DNA-GPT:用“续写 DNA”抓出 GPT——一篇训练免检测方法的全景解读
论文一开头就点出了今天的现实:ChatGPT、GPT-4 等 LLM 让机器生成文本在流畅度和多样性上快速逼近甚至部分超越普通人,随之而来的,是假新闻、学术不端、作业代写等一系列信任危机。与此同时,检测技术的发展明显慢于生成技术,尤其是在最新闭源大模型上,很多传统方法直接“失效”或要求的接口根本拿不到。作者认为困难有两层。一方面,当机器文本质量足够高时,“看起来像不像人写的”这类直觉判别几乎失灵,
1. 论文基本信息
这篇论文的标题是 “DNA-GPT: Divergent N-Gram Analysis for Training-Free Detection of GPT-Generated Text”,作者来自 UCSB、NEC Labs 等机构,时间为 2023 年 arXiv 预印本。它主要关注大语言模型(尤其是 GPT-3.5、GPT-4 等)生成文本的检测问题,提出了一种无需训练的新方法 DNA-GPT。研究领域落在自然语言处理中的文本生成与检测交叉方向,核心关键词可以概括为:大型语言模型(LLM)、AI 文本检测、黑盒 / 白盒检测、n-gram 分析、对数似然、零样本(zero-shot)方法、可解释性检测、鲁棒性与模型溯源(model sourcing)。
从应用角度看,它直接面对当前最热门的 GPT 家族,包括 text-davinci-003、gpt-3.5-turbo、gpt-4-0314 等闭源模型,也覆盖了 LLaMa-13B、GPT-NeoX-20B 这样的开源模型,实验数据集则跨越英文问答、科研摘要、新闻摘要、机器翻译和德语文本。因此,它不是一篇只在实验室玩具模型上做实验的论文,而是试图给“ChatGPT 时代的文本检测”提供一套通用方案。
2. 前言:为什么读这篇论文?
论文一开头就点出了今天的现实:ChatGPT、GPT-4 等 LLM 让机器生成文本在流畅度和多样性上快速逼近甚至部分超越普通人,随之而来的,是假新闻、学术不端、作业代写等一系列信任危机。与此同时,检测技术的发展明显慢于生成技术,尤其是在最新闭源大模型上,很多传统方法直接“失效”或要求的接口根本拿不到。
作者认为困难有两层。一方面,当机器文本质量足够高时,“看起来像不像人写的”这类直觉判别几乎失灵,理论上也出现了“AI 文本是否可检测”的争论。另一方面,现有主流检测器大多是训练好的分类模型,例如 OpenAI 官方的文本分类器、GPTZero 等,它们需要大量标注数据、定期重训,而且一旦模型家族更新或领域发生迁移,性能就会明显衰减,更不用说它们通常只给一个“AI/人类”的标签,没有任何可解释证据。
在这样的背景下,DNA-GPT 试图回答三个问题。第一,在不接触模型内部参数的情况下,是否仍然可以稳定地区分人写与 GPT 写?第二,能否不重新训练任何模型,只靠现成的 LLM API 做检测?第三,检测结果能否提供“证据”,而不是一个黑箱打分?作者的回答是肯定的:他们利用“同一个前缀下,机器续写高度集中、人类续写分布更散”的现象,构造了一个完全训练免的检测框架,在 GPT-3.5/4 上取得了超过 OpenAI 官方分类器的表现,还顺带实现了非英语检测、被改写文本检测以及“是哪一个模型写的”这种模型溯源任务。
对研究者和实践者来说,这篇论文值得解读,是因为它代表了一条与传统“再训练一个检测模型”不同的路线:直接把被怀疑的文本丢回去问大模型“你自己会怎么续写?”,再用统计方法比较“原文续写”和“模型续写”的差异,相当于利用了生成模型本身的“风格 DNA”来做检测。这种思路在模型不断演化、接口逐步收紧的现实环境下,显得尤为实用。
3. 基础概念铺垫
理解 DNA-GPT,首先要搞清楚几组概念。
大语言模型可以看成一个条件概率分布,它在给定前缀 () 的情况下,为下一个 token
产生一个概率
。生成一段完整文本,其实就是不断按这个条件分布采样或近似最大化对数似然。GPT 这一类是典型的 decoder-only Transformer 架构。
论文讨论了两种检测场景:白盒和黑盒。在白盒场景下,检测者不仅能让模型生成文本,还能拿到模型对每个输出 token 的对数概率(至少是该 token 的 logprob),例如 text-davinci-003 曾经提供 top-5 概率。而在黑盒场景中,像 gpt-3.5-turbo、gpt-4-0314 等,仅暴露一个“给我前缀,我返回文本”的接口,没有任何概率、logits 或参数信息。现实中的 API 使用几乎都是黑盒场景,所以论文重点放在黑盒检测。
在文本相似性上,作者采用了 n-gram 的视角。一个 n-gram 是长度为 n 的连续 token / 词片序列,例如 “language models are few-shot learners” 里,“language models are few” 是一个 4-gram。直觉上,如果我们用同一个前缀 X 让 GPT 连续生成 K 次续写 ,那么这些机器续写之间会共享大量相同的中长 n-gram,说明它们集中在训练分布的高密度区域;而如果原文的后半段
是人写的,那么它与这些 GPT 续写之间的中长 n-gram 重合就会少很多。
在概率空间里,作者提出了“似然差距假设”,即在相同前缀 (X) 下,机器生成的余下文本在模型自身的 log-likelihood 意义上,平均要比人类续写高一个显著的常数。直观理解是:GPT 的生成过程本质上是“尽量选概率大的下一个词”,而人类写作并不会严格做这种最大化,有时会主动选更罕见的表达,或者按结构、修辞需要重组语言,从而在模型眼里“似然更低”。
最后一个关键概念是“续写重采样”。DNA-GPT 的核心操作是:取一段待检测文本 S,把它从中间截断成前缀 X 和后缀,再用同一个模型对 X 重复采样生成 K 份新后缀
。之后的一切打分都建立在比较
与这些机器续写的相似度之上。
4. 历史背景与前置技术
在 DNA-GPT 出现之前,文本检测领域经历了几次方法论转换。早期的方法主要基于表层特征,例如统计 rare bigram 的频率、简单的 n-gram 分布差异,或者像 GLTR 那样用语言模型的 rank 和概率区间来可视化“这段文本有多像机器写的”。这些方法在 GPT-2 时代尚有一定效果,但面对更强大的 GPT-3.5/4 很快就显得力不从心。
随后兴起的是训练型检测器。OpenAI 官方发布过基于多模型集成微调的 AI Text Classifier,GPTZero 则强调用困惑度(perplexity)和“burstiness”(某种局部波动)来捕捉人类写作的节奏。这类方法的优点是可以针对特定模型、特定领域训练出强大的二分类器,但缺点也很明显:它们需要大量、持续的标注和再训练,一旦新模型或新解码策略出现,很快就会过拟合到旧的模式,表现严重下滑。论文的实验部分也证明了,OpenAI classifier 和 GPTZero 在作者构建的 Reddit 新数据和最新科学摘要数据上表现远不如 DNA-GPT。
与之并行的是“训练免”的思路,例如 DetectGPT 利用一个外部语言模型在被检测模型的判定曲面上做概率曲率估计,基于负对数概率曲线的“弯曲程度”来判断文本是否由某个模型生成;水印方法则通过在采样时对 token 集施加偏好,使得生成文本中隐藏某种统计信号,后端通过检测这个信号来识别 AI 文本。这些工作虽然在理论上很优雅,但要么需要完整的 token 概率分布(在 ChatGPT 时代不可用),要么要求生成时就配合水印采样(现实中平台分裂、模型众多,很难强制统一)。
更深一层的背景是理论上的“不可检测性”争论。有工作基于 LeCam 引理和 total variation distance 推导出当机器分布 M 与人类分布 H 足够接近时,任何检测器的 AUROC 上界都会非常接近随机猜测,并据此宣称“可靠检测是不可能的”。DNA-GPT 的作者并不否认这个结论在极限情况下成立,但他们认为,在现实的 LLM 生成设置下,只要条件在“给定相同前缀”的层面考虑,机器续写和人类续写之间仍然存在足够大的统计差异,可以被利用来构建高性能检测器。
因此,DNA-GPT 的前置技术可以理解为:建立在语言模型概率视角上的检测思想、类似 DetectGPT 的零样本方案,以及各类基于 n-gram 的表层统计方法。作者的创新点在于把“截断-续写-比较”这一简单操作组织成一个统一框架,既能在黑盒 API 上工作,又可在白盒场景下利用概率信息,还提供了可视化证据。
5. 论文核心贡献
从整体叙述来看,这篇论文的核心贡献可以浓缩为一个观测、两个算法和一系列系统性的实验。
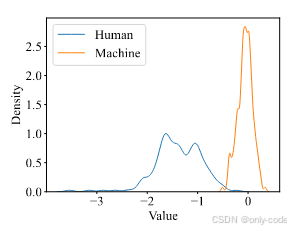
第一个关键观测是:在给定相同前缀 X 的情况下,同一个 LLM 对 X 多次续写得到的后缀 在分布上高度集中,而真实人类写作的后缀
相比之下更为分散。这种差异既体现在 n-gram 重合上,也体现在模型自身对文本给出的 log-likelihood 上。作者用一个“似然差距假设”把这种现象形式化,并通过图 2 中的概率分布图证明,在 Reddit 提示下 text-davinci-003 对 GPT 续写和人类续写的 log-likelihood 分布明显分离
在这个观测基础上,作者提出了 DNA-GPT 框架。对黑盒模型,利用“发散 n-gram 分析”,即多次让模型续写同一个前缀,然后用一个加权 n-gram 重合得分 BScore 衡量原始后缀与机器续写族之间的相似度,得分越高越像机器所写。对白盒模型,则直接比较模型在原始后缀和重采样后缀上的对数似然,构造一个 WScore,体现“原文比机器样本在模型眼里更不寻常还是更常见”。通过设定阈值 (\epsilon),两个分数都可以转化为二分类器,并且可以为每个判定附带一组重合的长 n-gram 片段,作为证明一段文本“非常像机器”的证据。
最后,作者在 GPT-4、GPT-3.5-turbo、text-davinci-003 以及 LLaMa-13B、GPT-NeoX-20B 上,结合 Reddit 问答、最新 Nature 科学摘要、PubMedQA、XSum 和 WMT16 德语翻译等数据,进行了全面实验。在黑盒 setting 下,DNA-GPT 的 AUROC 和在 1% FPR 时的 TPR 几乎全面超过 OpenAI classifier 和 GPTZero;在白盒 setting,WScore 对 text-davinci-003 的检测甚至接近“完美”,远远优于 DetectGPT。进一步,他们展示了该方法在高温采样、文本被另一模型改写、德语检测以及对开源模型文本的检测中,都具有良好的鲁棒性,还可以通过“对不同候选模型分别计算得分”完成模型溯源任务。整体来看,这篇论文提供了一套兼具理论直觉、工程可用性和解释能力的 AI 文本检测方案。
6. 方法详解
DNA-GPT 的方法可以看成三个步骤:截断、重生成和打分。

在形式化部分,作者首先定义了检测任务:给定一段文本序列 ,其中 L 是长度,已知它是由某个特定语言模型 M 生成,或者由人类分布 H 生成。目标是在二分类意义上判断 S 属于 M 还是 H。在黑盒场景中,检测者只可以调用 M 作为“续写 API”,即给它任意前缀 X,它会返回某个后缀 Y;在白盒场景中,检测者还可以观察到每个 token 的输出概率
的对数值。接着,作者引入截断率 (\gamma)。对每一个待检测的 S,他们把它分成前缀和后缀:
然后只把前缀 X 喂给模型 M,请它继续生成 K 次,得到一组新的后缀
。从直觉上说,如果 S 本来就是 M 生成的,那么
很有可能与这 K 份续写在“风格”和表达上非常接近,甚至出现大段完全一致的长 n-gram;如果 S 是人类写的,虽然模型也会生成看似合理的文本,但与人类真实续写相比,仍然存在明显的统计差异。
为了解释这种差异,论文提出了“Likelihood-Gap Hypothesis”。在相同前缀 X 下,机器 M 生成的后缀在语言模型自身的 log-likelihood 意义上应该平均高于人类写的后缀:
其中 是一个常数。作者进一步用 total variation 距离和 KL 散度做了不等式推导,说明如果这两个期望之间存在正间隔,那么在概率分布空间里 M 和 H 之间的距离
或
必然也存在正的下界。基于 LeCam 引理,这意味着在理论上,总存在某个检测器能够以非平凡的 AUROC 把两者区分开来。
在黑盒检测部分,由于拿不到任何 token 概率,作者选择了一个“n-gram 相似度”作为距离函数。对于每一个模型续写 ,他们枚举从某个起始长度
到最大长度 N 的所有 n-gram,计算这些 n-gram 在
和原始后缀 (Y_0) 之间的重合比例。具体的打分公式 BScore 是这样构造的:
其中 表示序列 S 中所有长度为 n 的 n-gram 集合,
做长度归一化,
是一个随 n 增大而增长的权重函数。论文实验中使用的经验配置是
、
、
。这样一来,较长的完全重合片段会被赋予更大的权重,可以更清晰地作为“证据”。
在白盒检测部分,作者假设可以拿到模型 M 对任意给定文本的对数概率。在这种情况下,他们定义了另一种得分 WScore:
直观上,如果 S 本身来自模型 M,那么在它眼里,的似然通常不会比随机采样出来的
低很多,得分会集中在某个区间;如果 S 是人类写的,由于人类选择了“模型不太会写”的那条路径,其 log-likelihood 往往偏低,导致这个比例和对数值显著区别于机器自写文本。通过在验证集上搜索阈值
,WScore 可以转化为一个简单的一维检测器。
DNA-GPT 还特别强调“证据”的生成。在黑盒算法中,他们把所有机器续写与
的重合 n-gram 收集起来,记为
当 n 较大(比如 10 词以上)时,如果在多次续写中反复出现完全相同的长片段,而这些片段又恰好出现在原文后缀中,那么可以非常有力地说明“原文极其符合模型在这个前缀下的典型输出模式”。论文在附录中给出了多个例子,展示如何高亮这些长 n-gram 片段,帮助教师寻找 AI 抄写或重用模板的证据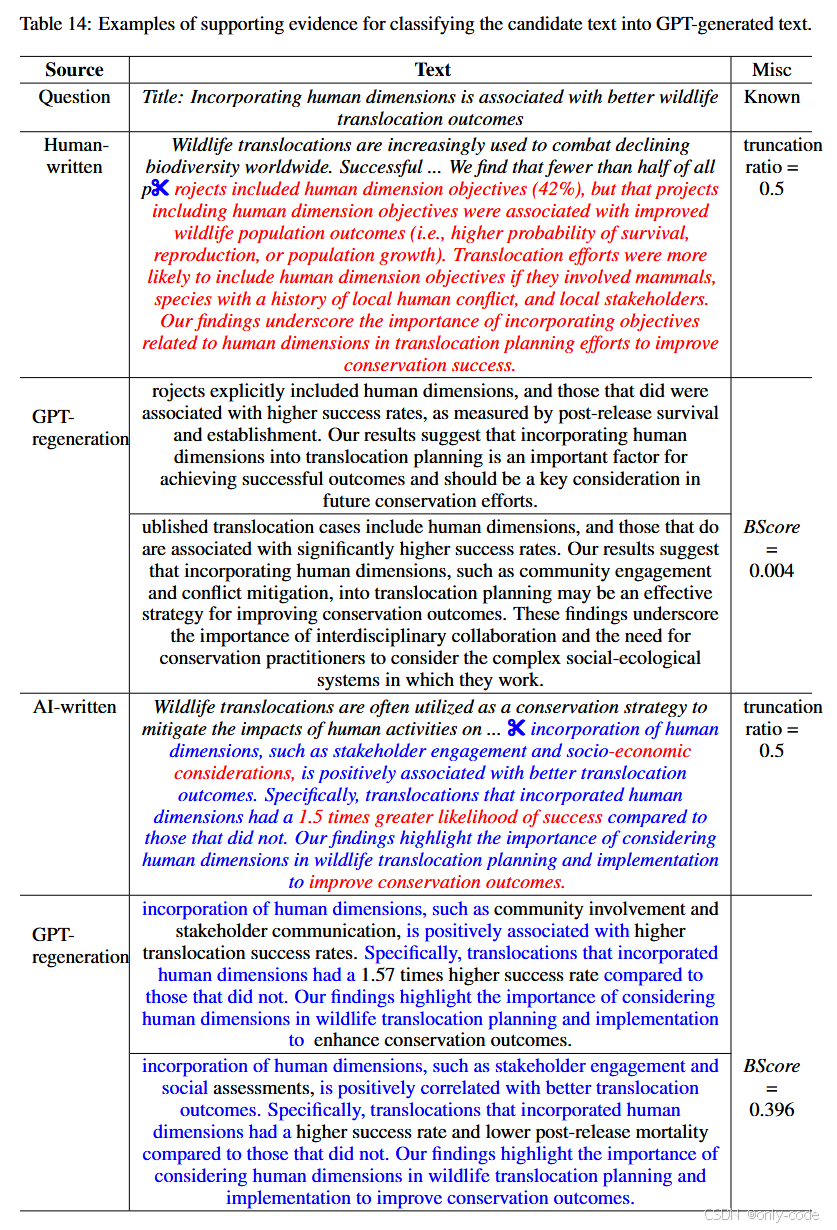
在参数选择方面,论文既给出理论分析,也提供经验结论。对重采样次数 K,作者假设距离函数 是次高斯随机变量,然后用 Hoeffding 不等式推导出,如果人类续写与机器续写之间的期望差距为
,且方差控制在
量级,那么为了以置信度
区分两种情况,所需的重采样次数 K 规模在
。实验中他们发现 K 在 5 到 10 之间时性能就已接近饱和,继续增加只会线性提高 API 成本。
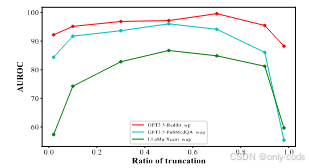
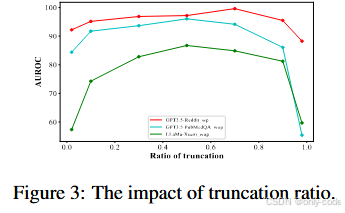
截断率 则在 0.02 到 0.98 区间上做了系统扫描。结果显示,当截断太短时,前缀信息不足,模型续写变得极其多样,导致机器与人类的差异被噪声淹没;当截断太长时,留给续写的空间太小,模型几乎只能微调几个词,重合 n-gram 不再能有效区分。综合多种模型和数据集的曲线,
即前后各占一半的截断点,往往带来最稳定的检测表现。
论文还在附录中讨论了几种方法扩展。针对“机器写前半段,人写后半段”的混合文本,他们提出使用滑动窗口,对长文本切片后分别做 DNA-GPT 检测,只要有任意一个窗口被判为 AI,就把整篇文章标记为可疑,从而对混合写作保持一定的敏感度。
对于未知源模型的检测,他们尝试用小型代理模型(如 OPT-125M、GPT-2-124M)来重采样,尽管性能不如“自举式检测”,但在 Reddit 数据上仍取得了中等 AUROC,说明即使不知道原始生成模型是谁,也可以通过一个通用的小模型获得一定的检测能力。
7. 实验结果与性能分析
论文的实验部分非常密集,覆盖了数据集构造、模型选择、基线设定以及多种分析维度。
在数据集方面,作者特别关注“避免训练集记忆”的问题,因此刻意选择了新近的数据。例如 Reddit-ELI5 数据集,他们从解释物理和生物问题的帖子中抽取了 2022 年 1 月到 2023 年 3 月的问答,并用 GPT 系列模型在这些新问题上生成答案;对于科学摘要,他们在 Nature 网站上抓取了 2023 年 4 月 23 日当天上线的最新文章摘要,并在同一天用 GPT 生成对应的“假摘要”,以减少这些内容被 OpenAI 用作训练或微调数据的可能性。在更传统的任务上,他们仍然采用 PubMedQA 生物医学问答、XSum 极限摘要以及 WMT16 英德翻译,这些数据集虽然可能被部分模型见过,但配合新数据集可以形成互补。
模型方面,作者选择了五个代表性 LLM。来自 OpenAI 的包括提供 logprob 接口的 text-davinci-003,以及不再提供 token 概率的 gpt-3.5-turbo 和 gpt-4-0314;开源侧则有 GPT-NeoX-20B 和 LLaMa-13B。默认温度为 0.7,最大输出长度约 300 token。对于 text-davinci-003 这样的白盒模型,他们同时计算 BScore 和 WScore;对于 gpt-3.5-turbo、gpt-4-0314 等黑盒模型,只能使用 BScore。
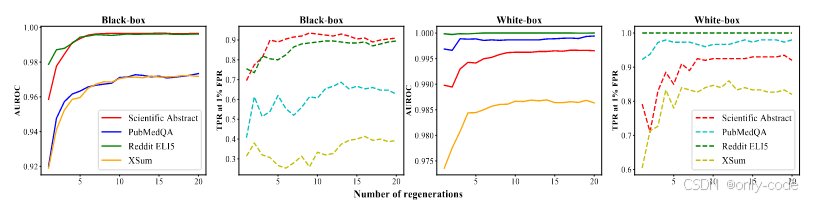
评价指标主要是 AUROC 和在 1% FPR 下的 TPR。作者指出,在 AUROC 接近 1 的场景中,单纯比较 AUROC 容易掩盖模型在“误报很低时”的体验差异,因此 TPR@1%FPR 才是实际部署更关心的。附录中另外给出了 F1、Accuracy 等指标,整体趋势与主文一致。
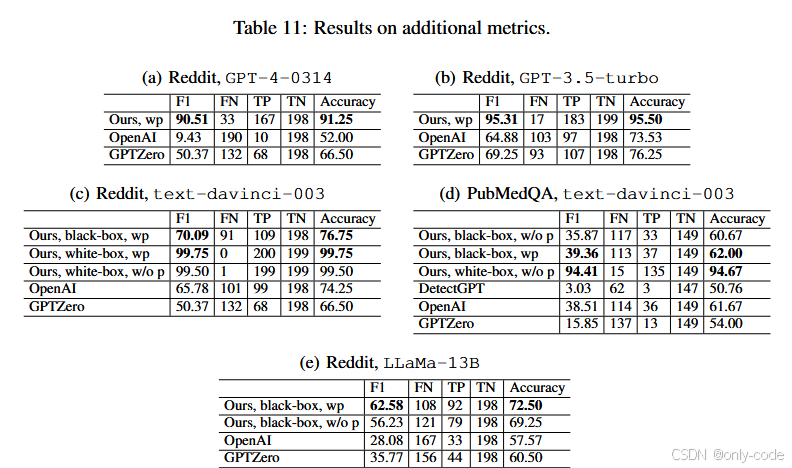
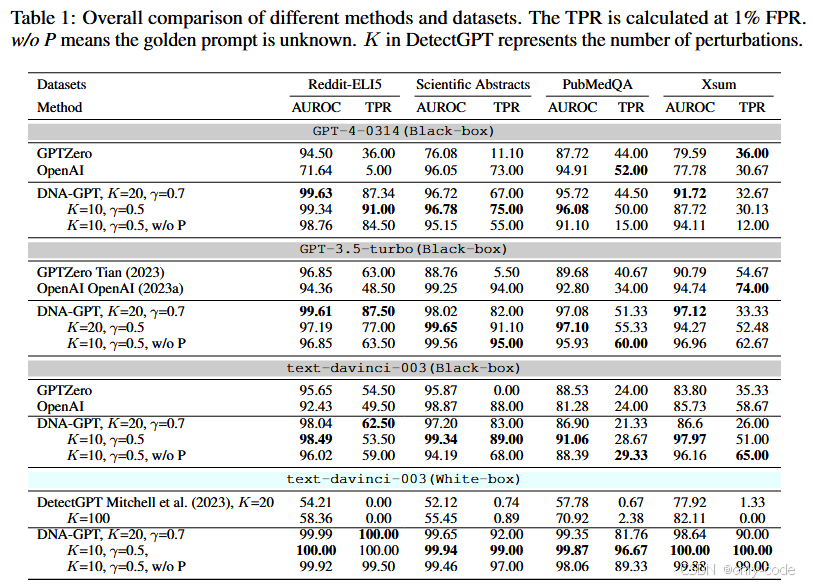
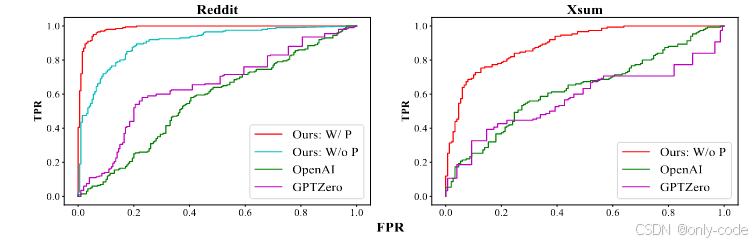
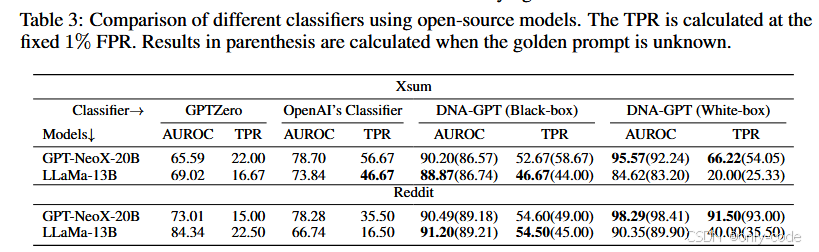
在总体结果表中,DNA-GPT 几乎在所有组合上都显著优于 GPTZero 和 OpenAI classifier。以 GPT-3.5-turbo 在 Reddit-ELI5 上为例,在已知问题提示(有 golden prompt)的设置下,DNA-GPT 的 AUROC 达到约 99.6,TPR@1%FPR 为 87.5%;同一配置下,GPTZero 的 TPR 只有 63%,OpenAI classifier 为 48.5%。在 Nature 科学摘要上,DNA-GPT 的 AUROC 约在 98 左右,TPR 高达 80% 左右,而 GPTZero 在这个新数据上几乎完全失效,TPR 低到个位数。即便在没有 golden prompt 的更困难场景中,DNA-GPT 仍然保持了较高 AUROC 和中等以上的 TPR。
白盒检测的结果更为极端。对 text-davinci-003,DetectGPT 在 Reddit、新摘要、PubMedQA 和 XSum 上的 AUROC 只有 50%–80% 左右,TPR 基本接近 0%,说明其对最新模型和新数据的适应性较差。而 DNA-GPT 的 WScore 在同样场景中,AUROC 接近 1,TPR 大多在 90% 以上;某些配置下甚至出现了“100% TPR @ 1% FPR”的近乎完美表现。这说明基于“自重采样 + 似然比”的白盒版本非常强,只是受限于真实世界中 logprob 接口的逐渐收紧。
作者接着分析了不同截断率和不同重采样次数下的性能变化。截断率曲线显示,在 Reddit-GPT3.5、PubMedQA-GPT3.5 和 XSum-LLaMa 这几项实验中,当 从 0.02 增加到 0.5 时,AUROC 快速上升,而继续增加到 0.9 甚至 0.98 时又缓慢下降,印证了前缀过短或过长都会损害检测力的直觉。
对重采样次数 K 的分析则表明,在黑盒场景中 K 从 5 增加到 10 带来的性能收益明显,而 10 之后曲线逐渐饱和;白盒场景中 K 甚至在 5 左右就已经接近极限,说明在成本和性能之间,5–10 次续写是一个比较务实的折中。
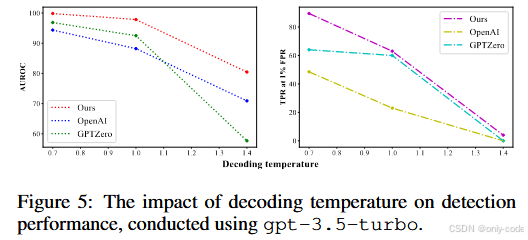
在温度敏感性实验中,作者将 GPT-3.5-turbo 的解码温度从 0.7 调高到 1.4。在 Reddit 数据上,无论 GPTZero 还是 OpenAI classifier,都随着温度升高出现了显著的 AUROC 和 TPR 下降,这可能是因为它们的训练数据集中,大多数 AI 文本是用默认或较低温度生成的。一旦生成策略偏离训练分布,分类器便难以适应。DNA-GPT 的性能同样有所下降,但始终保持明显领先;在温度高到 1.8 时,生成文本本身已变得胡言乱语,论文举了几个例子展示这种“乱码式”输出,很难想象真实用户会保留这样质量的文本。
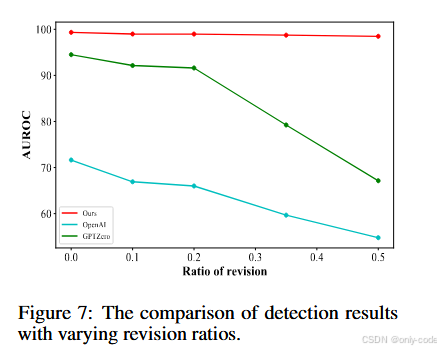
针对改写鲁棒性,作者借鉴 DetectGPT 的设置,用 T5-3B 模型在 GPT-4 生成的 Reddit 答案中随机替换一定比例的 5 词片段,模拟“被另一模型或人工改写”的场景。当改写比例从 0 到 50% 提升时,GPTZero 和 OpenAI classifier 的性能一开始略有下降,随后在改写超过 30% 后几乎崩溃;DNA-GPT 的 AUROC 则从 99.09 微降至 98.48,TPR 也保持在较高水平,整体表现非常稳健。
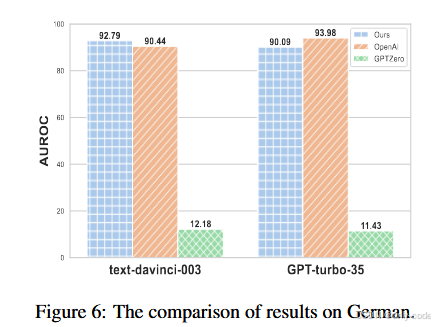
非英语检测是另一个亮点。作者在 WMT16 的德语部分上,让 GPT 在英文源句上生成德语译文,比较不同检测器的表现。结果表明,GPTZero 在德语上几乎只是随机猜测,OpenAI classifier 还能勉强工作,而 DNA-GPT 的黑盒和白盒版本则都取得了 90% 左右的 AUROC,在某些设置中甚至超过 OpenAI classifier。
在开源模型实验中,作者对 LLaMa-13B 和 GPT-NeoX-20B 生成的数据重复了上述分析。训练型检测器在这些模型上的 AUROC 和 TPR 普遍偏低,说明其训练集几乎没有覆盖这些模型的输出风格;DNA-GPT 则在大多数组合上表现优于基线,尽管在部分任务上白盒得分略有下降。
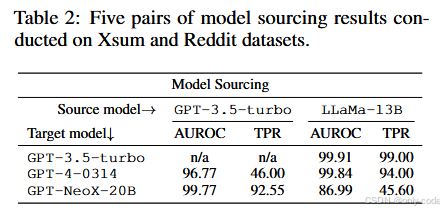
最后,模型溯源实验展示了 DNA-GPT 的一个附加能力。作者假设一段文本由某个模型生成,但检测者并不知道是哪一个,于是对候选模型集合中的每个模型都运行一遍 DNA-GPT 管道,比较得分高低。结果显示,在 XSum 和 Reddit 数据上,当真正的生成模型是 GPT-3.5-turbo 时,DNA-GPT 能以接近 100% 的 AUROC 把它与 LLaMa-13B 区分开;在 GPT-4 与其它模型的区分上,性能也非常可观。这一实验说明,DNA-GPT 所捕捉到的“文本 DNA”在不同模型之间确实存在差异,并不仅仅是“人 vs 机器”的二元对立。
8. 亮点与创新点总结
从方法论角度看,DNA-GPT 的最大亮点在于它把“检测”问题转化成了“同一前缀下的续写分布比较”。这一步巧妙地绕开了“我要预测整段文本是 AI 还是人”的困难,而是问:“如果这段文本是 GPT 写的,那么在给定前缀后,GPT 一般会如何续写?原文后缀有多像它自己典型的续写?”这种自举式的设计让方法在原理上非常简洁,却能够充分利用模型自身的统计特性。
第二个突出的创新是训练免。整个流程不需要为检测额外训练任何分类器,只依赖目标模型的生成能力和一些简单的 n-gram / log-likelihood 统计。这不仅避免了训练数据收集和标注的高成本,也让检测器天然兼容新模型和新领域:只要你能调用它的生成接口,就能在同一框架下做检测。
第三个值得强调的点是可解释性。通过收集多次续写中与原文重合的中长 n-gram,DNA-GPT 可以给出“这里有三段十几个词完全一致的片段”的具体证据,而不是一句“判定为 AI 文本”。对于教师、编辑或者审稿人来说,这种证据远比一个分数更具说服力,也有利于后续做人工判断和讨论。
在实验层面,这篇论文系统地把检测问题放在了最新 LLM 的语境下。它同时覆盖 GPT-4、GPT-3.5、text-davinci-003 和主流开源大模型,使用的新数据集刻意避开模型训练期,讨论了温度、截断率、重采样次数、文本长度、语言种类和改写比例等多个维度,构成了一个相对完整的“真实世界检测基准”。这种大规模、面向当前生产环境的评估本身也具有方法论意义。
最后,DNA-GPT 提出并初步验证了“模型溯源”的可能性。相比简单回答“是否 AI”,它尝试回答“更像哪一个模型写的”,这一方向对于未来的内容监管、平台责任划分乃至模型版权问题,都具有潜在价值。
9. 局限性与不足
尽管 DNA-GPT 展示了很强的性能和泛化性,作者在文末也坦率地指出了一些边界条件和风险。
首先,这一方法深度依赖于“目标模型可被调用”这一前提。黑盒检测仍然需要针对每个待检测文本调用模型 K 次,长文本和大规模批量检测会带来显著的时间和经济成本。如果平台限制调用频率或收费较高,DNA-GPT 在实际部署中的可行性会受到制约。
其次,似然差距假设隐含地要求“人类写作在模型眼中与模型自写有明显差别”。随着模型越来越强、训练数据越来越广泛,人类为了规避检测而刻意模仿模型风格的可能性也在上升。一旦大规模人类写作与模型输出在统计上逐渐靠拢,DNA-GPT 所依赖的 n-gram 和 log-likelihood 差异有可能缩小,检测性能理论上会下降。
第三,作者在伦理声明中也强调方法仅在这一长度范围内做过充分测试。对于特别短的文本(如一句话回复)或超长文章,即便可以用滑动窗口处理,单窗内部的上下文不足或跨窗依赖被打断,仍然可能导致检测性能不稳定。
第四,DNA-GPT 默认假设“检测模型与生成模型一致”,即你用 GPT-3.5 写的文本,用的也是 GPT-3.5 来做重采样检测。未知源模型的场景中,作者虽然用 OPT-125M 等代理模型取得了中等效果,但整体性能明显弱于自举式检测。现实世界里,文本可能来自任意一家闭源或开源模型,如何在这类“完全未知源”的条件下保持高性能,是未来需要进一步解决的问题。
第五,从公平性和误用角度看,任何检测器都有被滥用的风险。DNA-GPT 的证据机制在帮助识别 AI 抄写的同时,也可能在缺乏上下文的情况下被当作“铁证”使用,而忽略了模型本身的错误率。论文中虽然提醒用户“证据需谨慎解读、不得简单等同于抄袭判决”,但并未展开更多关于法律和伦理层面的讨论。此外,虽然作者在德语实验中显示出不错的性能,但在更多低资源语言上的偏差和误判情况,仍有待系统评估。
最后,方法本身没有考虑对抗性攻击。比如攻击者可以在 GPT 文本生成后进行有意识的语义保持、结构改写或引入噪音,专门针对长 n-gram 重合设计规避策略。论文利用 T5-3B 的改写实验展示了 DNA-GPT 对“随机局部替换”的鲁棒性,但对“针对检测器的自适应攻击”并未覆盖,这也是未来研究的重要方向。
10. 全文总结
综合来看,DNA-GPT 通过一个看似简单却非常有效的思路——“把文本从中间截断,再让模型多次续写,然后比较原文后缀与模型续写的相似度”——在 ChatGPT 时代为 AI 文本检测提供了一条训练免、可解释且适用于黑盒 API 的新路径。它在方法上依托似然差距假设和发散 n-gram 分析,在实现上只需要调用现有 LLM 接口,不再训练单独的检测模型。
大量实验证明,这一框架在 GPT-3.5/4 以及 LLaMa-13B、GPT-NeoX-20B 等模型上,面对 Reddit 问答、最新科学摘要、医疗问答、新闻摘要和德语翻译时,都能显著优于 OpenAI classifier 和 GPTZero 等训练型检测器;在 text-davinci-003 的白盒场景中,WScore 更是取得了接近完美的检测效果。温度敏感性、改写鲁棒性和非英语实验进一步说明,这种“自重采样 + 相似度打分”的做法具有良好的实用稳定性。
当然,DNA-GPT 也并非银弹。它仍然受限于 API 成本、文本长度、未知源模型和潜在对抗攻击等因素,其理论前提也依赖于当前 LLM 与人类写作之间仍存在的统计差异。然而,就当前阶段而言,这篇论文展示了一种在闭源大模型时代极具现实意义的检测范式:不再把检测器看成一个独立模型,而是把被检测的大模型本身当作“工具”和“证人”,让它通过自己的续写行为暴露出“机器写作的 DNA”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)