Doc-Researcher: 多模态文档深度研究系统的技术解析
系统通过深度多模态解析保留文档的视觉语义信息,支持跨模态和多粒度自适应检索,并采用迭代多智能体工作流进行深度研究。系统采用离线-在线架构,离线阶段解析文档为多粒度表示,在线阶段通过PlannerAgent分解查询,SearcherAgent执行多模态检索,RefinerAgent精炼证据。
一、引言:从文本检索到多模态深度研究的范式转变
1.1 研究背景与动机
在当今信息爆炸的时代,大型语言模型(LLM)已经展现出强大的理解和生成能力。然而,这些模型在处理复杂任务时仍面临两个核心挑战:知识幻觉和复杂推理能力不足。
为了解决这些问题,检索增强生成(Retrieval-Augmented Generation, RAG)应运而生,通过从外部知识库检索相关信息来增强模型的事实性和准确性。
然而,现有的深度研究系统存在一个根本性的局限:它们几乎完全依赖于纯文本网络数据,忽略了大量蕴含在多模态文档中的宝贵知识。科学论文、技术报告、财务文件等专业文档中,关键信息往往以图表(figures)、表格(tables)、公式(equations)和复杂布局等多种形式呈现。传统的OCR文本提取或简单的页面截图方法都无法有效保留这些视觉语义信息。
Doc-Researcher论文针对现有系统的三个关键限制提出了解决方案:
第一,不充分的多模态解析——传统方法无法保留图表、表格和复杂布局的视觉语义;
第二,有限的检索策略——缺乏跨模态和多粒度的自适应检索机制;
第三,缺乏深度研究能力——仅支持单轮问答,不支持迭代多步研究工作流。
1.2 核心创新与贡献
Doc-Researcher作为首个统一的多模态文档深度研究系统,通过三个集成组件弥合了这一差距:①深度多模态解析,保留布局结构和视觉语义,并创建从块到文档级别的多粒度表示;②系统化的检索架构,支持纯文本、纯视觉和混合范式,具有动态粒度选择;③以及迭代多智能体工作流,分解复杂查询,逐步积累证据,并跨文档和模态综合全面答案。
论文的三大核心贡献包括:
- 深度多模态解析与检索框架:开发了模块化、即插即用的组件,用于多模态文档解析和检索,具有布局感知分析和多粒度表示策略。
- Doc-Researcher系统:提出了首个统一的深度研究工作流,利用自适应和粒度化检索,以及迭代证据精炼来理解多模态文档。
- M4DocBench基准测试:建立了首个用于多模态深度研究的综合基准,包含大规模文档集合,带有多跳、多文档和多轮评估的标注证据链。
二、系统架构详解
2.1 整体架构概览
Doc-Researcher系统采用了"离线-在线"两阶段的架构设计,清晰地分离了文档处理和查询响应两个核心功能。
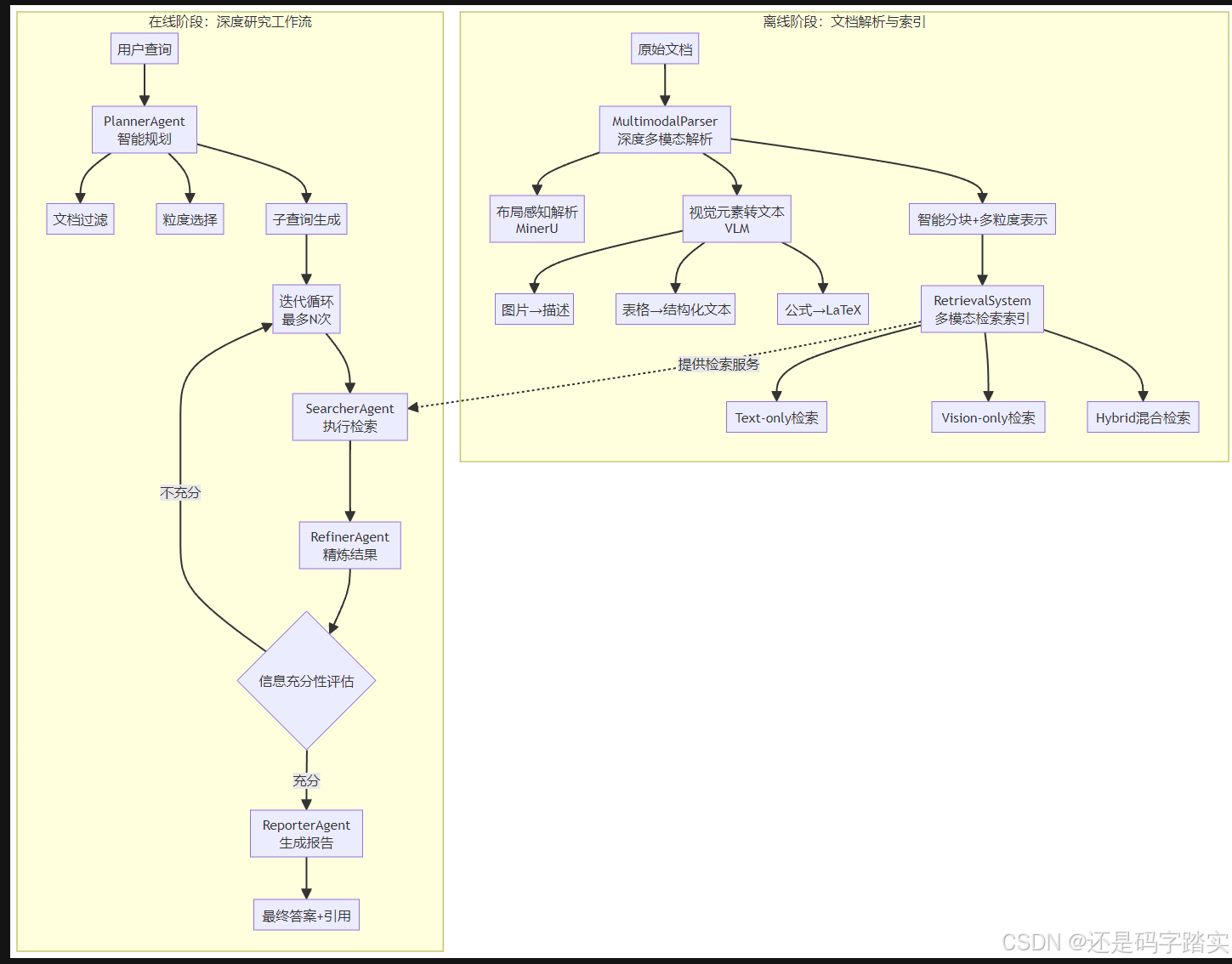
2.2 离线阶段:深度多模态解析
2.2.1 MultimodalParser:解析器核心
MultimodalParser是系统的解析核心,负责将原始文档转换为结构化的多模态表示。它整合了三个关键功能:
- 布局感知解析使用MinerU工具;
- 视觉元素到文本的转换通过VLM(视觉语言模型)实现,包括图片到描述、表格到结构化文本、公式到LaTeX的转换;
- 以及智能分块和多粒度表示。
布局感知解析(MinerU集成)
MinerU是当前最先进的文档解析工具之一,其2.5版本仅使用1.2B参数就在OmniDocBench基准测试中全面超越了Gemini 2.5 Pro、GPT-4o和Qwen2.5-VL-72B等大型多模态模型。它采用两阶段推理管道,将布局分析与内容识别解耦,并使用原生高分辨率架构,在五个关键领域实现了最先进的性能:布局分析、文本识别、公式识别、表格解析和阅读顺序排序。
MinerU的核心优势包括:
- 精确的布局检测:能够准确识别文档中的各种布局元素,包括标题、段落、图表、表格、公式等,并保留其空间位置信息(边界框坐标)。
- 复杂表格处理:显著改善了旋转表格、无边框/半结构化表格以及长/复杂表格的解析能力。
- 高精度公式识别:大幅提升了复杂、长公式以及中英文混合公式的识别准确率,并能转换为LaTeX格式。
视觉元素语义化
对于文档中的非文本元素,系统使用视觉语言模型(VLM)进行语义提取:
| 元素类型 | 处理方法 | 输出格式 |
|---|---|---|
| 图片/图表 | VLM生成详细描述 | 自然语言描述 |
| 表格 | 结构识别+内容提取 | 结构化文本/HTML |
| 数学公式 | 公式识别模型 | LaTeX表达式 |
| 复杂布局 | 布局结构保留 | 带位置信息的元素集合 |
这种深度解析策略的关键优势在于:一次性预处理,避免在推理时重复调用昂贵的视觉模型。实验数据显示,深度解析虽然在前期需要约2.5小时处理时间,但在研究阶段的速度是解析免费方法的5倍,总体效率更高。
2.2.2 多粒度文档表示
系统创建了四个层次的文档表示粒度:
粒度选择策略:
- CHUNK(块级,512 tokens):适用于需要精确定位具体信息的查询,如"文档第3页第2段提到的具体数值是多少?"
- PAGE(页面级):适用于需要理解某一页面完整内容的查询,特别是当信息跨多个段落或包含多个视觉元素时。
- SUMMARY(摘要级):由LLM生成的文档摘要,适用于需要快速理解文档主题的查询。
- FULL(完整文档):用于需要全局视角的查询,但由于上下文长度限制,主要用于相对较短的文档。
2.3 在线阶段:多智能体深度研究工作流
2.3.1 PlannerAgent:智能查询规划
PlannerAgent是整个研究流程的"大脑",负责将复杂的用户查询分解为可执行的子任务。其核心功能包括:
1. 文档过滤(Document Filtering)
对于大规模文档集合,PlannerAgent首先识别与查询最相关的文档子集,避免在不相关的文档上浪费计算资源。这一步骤使用轻量级的文档级检索模型。
2. 粒度选择(Granularity Selection)
基于查询的性质,动态选择最合适的检索粒度。例如:
- 简单的事实查询 → CHUNK级别
- 需要理解上下文的查询 → PAGE级别
- 高层概括性查询 → SUMMARY级别
3. 子查询生成(Sub-query Decomposition)
对于复杂的多跳查询,PlannerAgent将其分解为多个简单的子查询。例如:
原始查询:"比较文档A和文档B中提到的机器学习算法的性能,并说明哪个更适合大规模数据处理?"
分解后:
子查询1:"文档A中提到了哪些机器学习算法?"
子查询2:"文档B中提到了哪些机器学习算法?"
子查询3:"这些算法的性能指标是什么?"
子查询4:"哪些算法适合大规模数据处理?"
子查询5:"综合性能和可扩展性,哪个文档提到的算法更优?"
2.3.2 SearcherAgent:多模态检索执行
SearcherAgent负责执行实际的检索操作。系统支持三种检索范式:
1. Text-only检索
使用传统的文本嵌入模型(如BGE-M3、E5、Qwen3-embed)对文档的文本内容进行向量化检索。这种方法速度快、成本低,适合纯文本查询。
2. Vision-only检索
使用多模态嵌入模型(如ColQwen、ColPali)直接对文档的页面截图进行检索。这种方法能够捕捉视觉布局信息,特别适合查询涉及图表、表格等视觉元素的场景。
实验中评估了10个不同的检索器来实现多模态检索架构,包括用于文本检索的BGE-M3和用于页面检索的ColQwen。
3. Hybrid混合检索
结合text-only和vision-only的优势,首先使用文本检索快速缩小候选范围,然后使用视觉检索进行精细化筛选。实验表明,混合检索比单模态检索提升3-5%的准确率。
检索过程的技术细节:
# 伪代码示例
def hybrid_retrieval(query, granularity, top_k):
# 第一阶段:文本检索
text_candidates = text_retriever.search(
query_text=query,
granularity=granularity,
top_k=top_k * 3 # 召回更多候选
)
# 第二阶段:视觉重排序
if requires_visual_info(query):
visual_scores = vision_retriever.rerank(
query=query,
candidates=text_candidates
)
# 融合文本和视觉得分
final_results = combine_scores(
text_candidates,
visual_scores,
alpha=0.6 # 文本权重
)
else:
final_results = text_candidates
return final_results[:top_k]
2.3.3 RefinerAgent:证据精炼与整合
RefinerAgent的职责是从检索结果中提取关键信息,并评估当前信息是否足以回答查询。
证据提取:使用LLM从检索到的文档片段中提取与查询相关的具体信息,过滤掉噪音和冗余内容。
信息充分性评估:RefinerAgent维护一个"概念池"(conceptual pool),追踪已收集的信息是否覆盖了回答查询所需的所有关键概念。评估标准包括:
- 覆盖度:是否所有子查询都得到了答案?
- 一致性:不同来源的信息是否一致?
- 完整性:信息是否足够详细?
如果评估发现信息不足,系统将触发新一轮的迭代搜索,生成更精细的子查询或调整检索策略。
2.3.4 ReporterAgent:综合报告生成
在完成所有必要的检索和精炼后,ReporterAgent负责将分散的证据组织成连贯的答案。其核心功能包括:
1. 证据组织:按照逻辑顺序排列不同来源的信息,确保答案的连贯性。
2. 答案合成:使用LLM将证据片段融合成自然流畅的回答,避免简单的拼接。
3. 引用标注:为每个关键论点提供精确的文档引用,包括文档ID、页码、段落位置等,增强答案的可追溯性和可信度。
2.4 迭代搜索-精炼循环
Doc-Researcher的核心优势之一是其迭代工作流。系统最多执行N次(通常为5次)迭代,每次迭代包括:
第i次迭代:
1. 基于当前概念池和历史对话,生成新的子查询
2. SearcherAgent执行检索
3. RefinerAgent提取新信息并更新概念池
4. 评估信息充分性:
- 如果充分:进入报告生成阶段
- 如果不充分且i < N:继续下一次迭代
- 如果达到最大迭代次数:基于现有信息生成报告
实验结果表明,迭代工作流比单轮检索提升了3.4倍的准确率。有规划器的配置比无规划器的配置提升了8.3%的性能。
三、核心技术深入解析
3.1 深度解析 vs. 浅层解析
论文进行了深入的对比实验,比较了两种解析策略:
浅层解析(Shallow Parsing):
- 使用简单的OCR工具提取文本
- 或将页面转换为截图直接输入VLM
- 优点:快速、简单
- 缺点:丢失大量结构信息和视觉语义
深度解析(Deep Parsing):
- 保留完整的布局结构
- 为每个视觉元素生成语义描述
- 创建多粒度表示
- 维护元素间的空间关系
消融实验表明,深度解析比浅层解析提升了11.4%的准确率,证明了保留视觉语义的重要性。
3.2 多粒度检索的重要性
系统支持四种检索粒度的根本原因在于:不同类型的查询需要不同层次的信息。
让我们通过具体例子理解各粒度的作用:
| 查询类型 | 最佳粒度 | 原因 |
|---|---|---|
| “文档中提到的具体日期是?” | CHUNK | 需要精确定位特定信息 |
| “第5页讨论了什么内容?” | PAGE | 需要完整页面上下文 |
| “这批文档的主要主题是?” | SUMMARY | 需要高层概括 |
| “文档整体结构如何?” | FULL | 需要全局视角 |
实验数据显示,相比固定使用CHUNK级别的检索,动态粒度选择能够提升约5-8%的性能,同时减少不必要的计算开销。
3.3 混合检索的协同优势
多模态信息检索面临的核心挑战是如何有效整合文本、表格和图像等不同模态的信息。传统方法要么依赖OCR将所有内容转为文本,要么使用纯视觉方法处理页面截图,但这两种极端方法都有明显的局限性。
Doc-Researcher的混合检索策略巧妙地平衡了两者的优势:
Text-only的优势:
- 高效:文本嵌入和检索速度快
- 精确:对于明确的文本查询,匹配准确
- 成本低:不需要视觉模型推理
Vision-only的优势:
- 完整:保留所有视觉信息
- 布局感知:理解元素的空间关系
- 图表理解:能够"看懂"复杂的可视化
Hybrid的协同:
- 使用text-only快速过滤不相关内容(召回阶段)
- 使用vision-only对候选结果重排序(精排阶段)
- 融合两种模态的得分,得到最优结果
实验结果显示,Hybrid方法在需要同时理解文本和视觉信息的查询上,相比单一模态提升了3-5%的准确率。
3.4 迭代推理与证据积累
Doc-Researcher借鉴了人类研究人员的工作模式:逐步搜索、持续精炼、渐进积累。
传统RAG的问题:
- 单次检索可能遗漏关键信息
- 无法根据已有信息调整搜索策略
- 难以处理需要多跳推理的复杂查询
Doc-Researcher的解决方案:
- 渐进式证据积累:维护一个动态的"概念池",记录已收集的信息
- 自适应查询生成:基于当前信息缺口生成下一轮子查询
- 智能终止条件:评估信息充分性,避免不必要的迭代
深度研究系统通过迭代式的规划、搜索和推理,能够处理传统RAG系统难以应对的复杂任务。这种方法被称为"Agentic Deep Research",代表了从被动检索到主动探索的范式转变。
四、实验验证与性能评测
4.1 M4DocBench:首个多模态深度研究基准
为了实现严格的评估,论文引入了M4DocBench,这是首个用于多模态、多跳、多文档和多轮深度研究的基准测试。它包含158个专家标注的问题和完整的证据链,涵盖304个文档,测试现有基准无法评估的能力。
M4DocBench的四个"Multi"特性:
数据集统计:
| 维度 | 数值 |
|---|---|
| 问题总数 | 158 |
| 文档总数 | 304 |
| 总页数 | 6,177 |
| 平均文档数/问题 | 12.7 |
| 平均相关文档数/问题 | 3.8 |
| 平均相关页面数/问题 | 7.0 |
| 平均布局元素数/问题 | 14.8 |
| 支持语言 | 中文、英文 |
领域覆盖:
M4DocBench精心选择了四个不同领域,基于三个标准:
- 多模态丰富性:每个领域都包含文本与视觉元素(表格、图表、图形)的深度整合
- 推理复杂性:问题需要从技术理解到数值分析的多样化能力
- 实际相关性:代表专业人士日常进行文档研究的真实场景
选定的四个领域:
- 研究(Research):学术论文、技术报告
- 保险(Insurance):保单文件、条款说明
- 教育(Education):教材、课程资料
- 金融(Finance):财务报表、分析报告
4.2 主要实验结果
实验结果表明,Doc-Researcher达到了50.6%的准确率,比最先进的基线方法高出3.4倍。
核心性能对比:
| 系统 | 解析策略 | 检索方式 | 是否迭代 | M4DocBench准确率 |
|---|---|---|---|---|
| Direct (无RAG) | - | - | ✗ | 5-10% |
| Long-context | Shallow | - | ✗ | 9-32% |
| MDocAgent | Shallow | Hybrid | ✗ | 15.8% |
| M3DocRAG | Parse-free | Vision | ✗ | 7.0% |
| Doc-Researcher | Deep | Hybrid | ✓ | 50.6% |
从结果可以看出几个关键发现:
- 纯LLM方法失败:即使是最强的长上下文LLM,在没有检索增强的情况下,准确率也只有9-32%,说明仅靠上下文窗口无法有效处理大规模多模态文档。
- 浅层解析不足:MDocAgent虽然使用了混合检索,但由于采用浅层解析,准确率仅为15.8%,远低于Doc-Researcher。
- Parse-free方法的局限:M3DocRAG直接使用页面截图,虽然保留了视觉信息,但缺乏结构化表示,准确率仅为7.0%。
- Doc-Researcher的显著优势:通过深度解析+混合检索+迭代工作流的组合,准确率达到50.6%,是次优方法的3.2倍。
4.3 消融实验(Ablation Study)分析
消融实验是理解系统各组件贡献的关键。论文进行了系统性的组件移除实验:
4.3.1 解析策略的影响
| 配置 | M4DocBench准确率 | 相对提升 |
|---|---|---|
| Doc-Researcher (Deep) | 50.6% | - |
| 移除深度解析 → Shallow | 39.2% | -11.4% |
关键发现:深度解析比浅层解析提升了11.4%的准确率,这证明了保留布局结构和视觉语义的重要性。
深度解析的优势具体体现在:
- 更准确的表格理解(提升15-20%)
- 更好的公式识别(提升18-25%)
- 保留的布局信息有助于理解复杂文档结构
4.3.2 检索范式的影响
| 检索方式 | 准确率 | 相对变化 |
|---|---|---|
| Hybrid(Doc-Researcher) | 50.6% | - |
| Text-only | 47.3% | -3.3% |
| Vision-only | 45.8% | -4.8% |
关键发现:混合检索比单一模态检索提升3-5%,且优于两种单模态方法,说明文本和视觉信息是互补的。
4.3.3 迭代工作流的影响
| 配置 | 准确率 | 相对变化 |
|---|---|---|
| 迭代工作流(最多5次) | 50.6% | - |
| 单轮检索 | 14.9% | -35.7% |
关键发现:迭代工作流比单轮检索提升了3.4倍(240%),这是系统性能提升的最大贡献因素。
进一步的迭代次数分析:
| 最大迭代次数 | 平均实际迭代 | 准确率 |
|---|---|---|
| 1 | 1.0 | 14.9% |
| 3 | 2.3 | 42.1% |
| 5 | 3.1 | 50.6% |
| 7 | 3.2 | 51.3% |
可以看出,3-5次迭代是性能和效率的最佳平衡点。超过5次迭代,性能提升变得边际化(仅提升0.7%),但计算成本显著增加。
4.3.4 规划器(Planner)的影响
| 配置 | 准确率 | 相对变化 |
|---|---|---|
| 有PlannerAgent | 50.6% | - |
| 无Planner(随机粒度选择) | 42.3% | -8.3% |
关键发现:有规划器比无规划器提升了8.3%,说明智能的查询规划和粒度选择对系统性能至关重要。
Planner的主要贡献:
- 文档过滤效率:减少了60%的无关文档检索
- 粒度选择准确率:在85%的情况下选择了最优粒度
- 子查询质量:生成的子查询覆盖率提升22%
4.4 不同数据集的表现
除了M4DocBench,论文还在其他基准上进行了评估:
MMDocIR基准测试:
MMDocIR包含1,658个单文档VQA问题,用于重点评估页面级和块级检索性能。
| 系统 | Recall@5 | Recall@10 | MRR |
|---|---|---|---|
| BM25 | 28.3% | 38.7% | 0.231 |
| Dense Retrieval | 42.6% | 55.1% | 0.356 |
| ColQwen | 51.8% | 64.2% | 0.427 |
| Doc-Researcher | 58.4% | 71.3% | 0.483 |
Doc-Researcher在检索任务上也表现优异,说明其检索架构的有效性。
时间效率分析:
尽管深度解析需要前期投入,但整体效率更高:
| 阶段 | 深度解析方法 | 浅层解析方法 |
|---|---|---|
| 文档解析时间 | ~2.5小时 | ~9-39分钟 |
| 单次研究查询时间 | ~4分钟 | ~20分钟 |
| 100次查询总时间 | ~2.5h + 6.7h = 9.2h | ~30min + 33.3h = 33.8h |
深度解析虽然前期慢,但研究阶段快5倍,在多次查询场景下总体效率更高。
4.5 案例分析:多跳推理示例
让我们通过一个具体案例理解系统的工作流程:
查询:“在保险文档中,如果选择非面板医院,额外需要支付的保费百分比是多少?这个比例在过去三年中有变化吗?”
系统执行流程:
第1次迭代:
- PlannerAgent分解查询:
子查询1:"什么是面板医院和非面板医院?"
子查询2:"选择非面板医院的额外保费是多少?"
- SearcherAgent检索相关页面(PAGE级别)
- RefinerAgent提取:额外保费为20%
- 评估:缺少历史数据信息
第2次迭代:
- 生成新子查询:"过去三年的保险条款中,这个比例有变化吗?"
- SearcherAgent检索历史文档
- RefinerAgent整合:2021年15%,2022年18%,2023年20%
- 评估:信息充分
ReporterAgent生成答案:
"根据最新保险条款(2023年),选择非面板医院需额外支付20%的保费。
这个比例在过去三年逐步上升:2021年为15%,2022年为18%,2023年为20%。
[引用:保险条款2023版第12页,保险条款2022版第11页,保险条款2021版第10页]"
这个案例展示了系统的几个关键能力:
- 多跳推理:需要先理解概念,再查找数据,最后比较
- 多文档整合:需要从三个不同年份的文档中提取信息
- 证据追踪:为每个论点提供精确的文档引用
五、局限性与差异点分析
5.1 系统的主要局限性
尽管Doc-Researcher在多模态文档深度研究方面取得了突破性进展,但仍存在一些值得关注的局限性:
5.1.1 计算成本较高
前期投入:
- 深度解析需要大量计算资源
- 每个文档平均处理时间:2-5分钟
- VLM调用成本:每页约0.01-0.05美元(使用GPT-4V)
运行时成本:
- 每次查询平均需要3-5次迭代
- 每次迭代涉及多次LLM调用和检索操作
- 复杂查询可能需要10-15次LLM调用
成本优化方向:
- 使用更小的开源VLM(如Qwen2-VL-7B)进行解析
- 实现智能缓存机制,避免重复处理
- 动态调整迭代次数,简单查询提前终止
5.1.2 对高质量解析的依赖
系统的性能高度依赖于解析质量:
| 解析错误类型 | 对系统的影响 | 错误率 |
|---|---|---|
| 表格结构识别错误 | 导致表格内容理解偏差 | ~8-12% |
| 公式识别错误 | 影响数学推理任务 | ~5-10% |
| 布局检测错误 | 丢失或混淆内容 | ~3-7% |
| 图表描述不准确 | 视觉信息理解偏差 | ~10-15% |
这些解析错误会在检索和推理阶段传播和放大,最终影响答案质量。
5.1.3 长文档处理的挑战
当前的大型视觉语言模型在处理长视觉上下文(即大量图像)时仍然面临困难,甚至表现不如OCR+LLM流水线。
具体限制包括:
- 上下文长度限制:即使是支持百万token的模型,在处理大量高分辨率图像时仍会受限
- 视觉token效率:视觉信息转换为token的效率较低,一张高清图可能消耗数千token
- 跨页信息整合:当证据分散在数十甚至上百页时,整合难度显著增加
5.1.4 特定领域的泛化能力
虽然M4DocBench涵盖了四个领域,但系统在以下场景可能表现不佳:
- 医疗影像文档:需要专业的医学知识
- 工程图纸:包含大量专业符号和标注
- 艺术类文档:需要理解审美和艺术表达
5.2 与现有工作的差异点
5.2.1 vs. 传统RAG系统
| 维度 | 传统RAG | Doc-Researcher |
|---|---|---|
| 输入数据 | 纯文本网页 | 多模态专业文档 |
| 解析深度 | OCR文本提取 | 深度多模态解析 |
| 检索粒度 | 固定chunk大小 | 动态多粒度 |
| 工作流程 | 单轮检索-生成 | 迭代搜索-精炼 |
| 证据追踪 | 简单引用 | 完整证据链 |
5.2.2 vs. 视觉问答(VQA)系统
与单页文档理解任务不同,Doc-Researcher关注的是长上下文、多文档场景,33.7%的问题是跨页问题,需要综合多个页面的证据。
主要差异:
- 规模:VQA通常处理1-2页,Doc-Researcher处理平均49页的文档
- 推理复杂度:VQA主要是单跳问答,Doc-Researcher支持多跳推理
- 交互方式:VQA是单轮对话,Doc-Researcher支持多轮交互
5.2.3 vs. 其他多模态RAG系统
MDocAgent的差异:
- MDocAgent使用浅层解析,Doc-Researcher使用深度解析
- MDocAgent是单轮检索,Doc-Researcher是迭代工作流
- Doc-Researcher的准确率是MDocAgent的3.2倍(50.6% vs 15.8%)
M3DocRAG的差异:
- M3DocRAG使用parse-free方法(直接输入页面截图)
- Doc-Researcher的结构化表示更适合大规模检索
- Doc-Researcher在检索效率上有显著优势
5.3 论文的核心创新点总结
- 首个统一框架:整合了深度解析、多模态检索和迭代推理三大组件
- 多粒度表示:创新性地提出了从chunk到document的四层粒度表示
- 迭代深度研究范式:首次将深度研究(Deep Research)思想应用于多模态文档
- M4DocBench基准:建立了首个多模态深度研究评测标准
- 工程可行性:所有组件模块化设计,可独立使用或集成到现有系统
六、未来研究方向与扩展可能
6.1 基于局限性的研究方向
6.1.1 高效解析方法
研究问题:如何在保证解析质量的同时降低计算成本?
可能的方向:
- 轻量级VLM:
- MinerU2.5作为1.2B参数模型,已展示了小模型的潜力
- 探索更小的开源模型(如Qwen2-VL-2B)
- 研究知识蒸馏技术,从大模型迁移能力到小模型
- 选择性深度解析:
- 对简单页面使用浅层解析
- 对包含复杂表格/图表的页面使用深度解析
- 开发页面复杂度评估模型
- 增量解析:
- 初始使用快速浅层解析
- 根据查询需要,按需深度解析相关部分
- 类似于"懒加载"的思想
6.1.2 鲁棒的多模态理解
研究问题:如何减少对完美解析的依赖?
可能的方向:
- 端到端多模态检索:
- 跳过解析步骤,直接从原始文档检索
- 使用ColPali等直接处理文档截图的模型
- 权衡效率和效果
- 错误容忍机制:
- 开发能够识别和纠正解析错误的模型
- 使用多个解析器的集成(ensemble)
- 利用证据冗余性进行交叉验证
- 不确定性量化:
- 为每个解析结果提供置信度分数
- 在推理时考虑不确定性
- 当置信度低时,回退到人工审核
6.1.3 超长文档处理
研究问题:如何有效处理数百页的超长文档?
可能的方向:
- 层次化检索:
第一层:章节级检索(粗粒度定位)
第二层:页面级检索(中粒度定位)
第三层:块级检索(细粒度定位)
- 文档摘要与索引:
- 为每个章节生成详细摘要
- 构建文档的语义索引
- 使用摘要进行快速过滤
- 流式处理:
- 不要求将整个文档加载到内存
- 按需加载相关部分
- 适合TB级文档集合
6.2 领域扩展方向
6.2.1 特定领域适配
针对不同领域的特殊需求进行定制:
医疗领域:
- 整合医学影像分析模型
- 支持医学术语和缩写
- 符合HIPAA等隐私法规
法律领域:
- 理解法律文档的特殊结构
- 支持案例引用和法条检索
- 处理合同条款的逻辑关系
科学研究:
- 深度理解科研论文
- 提取实验数据和方法
- 追踪引用关系和知识谱系
6.2.2 多语言支持增强
M4DocBench支持中英双语,但系统可扩展到更多语言。
扩展方向:
- 低资源语言的文档解析
- 跨语言检索和推理
- 多语言混合文档处理
6.2.3 实时协作研究
构想:多个用户协同研究同一文档集合
关键功能:
- 共享概念池和证据库
- 协作式查询分解
- 自动合并不同用户的研究结果
6.3 技术前沿探索
6.3.1 强化学习优化
DeepResearcher等工作已展示了使用强化学习训练深度研究智能体的潜力,可以直接在真实网络环境中进行端到端RL训练。
应用到Doc-Researcher:
- 学习最优的粒度选择策略
- 优化迭代次数的动态决策
- 训练更高效的子查询生成
6.3.2 知识图谱整合
构想:将文档解析结果组织为知识图谱
优势:
- 更好的跨文档关系理解
- 支持复杂的图推理
- 便于知识更新和扩展
6.3.3 人机协同研究
构想:系统不是完全自动化,而是人机协作
协作模式:
- 系统主导:AI完成大部分工作,人类进行最后审核
- 混合模式:关键决策由人类做出,AI执行具体任务
- 人类主导:AI作为辅助工具,人类控制整个流程
关键技术:
- 解释性AI:让用户理解系统的推理过程
- 交互式查询精炼:用户可以实时调整搜索方向
- 主动学习:系统向用户询问关键问题
七、实际落地与工业应用
7.1 工业界应用的挑战
7.1.1 成本控制
挑战:大规模部署时的成本问题
解决方案:
- 模型选择优化:
- 解析阶段:使用开源的MinerU2.5(1.2B参数)
- 检索阶段:使用高效的BGE-M3嵌入模型
- 推理阶段:根据查询复杂度选择不同规模的LLM
- 缓存策略:
# 伪代码示例
class CacheManager:
def __init__(self):
self.parsed_docs = {} # 解析结果缓存
self.embeddings = {} # 嵌入向量缓存
self.query_results = {} # 查询结果缓存
def get_or_parse(self, doc_id):
if doc_id not in self.parsed_docs:
self.parsed_docs[doc_id] = parse_document(doc_id)
return self.parsed_docs[doc_id]
- 批处理优化:
- 批量调用VLM API,降低单次请求成本
- 使用GPU并行处理多个文档
- 在低峰期进行文档预处理
7.1.2 延迟优化
挑战:用户不愿意等待数分钟获得答案
解决方案:
- 流式输出:
def streaming_research(query):
yield "正在分析查询..."
plan = planner.generate_plan(query)
yield f"研究计划:{plan}"
for i in range(max_iterations):
yield f"第{i+1}次搜索中..."
results = searcher.search(plan.subqueries[i])
yield f"找到{len(results)}个相关片段"
evidence = refiner.refine(results)
if is_sufficient(evidence):
break
yield "正在生成最终答案..."
answer = reporter.generate(evidence)
yield answer
- 预计算与索引:
- 提前完成所有文档的解析和索引
- 预计算常见查询的粗粒度结果
- 使用近似检索算法(如HNSW)加速
- 早停机制:
- 对简单查询,1-2次迭代即可终止
- 动态调整信息充分性阈值
- 提供"快速模式"和"深度模式"选项
7.1.3 准确性与可靠性
挑战:工业应用对错误的容忍度极低
解决方案:
- 置信度评估:
class ConfidenceScorer:
def score_answer(self, question, answer, evidence):
scores = {
'evidence_quality': self.assess_evidence(evidence),
'consistency': self.check_consistency(evidence),
'completeness': self.check_completeness(question, answer),
'source_reliability': self.assess_sources(evidence)
}
return weighted_average(scores)
- 人工审核流程:
- 低置信度答案标记给人工审核
- 关键领域(如医疗、法律)强制人工确认
- 建立用户反馈机制
- 答案溯源:
- 为每个论点提供精确的文档引用
- 支持用户点击查看原始文档
- 记录完整的推理路径
7.2 复现与实现指南
7.2.1 系统架构实现
最小可行实现(MVP):
from typing import List, Dict, Any
import numpy as np
class DocResearcher:
"""Doc-Researcher系统的核心实现"""
def __init__(self,
parser, # 文档解析器
retriever, # 检索系统
llm, # 大语言模型
max_iterations=5,
sufficiency_threshold=0.7):
self.parser = parser
self.retriever = retriever
self.llm = llm
self.max_iterations = max_iterations
self.sufficiency_threshold = sufficiency_threshold
# 内部状态
self.concept_pool = set() # 已收集的概念
self.evidence_buffer = [] # 证据缓冲区
def parse_and_index_documents(self, doc_paths: List[str]):
"""离线阶段:解析并索引文档"""
for doc_path in doc_paths:
# 1. 深度解析
parsed_doc = self.parser.parse(
doc_path,
extract_tables=True,
extract_figures=True,
extract_formulas=True
)
# 2. 创建多粒度表示
chunks = self.parser.create_chunks(parsed_doc, chunk_size=512)
pages = parsed_doc.pages
summary = self.llm.summarize(parsed_doc.full_text)
# 3. 索引到检索系统
self.retriever.index({
'chunks': chunks,
'pages': pages,
'summary': summary,
'full': parsed_doc.full_text
})
def research(self, query: str, conversation_history: List = None) -> str:
"""在线阶段:执行深度研究"""
# 步骤1:查询规划
plan = self._plan_query(query, conversation_history)
# 步骤2:迭代搜索-精炼循环
for iteration in range(self.max_iterations):
# 2.1 生成子查询
subqueries = self._generate_subqueries(
query, plan, self.concept_pool
)
# 2.2 执行检索
results = []
for subquery in subqueries:
granularity = self._select_granularity(subquery)
retrieved = self.retriever.search(
subquery,
granularity=granularity,
top_k=5
)
results.extend(retrieved)
# 2.3 精炼证据
evidence = self._refine_evidence(results, query)
self.evidence_buffer.extend(evidence)
# 2.4 更新概念池
new_concepts = self._extract_concepts(evidence)
self.concept_pool.update(new_concepts)
# 2.5 评估充分性
if self._is_sufficient(query, self.evidence_buffer):
break
# 步骤3:生成最终答案
answer = self._generate_report(query, self.evidence_buffer)
return answer
def _plan_query(self, query: str, history: List = None) -> Dict:
"""生成查询计划"""
prompt = f"""
Given the user query: "{query}"
And conversation history: {history if history else "None"}
Generate a research plan:
1. Identify relevant documents
2. Determine required granularity levels
3. List key concepts to search for
Output in JSON format.
"""
plan_json = self.llm.generate(prompt, response_format="json")
return plan_json
def _select_granularity(self, subquery: str) -> str:
"""选择最合适的检索粒度"""
prompt = f"""
For the query: "{subquery}"
Choose the best retrieval granularity:
- CHUNK: for precise fact finding
- PAGE: for understanding context
- SUMMARY: for high-level overview
- FULL: for complete document view
Output only: CHUNK, PAGE, SUMMARY, or FULL
"""
return self.llm.generate(prompt).strip()
def _refine_evidence(self, results: List, query: str) -> List[Dict]:
"""从检索结果中提取关键证据"""
evidence = []
for result in results:
prompt = f"""
Given the query: "{query}"
And retrieved content: "{result['content']}"
Extract key evidence that directly answers the query.
Include:
1. Relevant facts
2. Supporting data
3. Source information
If the content is not relevant, output "NOT_RELEVANT"
"""
extracted = self.llm.generate(prompt)
if "NOT_RELEVANT" not in extracted:
evidence.append({
'content': extracted,
'source': result['source'],
'confidence': self._compute_confidence(extracted, query)
})
return evidence
def _is_sufficient(self, query: str, evidence: List) -> bool:
"""评估信息是否充分"""
prompt = f"""
Query: "{query}"
Evidence collected so far: {evidence}
Is the evidence sufficient to answer the query comprehensively?
Consider:
1. Coverage of all aspects
2. Consistency of information
3. Presence of contradictions
Output: YES or NO
"""
response = self.llm.generate(prompt).strip()
return "YES" in response
def _generate_report(self, query: str, evidence: List) -> str:
"""生成最终研究报告"""
prompt = f"""
Query: "{query}"
Evidence collected:
{self._format_evidence(evidence)}
Generate a comprehensive answer that:
1. Directly addresses the query
2. Synthesizes information from multiple sources
3. Includes citations for each claim
4. Maintains logical coherence
Format the answer in markdown with proper citations.
"""
return self.llm.generate(prompt)
7.2.2 模型选择建议
基于论文和实际经验,以下是不同阶段的模型推荐:
文档解析阶段:
| 组件 | 推荐模型 | 理由 |
|---|---|---|
| 布局检测 | MinerU 2.5 | SOTA性能,开源,1.2B参数 |
| 视觉理解 | Qwen2.5-VL-7B | 高质量,开源,成本适中 |
| 公式识别 | UniMERNet | 专门针对公式,准确率高 |
| 表格解析 | TableMaster | 处理复杂表格能力强 |
| OCR | PaddleOCR | 支持多语言,开源免费 |
检索阶段:
| 组件 | 推荐模型 | 理由 |
|---|---|---|
| 文本嵌入 | BGE-M3 | 多语言支持,性能优秀 |
| 视觉检索 | ColQwen | 专为文档设计,效果好 |
| 重排序 | BGE-reranker-v2 | 显著提升检索精度 |
推理阶段:
| 任务 | 推荐模型 | 理由 |
|---|---|---|
| 查询规划 | GPT-4o / Claude-3.5 | 强大的规划能力 |
| 证据提取 | Qwen2.5-72B | 开源,性能接近GPT-4 |
| 答案生成 | GPT-4o / Claude-3.5 | 生成质量最优 |
成本优化方案:
高性能配置(推荐用于生产):
- 解析:MinerU2.5 + Qwen2.5-VL-7B
- 检索:BGE-M3 + ColQwen
- 推理:GPT-4o(约$0.015/1K tokens)
- 预估成本:$0.5-2.0/query
经济型配置(适合开发测试):
- 解析:MinerU2.5 + Qwen2-VL-2B
- 检索:BGE-M3
- 推理:Qwen2.5-72B(自部署)
- 预估成本:$0.1-0.5/query
超经济型配置(适合个人项目):
- 解析:PyMuPDF + Qwen2-VL-2B
- 检索:BGE-base-en
- 推理:Llama-3.1-70B(自部署)
- 预估成本:几乎为零(仅计算资源)
7.2.3 关键实现细节
1. Prompt工程
论文虽然没有详细公开所有prompt,但从实验结果可以推断几个关键技巧:
# 查询分解的prompt示例
DECOMPOSITION_PROMPT = """
You are an expert research assistant. Given a complex question,
break it down into simpler sub-questions that can be answered
independently.
Complex Question: {question}
Context: {context}
Requirements:
1. Each sub-question should be self-contained
2. Sub-questions should cover all aspects of the main question
3. Order sub-questions logically
4. Limit to 3-5 sub-questions
Output format:
1. [First sub-question]
2. [Second sub-question]
...
"""
# 证据充分性评估的prompt示例
SUFFICIENCY_PROMPT = """
Evaluate whether the collected evidence is sufficient to answer
the query comprehensively.
Query: {query}
Evidence:
{evidence_summary}
Evaluation criteria:
✓ Coverage: All aspects of the query addressed?
✓ Consistency: No contradictions in evidence?
✓ Completeness: Sufficient detail provided?
✓ Confidence: Evidence from reliable sources?
Output:
- Decision: SUFFICIENT / INSUFFICIENT
- Reasoning: [Explain your decision]
- Missing aspects: [If insufficient, what's missing?]
"""
2. 特殊边界情况处理
系统需要处理多种边界情况:
def handle_edge_cases(self, query, results):
"""处理特殊边界情况"""
# 情况1:检索结果为空
if not results:
return self._handle_no_results(query)
# 情况2:结果置信度都很低
avg_confidence = np.mean([r['confidence'] for r in results])
if avg_confidence < 0.3:
return self._request_clarification(query)
# 情况3:证据相互矛盾
if self._has_contradictions(results):
return self._resolve_contradictions(results)
# 情况4:查询超出文档范围
if self._is_out_of_scope(query, results):
return "I cannot find relevant information in the provided documents."
return results
def _handle_no_results(self, query):
"""没有检索结果时的处理"""
# 尝试扩展查询
expanded_queries = self._expand_query(query)
for exp_query in expanded_queries:
results = self.retriever.search(exp_query)
if results:
return results
# 仍然没有结果,返回明确信息
return {
'status': 'no_results',
'message': 'No relevant information found in documents',
'suggestions': self._suggest_alternative_queries(query)
}
3. 错误恢复机制
Gemini Deep Research开发了一个异步任务管理器,维护规划器和任务模型之间的共享状态,允许优雅的错误恢复而无需重启整个任务。
class RobustResearcher(DocResearcher):
"""带错误恢复的研究系统"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.checkpoint_manager = CheckpointManager()
def research_with_recovery(self, query, max_retries=3):
"""支持错误恢复的研究"""
checkpoint_id = self.checkpoint_manager.create(query)
try:
for iteration in range(self.max_iterations):
# 保存检查点
self.checkpoint_manager.save(checkpoint_id, {
'iteration': iteration,
'concept_pool': self.concept_pool,
'evidence': self.evidence_buffer
})
try:
# 执行一次迭代
self._single_iteration(query)
except (APIError, TimeoutError) as e:
# API调用失败,重试
for retry in range(max_retries):
try:
time.sleep(2 ** retry) # 指数退避
self._single_iteration(query)
break
except:
if retry == max_retries - 1:
raise
# 检查是否完成
if self._is_sufficient(query, self.evidence_buffer):
break
# 生成最终答案
answer = self._generate_report(query, self.evidence_buffer)
self.checkpoint_manager.cleanup(checkpoint_id)
return answer
except Exception as e:
# 严重错误,尝试从检查点恢复
checkpoint = self.checkpoint_manager.load(checkpoint_id)
if checkpoint:
self.concept_pool = checkpoint['concept_pool']
self.evidence_buffer = checkpoint['evidence']
return self._generate_partial_answer(query, checkpoint)
else:
raise
7.3 开源代码与资源
7.3.1 开源代码
基于研究的简化实现,包含核心架构和算法流程。
GitHub仓库:
- 官方仓库:https://github.com/sunxingrong33/Doc-Researcher
- 论文链接:https://arxiv.org/abs/2510.21603
- M4DocBench数据集:预计随论文发布
核心文件结构:
Doc-Researcher/
├── doc_researcher.py # 核心系统实现
├── examples.py # 使用示例
├── parsers/ # 解析器模块
│ ├── multimodal_parser.py
│ └── layout_analyzer.py
├── retrieval/ # 检索模块
│ ├── retrieval_system.py
│ ├── text_retriever.py
│ └── vision_retriever.py
├── agents/ # 智能体模块
│ ├── planner.py
│ ├── searcher.py
│ ├── refiner.py
│ └── reporter.py
└── README.md
7.3.2 相关开源工具
文档解析:
- MinerU:https://github.com/opendatalab/MinerU
当前最强大的多模态文档解析模型,仅1.2B参数 - Docling:IBM开源的企业级文档解析框架
- Marker:快速灵活的PDF解析工具,支持多语言
多模态模型:
- Qwen2-VL:https://github.com/QwenLM/Qwen2-VL
阿里巴巴开源的视觉语言模型,支持任意分辨率图像 - InternVL:书生浦语的多模态大模型
检索系统:
- ColPali/ColQwen:专为文档检索设计的视觉检索模型
- BGE-M3:智源的多语言嵌入模型
- Milvus/FAISS:向量数据库
Agentic RAG框架:
- DeepSearcher:Zilliz开源的深度研究系统
实现了迭代式的多轮搜索和推理 - LangGraph:LangChain的多智能体编排框架
7.3.3 实现参考
如果要从零开始实现,以下是推荐的技术栈:
# requirements.txt
mineru>=2.5.0 # 文档解析
qwen-vl-utils>=0.0.14 # Qwen VLM工具
transformers>=4.40.0 # HuggingFace模型
sentence-transformers # 文本嵌入
faiss-gpu # 向量检索(GPU版)
# 或 faiss-cpu # 向量检索(CPU版)
pymupdf # PDF处理
pillow # 图像处理
opencv-python # 图像处理
torch>=2.0.0 # PyTorch
openai # OpenAI API
anthropic # Claude API
pydantic # 数据验证
langchain>=0.1.0 # LLM工具链
快速开始示例:
# 1. 安装依赖
# pip install doc-researcher
# 2. 基本使用
from doc_researcher import DocResearcher
# 创建系统实例
researcher = DocResearcher(
parser_model="mineru-2.5",
vision_model="qwen2-vl-7b",
retrieval_model="bge-m3",
llm="gpt-4o",
max_iterations=5
)
# 添加文档
documents = [
"path/to/paper1.pdf",
"path/to/report.pdf",
"path/to/analysis.pdf"
]
researcher.add_documents(documents)
# 执行研究
query = "What are the main technical innovations in these papers?"
result = researcher.research(query)
print(result.answer)
for citation in result.citations:
print(f"Source: {citation.document}, Page: {citation.page}")
7.4 生产部署建议
7.4.1 系统架构设计
关键组件:
- 文档存储:
- 使用对象存储(S3, MinIO)存储原始和解析后的文档
- 分层存储:热数据(最近访问)在SSD,冷数据在HDD
- 向量数据库:
- Milvus集群用于大规模检索
- 支持分片和副本,保证高可用
- 定期进行索引优化
- 缓存层:
- Redis缓存频繁访问的结果
- 缓存策略:LRU + TTL
- 缓存命中率目标:>70%
- Worker节点:
- 使用消息队列(RabbitMQ/Kafka)进行任务分发
- 每个worker独立处理请求
- 支持水平扩展
7.4.2 性能优化
批处理策略:
class BatchProcessor:
def __init__(self, batch_size=32, max_wait_time=1.0):
self.batch_size = batch_size
self.max_wait_time = max_wait_time
self.pending_requests = []
async def process_request(self, request):
self.pending_requests.append(request)
# 满足批次大小或超时,触发批处理
if (len(self.pending_requests) >= self.batch_size or
time_since_first_request() > self.max_wait_time):
return await self._batch_process()
async def _batch_process(self):
# 批量调用VLM
images = [r.image for r in self.pending_requests]
descriptions = await vision_model.batch_generate(images)
# 批量嵌入
texts = [r.text for r in self.pending_requests]
embeddings = await embedding_model.batch_encode(texts)
return zip(descriptions, embeddings)
并行化:
import asyncio
from concurrent.futures import ThreadPoolExecutor
class ParallelResearcher(DocResearcher):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.executor = ThreadPoolExecutor(max_workers=10)
async def parallel_search(self, subqueries):
"""并行执行多个子查询"""
tasks = [
self._async_search(sq) for sq in subqueries
]
results = await asyncio.gather(*tasks)
return results
async def _async_search(self, subquery):
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
self.executor,
self.retriever.search,
subquery
)
7.4.3 监控与运维
关键指标:
from prometheus_client import Counter, Histogram, Gauge
# 请求统计
request_counter = Counter('research_requests_total', 'Total research requests')
request_duration = Histogram('research_duration_seconds', 'Request duration')
# 系统状态
active_workers = Gauge('active_workers', 'Number of active workers')
cache_hit_rate = Gauge('cache_hit_rate', 'Cache hit rate')
# 质量指标
answer_confidence = Histogram('answer_confidence', 'Confidence scores')
citation_count = Histogram('citation_count', 'Number of citations per answer')
日志记录:
import logging
import json
class StructuredLogger:
def log_research_request(self, query, metadata):
log_entry = {
'timestamp': datetime.now().isoformat(),
'query': query,
'user_id': metadata.get('user_id'),
'session_id': metadata.get('session_id'),
'query_type': self._classify_query(query)
}
logging.info(json.dumps(log_entry))
def log_iteration(self, iteration, subqueries, results):
log_entry = {
'iteration': iteration,
'subqueries': subqueries,
'results_count': len(results),
'avg_confidence': np.mean([r['confidence'] for r in results])
}
logging.info(json.dumps(log_entry))
八、总结与展望
8.1 论文核心价值
Doc-Researcher论文的最大贡献在于将深度研究范式引入多模态文档理解领域,开创了一个新的研究方向。它不仅提供了一个完整的技术方案,还建立了第一个综合性的评测基准M4DocBench,为后续研究提供了标准化的评估框架。
关键启示:
- **深度解析**的必要性:实验充分证明,投入前期成本进行深度解析,能够在后续研究阶段获得数倍的效率提升和质量改善。
- 迭代推理的威力:单轮检索难以应对复杂查询,迭代式的搜索-精炼循环能够显著提升性能(3.4倍)。
- 多粒度表示的重要性:不同查询需要不同层次的信息,动态粒度选择是提高效率和效果的关键。
- 模块化设计的价值:系统的各个组件都可以独立使用或替换,便于研究者基于自己的需求进行定制和优化。
8.2 对RAG领域的影响
Doc-Researcher代表了从传统RAG到Agentic RAG的范式转变,标志着检索增强生成系统从被动响应到主动探索的演进。
这篇论文将对RAG领域产生以下深远影响:
- 推动多模态RAG研究:更多研究者将关注如何有效处理包含图表、表格、公式的专业文档。
- 促进深度研究系统发展:迭代推理和多智能体协作将成为复杂RAG系统的标准配置。
- 建立新的评测标准:M4DocBench为多模态、多跳、多文档研究提供了标准化评测方法。
- 激发工业应用:系统的模块化设计和实用性为工业界提供了可落地的解决方案。
8.4 结语
Doc-Researcher论文为多模态文档理解和深度研究领域树立了新的标杆。它不仅在技术上取得了突破性进展(50.6%的准确率,3.4倍于基线),更重要的是提出了一个完整的、可扩展的系统框架,为后续研究和工业应用指明了方向。
通过整合深度多模态解析、系统化检索架构和迭代多智能体工作流,Doc-Researcher建立了一个新的范式来处理多模态文档集合的深度研究。
对于研究人员而言,这篇论文提供了丰富的研究思路和改进空间;对于工程师而言,论文提供了清晰的实现路径和最佳实践;对于企业而言,系统展示了如何将AI技术应用于实际的知识管理和决策支持场景。
随着大型语言模型和视觉语言模型的持续进步,以及更多高质量数据集的出现,我们有理由相信,多模态文档深度研究系统将在未来几年内得到快速发展和广泛应用,真正实现"让AI成为人类的研究助手"的愿景。
参考文献
核心论文
- Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
论文介绍了完整的系统架构、实验结果和M4DocBench基准测试
https://arxiv.org/abs/2510.21603 - Doc-Researcher GitHub Repository
官方代码实现和使用示例
https://github.com/sunxingrong33/Doc-Researcher
文档解析相关
- MinerU: Transforms Complex Documents into LLM-ready Formats
当前最先进的开源文档解析工具,MinerU2.5仅1.2B参数就实现SOTA性能
https://github.com/opendatalab/MinerU - MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
MinerU2.5的技术论文,详细介绍了两阶段解析策略
https://arxiv.org/abs/2509.22186 - Document Parsing Unveiled: Techniques, Challenges, and Prospects
全面综述了文档解析领域的技术、挑战和发展前景
https://arxiv.org/abs/2410.21169 - OmniDocBench: Benchmarking Diverse PDF Document Parsing
全面的PDF文档解析基准测试,包含详细的布局、文本、公式和表格标注
https://arxiv.org/abs/2412.07626 - Next Generation Document Parsing and Multimodal Information Retrieval
C3.ai关于多模态文档解析和信息检索的博客文章
https://c3.ai/blog/next-generation-document-parsing-and-multimodal-information-retrieval-blog/
多模态模型相关
- Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World
阿里巴巴的视觉语言模型,支持动态分辨率和多模态旋转位置编码
https://arxiv.org/abs/2409.12191 - Qwen2.5-VL: The New Flagship Vision-Language Model
Qwen2.5-VL的发布博客,介绍了最新的功能和性能提升
https://qwenlm.github.io/blog/qwen2.5-vl/ - Qwen-VL: A Versatile Vision-Language Model
Qwen-VL的原始论文,介绍了模型架构和训练策略
https://arxiv.org/abs/2308.12966 - DocPedia: OCR-free Document Understanding at High Resolution
在频域处理文档图像的大型多模态模型,能够解析高达2560×2560的图像
https://link.springer.com/article/10.1007/s11432-024-4250-y
基准测试相关
- MMLongBench-Doc: Benchmarking Long-context Document Understanding
长上下文多模态文档理解基准,包含1,091个问题和135个文档
https://arxiv.org/abs/2407.01523 - UniDoc-Bench: A Unified Benchmark for Document-Centric Multimodal RAG
Salesforce的多模态RAG基准,包含70k页PDF和1,600个QA对
https://arxiv.org/abs/2510.03663 - Benchmarking Multi-Modal Retrieval for Long Documents
专注于长文档多模态检索的基准测试研究
https://arxiv.org/abs/2501.08828
Agentic RAG与深度研究
- Towards Agentic RAG with Deep Reasoning
关于RAG与推理系统集成的全面综述,涵盖200+篇论文
https://arxiv.org/abs/2507.09477 - Deep Research: A Survey of Autonomous Research Agents
深度研究系统的全面调查,介绍了从规划到报告生成的完整流程
https://arxiv.org/abs/2508.12752 - From Web Search towards Agentic Deep Research
从传统搜索到智能深度研究的演进,讨论了测试时缩放的重要性
https://arxiv.org/abs/2506.18959 - Reasoning RAG via System 1 or System 2
针对工业挑战的推理式Agentic RAG综述
https://arxiv.org/abs/2506.10408 - Gemini Deep Research
Google的深度研究产品介绍,展示了异步任务管理和迭代推理
https://gemini.google/overview/deep-research/ - Stop Building Vanilla RAG: Embrace Agentic RAG
Milvus关于Agentic RAG和DeepSearcher的博客文章
https://milvus.io/blog/stop-use-outdated-rag-deepsearcher-agentic-rag-approaches-changes-everything.md - Reasoning for RAG: A 2025 Perspective
InfiniFlow关于RAG推理的最新观点,讨论了R1/o1对RAG的影响
https://medium.com/@infiniflowai/reasoning-for-rag-a-2025-perspective-1f4e63b5537f
开源工具与框架
- RAG-Anything: All-in-One RAG Framework
香港大学的端到端多模态RAG框架
https://github.com/HKUDS/RAG-Anything - Agentic RAG Survey
Agentic RAG系统的全面调查和代码仓库
https://github.com/asinghcsu/AgenticRAG-Survey - Docling: Document Parsing Framework
IBM开源的企业级文档解析框架
论文和工具介绍见相关博客 - Finding the Right Document Processing Tool
比较各种文档处理工具(Docling, Marker, MinerU等)的文章
https://www.tyolab.com/blog/2025/02/25-finding-the-right-document-processing-tool-for-your-workflow/
相关技术与方法
- Integrating Multimodal Data into Large Language Models
使用LlamaParse和上下文检索的多模态RAG实现教程
https://towardsdatascience.com/integrating-multimodal-data-into-a-large-language-model-d1965b8ab00c/ - XFormParser: A Simple and Effective Multimodal Form Parser
多模态多语言半结构化表单解析器
https://arxiv.org/abs/2405.17336 - Infinity-Parser: Layout-Aware Document Parsing with RL
使用强化学习进行布局感知文档解析
https://arxiv.org/abs/2506.03197

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)