灵巧和具身机器人操作的发展与挑战:综述
25年7月来自浙大的论文“The Developments and Challenges towards Dexterous and Embodied Robotic Manipulation: A Survey”。实现类人灵巧的机器人操作一直是机器人领域的核心目标和关键挑战。人工智能(AI)的发展推动机器人操作的快速进步。本文概述机器人操作从机械编程到具身智能的演变历程,以及从简单夹爪到多指灵巧
25年7月来自浙大的论文“The Developments and Challenges towards Dexterous and Embodied Robotic Manipulation: A Survey”。
实现类人灵巧的机器人操作一直是机器人领域的核心目标和关键挑战。人工智能(AI)的发展推动机器人操作的快速进步。本文概述机器人操作从机械编程到具身智能的演变历程,以及从简单夹爪到多指灵巧手的过渡,并重点阐述其关键特征和主要挑战。着眼于具身灵巧操作的当前阶段,着重介绍两个关键领域的最新进展:灵巧操作数据采集(通过仿真、人类演示和远程操作)和技能学习框架(模仿和强化学习)。然后,基于对现有数据采集范式和学习框架的概述,总结并讨论制约灵巧机器人操作发展的三个关键挑战。
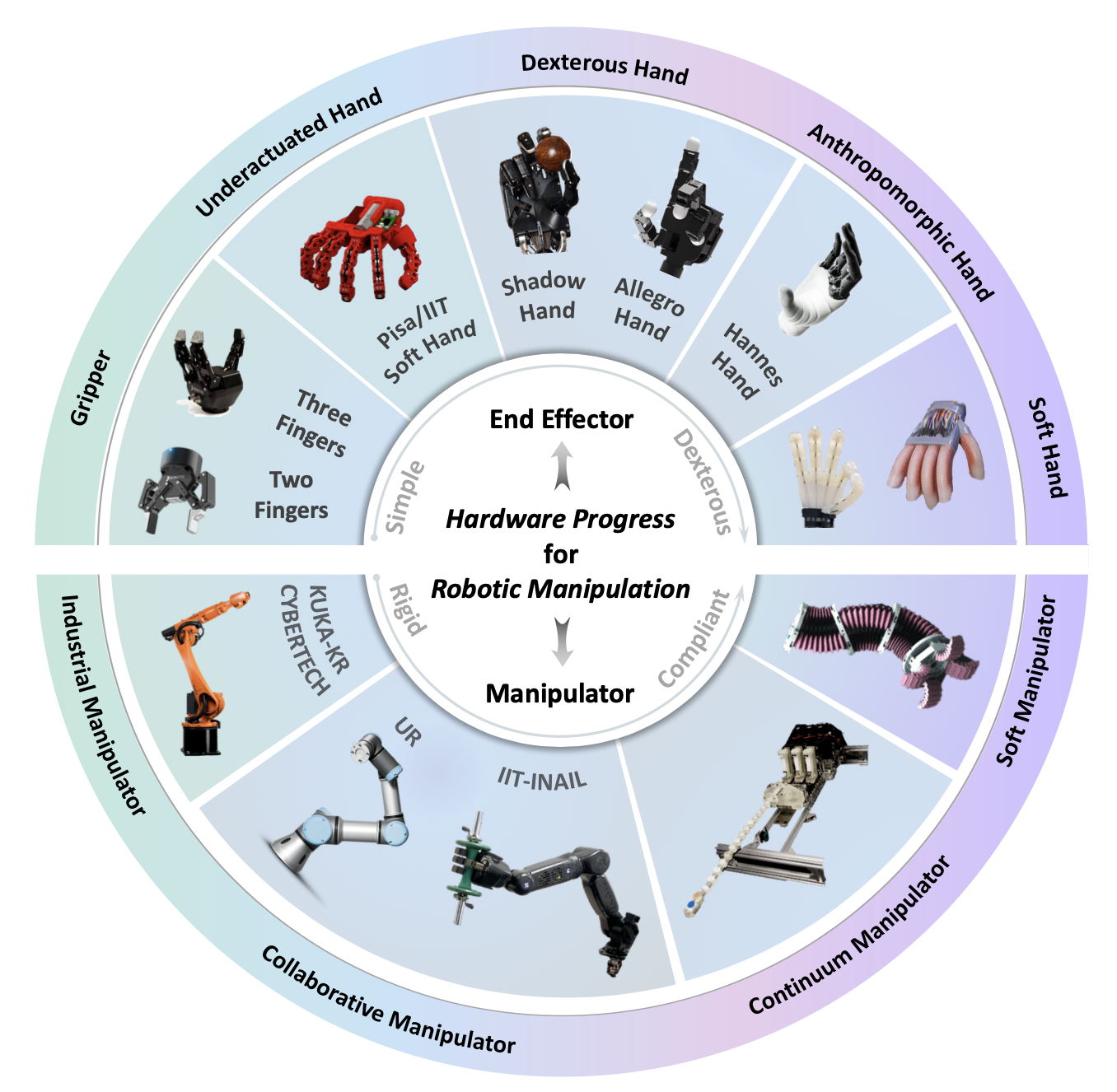
近年来,机器人技术取得长足的进步。为了给机器人灵巧操作奠定坚实的基础,不仅需要提高机器人的柔顺性和稳定性,还需要提高末端执行器的灵巧性。如图所示,机器人已从传统的工业机械臂逐步发展到能够与人类和不确定环境进行交互的协作机械臂[3]。同时,也出现一些特殊设计的机器人,例如能够连续变形为所需形状的连续体机械臂[4]和由特殊软材料制成的软体机械臂[5]。机器人的末端执行器也从最简单的平行夹爪发展到多指夹爪[6]、软体欠驱动手[7]、刚性灵巧手[8]以及全驱动高度拟人化手[9]。与此同时,随着软体机器人技术的发展,一些软体抓手和软体手也逐渐发展成熟[10][11]。这些进步为机器人灵巧操作提供了坚实的硬件基础,极大地提高了机器人的操作能力。
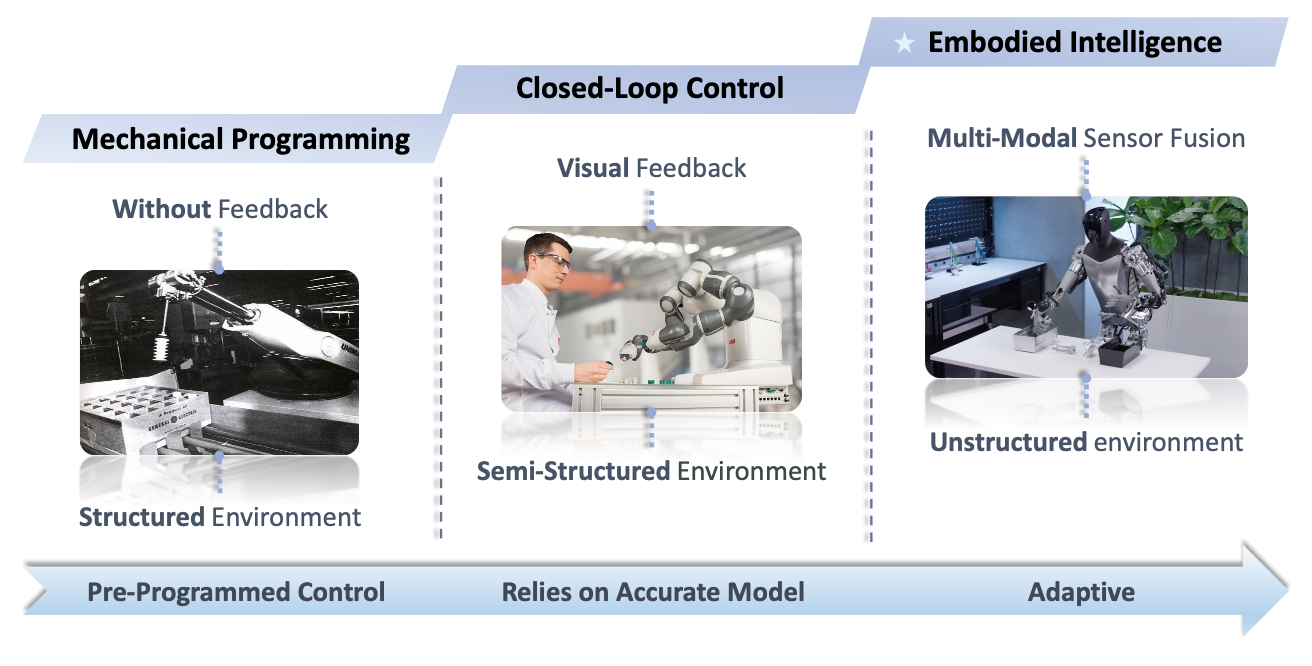
近年来,人们逐渐达成共识,认为没有物理实体的非具身智能最终会达到极限,而与物理实体(例如机器人)交互的具身智能是实现通用人工智能的唯一途径[21]。机器人操作的发展可以分为三个阶段,如图所示:
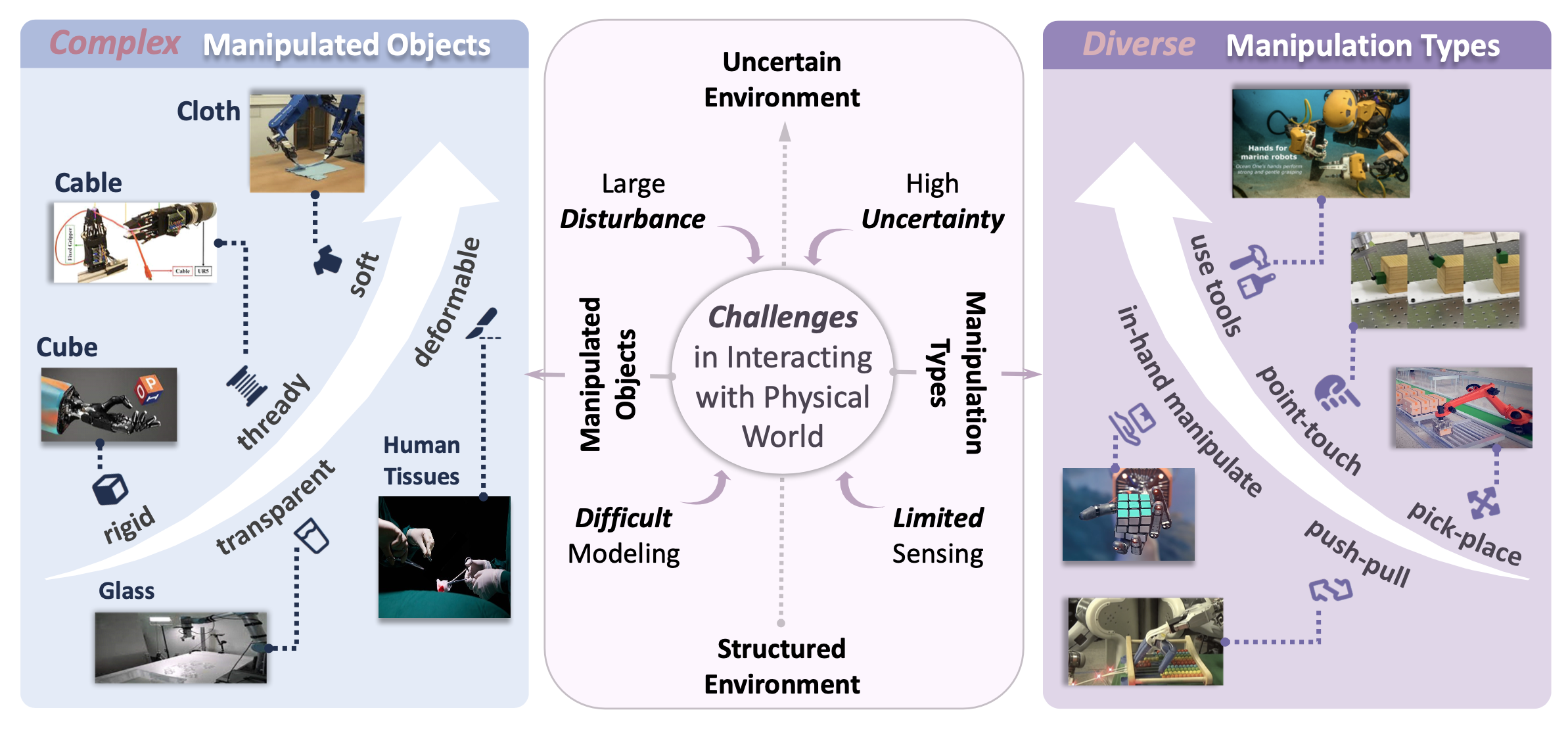
在具身智能操作阶段,与物理世界交互的复杂性是机器人操作面临的严峻挑战的主要来源。随着机器人走出结构化的工厂环境,其操作目标也从传统的刚性工件转变为难以感知或建模的复杂物体。如图所示,机器人操作线性体(例如电缆)[25]、透明体(例如眼镜)[26]、柔软体(例如布料)[27][28]以及可变形体(例如医疗手术中的人体组织)[29]都极具挑战性。当机器人与物理世界交互时,除了操作目标日益复杂之外,机器人操作的类型也变得更加多样化。除了基本的拾取放置操作外,交互还需要多种机器人操作类型,例如依靠单点接触实现复杂物体运动的点触滑动操作[30]、推拉操作(例如转动算盘和开关开关)[31]、仅依靠单手实现物体旋转的单手操作[32]以及各种场景下的灵巧操作(例如开关阀门、抓取物体和使用工具)[33]。复杂物体和多样化的操作使得机器人操作在建模难度大、不确定性高、干扰大以及感知能力有限等方面面临诸多挑战,这极大地影响了机器人技术的进一步发展和应用。
从机械编程阶段、闭环控制阶段到具身智能阶段,在人工智能的支持下,机器人操作取得了显著成果。海量高质量数据集是当前基于深度神经网络的人工智能框架的重要基石。当人工智能从局限于网络空间的脱离实体的智能扩展到强调与真实物理世界交互的具身智能时,如何获取海量交互数据成为实现具身智能的关键。如表所示,收集海量交互数据主要有三种范式:基于仿真平台的数据生成、基于人类演示的数据采集以及基于远程操作演示的数据采集。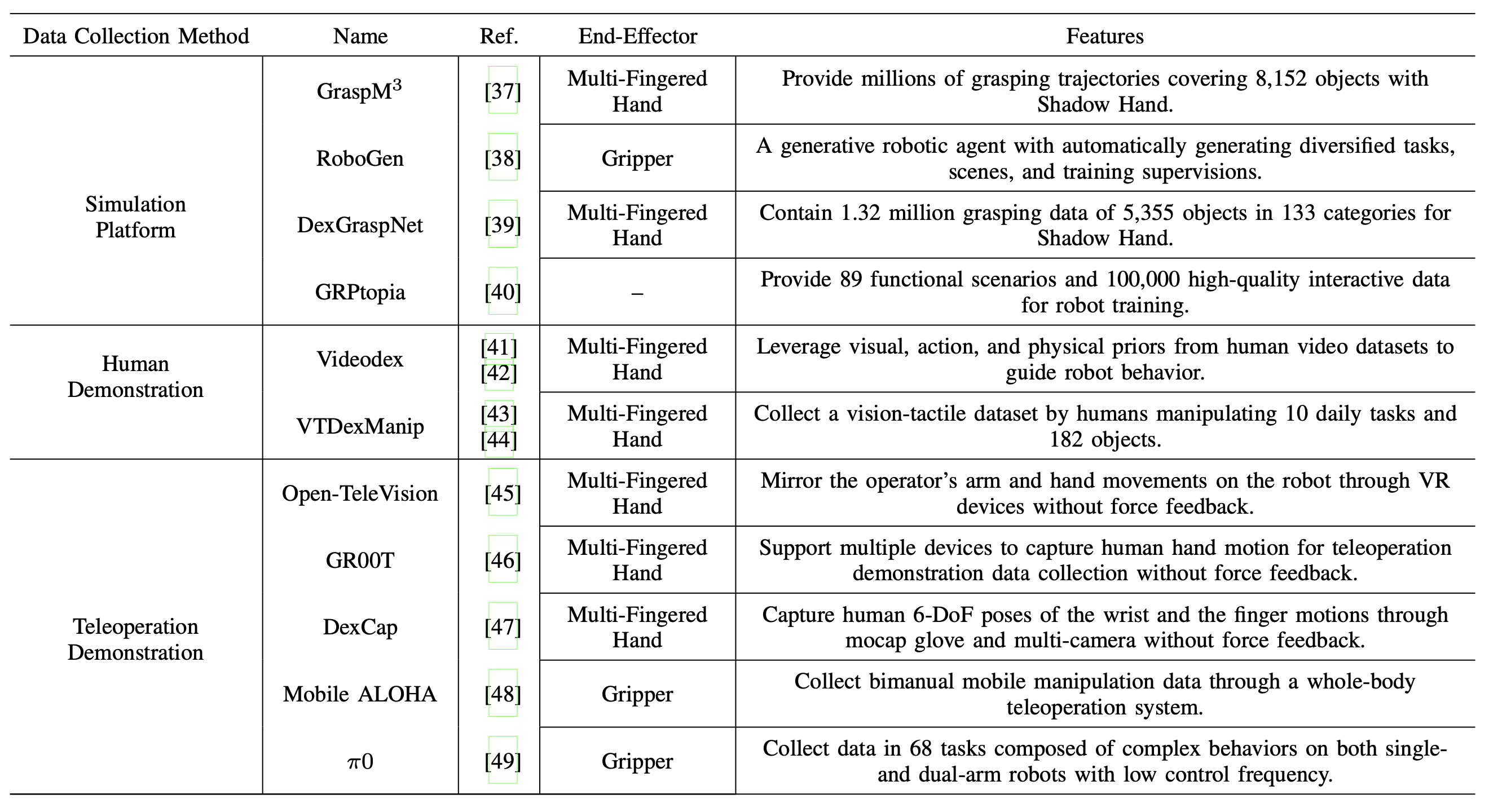
基于仿真平台的数据生成
面对复杂多样且高度不确定的应用场景,传统的依赖“机器人-环境”交互来获取智能的学习方法通常需要数百万次迭代才能学习到有用的技能,效率普遍较低。因此,最常用的方法是利用仿真平台生成大量数据以提高效率。基于仿真平台的数据生成具有一些独特的优势。首先,在仿真平台上生成数据可以避免现实世界中重复实验的高昂成本和潜在风险。其次,仿真平台能够高效、经济且可重复地生成大量具有比较意义的谱系数据。这可以增强数据集的多样性并提高生成数据的质量。最后,仿真平台可以通过改变仿真环境中的时间流速来加速在现实世界中可能需要更长时间的数据采集。
目前,已经开发出一些基于物理引擎的仿真数据集,例如 Genesis [50]、Isaac Sim、PyBullet [51] 和 MoJoCo [52]。例如,GraspM3 [37] 仿真数据集提供了数百万条抓取轨迹,涵盖 8152 个物体;生成式机器人智体 RoboGen [38] 可以无限生成数据。Wang [39] 为 Shadow Hand 生成大规模仿真数据集 DexGraspNet,其中包含 133 个类别、5355 个物体的 132 万条抓取数据。上海人工智能实验室 [40] 发布了城市级具身智能仿真平台 GRPtopia,可提供 89 个功能场景和 10 万条高质量交互式数据用于机器人训练。
这些工作极大地促进了机器人操作能力,尤其是抓取能力的提升。然而,这种范式的不足之处也十分明显。首先,仿真环境与真实环境之间存在各种偏差,例如摩擦力建模和空气阻力建模的不准确。这将不可避免地引入仿真到现实(Sim2Real)的鸿沟,使得基于仿真数据训练的模型难以直接迁移到真实机器人上。其次,对于某些复杂物体(例如可变形体和柔性体)的仿真,当前物理引擎的性能仍然不尽如人意。此外,这些物体的计算通常需要大量的计算资源和计算时间。因此,基于仿真平台生成数据的范式仍然难以取代从真实世界采集的数据。
来自人类演示的数据采集
机器人操作的最终目标是赋予机器人类似人类的灵巧操作能力。因此,直接从人类示范动作中学习操作技能已成为一种极具吸引力的解决方案。虽然基于人体运动示范的数据采集规模无法与仿真生成的数据相提并论,但它相比于使用真实机器人进行重复试验,显著降低了难度,并且无需机器人硬件即可扩大数据采集范围。同时,与仿真生成的数据相比,人体示范数据是在物理环境中产生的真实交互数据,可以极大地缩小仿真与现实之间的差距。例如,Bahl[41][42]提出从互联网上广泛存在的数十亿个视频数据中提取人体运动和关键交互元素,从而实现基于人体示范的操作数据采集。Liu[43][44]也开发一种视觉-触觉融合的人体运动捕捉系统,构建VTDexManip数据集。这些工作增强机器人在真实物理环境中的操作能力。
然而,就驱动传输效率和能量密度而言,目前的机电一体化系统与人体肌肉骨骼系统相比仍然相形见绌。因此,机器人系统与人体之间,尤其是人手与机器人手之间,仍然存在显著的形态差异。在有限的空间内实现与人手相当的高自由度仍然是一个巨大的挑战。目前的机器人灵巧手与人手在结构上仍然存在很大差异。例如,Allegro 手只有四个手指,而且每个手指都比人手的手指大得多。虽然 Shadow 手的手指与人手一样纤细,但其背部有一个巨大的驱动箱,这严重限制了手的可及范围。如图展示这些多指灵巧手与人手的对比。很明显,人手与多指灵巧手在手指尺寸和结构上存在巨大差距。由于人类和机器人之间存在这些差异,很难直接将人类的演示数据复制到机器人上,从而造成人机差距。
远程操作演示的数据采集
为了解决仿真与现实之间的差距以及人机交互之间的差距,远程机器人系统成为一种更高效的解决方案。远程机器人系统可以通过人机共享控制[53]将人类智能融入机器人操作中,同时严格遵守机器人固有的运动学/动力学约束。这可以有效缓解其他数据采集范式中固有的仿真与现实之间的差距以及人机交互之间的差距。近年来,多个团队开发了基于远程机器人系统的数据采集系统。
然而,现有系统仍然面临以下问题。首先,目前大多数远程机器人系统都是仅基于视觉反馈的“弱耦合”系统,缺乏力反馈和触觉反馈。例如,麻省理工学院和加州大学圣地亚哥分校联合开发的Open-TeleVision系统[45]、NVIDIA利用Vision Pro的GR00T系统[46]以及DexCap系统[47]。然而,在一些接触密集型任务中,人类的力和触觉经验难以有效地融入到采集的数据中[54][55]。其次,目前大多数远程机器人系统基于双指夹爪,缺乏来自多指灵巧手的高自由度数据集,例如Mobile ALOHA[48]和π0[49]。然而,如何在狭小空间内实现具有20个以上自由度的人手的精确运动捕捉和力反馈仍然是一个具有挑战性的问题[56]。与仅涉及末端执行器力交互的传统远程机器人系统不同,多指灵巧远程操作引入了多点接触以及机器人手指与物体之间复杂的动态交互。这种复杂性给系统稳定性和透明度分析带来了新的挑战,迫切需要新的理论框架和分析方法。最后,现有的远程操作系统存在超过几十毫秒的延迟,系统敏捷性远未达到要求。作为机器人学最早的研究方向之一,传统的远程机器人系统通常侧重于解决远距离通信引起的延迟问题[57]。然而,具身智能操作的数据采集对远程机器人系统的敏捷性提出了新的要求。如何保证远程机器人系统的敏捷性仍然是一个尚未得到充分研究的关键问题[58][59]。
机器人操作技能学习框架主要分为两大类:模仿学习(IL)和强化学习(RL)。如表所示,列出不同模仿学习和强化学习的特征。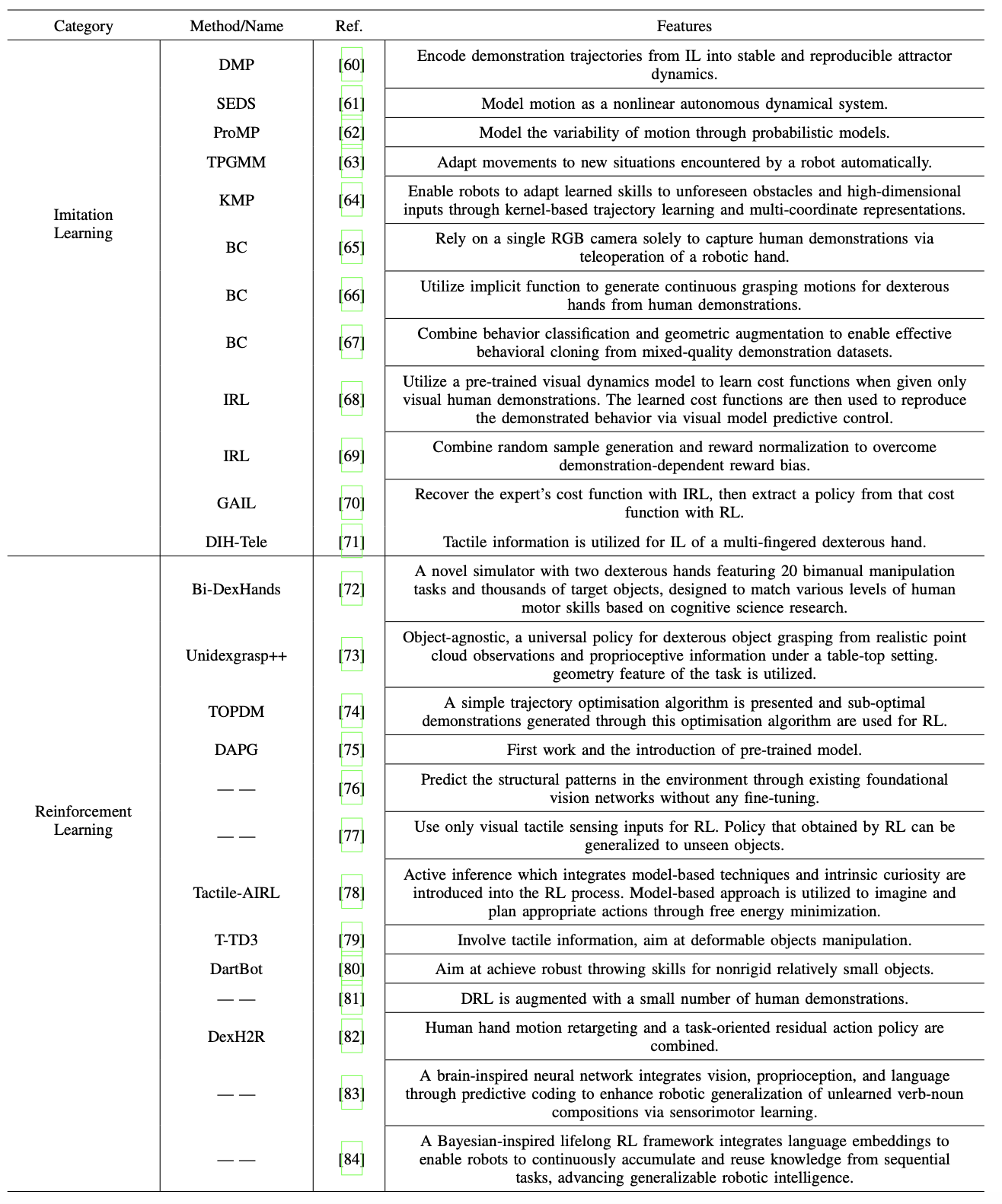
模仿学习
模仿学习可以分为两个子类。
第一类是利用高斯混合模型(GMM)和高斯混合回归(GMR)对人类演示数据进行概率建模。在技能复现过程中,轨迹会被参数化和优化,以匹配学习到的概率模型,从而确保复现的运动保留类人特征。与深度学习和强化学习相比,这种方法只需要极少的训练数据,无需先验知识,同时避免了对大型神经网络的依赖,并提供了更好的数学可解释性。常用的方法包括动态运动基元(DMP)[60]、动态系统稳定估计器(SEDS)[61]、概率运动基元(ProMP)[62]、任务参数化高斯混合模型(TPGMM)[63] 和核化运动基元(KMP)[64]。然而,这些方法主要适用于简单的轨迹复现,难以处理涉及复杂视觉-触觉信息的交互任务。它们的应用也主要局限于机械臂和双指夹爪的单任务学习,很少扩展到多指灵巧手。
智能学习的第二个子类采用深度学习来训练策略网络,以模拟人类专家的决策。与强化学习不同,这种方法不依赖于环境交互或奖励,而是从预先收集的数据集中学习。常用方法包括行为克隆(BC)[65]–[67]、[71]、逆强化学习(IRL)[68]、[69]和生成对抗模仿学习(GAIL)[70]。这些方法的一个主要局限性在于,它们只能从演示数据中学习静态行为,无法像强化学习(RL)那样超越人类的表现。此外,当遇到训练分布之外的状态时,它们的性能会显著下降,凸显了鲁棒性问题。
强化学习
强化学习(RL)已成为机器人灵巧操作技能学习的主流方法,它使智体能够与环境交互,并通过奖励反馈来优化策略。近期研究开发了专门的仿真环境(例如,用于双手操作的Bi-DexHands)[72],以及用于机器人控制的强化学习方法。与传统的反馈控制方法相比,强化学习已成功解决具有挑战性的操作技能问题[73]、[74]、[85]。然而,由于多指灵巧手的高自由度和复杂的接触动力学,将强化学习应用于多指灵巧手面临着独特的挑战[86]。仅依赖于智体-环境的纯强化学习通常存在奖励稀疏和样本效率低的问题,通常需要数百万次迭代才能学习到有用的行为。探索过程也可能导致不连贯或不安全的动作,从而难以达到预期的学习结果。
为了提高学习效率,近期研究利用预训练模型提取的特征来指导下游机器人任务[75]、[76]。利用现有的预训练模型,结合海量的互联网数据,可以快速高效地学习新任务。在机器人强化学习(RL)中,这种预训练范式具有关键优势:机器人可以利用公开数据和预训练模型,在极少的人工干预下习得新技能。与模仿学习(IL)类似,触觉信息也非常有用。Su [77]利用强化学习训练机器人,仅使用本体感觉和触觉信息即可将物体旋转到目标方向。Liu [78]提出一种名为TactileAIRL的新框架,用于机器人灵巧操作技能的学习。该方法将基于模型的技术和内在好奇心融入强化学习过程,并利用基于视觉的触觉传感来提取有意义的接触特征。这种设计使得TactileAIRL能够扩展到许多涉及触觉反馈的操作任务学习。Zhou等人提出了一种名为T-TD3的强化学习框架,利用触觉先验信息实现对可变形物体的稳定抓取[79]。Aslam [80]介绍一种名为 DartBot 的机器人,它融合触觉探索和强化学习 (RL),通过投掷任务实现在物体转移中稳健的投掷技能。
除了上述方法外,为了提高强化学习的效率,近期的研究重点在于将人类先验知识融入强化学习中。一些研究利用高质量的专家演示来加速训练,例如 Rajeswaran [81] 提出的 DAPG 方法。另一些研究,例如 DexH2R [82],则采用人机交互框架,由操作员在训练过程中提供纠正性反馈。类似地,加州大学伯克利分校的交互式系统也采用了这种方法,在学习过程中,系统会持续检查来自人类操作员的潜在纠正,并在检测到调整时离线更新策略 [87]。研究表明,这种人为干预能够使机器人更有效地从错误中学习,从而显著提高其性能。
虽然这些方法提高了学习效率,但目前的实现依赖于弱耦合、离散的人类监督,而不是连续、紧密集成的指导。大多数强化学习方法侧重于单任务学习,难以应对需要组合技能的长水平序列任务。长水平序列任务由相互关联的单任务组成。然而,尽管强化学习关注最终结果(例如,奖励最大化或目标达成),但它难以学习任务之间的转换条件。
最近的研究开始探索长水平序列任务中的技能组合,例如语言引导的技能组合。Meng[84]提出了用于终身学习的LEGION框架,该框架利用贝叶斯非参数模型和语言嵌入方法。这种方法使机器人能够在连续执行任务的过程中逐步积累知识。通过有效地整合和重用已获得的知识,该框架有助于解决复杂的长期任务。然而,这些进展仍然局限于简单的机械臂,而多指灵巧手的技能组合性仍未得到充分探索。对于多指灵巧手,Helix框架提出将系统1(快速反应控制)和系统2(较慢的深思熟虑推理)相结合,以模拟人类的认知系统。但如何在实践中实现这一概念仍然具有挑战性。如何构建多指灵巧手的技能库,如何实现多种技能的组合,这些问题仍待进一步研究。
赋予机器人类似人类的灵巧操作能力一直是机器人领域研究人员的重要目标。自Unimate机器人早期在结构化工厂环境中执行预编程的取放任务以来,机器人灵巧操作经历三个关键阶段的发展:机械编程阶段、闭环控制阶段和具身灵巧操作阶段。尽管每个阶段都取得显著进展,但机器人灵巧操作能力仍然远逊于人类,尤其是在多指手方面。下图总结并概括阻碍这一进展的几个关键挑战: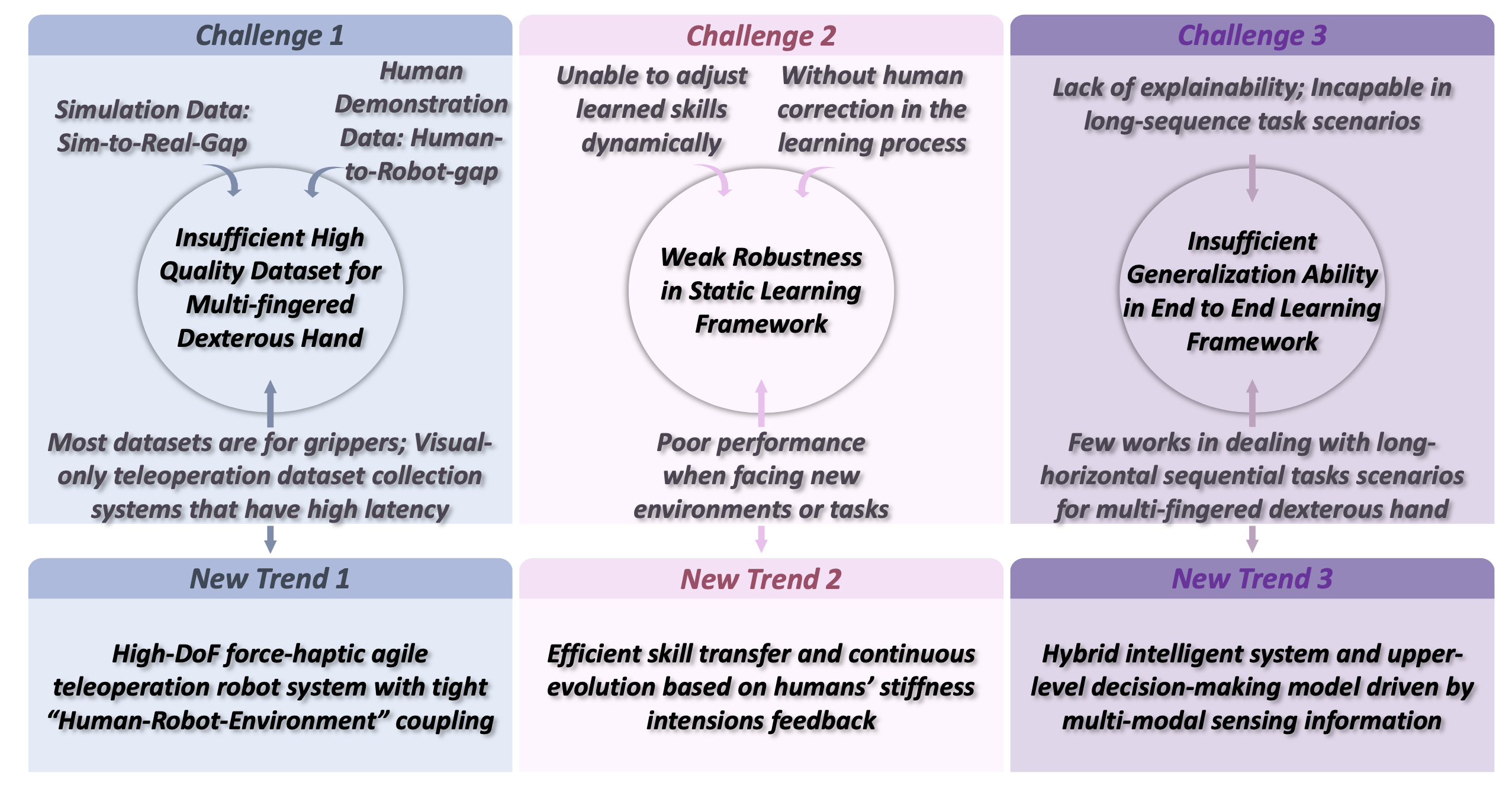

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献130条内容
已为社区贡献130条内容

所有评论(0)