后端面试面经每日随机day3
为经常出现在WHERE子句、JOIN条件或ORDER BY中的列创建索引。例如用户表的user_id或订单表的order_date,这类字段的索引能显著加速查询。主键()和唯一约束(UNIQUE)字段默认自动创建索引,确保数据唯一性并优化查找速度。例如用户邮箱(email)设为唯一索引可避免重复且快速验证。多表连接时,关联字段(如外键)应建立索引。若orders表通过关联customers表,对加
1、什么时候用到mysql索引
高频查询字段
为经常出现在 WHERE 子句、JOIN 条件或 ORDER BY 中的列创建索引。例如用户表的 user_id 或订单表的 order_date,这类字段的索引能显著加速查询。
主键与唯一约束
主键(PRIMARY KEY)和唯一约束(UNIQUE)字段默认自动创建索引,确保数据唯一性并优化查找速度。例如用户邮箱(email)设为唯一索引可避免重复且快速验证。
大表连接操作
多表连接时,关联字段(如外键)应建立索引。若 orders 表通过 customer_id 关联 customers 表,对 customer_id 加索引可减少嵌套循环查询的开销。
排序与分组优化
对频繁用于 GROUP BY 或 ORDER BY 的列加索引,避免全表扫描后的临时表排序。例如统计日志时按 create_time 分组,索引可加速聚合操作。
覆盖索引场景
若查询只需从索引中获取数据(无需回表),适合建复合索引。例如查询 SELECT username FROM users WHERE email='xxx',对 (email, username) 建索引可完全通过索引命中。
2、索引失效的原因
未遵循最左前缀原则
复合索引未按照定义时的字段顺序使用(如索引是(A,B,C),但查询条件仅用B,C),导致引擎无法利用索引。必须从最左列开始且不要跳过中间列。
对索引列使用函数或运算
例如WHERE YEAR(create_time) = 2023或WHERE price + 10 > 100,这类操作会使索引无法直接匹配原始数据。
隐式类型转换
字段类型与查询条件类型不匹配(如字符串列用数字查询),触发隐式转换。例如WHERE user_id = '123'(实际user_id为整型)。
使用OR条件不当OR连接的多个条件中若存在非索引列(如WHERE a=1 OR b=2,其中b无索引),可能导致全表扫描。
索引列使用NOT、!=或<>
负向查询通常无法有效利用索引(如WHERE status != 'active'),优化器可能选择全表扫描。
数据分布不均导致优化器放弃索引
当索引列的值重复率极高(如性别字段),优化器可能认为全表扫描比索引回表更高效。
联合索引包含范围查询后的列失效
如索引(A,B,C),查询条件为A=1 AND B>2 AND C=3,范围查询B>2会导致C列无法使用索引。
文本索引未使用左匹配LIKE查询以通配符开头(如LIKE '%abc')会导致索引失效,而LIKE 'abc%'仍可用索引。
表数据量过小
当表中数据极少(如不足千行),优化器可能直接选择全表扫描而非索引查询。
统计信息过期
数据库的索引统计信息未及时更新,导致优化器选择了低效的执行计划,需定期执行ANALYZE TABLE更新统计信息。
3、为什么点赞使用redis的zset数据
高效排序与查询
ZSET 通过分数(score)对成员进行排序,可以快速获取点赞数量排名或时间排序。每个点赞行为可以记录为成员(如用户ID)和分数(如时间戳或点赞权重),支持按分数范围查询或分页操作。
去重与唯一性
ZSET 的成员具有唯一性,天然避免重复点赞。同一用户对同一内容多次点赞时,ZSET 会自动覆盖旧记录,确保数据一致性。
高性能写入与读取
Redis 基于内存操作,ZSET 的插入(ZADD)和查询(ZRANGE、ZSCORE)时间复杂度为 O(log N),适合高并发场景。例如,统计点赞总数(ZCARD)的时间复杂度为 O(1)。
灵活的数据关联
可以通过组合键(如 like:post:123)将点赞数据与业务实体(如文章、评论)关联。同时支持多维度统计,如按用户、按内容聚合。
4、消息中间件怎么解决消息丢失
使用一个消息队列,其实就分为三大块:生产者、中间件、消费者,所以要保证消息就是保证三个环节都不能丢失数据。
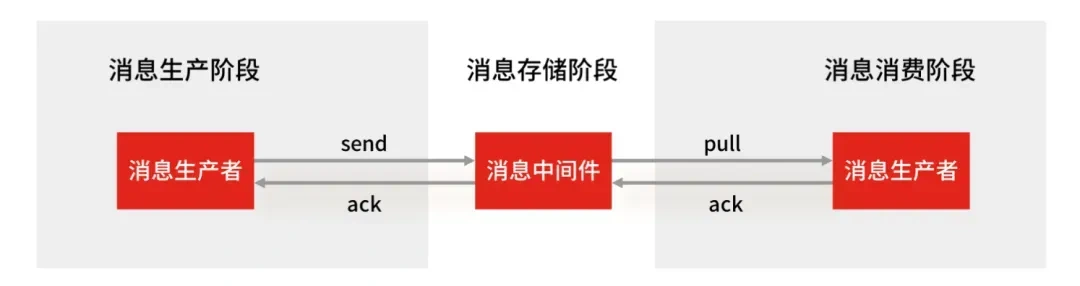
消息生产阶段:生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。从消息被生产出来,然后提交给 MQ的过程中,只要能正常收到 (MQ 中间件)的 ack 确认响应,就表示发送成功所以只要处理好返回值和异常,如果返回异常则进行消息重发,那么这个阶段是不会出现消息丢失的。
消息存储阶段:Kafka 在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
消息消费阶段:消费者接收消息+消息处理之后,才回复 ack 的话,那么消息阶段的消息不会丢失。不能收到消息就回 ack,否则可能消息处理中途挂掉了,消息就丢失了。
5、消息队列的可靠性、顺序性怎么保证?
可靠性
消息持久化 确保消息在传输过程中被持久化存储,避免因系统崩溃或重启导致消息丢失。常见的持久化方式包括将消息写入磁盘或数据库,设置持久化标志(如RabbitMQ的delivery_mode=2)。
确认机制(ACK) 引入消息确认机制,消费者处理完消息后向中间件发送确认信号。中间件收到ACK后才删除消息,否则重新投递。RabbitMQ的手动ACK模式(autoAck=false)和Kafka的消费者提交偏移量均属此类。
事务支持 使用事务确保消息的原子性操作。例如生产者发送消息时开启事务,消息成功投递后提交事务,失败则回滚。Kafka和RabbitMQ均支持事务,但可能影响性能。
重试机制与死信队列 为消息设置最大重试次数,超过阈值后转入死信队列(DLX)进行人工处理。RabbitMQ可通过x-dead-letter-exchange参数实现,Kafka可通过重试Topic实现。
顺序性
有序消息处理场景识别:首先需要明确业务场景中哪些消息是需要保证顺序的。例如,在金融交易系统中,对于同用户的转账操作顺序是不能打乱的。对于需要顺序处理的消息,要确保消息队列和消费者能够按照特定的顺序进行处理。
消息队列对顺序性的支持:部分消息队列本身提供了顺序性保证的功能。比如 Kafka 可以通过将消息划分到同一个分区(Partition)来保证消息在分区内是有序的,消费者按照分区顺序读取消息就可以保证消息顺序。但这也可能会限制消息的并行处理程度,需要在顺序性和吞吐量之间进行权衡。
消费者顺序处理策略:消费者在处理顺序消息时,应该避免并发处理可能导致顺序打乱的情况。例如可以通过单线程或者使用线程池并对顺序消息进行串行化处理等方式,确保消息按照正确的顺序被消费。
6、延迟队列用过吗?讲一下自己项目(选一种)
延迟队列的概念
延迟队列是一种特殊的消息队列,支持消息在指定时间后才被消费者处理。典型应用场景包括订单超时取消、定时任务调度、消息重试等。
实现延迟队列的常见方法
Redis + Sorted Set
利用 Redis 的 ZSET(有序集合)存储消息,以延迟时间作为分数(score),通过轮询或阻塞获取到期消息。
# 添加延迟消息
ZADD delay_queue <timestamp> <message>
# 查询到期消息
ZRANGEBYSCORE delay_queue 0 <current_timestamp>
RabbitMQ + 插件
RabbitMQ 通过 rabbitmq-delayed-message-exchange 插件实现延迟队列。消息发送到延迟交换机后,根据设定的延迟时间路由到队列。
# 声明延迟交换机
channel.exchange_declare(exchange='delayed_exchange', type='x-delayed-message', arguments={'x-delayed-type': 'direct'})
Kafka + 时间轮
Kafka 本身不支持延迟队列,但可通过外部时间轮(如 TimerWheel)或分层时间轮(如 HashedWheelTimer)模拟实现。
数据库 + 定时任务
使用数据库表存储消息和到期时间,通过定时任务扫描到期记录并处理。适合低频场景,但需注意性能问题。
延迟队列的注意事项
-
精度与性能:高精度延迟(如毫秒级)可能增加实现复杂度,需权衡性能。
-
消息丢失:确保消息持久化,避免系统崩溃导致数据丢失。
-
分布式一致性:分布式环境下需处理时钟同步和分片问题。
7、rabbitmq在项目中起到什么作用
异步处理 通过消息队列将耗时操作(如发送邮件、生成报表)异步化,避免阻塞主业务流程,提升系统响应速度。生产者将任务发送到队列后,消费者可异步处理,实现任务的削峰填谷。
应用解耦 不同模块或服务之间通过 RabbitMQ 通信,避免直接依赖。例如订单系统与库存系统通过消息交互,即使库存服务暂时不可用,订单消息仍可保存在队列中,待恢复后处理。
流量缓冲 在高并发场景下,RabbitMQ 作为缓冲区吸收突发流量,防止系统过载。消息按照处理能力被匀速消费,避免后端服务被压垮。
分布式系统通信 在微服务架构中,RabbitMQ 作为跨服务通信桥梁,支持多种协议(如 AMQP、MQTT)。服务间通过交换机和路由规则实现灵活的消息分发。
数据一致性 通过事务或发布确认机制确保消息可靠传输,结合死信队列、重试机制处理异常情况,常用于分布式事务的最终一致性方案。
典型使用场景
-
任务队列:将长时间任务(如视频转码)放入队列,由工作进程并行处理。
-
事件通知:实现系统事件(如订单创建)的发布/订阅模式,多个服务可同时响应。
-
日志收集:多个应用将日志发送到中央队列,由日志服务统一处理和存储。
-
跨语言集成:支持不同语言编写的系统通过标准协议交换数据。
技术特性支持
-
多种交换机类型:Direct、Fanout、Topic、Headers 实现不同路由策略。
-
消息持久化:防止服务器重启导致消息丢失。
-
QoS 控制:通过 prefetch count 限制未确认消息数量,平衡负载。
-
插件扩展:支持延迟队列、消息追踪等扩展功能。
8、DevOps 基础流程
DevOps 核心流程
DevOps 是一种将开发(Development)和运维(Operations)相结合的实践方法论,旨在通过自动化、协作和持续改进来加速软件交付。以下是其基础流程的关键组成部分:
持续集成(CI)
开发人员将代码频繁提交到共享仓库,每次提交触发自动化构建和测试流程。此阶段确保代码变更能够快速集成到主干,减少冲突风险。常见的工具包括 Jenkins、GitLab CI/CD 和 GitHub Actions。
持续交付(CD)
在持续集成的基础上,将代码自动部署到类生产环境,确保软件随时可发布。此阶段强调自动化测试和部署流程,减少人工干预。工具链可能包含 Ansible、Terraform 或 Kubernetes。
自动化测试
贯穿整个流程的自动化测试体系,包括单元测试、集成测试和端到端测试。测试结果反馈到开发环节,确保代码质量。常用框架如 Selenium、JUnit 或 pytest。
基础设施即代码(IaC)
通过代码定义和管理基础设施,确保环境一致性。工具如 Terraform 或 AWS CloudFormation 可将服务器、网络等资源配置模板化。
监控与日志
实时监控生产环境性能,收集日志数据以便快速定位问题。工具如 Prometheus、Grafana 或 ELK(Elasticsearch、Logstash、Kibana)堆栈常用于此环节。
协作与沟通
打破开发与运维团队的壁垒,通过共享工具链和沟通平台(如 Slack、Microsoft Teams)实现信息透明化。敏捷实践如每日站会(Scrum)也常被整合到流程中。
反馈与改进
通过监控和用户反馈持续优化流程。度量指标包括部署频率、变更失败率等,形成闭环改进机制。
9、Linux复制文件的命令
使用cp命令复制文件
cp命令是Linux中最基本的文件复制工具,语法为:
cp [选项] 源文件 目标文件
常见操作示例:
# 将file1复制到file2
cp file1 file2
# 复制到指定目录
cp file1 /path/to/directory/
常用选项参数
-
-i:覆盖前提示确认 -
-r或-R:递归复制目录 -
-v:显示复制过程 -
-u:仅复制更新的文件 -
-p:保留文件属性
# 带选项的示例
cp -iv file1 file2
复制多个文件到目录
可以通过指定多个源文件复制到目标目录:
cp file1 file2 file3 /target/directory/
10、线程池参数讲一下
corePoolSize(核心线程数)
线程池中保持存活的最小线程数量,即使这些线程处于空闲状态。当新任务提交时,若当前线程数小于corePoolSize,线程池会创建新线程执行任务。核心线程通常不会被回收,除非设置allowCoreThreadTimeOut为true。
maximumPoolSize(最大线程数)
线程池允许创建的最大线程数量。当任务队列已满且当前线程数小于maximumPoolSize时,线程池会创建新线程处理任务。超过corePoolSize的线程在空闲时会根据keepAliveTime被回收。
keepAliveTime(非核心线程空闲存活时间)
当线程数超过corePoolSize时,多余的空闲线程在终止前等待新任务的最长时间。时间单位由unit参数指定。
unit(时间单位)
keepAliveTime的时间单位,常用值为TimeUnit.SECONDS、TimeUnit.MILLISECONDS等。
workQueue(任务队列)
用于保存待执行任务的阻塞队列,常见实现包括:
-
LinkedBlockingQueue:无界队列(默认容量为
Integer.MAX_VALUE),可能导致资源耗尽。 -
ArrayBlockingQueue:有界队列,需指定固定容量。
-
SynchronousQueue:不存储元素的队列,每个插入操作需等待另一个线程的移除操作。
threadFactory(线程工厂)
可选参数,用于自定义线程创建过程(如线程命名、优先级等)。默认使用Executors.defaultThreadFactory()。
handler(拒绝策略)
当线程池和队列已满时,处理新任务的策略。常见策略:
-
AbortPolicy(默认):直接抛出异常。
-
CallerRunsPolicy:由提交任务的线程直接执行任务。
-
DiscardPolicy:静默丢弃任务。
-
DiscardOldestPolicy:丢弃队列中最旧的任务并重新提交新任务。
追问:jvm默认的拒绝策略是什么
答:当线程池无法处理新提交的任务时(例如队列已满且线程数达到最大值),AbortPolicy会直接抛出RejectedExecutionException异常。这是一种直接且严格的处理方式,确保任务不会因资源不足而被静默丢弃。
11、三个线程,依次打印A,B,C,如何设计
使用 synchronized 和 wait/notify 机制
创建三个线程,分别负责打印 A、B、C。通过共享的锁对象和状态变量控制执行顺序。
public class SequentialPrinting {
private static final Object lock = new Object();
private static int state = 0; // 0:A, 1:B, 2:C
public static void main(String[] args) {
Thread threadA = new Thread(() -> {
synchronized (lock) {
while (true) {
if (state == 0) {
System.out.println("A");
state = 1;
lock.notifyAll();
} else {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
});
Thread threadB = new Thread(() -> {
synchronized (lock) {
while (true) {
if (state == 1) {
System.out.println("B");
state = 2;
lock.notifyAll();
} else {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
});
Thread threadC = new Thread(() -> {
synchronized (lock) {
while (true) {
if (state == 2) {
System.out.println("C");
state = 0;
lock.notifyAll();
} else {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
});
threadA.start();
threadB.start();
threadC.start();
}
}
使用 ReentrantLock 和 Condition
利用 ReentrantLock 的精确唤醒机制,为每个线程创建独立的 Condition 对象。
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class SequentialPrintingWithLock {
private static ReentrantLock lock = new ReentrantLock();
private static Condition conditionA = lock.newCondition();
private static Condition conditionB = lock.newCondition();
private static Condition conditionC = lock.newCondition();
private static int state = 0;
public static void main(String[] args) {
Thread threadA = new Thread(() -> {
while (true) {
lock.lock();
try {
while (state != 0) {
conditionA.await();
}
System.out.println("A");
state = 1;
conditionB.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
});
Thread threadB = new Thread(() -> {
while (true) {
lock.lock();
try {
while (state != 1) {
conditionB.await();
}
System.out.println("B");
state = 2;
conditionC.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
});
Thread threadC = new Thread(() -> {
while (true) {
lock.lock();
try {
while (state != 2) {
conditionC.await();
}
System.out.println("C");
state = 0;
conditionA.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
});
threadA.start();
threadB.start();
threadC.start();
}
}
使用 Semaphore 控制顺序
通过三个信号量分别控制 A、B、C 线程的执行顺序,初始时只有 A 的信号量为 1。
import java.util.concurrent.Semaphore;
public class SequentialPrintingWithSemaphore {
private static Semaphore semaphoreA = new Semaphore(1);
private static Semaphore semaphoreB = new Semaphore(0);
private static Semaphore semaphoreC = new Semaphore(0);
public static void main(String[] args) {
Thread threadA = new Thread(() -> {
while (true) {
try {
semaphoreA.acquire();
System.out.println("A");
semaphoreB.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread threadB = new Thread(() -> {
while (true) {
try {
semaphoreB.acquire();
System.out.println("B");
semaphoreC.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread threadC = new Thread(() -> {
while (true) {
try {
semaphoreC.acquire();
System.out.println("C");
semaphoreA.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
threadA.start();
threadB.start();
threadC.start();
}
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)