[NeurIPS 2025]Deciphering the Extremes: A Novel Approach for Pathological Long-tailed Recognition in
计算机-人工智能-长尾分布损失约束

目录
2.3.1. Long-Tailed Phenomena in Scientific Tasks
2.3.2. Long-Tailed Learning (LTR)
2.4.1. Formalizing Pathological Long-Tailed Recognition as a Multi-Objective Optimization Problem
2.4.2. Derivation of the Training Objective from Multi-Objective Constraints
2.5.1. Datasets, Metrics, and Pathological Imbalance
2.5.6. Discussion of Experimental Findings
1. 心得
(1)写得很清楚
(2)创新性还好吧就
2. 论文逐段精读
2.1. Abstract
①作者想动态地重新加权尾类贡献(感觉也很常见?
2.2. Introduction
①科学类的数据集往往表现出极端的不平衡
②当前的长尾识别(Long-Tailed Recognition, LTR)方法有:重新采样,重新加权,解耦(就是两阶段)训练,损失设计
③当前方法的局限:在极端稀缺的情况下,重新加权可能过拟合噪声,重新采样可能丢失或冗余地添加信息,并且如果尾类的初始特征学习得不好,则解耦训练会很困难
④长尾分布示意图:
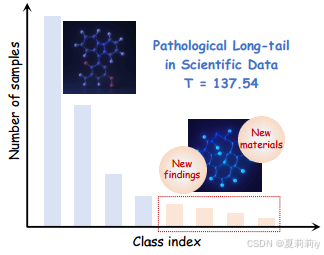
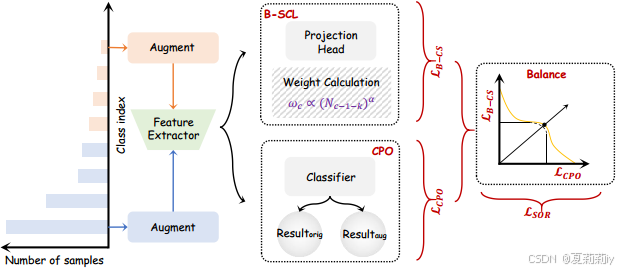
⑤作者提出的框架:
2.3. Related Work
2.3.1. Long-Tailed Phenomena in Scientific Tasks
①就说自然科学天体科学有很多长尾现象并且总样本量有限
2.3.2. Long-Tailed Learning (LTR)
①重采样策略:可能导致过拟合或信息丢失
②重加权策略:额
③解耦学习:性能更取决于初始表示
④迁移学习或知识蒸馏也行
⑤对比学习
2.4. Methodology: Balanced Contrastive Representation Learning under Dynamic Multi-Objective Constraints for Pathological Long-Tails
2.4.1. Formalizing Pathological Long-Tailed Recognition as a Multi-Objective Optimization Problem
①数据集定义为,
,
,
为类别数量
②代表每个类别的样本数,分布非常不均匀。样本不均匀指数由
确定,就是其中最大类越大最小类越小加上类别越多可能就越分布不均匀(但感觉不严谨哈比如样本数量为10,10,10,1这种或者10,1,1,1,还有10,7,4,1算出来都一样但实际上可能也有差别)
③作者目标:训练出包含参数的特征提取器
,投影头
,和分类头
(1)Robust Classification Performance (O1(θ))
①分类表现目标(Classification Performance Objective,CPO)损失:
其中交叉熵损失(不用太在意那个期望
,因为后面那两项是针对单个样本的,期望加在前面只是为了说要求整个数据集样本的平均损失)。作者把上面的CPO损失简化成原始交叉熵损失项和增强交叉熵损失项:
其中,
(2)Tail-Centric Discriminative Representation (O2(θ))
①平衡监督对比学习(Balanced Supervised Contrastive Learning,B-SCL)损失:
其中是每个锚点的SupCon损失,这个损失懒得单独敲了我截图在下面:

使用这个对比损失之后,作者还在外面加了一层权重,根据不同类别分配不同的权重:
其中(这是分布权重翻转,比如为最大样本类分配最少样本类的权重而为最小样本类分配最大样本类权重)
②交叉熵是尊重原始分布的而权重重分配会导致冲突,两个损失按理来说不能放在一起(要么就变成两阶段)。作者使用了帕累托最优去优化
(3)Optimization Target 1 (Constrained Multi-Objective Formulation)
①最优化策略:
其中是动态调整的上限
2.4.2. Derivation of the Training Objective from Multi-Objective Constraints
①使用最大值函数的可微凸近似LogSumExp(LSE):
这会对于有的成分的向量
有:
好妙啊这个LSE,得到一个向量里面最大值的近似:
它总是大于或等于最大值。
当最大值远大于其他值时,它无限接近最大值。
当所有值相差不多时,它会比最大值大一个与数值分布有关的量。

②使用切比雪夫最大最小方法来实现多目标优化,使得:
③引入平滑目标正则(Smooth Objective Regularization,SOR)项:
其中是正则强度,
是温度系数
④作者令有:
⑤最终训练目标:
在之前的分类损失和对比权重损失前面又加了这个SOR,展开就是:
2.5. Experiments
2.5.1. Datasets, Metrics, and Pathological Imbalance
①数据失衡指标:
②真实世界数据集:ZincFlour:

它的。统计展示:
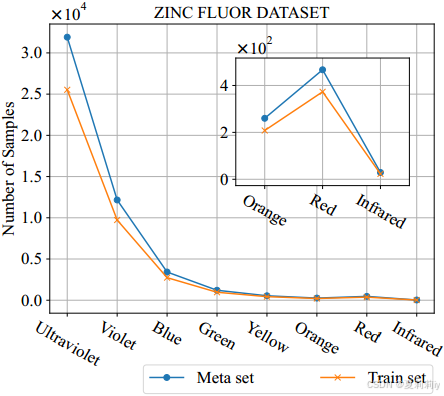
③合成数据集:CIFAR-LT。统计展示:
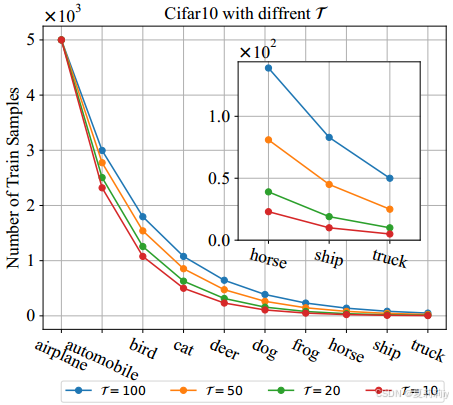
④评估指标:top-k正确率
fluorescence n. 荧光
2.5.2. Experimental Setup
①损失消融:
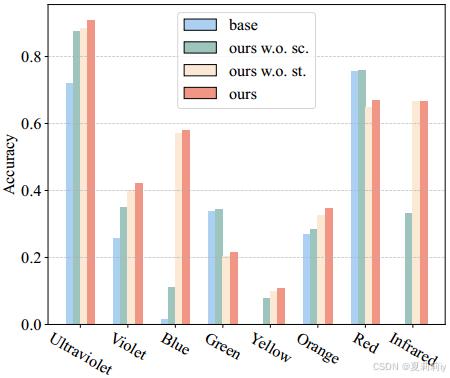
2.5.3. Quantitative Results
①ZincFluor上的Top-1精度对比实验:
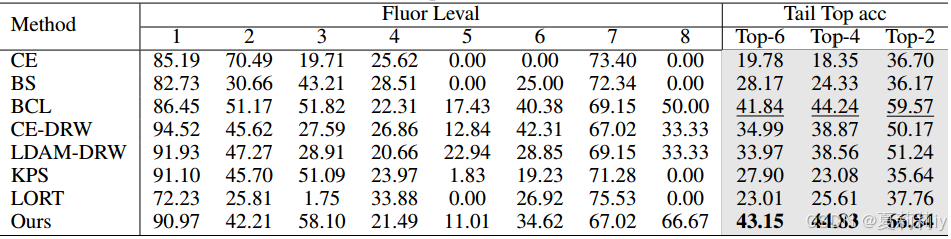
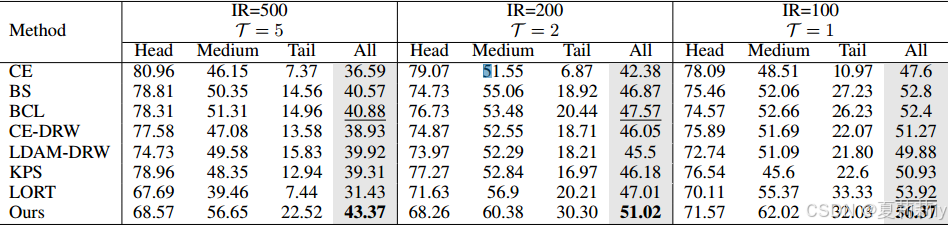
②CIFAR10-LT基准测试中的性能:

③CIFAR100-LT基准测试中的性能:
2.5.4. Ablation Studies
上面放了这里不放了
2.5.5. Qualitative Analysis
①CIFAT10-LT上原始样本及增强样本的特征:
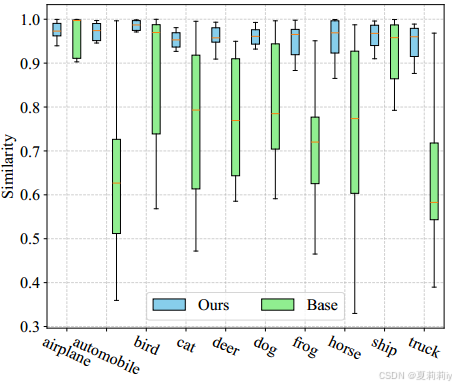
2.5.6. Discussion of Experimental Findings
①CIFAR-10-LT上原始的类间相似性和作者约束后的:
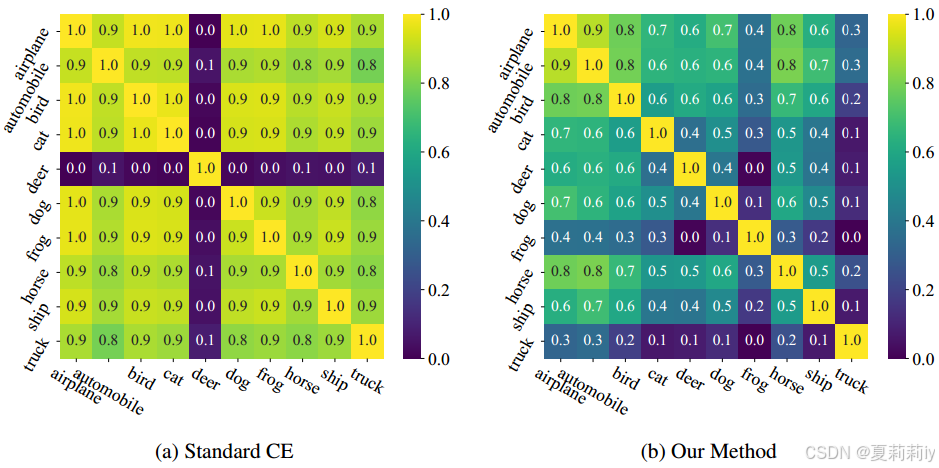
2.6. Conclusion
~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)