【干货收藏】AI Agent架构革新:代码执行环境与MCP的完美结合实现98.7%Token优化
本文介绍Anthropic提出的MCP创新解决方案,通过代码执行环境与MCP结合,实现98.7%的token使用率降低。文章分析传统工具调用瓶颈,提出将MCP服务器呈现为代码API,并阐述五大核心优势:渐进式工具披露、高效结果处理、强大控制流、隐私保护和状态持久化。这种架构使AI Agent能连接数千工具,处理大数据量,执行复杂工作流,显著降低成本和响应时间。
前言
Anthropic 在 2024 年 11 月推出了 Model Context Protocol (MCP),这是一个连接 AI Agent 到外部系统的开放标准协议。本文是 Anthropic 工程团队在 MCP 推出一年后,针对大规模工具连接场景下的性能瓶颈,提出的创新性解决方案——通过代码执行环境与 MCP 结合,实现 98.7% 的 token 使用率降低。
这不仅是一次技术优化,更是 AI Agent 架构设计理念的重大转变。
🎯 核心问题分析
问题背景:MCP 的快速普及与挑战
MCP 自推出以来取得了惊人的增长:
- 社区构建了数千个 MCP 服务器
- 所有主流编程语言都有 SDK 支持
- 已成为连接 Agent 与工具/数据的事实标准
然而,随着开发者构建连接数百甚至数千工具的 Agent,一个严重的问题浮现:传统的直接工具调用方式导致上下文窗口过载。
问题一:工具定义占用大量上下文空间
传统方式的工作流程
具体案例: 假设你的 Agent 连接了 Google Drive 和 Salesforce 两个 MCP 服务器:
Google Drive 工具定义示例:
gdrive.getDocument
Description:从GoogleDrive检索文档
Parameters:
- documentId (必需,string):要检索的文档 ID
- fields (可选,string):要返回的特定字段
Returns:
包含标题、正文内容、元数据、权限等的文档对象
Salesforce 工具定义示例:
salesforce.updateRecord
Description:更新Salesforce中的记录
Parameters:
- objectType (必需,string):Salesforce对象类型(潜在客户、联系人、账户等)
- recordId (必需,string):要更新的记录 ID
- data (必需,object):要更新的字段及其新值
Returns:
带确认的更新记录对象
问题严重性:
- 当连接到数十个服务器,每个服务器有数十个工具时
- 工具定义可能占用 数十万 tokens
- Agent 甚至还没开始处理请求,就已经消耗了大量资源
- 导致响应时间增加和成本上升
问题二:中间结果消耗额外的 Token
数据流转的低效模式
让我们看一个实际的任务场景:
用户请求:“从 Google Drive 下载我的会议记录,并将其附加到 Salesforce 的潜在客户记录中。”
传统执行流程:
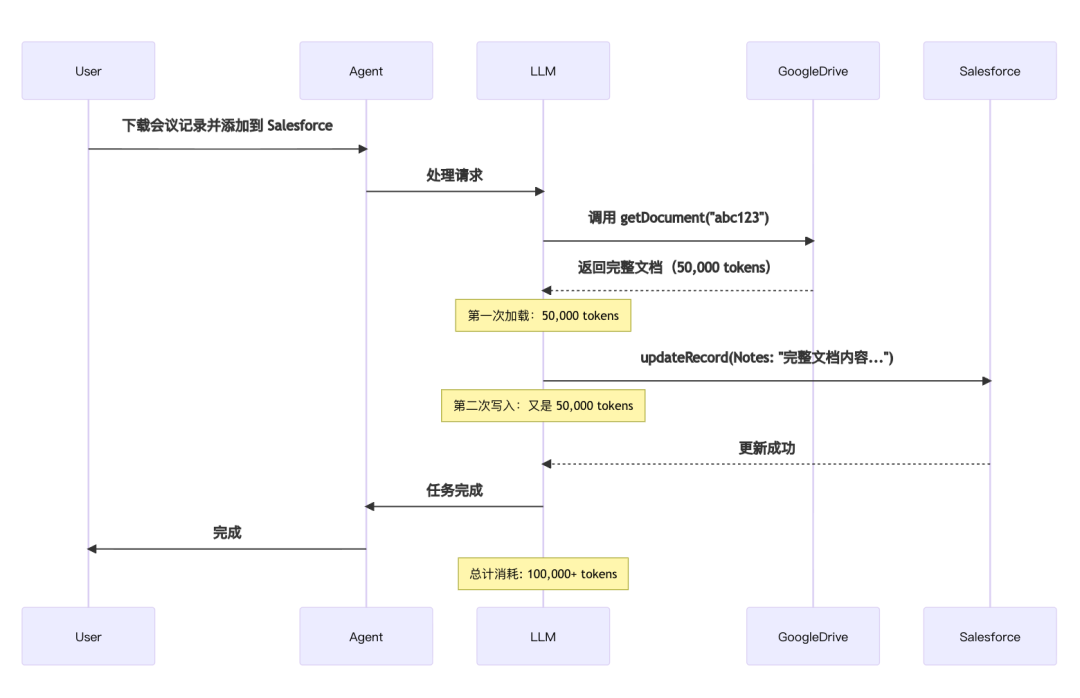
代码示例:
// 第一次工具调用
TOOL CALL: gdrive.getDocument(documentId:"abc123")
→返回"讨论了 Q4 目标...\n[完整的会议记录文本]"
→加载到模型上下文中(50,000 tokens)
// 第二次工具调用
TOOL CALL: salesforce.updateRecord(
objectType:"SalesMeeting",
recordId:"00Q5f000001abcXYZ",
data:{
"Notes":"讨论了 Q4 目标...\n[完整的会议记录文本再次写入]"
}
)
→模型需要将整个记录再次写入上下文(又是50,000 tokens)
问题严重性:
- 对于 2 小时的销售会议,可能需要处理额外的 50,000 tokens
- 更大的文档可能超出上下文窗口限制,导致工作流中断
- 模型在复制大型数据结构时更容易出错
传统架构图
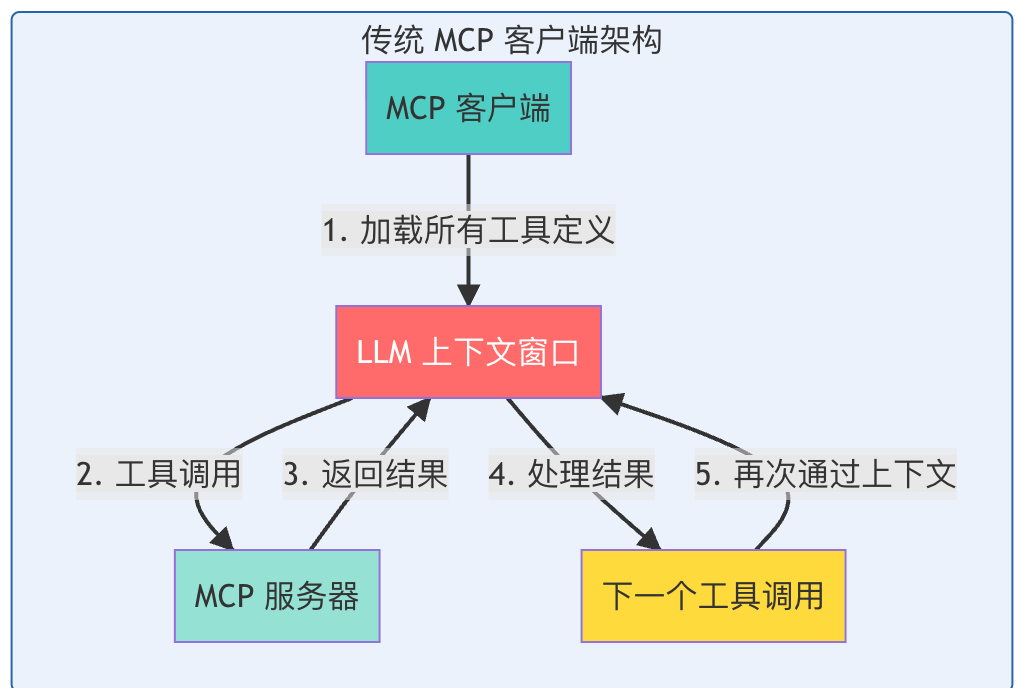
关键问题总结:
- ⚠️ 每个中间结果都必须通过模型
- ⚠️ 数据在工具调用之间重复加载
- ⚠️ 大型文档可能导致上下文溢出
- ⚠️ 增加延迟和成本
💡 解决方案:代码执行与 MCP 的结合
核心理念转变
从 “让 AI 直接调用工具” 转变为 “让 AI 编写代码来调用工具”
这个看似简单的转变,带来了革命性的效率提升。
实现方案:将 MCP 服务器呈现为代码 API
方案一:文件系统树结构
生成一个包含所有可用工具的文件树结构:
servers/
├── google-drive/
│├── getDocument.ts
│├── listFiles.ts
│├── createDocument.ts
│├──...(其他工具)
│└── index.ts
├── salesforce/
│├── updateRecord.ts
│├── queryRecords.ts
│├── createLead.ts
│├──...(其他工具)
│└── index.ts
└──...(其他服务器)
工具文件实现示例
每个工具对应一个文件,包含清晰的 TypeScript 接口:
// ./servers/google-drive/getDocument.ts
import{ callMCPTool }from"../../../client.js";
interfaceGetDocumentInput{
documentId:string;
}
interfaceGetDocumentResponse{
content:string;
}
/** 从 Google Drive 读取文档 */
exportasyncfunction getDocument(
input:GetDocumentInput
):Promise<GetDocumentResponse>{
return callMCPTool<GetDocumentResponse>(
'google_drive__get_document',
input
);
}
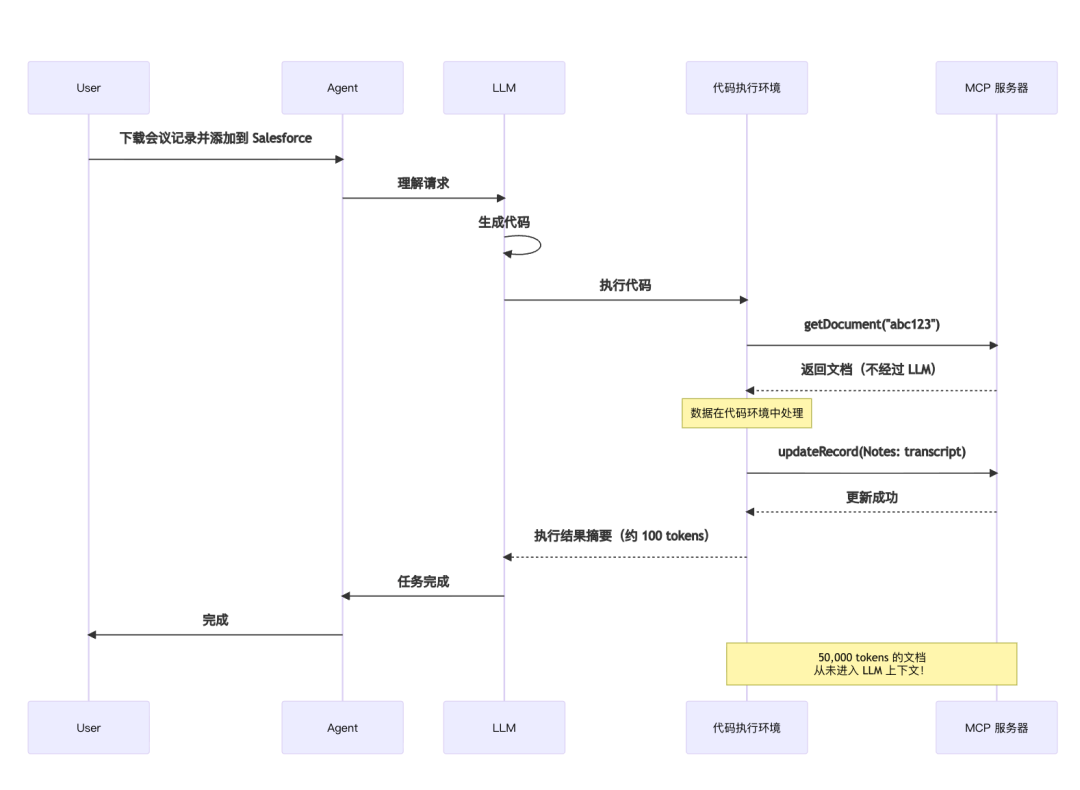
使用代码执行的优化流程
新的执行模式
// 从 Google Docs 读取记录并添加到 Salesforce 潜在客户
import*as gdrive from'./servers/google-drive';
import*as salesforce from'./servers/salesforce';
const transcript =(
await gdrive.getDocument({ documentId:'abc123'})
).content;
await salesforce.updateRecord({
objectType:'SalesMeeting',
recordId:'00Q5f000001abcXYZ',
data:{Notes: transcript }
});
新架构的数据流
新架构对比图
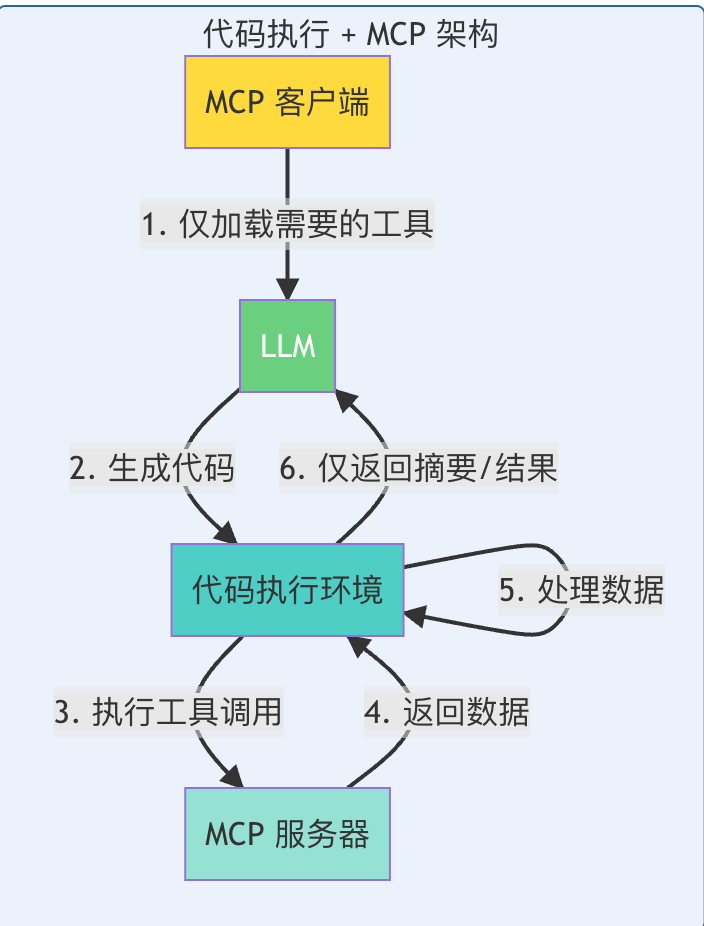
性能对比
Token 使用量对比
| 场景 | 传统方式 | 代码执行方式 | 节省率 |
|---|---|---|---|
| 工具定义加载 | 150,000 tokens | 2,000 tokens | 98.7% |
| 会议记录处理 | 100,000 tokens | ~500 tokens | 99.5% |
| 大型数据集筛选 | 200,000 tokens | ~1,000 tokens | 99.5% |
实际效果:
- ⚡ 响应速度提升 10-50 倍
- 💰 成本降低 98%+
- 📊 可扩展性增强 - 可处理数千个工具而不会上下文溢出
🚀 代码执行的五大核心优势
1. 渐进式工具披露(Progressive Disclosure)
核心概念
模型擅长浏览文件系统。将工具呈现为文件系统上的代码,允许模型按需读取工具定义,而不是一次性加载所有定义。
实现方式
方式一:文件系统探索
// Agent 的工作流程:
// 1. 列出 ./servers/ 目录,发现可用服务器
const servers =await fs.readdir('./servers/');
// 返回: ['google-drive', 'salesforce', 'slack', ...]
// 2. 对于当前任务,只读取需要的工具
const gdocTool =await fs.readFile(
'./servers/google-drive/getDocument.ts',
'utf-8'
);
const sfTool =await fs.readFile(
'./servers/salesforce/updateRecord.ts',
'utf-8'
);
// 只加载了 2 个工具定义,而不是全部 1000+ 个工具
方式二:工具搜索功能
// 添加一个 search_tools 工具到服务器
interfaceSearchToolsInput{
query:string;
detailLevel?:'name'|'summary'|'full';// 控制返回的详细程度
}
// Agent 使用示例
const salesforceTools =await searchTools({
query:'salesforce',
detailLevel:'summary'// 只返回名称和描述
});
// 当确定需要某个工具时,再获取完整定义
const fullDef =await searchTools({
query:'salesforce.updateRecord',
detailLevel:'full'// 返回完整的 schema
});
流程图
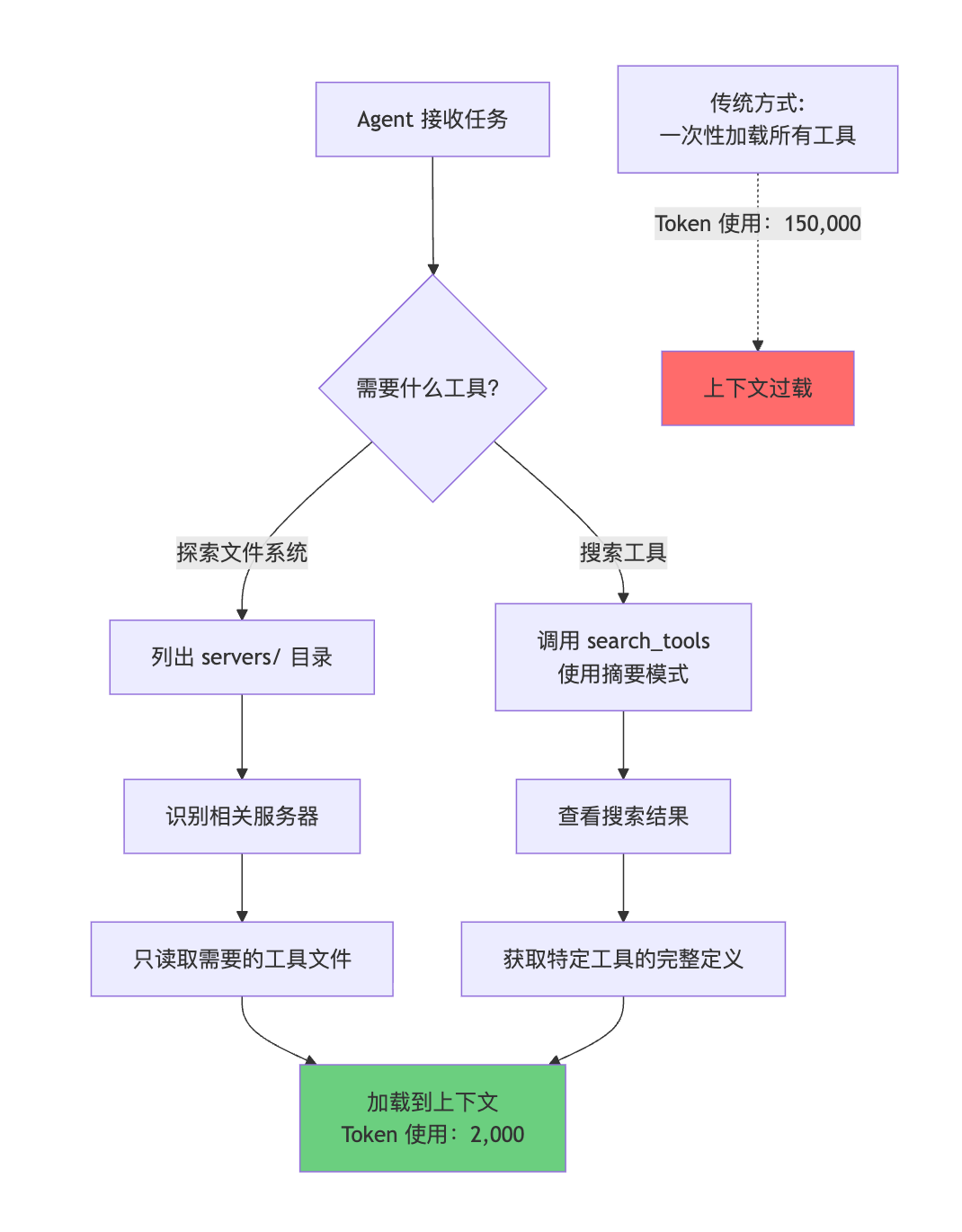
优势总结:
- ✅ 从 150,000 tokens → 2,000 tokens
- ✅ 更快的首次响应时间
- ✅ 支持连接数千个工具而不会溢出
2. 上下文高效的工具结果处理
核心概念
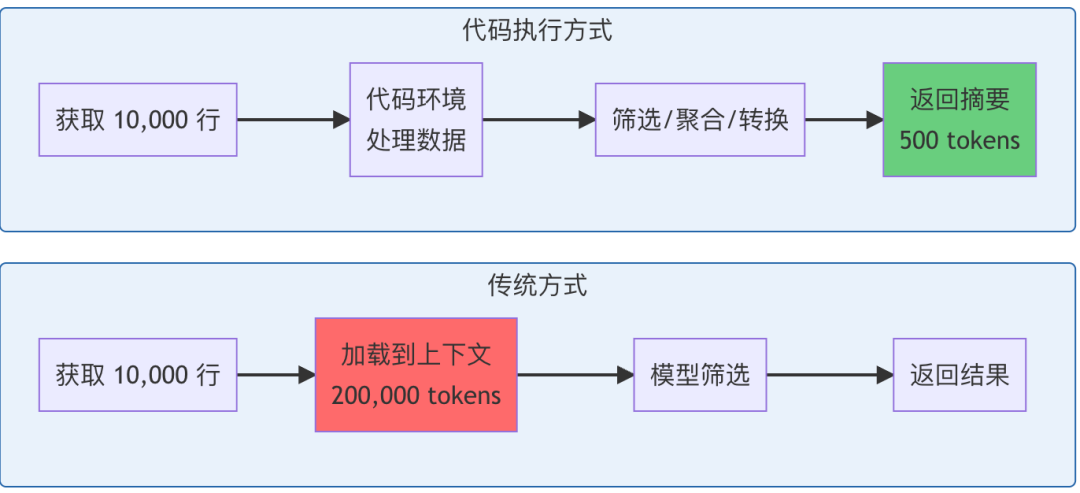
当处理大型数据集时,Agent 可以在代码中先过滤和转换结果,再返回给模型。
实际案例:处理 10,000 行电子表格
传统方式:
// 所有 10,000 行都流经上下文
TOOL CALL: gdrive.getSheet(sheetId:'abc123')
→返回10,000行数据到上下文中
→模型手动筛选(消耗大量 tokens)
代码执行方式:
// 在执行环境中筛选
const allRows =await gdrive.getSheet({ sheetId:'abc123'});
// 在代码中进行筛选和聚合
const pendingOrders = allRows.filter(row =>
row["Status"]==='pending'&&
row["Amount"]>1000
);
// 计算统计信息
const totalAmount = pendingOrders.reduce(
(sum, row)=> sum + row["Amount"],
0
);
// 只向模型返回摘要和样本
console.log(`找到 ${pendingOrders.length} 个待处理订单`);
console.log(`总金额: $${totalAmount.toLocaleString()}`);
console.log('前 5 个订单示例:');
console.log(pendingOrders.slice(0,5));
Agent 看到的内容(约 500 tokens):
找到157个待处理订单
总金额: $234,567
前5个订单示例:
[
{ orderId:'ORD-001', customer:'Acme Corp', amount:5000, status:'pending'},
{ orderId:'ORD-045', customer:'TechStart Inc', amount:3200, status:'pending'},
...
]
更多应用场景
场景一:数据聚合
// 跨多个数据源进行 JOIN 操作
const salesData =await salesforce.query({
query:'SELECT Id, Amount FROM Opportunity'
});
const customerData =await gdrive.getSheet({ sheetId:'customers'});
// 在代码中执行 JOIN
const enrichedData = salesData.map(sale =>({
...sale,
customer: customerData.find(c => c.id === sale.customerId)
}));
// 只返回汇总
console.log(`处理了 ${enrichedData.length} 条销售记录`);
console.log(`平均订单金额: $${average(enrichedData.map(d => d.Amount))}`);
场景二:字段提取
// 从大型 JSON 中只提取需要的字段
const largeDocument =await api.fetchDocument({ id:'123'});
// 只提取关键信息
const summary ={
title: largeDocument.metadata.title,
author: largeDocument.metadata.author,
wordCount: largeDocument.content.split(' ').length,
keyTopics: largeDocument.analysis.topics.slice(0,5)
};
console.log(summary);// 只返回摘要,而不是整个文档
对比图

3. 更强大的控制流能力
核心概念
使用熟悉的代码模式(循环、条件、错误处理)而不是链式工具调用。
实际案例:等待部署通知
传统方式的问题:
// Agent 需要在每次检查之间与用户交互
TOOL CALL: slack.getChannelHistory({ channel:'C123456'})
→检查消息
→未找到通知
TOOL CALL: sleep(5000)
TOOL CALL: slack.getChannelHistory({ channel:'C123456'})
→再次检查
→未找到通知
TOOL CALL: sleep(5000)
// ... 重复多次,每次都通过 Agent 循环
代码执行方式:
// 在代码中实现完整的轮询逻辑
let found =false;
let attempts =0;
const maxAttempts =60;// 最多等待 5 分钟
while(!found && attempts < maxAttempts){
const messages =await slack.getChannelHistory({
channel:'C123456'
});
found = messages.some(m =>
m.text.includes('deployment complete')
);
if(!found){
attempts++;
console.log(`等待部署通知... (尝试 ${attempts}/${maxAttempts})`);
awaitnewPromise(r => setTimeout(r,5000));// 等待 5 秒
}
}
if(found){
console.log('✓ 收到部署完成通知');
}else{
console.log('✗ 超时:未收到部署通知');
}
更多控制流案例
案例一:条件批处理
// 根据数据量决定处理策略
const records =await salesforce.query({
query:'SELECT Id FROM Lead WHERE Status = "New"'
});
if(records.length <100){
// 小批量:逐个处理
for(const record of records){
await processRecord(record);
}
}else{
// 大批量:批处理
const batches = chunk(records,50);
for(const batch of batches){
await processBatch(batch);
}
}
案例二:错误重试机制
// 实现智能重试逻辑
asyncfunction fetchWithRetry(url:string, maxRetries =3){
for(let i =0; i < maxRetries; i++){
try{
const result =await api.fetch({ url });
return result;
}catch(error){
if(i === maxRetries -1)throw error;
const delay =Math.pow(2, i)*1000;// 指数退避
console.log(`请求失败,${delay}ms 后重试...`);
awaitnewPromise(r => setTimeout(r, delay));
}
}
}
案例三:复杂的决策树
// 多条件决策逻辑
const customer =await crm.getCustomer({ id: customerId });
const orders =await orders.getHistory({ customerId });
let action;
if(customer.tier ==='premium'){
if(orders.length >10){
action ='send_vip_discount';
}else{
action ='send_welcome_gift';
}
}elseif(customer.tier ==='standard'){
if(hasRecentPurchase(orders)){
action ='send_survey';
}else{
action ='send_reminder';
}
}else{
action ='send_onboarding';
}
await executeAction(action, customer);
性能优势
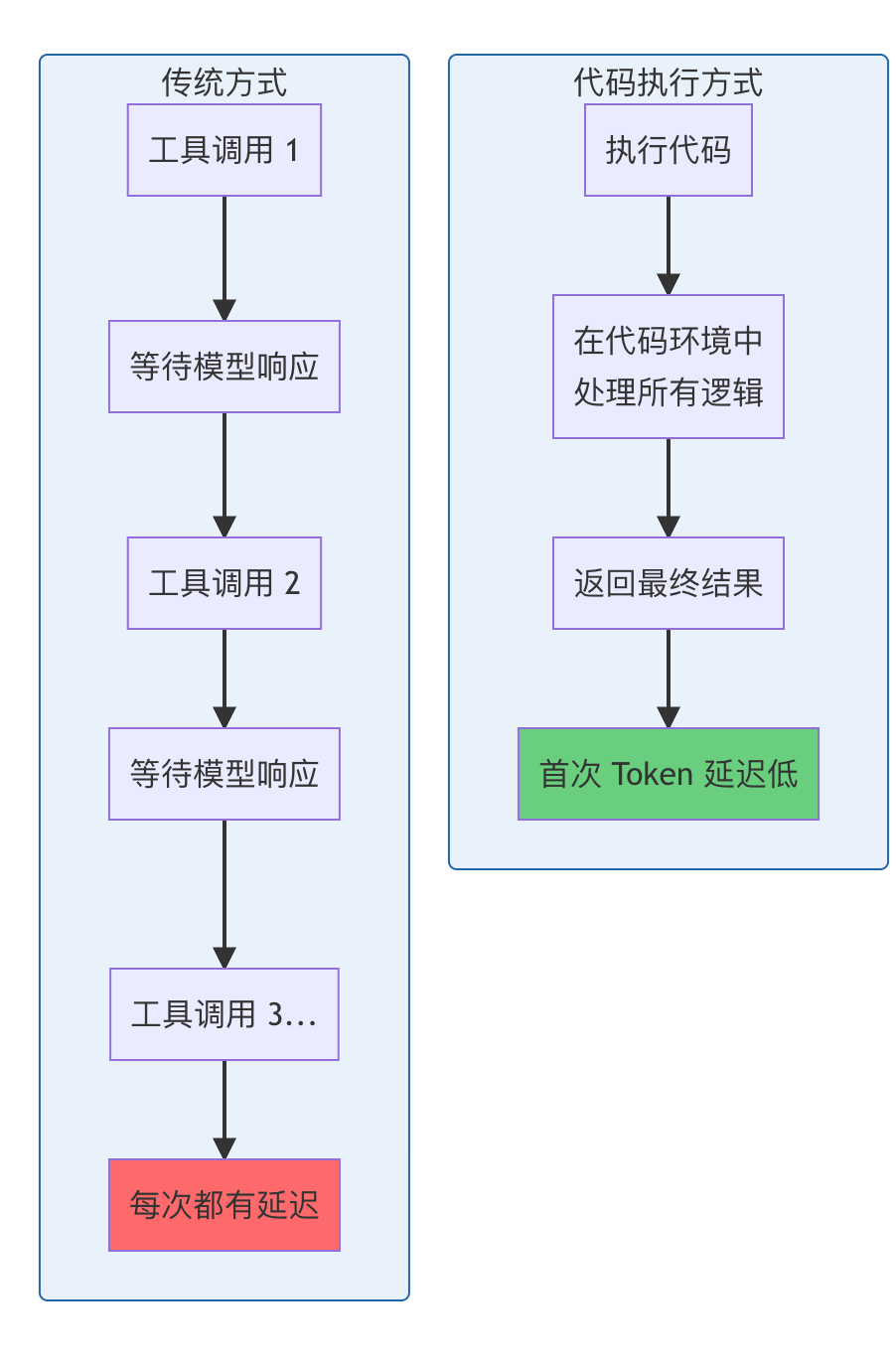
优势总结:
- ⚡ 减少"首次 Token 延迟" - 不需要等待模型评估每个 if 语句
- 🔧 使用成熟的编程模式 - 循环、条件、异常处理
- 📉 更少的往返通信 - 整个逻辑在一次执行中完成
4. 隐私保护操作
核心概念
中间结果默认保留在执行环境中。Agent 只看到你明确记录或返回的内容,敏感数据可以流经工作流而不进入模型的上下文。
实际案例:导入客户联系信息
场景:从 Google Sheets 导入客户联系信息到 Salesforce
传统方式的隐私风险:
// 传统方式:所有数据都通过模型上下文
TOOL CALL: gdrive.getSheet(sheetId:'abc123')
→返回包含敏感信息的完整数据:
[
{ name:"张三", email:"zhang@example.com", phone:"13800138000",...},
{ name:"李四", email:"li@example.com", phone:"13900139000",...},
// 所有敏感数据都加载到 LLM 上下文中
]
TOOL CALL: salesforce.updateRecord(...)
→模型需要再次写入所有敏感数据
代码执行方式:自动令牌化
// Agent 编写的代码
const sheet =await gdrive.getSheet({ sheetId:'abc123'});
for(const row of sheet.rows){
await salesforce.updateRecord({
objectType:'Lead',
recordId: row.salesforceId,
data:{
Email: row.email,// 实际的敏感数据
Phone: row.phone,// 实际的敏感数据
Name: row.name // 实际的敏感数据
}
});
}
console.log(`已更新 ${sheet.rows.length} 条潜在客户记录`);
MCP 客户端在后台的处理:
// 数据被自动令牌化
// Agent 如果记录 sheet.rows,看到的是:
[
{
salesforceId:'00Q...',
email:'[EMAIL_1]',// 已令牌化
phone:'[PHONE_1]',// 已令牌化
name:'[NAME_1]'// 已令牌化
},
{
salesforceId:'00Q...',
email:'[EMAIL_2]',
phone:'[PHONE_2]',
name:'[NAME_2]'
},
// ...
]
关键机制:
- 拦截和令牌化:MCP 客户端在数据进入 LLM 之前拦截
- 安全流转:数据通过执行环境从 Google Sheets → Salesforce
- 去令牌化:在实际 API 调用时,令牌化的数据被还原
- 零暴露:真实的邮箱、电话、姓名从未进入 LLM 上下文
高级隐私控制:确定性安全规则
// 定义数据流规则
const privacyPolicy ={
// PII 数据可以从哪些源读取
allowedSources:['google-drive','salesforce'],
// PII 数据可以写入哪些目标
allowedDestinations:['salesforce','local-storage'],
// 禁止的操作
forbidden:[
{ source:'*', destination:'public-api'},
{ source:'google-drive', destination:'slack'}
],
// 需要令牌化的字段
sensitiveFields:['email','phone','ssn','creditCard']
};
// MCP 客户端强制执行这些规则
// 如果 Agent 尝试违规操作,会被阻止:
try{
await slack.sendMessage({
channel:'general',
text: customer.email // ❌ 违反隐私策略
});
}catch(error){
// Error: Privacy policy violation:
// PII cannot be sent to slack
}
数据流对比
graph TB
subgraph "代码执行 + 令牌化"
A1[GoogleSheets<br/>真实数据]-->|读取| B1[代码执行环境]
B1 -->|令牌化| C1[LLM 上下文<br/>[EMAIL_1],[PHONE_1]]
B1 -->|真实数据| D1[Salesforce API]
D1 --> E1[数据安全导入]
end
subgraph "传统方式"
A2[GoogleSheets<br/>真实数据]-->|读取| B2[LLM 上下文<br/>完整敏感数据]
B2 -->|可能记录/泄露| C2[日志/缓存]
B2 --> D2[Salesforce API]
end
style C1 fill:#6bcf7f
style B2 fill:#ff6b6b
隐私保护总结:
- 🔒 零上下文暴露 - 敏感数据不进入 LLM
- 🛡️ 自动令牌化 - 无需手动处理
- 📋 审计和合规 - 可定义和强制执行数据流规则
- ✅ 符合 GDPR/CCPA - 最小化数据暴露
5. 状态持久化和技能演化
核心概念
代码执行环境的文件系统访问允许 Agent:
- 维护跨操作的状态 - 保存中间结果,恢复工作
- 持久化自己的代码 - 将成功的实现保存为可重用函数
5.1 状态持久化
案例:处理大批量数据
// Agent 可以保存进度,支持中断和恢复
const leads =await salesforce.query({
query:'SELECT Id, Email FROM Lead LIMIT 10000'
});
// 转换为 CSV 并保存
const csvData = leads.map(l =>`${l.Id},${l.Email}`).join('\n');
await fs.writeFile('./workspace/leads.csv', csvData);
console.log('已保存 10,000 条潜在客户记录到 leads.csv');
// -------- 稍后的执行(或从失败中恢复)--------
const saved =await fs.readFile('./workspace/leads.csv','utf-8');
const rows = saved.split('\n').map(row =>{
const[id, email]= row.split(',');
return{ id, email };
});
console.log(`从文件加载了 ${rows.length} 条记录,继续处理...`);
案例:跟踪处理进度
// 处理大量记录时保存检查点
const CHECKPOINT_FILE ='./workspace/progress.json';
// 加载之前的进度(如果有)
let progress ={ processed:0, failed:[]};
if(await fs.exists(CHECKPOINT_FILE)){
progress = JSON.parse(
await fs.readFile(CHECKPOINT_FILE,'utf-8')
);
console.log(`恢复进度:已处理 ${progress.processed} 条记录`);
}
const allRecords =await fetchRecords();
for(let i = progress.processed; i < allRecords.length; i++){
try{
await processRecord(allRecords[i]);
progress.processed++;
// 每 100 条记录保存一次进度
if(i %100===0){
await fs.writeFile(
CHECKPOINT_FILE,
JSON.stringify(progress)
);
}
}catch(error){
progress.failed.push({ index: i, error: error.message });
}
}
console.log(`完成!处理了 ${progress.processed} 条,失败 ${progress.failed.length} 条`);
5.2 技能演化(Skills)
核心概念:Agent 可以保存成功的代码实现,构建自己的"技能库"。
技能保存示例:
// ./skills/save-sheet-as-csv.ts
import*as gdrive from'./servers/google-drive';
import*as fs from'fs';
/**
* 将 Google Sheet 保存为本地 CSV 文件
* @param sheetId - Google Sheet 的 ID
* @returns 保存的 CSV 文件路径
*/
exportasyncfunction saveSheetAsCsv(sheetId:string):Promise<string>{
// 获取数据
const data =await gdrive.getSheet({ sheetId });
// 转换为 CSV
const csv = data.map(row =>
row.map(cell =>`"${cell}"`).join(',')
).join('\n');
// 保存到文件
const filePath =`./workspace/sheet-${sheetId}.csv`;
await fs.writeFile(filePath, csv);
console.log(`✓ 已保存 ${data.length} 行到 ${filePath}`);
return filePath;
}
技能文档(SKILL.md):
# Save Sheet as CSV
将GoogleSheet导出为本地 CSV 文件。
## 使用场景
-需要离线分析GoogleSheets数据
-将数据导入到不支持GoogleSheets API 的系统
-创建数据快照
## 使用示例
typescript import { saveSheetAsCsv } from ‘./skills/save-sheet-as-csv’;
const csvPath = await saveSheetAsCsv(‘1A2B3C4D5E6F’); console.log( CSV已保存到:${csvPath});
## 参数
-`sheetId`(string):GoogleSheet的 ID
## 返回值
-(string):保存的 CSV 文件路径
## 依赖
-`google-drive` MCP 服务器
技能复用示例:
// 在未来的任何执行中,Agent 可以直接使用这个技能
import{ saveSheetAsCsv }from'./skills/save-sheet-as-csv';
import{ uploadToS3 }from'./skills/upload-to-s3';
// 组合多个技能完成复杂任务
const csvPath =await saveSheetAsCsv('abc123');
const s3Url =await uploadToS3(csvPath,'my-bucket');
console.log(`数据已上传到: ${s3Url}`);
技能生态系统
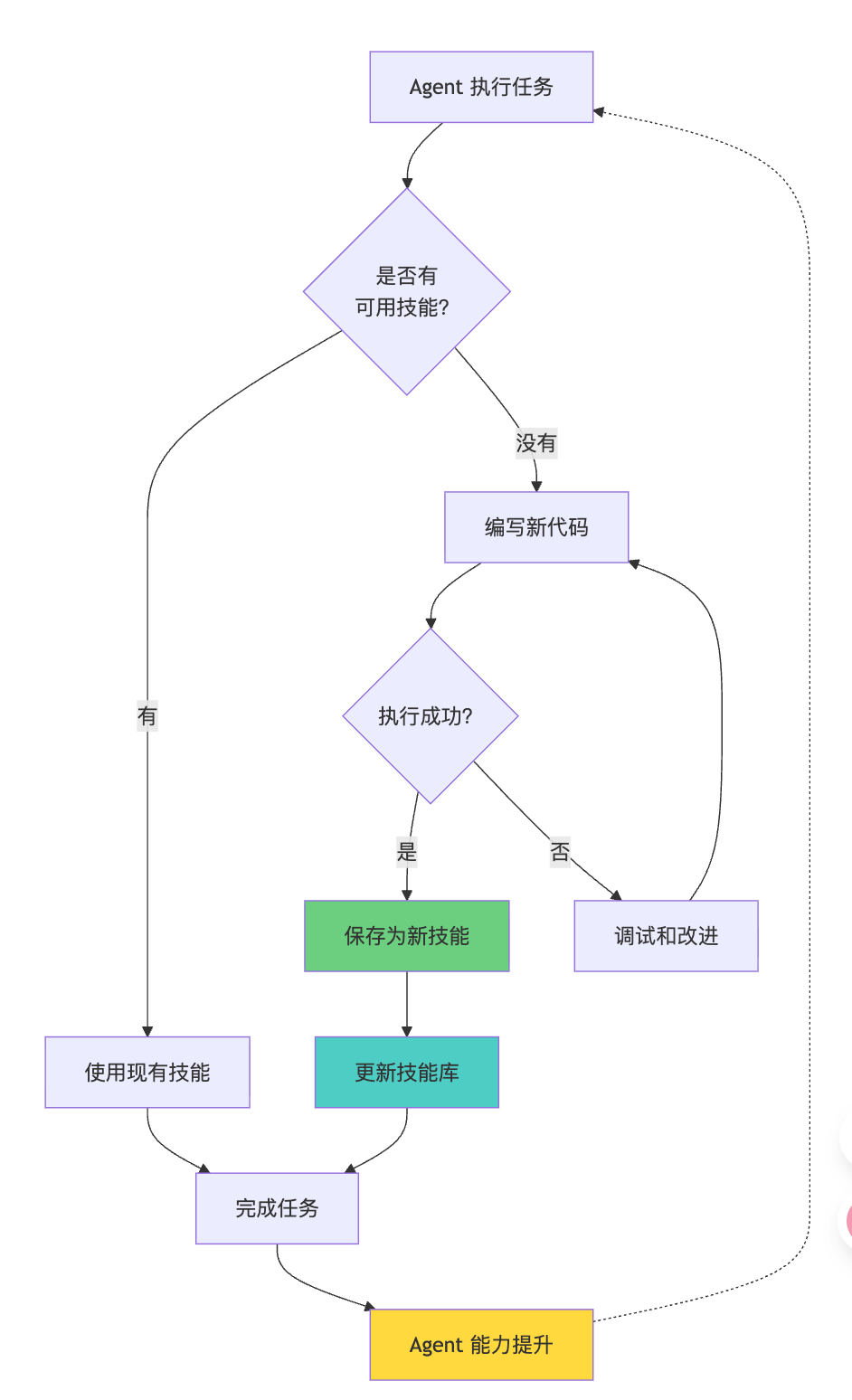
技能库结构:
skills/
├── data-processing/
│├── save-sheet-as-csv.ts
│├── merge-csv-files.ts
│├── filter-large-dataset.ts
│└── SKILLS.md
├── salesforce/
│├── bulk-update-leads.ts
│├──export-opportunities.ts
│└── SKILLS.md
├── notifications/
│├── wait-for-slack-message.ts
│├── send-summary-email.ts
│└── SKILLS.md
└── index.md # 技能库索引
高级技能示例:组合多个工具
// ./skills/salesforce/sync-leads-from-sheet.ts
import*as gdrive from'../servers/google-drive';
import*as salesforce from'../servers/salesforce';
import*as slack from'../servers/slack';
/**
* 从 Google Sheet 同步潜在客户到 Salesforce
* 并发送 Slack 通知
*/
exportasyncfunction syncLeadsFromSheet(
sheetId:string,
notifyChannel:string
):Promise<{ success: number; failed: number }>{
// 1. 读取数据
const sheet =await gdrive.getSheet({ sheetId });
console.log(`读取到 ${sheet.length} 条记录`);
// 2. 批量更新
let success =0, failed =0;
for(const row of sheet){
try{
await salesforce.createLead({
FirstName: row[0],
LastName: row[1],
Email: row[2],
Company: row[3]
});
success++;
}catch(error){
failed++;
console.error(`失败: ${row[1]}, 原因: ${error.message}`);
}
}
// 3. 发送通知
await slack.sendMessage({
channel: notifyChannel,
text:`✓ 潜在客户同步完成: ${success} 成功, ${failed} 失败`
});
return{ success, failed };
}
状态和技能总结:
- 💾 状态持久化 - 支持长时间运行的任务和错误恢复
- 📚 技能积累 - Agent 随时间变得更加高效
- 🔄 可复用性 - 一次编写,多次使用
- 🎯 专业化 - 针对特定领域构建专用工具集
⚠️ 实施考虑和权衡
代码执行引入的复杂性
虽然代码执行带来了显著的性能优势,但它也引入了新的挑战:
1. 安全隔离(Sandboxing)
需求:
- 防止恶意代码执行系统命令
- 限制文件系统访问范围
- 隔离网络请求
实现方案:
// 沙箱配置示例
const sandboxConfig ={
// 文件系统限制
filesystem:{
allowedPaths:['./workspace','./skills'],
deniedPaths:['/','/etc','/usr'],
maxFileSize:'100MB'
},
// 网络限制
network:{
allowedDomains:['api.example.com'],
deniedDomains:['*'],
requireHttps:true
},
// 资源限制
resources:{
maxMemory:'512MB',
maxCpuTime:'30s',
maxExecutionTime:'60s'
}
};
2. 资源限制
挑战:
- CPU 时间限制
- 内存使用限制
- 执行超时处理
监控示例:
// 资源监控
const monitor ={
startTime:Date.now(),
memoryUsed: process.memoryUsage().heapUsed,
check(){
const elapsed =Date.now()-this.startTime;
const memory = process.memoryUsage().heapUsed;
if(elapsed >60000){
thrownewError('执行超时(60 秒)');
}
if(memory >512*1024*1024){
thrownewError('内存超限(512MB)');
}
}
};
3. 监控和审计
需要追踪:
- 执行的代码
- API 调用
- 数据访问
- 错误和异常
审计日志示例:
{
"executionId":"exec-123",
"timestamp":"2024-11-05T10:30:00Z",
"code":"const data = await gdrive.getSheet(...)",
"apiCalls":[
{
"service":"google-drive",
"method":"getSheet",
"duration":"450ms",
"status":"success"
}
],
"dataAccess":[
{
"source":"google-drive",
"destination":"salesforce",
"recordCount":1000,
"privacyCheck":"passed"
}
]
}
架构对比:何时使用代码执行?
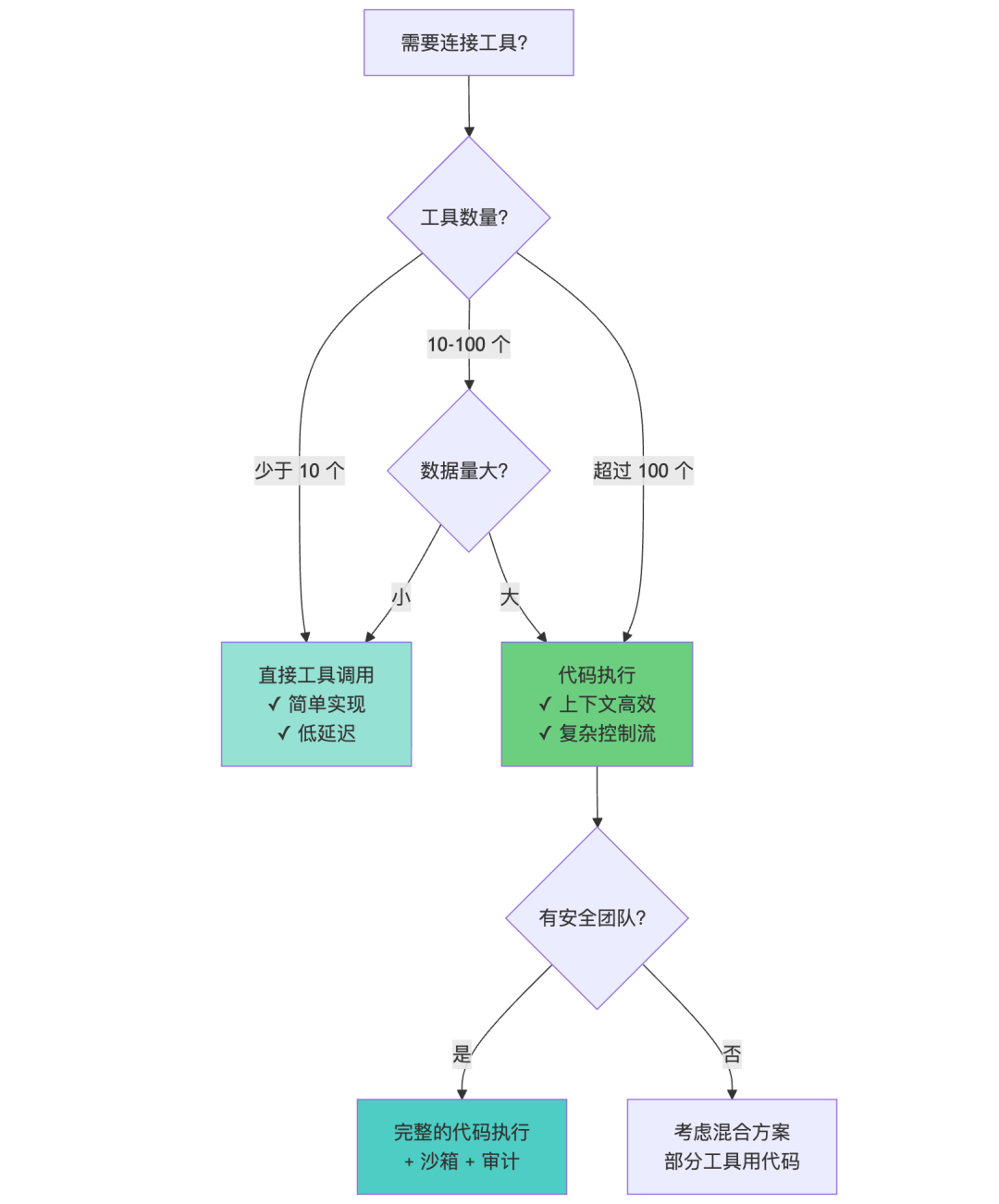
决策矩阵:
| 场景 | 建议方案 | 原因 |
|---|---|---|
| < 10 个工具,简单流程 | 直接工具调用 | 实现简单,overhead 低 |
| 10-100 个工具 | 混合方案 | 核心工具用代码,辅助工具直接调用 |
| > 100 个工具 | 代码执行 | 唯一可扩展的方案 |
| 大数据处理 | 代码执行 | 避免上下文溢出 |
| 复杂控制流 | 代码执行 | 循环、条件更自然 |
| 敏感数据 | 代码执行 + 令牌化 | 隐私保护 |
| 快速原型 | 直接工具调用 | 快速验证想法 |
实施建议
- 渐进式采用:
- 从核心工具开始迁移到代码执行
- 保留直接工具调用作为备选
- 逐步扩展到更多工具
- 混合架构:
// 配置哪些服务器使用代码执行
const executionStrategy ={
'google-drive':'code',// 大数据量,用代码
'salesforce':'code',// 复杂操作,用代码
'slack':'direct',// 简单通知,直接调用
'calendar':'direct'// 简单查询,直接调用
};
- 监控和优化:
- 追踪 token 使用量
- 测量执行时间
- 收集错误率
- 持续优化
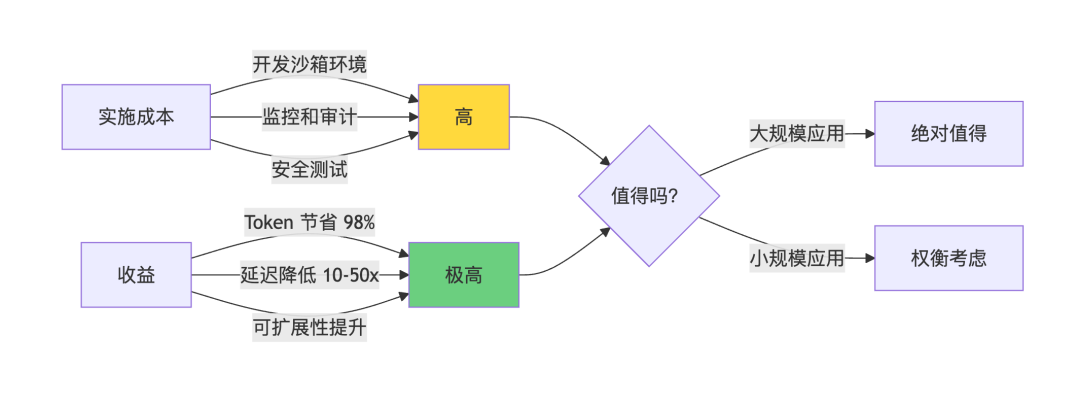
实施成本 vs 收益:
🎓 关键技术要点总结
核心创新
- 架构转变:从"直接工具调用"到"代码 API"
- 传统:LLM ↔️ 工具
- 创新:LLM → 代码 → 工具
- 性能提升:
- Token 使用降低 98.7%
- 响应速度提升 10-50 倍
- 成本降低 98%+
- 能力增强:
- 支持数千个工具而不会上下文溢出
- 复杂数据处理在执行环境中完成
- 自然的编程控制流(循环、条件、异常)
五大优势速查
| 优势 | 传统方式 | 代码执行方式 | 提升 |
|---|---|---|---|
| 工具加载 | 一次性加载全部 150,000 tokens | 按需加载 2,000 tokens | ↓ 98.7% |
| 数据处理 | 所有数据流经 LLM 200,000 tokens | 执行环境筛选 500 tokens | ↓ 99.8% |
| 控制流 | 每次循环都要等待 LLM | 代码中执行循环 | ⚡ 10-50x |
| 隐私 | 敏感数据进入上下文 | 自动令牌化 | 🔒 零暴露 |
| 技能 | 每次重新生成代码 | 持久化可复用 | 📈 持续提升 |
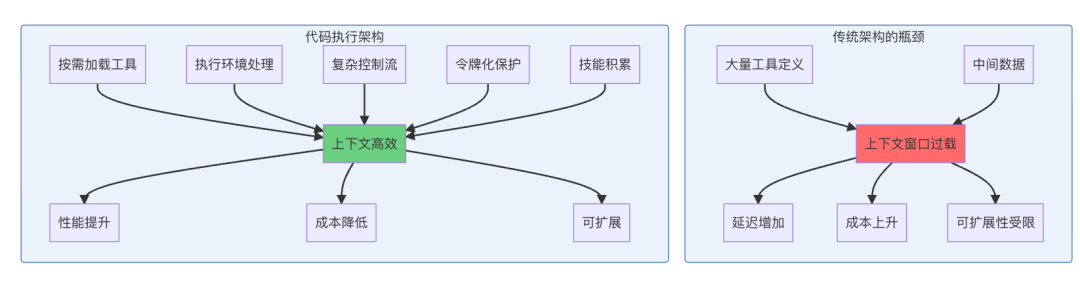
技术架构对比
最佳实践
- 工具发现:
- 使用文件系统探索或
search_tools - 渐进式加载定义
- 优先加载名称和摘要
- 数据处理:
- 在执行环境中筛选、聚合
- 只返回摘要和关键信息
- 避免大型数据进入上下文
- 控制流:
- 用代码实现循环和条件
- 实现错误重试机制
- 减少 Agent 往返通信
- 隐私保护:
- 启用自动令牌化
- 定义数据流规则
- 审计敏感数据访问
- 技能演化:
- 保存成功的代码实现
- 编写 SKILL.md 文档
- 构建可复用的技能库
🔮 技术影响和未来展望
对 AI Agent 生态的影响
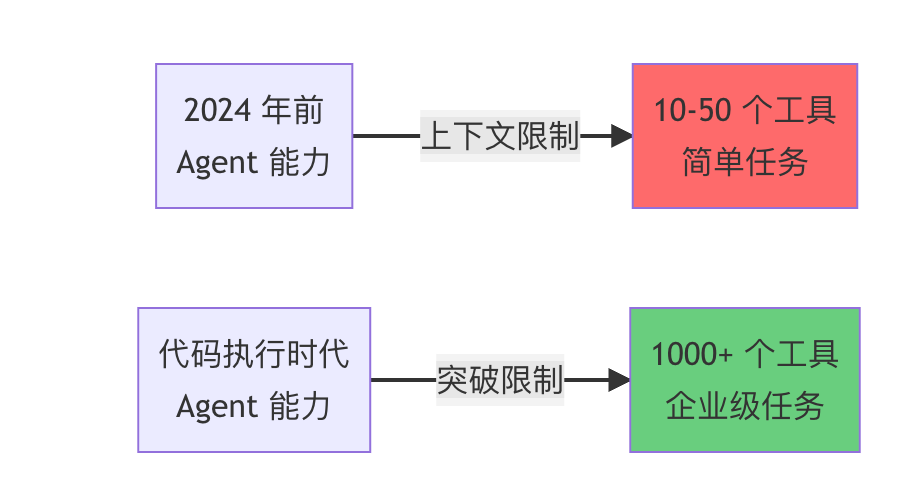
1. 重新定义 Agent 能力边界
之前的限制:
- Agent 连接的工具数量受上下文窗口限制
- 大数据处理几乎不可能
- 复杂工作流需要过多的往返通信
代码执行后:
- 可以连接数千个工具
- 处理 GB 级别的数据
- 执行复杂的多步骤工作流
2. 编程范式回归
有趣的观察:我们用 AI 来写代码,然后让代码执行来提升 AI 的效率。
这其实是一种"范式回归":
- 传统编程:人类编写代码 → 计算机执行
- AI Agent 1.0:AI 直接调用工具
- AI Agent 2.0:AI 编写代码 → 代码执行环境 → 调用工具
为什么代码如此强大?
- 成熟的抽象:循环、函数、模块化
- 高效的数据处理:就地转换,不需要序列化
- 确定性:代码执行是可预测的
- 可组合性:复用和扩展
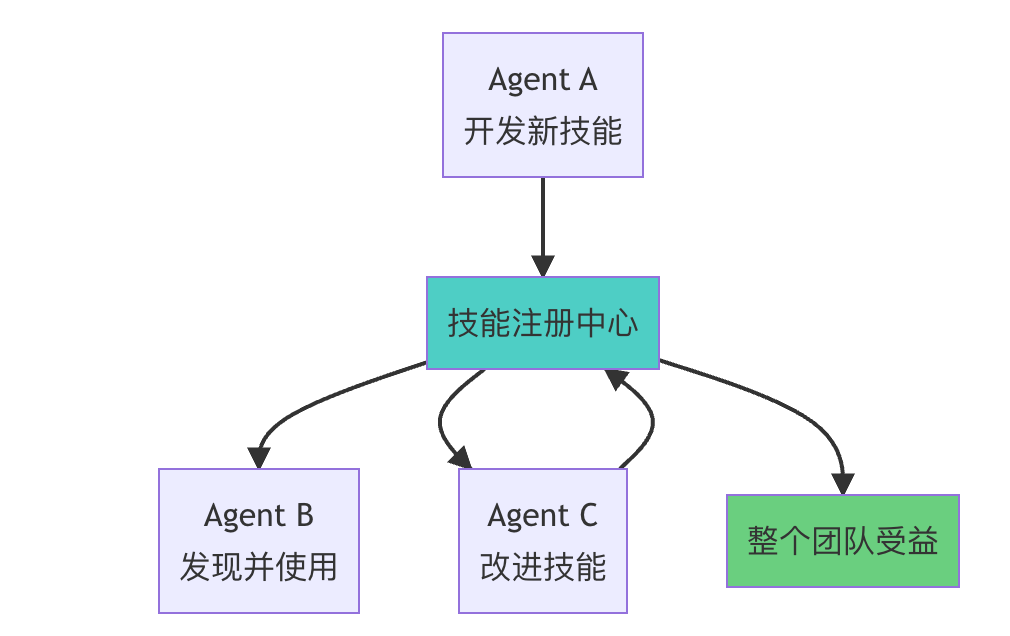
3. 技能经济(Skills Economy)
随着 Agent 可以持久化自己的代码,一个新的"技能经济"正在形成:
个人技能库:
my-agent/
├── skills/
│├── personal/
││├── weekly-report.ts # 生成周报
││├── expense-tracker.ts # 追踪支出
││└── meeting-scheduler.ts # 智能排期
│└── work/
│├── customer-onboarding.ts # 客户入职流程
│└── sales-pipeline.ts # 销售管道管理
团队技能库:
company-skills/
├── sales/
│├── lead-qualification.ts
│├── proposal-generator.ts
│└── crm-sync.ts
├── marketing/
│├── campaign-analyzer.ts
│└── social-media-poster.ts
└── ops/
├── incident-response.ts
└── deployment-checker.ts
开源技能市场:
- 开发者分享通用技能
- 企业采用最佳实践
- 社区协作改进
Cloudflare 的验证
文章提到 Cloudflare 发布了类似的发现,称之为"代码模式"(Code Mode)。核心洞察一致:
LLM 擅长编写代码,开发者应该利用这一优势来构建与 MCP 服务器交互更高效的 Agent。
这不是巧合,而是技术演进的必然:
- LLM 最初是为代码生成训练的
- 代码是最高效的工具组合方式
- 执行环境提供了必要的隔离和控制
未来方向
1. 自动化技能发现和组合
// Agent 自动发现相关技能
const skills =await skillRegistry.search({
query:"sync data from Google Sheets to Salesforce",
similarity:0.8
});
// 自动组合多个技能
const workflow =await composer.combine([
skills.find('read-google-sheet'),
skills.find('transform-csv'),
skills.find('bulk-import-salesforce')
]);
2. 跨 Agent 技能共享
3. 智能工具推荐
// Agent 根据任务自动推荐工具
const task ="分析最近的销售趋势";
const recommendations =await toolRecommender.suggest(task);
// 返回:
// 1. salesforce.query (相关度: 0.95)
// 2. google-sheets.getSheet (相关度: 0.82)
// 3. chart-generator.createGraph (相关度: 0.78)
4. 渐进式安全增强
// 基于信任度的权限系统
const securityPolicy ={
untrustedCode:{
allowedTools:['read-only'],
requireApproval:true
},
trustedSkills:{
allowedTools:['all'],
requireApproval:false
},
learnFromExecution:true// 从安全执行中学习
};
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)