大模型如何真正“记住”你:揭秘个性化AI Agent的技术底层
实现。
RAG能搜资料,却很难认识你。这套框架用持久化记忆 + 动态用户画像 + 多智能体协作,把一次次聊天变成可累积的个性化能力。
1 个性化原理
对象/目标/主体/方式四维定义,映射为三条硬性技术需求:自适应、连续性、定制化。
1.对象是被个性化的输出(内容/功能/风格),目标是满足个人需求与体验提升。
2.主体既有显式(用户告诉系统)也有隐式(系统自动学习),因此必须有可演化的记忆与可更新的用户画像。
3.从原理看,本质是把当前任务 + 历史交互 + 用户偏好转为决策的上下文,驱动不同检索与推理策略。
4.工程落地需要把概念→约束→组件严格映射,避免停留在体验层描述。
2 多智能体实现
目标:满足“自适应”要求,随用户语境与任务复杂度动态调整。
关键模式:中央协调、规划、多源检索、多代理协作、反思、持久记忆。
工作流:协调器分流请求;操作员以 RAG+MCP 访问 LTM/STM/会话摘要/用户画像/网页并择优组合;自验证器检查充分性与一致性并迭代改进;响应生成器结合用户画像输出个性化结果。
价值:以角色化提示与历史对齐,实现上下文敏感、可重复、稳健且以用户为中心的系统行为。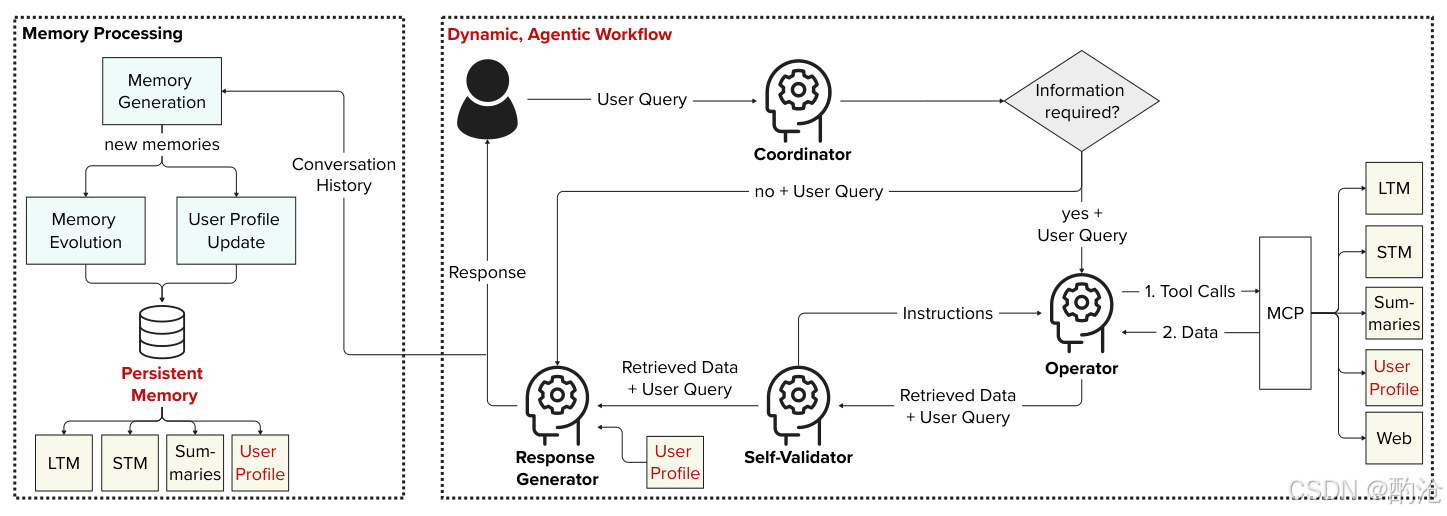
框架以LLM为中枢,落地六大Agentic模式:中央协调、规划、跨源检索、多智能体协作、反思校验、持久记忆。
1.Coordinator按任务复杂度决策:简单问答直达生成,复杂问题转Operator做检索与工具调用。
2.Operator通过MCP统一接口调用STM/LTM/对话摘要/用户画像/网页搜索,实现多源可插拔检索。
3.Self-Validator执行反思式校验,不足则回指令让Operator追加检索,形成检索—验证—再检索闭环。
4.Response Generator用用户画像控制语气、粒度与示例,输出对人对事双对齐的答案。
3 持久记忆四件套
记忆不是一个向量库,而是时间尺度 + 表征形态的协同:
1.STM保存最近轮次全文,确保即时上下文;对话积累后由摘要器生成主题摘要,覆盖更长跨度。
2.LTM存压缩记忆(摘要向量+标签+时间戳+前5相关记忆),写入时回流更新关联,仿照人类巩固。
3.用户画像是结构化JSON,记录偏好、语气、兴趣、目标,由LLM隐式更新,用于检索过滤与风格控制。
4.检索时采用相似度+标签扩展双通道,既准又广,减少只像不对的相似度陷阱。
4 反思校验
仅有检索仍会漏信息或拼贴,Self-Validator通过可用性/一致性/特异性三问来兜底:
1.若证据不足或矛盾,返回精确拉取指令(要什么、从哪拉、补充到何处),驱动二轮检索。
2.在碎片化记忆场景,反思能显著提升上下文充分性,减少看似相关但答非所问。
3.验证也要节制:当结果已充分时放行,避免过度反思带来的时延。
图示反思回路:不足则返工,充分则生成
5 评测要点与实践
在GVD、LoCoMo、LongMemEval三套数据上,对比标准RAG与消融(去掉协调/验证/画像)。
1.总体上,检索准确率与回答正确率优于或持平RAG,尤其长对话任务提升显著。
2.去掉用户画像,检索与正确率均下滑,说明画像不仅调风格,更直接影响取数与判断。
3.协调器/自我验证收益受模型与数据分布影响,在人类噪声场景预期价值更高。
4.自动指标(ROUGE、BertScore)与人类目标弱相关,个性化评测应以检索命中、正确性、连贯性为主。
| 核心概念 | 关键特征 | 举例说明 |
|---|---|---|
| 数据集 | 长期与事实混合 | GVD/LoCoMo/LongMemEval |
| 核心指标 | 命中/正确/连贯 | 人判主导 |
| 对比基线 | 标准RAG | 全量历史+搜索 |
| 关键发现 | 画像最关键 | 去画像显著回退 |
| 实践建议 | 人本指标优先 | 结合少量人工复核 |
| 落地重点 | 冷启动与主动性 | 轻量问卷+主动追问 |
从第一性原理看,个性化=把当前任务+历史交互+个人画像注入决策上下文;
工程上以多智能体工作流实现自适应,用STM/摘要/LTM/画像保证跨会话连续,用自我验证把不确定性转为可靠答案;
评测则以检索命中、答案正确、对话连贯三指标为主,结合少量人工标注,更贴近真实体验。
下一步实践,重点解决冷启动(轻量化画像初始化)与主动性(系统适时追问与建议),让会搜的模型真正进化成懂你的助理。
TM/摘要/LTM/画像保证跨会话连续,用自我验证**把不确定性转为可靠答案;
评测则以检索命中、答案正确、对话连贯三指标为主,结合少量人工标注,更贴近真实体验。
下一步实践,重点解决冷启动(轻量化画像初始化)与主动性(系统适时追问与建议),让会搜的模型真正进化成懂你的助理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)