四、解构 K8s 节点:核心组件在 Linux 上是如何协同工作的?
前言
前面我们已经吃透了 Linux 的 Namespace(隔离)和 cgroups(资源管控)—— 这是容器技术的两大底层基石。但 K8s 作为容器编排平台,不可能让我们直接去操作内核 API 管理容器。
K8s 节点就像一个高效运转的 “办公室”,里面的每个组件都是各司其职的 “员工”,它们分工协作,把复杂的容器管理工作拆解成简单的步骤,最终通过调用 Linux 内核能力完成落地。
今天这篇文章就带大家解构 K8s 节点的内部协作逻辑:认识每个核心组件的 “岗位职责”,看清它们如何与 Linux 内核交互,通过时序图还原 Pod 启动的完整流水线,最后给出排查问题的清晰思路,让你对 K8s 的工作原理不再模糊。
一、先入戏:K8s 节点的 “办公室” 角色扮演
要理解组件协作,先给每个核心组件一个通俗的 “岗位定位”,结合办公室场景快速 get 核心功能:
| K8s 组件 | 办公室角色 | 核心职责 | 与 Linux 的核心交互点 |
|---|---|---|---|
| containerd(容器运行时) | 施工队 | 负责镜像下载、容器创建 / 启动 / 停止,是直接操作内核的 “执行者” | 调用 Namespace API 实现隔离,调用 cgroups API 做资源限制 |
| kubelet | 项目经理 | 节点的 “大管家”,接收 Master 指令,协调施工队干活,汇报节点状态 | 通过 CRI 接口下发指令,监控节点内核资源(CPU / 内存 / 磁盘) |
| kube-proxy | 路由器 / 网络保安 | 负责配置节点网络规则,实现 Service 的负载均衡,让 Pod 能被外部访问 | 操作 iptables/ipvs 内核模块,配置网络转发规则 |
| kube-apiserver | 总部联络员 | 接收 kubectl 命令,传递指令给节点,汇总节点状态(注:属于 Master 组件,跨节点协作核心) | 与节点组件通过 HTTP/HTTPS 通信,不直接操作内核 |
| 调度器(scheduler) | 人事分配专员 | 决定哪个 Pod 放在哪个节点上(注:属于 Master 组件) | 基于节点内核资源状态(如剩余 CPU / 内存)做调度决策 |
简单总结:Master 组件(API Server、调度器)负责 “发号施令和分配任务”,节点组件(kubelet、containerd、kube-proxy)负责 “执行任务”,而执行的底层依赖就是 Linux 内核的 Namespace、cgroups、iptables 等能力。
二、深度拆解:每个组件如何与 Linux “对话”?
2.1 containerd:直接调用内核的 “施工队”
containerd 是节点上最贴近 Linux 内核的组件,它不搞复杂逻辑,只专注于 “镜像管理” 和 “容器生命周期”,是 K8s 与 Linux 内核之间的 “翻译官”。
核心工作流程与 Linux 交互:
- 镜像处理:接收 kubelet 指令后,先从镜像仓库下载镜像,解压后存储在节点的文件系统(如
/var/lib/containerd); - 创建容器:
- 调用 Linux Namespace API:创建 PID、Network、Mount 等命名空间,为容器划分独立运行环境;
- 调用 Linux cgroups API:根据 Pod 的
resources.limits配置,创建对应的 cgroups 分组,限制 CPU、内存使用; - 挂载容器根文件系统:将解压后的镜像层挂载为容器的根目录(rootfs),实现文件系统隔离;
- 容器生命周期管理:通过 Linux 的进程管理(如
fork/exec)启动容器进程,通过kill命令停止容器,记录容器运行状态。
关键说明:
- containerd 不直接接收用户命令,只通过 CRI(容器运行时接口)与 kubelet 通信,相当于 “只听项目经理的话”;
- 早期 K8s 用 Docker 作为容器运行时,现在 Docker 已逐步被 containerd 替代(更轻量、更专注于核心功能)。
2.2 kubelet:节点上的 “项目经理”,全程把控进度
kubelet 是节点上的核心组件,从 Pod 启动到运行,全程由它协调,是连接 Master 和节点的 “桥梁”。
核心工作流程与 Linux 交互:
- 接收任务:通过 kube-apiserver 获取分配给当前节点的 Pod 清单(Pod Spec);
- 准备环境:
- 检查节点资源:通过 Linux 命令(如
free、top)或内核接口,确认节点剩余 CPU、内存是否满足 Pod 需求; - 配置存储:如果 Pod 需要持久化存储(如 PVC),协调 Linux 的存储驱动(如 ext4、xfs)挂载存储卷;
- 检查节点资源:通过 Linux 命令(如
- 下发指令:通过 CRI 接口向 containerd 发送 “创建容器” 指令,明确 Namespace 隔离要求和 cgroups 资源限制;
- 监控状态:
- 持续检查容器进程状态(通过 Linux 的
ps命令或进程文件系统/proc); - 监控容器资源使用(通过 cgroups 的统计文件,如
/sys/fs/cgroup/memory/.../memory.usage_in_bytes); - 定期向 kube-apiserver 汇报 Pod 状态(Running/Error/ContainerCreating)和节点状态(Ready/NotReady)。
- 持续检查容器进程状态(通过 Linux 的
关键说明:
- kubelet 是 “永不离岗” 的项目经理,只要节点运行,它就持续监控,一旦发现 Pod 状态异常(如容器崩溃),会尝试重启容器;
- 如果节点资源不足,kubelet 会拒绝启动新 Pod,并向 Master 汇报 “节点资源不够”。
2.3 kube-proxy:配置网络规则的 “路由器”
Pod 的 IP 是动态分配的,且 Pod 重启后 IP 会变,Service 就是通过固定访问地址解决这个问题 —— 而 kube-proxy 就是实现 Service 功能的核心组件,它的本质是 “操作 Linux 内核的网络规则”。
核心工作流程与 Linux 交互:
- 同步规则:通过 kube-apiserver 获取集群内的 Service 和 Endpoint 信息(Endpoint 记录了 Service 对应的 Pod IP 列表);
- 配置转发规则:
- 主流模式(iptables):在 Linux 内核的 iptables 中添加 DNAT(目的地址转换)规则,将 Service 的虚拟 IP(ClusterIP)转发到对应的 Pod IP;
- 高性能模式(ipvs):当集群规模较大时,可切换为 ipvs 模式,通过 Linux 的 ipvs 内核模块配置负载均衡规则(比 iptables 性能更高);
- 维护规则:当 Service 或 Pod 发生变化(如 Pod 新增 / 删除),kube-proxy 会实时更新内核中的网络规则,确保转发始终有效。
举例理解:
当你访问 Service 的 ClusterIP(如 10.96.0.10): 端口时,Linux 内核会通过 kube-proxy 配置的 iptables/ipvs 规则,自动将请求转发到其中一个健康的 Pod IP,实现负载均衡。
三、核心流程图:Pod 启动的完整 “流水线”(时序 + Linux 交互点)
下面用 Mermaid 时序图,还原从执行kubectl create -f pod.yaml到 Pod 在节点上成功运行的全流程,每个环节都标清组件交互和 Linux 的参与点:
PCLKMUL (Namespace/cgroups/iptables)PCKM (kube-apiserver+调度器)UPCLKMUL (Namespace/cgroups/iptables)PCKM (kube-apiserver+调度器)U执行kubectl create -f pod.yaml(创建Pod)1. API Server验证Pod配置合法性2. 调度器根据节点资源状态,选择目标节点3. 向目标节点的kubelet下发Pod创建指令4. 检查节点Linux内核资源(CPU/内存/磁盘)5. 通过CRI接口,要求containerd创建容器6. 调用Namespace API,创建独立运行环境7. 调用cgroups API,配置资源限制(按Pod limits)8. 下载镜像并挂载容器根文件系统9. 通过fork/exec启动容器进程10. 向kubelet返回容器创建成功状态11. 监控容器进程状态(/proc)和资源使用(cgroups统计)12. 向API Server汇报Pod状态为Running13. 同步Service和Pod的Endpoint信息14. 在iptables/ipvs中配置网络转发规则15. 内核生效网络规则,Service可访问Pod
PCLKMUL (Namespace/cgroups/iptables)PCKM (kube-apiserver+调度器)UPCLKMUL (Namespace/cgroups/iptables)PCKM (kube-apiserver+调度器)U执行kubectl create -f pod.yaml(创建Pod)1. API Server验证Pod配置合法性2. 调度器根据节点资源状态,选择目标节点3. 向目标节点的kubelet下发Pod创建指令4. 检查节点Linux内核资源(CPU/内存/磁盘)5. 通过CRI接口,要求containerd创建容器6. 调用Namespace API,创建独立运行环境7. 调用cgroups API,配置资源限制(按Pod limits)8. 下载镜像并挂载容器根文件系统9. 通过fork/exec启动容器进程10. 向kubelet返回容器创建成功状态11. 监控容器进程状态(/proc)和资源使用(cgroups统计)12. 向API Server汇报Pod状态为Running13. 同步Service和Pod的Endpoint信息14. 在iptables/ipvs中配置网络转发规则15. 内核生效网络规则,Service可访问Pod
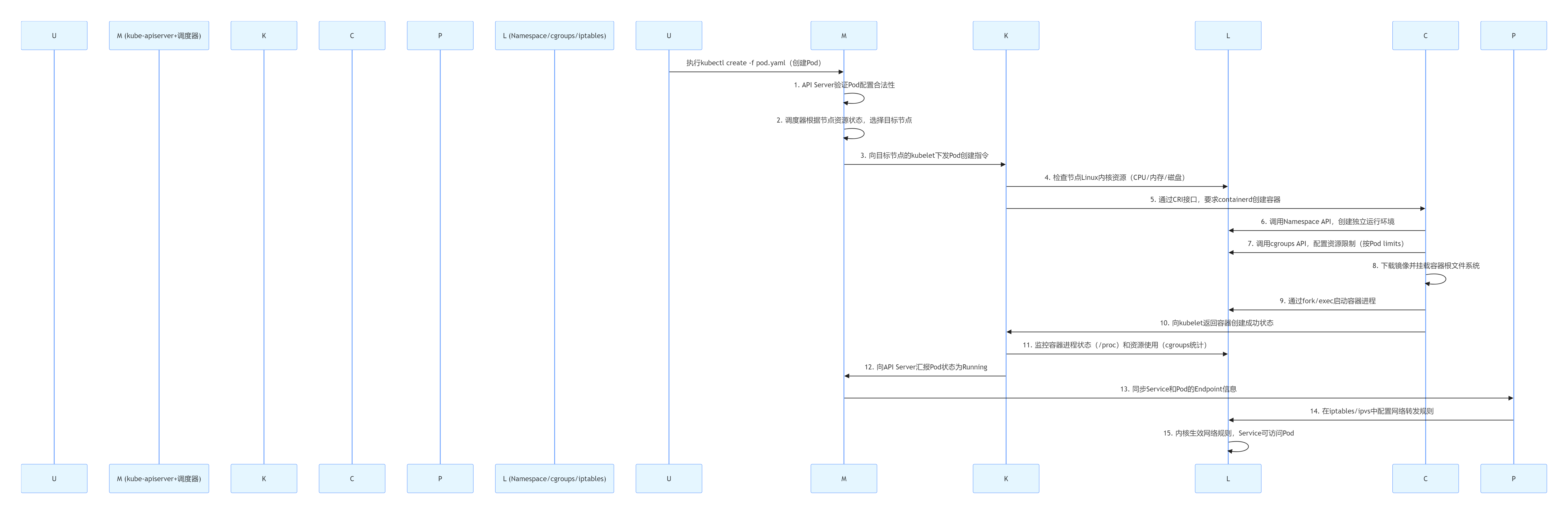
流程关键总结:
- 整个流程的 “指挥中心” 是 Master 的 kube-apiserver,所有组件都通过它同步信息;
- kubelet 是节点上的 “协调者”,不直接操作内核,而是通过 containerd 和 Linux 命令完成环境检查和状态监控;
- Linux 内核是最终的 “执行者”,Namespace、cgroups、iptables/ipvs 等能力是 Pod 能隔离运行、资源可控、网络可达的核心保障。
四、排查思路:Pod 卡在 ContainerCreating?按这个顺序查!
Pod 启动失败最常见的状态就是ContainerCreating,结合上面的组件协作流程,按 “从上层到下层、从组件到内核” 的顺序排查,效率最高:
4.1 第一步:查 kubelet 日志(看 “项目经理” 的工作记录)
kubelet 是 Pod 创建的协调者,日志会记录所有环节的报错,是排查的首选:
bash
# 查看kubelet日志(CentOS/Ubuntu通用)
journalctl -u kubelet -f | grep Pod名称
常见报错与处理:
- 报错 “insufficient memory”:节点内存不足,清理无用 Pod 或扩容节点;
- 报错 “CRI error: failed to create container”:containerd 异常,进入下一步检查。
4.2 第二步:查 containerd 状态(看 “施工队” 是否正常)
containerd 是创建容器的核心,先确认它是否运行,再查看容器创建日志:
bash
# 1. 检查containerd服务状态
systemctl status containerd
# 若未运行,启动:systemctl start containerd
# 2. 查看containerd日志,找容器创建报错
journalctl -u containerd -f | grep 容器ID(可通过kubectl describe pod获取)
常见报错与处理:
- 报错 “image pull failed”:镜像下载失败,检查镜像名称、仓库地址、网络连通性;
- 报错 “failed to create cgroup”:内核不支持 cgroups 或配置异常,检查
/sys/fs/cgroup挂载状态。
4.3 第三步:查 Linux 内核资源与配置(看 “底层环境” 是否达标)
如果组件状态正常,大概率是 Linux 内核资源或配置问题:
bash
# 1. 检查内存和CPU使用情况(是否耗尽)
free -h # 查看内存
top # 查看CPU占用
# 2. 检查Namespace和cgroups是否正常启用
ls /proc/self/ns/ # 有pid、net等目录说明Namespace正常
mount | grep cgroup # 有/sys/fs/cgroup挂载说明cgroups正常
# 3. 检查网络配置(若涉及网络插件)
ip addr # 查看Pod网卡是否创建
iptables -L -n # 查看网络规则是否存在
4.4 第四步:查 kube-proxy(仅当 Pod 启动成功但无法访问时)
如果 Pod 状态是 Running 但无法通过 Service 访问,检查 kube-proxy:
bash
# 1. 检查kube-proxy服务状态
systemctl status kube-proxy
# 2. 查看iptables/ipvs规则是否生成
iptables -L -n | grep Service的ClusterIP
# 或(若用ipvs)
ipvsadm -Ln
常见报错与处理:
- 无对应转发规则:kube-proxy 未同步 Endpoint 信息,重启 kube-proxy(
systemctl restart kube-proxy)。
K8s 组件与 Linux 内核版本兼容性对照表
一、核心兼容性总表(生产环境优先推荐)
| Linux 内核版本 | 推荐 K8s 版本范围 | Namespace 特性支持 | cgroups 特性支持 | 核心组件适配要求 | 推荐场景 | ||
|---|---|---|---|---|---|---|---|
| 4.19.x(LTS) | 1.20 ~ 1.26 | ✅ 完整支持 PID/Network/Mount/UTS/IPC Namespace❌ User Namespace(需反向移植)✅ Cgroup Namespace(4.6 + 已支持) | 🟡 主要支持 cgroups v1(全控制器)❌ cgroups v2 核心功能(如 freezer) | - kubelet:1.20+ 无兼容性问题- containerd:1.4+ ~ 1.6+(推荐 1.6.20+)- kube-proxy:支持 iptables 模式(默认),ipvs 模式需内核 4.1+(满足) | 存量集群升级、对稳定性要求极高的生产环境 | ||
| 5.4.x(LTS) | 1.24 ~ 1.30 | ✅ 所有基础 Namespace(含 User Namespace 实验性支持)✅ Cgroup Namespace 稳定支持 | 🟡 双模式支持:cgroups v1 全功能 + cgroups v2 基础功能✅ 支持 PSI(压力阻塞信息,4.20 + 已支持) | - kubelet:1.24+ 支持 cgroups v2 混合模式- containerd:1.5+ ~ 1.7+(推荐 1.7.11+)- kube-proxy:支持 iptables/ipvs 模式,nftables 模式需开启skipKernelVersionCheck(非生产推荐) |
新建集群、中等规模生产环境(节点数≤500) | ||
| 5.15.x(LTS) | 1.28 ~ 1.34 | ✅ 全量 Namespace 支持(含 User Namespace 稳定版)✅ 递归只读挂载(5.12 + 已支持) | ✅ 优先推荐 cgroups v2(全功能)✅ 根 cgroup cpu.stat文件(5.8 + 已支持)❌ cgroups v1 部分控制器(如 net_cls)逐步废弃 |
- kubelet:1.28+ 自动适配 cgroups v2- containerd:1.6+ ~ 1.7+(默认启用 cgroups v2)- kube-proxy:支持 nftables 模式(需 5.13+,满足),ipvs 模式兼容 | 大规模生产环境、需使用新特性(如 Pod 用户命名空间) | ||
| 6.1.x(LTS) | 1.32 ~ 1.36+ | ✅ 所有 Namespace 特性(含 Pod 用户命名空间 GA 支持)✅ tmpfs noswap支持(6.3 + 已支持) |
✅ cgroups v2 最优支持✅ 所有控制器(cpu/memory/io/pids)性能优化 | - kubelet:1.32+ 支持最新 sysctl 参数(如 tcp_rmem)- containerd:1.7+ ~ 2.0+- kube-proxy:nftables 模式原生支持(无需跳过版本检查) | 超大规模集群、对性能和安全性要求极高的场景 |
二、关键特性与内核版本映射表(生产环境重点关注)
| 特性名称 | 最低内核版本要求 | 关联 K8s 组件 / 功能 | 生产使用建议 |
|---|---|---|---|
| Namespace 完整隔离(PID/Network/Mount/UTS/IPC) | 2.6.32+ | 所有容器基础隔离 | 无特殊要求,所有推荐内核均满足 |
| User Namespace(Pod 独立用户权限) | 6.5+(GA) | kubelet、containerd | K8s 1.34 + 支持 GA,需内核 6.5+;旧内核仅实验性支持,不推荐生产使用 |
| Cgroup Namespace(容器级 cgroup 隔离) | 4.6+ | containerd、runc | 生产环境建议内核≥5.4,避免旧内核的隔离漏洞 |
| cgroups v2(推荐) | 4.5+(基础)/ 5.2+(完整)/ 5.8+(优化) | kubelet、containerd | K8s 1.31 + 推荐使用,内核≥5.15 时体验最佳 |
| kube-proxy ipvs 模式 | 4.1+ | kube-proxy | 需启用内核模块(ip_vs、ip_vs_rr 等),内核 4.19 + 性能更优 |
| kube-proxy nftables 模式 | 5.13+(生产)/ 5.4+(测试) | kube-proxy | 生产环境必须内核≥5.13,搭配 K8s 1.33+,nft 工具≥1.0.1 |
| Pod sysctl 参数(net.ipv4.tcp_keepalive_*) | 4.5+ | kubelet | K8s 1.29 + 支持,需内核≥4.5 才能生效 |
| Pod sysctl 参数(net.ipv4.tcp_rmem) | 4.15+ | kubelet | K8s 1.32 + 支持,仅内核≥4.15 可配置 |
| 压力阻塞信息(PSI) | 4.20+ | kubelet、监控组件(如 Prometheus) | 推荐开启,帮助识别节点资源瓶颈,内核≥5.4 时统计更准确 |
三、生产环境验证命令(快速排查内核兼容性)
1. 检查内核版本
bash
uname -r # 输出示例:5.15.0-88-generic
2. 验证 cgroups 版本(关键!)
bash
# 方法1:查看挂载点
mount | grep cgroup
# 输出含 "cgroup2 on /sys/fs/cgroup" 表示启用v2;含多个cgroup目录(如cpu、memory)表示v1
# 方法2:查看cgroups模式(kubelet视角)
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.nodeInfo.containerRuntimeVersion}{"\t"}{.status.nodeInfo.kernelVersion}{"\t"}{.status.conditions[?(@.type=="MemoryPressure")].status}{"\n"}{end}'
3. 验证 Namespace 支持
bash
# 查看当前进程的Namespace(支持的类型越多越好)
ls /proc/self/ns/
# 输出含 pid、net、mnt、uts、ipc、user、cgroup 表示全量支持
4. 验证 kube-proxy 模式兼容性
bash
# 查看kube-proxy配置(确认模式和内核要求)
kubectl -n kube-system get configmap kube-proxy -o yaml | grep mode
# 若为nftables模式,验证内核版本
if [ $(uname -r | awk -F '.' '{print $1*100 + $2}') -ge 513 ]; then
echo "内核满足nftables生产环境要求"
else
echo "内核版本过低,不推荐生产使用nftables模式"
fi
四、生产环境避坑指南
- 发行版反向移植特性:RHEL、Ubuntu、SUSE 等发行商会将新内核特性反向移植到旧内核(如 RHEL 7 的 3.10 内核支持部分 5.x 特性),实际使用时优先以发行版官方 K8s 兼容性列表为准,而非单纯看内核版本号。
- cgroups v2 迁移注意事项:从 cgroups v1 迁移到 v2 时,需确保:
- 容器运行时(containerd≥1.5)支持 v2;
- 无依赖 cgroups v1 专属控制器(如 net_cls)的应用;
- 内核参数添加
cgroup_no_v1=all(避免混合模式)。
- 内核模块启用:ipvs 模式需手动加载内核模块(
modprobe ip_vs ip_vs_rr ip_vs_wrr),nftables 模式需启用nft工具和内核模块。 - 长期维护内核优先:生产环境避免使用非 LTS 内核(如 5.6、5.7),优先选择 6.1.x、5.15.x、5.4.x、4.19.x 等 LTS 版本,维护周期长、bug 修复及时。
总结
K8s 节点的核心协作逻辑其实很简单:Master 组件负责 “决策和指令下发”,节点组件负责 “执行和状态反馈”,Linux 内核提供 “底层能力支撑”。
containerd 是直接操作内核的 “施工队”,kubelet 是协调全局的 “项目经理”,kube-proxy 是配置网络的 “路由器”,它们各司其职,通过标准化的接口(如 CRI)协作,最终依赖 Linux 的 Namespace、cgroups、iptables 等内核能力,实现 Pod 的隔离运行、资源可控和网络可达。
理解了这个协作流程,你再遇到 Pod 启动失败、资源超限、网络不通等问题时,就能快速定位是哪个组件或底层环节出了问题,排查思路会清晰很多。
这就是本文的全部内容,也感谢耐心看到这里的读者,我会持续更新,希望你能够多多关注,如果本文有帮组到你的话,还请三连加关注,你的支持就是我创作的最大动力!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)