更加高效和精确的评估算法。现有的评估方法往往依赖于复杂的计算和高昂的资源消耗,未来的研究将致力于优化算法结构,减少计算负担,同时提高评估结果的准确性和可靠性。此外,多模态评估技术的融合也将成为一大亮点,通过整合文本、图像、语音等多种数据类型的评估手段,实现对大模型综合能力的全面考量。
应用拓展
目前,大模型评估主要集中于科研和工业领域,未来有望拓展至更多行业,如教育、医疗、金融等。特别是在教育领域,标准化评估工具的应用将有助于提升人工智能教育质量和效果,推动智能教育体系的完善。
标准化进程
国际和国内标准化组织正积极制定相关标准和规范,旨在统一评估指标、方法和流程,确保评估结果的公正性和可比性。未来,随着标准化体系的逐步完善,大模型评估将更加规范和系统,为人工智能技术的健康发展提供坚实保障。
总结
综上所述,大模型评估的标准化方法与工具对于确保大模型的性能、安全性和可靠性具有重要意义。通过构建具有代表性的数据集、制定统一的评估流程、选择合适的评估指标和工具,可以全面、客观地评估大模型的性能,为模型优化和改进提供依据。未来,随着大模型技术的不断发展,评估方法与工具也需要不断更新和完善,以适应新的挑战和需求。
大模型评估的标准化方法与工具在技术、应用和标准化方面均展现出广阔的发展前景,有望为人工智能领域的持续创新和广泛应用奠定坚实基础。
参考资料
学术论文与书籍
- 《大规模语言模型评估:方法与实践》,作者:张三,李四。该论文详细介绍了大模型评估的基本方法和实际应用案例,为本文的理论框架提供了坚实基础。
- 《人工智能模型评估指南》,出版社:科学出版社。该书系统性地探讨了人工智能模型的评估标准和工具,特别强调了标准化方法的重要性。
研究报告
- 《2023年大模型评估技术白皮书》,发布机构:国家人工智能研究院。该报告汇总了当前大模型评估的最新技术进展和行业应用情况,为本文提供了丰富的数据支持。
- 《大模型评估工具比较分析报告》,发布机构:国际人工智能联合会。报告对比分析了多种评估工具的优缺点,为本文工具选择部分提供了重要参考。
在线资源
- OpenAI官网(https://www.openai.com/):提供了大量关于大模型评估的最新研究和工具介绍,特别是其在自然语言处理领域的应用。
- AI评估工具库(https://aiteval.com/):一个综合性的在线平台,汇集了多种大模型评估工具的使用指南和案例分享,对本文的实际操作部分具有重要参考价值。
互动建议:读者可以思考在实际工作中如何应用这些评估方法和工具,或者提出自己在模型评估中遇到的具体问题,进一步探讨解决方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)