【AI大模型面试】大模型经典面试题——如何评估大模型微调效果?一文讲清!建议收藏!!
“如何评估大模型微调效果?”这个问题在面试中出现的频率极高,在真实的工业场景下微调好的模型不一定能够达到使用标准,因此评估微调模型的效果几乎是每个大模型技术人的必备技能。在真实的工业环境中微调效果的评估往往都是人工评估+自动化评估两条腿走路。
一、面试题:如何评估大模型微调效果?
1.1 问题浅析
“如何评估大模型微调效果?”这个问题在面试中出现的频率极高,在真实的工业场景下微调好的模型不一定能够达到使用标准,因此评估微调模型的效果几乎是每个大模型技术人的必备技能。在真实的工业环境中微调效果的评估往往都是人工评估+自动化评估两条腿走路。
1.2 标准答案
第一段先简明扼要的说明微调效果评估的整体思路以及人工评估的一般方法:
评估大模型微调效果,通常需要结合人工评估与自动化评估两条路径。人工评估的核心,是让专业人员或者目标用户直接去体验模型的输出效果,通过打分、对比和主观判断来衡量模型是否更贴近人类偏好。比如在法律场景中,可以邀请律师对模型的答复进行专业性和准确性评分;在金融场景中,则由分析师判断回答是否具备实用价值。人工评估的优势在于它能真实反映“模型的回答是否符合预期场景’,而不是单纯依赖指标。现在人工评估的门槛已经变低,例如开源的openwebui就内置了模型对比功能,让用户在不知情的情况下同时体验两个不同模型的回答,然后通过选择“更喜欢哪一个”来收集偏好反馈,这种盲测机制非常有效,能真实反映模型优劣。
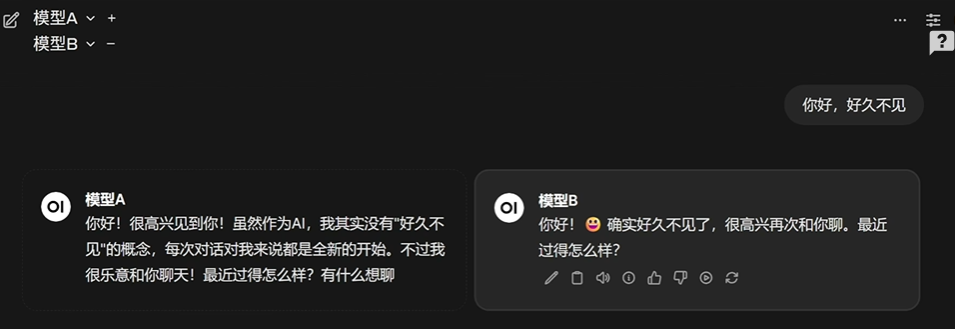
同时现在还有很多权威模型评测榜单,例如LM ARENA,它的排行榜就是通过成千上万用户的匿名打分累计出来的。
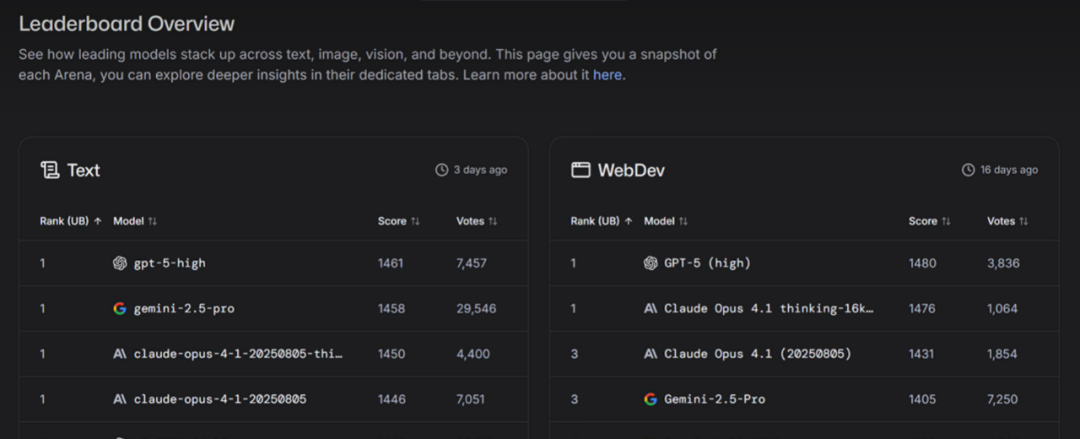
人工评估存在很大局限性,例如会存在主观偏见的问题,对于数学、推理、编程类问题人工评估成本太高。因此模型评估往往还需要借助数据集进行全自动的评估。
第二段主要介绍如何进行数据驱动的评估:
除了人工评估外,我们往往还需要依靠数据集驱动的系统化评估,来评估模型的数学、推理、代码、Agent性能。常见做法是构建一套独立的验证数据集,在微调前后对比模型的各项指标是否发生变化。例如想要验证模型的在数学和推理方面性能,可以使用AIME、GPOA等数据集进行评估,如果想要验证模型的代码能力,可以使用SWE-Bench数据集进行评估,而如果希望验证模型指令跟随或者Function calling能力,则可以IFEval数据集。总的来说,只有把人工评估的主观体验与这些客观数据指标结合起来,我们才能真正全面可靠地判断微调是否达到效果。
第三段还可以补充当前流行的评估框架,例如OpenCompass,EvalScope来表明自己的工程化经验。关于评估工具的使用可参考笔者文章:最强大模型评测工具EvalScope——模型好不好我自己说了算!
二、相关热点问题
2.1 在人工评估微调结果过程中,如何尽量避免偏差?
答案: 人工评估不可避免会受到主观因素的影响,因此要尽量通过多评审员+盲测来降低评审员之间的尺度一致 偏差。多评审员能平衡个体差异,取平均或投票结果更可靠;盲测则可以避免因对模型身份的预期而影响判断。此外,还可以制定统一的评分标准和示例,保证不同评审员之间的尺度一致。
2.2 如何构建用于评估微调效果的验证集或者测试集?
答案: 首先,验证集或者测试集数据需要覆盖模型未来可能面对的各类典型任务场景,例如金融模型就要包含行情解读、风险分析、投资建议等多种类型的问题;其次,要保证样本多样性,避免模型只在某一种题型上表现良好而在真实应用中失效。
2.3 请问通常有哪些工具可以用于快速构建模型评估数据集?
答案: 工程化场景下,往往会考虑使用魔搭社区EvalScope项目,来自动地构建测试数据集,自动评估模型性能并产出分析报告
最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇


面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)