每日AIGC最新进展(94):MIT提出实时流式视频生成StreamDiffusionV2、LeCun&李飞飞&谢赛宁联合提出空间超感知Cambrian-S
MIT提出实时流式视频生成StreamDiffusionV2、LeCun&李飞飞&谢赛宁联合提出空间超感知Cambrian-S
目录
StreamDiffusionV2

现有视频扩散模型虽在离线生成中表现出色,但难以适应实时直播流媒体的严格要求。具体而言,有以下四大挑战:
-
一是无法满足实时SLO(如最小化首帧时间和每帧截止期限);
-
二是长时序生成中出现漂移,导致视觉一致性下降;
-
三是在高速动态场景下产生运动撕裂和模糊;
-
四是多GPU扩展性差,无法在异构环境中实现线性FPS提升。
这些问题源于现有系统对离线批处理优化的偏向,而忽略了在线流媒体的无限输入和低抖动需求。本工作通过系统级优化,填补了这一空白。
StreamDiffusionV2,这是一个无需训练的流式系统,它同时实现了实时的效率和长时序的视觉稳定性。从高层次来看,本工作的设计基于两个关键的优化层面:(1)实时调度与质量控制,它协同整合了服务等级目标(SLO)感知的批处理、自适应的sink与RoPE刷新、以及运动感知的噪声调度,以满足每帧的截止期限,同时维持长时序的时序连贯性和视觉保真度;(2)可扩展的pipeline编排,它通过跨去噪步骤和网络阶段进行并行化,以实现近线性的FPS扩展,且不违反延迟保证。此外,还探讨了数个轻量级的系统级优化,包括DiT块调度器、Stream-VAE和异步通信重叠,它们进一步增强了长时间运行的直播流的吞吐量和稳定性。
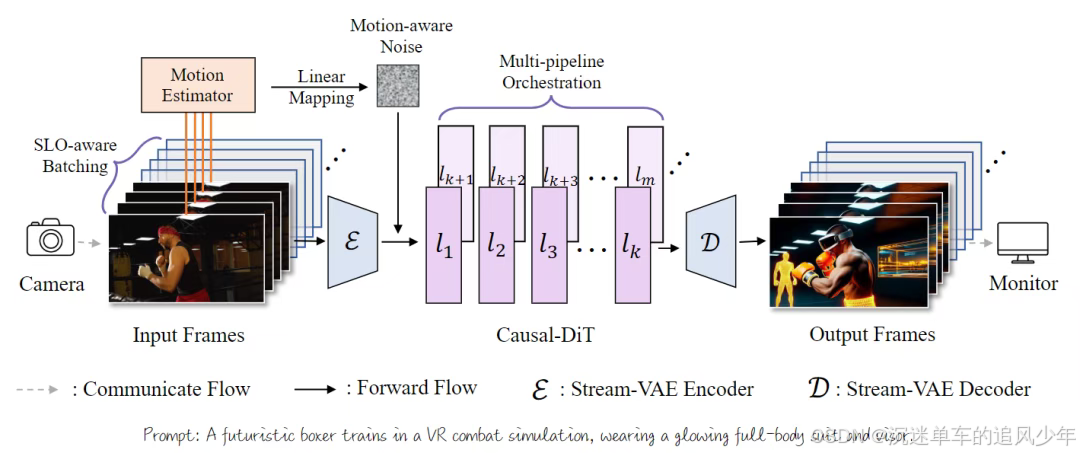
多pipeline编排扩展 (Multi-pipeline orchestration extension) 。为了在多GPU平台上提升系统吞吐量,本文提出了一种可扩展的pipeline编排方案用于并行推理。具体来说,DiT的模块被划分到不同的设备上。如图7所示,每个设备将其输入序列作为一个微步(micro-step)进行处理,并在一个环形结构内将结果传输到下一个阶段。这使得模型的连续阶段能够以pipeline并行的方式并发运行,从而在DiT的吞吐量上实现近线性的加速。
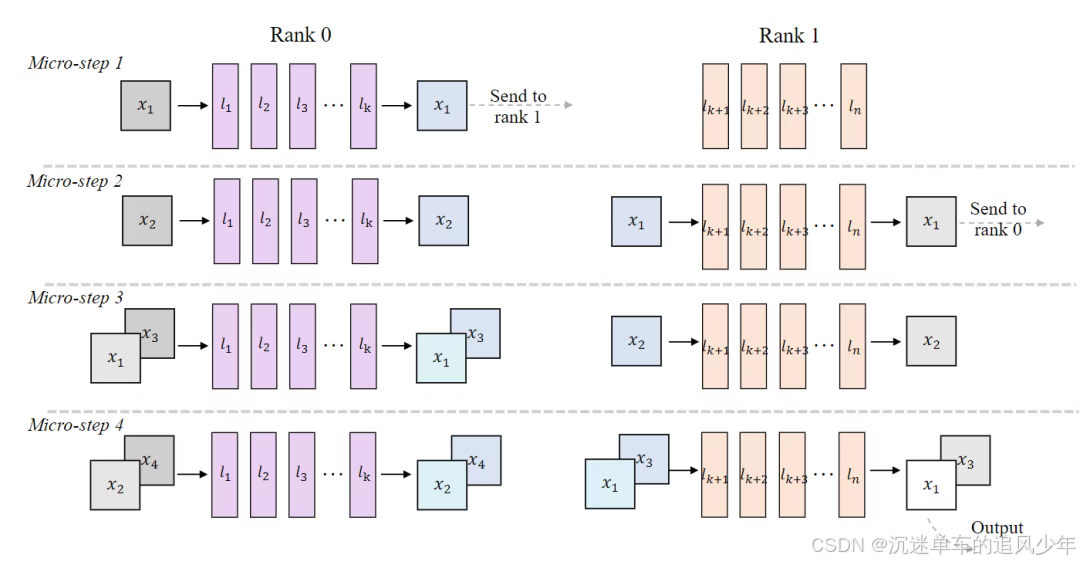
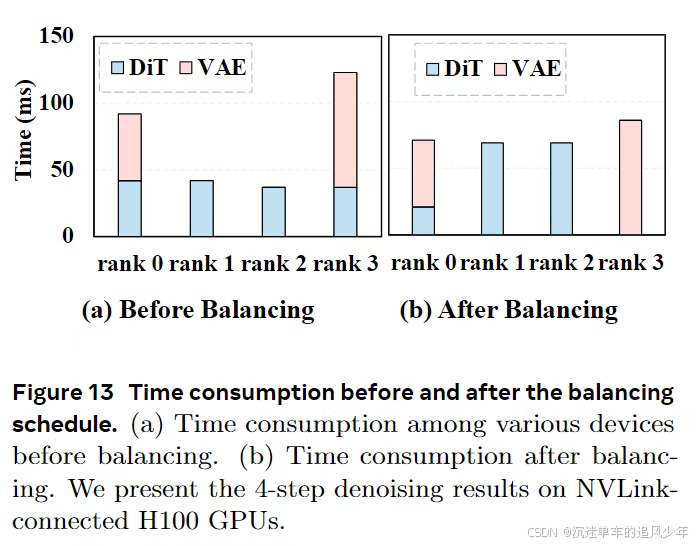
值得注意的是,pipeline并行推理增加了阶段间的通信,这与激活流量一起,使得工作负载保持在内存受限状态。为了应对这一点并仍然满足实时约束,本文将SLO感知的批处理机制扩展到了多pipeline设置,并将其与批-去噪策略相结合。具体地,本文在每个微步(图7)都会产生一个精细去噪的输出,同时将n个去噪步骤视为一个有效的批次乘数,从而得到一个精炼的延迟模型 。调度器会根据观察到的端到端延迟持续调整B,以使每个流的速率满足 ,而聚合的吞吐量则逼近带宽的屋顶线。
Stream-VAE。StreamDiffusionV2集成了一个为流式推理设计的低延迟Video-VAE变体。Stream-VAE不是编码长序列,而是处理短的视频块(例如4帧),并在每个3D卷积内部缓存中间特征,以维持时序的连贯性。
异步通信重叠 (Asynchronous communication overlap) 。为了进一步减少同步停顿,每个GPU都维护两个CUDA流:一个计算流和一个通信流。GPU间的传输是异步执行的,与本地计算重叠以隐藏通信延迟。这种双流设计使每个设备的计算节奏与其通信带宽保持一致,有效地缓解了残余的气泡,并在多GPUpipeline中保持了高利用率。
Cambrian-S
让多模态模型像人类一样在视频中建立3D空间认知并进行预测性世界建模,而不再局限于“看图说话”或暴力记忆。
文章指出,现有大语言模型(LLM)在真正的空间推理任务上存在系统性缺陷,于是团队构建了:
-
VSI-590K 数据集:59 万段带 3D 标注的视频样本;
-
VSI-SUPER 基准:包含长时视觉空间回忆(VSR)和持续空间计数(VSC)两项任务,考察模型对数小时视频中物体位置、数量变化的记忆与推理能力;
-
Cambrian-S 系列模型:5 亿–70 亿参数规模,经过四阶段训练(图像对齐→图文指令→视频指令→空间指令),在 VSI-SUPER 上相对基线最高提升约 30%,小模型也能保持强劲表现。
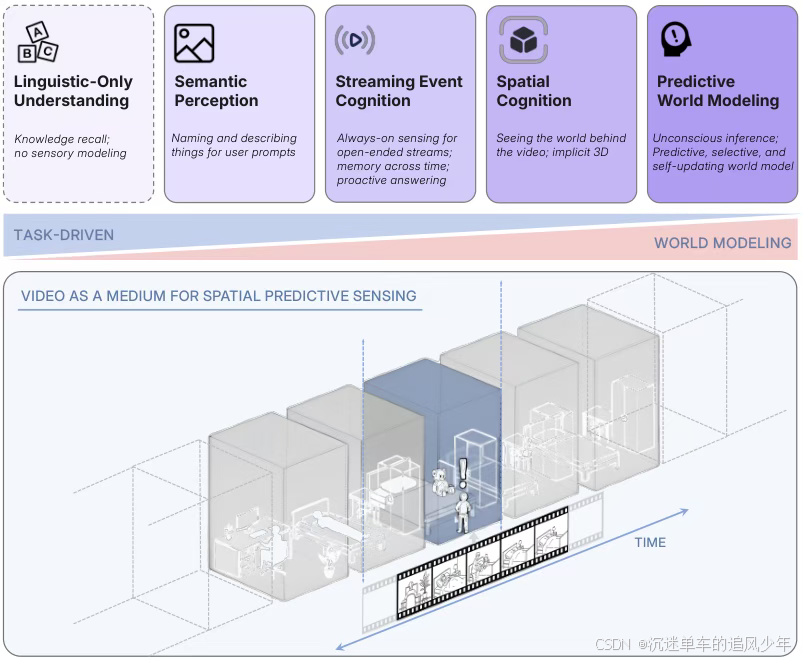
研究指出,当前顶尖的多模态大语言模型(MLLMs)在理解视频时,本质上可能更像在阅读图文摘要,而非真正理解三维空间。
我们以为AI在看视频,但它们处理的往往是几张孤立的、被抽取的帧。
研究团队提出了一个全新的概念——空间超感知(Spatial Supersensing),旨在推动AI从被动的模式识别,进化到主动地理解和预测我们身处的这个三维世界。
多模态AI正试图摆脱对海量上下文的暴力记忆,转而学习人类大脑高效处理信息的根本机制:预测。
当前范式的局限,促使研究团队探索一条全新的路径——预测性感知(Predictive Sensing)。
这个想法的内核是,模型不应该只是被动地接收和处理信息,而应该主动地预测接下来会看到什么。当现实与预测产生偏差,即出现惊喜时,模型就利用这个信号来指导自身的注意力、记忆和学习。
研究团队提出了一个基于自监督学习的、预测下一帧画面的概念验证方案。模型利用预测误差,也就是惊喜,来做两件关键的事:管理记忆,以及分割事件。
在VSI-SUPER Recall(大海捞针)任务中,他们设计了一个惊喜驱动的记忆管理系统。
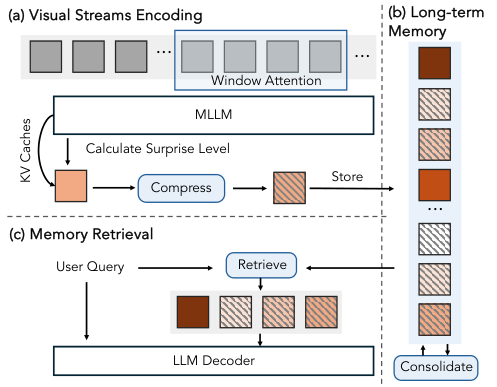
系统会持续监控模型的预测误差。当检测到强烈的惊喜信号时,比如画面中突然出现了一只本不该在客厅里的泰迪熊,系统就会将这个意外事件及其相关信息存入一个长期记忆库。
这完美模拟了人类的注意力机制。
我们更容易记住那些出乎意料的事情。通过这种方式,模型能高效利用有限的记忆资源,只存储那些最关键、最反常的信息。
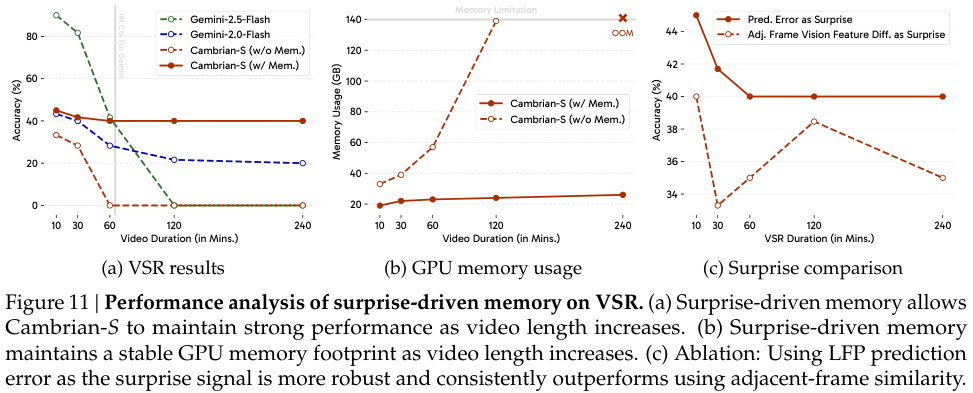
实验证明,在长达数小时的视频中,这种方法的性能远超传统的长上下文模型,后者的性能会随着视频长度的增加而急剧衰减。
在VSI-SUPER Count(跨场景计数)任务中,惊喜信号被用来做持续的视频分割。
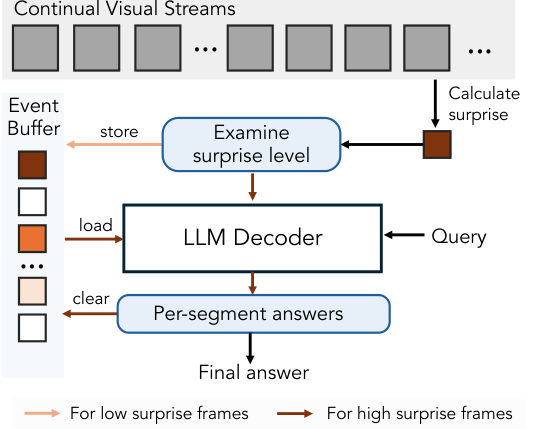
当预测误差飙升时,比如镜头从一个房间切换到另一个房间,或者一个新物体进入视野,系统就认为这是一个自然的事件边界。
它将漫长的视频流自动切分成一个个有意义的、更易于管理的事件片段。
模型可以对每个片段进行独立的计数处理,然后将结果汇总,从而在复杂的长视频中保持计数的准确性和一致性。
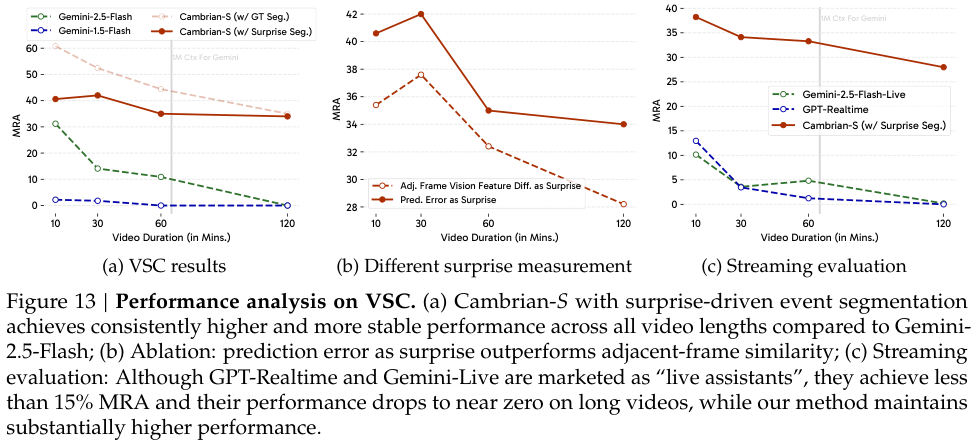
实验结果同样显示,这种方法的表现显著优于其他基线方法。
将预测性感知与传统的长视频处理方法,如扩大上下文窗口、均匀采样、关键帧提取等进行比较,在新提出的VSI-SUPER两个任务上,预测性感知都取得了压倒性的优势。
尤其是在超长视频上,它的性能保持相对稳定,而其他方法的性能则早已崩溃。
这一系列研究和实验,从提出空间超感知的理论框架,到揭示现有基准的不足,再到构建新基准和新模型,最终指向了一个激动人心的新范式。
通往真正机器智能的道路,需要的或许不是让AI看得更多,而是让它学会像我们一样,主动地去预测和理解这个世界。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)