Hello-agent task2 --笔记
以下内容均来自Hello-agent(Data Whale)第三章 大语言模型基础语言模型(language model)是自然语言处理的核心,根本任务是计算一个词序列出现的概率。在深度学习兴起之前,统计方法是语言模型的主流。其核心思想是,一个句子出现的概率,等于该句子中每个词出现的条件概率的连乘。词用wi表示难以直接计算,故引入马尔可夫假设。核心思想:不必回溯一个词的全部历史,而是认为一个词出现
以下内容均来自Hello-agent(Data Whale)
第三章 大语言模型基础
语言模型(language model)是自然语言处理的核心,根本任务是计算一个词序列出现的概率。
在深度学习兴起之前,统计方法是语言模型的主流。其核心思想是,一个句子出现的概率,等于该句子中每个词出现的条件概率的连乘。词用wi表示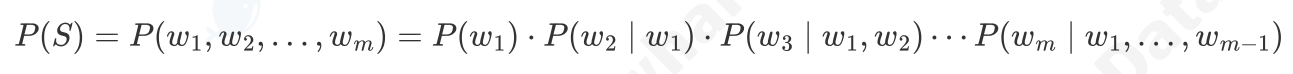
难以直接计算,故引入马尔可夫假设。核心思想:不必回溯一个词的全部历史,而是认为一个词出现概率只与它前面有限的n-1个词有关。基于这个假设建立的语言模型,我们称之为 N-gram模型。N为上下文窗口大小。
N-gram 模型虽然简单有效,但有两个致命缺陷:
1. 数据稀疏性 (Sparsity) :如果一个词序列从未在语料库中出现,其概率估计就为 0,这显然是不合理的。虽然可以通过平滑 (Smoothing) 技术缓解,但无法根除。
2. 泛化能力差:模型无法理解词与词之间的语义相似性。例如,即使模型在语料库中见过很多次 agent learns ,它也无法将这个知识泛化到语义相似的词上。当我们计算 robot learns 的概率时,如果 robot 这个词从未出现过,或者 robot learns 这个组合从未出现过,模型计算出的概率也会是零。模型无法理解agent 和 robot 在语义上的相似性。
根本缺陷是它将词视为孤立、离散的符号。所以人们转向神经网络:用连续的向量来表示词
“前馈神经网络语言模型“:
1)构建一个语义空间:创建一个高维的连续向量空间,然后将词汇表中的每个词都映射为该空间中的一个点。这个点(即向量)就被称为词嵌入 (Word Embedding) 或词向量。在这个空间里,语义上相近的词,它们对应的向量在空间中的位置也相近。例如, agent 和 robot 的向量会靠得很近,而 agent 和 apple 的向量会离得很远。
2)学习从上下文到下一个词的映射
一旦我们将词转换成了向量,我们就可以用数学工具来度量它们之间的关系。最常用的方法是余弦相似度 (Cosine Similarity) ,它通过计算两个向量夹角的余弦值来衡量它们的相似性。
![]()
这个公式的含义是:
如果两个向量方向完全相同,夹角为0°,余弦值为1,表示完全相关。
如果两个向量方向正交,夹角为90°,余弦值为0,表示毫无关系。
如果两个向量方向完全相反,夹角为180°,余弦值为-1,表示完全负相关
一个著名的例子展示了词向量捕捉到的语义关系: vector('King') - vector('Man') + vector('Woman') 这个向量运算的结果,在向量空间中与 vector('Queen') 的位置惊人地接近。证明了词嵌入能够学习到“性别”、“皇室”这类抽象概念。
“循环神经网络 (RNN) 与长短时记忆网络 (LSTM)“
1)RNN:在处理序列的每一步,网络都会读取当前的输入词,并结合它上一刻的记忆,存在长期依赖问题,当序列很长时,梯度再从后向前传播的过程中会经过多次连乘,导致梯度消失/梯度爆炸。梯度消失使得模型无法有效学习到序列早期信息对后期输出的影响,即难以捕捉长距离的依赖关系。
2)LSTM:核心创新在于引入了细胞状态 (Cell State) 和一套精密的门控机制 (Gating Mechanism)
门控机制则是由几个小型神经网络构成,它们可以学习如何有选择地让信息通过,从而控制细胞状态中信息的增加与移除。
遗忘门 (Forget Gate):决定从上一时刻的细胞状态中丢弃哪些信息
输入门 (Input Gate):决定将当前输入中的哪些新信息存入细胞状态
输出门 (Output Gate):决定根据当前的细胞状态,输出哪些信息到隐藏状态
Transformer架构
RNN、LSTM通过引入循环结构来处理序列数据,它必须按顺序处理数据。第 t 个时间步的计算,必须等待第 t−1个时间步完成后才能开始。这意味着 RNN 无法进行大规模的并行计算,在处理长序列时效率低下,这极大地限制了模型规模和训练速度的提升。
1)Encoder-Decoder
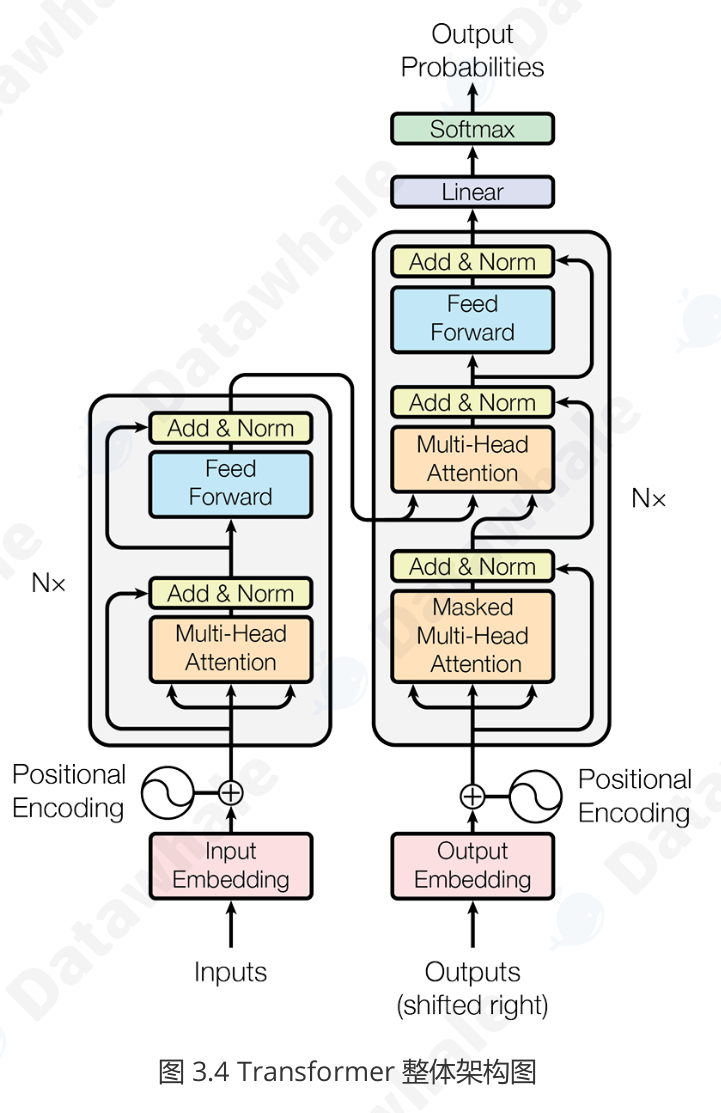
编码器 (Encoder) :任务是“理解”输入的整个句子。它会读取所有输入词元(这个概念会在3.2.2节介绍),最终为每个词元生成一个富含上下文信息的向量表示。
解码器 (Decoder) :任务是“生成”目标句子。它会参考自己已经生成的前文,并“咨询”编码器的理解结果,来生成下一个词。
class EncoderLayer(nn.Module):
def __init__(self,d_model,num_heads,d_ff,dropout):
super(EncoderLayer,self).__init__()
self.self_attn = MultiHeadAttention()
self.feed_forward = PositionWiseFeedForward()
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self,x,mask):
#残差连接与层归一化将在后续解释
#1.多头自注意力
attn_output = self.self_attn(x,x,x,mask)
x = self.norm1(x + self.dropout(attn_output))
#2.前馈网络
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
#---解码器核心层
class DecoderLayer(nn.Module):
def __init_(self,d_model,num_heads,d_ff,dropout):
super(DecoderLayer,self).__init__()
self.self_attn = MultiHeadAttention()
self.cross_attn = MultiHeadAttention()
self.feed_forward = PositionWiseFeedForward()
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self,x,encoder_output,src_mask,tgt_mask):
#1.掩码多头自注意力(对自己)
attn_output = self.self_attn(x,x,x,tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
#2.交叉注意力(对编码器输出)
cross_attn_output = self.cross_attn(x,encoder_output,encoder_output,src_mask)
x = self.norm2(x + self.dropout(cross_attn_output))
#3.前馈网络
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x自注意力机制为每个输入的词元向量引入了三个可学习的角色:
查询 (Query, Q):代表当前词元,它正在主动地“查询”其他词元以获取信息。
键 (Key, K):代表句子中可被查询的词元“标签”或“索引”。
值 (Value, V):代表词元本身所携带的“内容”或“信息”。
三个向量都是由原始的词嵌入向量乘以三个不同的、可学习的权重矩阵![]() 得到的
得到的
- 准备“考题”和“资料”:对于句子中的每个词,都通过权重矩阵生成其向量。
- 计算相关性得分:要计算词 的新表示,就用词 的 向量,去和句子中所有词(包括 自己)的点积运算。这个得分反映了其他词对于理解词的重要性。
- 向量进行稳定化与归一化:将得到的所有分数除以一个缩放因子
 ,以防止梯度过小,然后用Softmax函数将分数转换成总和为1的权重,也就是归一化的过程。
,以防止梯度过小,然后用Softmax函数将分数转换成总和为1的权重,也就是归一化的过程。 - 加权求和:将上一步得到的权重分别乘以每个词对应的V向量,然后将所有结果相加。最终得到的向量,就是词A融合了全局上下文信息后的新表示。
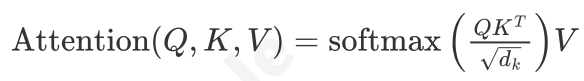
它将原始的 Q, K, V 向量在维度上切分成 h 份(h 就是“头”数),每一份都独立地进行一次单头注意力的计算。这就好比让 h 个不同的“专家”从不同的角度去审视句子,每个专家都能捕捉到一种不同的特征关系。最后,将这 h 个专家的“意见”(即输出向量)拼接起来,再通过一个线性变换进行整合,就得到了最终的输出。
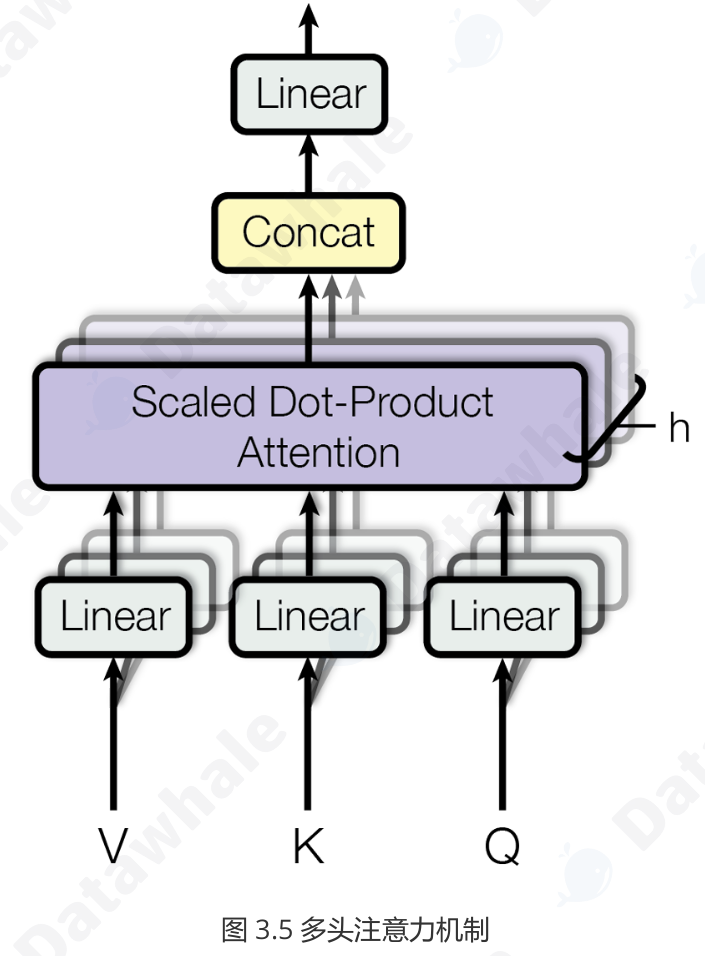
这种设计让模型能够共同关注来自不同位置、不同表示子空间的信息,极大地增强了模型的表达能力。
逐位置前馈网络(Position-wise Feed-ForwardNetwork, FFN)
注意力层的作用是从整个序列中“动态地聚合”相关信息,那么前馈网络的作用从这些聚合后的信息中提取更高阶的特征.
“逐位置”。它意味着这个前馈网络会独立地作用于序列中的每一个词元向量
对于一个长度为 seq_len 的序列,这个 FFN 实际上会被调用 seq_len 次,每次处理一个词元
![]()
x是注意力子层的输出,其余是参数。
残差连接与层归一化
残差连接 (Add):该操作将子模块的输入 x 直接加到该子模块的输出 Sublayer(x) 上。这一结构解决了深度神经网络中的梯度消失 (Vanishing Gradients) 问题。在反向传播时,梯度可以绕过子模块直接向前传播,从而保证了即使网络层数很深,模型也能得到有效的训练。其公式可以表示为:
层归一化 (Norm):该操作对单个样本的所有特征进行归一化,使其均值为0,方差为1。这解决了模型训练过程中的内部协变量偏移 (Internal Covariate Shift) 问题,使每一层的输入分布保持稳定,从而加速模型收敛并提高训练的稳定性
自注意力机制它本身不包含任何关于词元顺序或位置的信息。对于自注意力来说,“agent learns” 和 “learns agent” 这两个序列是完全等价的,因为它只关心词元之间的关系,而忽略了它们的排列。为了解决这个问题,Transformer 引入了位置编码 (Positional Encoding) 。
位置编码的核心思想是,为输入序列中的每一个词元嵌入向量,都额外加上一个能代表其绝对位置和相对位置信息的“位置向量”。这个位置向量不是通过学习得到的,而是通过一个固定的数学公式直接计算得出。这样一来,即使两个词元(例如,两个都叫 agent 的词元)自身的嵌入是相同的,但由于它们在句子中的位置不同,它们最终输入到Transformer 模型中的向量就会因为加上了不同的位置编码而变得独一无二。

Decoder-Only 架构
无论是回答问题、写故事还是生成代码,本质上都是在一个已有的文本序列后面,一个词一个词地添加最合理的内容。基于这个思想,GPT 做了一个大胆的简化:它完全抛弃了编码器,只保留了解码器部分。 这就是 Decoder-Only架构的由来。
Decoder-Only 架构的工作模式被称为自回归 (Autoregressive) 。这个听起来很专业的术语,其实描述了一个非常简单的过程:
1. 给模型一个起始文本(例如 “Datawhale Agent is”)。
2. 模型预测出下一个最有可能的词(例如 “a”)。
3. 模型将自己刚刚生成的词 “a” 添加到输入文本的末尾,形成新的输入(“Datawhale Agent is a”)。
4. 模型基于这个新输入,再次预测下一个词(例如 “powerful”)。
5. 不断重复这个过程,直到生成完整的句子或达到停止条件。
掩码自注意力 (Masked Self-Attention)->保证在预测第 t 个词时,不去“偷看”第 t+1 个词的答案
在进行 Softmax 归一化之前,模型会应用一个“掩码”。这个掩码会将所有位于当前位置之后(即目前尚未观测到)的词元对应的分数,替换为一个非常大的负数。当这个带有负无穷分数的矩阵经过 Softmax 函数时,这些位置的概率就会变为 0。这样一来,模型在计算任何一个位置的输出时,都从数学上被阻止了去关注它后面的信息。这种机制保证了模型在预测下一个词时,能且仅能依赖它已经见过的、位于当前位置之前的所有信息,从而确保了预测的公平性和逻辑的连贯性
Decoder-Only 架构的优势
这种看似简单的架构,却带来了巨大的成功,其优势在于:
- 训练目标统一:模型的唯一任务就是“预测下一个词”,这个简单的目标非常适合在海量的无标注文本数据上进行预训练。
- 结构简单,易于扩展:更少的组件意味着更容易进行规模化扩展。今天的 GPT-4、Llama 等拥有数千亿甚至万亿参数的巨型模型,都是基于这种简洁的架构。
- 天然适合生成任务:其自回归的工作模式与所有生成式任务(对话、写作、代码生成等)完美契合,这也是它能成为构建通用智能体基础的核心原因。
提示工程
提示工程,就是研究如何设计出精准的提示,从而引导模型产生我们期望输出的回复。对于构建智能体而言,一个精心设计的提示能让智能体之间协作分工变得高效。
(1)模型采样参数
在使用大模型时,你会看到类似 Temperature 这类的可配置参数,其本质是通过调整模型对 “概率分布” 的采样策略,让输出匹配具体场景需求,配置合适的参数可以提升Agent在特定场景的性能。
与温度采样的区别与联系:温度采样通过温度 T 调整所有 token 的概率分布(平滑或陡峭),不改变候选token 的数量(仍考虑全部 N 个)。Top-k 采样通过 k 值限制候选 token 的数量(只保留前 k 个高概率token),再从其中采样。当k=1时输出完全确定,退化为 “贪心采样”。
Top-p :其原理是将所有 token 按概率从高到低排序,从排序后的第一个 token 开始,逐步累加概率,直到累积和首次达到或超过阈值 p:![]() 此时累加过程中包含的所有 token 组成 “核集合”,最后对核集合进行归一化。
此时累加过程中包含的所有 token 组成 “核集合”,最后对核集合进行归一化。
与Top-k的区别与联系:相对于固定截断大小的 Top-k,Top-p 能动态适应不同分布的“长尾”特性,对概率分布不均匀的极端情况的适应性更好
需要注意的是,如果将温度设置为 0,则 Top-k 和 Top-p 将变得无关紧要,因为最有可能的 Token 将成为下一个预测的 Token;如果将 Top-k 设置为 1,温度和 Top-p 也将变得无关紧要,因为只有一个 Token 通过 Top-k 标准,它将是下一个预测的 Token。
(2)零样本、单样本与少样本提示
零样本提示 (Zero-shot Prompting) 这指的是我们不给模型任何示例,直接让它根据指令完成任务。这得益于模型在海量数据上预训练后获得的强大泛化能力
单样本提示 (One-shot Prompting) 我们给模型提供一个完整的示例,向它展示任务的格式和期望的输出风格。
少样本提示 (Few-shot Prompting) 我们提供多个示例,这能让模型更准确地理解任务的细节、边界和细微差别,从而获得更好的性能。
(3)指令调优的影响
指令调优 (Instruction Tuning) 是一种微调技术,它使用大量“指令-回答”格式的数据对预训练模型进行进一步的训练。经过指令调优后,模型能更好地理解并遵循用户的指令。我们今天日常工作学习中使用的所有模型(如ChatGPT , DeepSeek , Qwen )都是其模型家族中经过指令调优过的模型
(4)基础提示技巧
角色扮演 (Role-playing) 通过赋予模型一个特定的角色,我们可以引导它的回答风格、语气和知识范围,使其输出更符合特定场景的需求
上下文示例 (In-context Example) 这与少样本提示的思想一致,通过在提示中提供清晰的输入输出示例,来“教会”模型如何处理我们的请求,尤其是在处理复杂格式或特定风格的任务时非常有效。
(5)思维链
对于需要逻辑推理、计算或多步骤思考的复杂问题,直接让模型给出答案往往容易出错。思维链 (Chain-of-Thought,
CoT) 是一种强大的提示技巧,它通过引导模型“一步一步地思考”,提升了模型在复杂任务上的推理能力。实现 CoT 的关键,是在提示中加入一句简单的引导语,如“请逐步思考”或“Let's think step by step”。
文本分词
这个将文本序列转换为数字序列的过程,就叫做分词 (Tokenization) 。分词器 (Tokenizer) 的作
用,就是定义一套规则,将原始文本切分成一个个最小的单元,我们称之为词元 (Token)
现代大语言模型普遍采用子词分词 (Subword Tokenization) 算法。它的核心思想是:将常见的词(如 "agent")保留为完整的词元,同时将不常见的词(如 "Tokenization")拆分成多个有意义的子词片段(如 "Token" 和 "ization")。这样既控制了词表的大小,又能让模型通过组合子词来理解和生成新词。
字节对编码 (Byte-Pair Encoding, BPE) 是最主流的子词分词算法之一
GPT系列模型就采用了这种算法,
1. 初始化:将词表初始化为所有在语料库中出现过的基本字符。
2. 迭代合并:在语料库上,统计所有相邻词元对的出现频率,找到频率最高的一对,将它们合并成一个新的词元,并加入词表。
3. 重复:重复第 2 步,直到词表大小达到预设的阈值。
Google 开发的 WordPiece 和 SentencePiece 是影响力最大的两种。
WordPiece:Google BERT 模型采用的算法[7]。它与 BPE 非常相似,但合并词元的标准不是“最高频率”,而是“能最大化提升语料库的语言模型概率”。简单来说,它会优先合并那些能让整个语料库的“通顺度”提升最大的词元对。
SentencePiece:Google 开源的一款分词工具[8],Llama 系列模型采用了此算法。它最大的特点是,将空格也视作一个普通字符(通常用下划线 _ 表示)。这使得分词和解码过程完全可逆,且不依赖于特定的语言(例如,它不需要知道中文不使用空格分词)
Hugging Face Transformers 是一个强大的开源库,它提供了标准化的接口来加载和使用数以万计的预训练模型
大语言模型的缩放法则与局限性
1、在对数-对数坐标系下,模型的性能(通常用损失 Loss 来衡量)与参数量、数据量和计算量这三个因素都呈现出平滑的幂律关系[9]。简单来说,只要我们持续、按比例地增加这三个要素,模型的性能就会可预测地、平滑地提升,而不会出现明显的瓶颈。这一发现为大模型的设计和训练提供了清晰的指导:在资源允许的范围内,尽可能地扩大模型规模和训练数据量。
缩放法则最令人惊奇的产物是“能力的涌现”。所谓能力涌现,是指当模型规模达到一定阈值后,会突然展现出在小规模模型中完全不存在或表现不佳的全新能力。例如,链式思考 (Chain-of-Thought) 、指令遵循 (Instruction Following) 、多步推理、代码生成等能力,都是在模型参数量达到数百亿甚至千亿级别后才显著出现的。这种现象表明,大语言模型不仅仅是简单地记忆和复述,它们在学习过程中可能形成了某种更深层次的抽象和推理能力。对于智能体开发者而言,能力的涌现意味着选择一个足够大规模的模型,是实现复杂自主决策和规划能力的前提。
模型幻觉(Hallucination)通常指的是大语言模型生成的内容与客观事实、用户输入或上下文信息相矛盾,或者生成了不存在的事实、实体或事件。幻觉的本质是模型在生成过程中,过度自信地“编造”了信息,而非准确地检索或推理。根据其表现形式,幻觉可以被分为多种类型


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)